


Artikelverzeichnis
import requestsimport jsonimport os
Öffnen Sie zunächst Baidu und suchen Sie nach dem männlichen Gott (). er selbst)—— Eddie Peng Öffnen Sie dann das Paketerfassungstool, wählen Sie die Option XHR
, drücken SieStrg+R, und dann werden Sie feststellen, dass beim Gleiten mit der Maus ein Datenpaket nach dem anderen angezeigt wird erscheint auf der rechten Seite.
...Fügen Sie nach dem Abfangen „On Notepad“ als URL ein, die später verwendet wird.
Hier gibt es viele, viele Parameter, und ich weiß nicht, welche ich ignorieren kann. Ich werde sie einfach alle im folgenden Artikel kopieren.
Das ist das Ende dessen, was direkt beobachtet werden kann. Helfen Sie uns als Nächstes, die Tür zu einer anderen Welt zu öffnen. Das ist alles! 2. Code-Analyse
“. Wenn Sie es selbst machen, kopieren Sie am besten Ihre eigenen „Anderen Parameter“. 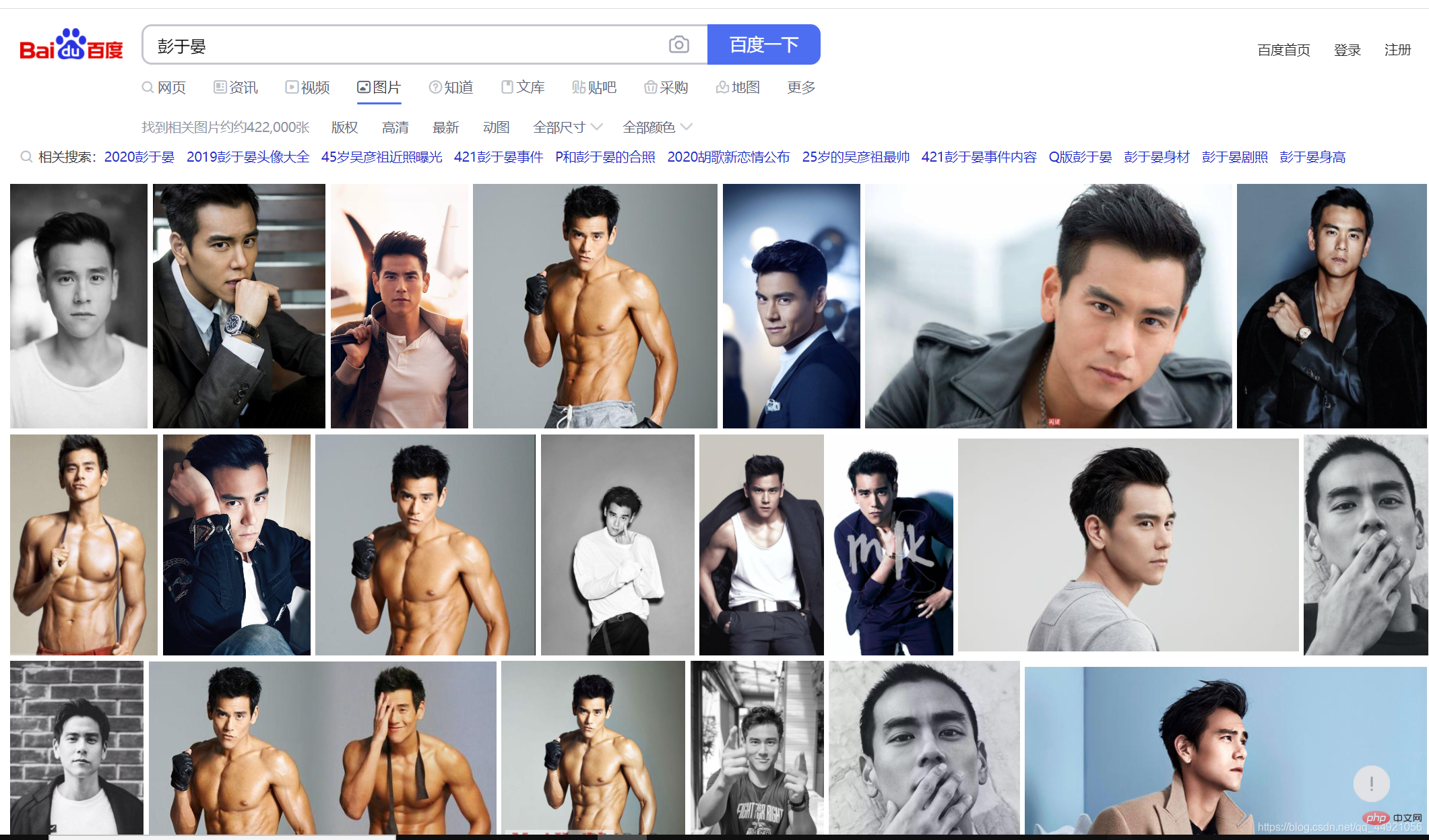 Danach können wir zunächst versuchen, es zu extrahieren und das Codierungsformat in
Danach können wir zunächst versuchen, es zu extrahieren und das Codierungsformat in 'utf-8' ändern.
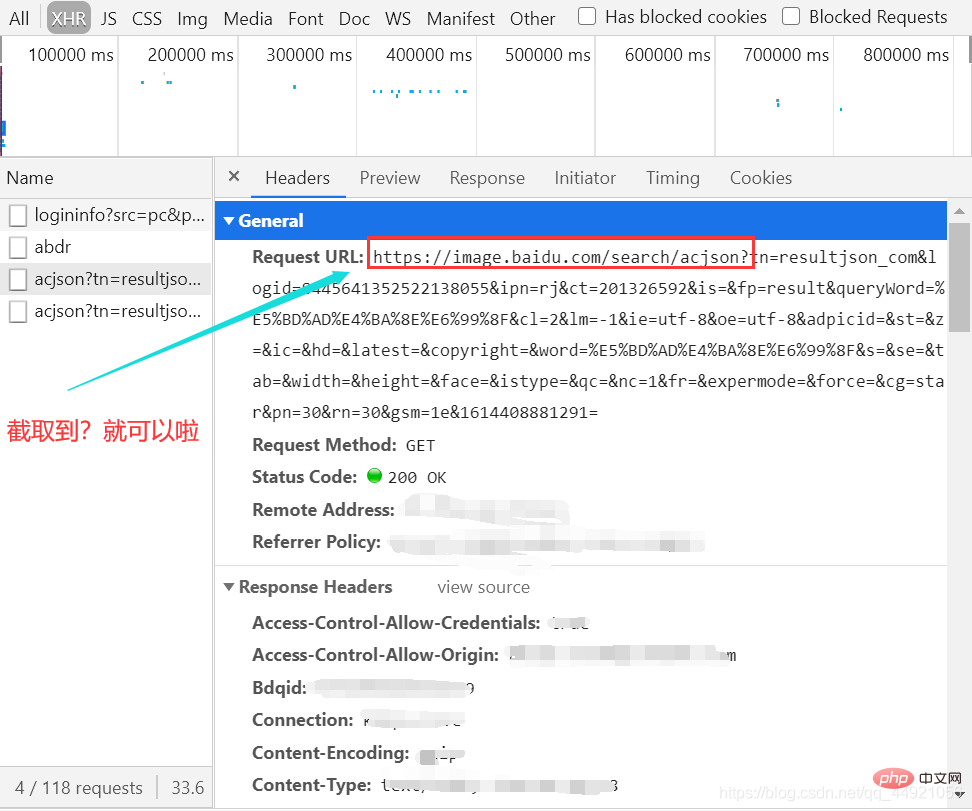
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': ' 7517080705015306512',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '彭于晏',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': '彭于晏',
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'star',
'pn': '30',
'rn': '30',
'gsm': '1e',
}
# 将编码形式转换为utf-8
response = requests.get(url=url, headers=header, params=param)
response.encoding = 'utf-8'
response = response.text print(response)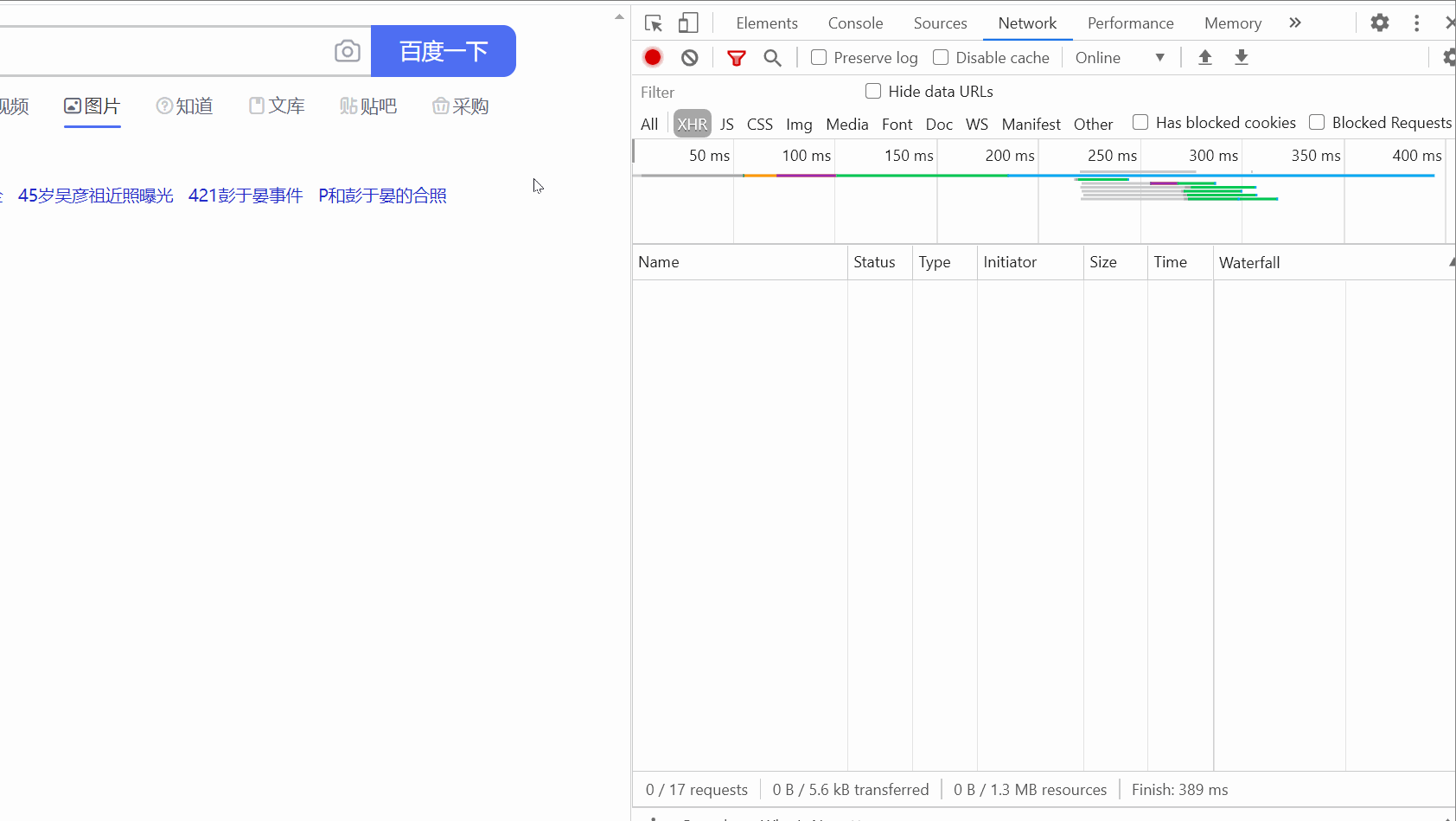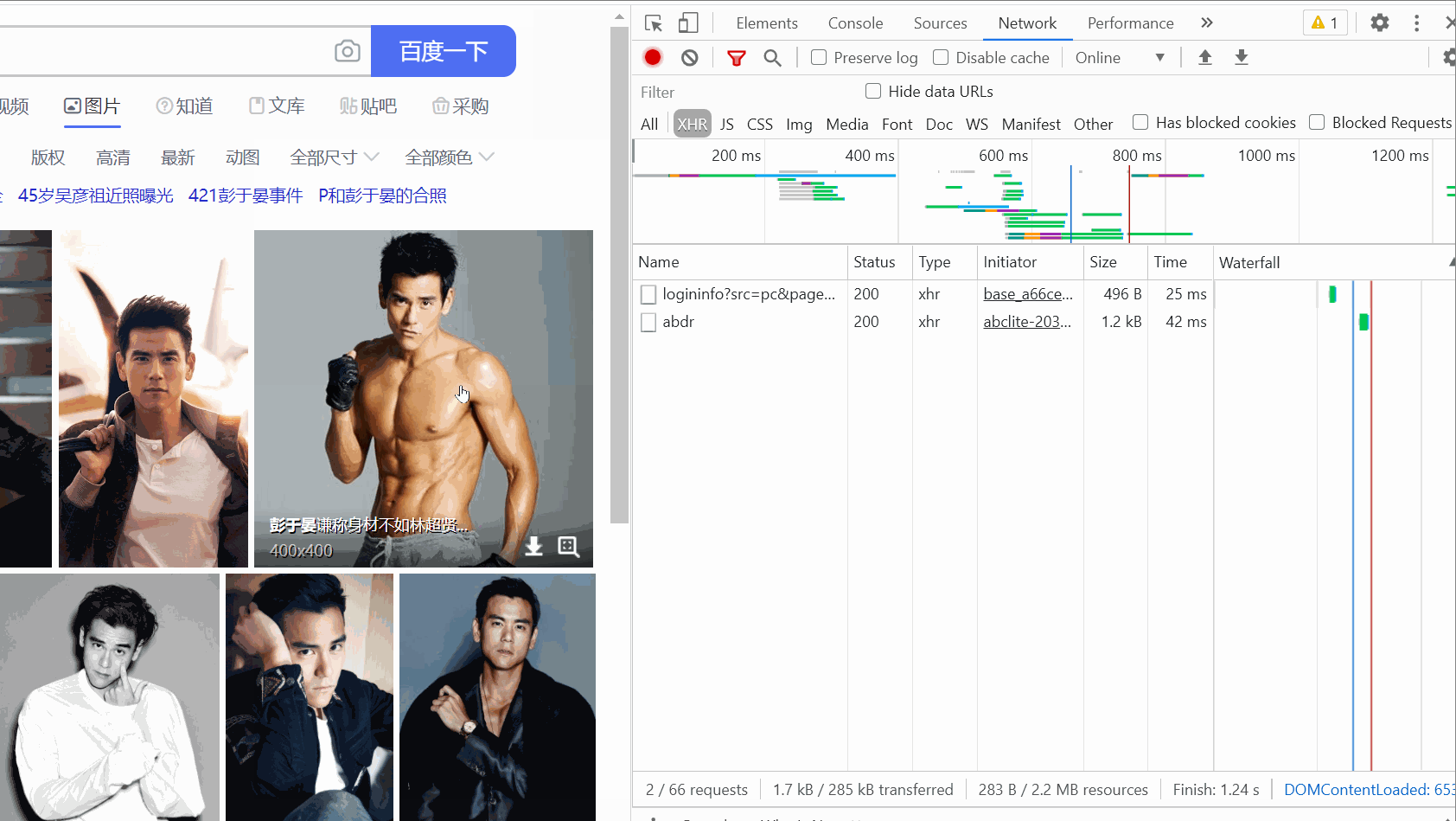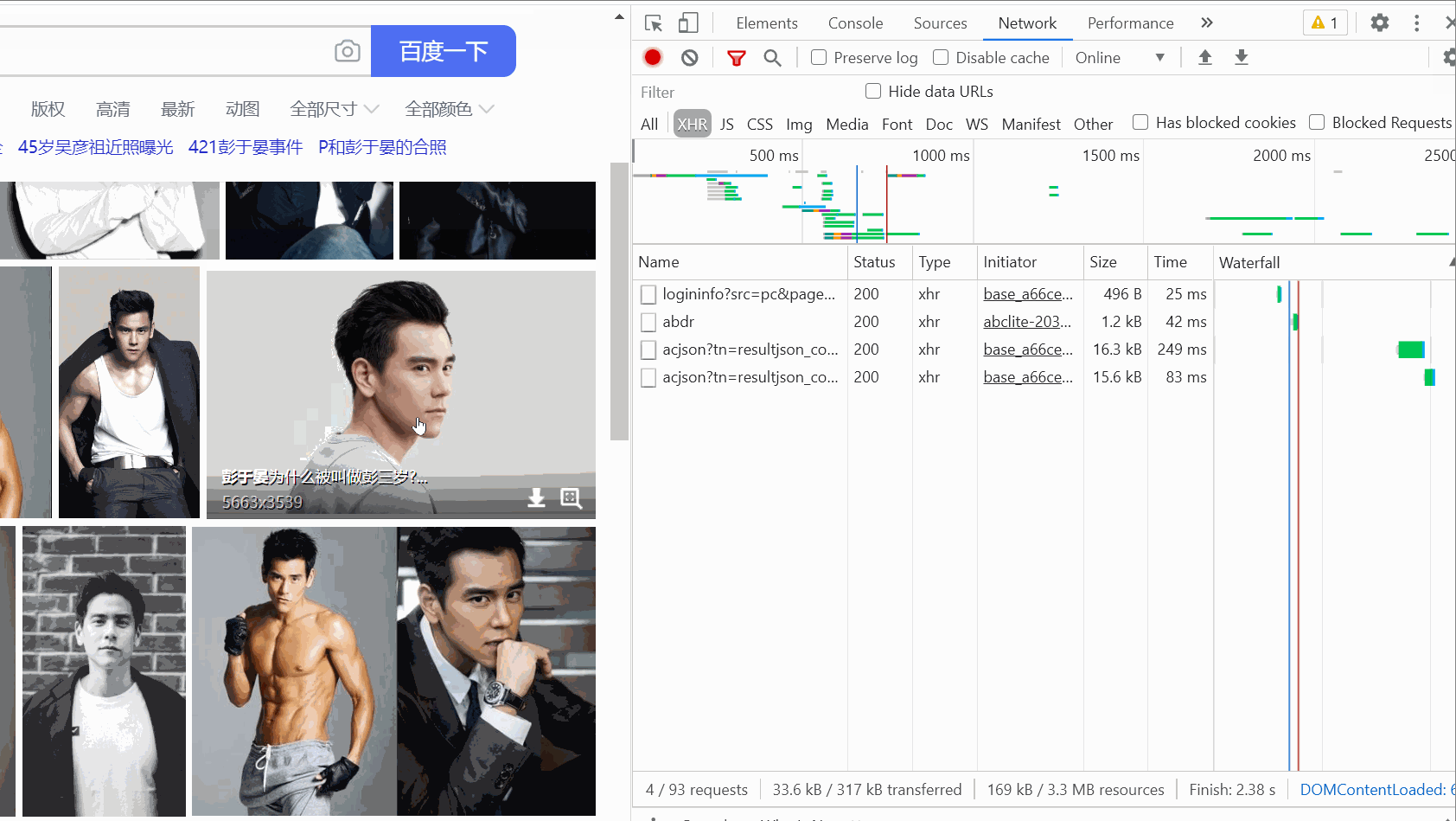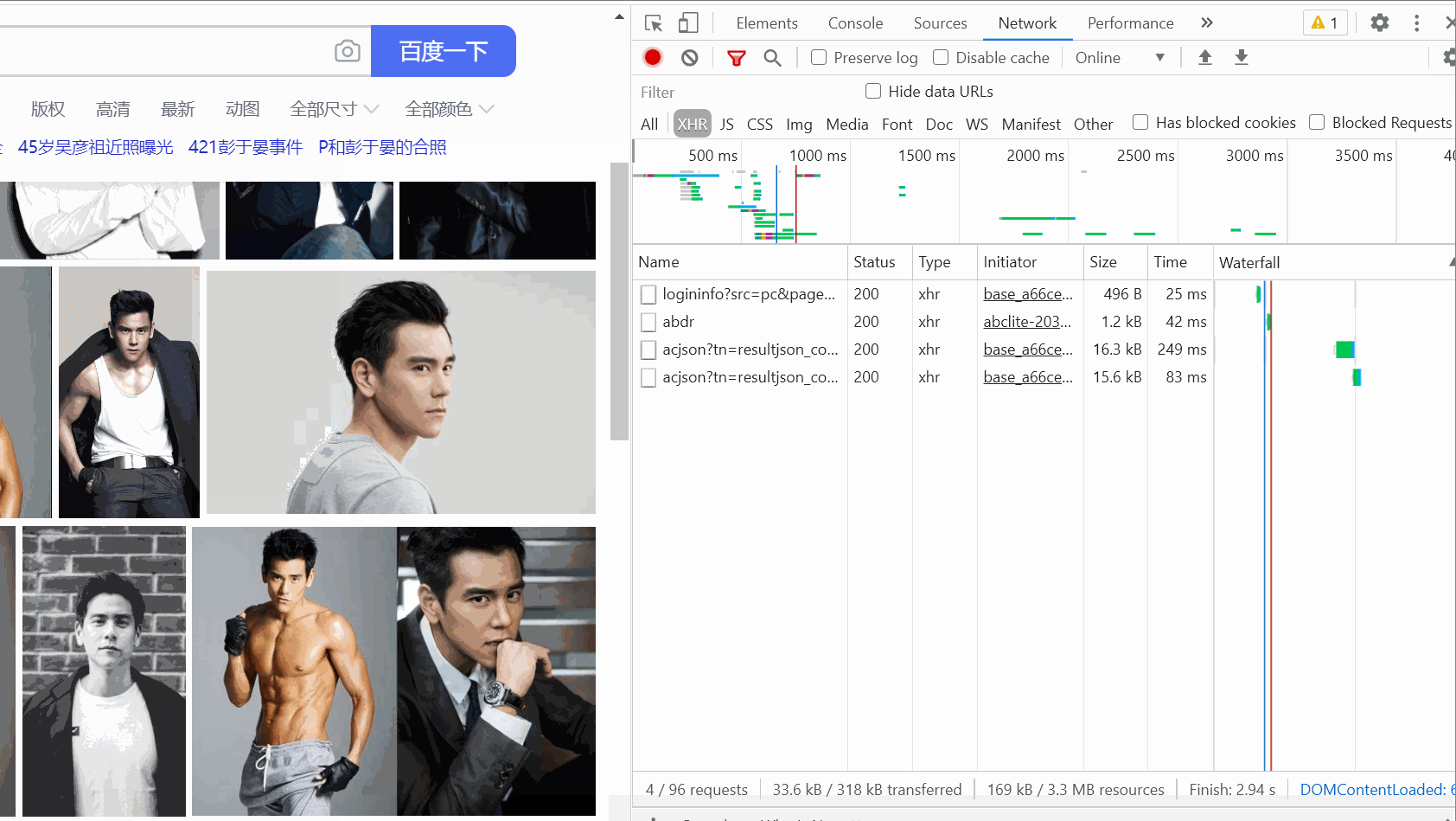 Es sieht ziemlich chaotisch aus. Es ist in Ordnung. Verpacken wir es!
Es sieht ziemlich chaotisch aus. Es ist in Ordnung. Verpacken wir es! # 把字符串转换成json数据 data_s = json.loads(response) print(data_s)
 Im Vergleich zu oben ist es viel klarer, aber immer noch nicht klar genug. Warum? Weil das gedruckte Format für uns nicht bequem anzusehen ist!
Im Vergleich zu oben ist es viel klarer, aber immer noch nicht klar genug. Warum? Weil das gedruckte Format für uns nicht bequem anzusehen ist!
Dafür gibt es zwei Lösungen.
①Importieren Sie die pprint-Bibliothek, geben Sie dann pprint.pprint(data_s) ein und Sie können drucken, wie unten gezeigt

Lösen Sie den vorherigen Schritt, Wir werden feststellen, dass alle Daten, die ich wollte, in data waren!
Dann extrahieren Sie es!
a = data_s["data"]
for i in range(len(a)-1): # -1是为了去掉上面那个空数据
data = a[i].get("thumbURL", "not exist")
print(data)Zu diesem Zeitpunkt ist es zu 90 % erfolgreich. Jetzt muss nur noch der Code gespeichert und optimiert werden!
3. Vollständiger CodeDieser Teil unterscheidet sich geringfügig vom oben genannten. Wenn Sie genau hinschauen, werden Sie ihn finden!
# -*- coding: UTF-8 -*-"""
@Author :远方的星
@Time : 2021/2/27 17:49
@CSDN :https://blog.csdn.net/qq_44921056
@腾讯云 : https://cloud.tencent.com/developer/user/8320044
"""import requestsimport jsonimport osimport pprint# 创建一个文件夹path = 'D:/百度图片'if not os.path.exists(path):
os.mkdir(path)# 导入一个请求头header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}# 用户(自己)输入信息指令keyword = input('请输入你想下载的内容:')page = input('请输入你想爬取的页数:')page = int(page) + 1n = 0pn = 1# pn代表从第几张图片开始获取,百度图片下滑时默认一次性显示30张for m in range(1, page):
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': ' 7517080705015306512',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'star',
'pn': pn,
'rn': '30',
'gsm': '1e',
}
# 定义一个空列表,用于存放图片的URL
image_url = list()
# 将编码形式转换为utf-8
response = requests.get(url=url, headers=header, params=param)
response.encoding = 'utf-8'
response = response.text # 把字符串转换成json数据
data_s = json.loads(response)
a = data_s["data"] # 提取data里的数据
for i in range(len(a)-1): # 去掉最后一个空数据
data = a[i].get("thumbURL", "not exist") # 防止报错key error
image_url.append(data)
for image_src in image_url:
image_data = requests.get(url=image_src, headers=header).content # 提取图片内容数据
image_name = '{}'.format(n+1) + '.jpg' # 图片名
image_path = path + '/' + image_name # 图片保存路径
with open(image_path, 'wb') as f: # 保存数据
f.write(image_data)
print(image_name, '下载成功啦!!!')
f.close()
n += 1
pn += 29'utf-8'
运行结果如下:
看上去挺乱的哈,没事,我们给包装一下!
在上面的基础上加上:
rrreee运行结果如下:
和上面相比,已经明晰很多了,但依旧不够明确,为什么呢?因为它打印的格式不方便我们观看!
对此,有两种解决办法。
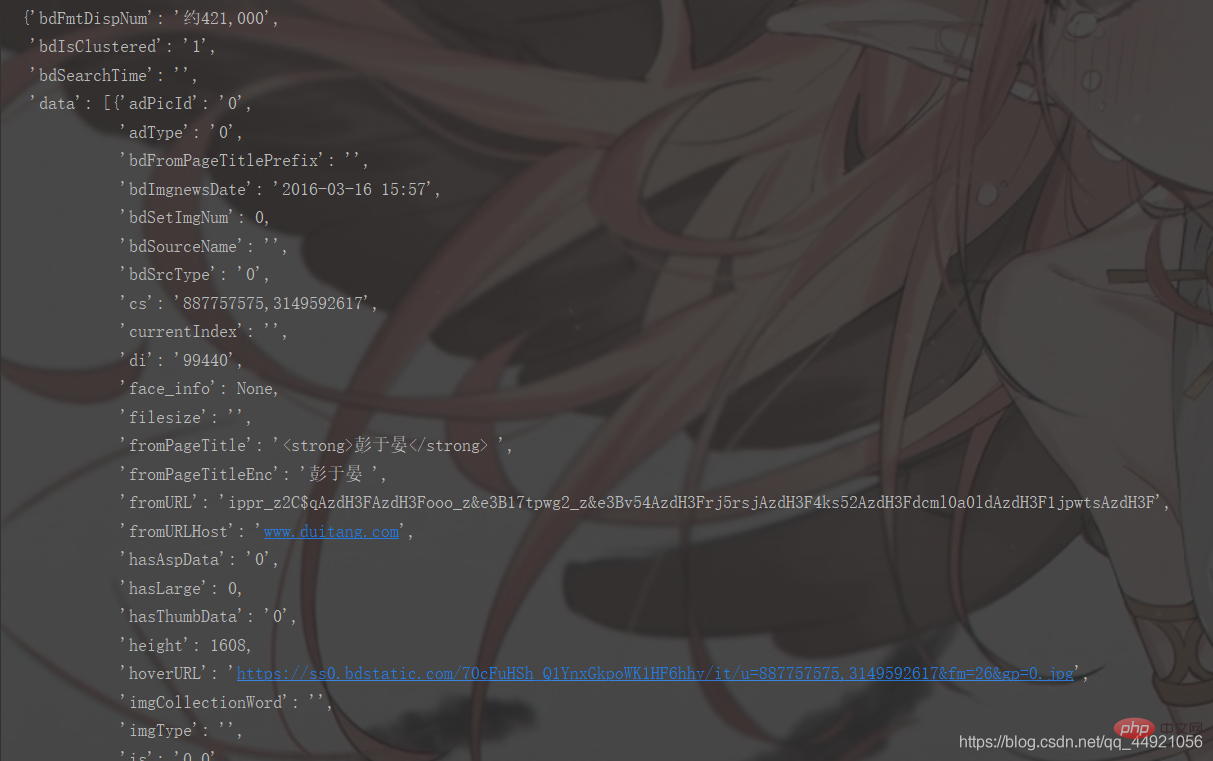
①导入pprint库,接着输入pprint.pprint(data_s),就能打印啦,如下图
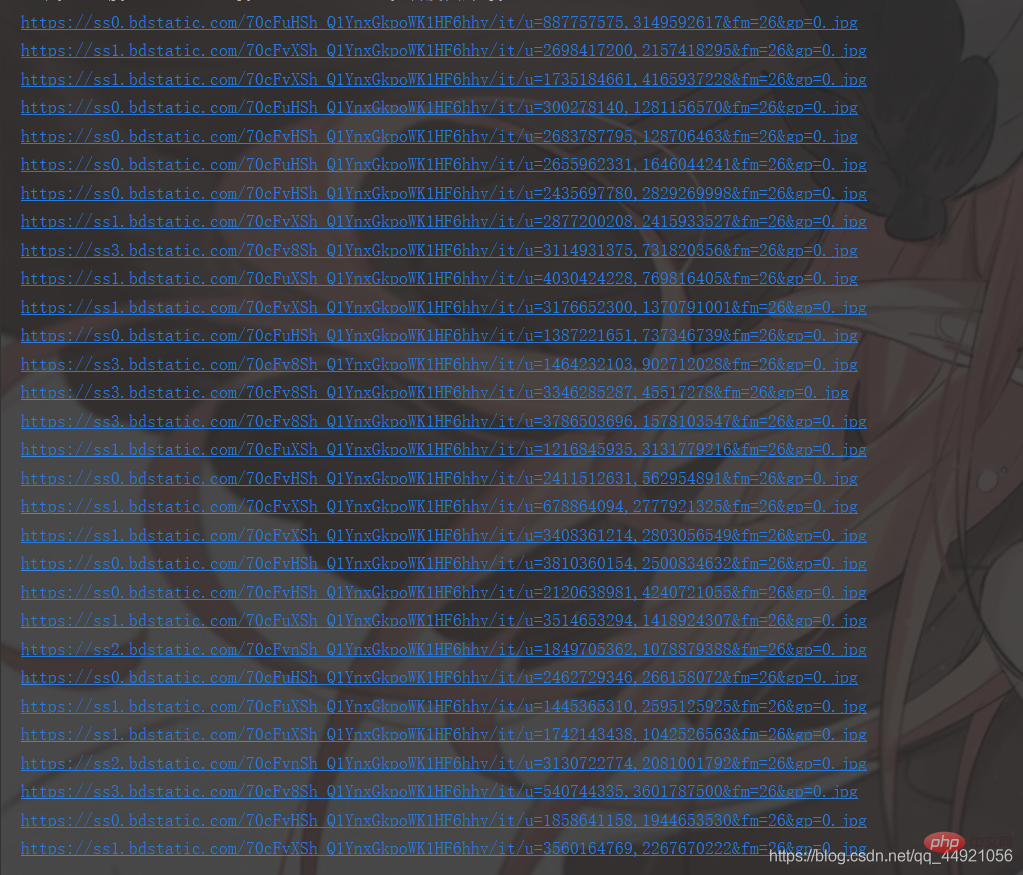
②使用json在线解析器(自行百度),结果如下:
解决掉上一步,我们会发现,想要的数据都在data
Freundliche Erinnerung
: ①: Es gibt 30 Bilder auf einer Seite
①: Es gibt 30 Bilder auf einer Seite
②: Der Eingabeinhalt kann variiert werden: wie Brücke, Mond, Sonne, Hu Ge , Zhao Liying usw.
Ich hoffe, Sie können es dreimal hintereinander liken, verfolgen, sammeln und unterstützen!
Viele kostenlose Lernempfehlungen finden Sie im Python-Tutorial(Video)
Das obige ist der detaillierte Inhalt vonPython-Crawler: Crawlen Sie Baidu-Bilder nach Ihren Wünschen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



