

Was ist der Kern von Big Data?

Der Kern von Big Data ist die Vorhersage. Der Kern von Big Data besteht darin, Probleme zu lösen, und der Kernwert von Big Data besteht darin, mathematische Algorithmen auf große Datenmengen anzuwenden, um die Möglichkeit von Ereignissen vorherzusagen und Vorhersagemodelle die Wahrscheinlichkeit, dass etwas passiert.

Die Betriebsumgebung dieses Tutorials: Windows 7-System, Dell G3-Computer.
Der Kern von Big Data ist die Vorhersage. Es wird oft als Teil der künstlichen Intelligenz bzw. als eine Art maschinelles Lernen betrachtet. Doch diese Definition ist irreführend. Bei Big Data geht es nicht darum, Maschinen beizubringen, wie Menschen zu denken.
Im Gegenteil: Es wendet mathematische Algorithmen auf riesige Datenmengen an, um die Möglichkeit von Ereignissen vorherzusagen. Die Wahrscheinlichkeit, dass eine E-Mail als Spam herausgefiltert wird, die Wahrscheinlichkeit, dass das eingegebene „teh“ „the“ sein sollte, die Wahrscheinlichkeit, dass eine Person die Straße rechtzeitig überqueren kann, basierend auf der Flugbahn und Geschwindigkeit einer Person, die über die Straße läuft innerhalb des Bereichs, den Big Data vorhersagen kann. Wenn eine Person die Straße rechtzeitig überqueren kann, muss das Auto natürlich beim Überqueren nur geringfügig langsamer werden. Der Schlüssel zum Erfolg dieser Prognosesysteme liegt darin, dass sie auf riesigen Datenmengen basieren. Wenn Systeme außerdem immer mehr Daten erhalten, können sie intelligent genug werden, um automatisch nach den besten Signalen und Mustern zu suchen und sich selbst zu verbessern.
Big-Data-Vorhersage (Big-Data-Kernanwendung)
Big-Data-Vorhersage ist die Kernanwendung von Big Data, die die traditionelle Vorhersage auf „On-the-Fly-Messung“ erweitert. Der Vorteil der Big-Data-Vorhersage besteht darin, dass sie ein sehr schwieriges Vorhersageproblem in ein relativ einfaches Beschreibungsproblem umwandelt, das für herkömmliche kleine Datensätze einfach unerreichbar ist. Aus der Perspektive der Vorhersage sind die durch die Big-Data-Vorhersage erzielten Ergebnisse nicht nur einfache und objektive Schlussfolgerungen für den Umgang mit realen Geschäften, sondern können auch zur Unterstützung von Geschäftsentscheidungen verwendet werden.
1. Vorhersage ist der Kernwert von Big Data
Der Kernwert von Big Data liegt in der Vorhersage, und der Kern des Geschäftsbetriebs besteht darin, auf der Grundlage von Vorhersagen korrekte Urteile zu fällen . Wenn es um Big-Data-Anwendungen geht, sind die häufigsten Anwendungsfälle „Vorhersage des Aktienmarktes“, „Vorhersage der Grippe“, „Vorhersage des Verbraucherverhaltens“ usw.
Big-Data-Vorhersage basiert auf Big Data und Vorhersagemodellen, um die Wahrscheinlichkeit von etwas in der Zukunft vorherzusagen. Der größte Unterschied zwischen Big Data und traditioneller Datenanalyse besteht darin, dass die Analyse von der „Betrachtung der Vergangenheit, die geschehen ist“, zur „Betrachtung der Zukunft, die bald geschehen wird“ verlagert wird.
Die logische Grundlage der Big-Data-Vorhersage ist, dass jede unkonventionelle Änderung im Voraus Zeichen haben muss und alles Spuren hat, denen es folgen kann. Wenn das Muster zwischen Zeichen und Änderungen gefunden wird, können Vorhersagen getroffen werden. Bei der Big-Data-Prognose kann nicht festgestellt werden, dass etwas definitiv passieren wird. Vielmehr geht es darum, die Wahrscheinlichkeit dafür anzugeben, dass ein Ereignis eintritt.
Die kontinuierliche Wiederholung von Experimenten und die zunehmende Anhäufung großer Datenmengen ermöglichen es dem Menschen, kontinuierlich verschiedene Muster zu entdecken und so die Zukunft vorherzusagen. Die Nutzung von Big Data zur Vorhersage möglicher Katastrophen, die Nutzung von Big Data zur Analyse möglicher Krebsursachen und zur Suche nach Behandlungsmethoden sind Unternehmungen, von denen die Menschheit in Zukunft profitieren kann.
Big Data wurde beispielsweise von der Polizei von Los Angeles und der University of California verwendet, um das Auftreten von Kriminalität vorherzusagen. Google Flu Trends verwendet Suchschlüsselwörter, um die Ausbreitung der Vogelgrippe vorherzusagen Daten für die Stadtplanung; Das Meteorologische Büro sammelt aktuelle meteorologische Bedingungen und Satellitenwolkenbilder, um zukünftige Wetterbedingungen genauer beurteilen zu können.
2. Veränderungen im Denken über Big-Data-Vorhersagen
In der Vergangenheit stützten sich die Entscheidungen der Menschen hauptsächlich auf 20 % strukturierter Daten, während Big-Data-Vorhersagen die anderen 80 % unstrukturierter Daten zur Entscheidungsfindung nutzen können. Die Big-Data-Vorhersage verfügt über mehr Datendimensionen, eine schnellere Datenfrequenz und eine größere Datenbreite. Im Vergleich zur Ära kleiner Daten hat sich das Denken der Big-Data-Vorhersage in drei wesentliche Richtungen verändert: echte Stichproben statt Vorhersageeffizienz statt Genauigkeit;
1) Echte Stichproben statt Stichproben
Im Zeitalter kleiner Datenmengen erfanden die Menschen aufgrund fehlender Mittel zur Gewinnung aller Stichproben die Methode der „zufälligen Umfragedaten“. Theoretisch gilt: Je zufälliger eine Stichprobe gezogen wird, desto repräsentativer ist sie für die Gesamtstichprobe. Das Problem ist jedoch, dass die Gewinnung einer Zufallsstichprobe äußerst teuer und zeitaufwändig ist. Bevölkerungsumfragen sind ein typisches Beispiel. Für ein Land ist es schwierig, jedes Jahr eine Bevölkerungsumfrage durchzuführen, da Zufallsumfragen zu zeitaufwändig und arbeitsintensiv sind. Das Aufkommen von Cloud Computing und Big-Data-Technologie ermöglicht jedoch große Datenmengen genügend Beispieldaten und sogar die gesamte Bevölkerungsdaten werden möglich. 2) Effizienz statt Genauigkeit tausend Meilen verpasst". Wenn beispielsweise für eine Volkszählung 1.000 Personen zufällig aus einer Gesamtstichprobe von 100 Millionen Menschen ausgewählt werden und bei der Berechnung für 1.000 Personen ein Fehler auftritt, wird die Abweichung bei einer Vergrößerung auf 100 Millionen Menschen sehr groß sein. Bei der vollständigen Stichprobe gibt es jedoch genauso viele Abweichungen wie vorhanden, und sie werden nicht verstärkt.
Im Zeitalter von Big Data ist es viel wichtiger, schnell einen groben Überblick und Entwicklungskontext zu erhalten, als strikte Genauigkeit. Manchmal, wenn wir über große Mengen neuer Datentypen verfügen, ist die Genauigkeit weniger wichtig, weil wir immer noch einen Überblick darüber haben, wie die Dinge laufen. Einfache Algorithmen, die auf großen Datenmengen basieren, sind effektiver als komplexe Algorithmen, die auf kleinen Datenmengen basieren. Der Zweck der Datenanalyse besteht nicht nur in der Datenanalyse, sondern auch in der Entscheidungsfindung. Daher ist auch die Aktualität sehr wichtig.
3) Korrelation statt Kausalität
Big-Data-Forschung unterscheidet sich von der herkömmlichen logischen Argumentationsforschung. Sie erfordert statistische Suche, Vergleich, Clustering, Klassifizierung und andere Analysen und Induktionen großer Datenmengen und achtet auf die Korrelation bzw. Korrelation der Daten Relevanz. Korrelation bedeutet, dass zwischen den Werten von zwei oder mehr Variablen eine gewisse Regelmäßigkeit besteht. Es gibt keine absoluten Korrelationen, sondern nur Möglichkeiten. Wenn die Korrelation jedoch stark ist, ist die Wahrscheinlichkeit, dass eine Korrelation erfolgreich ist, sehr hoch.
Korrelation kann uns helfen, die Gegenwart zu erfassen und die Zukunft vorherzusagen. Wenn A und B oft zusammen auftreten, müssen wir nur beachten, dass B auftritt, um vorherzusagen, dass A auch auftreten wird.
Der Korrelation zufolge muss unser Verständnis der Welt nicht mehr auf Annahmen basieren. Diese Annahme bezieht sich auf die Annahme, die für ein Phänomen über seinen Entstehungsmechanismus und seinen internen Mechanismus aufgestellt wurde. Wir müssen also keine Hypothesen darüber aufstellen, welche Suchbegriffe darauf hinweisen, wann und wo sich die Grippe ausbreitet; wie Fluggesellschaften Flüge bewerten oder welche Kochvorlieben die Walmart-Kunden haben; Stattdessen können wir eine Korrelationsanalyse mit Big Data durchführen, um herauszufinden, welche Suchbegriffe am meisten auf die Ausbreitung der Grippe hinweisen, ob die Preise für Flugtickets in die Höhe schnellen werden und welche Lebensmittel von Menschen, die während eines Hurrikans zu Hause bleiben, am meisten nachgefragt werden.
Datengetriebene Korrelationsanalyse von Big Data ersetzt fehleranfällige, auf Annahmen basierende Methoden. Methoden zur Big-Data-Korrelationsanalyse sind genauer, schneller und weniger anfällig für Verzerrungen. Auf Korrelationsanalysen basierende Vorhersagen sind der Kern von Big Data.
Die Korrelationsanalyse selbst ist von großer Bedeutung und legt auch die Grundlage für die Untersuchung kausaler Zusammenhänge. Indem wir Dinge identifizieren, die möglicherweise zusammenhängen, können wir darauf aufbauend eine weitere kausale Analyse durchführen. Wenn ein kausaler Zusammenhang besteht, dann gehen Sie noch einen Schritt weiter, um herauszufinden, warum. Dieser praktische Mechanismus reduziert die Kosten der Kausalanalyse durch strenge Experimente. Aus den Korrelationen können wir auch einige wichtige Variablen ermitteln, die in Experimenten zur Überprüfung kausaler Zusammenhänge verwendet werden können.
3. Typische Anwendungsfelder der Big-Data-Vorhersage
Das Internet hat die Popularisierung von Big-Data-Vorhersageanwendungen erleichtert. Basierend auf inländischen und ausländischen Fällen sind die folgenden 11 Bereiche die vielversprechendsten Anwendungsfelder für Big-Data-Vorhersage. .
1) Wettervorhersage
Die Wettervorhersage ist ein typisches Anwendungsgebiet für Big-Data-Vorhersage. Die Granularität der Wettervorhersagen wurde von Tagen auf Stunden verkürzt, und es gelten strenge Anforderungen an die Aktualität. Wenn Berechnungen mit herkömmlichen Methoden auf der Grundlage massiver Daten durchgeführt werden, ist die Zukunft bereits gekommen und die Vorhersagen werden zum Zeitpunkt der Schlussfolgerung keinen Wert mehr haben. Die Entwicklung der Big-Data-Technologie bietet jedoch Hochgeschwindigkeits-Rechenfunktionen, die die Effektivität erheblich verbessern und Genauigkeit der Wettervorhersagen.
2) Vorhersage von Sportereignissen
Während der Weltmeisterschaft 2014 haben Unternehmen wie Google, Baidu, Microsoft und Goldman Sachs Plattformen zur Vorhersage von Spielergebnissen eingeführt. Die Vorhersageergebnisse von Baidu sind mit einer Vorhersagegenauigkeit von 67 % in den gesamten 64 Spielen und einer Genauigkeit von 94 % nach dem Einzug in die Ko-Runde am auffälligsten. Das bedeutet, dass zukünftige Sportereignisse durch Big-Data-Vorhersagen gesteuert werden.
Die Google-WM-Vorhersage basiert auf den umfangreichen Veranstaltungsdaten von Opta Sports, um das endgültige Vorhersagemodell zu erstellen. Baidu hat in den letzten fünf Jahren 37.000 Spieldaten von 987 Mannschaften (einschließlich Nationalmannschaften und Vereinsmannschaften) auf der ganzen Welt durchsucht und Daten mit der chinesischen Lotterie-Website Lecai.com und dem europäischen Betfair-Indexdatenanbieter SPdex Cooperation importiert Daten aus dem Wettmarkt, erstellte ein Prognosemodell mit 199.972 Spielern und 112 Millionen Daten und erstellte auf dieser Basis Ergebnisprognosen.
Nach der erfolgreichen Erfahrung von Internetunternehmen zu urteilen, können Vorhersagen über andere Ereignisse wie die Champions League, die NBA und andere Ereignisse getroffen werden, solange historische Daten zu Sportereignissen und die Zusammenarbeit mit Indexunternehmen vorliegen.
3) Börsenprognose
Letztes Jahr ergaben Untersuchungen der Warwick Business School in Großbritannien und des Department of Physics der Boston University in den USA, dass von Nutzern bei Google gesuchte Finanzschlüsselwörter möglicherweise die Richtung der Finanzen vorhersagen können Markt, und die Rendite der entsprechenden Anlagestrategie lag bei bis zu 326 %. Zuvor versuchten einige Experten, Börsenschwankungen anhand der Stimmung von Twitter-Blogbeiträgen vorherzusagen.
4) Marktpreisprognose
CPI wird verwendet, um die aufgetretenen Preisschwankungen zu charakterisieren, aber die Daten des Bureau of Statistics sind nicht maßgeblich. Big Data kann den Menschen helfen, die zukünftige Preisentwicklung zu verstehen und Inflation oder Wirtschaftskrisen im Voraus vorherzusagen. Der typischste Fall ist, dass Jack Ma im Voraus durch Alibaba B2B Big Data von der asiatischen Finanzkrise erfahren hat.
Es ist einfacher, den Preis eines einzelnen Produkts vorherzusagen, insbesondere für standardisierte Produkte wie Flugtickets. Der von „Qunar“ bereitgestellte „Flugticketkalender“ ist eine Preisvorhersage, die Ihnen den ungefähren Preis von Flugtickets verraten kann ein paar Monate.
Da die Produktion, die Kanalkosten und der ungefähre Bruttogewinn der Waren in einem vollständig wettbewerbsorientierten Markt relativ stabil sind, sind die preisbezogenen Variablen relativ fest und das Verhältnis von Angebot und Nachfrage der Waren kann im E-Commerce in Echtzeit überwacht werden Plattform, sodass Preise vorhersehbar sind. Basierend auf den Vorhersageergebnissen können Kaufzeitempfehlungen gegeben oder Händler dazu angeleitet werden, dynamische Preisanpassungen und Marketingaktivitäten durchzuführen, um den Gewinn zu maximieren. 5) Vorhersage des Nutzerverhaltens . „House of Cards“ wählt Schauspieler und Handlungsstränge aus, Baidu betreibt präzise Werbung und Marketing auf der Grundlage von Benutzerpräferenzen, Alibaba verpackt maßgeschneiderte Produkte für die Produktionslinie basierend auf Tmall-Benutzereigenschaften und Amazon prognostiziert das Klickverhalten der Benutzer und versendet Produkte im Voraus Profitieren Sie von Vorhersagen zum Internetnutzerverhalten. Wie in Abbildung 1 dargestellt.
Abbildung 1 Vorhersage des Benutzerverhaltens
Dank der Entwicklung der Sensortechnologie und des Internets der Dinge brauen sich Erkenntnisse zum Offline-Benutzerverhalten zusammen. Kostenloses kommerzielles WLAN, iBeacon-Technologie, Kamerabildüberwachung, Indoor-Positionierungstechnologie, NFC-Sensornetzwerk und Warteschlangensystem können Offline-Bewegung, Aufenthalt, Reisemuster und andere Daten der Benutzer erkennen, um präzise Marketing- oder Produktanpassungen durchzuführen. 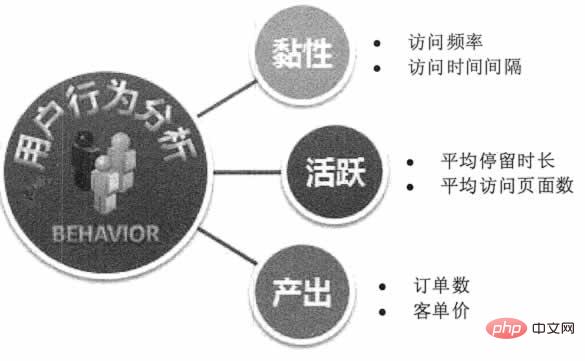
6) Vorhersage der menschlichen Gesundheit
Die traditionelle chinesische Medizin kann einige versteckte chronische Krankheiten im menschlichen Körper durch Schauen, Riechen, Fragen und Beobachten entdecken und kann sogar erkennen, welche Symptome eine Person in Zukunft haben könnte, indem sie auf ihren Körper schaut ihre Verfassung. Die körperlichen Anzeichen des Körpers verändern sich nach bestimmten Regeln, und der menschliche Körper weist bereits vor dem Auftreten chronischer Krankheiten einige anhaltende Anomalien auf. Wenn Big Data solche Anomalien beherrscht, können theoretisch chronische Krankheiten vorhergesagt werden.
Nature News & Views berichteten über eine Studie von Zeevi et al. Die komplexe Frage, wie die Blutzuckerkonzentration eines Menschen durch bestimmte Lebensmittel beeinflusst wird. Die Studie schlägt ein Vorhersagemodell vor, das personalisierte Ernährungsempfehlungen basierend auf den Mikroben im Darm und anderen Aspekten der Physiologie liefern und Blutzuckerreaktionen genauer vorhersagen kann als aktuelle Standards. Wie in Abbildung 2 dargestellt.
Abbildung 2 Modell zur Vorhersage der Blutzuckerkonzentration
Intelligente Hardware ermöglicht die Big-Data-Vorhersage chronischer Krankheiten. Tragbare Geräte und intelligente Gesundheitsgeräte können dem Netzwerk dabei helfen, menschliche Gesundheitsdaten wie Herzfrequenz, Gewicht, Blutfette, Blutzucker, Menge an Bewegung, Schlafmenge usw. zu sammeln. Wenn diese Daten genau und umfassend genug sind und über Modelle zur Vorhersage chronischer Krankheiten verfügen, die Algorithmen bilden können, werden diese tragbaren Geräte die Benutzer möglicherweise in Zukunft an das Risiko bestimmter chronischer Krankheiten erinnern. 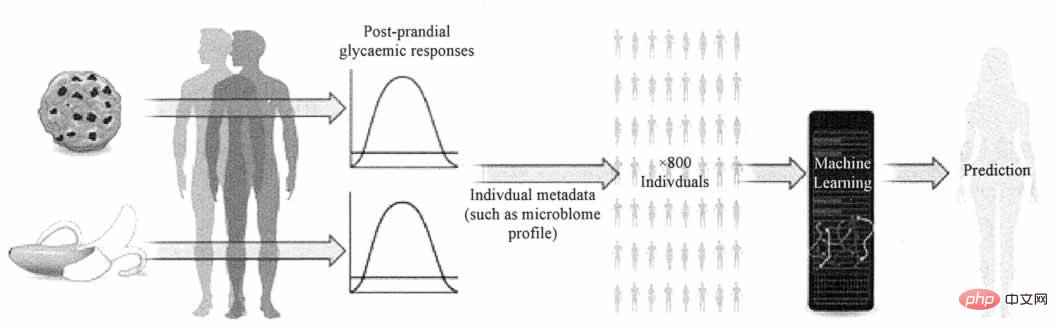
7) Vorhersage einer Krankheitsepidemie
Die Vorhersage einer Krankheitsepidemie bezieht sich auf die Vorhersage der Möglichkeit eines großflächigen Epidemieausbruchs auf der Grundlage der Suchbedingungen und des Einkaufsverhaltens der Menschen. Die klassischste „Grippevorhersage“ fällt in diese Kategorie. Wenn es aus einem bestimmten Gebiet immer mehr Suchanfragen nach „Influenza“ und „Isatis-Wurzel“ gibt, liegt die Vermutung nahe, dass es dort einen Influenza-Trend gibt.
Baidu hat ein Produkt zur Krankheitsvorhersage auf den Markt gebracht. Es kann derzeit eine umfassende Analyse der Aktivitäts- und Trenddiagramme jeder Provinz des Landes und der meisten Städte, Bezirke und Kreise auf Präfekturebene für vier Krankheiten durchführen: Grippe, Hepatitis, Tuberkulose und Überwachung sexuell übertragbarer Krankheiten. In Zukunft wird die Zahl der von Baidu Disease Prediction überwachten Krankheitsarten von derzeit 4 auf über 30 erweitert und deckt damit häufigere Krankheiten und Epidemien ab. Benutzer können gezielte Prävention basierend auf lokalen Vorhersageergebnissen ergreifen.
8) Katastrophenvorhersage
Meteorologische Vorhersage ist die typischste Katastrophenvorhersage. Wenn Naturkatastrophen wie Erdbeben, Überschwemmungen, hohe Temperaturen und starke Regenfälle mithilfe von Big Data vorhergesagt und im Voraus informiert werden können, wird dies dazu beitragen, Katastrophen zu reduzieren, zu verhindern und Katastrophenhilfe zu leisten. Der Unterschied zur Vergangenheit besteht darin, dass die bisherigen Datenerfassungsmethoden Probleme wie Sackgassen und hohe Kosten aufwiesen. Im Zeitalter des Internets der Dinge können Menschen billige Sensorkameras und drahtlose Kommunikationsnetzwerke verwenden, um eine Echtzeit-Datenüberwachung durchzuführen Erfassung und anschließende Analyse von Big-Data-Vorhersagen, um genauere Vorhersagen von Naturkatastrophen zu erzielen.
9) Vorhersage von Umweltveränderungen
Zusätzlich zu kurzfristigen Mikrowetter- und Katastrophenvorhersagen können auch längerfristige und makroökonomische Vorhersagen zu Umwelt- und ökologischen Veränderungen erstellt werden. Die schrumpfenden Wald- und Ackerflächen, die gefährdete Tier- und Pflanzenwelt, die zunehmenden Küsten und der Treibhauseffekt sind „chronische Probleme“, mit denen die Erde konfrontiert ist. Je mehr Daten Menschen über Veränderungen in den Ökosystemen und Wettermustern der Erde wissen, desto einfacher wird es sein, zukünftige Umweltveränderungen zu modellieren und schlimme Veränderungen zu verhindern. Big Data kann Menschen dabei helfen, mehr Erddaten zu sammeln, zu speichern und auszuwerten, und stellt gleichzeitig Werkzeuge für Vorhersagen bereit.
10) Vorhersage des Verkehrsverhaltens
Die Vorhersage des Verkehrsverhaltens bezieht sich auf die Analyse der Einzel- und Gruppenmerkmale von reisenden Personen und Fahrzeugen auf der Grundlage der LBS-Positionsdaten von Benutzern und Fahrzeugen und die Vorhersage des Verkehrsverhaltens. Die Transportabteilung kann eine intelligente Fahrzeugplanung durchführen oder Gezeitenspuren anwenden, indem sie den Verkehrsfluss auf verschiedenen Straßen zu unterschiedlichen Zeiten vorhersagt. Benutzer können basierend auf den Vorhersageergebnissen Straßen mit geringerer Stauwahrscheinlichkeit auswählen.
Baidus LBS-Vorhersage basierend auf Kartenanwendungen deckt einen größeren Bereich ab. Es kann die Migrationstrends der Menschen während des Frühlingsfestes vorhersagen, um die Einstellung von Zuglinien und -routen zu steuern. Es kann den Personenstrom an malerischen Orten während der Feiertage vorhersagen, um die Menschen bei der Auswahl malerischer Orte zu unterstützen. Darüber hinaus verfügt es über Baidu-Heatmaps, über die es Benutzer informieren kann Geschäftsviertel, Zoos und andere Orte in Städten können die Reiseentscheidungen der Benutzer und die Standortwahl von Unternehmen beeinflussen.
11) Energieverbrauchsprognose
Das Likou State Grid System Operations Center verwaltet mehr als 80 % des kalifornischen Stromnetzes und liefert jährlich 289 Millionen Megawatt Strom an 35 Millionen Nutzer mit mehr als 40.000 Kilometern Stromleitungen. Das Zentrum nutzt die Software von Space-Time Insight für intelligentes Management, analysiert umfassend umfangreiche Daten aus verschiedenen Datenquellen wie Wetter, Sensoren und Messgeräten, prognostiziert Änderungen des Energiebedarfs an verschiedenen Orten, führt eine intelligente Stromverteilung durch und gleicht die Stromversorgung aus das gesamte Netzwerk und die Bedürfnisse und reagieren schnell auf mögliche Krisen. Chinas Smart-Grid-Industrie testet bereits ähnliche Big-Data-Vorhersageanwendungen.
Zusätzlich zu den 11 oben aufgeführten Feldern kann die Big-Data-Vorhersage auch auf die Vorhersage von Immobilien, die Vorhersage der Beschäftigungssituation, die Vorhersage der Punktzahl für Hochschulaufnahmeprüfungen, die Vorhersage des Wahlergebnisses, die Vorhersage der Oscar-Verleihung, die Risikobewertung von Versicherungsnehmern und die Rückzahlung von Kreditnehmern angewendet werden Kapazitätsbewertung und andere Bereiche ermöglichen es Menschen, quantifizierbare, überzeugende und überprüfbare Einblicke in die Zukunft zu gewinnen, und der Charme der Big-Data-Vorhersage wird entfesselt.
Weitere Informationen zu diesem Thema finden Sie in der Spalte „FAQ“!
Das obige ist der detaillierte Inhalt vonWas ist der Kern von Big Data?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
Fähigkeiten zur Verarbeitung von Big-Data-Strukturen: Chunking: Teilen Sie den Datensatz auf und verarbeiten Sie ihn in Blöcken, um den Speicherverbrauch zu reduzieren. Generator: Generieren Sie Datenelemente einzeln, ohne den gesamten Datensatz zu laden, geeignet für unbegrenzte Datensätze. Streaming: Lesen Sie Dateien oder fragen Sie Ergebnisse Zeile für Zeile ab, geeignet für große Dateien oder Remote-Daten. Externer Speicher: Speichern Sie die Daten bei sehr großen Datensätzen in einer Datenbank oder NoSQL.
 Erfahrungsaustausch in der C++-Entwicklung: praktische Erfahrung in der C++-Big-Data-Programmierung
Nov 22, 2023 am 09:14 AM
Erfahrungsaustausch in der C++-Entwicklung: praktische Erfahrung in der C++-Big-Data-Programmierung
Nov 22, 2023 am 09:14 AM
Im Internetzeitalter ist Big Data zu einer neuen Ressource geworden. Mit der kontinuierlichen Verbesserung der Big-Data-Analysetechnologie ist die Nachfrage nach Big-Data-Programmierung immer dringlicher geworden. Als weit verbreitete Programmiersprache sind die einzigartigen Vorteile von C++ bei der Big-Data-Programmierung immer deutlicher hervorgetreten. Im Folgenden werde ich meine praktischen Erfahrungen in der C++-Big-Data-Programmierung teilen. 1. Auswahl der geeigneten Datenstruktur Die Auswahl der geeigneten Datenstruktur ist ein wichtiger Bestandteil beim Schreiben effizienter Big-Data-Programme. In C++ gibt es eine Vielzahl von Datenstrukturen, die wir verwenden können, z. B. Arrays, verknüpfte Listen, Bäume, Hash-Tabellen usw.
 Fünf große Entwicklungstrends in der AEC/O-Branche im Jahr 2024
Apr 19, 2024 pm 02:50 PM
Fünf große Entwicklungstrends in der AEC/O-Branche im Jahr 2024
Apr 19, 2024 pm 02:50 PM
AEC/O (Architecture, Engineering & Construction/Operation) bezieht sich auf die umfassenden Dienstleistungen, die Architekturdesign, Ingenieurdesign, Bau und Betrieb in der Bauindustrie anbieten. Im Jahr 2024 steht die AEC/O-Branche angesichts des technologischen Fortschritts vor sich ändernden Herausforderungen. In diesem Jahr wird voraussichtlich die Integration fortschrittlicher Technologien stattfinden, was einen Paradigmenwechsel in Design, Bau und Betrieb einläuten wird. Als Reaktion auf diese Veränderungen definieren Branchen Arbeitsprozesse neu, passen Prioritäten an und verbessern die Zusammenarbeit, um sich an die Bedürfnisse einer sich schnell verändernden Welt anzupassen. Die folgenden fünf großen Trends in der AEC/O-Branche werden im Jahr 2024 zu Schlüsselthemen und empfehlen den Weg in eine stärker integrierte, reaktionsfähigere und nachhaltigere Zukunft: integrierte Lieferkette, intelligente Fertigung
 Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
May 09, 2024 am 09:01 AM
Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
May 09, 2024 am 09:01 AM
1. Hintergrund des Baus der 58-Portrait-Plattform Zunächst möchte ich Ihnen den Hintergrund des Baus der 58-Portrait-Plattform mitteilen. 1. Das traditionelle Denken der traditionellen Profiling-Plattform reicht nicht mehr aus. Der Aufbau einer Benutzer-Profiling-Plattform basiert auf Data-Warehouse-Modellierungsfunktionen, um Daten aus mehreren Geschäftsbereichen zu integrieren, um genaue Benutzerporträts zu erstellen Und schließlich muss es über Datenplattformfunktionen verfügen, um Benutzerprofildaten effizient zu speichern, abzufragen und zu teilen sowie Profildienste bereitzustellen. Der Hauptunterschied zwischen einer selbst erstellten Business-Profiling-Plattform und einer Middle-Office-Profiling-Plattform besteht darin, dass die selbst erstellte Profiling-Plattform einen einzelnen Geschäftsbereich bedient und bei Bedarf angepasst werden kann. Die Mid-Office-Plattform bedient mehrere Geschäftsbereiche und ist komplex Modellierung und bietet allgemeinere Funktionen. 2.58 Benutzerporträts vom Hintergrund der Porträtkonstruktion im Mittelbahnsteig 58
 Diskussion über die Gründe und Lösungen für das Fehlen eines Big-Data-Frameworks in der Go-Sprache
Mar 29, 2024 pm 12:24 PM
Diskussion über die Gründe und Lösungen für das Fehlen eines Big-Data-Frameworks in der Go-Sprache
Mar 29, 2024 pm 12:24 PM
Im heutigen Big-Data-Zeitalter sind Datenverarbeitung und -analyse zu einer wichtigen Unterstützung für die Entwicklung verschiedener Branchen geworden. Als Programmiersprache mit hoher Entwicklungseffizienz und überlegener Leistung hat die Go-Sprache im Bereich Big Data nach und nach Aufmerksamkeit erregt. Im Vergleich zu anderen Sprachen wie Java, Python usw. verfügt die Go-Sprache jedoch über eine relativ unzureichende Unterstützung für Big-Data-Frameworks, was einigen Entwicklern Probleme bereitet hat. In diesem Artikel werden die Hauptgründe für das Fehlen eines Big-Data-Frameworks in der Go-Sprache untersucht, entsprechende Lösungen vorgeschlagen und anhand spezifischer Codebeispiele veranschaulicht. 1. Gehen Sie zur Sprache
 KI, digitale Zwillinge, Visualisierung ... Höhepunkte der Yizhiwei-Herbst-Produkteinführungskonferenz 2023!
Nov 14, 2023 pm 05:29 PM
KI, digitale Zwillinge, Visualisierung ... Höhepunkte der Yizhiwei-Herbst-Produkteinführungskonferenz 2023!
Nov 14, 2023 pm 05:29 PM
Die Produkteinführung im Herbst 2023 von Yizhiwei ist erfolgreich abgeschlossen! Lassen Sie uns gemeinsam die Highlights der Konferenz Revue passieren lassen! 1. Intelligente, integrative Offenheit, die es digitalen Zwillingen ermöglicht, produktiv zu werden. Ning Haiyuan, Mitbegründer von Kangaroo Cloud und CEO von Yizhiwei, sagte in seiner Eröffnungsrede: Beim diesjährigen strategischen Treffen des Unternehmens haben wir die Hauptrichtung der Produktforschung und -entwicklung als festgelegt „Intelligente inklusive Offenheit“ „Drei Kernfähigkeiten“, wobei wir uns auf die drei Kernschlüsselwörter „intelligente inklusive Offenheit“ konzentrieren, schlagen wir außerdem das Entwicklungsziel vor, „digitale Zwillinge zu einer Produktivkraft zu machen“. 2. EasyTwin: Entdecken Sie eine neue Digital-Twin-Engine, die einfacher zu verwenden ist 1. Erkunden Sie von 0.1 bis 1.0 weiterhin die Digital-Twin-Fusion-Rendering-Engine, um bessere Lösungen mit ausgereiftem 3D-Bearbeitungsmodus, praktischen interaktiven Blaupausen und umfangreichen Modellressourcen zu erhalten
 Erste Schritte: Verwendung der Go-Sprache zur Verarbeitung großer Datenmengen
Feb 25, 2024 pm 09:51 PM
Erste Schritte: Verwendung der Go-Sprache zur Verarbeitung großer Datenmengen
Feb 25, 2024 pm 09:51 PM
Als Open-Source-Programmiersprache hat die Go-Sprache in den letzten Jahren nach und nach große Aufmerksamkeit und Verwendung gefunden. Es wird von Programmierern wegen seiner Einfachheit, Effizienz und leistungsstarken Funktionen zur gleichzeitigen Verarbeitung bevorzugt. Auch im Bereich der Big-Data-Verarbeitung verfügt die Go-Sprache über großes Potenzial. Sie kann zur Verarbeitung großer Datenmengen, zur Leistungsoptimierung und zur guten Integration in verschiedene Big-Data-Verarbeitungstools und Frameworks eingesetzt werden. In diesem Artikel stellen wir einige grundlegende Konzepte und Techniken der Big-Data-Verarbeitung in der Go-Sprache vor und zeigen anhand spezifischer Codebeispiele, wie die Go-Sprache verwendet wird.
 Big-Data-Verarbeitung in C++-Technologie: Wie nutzt man In-Memory-Datenbanken, um die Big-Data-Leistung zu optimieren?
May 31, 2024 pm 07:34 PM
Big-Data-Verarbeitung in C++-Technologie: Wie nutzt man In-Memory-Datenbanken, um die Big-Data-Leistung zu optimieren?
May 31, 2024 pm 07:34 PM
Bei der Verarbeitung großer Datenmengen kann die Verwendung einer In-Memory-Datenbank (z. B. Aerospike) die Leistung von C++-Anwendungen verbessern, da sie Daten im Computerspeicher speichert, wodurch Festplatten-E/A-Engpässe vermieden und die Datenzugriffsgeschwindigkeiten erheblich erhöht werden. Praxisbeispiele zeigen, dass die Abfragegeschwindigkeit bei Verwendung einer In-Memory-Datenbank um mehrere Größenordnungen schneller ist als bei Verwendung einer Festplattendatenbank.