
Ich habe 6 große Hersteller interviewt und Ihnen eine Zusammenfassung häufiger Redis-Interviewfragen mitgeteilt, die schlecht gestellt wurden (mit Antworten und Analyse). Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird für alle hilfreich sein.

【Verwandte Empfehlung: Redis-Video-Tutorial】
Wissenspunkte zwischenspeichern

Welche Arten von Cache gibt es?
Caching ist ein wirksames Mittel zur Verbesserung der Hotspot-Datenzugriffsleistung in Szenarien mit hoher Parallelität und wird häufig bei der Entwicklung von Projekten eingesetzt.
Die Cache-Typen sind unterteilt in: lokaler Cache, verteilter Cache und mehrstufiger Cache.
Lokaler Cache:
Der lokale Cache wird im Speicher des Prozesses zwischengespeichert, z. B. in unserem JVM-Heap. Er kann mit LRUMap implementiert werden, oder Sie können Tools wie Ehcache verwenden zu erreichen.
Lokaler Cache ist Speicherzugriff, hat keinen Remote-Interaktionsaufwand und bietet die beste Leistung. Im Allgemeinen ist der Cache jedoch klein und kann nicht erweitert werden.
Verteilter Cache:
Verteilter Cache kann dieses Problem sehr gut lösen.
Der verteilte Cache weist im Allgemeinen eine gute horizontale Skalierbarkeit auf und kann problemlos Szenarien mit großen Datenmengen verarbeiten. Der Nachteil besteht darin, dass Remote-Anfragen erforderlich sind und die Leistung nicht so gut ist wie beim lokalen Caching.
Mehrstufiger Cache:
Um diese Situation auszugleichen, wird im tatsächlichen Geschäft im Allgemeinen der mehrstufige Cache verwendet. Der lokale Cache speichert nur einige Hotspot-Daten mit der höchsten Zugriffshäufigkeit und andere Hotspots Die Daten werden im verteilten Cache abgelegt.
Bei den aktuellen First-Tier-Herstellern ist dies auch die am häufigsten verwendete Caching-Lösung. Eine einzelne Caching-Lösung ist oft schwierig, viele Szenarien mit hoher Parallelität zu unterstützen.Eliminierungsstrategie
Um eine höhere Leistung zu gewährleisten, wird Speicher zum Speichern von Daten verwendet, wenn die gespeicherten Daten die Cache-Kapazität überschreiten , müssen die zwischengespeicherten Daten entfernt werden. Allgemeine Eliminierungsstrategien umfassenFIFO zur Löschung der ältesten Daten, LRU zur Löschung der am längsten verwendeten Daten und LFU zur Löschung der am längsten verwendeten Daten.
noeviction: Gibt einen Fehler zurück, wenn das Speicherlimit erreicht ist und der Client versucht, einen Befehl auszuführen, der dazu führen würde, dass mehr Speicher verwendet wird (die meisten Schreibbefehle, aber DEL und einige Ausnahmen)
allkeys- lru: Versuchen Sie, die am wenigsten verwendeten Schlüssel (LRU) zu recyceln, damit Platz für neu hinzugefügte Daten bleibt.
volatile-lru: Versuchen Sie, die am wenigsten verwendeten Schlüssel (LRU) zu recyceln, aber nur Schlüssel im abgelaufenen Satz, damit Platz für neu hinzugefügte Daten bleibt.
allkeys-random: Zufallsschlüssel wiederverwenden, um Platz für neu hinzugefügte Daten zu schaffen.
volatile-random: Zufallsschlüssel wiederverwenden, um Platz für neu hinzugefügte Daten zu schaffen, jedoch nur für Schlüssel im abgelaufenen Satz.
volatile-ttl: Schlüssel im abgelaufenen Satz recyceln und Schlüsseln mit kürzerer Überlebenszeit (TTL) Vorrang geben, damit Platz für die Speicherung neu hinzugefügter Daten vorhanden ist.
Wenn kein Schlüssel die Voraussetzungen für das Recycling erfüllt, sind die Strategienvolatile-lru, volatile-random und volatile-ttl fast identisch mit noeviction.
LinkedHashMap implementiert. Die Implementierung ist wie folgt:

LRU-Strategie: Fügen Sie das Mindeste hinzu Kürzlich unbenutztes TimeoutInfoHolder Objekt evict gelöscht.
In einem echten Interview werden Sie gebeten, den LUR-Algorithmus zu schreiben. Es gibt so viele Tricks und Sie können sie nicht beenden. Sie können entweder den oben genannten oder den folgenden beantworten. Es ist relativ einfach, eine Datenstruktur für die Implementierung der LRU zu finden, sofern Sie die Prinzipien kennen.
Memcache
Bitte beachten Sie, dassMemcache später als MC abgekürzt wird.
Werfen wir zunächst einen Blick auf die Eigenschaften von MC:und MongoDB entscheidet:
Schlüssel darf 250 Bytes nicht überschreiten;Redis Lassen Sie uns kurz über die Eigenschaften von
Redissprechen, um einen einfachen Vergleich mit MC zu ermöglichen.
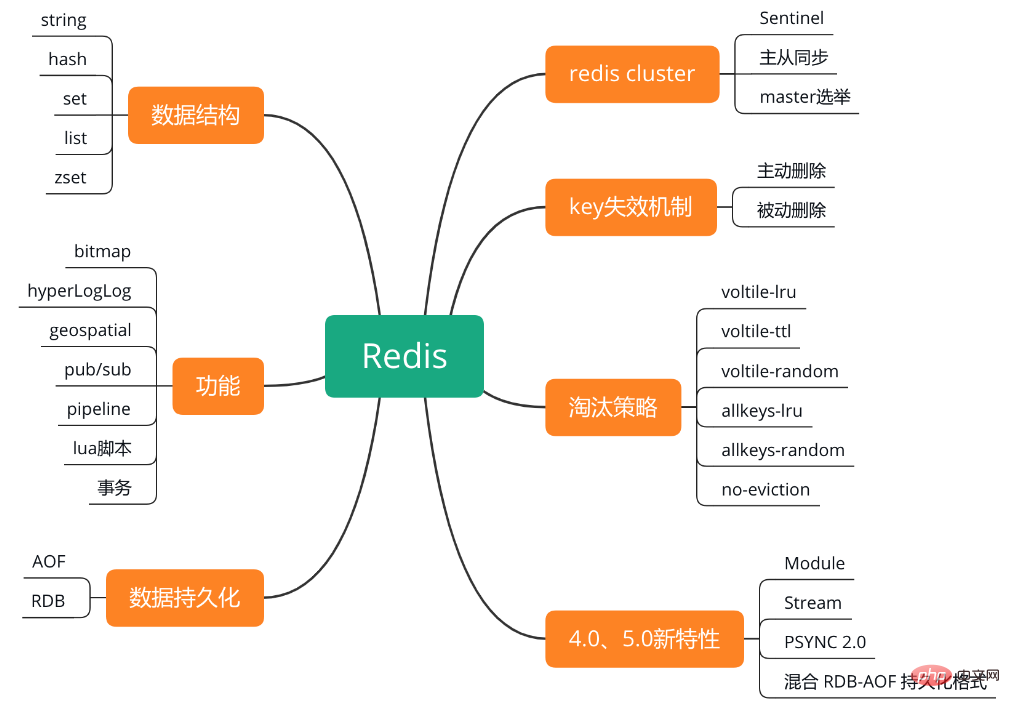
Anders als MC verwendet Redis den Single-Threaded-Modus, um Anfragen zu verarbeiten. Dafür gibt es zwei Gründe: Zum einen, weil ein nicht blockierender asynchroner Ereignisverarbeitungsmechanismus verwendet wird, und zum anderen, dass es sich bei den zwischengespeicherten Daten ausschließlich um Speichervorgänge handelt und die E/A-Zeit nicht zu lang ist und ein einzelner Thread die Kosten vermeiden kann des Thread-Kontextwechsels.Detaillierte Erklärung von RedisDie Wissenspunktstruktur von Redis ist in der folgenden Abbildung dargestellt.
FunktionSehen wir uns an, welche Funktionen
Redisbietet! Schauen wir uns zunächst die Grundtypen an:
String: Der Typ
Stringist der am häufigsten verwendete Typ in Redis, und die interne Implementierung wird über SDS (Simple Dynamic String) gespeichert. . SDS ähnelt ArrayList in Java, was die häufige Zuweisung von Speicher durch die Vorabzuweisung von redundantem Speicherplatz reduzieren kann. Dies ist der einfachste Typ, einfach gewöhnliches Set-and-Get, das einfaches KV-Caching durchführt.
Aber in einer echten Entwicklungsumgebung konvertieren viele Leute möglicherweise viele komplexe Strukturen zur Speicherung und Verwendung in
String. Einige Leute konvertieren beispielsweise gerne Objekte oder List zur Speicherung in JSONString die Reihenfolge umkehren und so weiter. Ich werde hier nicht darüber diskutieren, ob dies richtig oder falsch ist, aber ich hoffe dennoch, dass jeder die am besten geeignete Datenstruktur im am besten geeigneten Szenario verwenden kann. Wenn das Objekt nicht die am besten geeignete Struktur finden kann, können Sie am besten auswählen Wenn jemand anderes Ihren Code übernimmt und sieht, dass er so
Standardist, hat dieser Typ etwas . Er sieht, dass Sie String für alles verwenden, Müll!
sind relativ umfangreich:
String ist der am häufigsten verwendete Datentyp, nicht nur Redis, jede Sprache ist der grundlegendste Typ, daher wird verwendet Redis als Cache, die Zusammenarbeit mit anderen Datenbanken als Speicherschicht und die Verwendung von Redis zur Unterstützung hoher Parallelität können die Lese- und Schreibgeschwindigkeit des Systems erheblich beschleunigen und den Druck auf die Back-End-Datenbank verringern.
Viele Systeme verwenden Redis als Echtzeitzähler des Systems, der Zähl- und Abfragefunktionen schnell implementieren kann. Und die endgültigen Datenergebnisse können zu einem bestimmten Zeitpunkt zur dauerhaften Speicherung in einer Datenbank oder einem anderen Speichermedium gespeichert werden.
Der Benutzer aktualisiert die Benutzeroberfläche und muss möglicherweise auf die Daten zugreifen, um sich erneut anzumelden, oder auf den Seitencache Cookie zugreifen, aber Redis kann verwendet werden, um die des Benutzers zentral zu verwalten Sitzung, hier Dieser Modus muss nur die hohe Verfügbarkeit von Redis sicherstellen, und jede Aktualisierung und Akquise von Benutzer-Session kann schnell abgeschlossen werden. Verbessern Sie die Effizienz erheblich.
Hash:
Dies ist eine ähnliche Struktur wie Map. Dies ermöglicht im Allgemeinen strukturierte Daten, z. B. ein Objekt (vorausgesetzt, dass dieses Objekt keine anderen Objekte verschachtelt) in liegt Redis, und jedes Mal, wenn Sie den Cache lesen oder schreiben, können Sie ein bestimmtes Feld in Hash bearbeiten.
Aber dieses Szenario ist tatsächlich etwas einfacher, da viele Objekte jetzt relativ komplex sind. Beispielsweise kann Ihr Produktobjekt viele Attribute enthalten, darunter auch Objekte. Ich verwende es in meinen eigenen Anwendungsfällen nicht so oft.
Liste:
Liste ist eine geordnete Liste, mit der man noch viele Tricks spielen kann.
Zum Beispiel können Sie List verwenden, um einige listenartige Datenstrukturen zu speichern, wie z. B. Fanlisten und Artikelkommentarlisten.
Sie können beispielsweise den Befehl lrange verwenden, um Elemente in einem bestimmten geschlossenen Intervall zu lesen, und Sie können eine Paging-Abfrage basierend auf List implementieren. Dies ist eine großartige Funktion, die Sie einfach implementieren können Hochleistungs-Paging. Etwas wie Weibo, das Dropdown- und kontinuierliches Paging verwendet, ist leistungsstark und kann seitenweise aufgerufen werden. Zum Beispiel können Sie eine einfache Nachrichtenwarteschlange erstellen, diese am Kopf der
Listeeinfügen und am Ende der Liste wieder herausholen.
Listeselbst ist eine häufig verwendete Datenstruktur in unserem Entwicklungsprozess, ganz zu schweigen von heißen Daten.
kann problemlos blockierende Warteschlangen implementieren, und Sie können Left-In- und Right-Out-Befehle verwenden, um das Warteschlangendesign abzuschließen. Beispiel: Ein Datenproduzent kann Daten von links über den Befehl Lpush einfügen, und mehrere Datenkonsumenten können den Befehl BRpop verwenden, um die Daten am Ende der Liste zu „greifen“, die durch den Befehl BRpop blockiert wurden.
Anwendung zur Artikellisten- oder Datenseitenanzeige.
Wenn beispielsweise die Anzahl der Benutzer unserer häufig verwendeten Blog-Website zunimmt und jeder Benutzer seine eigene Artikelliste hat und diese in Seiten angezeigt werden müssen, können Sie dies in Betracht ziehen Redis Die Liste ist nicht nur geordnet, sondern unterstützt auch das Abrufen von Elementen entsprechend dem Bereich, wodurch die Paging-Abfragefunktion perfekt gelöst werden kann. Verbessern Sie die Abfrageeffizienz erheblich.
Set:
Set ist ein ungeordneter Satz, der Duplikate automatisch entfernt.
Geben Sie die Daten, die dedupliziert werden müssen, direkt auf der Basis von Set in das System ein und sie werden automatisch dedupliziert. Wenn Sie eine schnelle globale Deduplizierung einiger Daten benötigen, können Sie diese natürlich auch auf Basis von JVM verwenden im Speicher HashSet führt die Deduplizierung durch, aber was ist, wenn eines Ihrer Systeme auf mehreren Maschinen bereitgestellt wird? Die globale Set-Deduplizierung muss basierend auf Redis durchgeführt werden.
Sie können Schnitt-, Vereinigungs- und Differenzoperationen basierend auf Set spielen. Wenn wir uns beispielsweise überschneiden, können wir die Freundeslisten zweier Personen kombinieren, um zu sehen, wer ihre gemeinsamen Freunde sind. Rechts.
Jedenfalls gibt es viele dieser Szenarien, da der Vergleich schnell und die Bedienung einfach ist. Zwei Abfragen können mit einem Set durchgeführt werden.
Sortierter Satz:
Sortierter Satz ist sortierter Satz, dedupliziert, kann aber sortiert werden. Beim Einschreiben wird eine Punktzahl angegeben und automatisch nach der Punktzahl sortiert.
Die Verwendungsszenarien geordneter Sätze ähneln denen von Sätzen, aber Satzsätze werden nicht automatisch geordnet, während Sortierter Satz Punkte zum Sortieren von Mitgliedern verwenden kann und beim Einfügen sortiert wird. Wenn Sie also eine geordnete und nicht duplizierte Set-Liste benötigen, können Sie optional die Datenstruktur „Sortierter Satz“ wählen.
, um eine gewichtete Warteschlange zu erstellen. Beispielsweise beträgt die Punktzahl für normale Nachrichten 1 und die Punktzahl für wichtige Nachrichten 2. Anschließend kann der Arbeitsthread die Arbeitsaufgaben in umgekehrter Reihenfolge abrufen der Partitur. Priorisieren Sie wichtige Aufgaben. Die Weibo-Hot-Search-Liste hat hinten einen Beliebtheitswert und vorne einen Namen Wird zur Implementierung von
BloomFilterverwendet;
HyperLogLog: bietet eine ungenaue Deduplizierungszählfunktion, die sich besser für Deduplizierungsstatistiken großer Datenmengen eignet, wie z
Kann verwendet werden, um den geografischen Standort zu speichern und die Standortentfernung zu berechnen oder den Standort anhand des Radius usw. zu berechnen. Haben Sie jemals darüber nachgedacht, Redis zu verwenden, um Menschen in der Nähe zu implementieren? Oder den optimalen Kartenpfad berechnen?
Diese drei können tatsächlich als Datenstruktur gezählt werden. Ich weiß nicht, wie viele Freunde sich noch daran erinnern, dass ich es in den Redis-Grundlagen erwähnt habe, wo der Traum begann. Wenn man nur die fünf Grundtypen kennt, kann man nur 60 bekommen Nun, wenn Sie die fortgeschrittene Verwendung erklären können, dann haben Sie meiner Meinung nach etwas.
pub/sub: Die -Funktion ist eine Abonnement-Veröffentlichungsfunktion, die als einfache Nachrichtenwarteschlange verwendet werden kann.
Pipeline: kann eine Reihe von Anweisungen stapelweise ausführen und alle Ergebnisse auf einmal zurückgeben, wodurch häufige Anfragenantworten reduziert werden können.
Lua:
Redisunterstützt die Übermittlung von Lua-Skripts zur Ausführung einer Reihe von Funktionen. Als ich bei meinem alten E-Commerce-Chef war, habe ich dieses Ding oft in Flash-Sale-Szenarien verwendet. Es macht Sinn und nutzt seine Atomizität.
Möchten Sie übrigens das Flash-Sale-Design sehen? Ich erinnere mich, dass ich diese Frage jedes Mal während des Interviews gestellt habe. Wenn Sie es sehen möchten, „liken“ Sie es einfach und kommentieren Sie es, um es sofort zu verkaufen.
Transaktion:
Die letzte Funktion ist eine Transaktion, aber Redis bietet keine strikte Transaktion.
Redisgarantiert nur die serielle Ausführung von Befehlen und kann alle Ausführungen garantieren, funktioniert jedoch nicht Die Ausführung des Befehls schlägt fehl, wird jedoch rückgängig gemacht, die Ausführung wird jedoch fortgesetzt. Persistenz
Redis bietet zwei Persistenzmethoden: RDB und AOF schreiben den Datensatz im Speicher in Form eines Snapshots auf die Festplatte. unter Verwendung binärer komprimierter Speicherung; AOF zeichnet jeden von
Redisverarbeiteten Schreib- oder Löschvorgang in Form eines Textprotokolls auf. RDB Speichern Sie die gesamten Redis-Daten in einer einzigen Datei, was sich besser für die Notfallwiederherstellung eignet. Der Nachteil besteht jedoch darin, dass die Daten während dieses Zeitraums verloren gehen Darüber hinaus kann das Speichern des Snapshots dazu führen, dass der Dienst für kurze Zeit nicht verfügbar ist.
AOF Der für Protokolldateischreibvorgänge verwendete Anhängemodus verfügt über eine flexible Synchronisierungsstrategie, die Synchronisierung pro Sekunde, Synchronisierung pro Änderung und Nichtsynchronisierung unterstützt. Der Nachteil besteht darin, dass AOF bei Datensätzen gleicher Größe größer ist RDB. Die Betriebseffizienz ist oft langsamer als bei RDB.
Weitere Informationen finden Sie im Kapitel zur Hochverfügbarkeit, insbesondere zu den Vor- und Nachteilen der beiden und zur Auswahl.
Serie „Slap the Interviewer“ – Redis-Wächter, Persistenz, Master-Slave, handgeschreddertes LRUHohe Verfügbarkeit
Schauen wir uns die hohe Verfügbarkeit von Redis an. Redis unterstützt die Master-Slave-Synchronisierung, bietet den Cluster-Cluster-Bereitstellungsmodus und überwacht den Status des Redis-Masterservers über Sentinel. Wenn der Master ausfällt, wird gemäß einer bestimmten Strategie ein neuer Master aus dem Slave-Knoten ausgewählt und andere Slaves werden an den neuen Master angepasst. Einfach ausgedrückt gibt es drei Strategien zur Auswahl des Masters:
Je niedriger die Priorität des Slaves eingestellt ist, desto höher ist die Priorität; Unter den gleichen Umständen gilt: Je mehr Daten der Slave kopiert, desto höher ist die Priorität ;Sentinel
Sentinel muss drei Instanzen verwenden, um seine Robustheit sicherzustellen. kann nicht garantieren, dass keine Daten verloren gehen, aber es kann die
hohe Verfügbarkeitdes Clusters sicherstellen. Warum brauchen wir drei Instanzen? Schauen wir uns zunächst an, was mit den beiden Wachposten passiert.
 Master ist ausgefallen, solange einer der beiden Sentinels, s1 und s2, denkt, dass Sie ausgefallen sind, wird er umgeschaltet und ein Sentinel wird ausgewählt, der den Fehler ausführt, aber zu diesem Zeitpunkt die meisten der Wächter müssen laufen.
Master ist ausgefallen, solange einer der beiden Sentinels, s1 und s2, denkt, dass Sie ausgefallen sind, wird er umgeschaltet und ein Sentinel wird ausgewählt, der den Fehler ausführt, aber zu diesem Zeitpunkt die meisten der Wächter müssen laufen. Der klassische Sentinel-Cluster sieht so aus:
 Die Maschine, auf der sich M1 befindet, ist ausgefallen, und es gibt zwei Sentinels. Wenn die beiden sehen, dass sie ausgefallen ist, wählen wir einen aus, der ausgeführt werden soll Failover. Einfach gut.
Die Maschine, auf der sich M1 befindet, ist ausgefallen, und es gibt zwei Sentinels. Wenn die beiden sehen, dass sie ausgefallen ist, wählen wir einen aus, der ausgeführt werden soll Failover. Einfach gut. Lieber Mann, lassen Sie mich kurz die Hauptfunktionen der Sentinel-Komponente zusammenfassen:
Master-Slave
hat dies erwähnt, es hängt eng mit der Datenpersistenz RDB und AOF zusammen, die ich zuvor erwähnt habe.
Lassen Sie mich zunächst darüber sprechen, warum wir ein Master-Slave-Architekturmodell verwenden müssen. Wie bereits erwähnt, hat eine einzelne Maschine QPS eine Obergrenze und das Merkmal von Redis ist, dass sie eine hohe Leseparallelität unterstützen muss. Dann können Sie auf einer Maschine lesen. Er schrieb auch: „Wer kann das aushalten?“ Du bist kein Mensch! Aber wenn Sie diese Master-Maschine schreiben lassen, die Daten mit anderen Slave-Maschinen synchronisieren und sie alle zum Lesen verwenden, wäre es dann nicht viel besser, eine große Anzahl von Anforderungen zu verteilen, und bei der Erweiterung kann auch problemlos eine horizontale Ebene erreicht werden Erweiterung.

-Befehl an den Master. Wenn dieser Slave zum ersten Mal eine Verbindung zum Master herstellt, wird eine vollständige Kopie ausgelöst. Der Master startet einen Thread, generiert einen RDB-Snapshot und speichert neue Schreibanforderungen im Speicher. Nachdem die RDB-Datei generiert wurde, sendet der Master diese RDB an den Slave, und der Slave führt dies anschließend aus Der erste Schritt besteht darin, ihn auf die lokale Festplatte zu schreiben und ihn dann in den Speicher zu laden. Anschließend sendet der Master alle im Speicher zwischengespeicherten neuen Namen.
Nachdem ich es gepostet habe, stellte ein Internetnutzer von CSDN: Jian_Shen_Zer eine Frage:Wenn während der Master-Slave-Synchronisierung ein neuer Slave eingeht, verwendet er
RDB. Wenn neue Daten in den Master eingehen, wie können sie mit dem Slave synchronisiert werden? Ao Bing antwortete: Dumm,
AOF, das Inkrement ist genau wie MySQLs Binlog, synchronisieren Sie einfach das Protokollinkrement mit dem Slave Service
SchlüsselablaufmechanismusDer Redis-Schlüssel kann die Ablaufzeit festlegen. Nach dem Ablauf verwendet Redis eine Kombination aus aktiven und passiven Ablaufmechanismen, wie bei MC, und der andere ist regelmäßig Aktiv löschen.
Periodisch + Lazy + Speicherbeseitigung
Caching-FAQ
Cache-Aktualisierungsmethode
Dies ist ein Problem, das bei der Entscheidung für die Verwendung von Cache berücksichtigt werden sollte. Die zwischengespeicherten Daten müssen aktualisiert werden, wenn sich die Datenquelle ändert. Die Datenquelle kann DB oder ein Remote-Dienst sein. Die Update-Methode kann ein aktives Update sein. Wenn die Datenquelle eine Datenbank ist, kann der Cache direkt nach der Aktualisierung der Datenbank aktualisiert werden.
Wenn es sich bei der Datenquelle nicht um DB, sondern um andere Remote-Dienste handelt, kann es sein, dass Datenänderungen nicht rechtzeitig aktiv erkannt werden. In diesem Fall legen Sie normalerweise ein Ablaufdatum für die zwischengespeicherten Daten fest, bei dem es sich um die maximale Toleranzzeit handelt wegen Dateninkonsistenz.
In diesem Szenario können Sie die Aktualisierung der Ungültigkeitserklärung auswählen. Wenn der Schlüssel nicht vorhanden oder ungültig ist, fordern Sie zunächst die Datenquelle auf, die neuesten Daten abzurufen, speichern Sie sie dann erneut und aktualisieren Sie das Ablaufdatum.
Dabei liegt jedoch ein Problem vor. Wenn der abhängige Remote-Dienst während der Aktualisierung auf eine Ausnahme stößt, sind die Daten nicht verfügbar. Die verbesserte Methode ist die asynchrone Aktualisierung. Dies bedeutet, dass die Daten bei Ablauf nicht gelöscht werden, sondern die alten Daten weiterhin verwendet werden und der asynchrone Thread dann die Aktualisierungsaufgabe ausführt. Dadurch wird die Fensterperiode zum Zeitpunkt des Fehlers vermieden. Es gibt auch eine rein asynchrone Update-Methode, die Daten in regelmäßigen Abständen stapelweise aktualisiert. Bei der tatsächlichen Verwendung können Sie die Aktualisierungsmethode entsprechend dem Geschäftsszenario auswählen.
Dateninkonsistenz
Das zweite Problem ist das Problem der Dateninkonsistenz. Man kann sagen, dass Sie überlegen müssen, wie Sie diesem Problem begegnen können, solange Sie den Cache verwenden. Der Grund für die Cache-Inkonsistenz ist im Allgemeinen das Scheitern der aktiven Aktualisierung. Beispielsweise kommt es nach der Aktualisierung der Datenbank aus Netzwerkgründen zu einer Zeitüberschreitung. Die Lösung besteht darin, dass Sie die Wiederholungsversuche erhöhen können, wenn der Dienst nicht besonders zeitaufwändig ist. Wenn der Dienst zeitaufwändig ist, können Sie asynchrone Kompensationsaufgaben verwenden, um fehlgeschlagene Aktualisierungen oder kurzfristige Dateninkonsistenzen zu verarbeiten wird sich nicht auf das Geschäft auswirken, solange das nächste Update erfolgreich ist und die endgültige Konsistenz garantiert werden kann.
Cache-Penetration
Cache-Penetration. Die Ursache für dieses Problem kann ein externer böswilliger Angriff sein. Beispielsweise werden Benutzerinformationen zwischengespeichert, aber der böswillige Angreifer fordert die Schnittstelle häufig mit einer nicht vorhandenen Benutzer-ID an, was dazu führt, dass der Abfrage-Cache fehlt und die Abfrage dann über die Datenbank erfolgt fehlt immer noch. Zu diesem Zeitpunkt dringt eine große Anzahl von Anforderungen in den Cache ein, um auf die Datenbank zuzugreifen. Die Lösung ist wie folgt. Speichern Sie für nicht vorhandene Benutzer ein leeres Objekt im Cache, um es zu markieren und zu verhindern, dass dieselbe ID erneut auf die Datenbank zugreift. Manchmal löst diese Methode das Problem jedoch nicht richtig und kann dazu führen, dass eine große Menge nutzloser Daten im Cache gespeichert wird. Der BloomFilter-Filter zeichnet sich durch die Existenzerkennung aus. Wenn er nicht in BloomFilter vorhanden ist, dürfen die Daten nicht vorhanden sein. Sehr gut geeignet zur Lösung dieser Art von Problemen. Cache-Aufschlüsselung Cache-Aufschlüsselung bedeutet, dass bei einem Ausfall bestimmter Hot-Daten eine große Anzahl von Anfragen für diese Daten in die Datenquelle eindringen. Es gibt folgende Möglichkeiten, dieses Problem zu lösen. Sie können die Aktualisierung der Mutex-Sperre verwenden, um sicherzustellen, dass derselbe Prozess nicht gleichzeitig dieselben Daten an die Datenbank anfordert, wodurch der DB-Druck verringert wird. Verwenden Sie die zufällige Backoff-Methode. Wenn es fehlschlägt, wird es für einen kurzen Zeitraum nach dem Zufallsprinzip in den Ruhezustand versetzt, erneut abgefragt und Aktualisierungen durchgeführt, wenn es fehlschlägt. Um das Problem zu lösen, dass mehrere Hotspot-Schlüssel gleichzeitig ausfallen, können Sie beim Caching eine feste Zeit plus eine kleine Zufallszahl verwenden, um zu verhindern, dass eine große Anzahl von Hotspot-Schlüsseln gleichzeitig ausfällt. Cache-Lawine Cache-Lawine, der Grund ist, dass der Cache hängen bleibt und alle Anfragen in die Datenbank eindringen. Lösung: Verwenden Sie eine Schnellausfall-Leistungsschalterstrategie, um den momentanen Druck auf die Datenbank zu reduzieren. Verwenden Sie den Master-Slave-Modus und den Cluster-Modus, um die hohe Verfügbarkeit des Cache-Dienstes sicherzustellen. In tatsächlichen Szenarien werden diese beiden Methoden zusammen verwendet. Alte Freunde wissen alle, warum ich es nicht ausführlich vorgestellt habe Nur ein paar Punkte, mein vorheriger Artikel war wirklich zu detailliert, ich konnte nicht anders, als es zu mögen das werde ich hier nicht tun . Wiederholt kopiert. Testpunkte und Bonuspunkte Get it Take Notizen! Testpunkt Während des Interviews werde ich Sie zum Thema Caching befragen, hauptsächlich um Ihr Verständnis der Caching-Funktionen und die Beherrschung der Eigenschaften und Verwendung von MC und Redis zu testen. -Cache von DB-Hot-Daten, um den DB-Druck zu reduzieren, um die Parallelitätsleistung zu verbessern; Redis verwenden. Zum Speichern und Berechnen von Ranking-Daten können Sie zset verwenden Struktur von Redis, um es zu speichern. Um die gemeinsamen Befehle von MC und Redis zu verstehen, wie z. B. atomare Vergrößerung und Verringerung, Befehle zum Bearbeiten verschiedener Datenstrukturen usw. Verstehen Sie die Datenausfallmethoden und Culling-Strategien von MC und Um die Persistenz, Master-Slave-Synchronisation und zu verstehen Redis-Prinzipien, wie die Implementierungsmethoden und Unterschiede zwischen RDB Sie müssen die Gemeinsamkeiten, Unterschiede und Lösungen von Cache-Penetration, -Aufschlüsselung und -Lawine kennen. Ob Sie E-Commerce-Erfahrung haben oder nicht, ich denke, Sie sollten die konkrete Umsetzung von Flash-Sales und die Details kennen. besteht darin, die Verwendung von Cache basierend auf tatsächlichen Anwendungsszenarien einzuführen. Wenn Sie beispielsweise die Back-End-Serviceschnittstelle aufrufen, um Informationen zu erhalten, können Sie den lokalen + Remote-Mehrebenen-Cache verwenden. Für dynamische Ranking-Szenarien können Sie die Verwendung des „Sorted Set“ von Redis in Betracht ziehen, um dies zu erreichen usw. Es ist am besten, wenn Sie Erfahrung im Design und der Verwendung verteilter Caches haben, z. B. in welchen Szenarien Sie Redis im Projekt verwendet haben, welche Datenstrukturen verwendet werden und welche Arten von Problemen bei der Verwendung von MC gelöst werden. entsprechend dem geschätzten Wert anpassen McSlab Parameter zuweisen und mehr. Es ist am besten, die Probleme zu verstehen, die bei der Verwendung des Caches auftreten können. Redis ist beispielsweise eine Single-Threaded-Verarbeitungsanforderung, die so weit wie möglich vermieden werden sollte, um eine gegenseitige Beeinflussung zu verhindern. Redis-Dienst sollte nicht auf demselben Computer wie andere CPU-intensive Prozesse bereitgestellt werden ; oder Swap-Speicheraustausch sollte deaktiviert werden, um zu verhindern, dass zwischengespeicherte Daten von Redis auf die Festplatte ausgetauscht werden. Ein weiteres Beispiel ist das bereits erwähnte MC-Verkalkungsproblem. Um die typischen Anwendungsszenarien von Redis zu verstehen, verwenden Sie beispielsweise Redis, um verteilte Sperren zu implementieren; verwenden Sie Bitmap, um BloomFilter zu implementieren, verwenden Sie HyperLogLog, um UV-Statistiken durchzuführen usw. Kennen Sie die neuen Funktionen in Redis 4.0 und 5.0, wie z. B. den persistenten Nachrichtenwarteschlangen-Stream, der benutzerdefinierte Funktionserweiterungen über das Modulsystem unterstützt; …….. Weitere Programmierkenntnisse finden Sie unter: Programmiervideo! !

Verstehen Sie die Speicherstruktur von MC und Redis
Das obige ist der detaillierte Inhalt vonZusammenfassung häufiger Interviewfragen zu Redis (mit Antwortanalyse). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?











![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



