

Was sind die am häufigsten verwendeten Datenstrukturen in Java?

Zu den Java-Datenstrukturen gehören: 1. Array; 2. Verknüpfte Liste, eine rekursive Datenstruktur; 3. Stapel, der Daten nach den Prinzipien „Last In, First Out“ speichert; . Warteschlange; 5. Ein Baum ist eine Sammlung hierarchischer Beziehungen, die aus n (n>0) begrenzten Knoten besteht. 7. Diagramm;

Die Betriebsumgebung dieses Tutorials: Windows7-System, Java8-Version, DELL G3-Computer.
Gemeinsame Datenstrukturen in Java
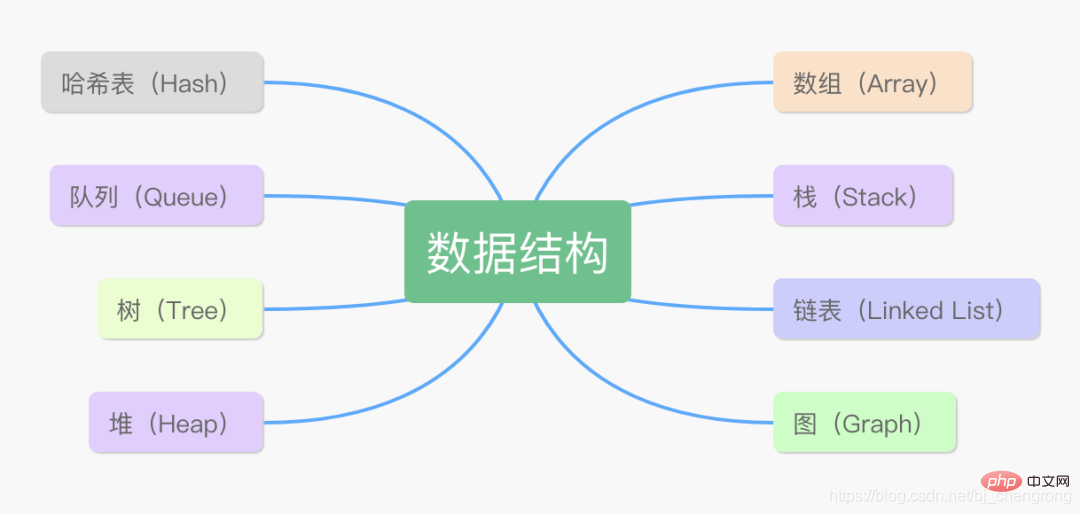
Was sind die Unterschiede zwischen diesen 8 Datenstrukturen?
①, Array
Vorteile:
Das Abfragen von Elementen nach Index ist schnell;
Es ist auch praktisch, das Array nach Index zu durchlaufen.
Nachteile:
Die Größe des Arrays wird nach der Erstellung festgelegt und kann nicht erweitert werden.
Arrays können nur einen Datentyp speichern.
Die Vorgänge zum Hinzufügen und Löschen von Elementen sind zeitaufwändig -aufwändig, da andere Elemente verschoben werden müssen.
②, verknüpfte Liste
-
Das Buch „Algorithmus (4. Auflage)“ definiert eine verknüpfte Liste wie folgt:
Die verknüpfte Liste ist eine rekursive Datenstruktur, sie ist entweder leer (null), Oder ein Verweis auf einen Knoten, der auch ein Element enthält, und ein Verweis auf eine andere verknüpfte Liste.
Die LinkedList-Klasse von Java kann die Struktur einer verknüpften Liste sehr anschaulich in Form von Code ausdrücken:
public class LinkedList<E> {
transient Node<E> first;
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}Dies ist eine doppelt verknüpfte Liste. Das aktuelle Elementelement hat sowohl prev als auch next, aber das prev von first ist null und next of last ist null. Wenn es sich um eine einseitig verknüpfte Liste handelt, gibt es nur next und kein prev.
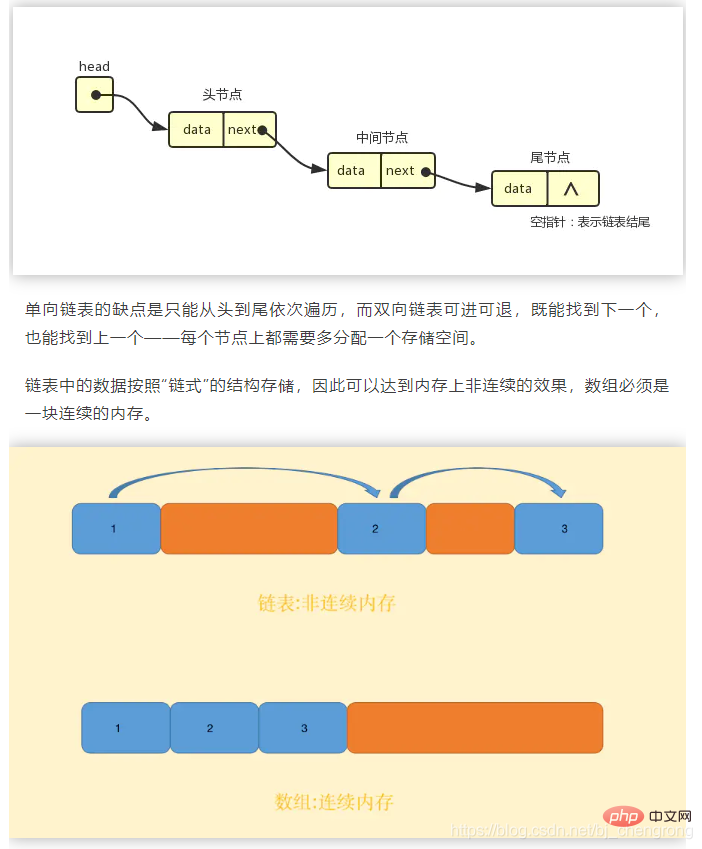
Da die verknüpfte Liste nicht sequentiell gespeichert werden muss, kann sie beim Einfügen und Löschen eine O(1)-Zeitkomplexität erreichen (Sie müssen nur die Referenz erneut verweisen, und das ist nicht der Fall müssen andere Elemente wie ein Array verschieben). Darüber hinaus überwindet die verknüpfte Liste auch den Nachteil des Arrays, dass die Datengröße im Voraus bekannt sein muss, und ermöglicht so eine flexible dynamische Speicherverwaltung.
Vorteile:
Keine Notwendigkeit, die Kapazität zu initialisieren;
Sie können jedes Element hinzufügen;
Aktualisieren Sie die Referenz nur beim Einfügen und Löschen.
Nachteile:
enthält eine große Anzahl von Referenzen und nimmt viel Speicherplatz ein;
Das Suchen von Elementen erfordert das Durchlaufen der gesamten verknüpften Liste, was zeitaufwändig ist.
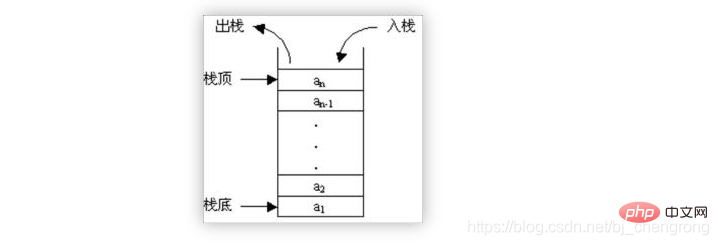
③, Stapel
Stapel ist wie ein Eimer, der Boden ist versiegelt und die Oberseite ist offen, Wasser kann ein- und austreten. Freunde, die Eimer benutzt haben, sollten dieses Prinzip verstehen: Das Wasser, das zuerst hineinfließt, befindet sich am Boden des Eimers, und das Wasser, das später hineinfließt, befindet sich oben im Eimer. Das Wasser, das zuletzt hineinfließt, wird zuerst ausgegossen. und das Wasser, das zuerst einströmt, wird zuletzt ausgegossen.
In ähnlicher Weise speichert der Stapel Daten nach den Prinzipien „Zuletzt rein, zuerst raus“ und „Zuerst rein, zuletzt raus“. Wenn die Daten ausgelesen werden, werden sie nacheinander gelesen.
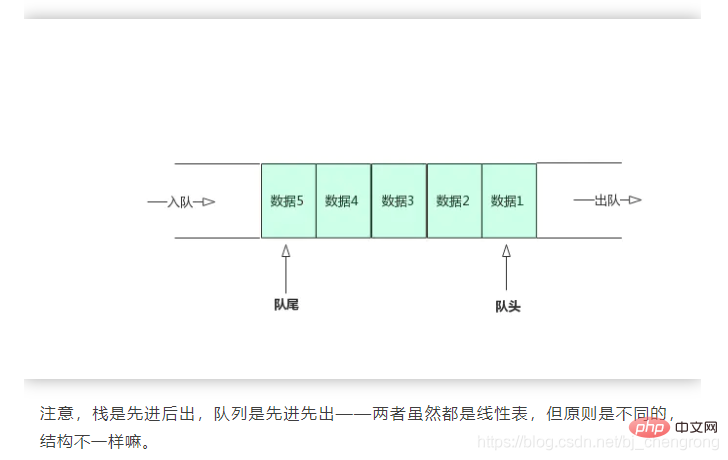
④, Warteschlange
Die Warteschlange ist wie ein Abschnitt einer Wasserleitung, bei der beide Enden offen sind, Wasser fließt an einem Ende ein und kommt dann am anderen Ende wieder heraus. Das Wasser, das zuerst einströmt, kommt zuerst heraus, und das Wasser, das zuletzt einströmt, kommt zuletzt heraus.
Etwas anders als die Wasserleitung definiert die Warteschlange zwei Enden, ein Ende wird als Anführer der Warteschlange und das andere Ende als Ende der Warteschlange bezeichnet. Der Kopf der Warteschlange erlaubt nur Löschvorgänge (Dequeue), und der Schwanz der Warteschlange erlaubt nur Einfügevorgänge (Enqueue).
⑤, Baum
Der Baum ist eine typische nichtlineare Struktur, bei der es sich um eine Reihe hierarchischer Beziehungen handelt, die aus n (n>0) begrenzten Knoten bestehen.
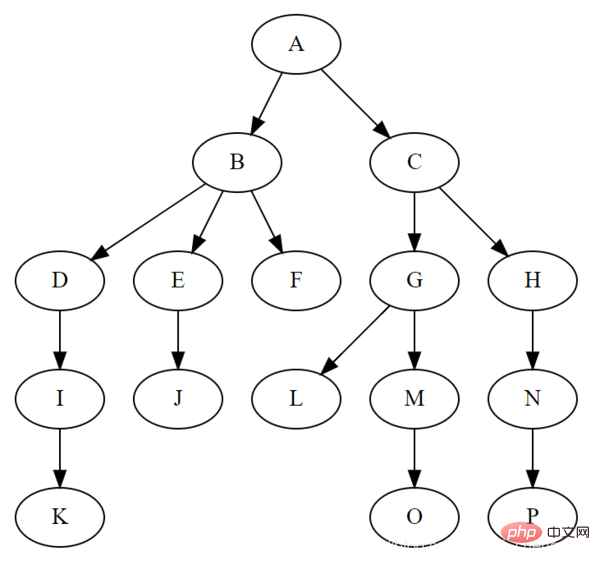
Der Grund, warum es „Baum“ genannt wird, liegt darin, dass diese Datenstruktur wie ein umgedrehter Baum aussieht, außer dass die Wurzeln oben und die Blätter unten sind. Die Baumdatenstruktur weist die folgenden Merkmale auf:
Jeder Knoten hat nur eine begrenzte Anzahl untergeordneter Knoten oder keine untergeordneten Knoten.
Ein Knoten ohne übergeordneten Knoten wird als Wurzelknoten bezeichnet hat Und es gibt nur einen übergeordneten Knoten;
Mit Ausnahme des Wurzelknotens kann jeder untergeordnete Knoten in mehrere disjunkte Teilbäume unterteilt werden.
-
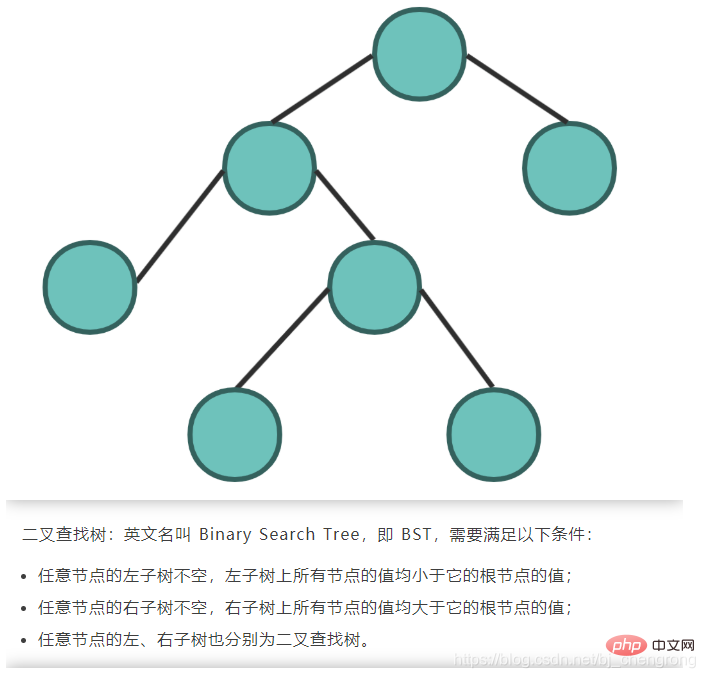
Das Bild unten zeigt einige Begriffe für Bäume:
Basierend auf den Eigenschaften des binären Suchbaums besteht sein Vorteil gegenüber anderen Datenstrukturen darin, dass die zeitliche Komplexität von Suche und Einfügung gering ist, was O (logn) ist. Wenn wir 5 Elemente aus dem obigen Bild finden möchten, beginnen wir mit dem Wurzelknoten 7. Wenn wir 5 finden, muss es links von 7 sein. Wenn wir 4 finden, muss 5 rechts von 4 sein. Wenn wir finden 6, dann muss 5 links von 6 sein. Seite, gefunden. Idealerweise kann durch die Suche nach Knoten über BST die Anzahl der zu überprüfenden Knoten halbiert werden.
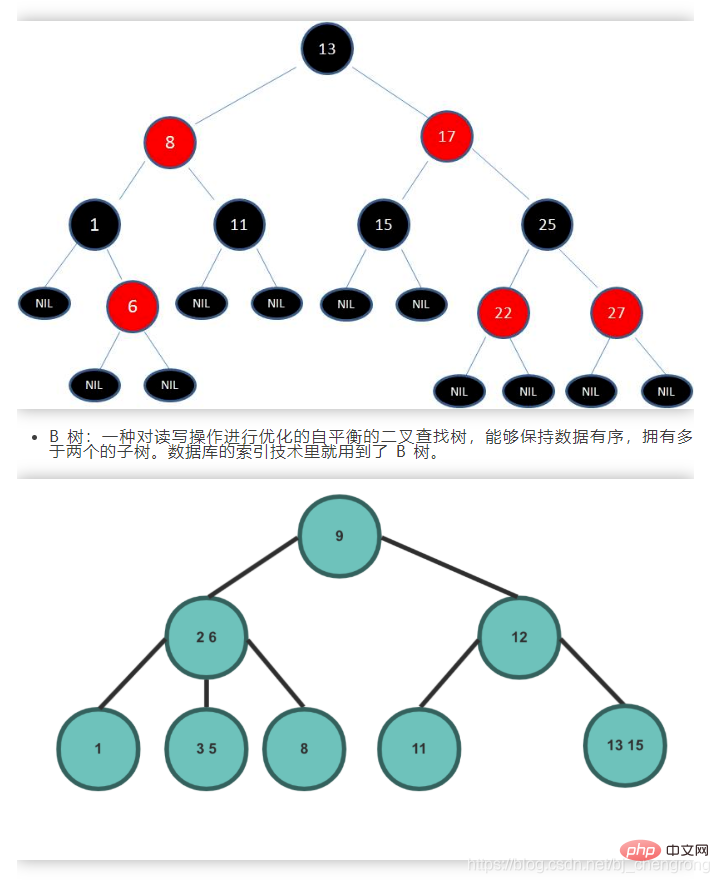
Idealerweise kann durch die Suche nach Knoten über BST die Anzahl der zu überprüfenden Knoten halbiert werden. Ausgewogener Binärbaum: Ein Binärbaum genau dann, wenn der Höhenunterschied zwischen den beiden Teilbäumen eines Knotens nicht größer als 1 ist. Der von den ehemaligen sowjetischen Mathematikern Adelse-Velskil und Landis 1962 vorgeschlagene hochbalancierte Binärbaum wird nach dem englischen Namen der Wissenschaftler auch AVL-Baum genannt.
Ein ausgeglichener Binärbaum ist im Wesentlichen ein binärer Suchbaum. Um jedoch den Höhenunterschied zwischen dem linken und dem rechten Teilbaum zu begrenzen und Situationen wie schiefe Bäume zu vermeiden, die dazu neigen, sich zu linearen Strukturen zu entwickeln, werden jeweils der linke und rechte Teilbaum verwendet Knoten im binären Suchbaum Der Höhenunterschied zwischen dem linken und dem rechten Teilbaum wird als Ausgleichsfaktor bezeichnet. Der Absolutwert des Ausgleichsfaktors jedes Knotens im Baum ist nicht größer als 1.Die Schwierigkeit beim Ausbalancieren eines Binärbaums besteht darin, das Links-Rechts-Gleichgewicht durch Links- oder Rechtsdrehung aufrechtzuerhalten, wenn Knoten gelöscht oder hinzugefügt werden. Der häufigste ausgeglichene Binärbaum in Java ist der Rot-Schwarz-Baum. Die Knoten sind rot oder schwarz. Das Gleichgewicht des Binärbaums wird durch Farbbeschränkungen aufrechterhalten:
1) Jeder Knoten kann nur rot oder schwarz sein 2) Wurzelknoten sind schwarz3) Jeder Blattknoten (NIL-Knoten, leerer Knoten) ist schwarz.
4) Wenn ein Knoten rot ist, sind beide untergeordneten Knoten schwarz. Das heißt, zwei benachbarte rote Knoten dürfen nicht auf einem Pfad erscheinen. 5) Alle Pfade von jedem Knoten zu jedem seiner Blätter enthalten die gleiche Anzahl schwarzer Knoten.⑥, Heap
Der Heap kann als Array-Objekt eines Baums mit den folgenden Eigenschaften betrachtet werden:
Der Wert eines Knotens im Heap ist immer nicht größer oder kleiner als es Der Wert des übergeordneten Knotens;
Der Heap ist immer ein vollständiger Binärbaum.
Der Heap mit dem größten Wurzelknoten wird als maximaler Heap oder großer Wurzelheap bezeichnet, und der Heap mit dem kleinsten Wurzelknoten wird als minimaler Heap oder kleiner Wurzelheap bezeichnet.In einer linearen Struktur wird eine eindeutige lineare Beziehung zwischen Datenelementen erfüllt, und jedes Datenelement (außer dem ersten und letzten) hat einen eindeutigen „Vorgänger“ und „Nachfolger“
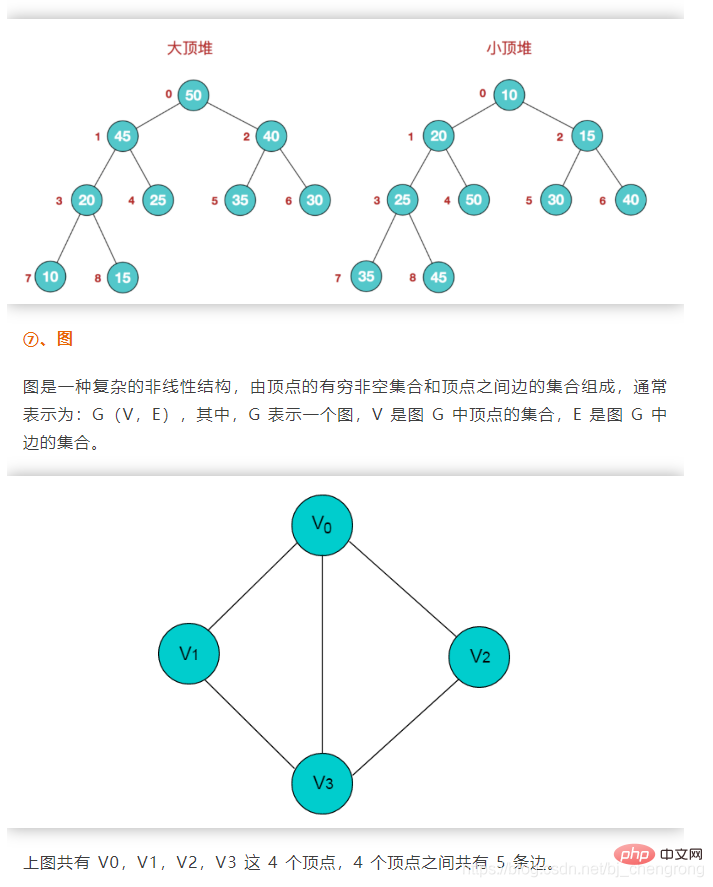
- In der Baumstruktur Es besteht eine offensichtliche hierarchische Beziehung zwischen Datenelementen, und jedes Datenelement bezieht sich nur auf ein Element (übergeordneter Knoten) in der oberen Ebene und mehrere Elemente (untergeordnete Knoten) in der unteren Ebene.
In der Diagrammstruktur ist die Beziehung zwischen Knoten ist willkürlich und zwei beliebige Datenelemente im Diagramm können in Beziehung stehen.
⑧, Hash-Tabelle
Hash-Tabelle, auch Hash-Tabelle genannt, ist eine Datenstruktur, auf die direkt über Schlüsselwerte zugegriffen werden kann. Die größte Funktion besteht darin, dass Suchen, Einfügen und Löschen schnell realisiert werden können.
Das größte Merkmal von Arrays ist, dass sie leicht zu durchsuchen, aber schwer einzufügen und zu löschen sind. Im Gegensatz dazu ist die verknüpfte Liste schwer zu durchsuchen, aber leicht einzufügen und zu löschen. Hash-Tabellen kombinieren perfekt die Vorteile beider. Javas HashMap fügt auf dieser Basis auch die Vorteile von Bäumen hinzu.
Die Hash-Funktion spielt eine sehr wichtige Rolle in der Hash-Tabelle. Sie kann eine Eingabe beliebiger Länge in eine Ausgabe fester Länge umwandeln, und die Ausgabe ist der Hash-Wert. Die Hash-Funktion macht den Zugriffsprozess auf eine Datensequenz schneller und effizienter. Durch die Hash-Funktion können die Datenelemente schnell gefunden werden.
Wenn das Schlüsselwort k ist, wird sein Wert am Speicherort von
gespeichert. Daher kann der Wert, der k entspricht, direkt ohne Durchqueren erhalten werden.Für zwei beliebige Datenblöcke ist die Wahrscheinlichkeit, dass ihre Hash-Werte gleich sind, äußerst gering. Das heißt, es ist äußerst schwierig, für einen bestimmten Datenblock einen Datenblock mit demselben Hash-Wert zu finden. Darüber hinaus ist bei einem Datenblock die Änderung des Hash-Werts sehr groß, selbst wenn nur ein Bit davon geändert wird – das ist der Wert von Hash!
Obwohl die Wahrscheinlichkeit äußerst gering ist, wird es dennoch vorkommen, dass Javas HashMap eine verknüpfte Liste an derselben Position im Array hinzufügt. Wenn die Länge der verknüpften Liste größer als 8 ist, wird dies der Fall sein Zur Verarbeitung in einen rot-schwarzen Baum umgewandelt – Dies ist die sogenannte Zipper-Methode (Array + verknüpfte Liste).
Weitere Kenntnisse zum Thema Programmierung finden Sie unter: Programmiervideos! !
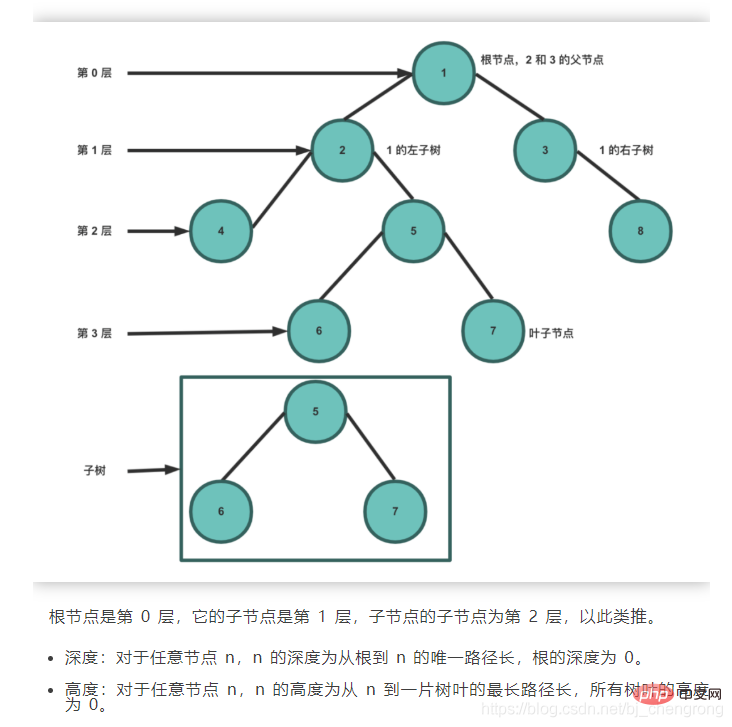 Idealerweise kann durch die Suche nach Knoten über BST die Anzahl der zu überprüfenden Knoten halbiert werden.
Idealerweise kann durch die Suche nach Knoten über BST die Anzahl der zu überprüfenden Knoten halbiert werden. 
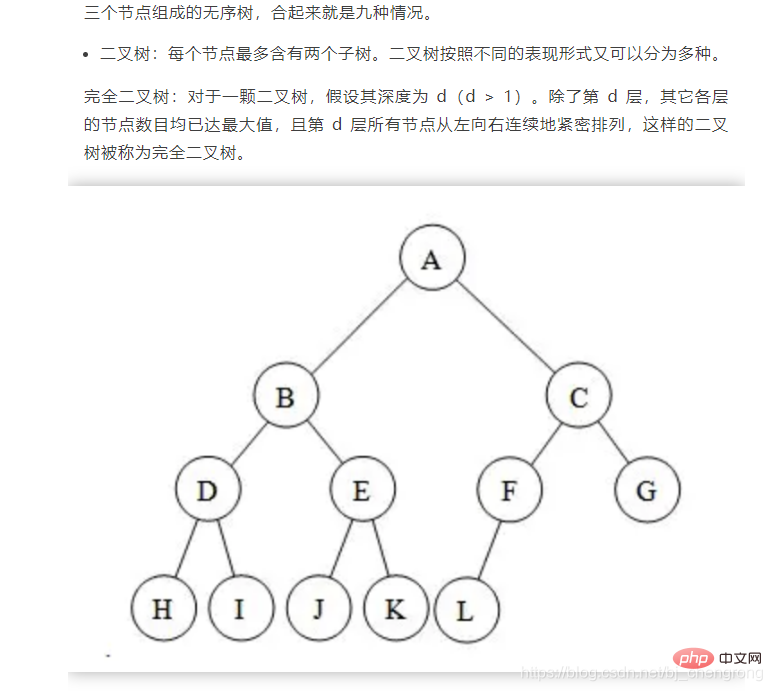 Die Schwierigkeit beim Ausbalancieren eines Binärbaums besteht darin, das Links-Rechts-Gleichgewicht durch Links- oder Rechtsdrehung aufrechtzuerhalten, wenn Knoten gelöscht oder hinzugefügt werden.
Die Schwierigkeit beim Ausbalancieren eines Binärbaums besteht darin, das Links-Rechts-Gleichgewicht durch Links- oder Rechtsdrehung aufrechtzuerhalten, wenn Knoten gelöscht oder hinzugefügt werden. 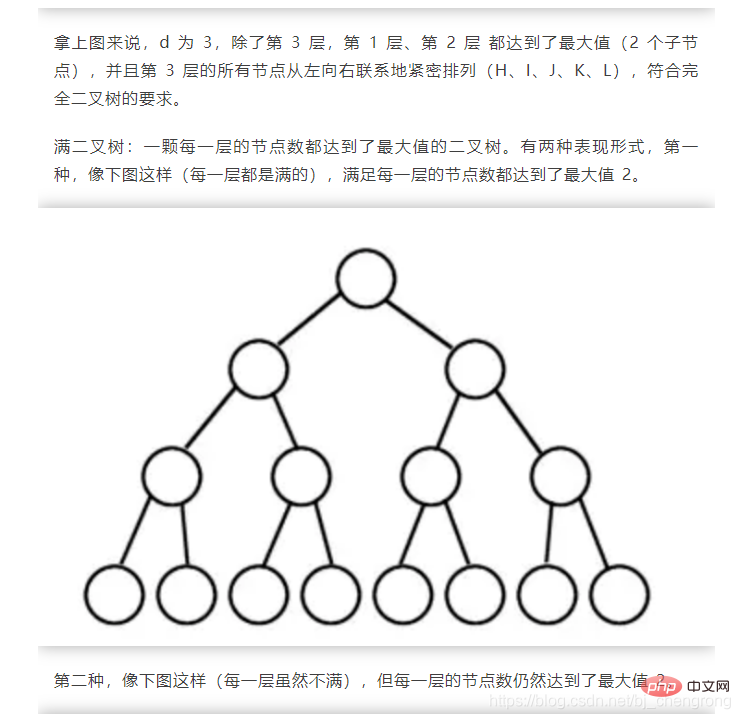
 2) Wurzelknoten sind schwarz
2) Wurzelknoten sind schwarz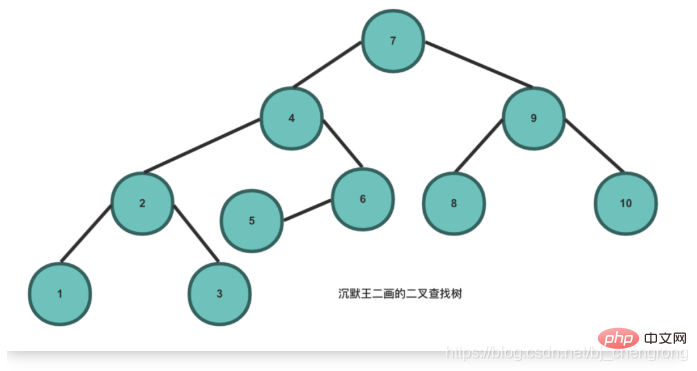
Das obige ist der detaillierte Inhalt vonWas sind die am häufigsten verwendeten Datenstrukturen in Java?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur Smith-Zahl in Java. Hier besprechen wir die Definition: Wie überprüft man die Smith-Nummer in Java? Beispiel mit Code-Implementierung.
 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Anleitung zum TimeStamp to Date in Java. Hier diskutieren wir auch die Einführung und wie man Zeitstempel in Java in ein Datum konvertiert, zusammen mit Beispielen.
 Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Kapseln sind dreidimensionale geometrische Figuren, die aus einem Zylinder und einer Hemisphäre an beiden Enden bestehen. Das Volumen der Kapsel kann berechnet werden, indem das Volumen des Zylinders und das Volumen der Hemisphäre an beiden Enden hinzugefügt werden. In diesem Tutorial wird erörtert, wie das Volumen einer bestimmten Kapsel in Java mit verschiedenen Methoden berechnet wird. Kapselvolumenformel Die Formel für das Kapselvolumen lautet wie folgt: Kapselvolumen = zylindrisches Volumenvolumen Zwei Hemisphäre Volumen In, R: Der Radius der Hemisphäre. H: Die Höhe des Zylinders (ohne die Hemisphäre). Beispiel 1 eingeben Radius = 5 Einheiten Höhe = 10 Einheiten Ausgabe Volumen = 1570,8 Kubikeinheiten erklären Berechnen Sie das Volumen mithilfe der Formel: Volumen = π × R2 × H (4
 Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Java ist eine beliebte Programmiersprache, die sowohl von Anfängern als auch von erfahrenen Entwicklern erlernt werden kann. Dieses Tutorial beginnt mit grundlegenden Konzepten und geht dann weiter zu fortgeschrittenen Themen. Nach der Installation des Java Development Kit können Sie das Programmieren üben, indem Sie ein einfaches „Hello, World!“-Programm erstellen. Nachdem Sie den Code verstanden haben, verwenden Sie die Eingabeaufforderung, um das Programm zu kompilieren und auszuführen. Auf der Konsole wird „Hello, World!“ ausgegeben. Mit dem Erlernen von Java beginnt Ihre Programmierreise, und wenn Sie Ihre Kenntnisse vertiefen, können Sie komplexere Anwendungen erstellen.
 Wie führe ich Ihre erste Spring -Boot -Anwendung in der Spring Tool Suite aus?
Feb 07, 2025 pm 12:11 PM
Wie führe ich Ihre erste Spring -Boot -Anwendung in der Spring Tool Suite aus?
Feb 07, 2025 pm 12:11 PM
Spring Boot vereinfacht die Schaffung robuster, skalierbarer und produktionsbereiteter Java-Anwendungen, wodurch die Java-Entwicklung revolutioniert wird. Der Ansatz "Übereinkommen über Konfiguration", der dem Feder -Ökosystem inhärent ist, minimiert das manuelle Setup, Allo
 PHP vs. Python: Verständnis der Unterschiede
Apr 11, 2025 am 12:15 AM
PHP vs. Python: Verständnis der Unterschiede
Apr 11, 2025 am 12:15 AM
PHP und Python haben jeweils ihre eigenen Vorteile, und die Wahl sollte auf Projektanforderungen beruhen. 1.PHP eignet sich für die Webentwicklung mit einfacher Syntax und hoher Ausführungseffizienz. 2. Python eignet sich für Datenwissenschaft und maschinelles Lernen mit präziser Syntax und reichhaltigen Bibliotheken.
