

Detaillierte Erläuterung der MySQL-Abfrageoptimierung


1. Was sind die Ideen und Prinzipien der Optimierung
1. Optimieren Sie die Abfragen, die optimiert werden müssen
2. Lokalisieren Sie den Leistungsengpass des Optimierungsobjekts
3. Klären Sie das Ziel der Optimierung
4. Beginnen Sie mit Erklären Sie
5. Verwenden Sie Profile häufiger
6. Verwenden Sie immer kleine Ergebnismengen, um große Ergebnismengen zu erzielen
7. Vervollständigen Sie die Sortierung im Index so weit wie möglich
8. Entfernen Sie nur die Felder (Spalten), die Sie benötigen
9. Verwenden Sie nur die effektivsten Filterbedingungen
10. Vermeiden Sie komplexe Verknüpfungen so weit wie möglich
Verwandte kostenlose Lernempfehlungen: MySQL-Video-Tutorial
1. Optimieren Sie Abfragen, die optimiert werden müssen
Hohe Parallelität und geringer Verbrauch ( relativ) Abfragen wirken sich viel größer auf das gesamte System aus als Abfragen mit geringer Parallelität und hohem Verbrauch.
2. Lokalisieren Sie den Leistungsengpass des Optimierungsobjekts
Wenn wir eine Abfrage erhalten, die optimiert werden muss, müssen wir zunächst feststellen, ob der Engpass der Abfrage E/A oder CPU ist. Ist es der Datenbankzugriff, der mehr verbraucht, oder sind es Datenoperationen (z. B. Gruppieren und Sortieren), die mehr verbrauchen?
3. Klare Optimierungsziele
Verstehen Sie den aktuellen Gesamtstatus der Datenbank. Sie können den maximalen Druck kennen, dem die Datenbank standhalten kann. Das heißt, wir kennen die pessimistischste Situation.
Um die zugehörigen Datenbankobjektinformationen zu erfassen Zur Abfrage können wir wissen, wie viele Ressourcen unter den besten und schlechtesten Bedingungen verbraucht werden.
Um den Status der Abfrage im Anwendungssystem zu ermitteln, können wir den Anteil der Systemressourcen analysieren, die die Abfrage belegen kann Wissen Sie auch, wie effizient die Abfrage auf das Kundenerlebnis ist, wie groß die Auswirkung ist.
4. Beginnen Sie mit Explain
Explain kann Ihnen sagen, welche Art von Ausführungsplan diese Abfrage in der Datenbank implementiert ist. Zunächst müssen wir ein Ziel haben, indem wir ständig anpassen und versuchen und dann mithilfe von Explain überprüfen, ob die Ergebnisse unseren Anforderungen entsprechen, um die erwarteten Ergebnisse zu erzielen.
5. Verwenden Sie immer kleine Ergebnismengen, um große Ergebnismengen zu erzielen. Viele Leute sagen bei der Optimierung von SQL gerne: „Kleine Tabellen führen zu großen Tabellen.“ Da die von der großen Tabelle nach dem Filtern durch die Where-Bedingung zurückgegebene Ergebnismenge nicht unbedingt größer ist als die von der kleinen Tabelle zurückgegebene Ergebnismenge, wird der gegenteilige Leistungseffekt erzielt, wenn zu diesem Zeitpunkt die große Tabelle zum Ansteuern der kleinen Tabelle verwendet wird erhalten werden. Dieses Ergebnis ist auch sehr leicht zu verstehen. In MySQL gibt es nur eine Join-Methode, nämlich Nested Loop. Das heißt, MySQLs Join wird durch verschachtelte Schleifen implementiert. Je größer die gesteuerte Ergebnismenge ist, desto mehr Schleifen sind erforderlich, und die Anzahl der Zugriffe auf die gesteuerte Tabelle wird natürlich höher sein. Bei jedem Zugriff auf die gesteuerte Tabelle ist die Anzahl der Schleifen höher, auch wenn die erforderliche logische E/A sehr gering ist Natürlich kann die Gesamtmenge nicht sehr gering sein, und jeder Zyklus verbraucht zwangsläufig die CPU, sodass auch die Menge an CPU-Berechnungen zunimmt. Wenn wir also nur die Größe der Tabelle als Grundlage für die Beurteilung der Treibertabelle verwenden und die Ergebnismenge, die nach dem Filtern der kleinen Tabelle übrig bleibt, viel größer ist als die der großen Tabelle, führt dies zu mehr Schleifen in der erforderlichen Verschachtelung Im Gegenteil, die Anzahl der erforderlichen Zyklen wird geringer sein und auch die Gesamtmenge an E/A- und CPU-Operationen wird geringer sein. Darüber hinaus ist es auch für nicht-Nested-Loop-Join-Algorithmen wie Hash Join in Oracle immer noch die optimale Wahl, wenn eine kleine Ergebnismenge eine große Ergebnismenge steuern soll.
Daher lautet das grundlegendste Prinzip bei der Optimierung von Join-Abfragen: „Kleine Ergebnismengen führen zu großen Ergebnismengen.“ Durch dieses Prinzip kann die Anzahl der Schleifen in verschachtelten Schleifen reduziert werden, wodurch die Gesamtmenge an E/A und die Anzahl der CPUs reduziert werden Operationen. Vervollständigen Sie die Sortierung im Index so weit wie möglich 6. Nehmen Sie nur die Felder (Spalten) heraus, die Sie benötigen
7. Verwenden Sie nur die effektivsten Filterbedingungen.
Ein Benutzer in der Tabelle hat beispielsweise Felder wie „id“ und „nike_name“. Die folgenden Indizes sind zwei Abfrageanweisungen: „Zwei Abfragen“. ist derselbe, aber der von der ersten Anweisung verwendete Index nimmt viel mehr Platz ein als der der zweiten Anweisung. Der höhere Platzbedarf bedeutet auch, dass mehr Daten gelesen werden müssen. Das heißt, die Abfrageanweisung von 2 ist die optimale Abfrage.8. Vermeiden Sie komplexe Join-Abfragen
Je mehr Tabellen unsere Abfrage umfasst, desto mehr Ressourcen müssen wir sperren. Mit anderen Worten: Je komplexer die Join-Anweisung ist, desto mehr Ressourcen muss sie sperren und desto mehr andere Threads werden blockiert. Im Gegenteil: Wenn wir eine komplexere Abfrageanweisung in mehrere einfachere Abfrageanweisungen aufteilen und diese Schritt für Schritt ausführen, werden jedes Mal weniger Ressourcen gesperrt und weniger andere Threads blockiert.
Viele Leute haben möglicherweise Fragen: Werden wir nach der Aufteilung der komplexen Join-Anweisung in mehrere einfache Abfrageanweisungen nicht mehr Netzwerkinteraktionen haben? Der Gesamtverbrauch in Bezug auf die Netzwerkverzögerung wird größer sein. Würde es nicht länger dauern, die gesamte Abfrage abzuschließen? Ja, das ist möglich, aber sicher ist es nicht. Wir können es noch einmal analysieren. Wenn eine komplexe Abfrageanweisung ausgeführt wird, müssen mehr Ressourcen gesperrt werden, und die Wahrscheinlichkeit, von anderen blockiert zu werden, ist größer. Wenn es sich um eine einfache Abfrage handelt, müssen weniger Ressourcen gesperrt werden. Auch die Wahrscheinlichkeit, blockiert zu werden, wird deutlich geringer sein. Daher können komplexere Verbindungsabfragen vor der Ausführung blockiert werden und mehr Zeit verschwenden. Darüber hinaus bedient unsere Datenbank nicht nur diese Anfrage, sondern auch viele, viele andere Anfragen. In einem System mit hoher Parallelität lohnt es sich sehr, die kurze Antwortzeit einer einzelnen Anfrage zu opfern, um die Gesamtverarbeitungsfähigkeit zu verbessern. Die Optimierung selbst ist eine Kunst des Gleichgewichts und der Kompromisse. Nur wenn man die Kompromisse kennt und das Ganze ausbalanciert, kann das System besser werden.
2. Verwenden Sie „Explain“ und „Profiling“. Die im Plan abgefragte Seriennummer
Select_type
Abfragetyp:ABHÄNGIGE UNTERABFRAGE: Das erste SELECT in der inneren Ebene der Unterabfrage, das von der externen Abfrageergebnismenge abhängt;
ABHÄNGIGE UNION: Alle nachfolgenden SELECTs in der UNION in der Unterabfrage, beginnend mit der zweiten SELECT SELECT, hängt auch von der externen Abfrageergebnismenge ab;| UNION: Alle SELECTs ab dem zweiten SELECT in der UNION-Anweisung, das erste SELECT ist PRIMARY | UNION RESULT: Die zusammengeführten Ergebnisse in UNION|
|---|---|
| TYPE | |
| const: Konstante, es stimmt höchstens ein Datensatz überein. Da es sich um eine Konstante handelt, muss sie eigentlich nur gelesen werden einmal | eq_ref: Es gibt höchstens eine Übereinstimmung. Auf das Ergebnis wird im Allgemeinen über den Primärschlüssel oder den eindeutigen Index zugegriffen. Index: vollständiger Indexscan. Bereich: Indexbereichsscan. Ref: Referenzabfrage des gesteuerten Tabellenindex in der Jion-Anweisung System: Systemtabelle, es gibt nur eine Datenzeile in der TabelleZeilen Die geschätzte Anzahl der Ergebnissatzdatensätze Extra | Zusätzliche Informationen
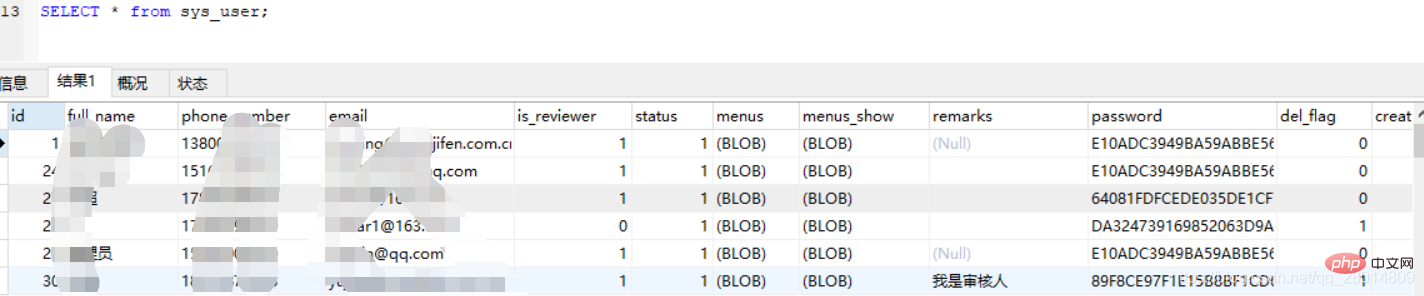
 4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)
4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)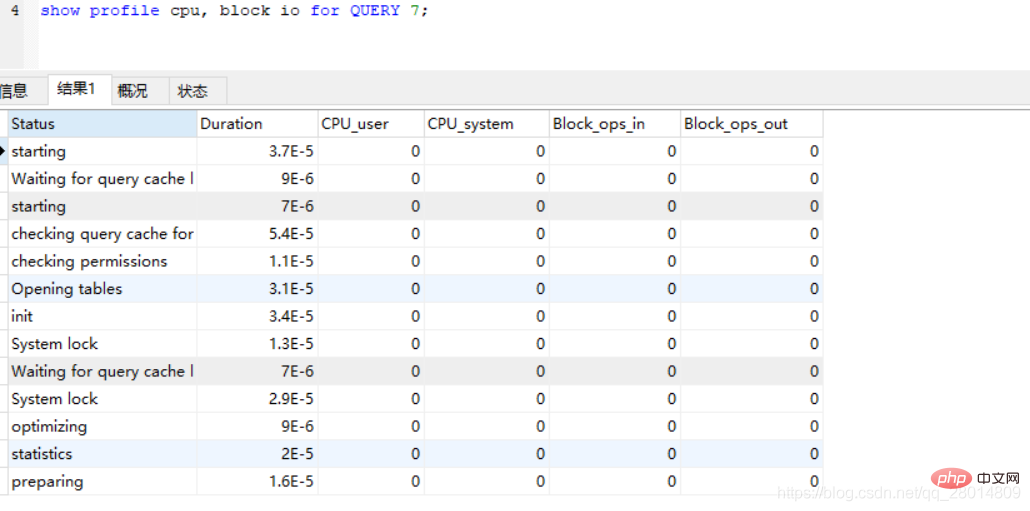
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der MySQL-Abfrageoptimierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 So lösen Sie das Problem fehlender Abhängigkeiten bei der Installation von MySQL
Apr 08, 2025 pm 12:00 PM
So lösen Sie das Problem fehlender Abhängigkeiten bei der Installation von MySQL
Apr 08, 2025 pm 12:00 PM
Der MySQL -Installationsfehler wird normalerweise durch das Fehlen von Abhängigkeiten verursacht. Lösung: 1. Verwenden Sie den Systempaketmanager (z. B. Linux APT, YUM oder DNF, Windows VisualC Neuverteilung), um die fehlenden Abhängigkeitsbibliotheken wie sudoaptinstalllibmysqlclient-dev zu installieren; 2. Überprüfen Sie die Fehlerinformationen sorgfältig und lösen Sie die komplexen Abhängigkeiten nacheinander. 3. Stellen Sie sicher, dass die Paket -Manager -Quelle korrekt konfiguriert ist und auf das Netzwerk zugreifen kann. 4. Laden Sie die erforderlichen Laufzeitbibliotheken herunter und installieren Sie sie für Windows. Die Entwicklung der Gewohnheit, offizielle Dokumente zu lesen und Suchmaschinen gut zu nutzen, kann effektiv Probleme lösen.
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Reduzieren Sie die Speicherung von MySQL RDS -Datenbanken mit Nullausfallzeit mit AWS Blue/Green -Bereitstellung
Apr 08, 2025 pm 12:42 PM
Reduzieren Sie die Speicherung von MySQL RDS -Datenbanken mit Nullausfallzeit mit AWS Blue/Green -Bereitstellung
Apr 08, 2025 pm 12:42 PM
DevOps -Ingenieure stehen häufig vor den Herausforderungen der RDS -Datenbankoptimierung und -aktualisierung, insbesondere in Situationen mit hoher Last, in denen herkömmliche Methoden anfällig für Ausfallzeiten sind. In diesem Artikel wird die AWS Blue/Green Deployment -Strategie eingeführt, um keine Ausfallzeit -Update der RDS -Datenbank zu erreichen. Verabschieden Sie sich vom Albtraum der Datenbank -Update -Ausfallzeit! In diesem Artikel wird die Blue/Green -Bereitstellungsstrategie im Detail erläutert und in der AWS -Umgebung betriebliche Schritte bereitgestellt, um die RDS -Datenbankinstanz zu aktualisieren, ohne die Verfügbarkeit von Dienstleistungen zu beeinträchtigen. Vorbereitung Erstens koordinieren Sie das Entwicklungsteam und wählen Sie den Zeitraum mit dem niedrigsten Workload -Verkehr für Aktualisierungen aus. Gute DevOps üben Ratschläge, um das Team im Voraus zu benachrichtigen. In diesem Beispiel wird gezeigt, wie die Datenbankinstanz Speicherplatz mit null Ausfallzeiten mit Blue/Green -Bereitstellung reduziert wird. Sie können die AWSRDS -Konsole verwenden
 Optimiert MySQL Schließtabellen?
Apr 08, 2025 pm 01:51 PM
Optimiert MySQL Schließtabellen?
Apr 08, 2025 pm 01:51 PM
MySQL verwendet freigegebene Sperren und exklusive Sperren, um die Parallelität zu verwalten, und bietet drei Sperrtypen: Tabellenverriegelungen, Zeilensperrungen und Seitenverriegelungen. Zeilensperren können die Parallelität verbessern und die Anweisung für Update verwenden, um Zeilen exklusive Sperren hinzuzufügen. Pessimistische Schlösser nehmen Konflikte an, und optimistische Sperren beurteilen die Daten über die Versionsnummer. Häufige Probleme mit der Sperrtabelle, die sich als langsame Abfrage manifestieren, verwenden Sie den Befehl show processlist, um die vom Sperre gehaltenen Abfragen anzuzeigen. Zu den Optimierungsmaßnahmen gehören die Auswahl geeigneter Indizes, die Reduzierung des Transaktionsumfangs, die Batch -Operationen und die Optimierung von SQL -Anweisungen.
 So verwenden Sie Substring_index in MySQL
Apr 08, 2025 pm 02:09 PM
So verwenden Sie Substring_index in MySQL
Apr 08, 2025 pm 02:09 PM
In MySQL -Datenbankoperationen ist die String -Verarbeitung ein unvermeidlicher Link. Die Funktion substring_index ist dafür ausgelegt, die Substrings basierend auf Separatoren effizient extrahieren kann. Beispiel für substring_index -Funktionsanwendung Das folgende Beispiel zeigt die Flexibilität und Praktikabilität der Funktion substring_index: Extrahieren Sie bestimmte Teile aus der URL, extrahieren Sie den Domänennamen: selectSubstring_index ('www.mysql.com', '.', 2); Dateierweiterung extrahieren, um die Dateierweiterung einfach abzurufen: selectSubstring_index ('file.pdf', '.',-1); Verarbeitung existiert nicht
 Benötigt MySQL einen Server?
Apr 08, 2025 pm 02:12 PM
Benötigt MySQL einen Server?
Apr 08, 2025 pm 02:12 PM
Für Produktionsumgebungen ist in der Regel ein Server erforderlich, um MySQL auszuführen, aus Gründen, einschließlich Leistung, Zuverlässigkeit, Sicherheit und Skalierbarkeit. Server haben normalerweise leistungsstärkere Hardware, redundante Konfigurationen und strengere Sicherheitsmaßnahmen. Bei kleinen Anwendungen mit niedriger Last kann MySQL auf lokalen Maschinen ausgeführt werden, aber Ressourcenverbrauch, Sicherheitsrisiken und Wartungskosten müssen sorgfältig berücksichtigt werden. Für eine größere Zuverlässigkeit und Sicherheit sollte MySQL auf Cloud oder anderen Servern bereitgestellt werden. Die Auswahl der entsprechenden Serverkonfiguration erfordert eine Bewertung basierend auf Anwendungslast und Datenvolumen.
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
