
 Backend-Entwicklung
Golang
Lassen Sie uns über die gleichzeitige Programmierung in Go (2) sprechen.
Backend-Entwicklung
Golang
Lassen Sie uns über die gleichzeitige Programmierung in Go (2) sprechen.
Lassen Sie uns über die gleichzeitige Programmierung in Go (2) sprechen.

Lassen Sie uns über Gos Goroutine und Channel sprechen
Der Anwendungsfall Im ersten Artikel befindet sich noch der in Abschnitt 2 geschriebene Code, hier ist jedoch nur ein Absatz erforderlich. package mainimport (
"fmt"
"time")func createWorker(id int) chan
package mainimport (
"fmt")type worker struct {
in chan int
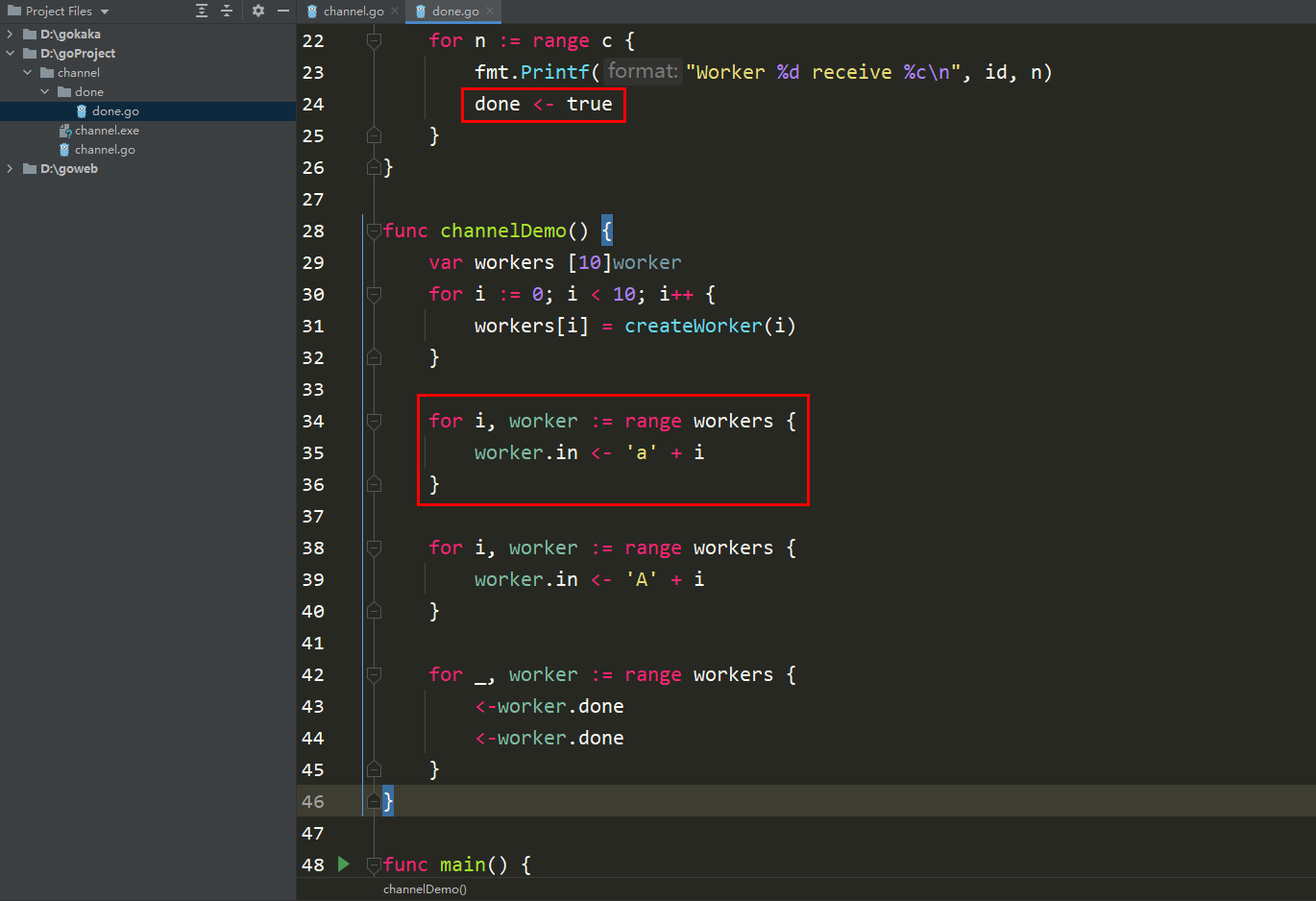
done chan bool}func createWorker(id int) worker {
w := worker{
in: make(chan int),
done: make(chan bool),
}
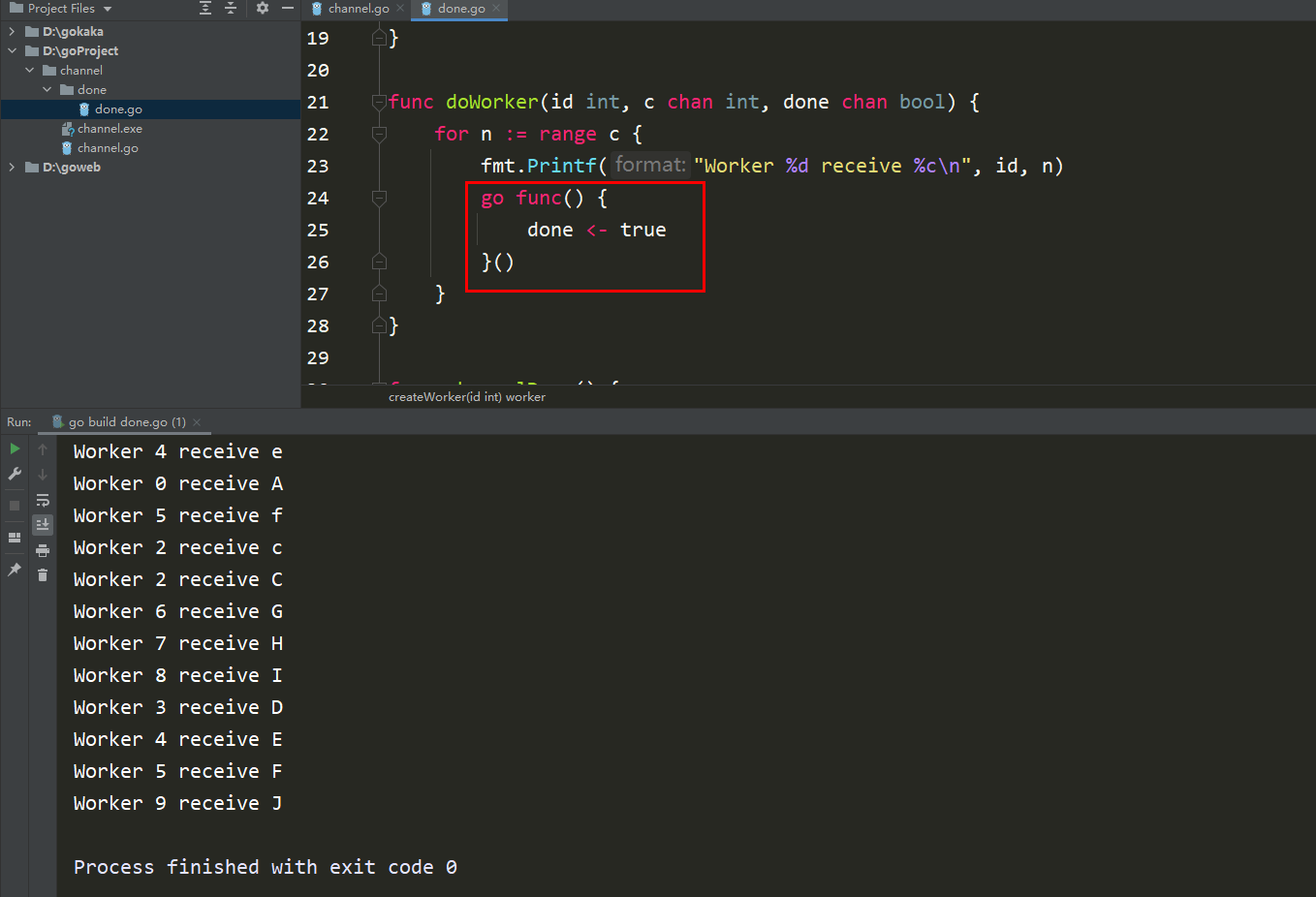
go doWorker(id, w.in, w.done)
return w}func doWorker(id int, c chan int, done chan bool) {
for n := range c {
fmt.Printf("Worker %d receive %c\n", id, n)
done 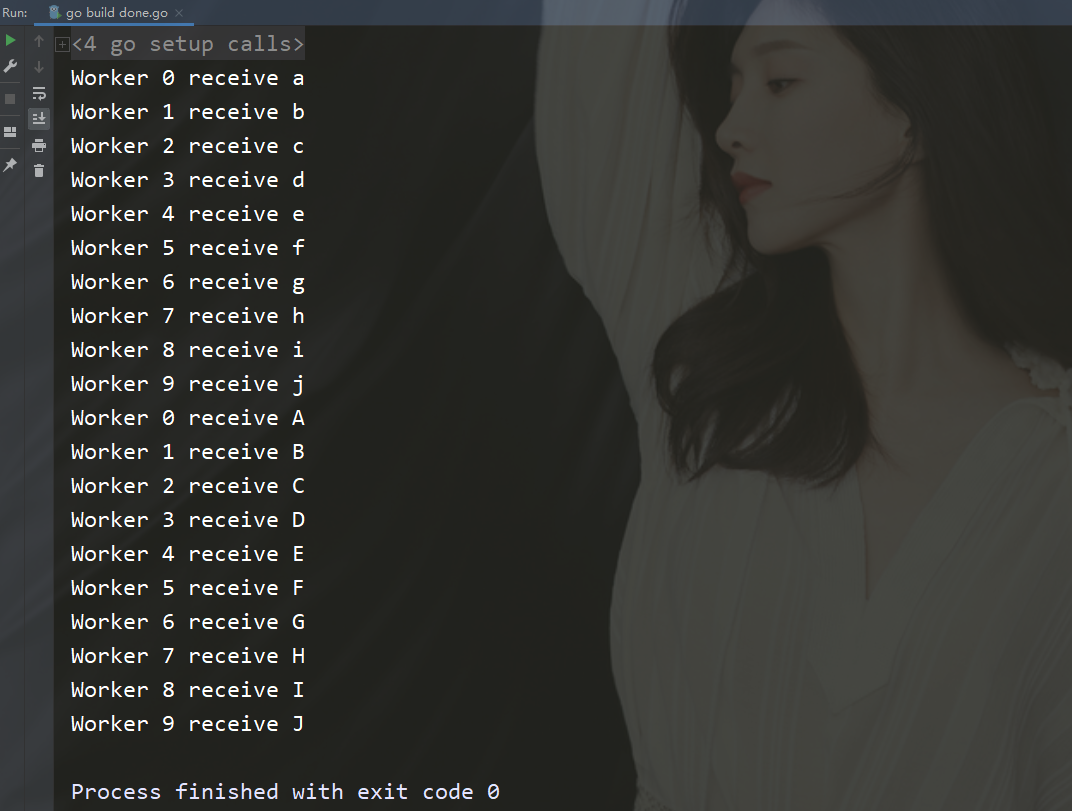
package mainimport (
"fmt")type worker struct {
in chan int
done chan bool}func createWorker(id int) worker {
w := worker{
in: make(chan int),
done: make(chan bool),
}
go doWorker(id, w.in, w.done)
return w}func doWorker(id int, c chan int, done chan bool) {
for n := range c {
fmt.Printf("Worker %d receive %c\n", id, n)
done 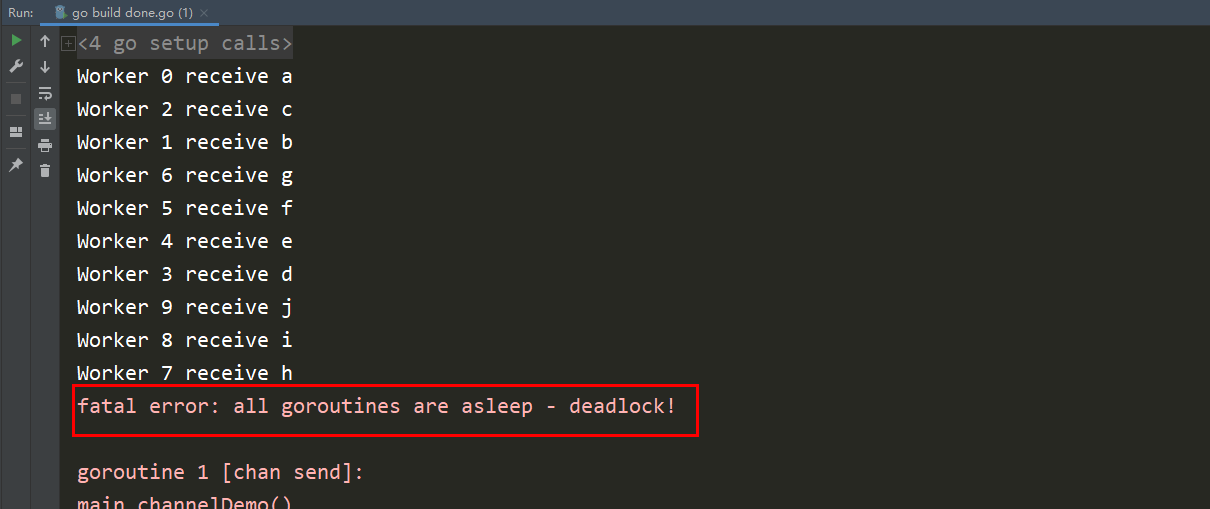
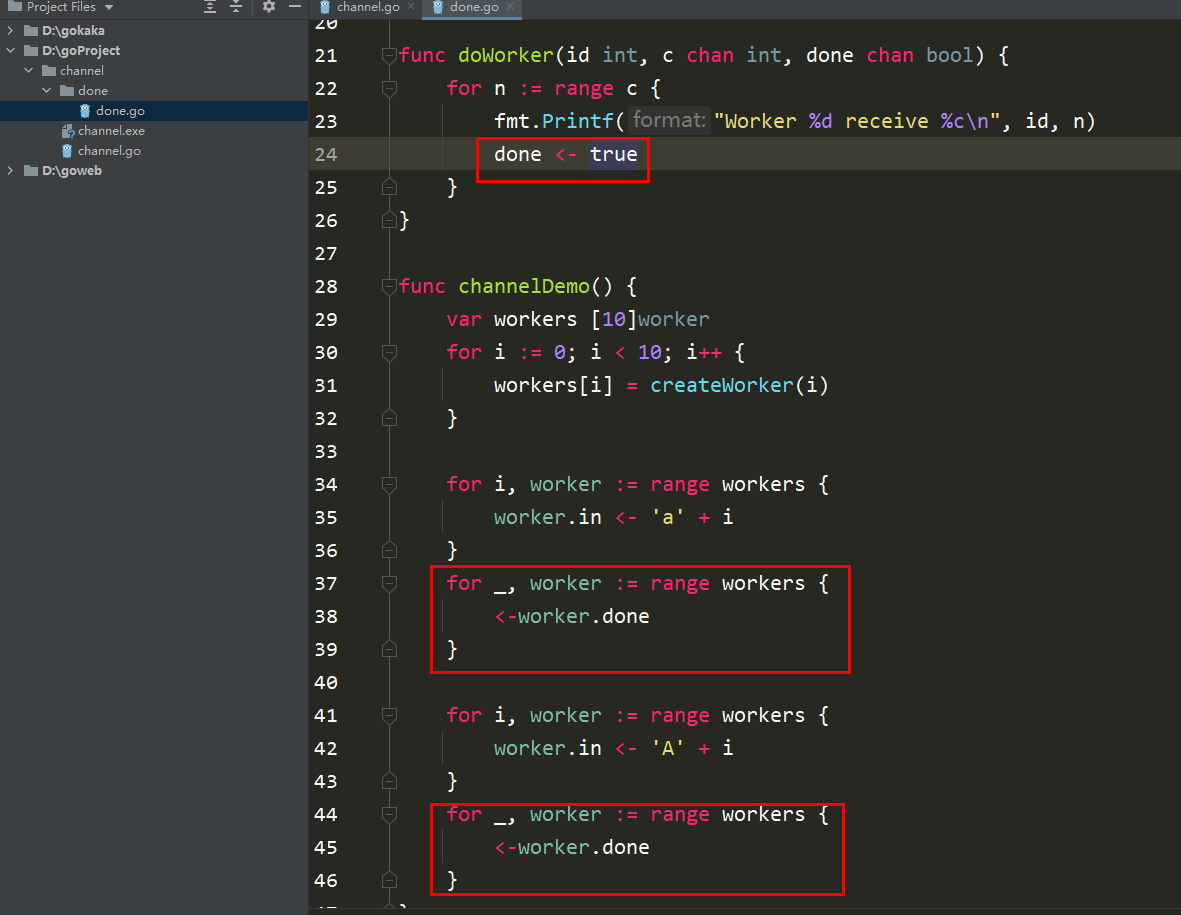
package mainimport (
"fmt"
"sync")type worker struct {
in chan int
wg *sync.WaitGroup}func createWorker(id int, wg *sync.WaitGroup) worker {
w := worker{
in: make(chan int),
wg: wg,
}
go doWorker(id, w.in, wg)
return w}func doWorker(id int, c chan int, wg *sync.WaitGroup) {
for n := range c {
fmt.Printf("Worker %d receive %c\n", id, n)
wg.Done()
}}func channelDemo() {
var wg sync.WaitGroup var workers [10]worker for i := 0; i 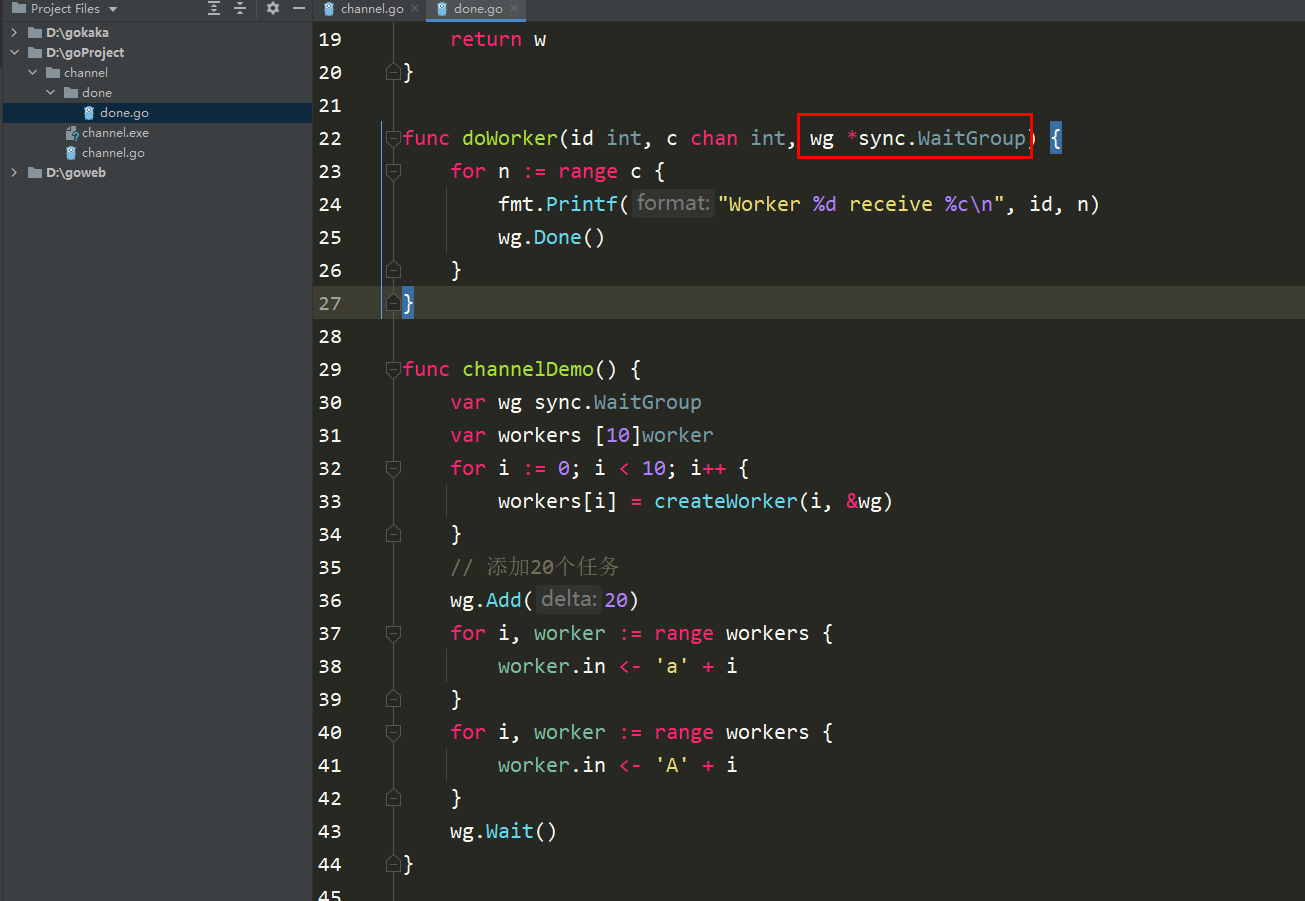
package mainimport (
"fmt"
"sync")type worker struct {
in chan int
done func()}func createWorker(id int, wg *sync.WaitGroup) worker {
w := worker{
in: make(chan int),
done: func() {
wg.Done()
},
}
go doWorker(id, w)
return w}func doWorker(id int, w worker) {
for n := range w.in {
fmt.Printf("Worker %d receive %c\n", id, n)
w.done()
}}func channelDemo() {
var wg sync.WaitGroup var workers [10]worker for i := 0; i package mainimport (
"fmt"
"math/rand"
"time")func generator() chan int {
out := make(chan int)
go func() {
i := 0
for {
// 随机睡眠1500毫秒以内
time.Sleep(
time.Duration(rand.Intn(1500)) *
time.Millisecond)
// 往out这个channel发送i值
out package mainimport (
"fmt"
"math/rand"
"time")func worker(id int, c chan int) {
for n := range c {
fmt.Printf("Worker %d receive %d\n", id, n)
}}func createWorker(id int) chan
package mainimport (
"fmt"
"math/rand"
"time")func worker(id int, c chan int) {
for n := range c {
fmt.Printf("Worker %d receive %d\n", id, n)
}}func createWorker(id int) chan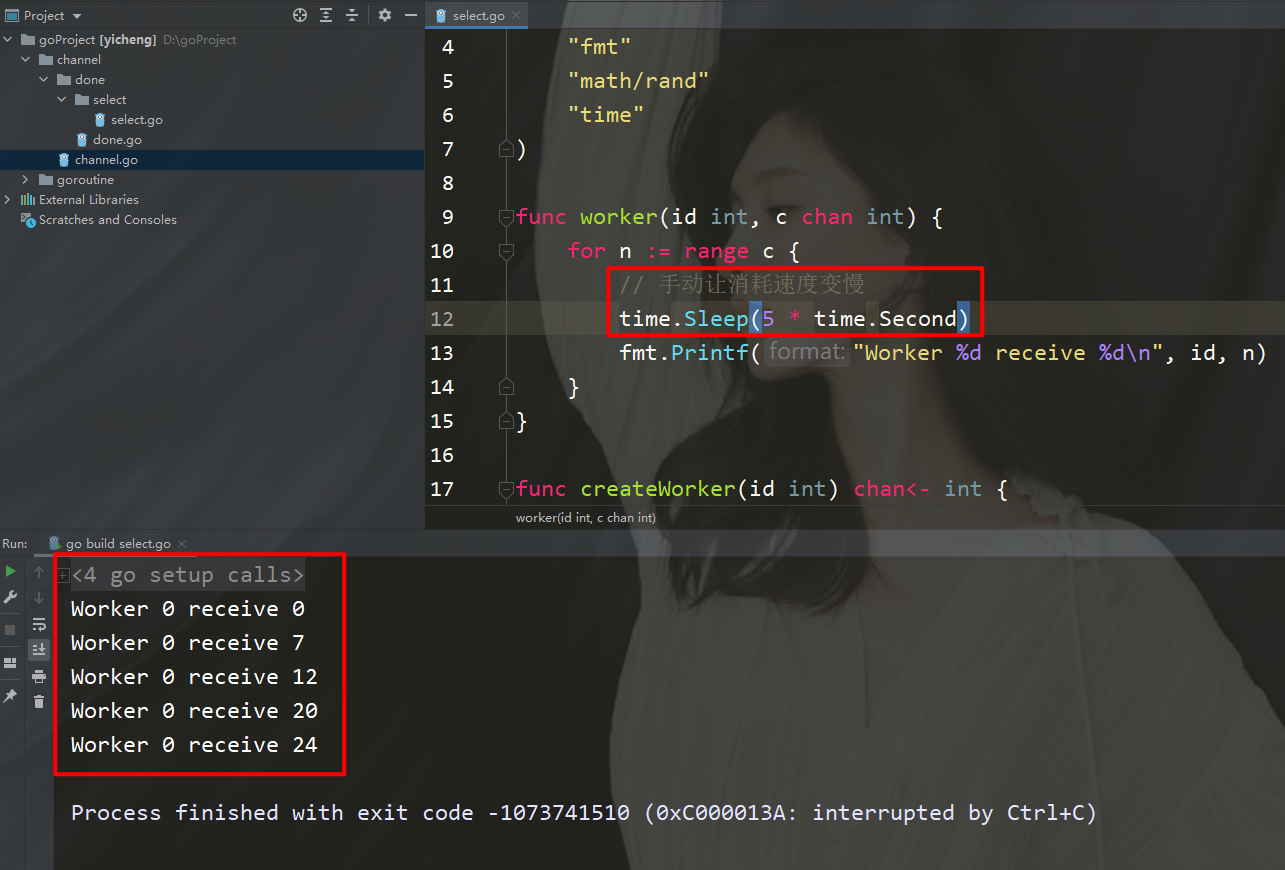
package mainimport (
"fmt"
"math/rand"
"time")func worker(id int, c chan int) {
for n := range c {
// 手动让消耗速度变慢
time.Sleep(5 * time.Second)
fmt.Printf("Worker %d receive %d\n", id, n)
}}func createWorker(id int) chan 0 {
activeWorker = worker // 取出索引为0的值
activeValue = values[0]
}
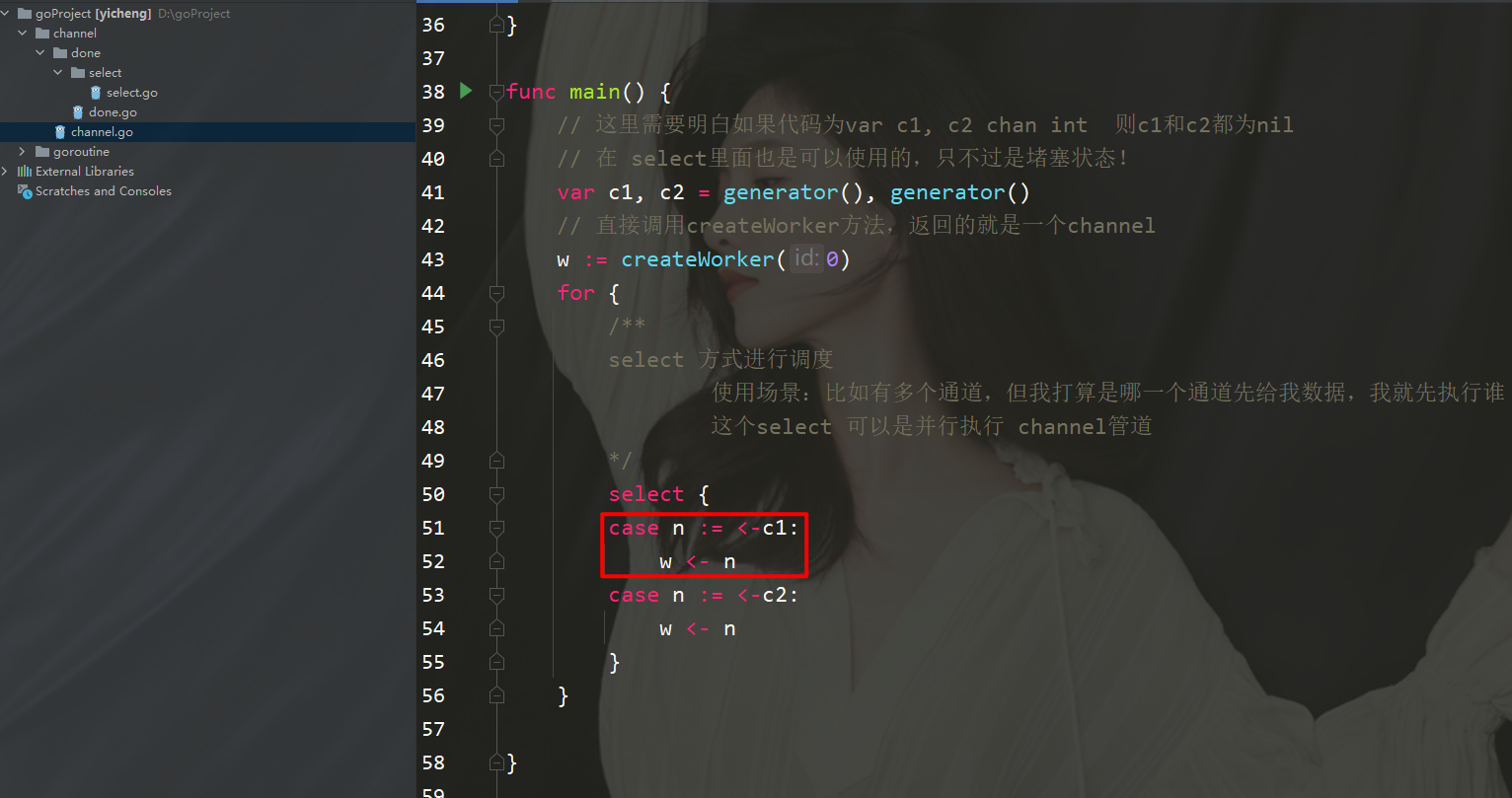
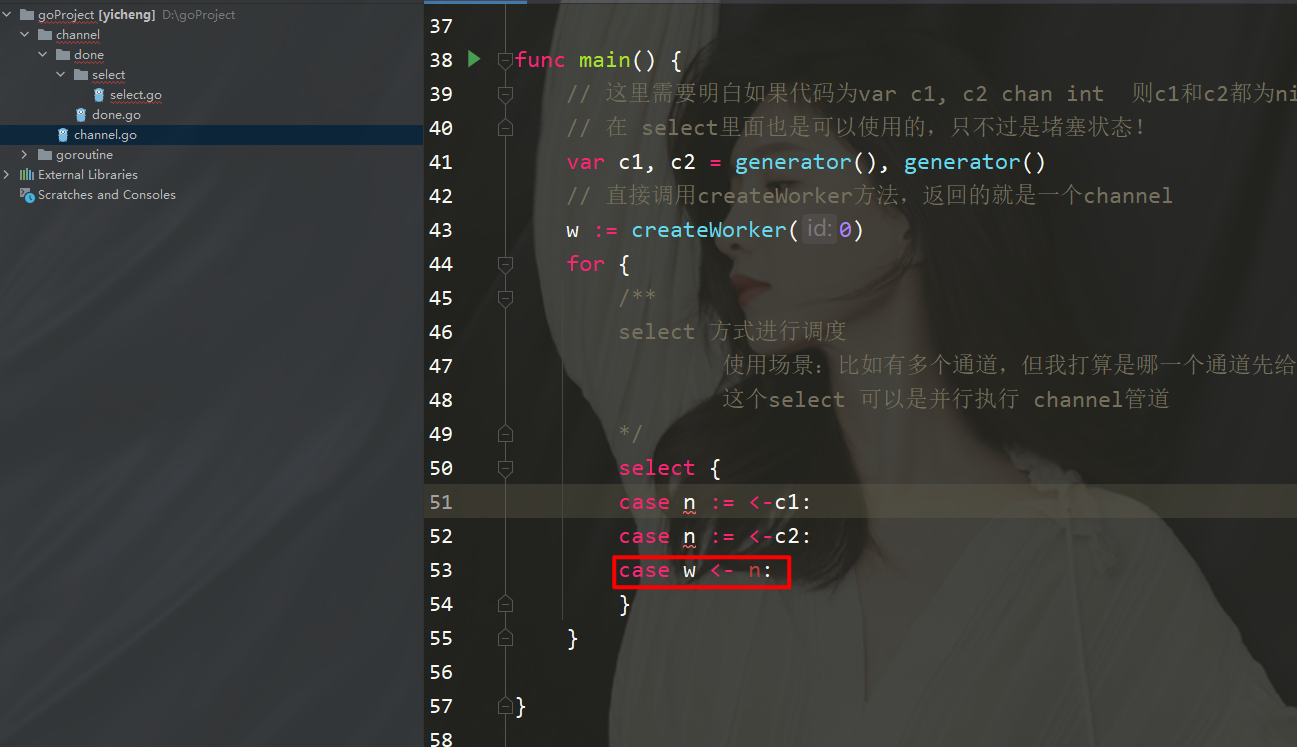
/**
select 方式进行调度
使用场景:比如有多个通道,但我打算是哪一个通道先给我数据,我就先执行谁
这个select 可以是并行执行 channel管道
*/
select {
case n := 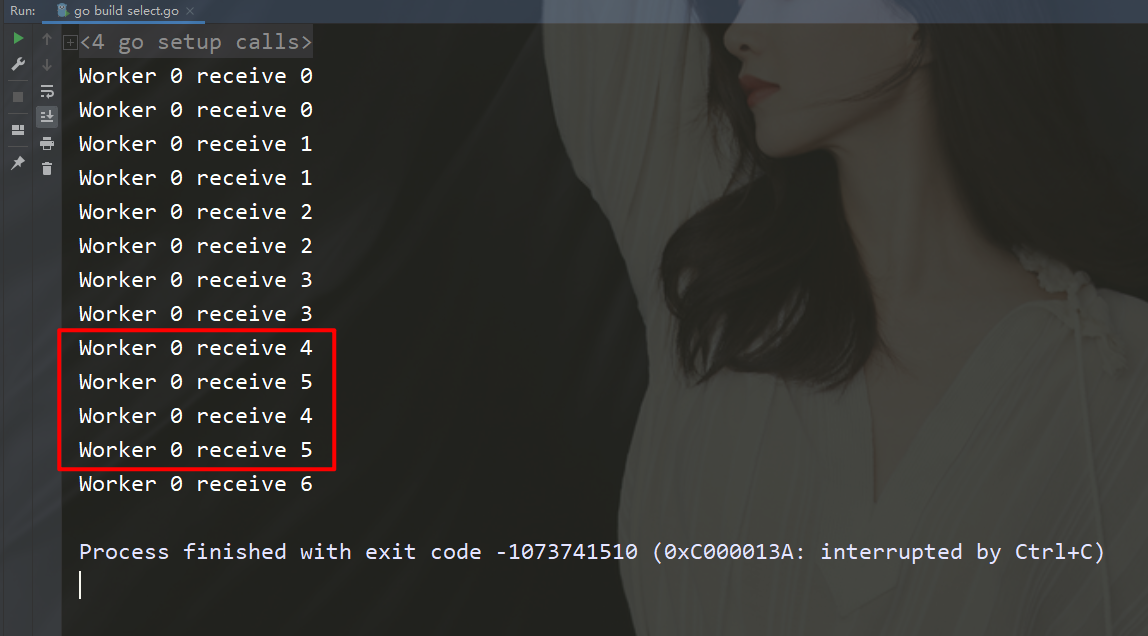
package mainimport (
"fmt"
"math/rand"
"time")func worker(id int, c chan int) {
for n := range c {
// 手动让消耗速度变慢
time.Sleep(time.Second)
fmt.Printf("Worker %d receive %d\n", id, n)
}}func createWorker(id int) chan 0 {
activeWorker = worker // 取出索引为0的值
activeValue = values[0]
}
/**
select 方式进行调度
使用场景:比如有多个通道,但我打算是哪一个通道先给我数据,我就先执行谁
这个select 可以是并行执行 channel管道
*/
select {
case n := 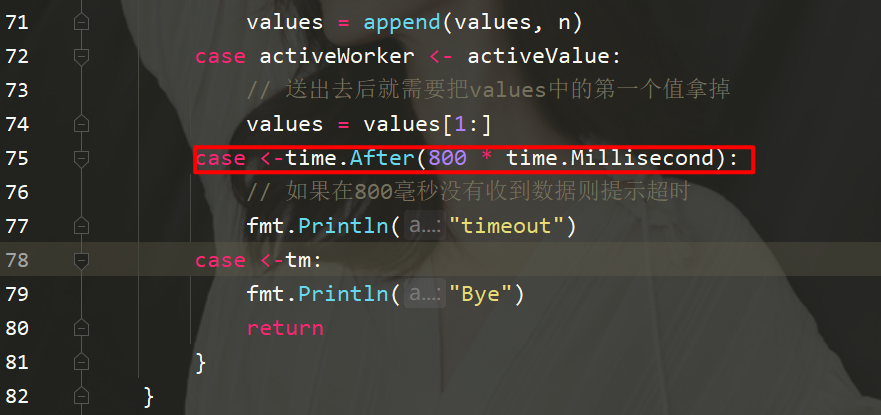
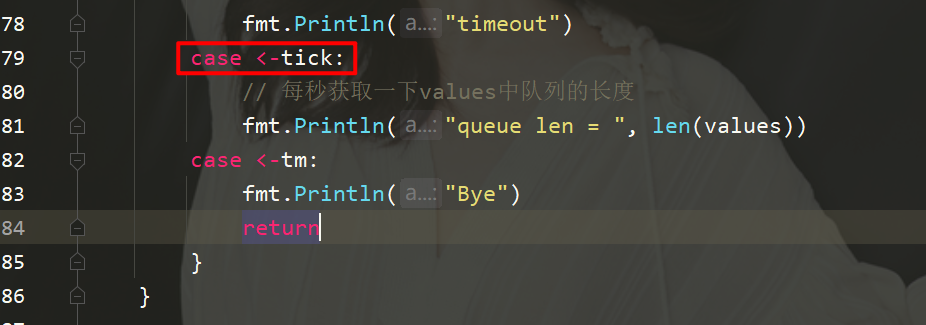
package mainimport (
"fmt"
"math/rand"
"time")func worker(id int, c chan int) {
for n := range c {
// 手动让消耗速度变慢
time.Sleep(time.Second)
fmt.Printf("Worker %d receive %d\n", id, n)
}}func createWorker(id int) chan 0 {
activeWorker = worker // 取出索引为0的值
activeValue = values[0]
}
/**
select 方式进行调度
使用场景:比如有多个通道,但我打算是哪一个通道先给我数据,我就先执行谁
这个select 可以是并行执行 channel管道
*/
select {
case n := Das obige ist der detaillierte Inhalt vonLassen Sie uns über die gleichzeitige Programmierung in Go (2) sprechen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1389
1389
 52
52

 Wie sende ich Go WebSocket-Nachrichten?
Jun 03, 2024 pm 04:53 PM
Wie sende ich Go WebSocket-Nachrichten?
Jun 03, 2024 pm 04:53 PM
In Go können WebSocket-Nachrichten mit dem Paket gorilla/websocket gesendet werden. Konkrete Schritte: Stellen Sie eine WebSocket-Verbindung her. Senden Sie eine Textnachricht: Rufen Sie WriteMessage(websocket.TextMessage,[]byte("message")) auf. Senden Sie eine binäre Nachricht: Rufen Sie WriteMessage(websocket.BinaryMessage,[]byte{1,2,3}) auf.
 Vertiefendes Verständnis des Golang-Funktionslebenszyklus und des Variablenumfangs
Apr 19, 2024 am 11:42 AM
Vertiefendes Verständnis des Golang-Funktionslebenszyklus und des Variablenumfangs
Apr 19, 2024 am 11:42 AM
In Go umfasst der Funktionslebenszyklus Definition, Laden, Verknüpfen, Initialisieren, Aufrufen und Zurückgeben; der Variablenbereich ist in Funktionsebene und Blockebene unterteilt. Variablen innerhalb einer Funktion sind intern sichtbar, während Variablen innerhalb eines Blocks nur innerhalb des Blocks sichtbar sind .
 Wie kann ich Zeitstempel mithilfe regulärer Ausdrücke in Go abgleichen?
Jun 02, 2024 am 09:00 AM
Wie kann ich Zeitstempel mithilfe regulärer Ausdrücke in Go abgleichen?
Jun 02, 2024 am 09:00 AM
In Go können Sie reguläre Ausdrücke verwenden, um Zeitstempel abzugleichen: Kompilieren Sie eine Zeichenfolge mit regulären Ausdrücken, z. B. die, die zum Abgleich von ISO8601-Zeitstempeln verwendet wird: ^\d{4}-\d{2}-\d{2}T \d{ 2}:\d{2}:\d{2}(\.\d+)?(Z|[+-][0-9]{2}:[0-9]{2})$ . Verwenden Sie die Funktion regexp.MatchString, um zu überprüfen, ob eine Zeichenfolge mit einem regulären Ausdruck übereinstimmt.
 Der Unterschied zwischen Golang und Go-Sprache
May 31, 2024 pm 08:10 PM
Der Unterschied zwischen Golang und Go-Sprache
May 31, 2024 pm 08:10 PM
Go und die Go-Sprache sind unterschiedliche Einheiten mit unterschiedlichen Eigenschaften. Go (auch bekannt als Golang) ist bekannt für seine Parallelität, schnelle Kompilierungsgeschwindigkeit, Speicherverwaltung und plattformübergreifende Vorteile. Zu den Nachteilen der Go-Sprache gehören ein weniger umfangreiches Ökosystem als andere Sprachen, eine strengere Syntax und das Fehlen dynamischer Typisierung.
 Wie vermeidet man Speicherlecks bei der technischen Leistungsoptimierung von Golang?
Jun 04, 2024 pm 12:27 PM
Wie vermeidet man Speicherlecks bei der technischen Leistungsoptimierung von Golang?
Jun 04, 2024 pm 12:27 PM
Speicherlecks können dazu führen, dass der Speicher des Go-Programms kontinuierlich zunimmt, indem: Ressourcen geschlossen werden, die nicht mehr verwendet werden, wie z. B. Dateien, Netzwerkverbindungen und Datenbankverbindungen. Verwenden Sie schwache Referenzen, um Speicherlecks zu verhindern, und zielen Sie auf Objekte für die Garbage Collection ab, wenn sie nicht mehr stark referenziert sind. Bei Verwendung von Go-Coroutine wird der Speicher des Coroutine-Stapels beim Beenden automatisch freigegeben, um Speicherverluste zu vermeiden.
 Wie kann ich die Golang-Funktionsdokumentation in der IDE anzeigen?
Apr 18, 2024 pm 03:06 PM
Wie kann ich die Golang-Funktionsdokumentation in der IDE anzeigen?
Apr 18, 2024 pm 03:06 PM
Go-Funktionsdokumentation mit der IDE anzeigen: Bewegen Sie den Cursor über den Funktionsnamen. Drücken Sie den Hotkey (GoLand: Strg+Q; VSCode: Nach der Installation von GoExtensionPack F1 und wählen Sie „Go:ShowDocumentation“).
 Eine Anleitung zum Unit-Testen gleichzeitiger Go-Funktionen
May 03, 2024 am 10:54 AM
Eine Anleitung zum Unit-Testen gleichzeitiger Go-Funktionen
May 03, 2024 am 10:54 AM
Das Testen gleichzeitiger Funktionen in Einheiten ist von entscheidender Bedeutung, da dies dazu beiträgt, ihr korrektes Verhalten in einer gleichzeitigen Umgebung sicherzustellen. Beim Testen gleichzeitiger Funktionen müssen grundlegende Prinzipien wie gegenseitiger Ausschluss, Synchronisation und Isolation berücksichtigt werden. Gleichzeitige Funktionen können Unit-Tests unterzogen werden, indem Rennbedingungen simuliert, getestet und Ergebnisse überprüft werden.
 Was ist zu beachten, wenn Golang-Funktionen Kartenparameter empfangen?
Jun 04, 2024 am 10:31 AM
Was ist zu beachten, wenn Golang-Funktionen Kartenparameter empfangen?
Jun 04, 2024 am 10:31 AM
Beim Übergeben einer Karte an eine Funktion in Go wird standardmäßig eine Kopie erstellt und Änderungen an der Kopie haben keinen Einfluss auf die Originalkarte. Wenn Sie die Originalkarte ändern müssen, können Sie sie über einen Zeiger übergeben. Leere Karten müssen mit Vorsicht behandelt werden, da es sich technisch gesehen um Nullzeiger handelt und die Übergabe einer leeren Karte an eine Funktion, die eine nicht leere Karte erwartet, einen Fehler verursacht.
