

Dieser Artikel führt Sie durch die Master-Slave-, Master-Slave- und Lese-Schreib-Trennung in MySQL. Ich hoffe, er wird Ihnen hilfreich sein!
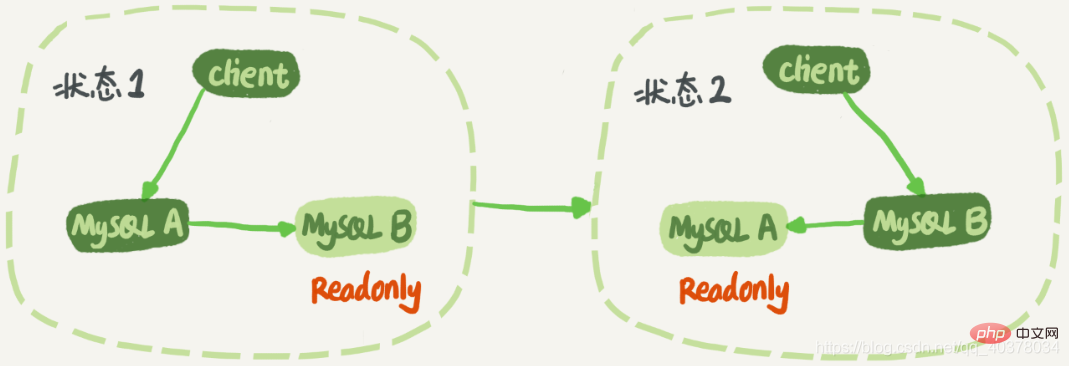
Im Zustand 1 greift der Client zum Lesen und Schreiben direkt auf Knoten A zu, und Knoten B ist die Backup-Datenbank von A. Er synchronisiert lediglich die Aktualisierungen von A bis Lokal ausgeführt. Dadurch bleiben die Daten der Knoten B und A gleich. Wenn eine Umschaltung erforderlich ist, wechselt es in den Zustand 2. Zu diesem Zeitpunkt liest und schreibt der Client auf Knoten B, und Knoten A ist die Standby-Datenbank von B. [Verwandte Empfehlungen: MySQL-Video-Tutorial]
Obwohl im Status 1 nicht direkt auf Knoten B zugegriffen wird, wird empfohlen, den Standby-Knoten B in den schreibgeschützten Modus zu versetzen. Dafür gibt es mehrere Gründe:
1. Manchmal werden einige operative Abfrageanweisungen zur Überprüfung in die Standby-Datenbank gestellt, um Fehlbedienungen zu verhindern.
3 Verwenden Sie den schreibgeschützten Status, um die Rolle des Knotens zu bestimmen
Wenn die Standby-Datenbank auf schreibgeschützt eingestellt ist, wie kann sie synchron mit der Hauptdatenbank aktualisiert werden?
Die Einstellung „Schreibgeschützt“ ist für Benutzer mit Superprivilegien ungültig und der Thread, der für synchronisierte Updates verwendet wird, verfügt über Superprivilegien
Die folgende Abbildung ist ein vollständiges Flussdiagramm einer Update-Anweisung, die auf Knoten A ausgeführt und dann mit Knoten B synchronisiert wird:
Zwischen der Standby-Datenbank B und der Primärdatenbank A wird eine lange Verbindung aufrechterhalten. In der Hauptbibliothek A gibt es einen Thread, der für die lange Verbindung der Standby-Bibliothek B zuständig ist. Der vollständige Prozess der Transaktionsprotokollsynchronisierung ist wie folgt: 
1. Verwenden Sie den Befehl „Change Master“ für die Standby-Datenbank B, um die IP, den Port, den Benutzernamen und das Kennwort der Primärdatenbank A und den Speicherort festzulegen, von dem aus das Binlog angefordert werden soll Der Speicherort enthält den Dateinamen und den Protokolloffset
2. Führen Sie den Befehl „Start Slave“ in der Standby-Datenbank B aus. Zu diesem Zeitpunkt startet die Standby-Datenbank zwei Threads, nämlich io_thread und sql_thread im Bild. Unter anderem ist io_thread für den Verbindungsaufbau mit der Hauptbibliothek verantwortlich
3 Nachdem die Hauptbibliothek A den Benutzernamen und das Kennwort überprüft hat, beginnt sie, das Binlog entsprechend dem von der Standby-Bibliothek B übergebenen Speicherort zu lesen und zu senden es nach B
4. Standby-Bibliothek B Nachdem Sie das Binlog erhalten haben, schreiben Sie es in eine lokale Datei, das Transitprotokoll genannt
5.sql_thread liest das Transitprotokoll, analysiert die Befehle im Protokoll und führt es aus
Aufgrund von Mit der Einführung des Multithread-Replikationsschemas entwickelte sich sql_thread zu mehreren Threads. Auf diese Weise muss die Aktiv-Standby-Beziehung während des Wechsels nicht geändert werden. Es gibt ein Problem, das in der Doppel-M-Struktur gelöst werden muss. Die Geschäftslogik aktualisiert eine Anweisung an Knoten A und sendet dann das generierte Binlog Knoten B. Nachdem Knoten B dieses Binlog ausgeführt hat, wird es auch nach Update-Anweisungen generiert. Wenn Knoten A dann auch die Standby-Datenbank von Knoten B ist, entspricht dies der einmaligen Ausführung des neu generierten Binlogs von Knoten B. Anschließend wird die Aktualisierungsanweisung kontinuierlich in einer Schleife zwischen den Knoten A und B ausgeführt ist die Schleifenreplikation
MySQL zeichnet die Server-ID der Instanz auf, in der dieser Befehl zum ersten Mal im Binlog ausgeführt wurde. Daher kann die folgende Logik verwendet werden, um das Problem der zirkulären Replikation zwischen zwei Knoten zu lösen:
3 Nachdem jede Datenbank das von ihrer Hauptdatenbank gesendete Protokoll empfangen hat, wird es zuerst bestimmt Wenn die Server-ID mit Ihrer eigenen übereinstimmt, bedeutet dies, dass das Protokoll von Ihnen selbst erstellt wurde. Verwerfen Sie das Protokoll also einfach direkt. Der Ausführungsablauf des Doppel-M-Strukturprotokolls ist wie folgt:
1 Die Transaktionen wurden aktualisiert von Knoten A werden in der Server-ID von Binlog A aufgezeichnet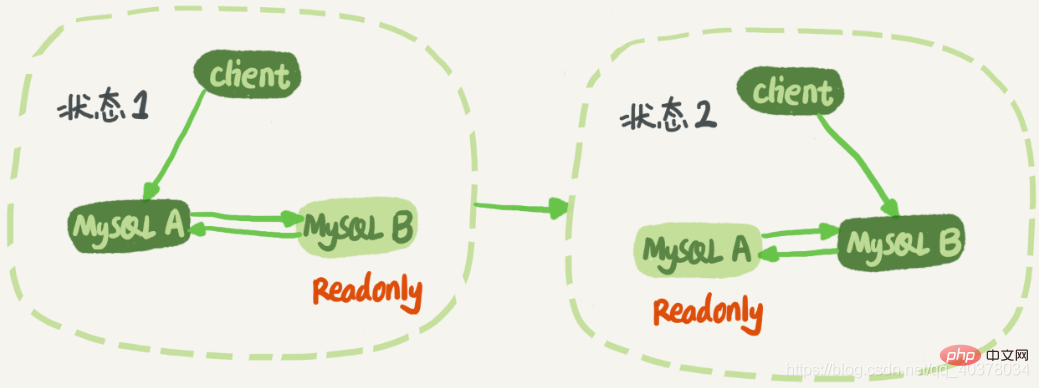
2 Nachdem es einmal zur Ausführung an Knoten B gesendet wurde, ist die Server-ID des von Knoten B generierten Binlogs auch die Server-ID von A
3 Knoten A und A stellt fest, dass die Server-ID mit seiner eigenen übereinstimmt. Dieses Protokoll wird nicht erneut verarbeitet. Daher wird hier die Endlosschleife unterbrochen
3. Primäre und sekundäre Verzögerungen1. Was sind primäre und sekundäre Verzögerungen?
Die mit der Datensynchronisierung verbundenen Zeitpunkte umfassen hauptsächlich die folgenden drei: 1 Die Hauptdatenbank A schließt eine Transaktion ab und schreibt sie in das Binlog. Dieser Moment wird als T1 aufgezeichnet Standby-Datenbank B und die Standby-Datenbank Der Moment, in dem B den Empfang dieses Binlogs beendet, wird als T23 aufgezeichnet. Nachdem die Standby-Datenbank B diese Transaktion ausgeführt hat, wird der Moment als T31. Im Binlog jeder Transaktion gibt es ein Zeitfeld, das zum Aufzeichnen der in die Hauptdatenbank geschriebenen Zeit verwendet wird.
2 Die Standby-Datenbank entnimmt den Wert des Zeitfelds der aktuell ausgeführten Transaktion Differenz zur aktuellen Systemzeit. Holen Sie sich seconds_behind_master
Wenn die Systemzeiteinstellungen der Master- und Backup-Datenbankmaschinen inkonsistent sind, führt dies nicht dazu, dass die Master- und Backup-Verzögerungswerte ungenau sind. Wenn die Standby-Datenbank mit der Primärdatenbank verbunden ist, erhält sie die Systemzeit der aktuellen Primärdatenbank über die Funktion SELECTUNIX_TIMESTAMP(). Wenn zu diesem Zeitpunkt festgestellt wird, dass die Systemzeit der Hauptdatenbank nicht mit ihrer eigenen übereinstimmt, zieht die Standby-Datenbank diese Differenz automatisch ab, wenn sie die Berechnung seconds_behind_master ausführt.
Unter normalen Netzwerkbedingungen ist dies die Hauptverzögerungsquelle zwischen der aktiven und der Standby-Datenbank Datenbanken ist die Zeit, nachdem die Standby-Datenbank das Binlog empfangen und die Ausführung abgeschlossen hat der Hauptdatenbank, die Binlog erstellt
2. Der ursprüngliche Grund für die Master-Backup-Verzögerungmysql> CREATE TABLE `t` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `c` int(11) unsigned DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;insert into t(c) values(1),(2),(3);
1. In Schritt 2 wird die Hauptbibliothek A abgeschlossen Die Einfügeanweisung, das Einfügen einer Datenzeile (4,4) und das anschließende Starten des Aktiv-Standby-Schalters
2 In Schritt 3 hatte die Standby-Datenbank B aufgrund der 5-Sekunden-Verzögerung keine Zeit Zeit, das Einfügen von c=4 anzuwenden. Nach der Übertragung des Protokolls beginnt es, den Befehl des Clients zum Einfügen von c=5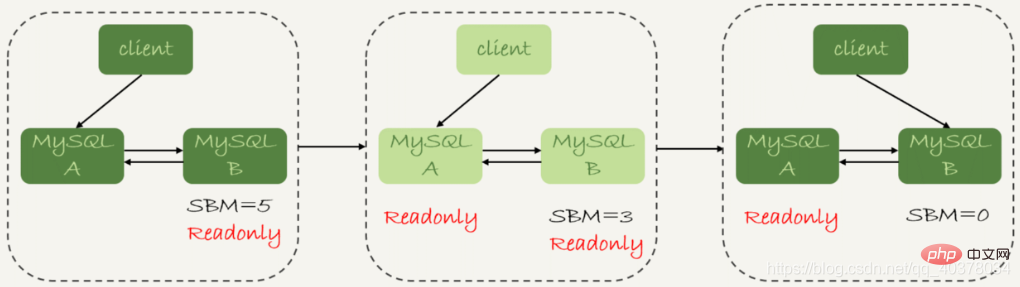
3 zu empfangen. In Schritt 4 fügt die Standby-Datenbank B eine Datenzeile (4,5) ein und sendet diese binlog zur Hauptdatenbank A
4. Schritt 5: Die Standby-Datenbank B führt das Einfügen des Übertragungsprotokolls c=4 aus und fügt eine Datenzeile ein (5,4). Die Anweisung insert c=5, die direkt in der Standby-Datenbank B ausgeführt wird, wird an die Hauptdatenbank A übertragen und eine neue Datenzeile (5,5) eingefügt. Das Endergebnis ist, dass zwei Zeilen in der Hauptdatenbank A erscheinen und die Standby-Datenbank B. Zeilen inkonsistenter Daten
Verfügbarkeitsprioritätsstrategie, setze binlog_format=row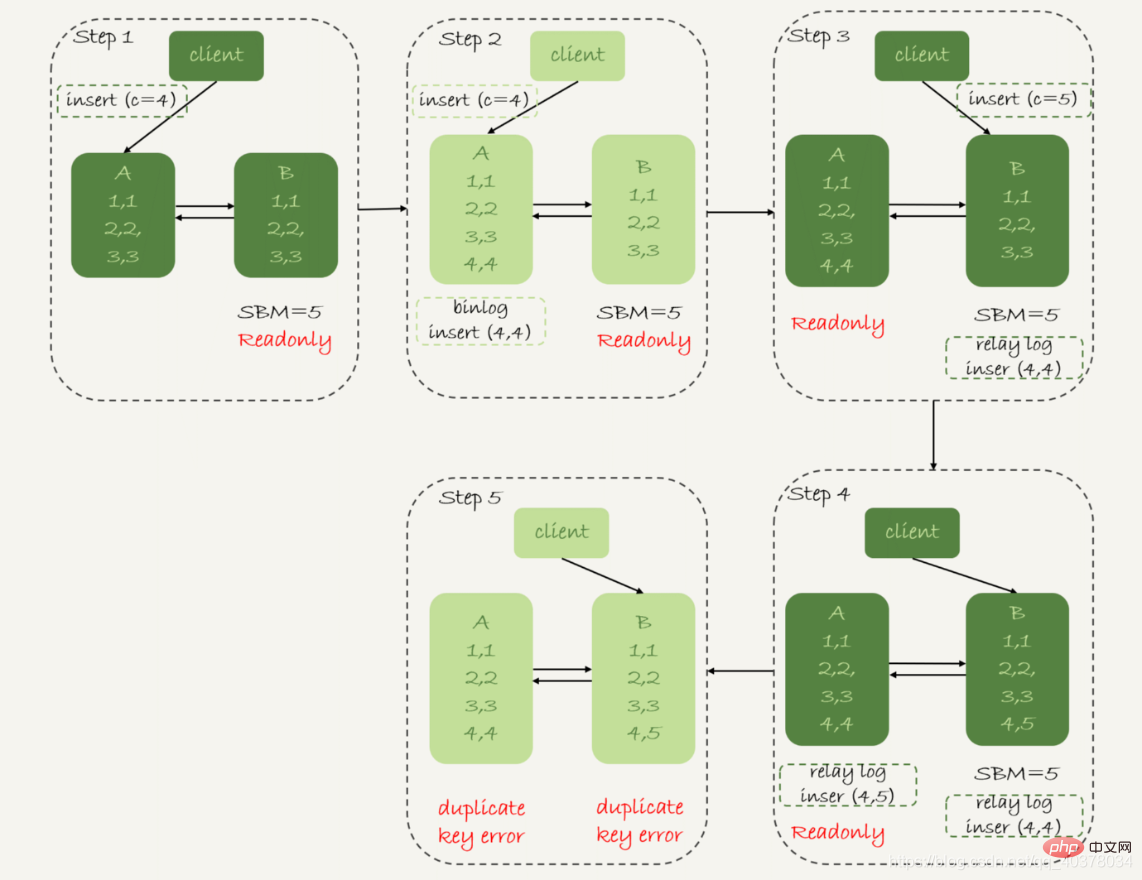
Wenn das Zeilenformat binlog aufzeichnet, werden daher alle Feldwerte der neu eingefügten Zeilen aufgezeichnet, sodass am Ende nur eine Zeile inkonsistent ist . Darüber hinaus melden die Anwendungsthreads der aktiven und Standby-Synchronisierung auf beiden Seiten einen Fehler wegen doppeltem Schlüssel und stoppen. Mit anderen Worten, in diesem Fall werden die beiden Datenzeilen (5,4) in der Standby-Datenbank B und (5,5) in der Primärdatenbank A nicht von der anderen Partei ausgeführt
1. Bei Verwendung von Binlog im Zeilenformat sind Dateninkonsistenzprobleme leichter zu finden. Bei der Verwendung von Binlog im gemischten Format oder im Anweisungsformat kann es lange dauern, bis das Problem der Dateninkonsistenz erkannt wird. Daher wird in den meisten Fällen empfohlen, eine Strategie zu übernehmen, bei der die Zuverlässigkeit an erster Stelle steht
5. Die parallele Replikationsstrategie von MySQL
Der Multithread-Replikationsmechanismus teilt den sql_thread mit nur einem Thread in mehrere Threads auf, was dem folgenden Modell entspricht: 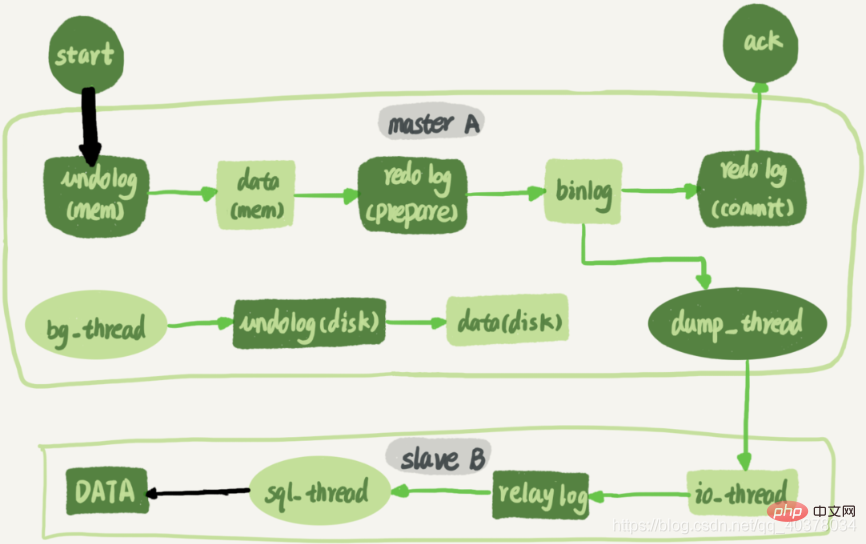
Der Koordinator ist der ursprüngliche sql_thread, aber jetzt ist er nicht mehr vorhanden Aktualisiert die Daten nicht mehr direkt und ist nur noch für das Lesen des Transitprotokolls und die Verteilung von Transaktionen verantwortlich. Was das Protokoll tatsächlich aktualisiert, wird zum Arbeitsthread. Die Anzahl der Worker-Threads wird durch den Parameter „slave_parallel_workers“ bestimmt. Bei der Verteilung muss der Koordinator die folgenden zwei Grundanforderungen erfüllen:
kann keine Update-Abdeckung verursachen. Dies erfordert, dass zwei Transaktionen, die dieselbe Zeile aktualisieren, an denselben Worker verteilt werden müssen. Dieselbe Transaktion kann nicht aufgeteilt werden und muss im selben Worker platziert werden. 1 Parallele Replikationsstrategie von MySQL Version 5.6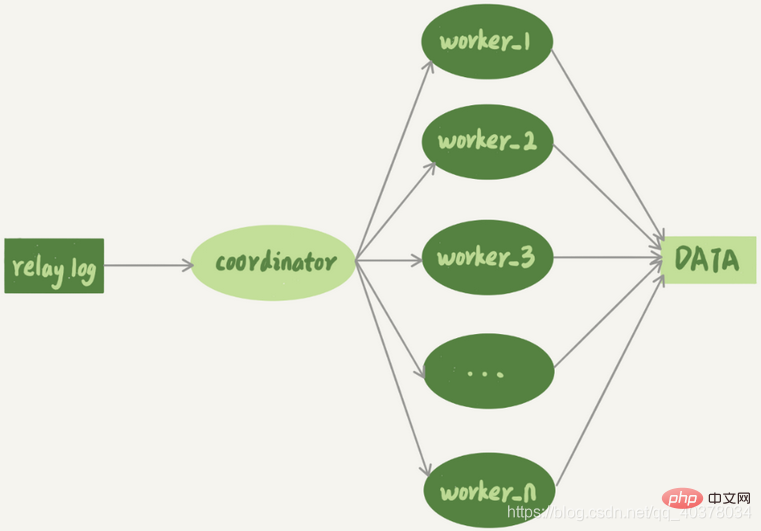
MySQL Version 5.6 unterstützt die parallele Replikation, die unterstützte Granularität ist jedoch die parallele Replikation nach Datenbank. In der Hash-Tabelle, die zur Bestimmung der Verteilungsstrategie verwendet wird, ist der Schlüssel der Datenbankname
Der parallele Effekt dieser Strategie hängt vom Druckmodell ab. Wenn in der Hauptdatenbank mehrere Datenbanken vorhanden sind und der Druck jeder Datenbank ausgeglichen ist, ist die Wirkung dieser Strategie sehr gut Bibliotheksname ist erforderlich
Transaktionen, die in derselben Gruppe übermittelt werden können, ändern definitiv nicht dieselbe Zeile
Master-Transaktionen, die parallel in der Datenbank ausgeführt werden können, müssen auch parallel in der Standby-Datenbank ausgeführt werden. In Bezug auf die Implementierung führt MariaDB Folgendes aus:
Die folgende Abbildung geht von der Ausführung von drei Transaktionssätzen in der Hauptbibliothek aus. Wenn trx1, trx2 und trx3 übermittelt werden, werden trx4, trx5 und trx6 ausgeführt. Auf diese Weise wird, wenn die erste Gruppe von Transaktionen übermittelt wird, die nächste Gruppe von Transaktionen bald in den Commit-Status wechseln
konfiguriert als LOGICAL_CLOCK, was eine ähnliche Strategie wie MariaDB bedeutet. MySQL wurde auf dieser Basis optimiert. Können alle Transaktionen, die sich gleichzeitig im Ausführungszustand befinden, parallelisiert werden?
不可以,因为这里面可能有由于锁冲突而处于锁等待状态的事务。如果这些事务在备库上被分配到不同的worker,就会出现备库跟主库不一致的情况
而MariaDB这个策略的核心是所有处于commit状态的事务可以并行。事务处于commit状态表示已经通过了锁冲突的检验了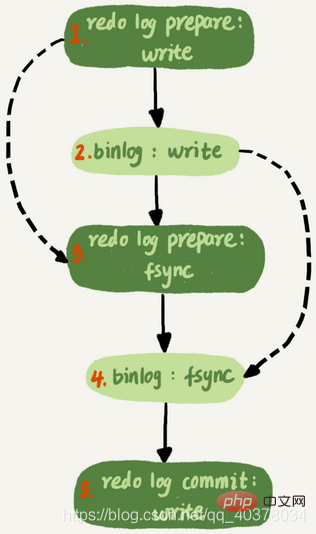
其实只要能够达到redo log prepare阶段就表示事务已经通过锁冲突的检验了
因此,MySQL5.7并行复制策略的思想是:
1.同时处于prepare状态的事务,在备库执行时是可以并行的
2.处于prepare状态的事务,与处于commit状态的事务之间,在备库执行时也是可以并行的
binlog组提交的时候有两个参数:
这两个参数是用于故意拉长binlog从write到fsync的时间,以此减少binlog的写盘次数。在MySQL5.7的并行复制策略里,它们可以用来制造更多的同时处于prepare阶段的事务。这样就增加了备库复制的并行度。也就是说,这两个参数既可以故意让主库提交得慢些,又可以让备库执行得快些
MySQL5.7.22增加了一个新的并行复制策略,基于WRITESET的并行复制,新增了一个参数binlog-transaction-dependency-tracking用来控制是否启用这个新策略。这个参数的可选值有以下三种:
为了唯一标识,hash值是通过库名+表名+索引名+值计算出来的。如果一个表上除了有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert语句对应的writeset就要多增加一个hash值
1.writeset是在主库生成后直接写入到binlog里面的,这样在备库执行的时候不需要解析binlog内容
2.不需要把整个事务的binlog都扫一遍才能决定分发到哪个worker,更省内存
3.由于备库的分发策略不依赖于binlog内容,索引binlog是statement格式也是可以的
对于表上没主键和外键约束的场景,WRITESET策略也是没法并行的,会暂时退化为单线程模型
下图是一个基本的一主多从结构
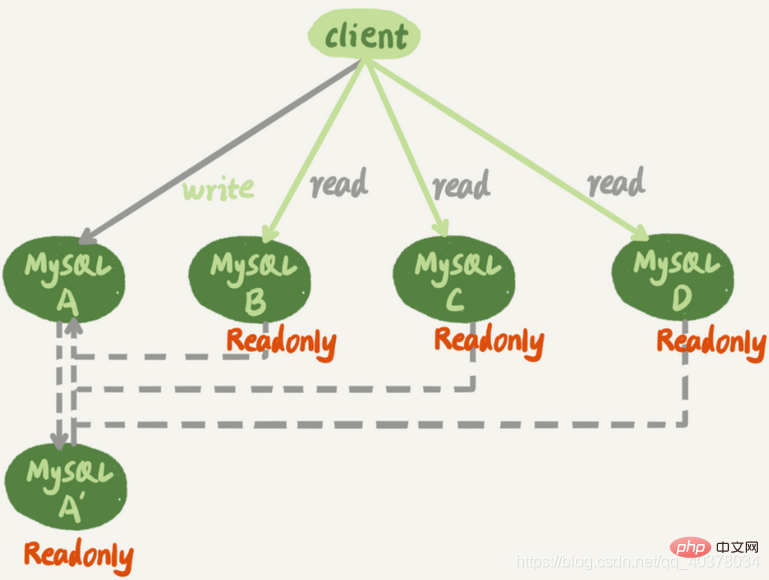
图中,虚线箭头表示的是主备关系,也就是A和A’互为主备,从库B、C、D指向的是主库A。一主多从的设置,一般用于读写分离,主库负责所有的写入和一部分读,其他的读请求则由从库分担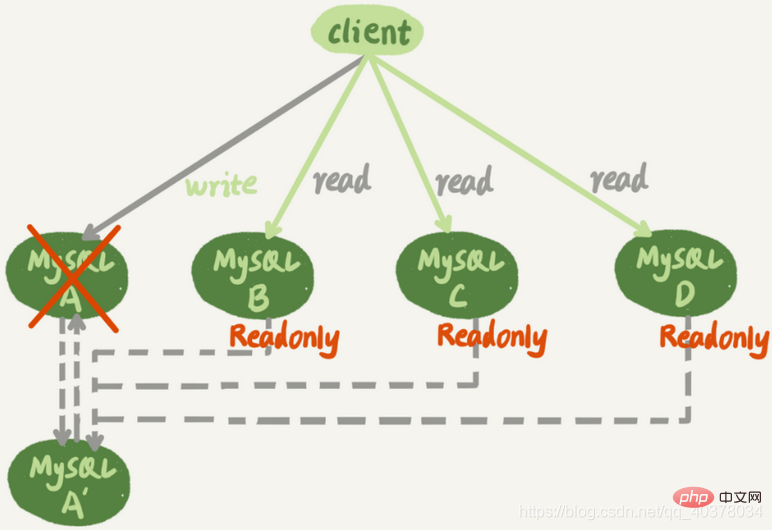
一主多从结构在切换完成后,A’会成为新的主库,从库B、C、D也要改接到A’
当我们把节点B设置成节点A’的从库的时候,需要执行一条change master命令:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password MASTER_LOG_FILE=$master_log_name MASTER_LOG_POS=$master_log_pos
找同步位点很难精确取到,只能取一个大概位置。一种去同步位点的方法是这样的:
1.等待新主库A’把中转日志全部同步完成
2.在A’上执行show master status命令,得到当前A’上最新的File和Position
3.取原主库A故障的时刻T
4.用mysqlbinlog工具解析A’的File,得到T时刻的位点,这个值就可以作为$master_log_pos
这个值并不精确,有这么一种情况,假设在T这个时刻,主库A已经执行完成了一个insert语句插入了一行数据R,并且已经将binlog传给了A’和B,然后在传完的瞬间主库A的主机就掉电了。那么,这时候系统的状态是这样的:
1.在从库B上,由于同步了binlog,R这一行已经存在
2.在新主库A’上,R这一行也已经存在,日志是写在master_log_pos这个位置之后的
3.在从库B上执行change master命令,指向A’的File文件的master_log_pos位置,就会把插入R这一行数据的binlog又同步到从库B去执行,造成主键冲突,然后停止tongue
通常情况下,切换任务的时候,要先主动跳过这些错误,有两种常用的方法
一种是,主动跳过一个事务
set global sql_slave_skip_counter=1;start slave;
另一种方式是,通过设置slave_skip_errors参数,直接设置跳过指定的错误。这个背景是,我们很清楚在主备切换过程中,直接跳过这些错误是无损的,所以才可以设置slave_skip_errors参数。等到主备间的同步关系建立完成,并稳定执行一段时间之后,还需要把这个参数设置为空,以免之后真的出现了主从数据不一致,也跳过了
MySQL5.6引入了GTID,是一个全局事务ID,是一个事务提交的时候生成的,是这个事务的唯一标识。它的格式是:
GTID=source_id:transaction_id
GTID模式的启动只需要在启动一个MySQL实例的时候,加上参数gtid_mode=on和enforce_gtid_consistency=on就可以了
在GTID模式下,每个事务都会跟一个GTID一一对应。这个GTID有两种生成方式,而使用哪种方式取决于session变量gtid_next的值
1.如果gtid_next=automatic,代表使用默认值。这时,MySQL就把GTID分配给这个事务。记录binlog的时候,先记录一行SET@@SESSION.GTID_NEXT=‘GTID’。把这个GTID加入本实例的GTID集合
2.如果gtid_next是一个指定的GTID的值,比如通过set gtid_next=‘current_gtid’,那么就有两种可能:
一个current_gtid只能给一个事务使用。这个事务提交后,如果要执行下一个事务,就要执行set命令,把gtid_next设置成另外一个gtid或者automatic
这样每个MySQL实例都维护了一个GTID集合,用来对应这个实例执行过的所有事务
在GTID模式下,备库B要设置为新主库A’的从库的语法如下:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password master_auto_position=1
其中master_auto_position=1就表示这个主备关系使用的是GTID协议
实例A’的GTID集合记为set_a,实例B的GTID集合记为set_b。我们在实例B上执行start slave命令,取binlog的逻辑是这样的:
1.实例B指定主库A’,基于主备协议建立连接
2.实例B把set_b发给主库A’
3.实例A’算出set_a与set_b的差集,也就是所有存在于set_a,但是不存在于set_b的GTID的集合,判断A’本地是否包含了这个差集需要的所有binlog事务
4.之后从这个事务开始,往后读文件,按顺序取binlog发给B去执行
如果是由于索引缺失引起的性能问题,可以在线加索引来解决。但是,考虑到要避免新增索引对主库性能造成的影响,可以先在备库加索引,然后再切换,在双M结构下,备库执行的DDL语句也会传给主库,为了避免传回后对主库造成影响,要通过set sql_log_bin=off关掉binlog,但是操作可能会导致数据和日志不一致
两个互为主备关系的库实例X和实例Y,且当前主库是X,并且都打开了GTID模式。这时的主备切换流程可以变成下面这样:
set GTID_NEXT="source_id_of_Y:transaction_id";begin;commit;set gtid_next=automatic;start slave;
这样做的目的在于,既可以让实例Y的更新有binlog记录,同时也可以确保不会在实例X上执行这条更新
读写分离的基本结构如下图:
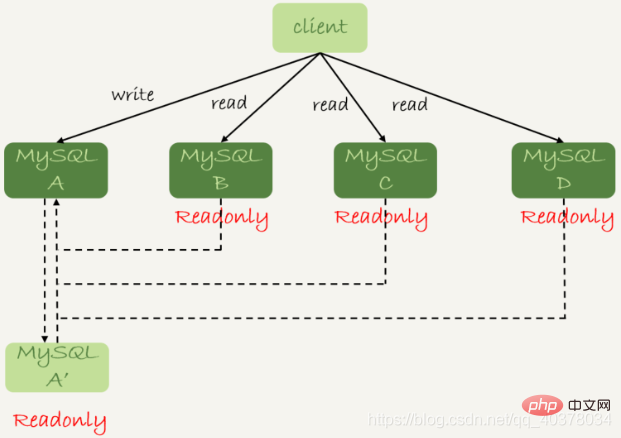
读写分离的主要目的就是分摊主库的压力。上图中的结构是客户端主动做负载均衡,这种模式下一般会把数据库的连接信息放在客户端的连接层。由客户端来选择后端数据库进行查询
还有一种架构就是在MySQL和客户端之间有一个中间代理层proxy,客户端只连接proxy,由proxy根据请求类型和上下文决定请求的分发路由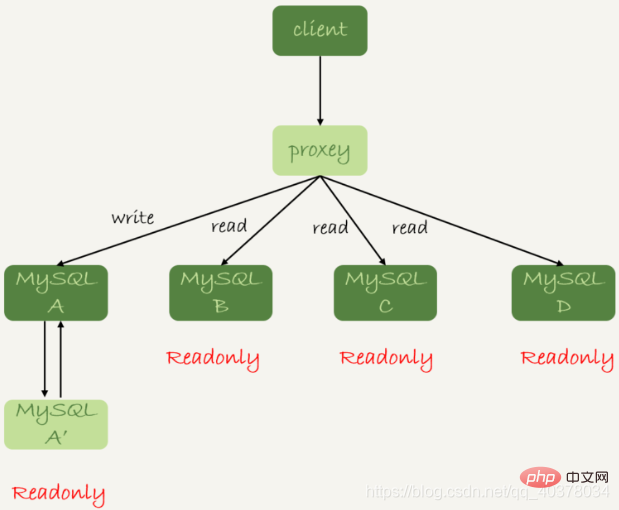
1.客户端直连方案,因此少了一层proxy转发,所以查询性能稍微好一点,并且整体架构简单,排查问题更方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息。一般采用这样的架构,一定会伴随一个负责管理后端的组件,比如Zookeeper,尽量让业务端只专注于业务逻辑开发
2.带proxy的架构,对客户端比较友好。客户端不需要关注后端细节,连接维护、后端信息维护等工作,都是由proxy完成的。但这样的话,对后端维护团队的要求会更高,而且proxy也需要有高可用架构
在从库上会读到系统的一个过期状态的现象称为过期读
强制走主库方案其实就是将查询请求做分类。通常情况下,可以分为这么两类:
1.对于必须要拿到最新结果的请求,强制将其发到主库上
2.对于可以读到旧数据的请求,才将其发到从库上
这个方案最大的问题在于,有时候可能会遇到所有查询都不能是过期读的需求,比如一些金融类的业务。这样的话,就需要放弃读写分离,所有读写压力都在主库,等同于放弃了扩展性
主库更新后,读从库之前先sleep一下。具体的方案就是,类似于执行一条select sleep(1)命令。这个方案的假设是,大多数情况下主备延迟在1秒之内,做一个sleep可以很大概率拿到最新的数据
以买家发布商品为例,商品发布后,用Ajax直接把客户端输入的内容作为最新商品显示在页面上,而不是真正地去数据库做查询。这样,卖家就可以通过这个显示,来确认产品已经发布成功了。等到卖家再刷新页面,去查看商品的时候,其实已经过了一段时间,也就达到了sleep的目的,进而也就解决了过期读的问题
但这个方案并不精确:
1.如果这个查询请求本来0.5秒就可以在从库上拿到正确结果,也会等1秒
2.如果延迟超过1秒,还是会出现过期读
show slave status结果里的seconds_behind_master参数的值,可以用来衡量主备延迟时间的长短
1.第一种确保主备无延迟的方法是,每次从库执行查询请求前,先判断seconds_behind_master是否已经等于0。如果还不等于0,那就必须等到这个参数变为0才能执行查询请求
show slave status结果的部分截图如下:
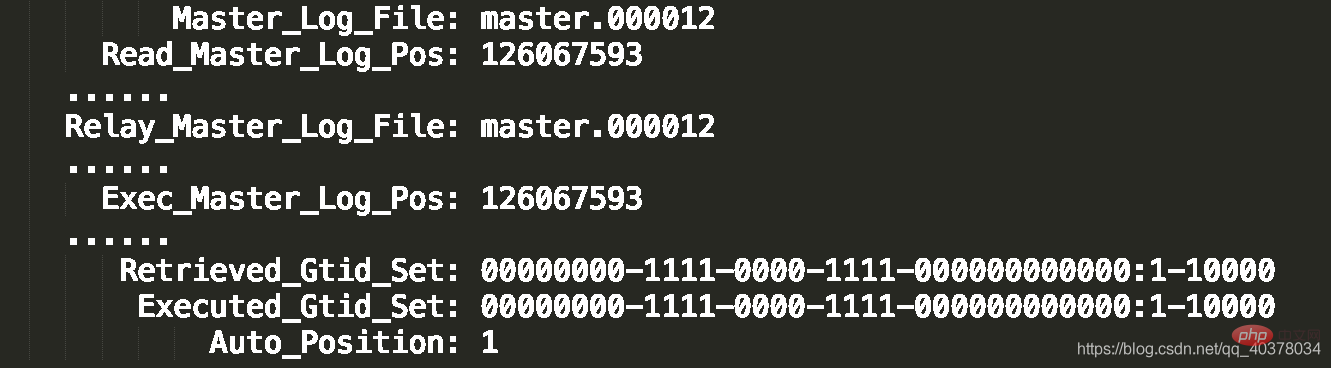
2.第二种方法,对比位点确保主备无延迟:
如果Master_Log_File和Read_Master_Log_Pos和Relay_Master_Log_File和Exec_Master_Log_Pos这两组值完全相同,就表示接收到的日志已经同步完成
3.第三种方法,对比GTID集合确保主备无延迟:
如果这两个集合相同,也表示备库接收到的日志都已经同步完成
4.一个事务的binlog在主备库之间的状态:
1)主库执行完成,写入binlog,并反馈给客户端
2)binlog被从主库发送给备库,备库收到
3)在备库执行binlog完成
上面判断主备无延迟的逻辑是备库收到的日志都执行完成了。但是,从binlog在主备之间状态的分析中,有一部分日志,处于客户端已经收到提交确认,而备库还没收到日志的状态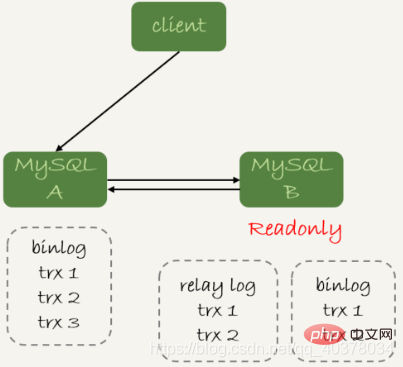
这时,主库上执行完成了三个事务trx1、trx2和trx3,其中:
如果这时候在从库B上执行查询请求,按照上面的逻辑,从库认为已经没有同步延迟,但还是查不到trx3的
要解决上面的问题,就要引入半同步复制。semi-sync做了这样的设计:
1.事务提交的时候,主库把binlog发送给从库
2.从库收到binlog以后,发回给主库一个ack,表示收到了
3.主库收到这个ack以后,才能给客户端返回事务完成的确认
如果启用了semi-sync,就表示所有给客户端发送过确认的事务,都确保了备库已经收到了这个日志
semi-sync+位点判断的方案,只对一主一备的场景是成立的。在一主多从场景中,主库只要等到一个从库的ack,就开始给客户端返回确认。这时,在从库上执行查询请求,就有两种情况:
1.如果查询是落在这个响应了ack的从库上,是能够确保读到最新数据
2.但如果查询落到其他从库上,它们可能还没有收到最新的日志,就会产生过期读的问题
判断同步位点的方案还有另外一个潜在的问题,即:如果在业务更新的高峰期,主库的位点或者GTID集合更新很快,那么上面的两个位点等值判断就会一直不成立,很有可能出现从库上迟迟无法响应查询请求的情况
上图从状态1到状态4,一直处于延迟一个事务的状态。但是,其实客户端是在发完trx1更新后发起的select语句,我们只需要确保trx1已经执行完成就可以执行select语句了。也就是说,如果在状态3执行查询请求,得到的就是预期结果了
semi-sync配合主备无延迟的方案,存在两个问题:
1.一主多从的时候,在某些从库执行查询请求会存在过期读的现象
2.在持续延迟的情况下,可能出现过度等待的问题
select master_pos_wait(file, pos[, timeout]);
这条命令的逻辑如下:
1.它是在从库执行的
2.参数file和pos指的是主库上的文件名和位置
3.timeout可选,设置为正整数N表示这个函数最多等待N秒
这个命令正常返回的结果是一个正整数M,表示从命令开始执行,到应用完file和pos表示的binlog位置,执行了多少事务
1.如果执行期间,备库同步线程发生异常,则返回NULL
2.如果等待超过N秒,就返回-1
3.如果刚开始执行的时候,就发现已经执行过这个位置了,则返回0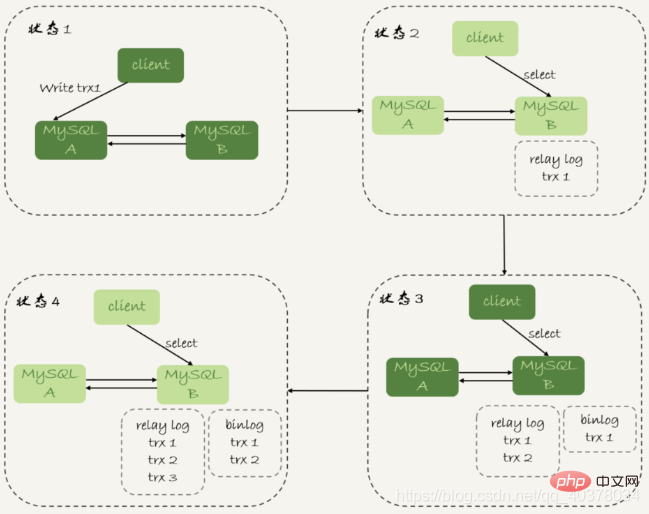
对于上图中先执行trx1,再执行一个查询请求的逻辑,要保证能够查到正确的数据,可以使用这个逻辑:
1.trx1事务更新完成后,马上执行show master status得到当前主库执行到的File和Position
2.选定一个从库执行查询语句
3.在从库上执行select master_pos_wait(file, pos, 1)
4.如果返回值是>=0的正整数,则在这个从库执行查询语句
5.否则,到主库执行查询语句
流程如下:
select wait_for_executed_gtid_set(gtid_set, 1);
这条命令的逻辑如下:
1.等待,直到这个库执行的事务中包含传入的gtid_set,返回0
2.超时返回1
等主库位点方案中,执行完事务后,还要主动去主库执行show master status。而MySQL5.7.6版本开始,允许在执行完更新类事务后,把这个事务的GTID返回给客户端,这样等GTID的方案可以减少一次查询
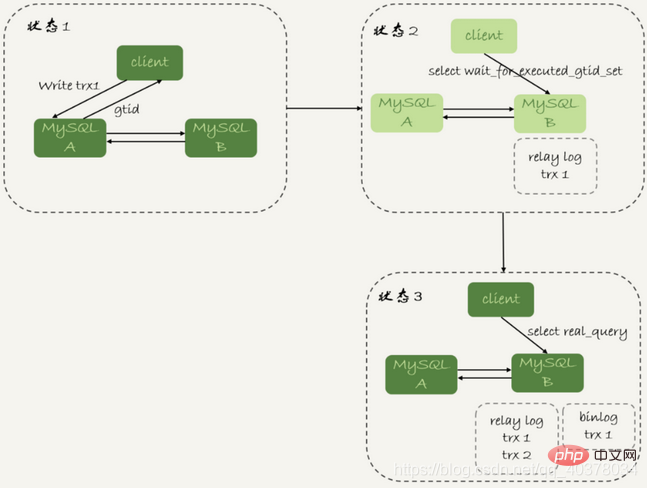
等GTID的流程如下:
1.trx1事务更新完成后,从返回包直接获取这个事务的GTID,记为gtid1
2.选定一个从库执行查询语句
3. Führen Sie select wait_for_executed_gtid_set(gtid1, 1);
4 aus. Wenn der Rückgabewert 0 ist, führen Sie die Abfrageanweisung in dieser Slave-Bibliothek aus.
 Weitere Programmierkenntnisse finden Sie unter:
Weitere Programmierkenntnisse finden Sie unter:
Das obige ist der detaillierte Inhalt vonErfahren Sie mehr über die Master-Standby-, Master-Slave- und Lese-Schreib-Trennung in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen







![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



