
select id%10 as m, count(*) as c from t1 group by m;
 Datenbank
MySQL-Tutorial
Detaillierte Erläuterung der Anweisungen count(), union() und group by in MySQL
Datenbank
MySQL-Tutorial
Detaillierte Erläuterung der Anweisungen count(), union() und group by in MySQL
Detaillierte Erläuterung der Anweisungen count(), union() und group by in MySQL

Dieser Artikel führt Sie durch count(), Union() und Group-by-Anweisungen und ergänzt MySQL-Wissenspunkte (die Verwendung verschiedener count()-, Union-Ausführungsprozesse, Group-by-Anweisungen).

1. Verschiedene Verwendungen von count() in MySQL
count() ist eine Aggregatfunktion. Die zurückgegebene Ergebnismenge wird zeilenweise beurteilt. Wenn der Parameter der Zählfunktion nicht NULL ist, wird die Summe ermittelt Wert wird 1 addiert, andernfalls nicht addieren. Abschließend wird der kumulative Wert zurückgegeben. [Verwandte Empfehlungen: MySQL-Video-Tutorial]
1 Für count (Primärschlüssel-ID) durchläuft die InnoDB-Engine die gesamte Tabelle, entnimmt den ID-Wert jeder Zeile und gibt ihn an die Serverebene zurück. Nachdem die Serverschicht die ID erhalten hat, beurteilt sie, dass sie nicht leer sein darf, und akkumuliert sie daher zeilenweise
2. Für count(1) durchläuft die InnoDB-Engine die gesamte Tabelle, nimmt jedoch keinen Wert an. Die Serverschicht fügt in jede zurückgegebene Zeile eine Zahl ein. Es wird davon ausgegangen, dass sie nicht leer sein darf, und wird in Zeile 3 akkumuliert. Wenn dieses Feld nicht als Null definiert ist, wird dieses Feld zeilenweise gelesen Beurteilen Sie den Datensatz, dass er nicht null sein kann, und akkumulieren Sie ihn zeilenweise. Wenn die Felddefinition Null zulässt, wird bei der Ausführung beurteilt, dass er möglicherweise null ist, und der Wert muss herausgenommen und beurteilt werden, um festzustellen, ob dies der Fall ist nicht null. Akkumulieren
4. Für
darf es nicht null sein. Akkumulieren nach Zeilecount(*)来说,并不会把全部字段取出来,而是专门做了优化。不取值,count(*)
 2. Union-Ausführungsprozess
2. Union-Ausführungsprozess
Um die quantitative Analyse zu erleichtern, nehmen Sie die folgende Tabelle t1 als Beispiel create table t1(id int primary key, a int, b int, index(a));
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
ENDNach dem Login kopierenanalysieren Sie die folgende SQL-Anweisung: Die Semantik von
create table t1(id int primary key, a int, b int, index(a));
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
END(select 1000 as f) union (select id from t1 order by id desc limit 2);
union besteht darin, die Ergebnisse dieser beiden Unterabfragen zu vereinen. Die Vereinigung bedeutet, dass die beiden Sätze addiert werden und nur eine Zeile doppelter Zeilen erhalten bleibt
key=PRIMARY in der zweiten Zeile, was darauf hinweist, dass die zweite Klausel das Index-ID
- 1 Diese temporäre Tabelle enthält nur ein ganzzahliges Feld , und f ist das Primärschlüsselfeld
- 2. Führen Sie die erste Unterabfrage aus und erhalten Sie den Wert 1000
Erhalten Sie die erste Zeilen-ID = 1000 und versuchen Sie, sie in die temporäre Tabelle einzufügen. Da jedoch der Wert 1000 bereits in der temporären Tabelle vorhanden ist, was gegen die Eindeutigkeitsbeschränkung verstößt, schlägt das Einfügen fehl und die Ausführung wird fortgesetzt
Die zweite Zeilen-ID = 999 wird erhalten und das Einfügen in die temporäre Tabelle ist erfolgreich
4. Drücken Sie aus der temporären Tabelle. Nehmen Sie die Daten Zeile für Zeile heraus, geben Sie das Ergebnis zurück und löschen Sie die temporäre Tabelle. Das Ergebnis enthält zwei Datenzeilen, nämlich 1000 und 999- Die temporäre Speichertabelle spielt hier ab Rolle der temporären Speicherung von Daten, und der Berechnungsprozess verwendet auch die temporäre Tabelle. Die Eindeutigkeitsbeschränkung der Primärschlüssel-ID implementiert die Semantik von Union
Wenn die Union in der obigen Anweisung in Union All geändert wird, gibt es keine Semantik von Deduplizierung. Bei dieser Ausführung werden die Unterabfragen nacheinander ausgeführt und die erhaltenen Ergebnisse werden als Teil der Ergebnismenge direkt an den Client gesendet. Daher ist keine temporäre Tabelle erforderlich

Das Feld „Extra“ in der zweiten Zeile zeigt „Index verwenden“, was bedeutet, dass nur der abdeckende Index verwendet wird und die temporäre Tabelle nicht verwendet wird
3 Erklärung der Gruppierung nach Anweisung
1, Gruppierung nach Ausführungsprozess
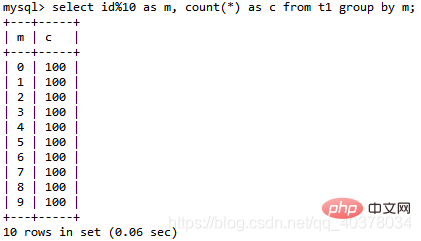
Verwenden Sie weiterhin die obige Tabelle t1, um die folgende SQL-Anweisung zu analysieren: select id%10 as m, count(*) as c from t1 group by m;
Nach dem Login kopieren
Die Logik dieser Anweisung besteht darin, die Daten in Tabelle t1 entsprechend zu gruppieren id%10 und führen Sie Statistiken gemäß dem Ergebnis von m durch. Ausgabe nach der Sortierung. Das Erklärungsergebnis lautet wie folgt: select id%10 as m, count(*) as c from t1 group by m;
Im Extra-Feld können Sie drei Informationen sehen:
Index verwenden, was bedeutet, dass diese Anweisung einen abdeckenden Index verwendet, Index a auswählt und nicht zurückgegeben werden muss Die Tabelle
Die Verwendung einer temporären Tabelle 
Die Verwendung von Dateisortierung bedeutet, dass eine Sortierung erforderlich ist
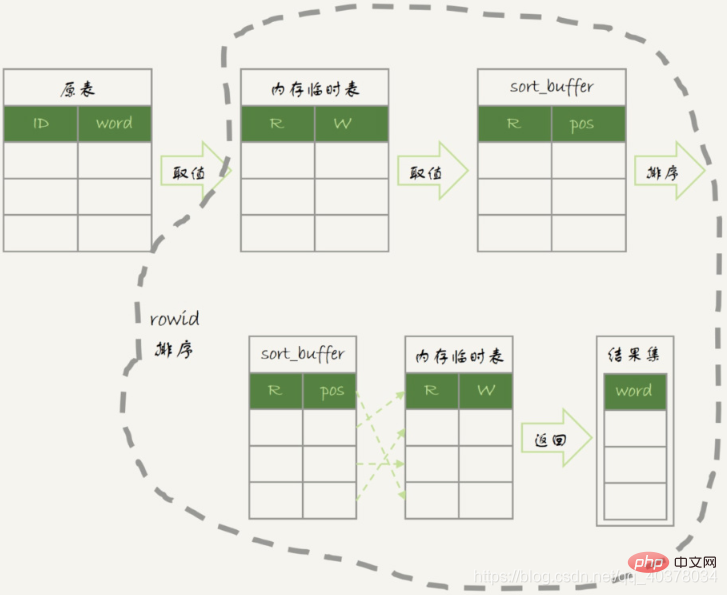
- Der Ausführungsablauf dieser Anweisung ist wie folgt:
- 1 Erstellen Sie eine temporäre Tabelle im Speicher m und c in der Tabelle, und der Primärschlüssel ist m
- 2. Scannen Sie Tabelle t1, indizieren Sie a, nehmen Sie nacheinander den ID-Wert auf dem Blattknoten heraus, berechnen Sie das Ergebnis von id%10 und zeichnen Sie es als auf Zeile mit dem Primärschlüssel x, addieren Sie 1 zum c-Wert der Zeile
内存临时表排序流程图:

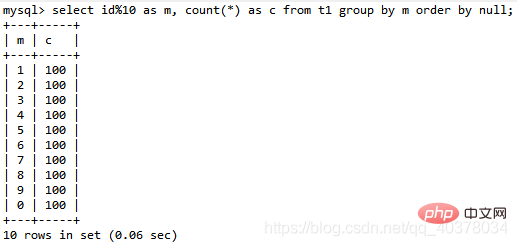
如果并不需要对结果进行排序,在SQL语句末尾增加order by null:
select id%10 as m, count(*) as c from t1 group by m order by null;
Nach dem Login kopieren由于表t1中的id值是从1开始的,因此返回的结果集中第一行是id=1
这个例子里由于临时表只有10行,内存可以放得下,因此全程只使用了内存临时表。但是,内存临时表的大小是有限的,参数tmp_table_size就是控制整个内存大小的,默认是16M
set tmp_table_size=1024; select id%100 as m, count(*) as c from t1 group by m order by null limit 10;
Nach dem Login kopieren把内存临时表的大小限制为最大1024字节,并把语句改成id%100,这样返回结果里有100行数据。但是,这时的内存临时表大小不够存下这100行数据,也就是说,执行过程中会发现内存临时表大小达到了上限。那么,这时候会把内存临时表转成磁盘临时表,磁盘临时表默认使用的引擎是InnoDB
2、group by优化方法——索引
group by的语义逻辑,是统计不同的值的个数。但是,由于每一行的id%100的结果是无序的,所以就需要有一个临时表来记录并统计结果。那么,如果扫描过程中可以保证出现的数据是有序的就可以了
假设,现在有一个类似下图的这么一个数据结构
如果可以确保输入的数据是有序的,那么计算group by的时候,就只需要从左到右,顺序扫描,依次累加。也就是下面这个流程:- 当碰到第一个1的时候,已经知道累积了X个0,结果集里的第一行就是(0,X)
- 当碰到第一个2的时候,已经知道累积了Y个1,结果集里的第一行就是(1,Y)
按照这个逻辑执行的话,扫描到整个输入的数据结束,就可以拿到group by的结果,不需要临时表,也需要再额外排序
在MySQL5.7版本支持了generated column机制,用来实现列数据的关联更新。创建一个列z,在z列上创建一个索引
alter table t1 add column z int generated always as(id % 100), add index(z);
Nach dem Login kopieren这样,索引z上的数据就是有序的了。group by语句就可以改成:
select z, count(*) as c from t1 group by z;
Nach dem Login kopieren
从这个Extra字段可以看到,这个语句的执行不再需要临时表,也不需要排序了3、group by优化方法——直接排序
在group by语句中加入SQL_BIG_RESULT这个提示,就可以告诉优化器:这个语句涉及的数据量很大,直接用磁盘临时表。因为磁盘临时表是B+树存储,存储效率不如数组来得高。所以MySQL优化器直接用数组来存
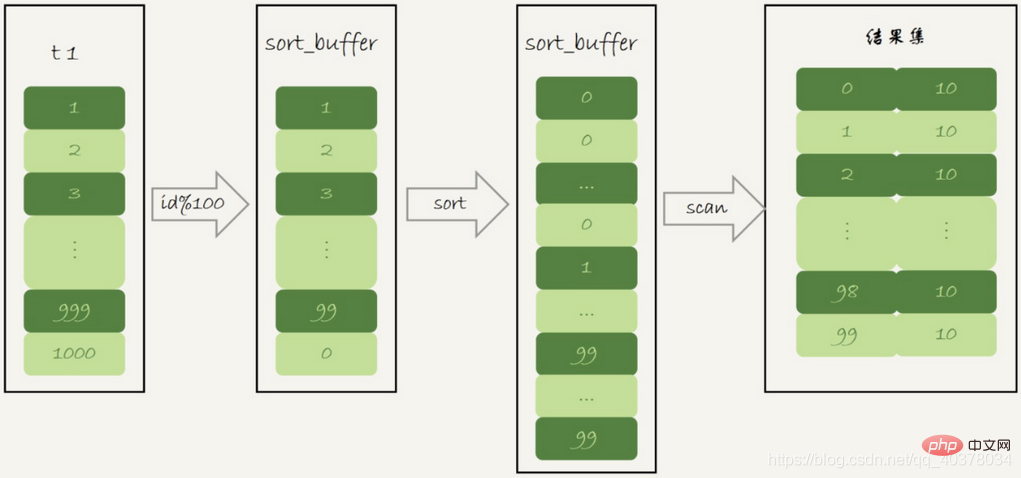
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
Nach dem Login kopieren1.初始化sort_buffer,确定放入一个整型字段,记为m
2.扫描表t1的索引a,依次取出里面的id值,将id%100的值存入sort_buffer中
3.扫描完成后,对sort_buffer的字段m做排序(如果sort_buffer内存不够用,就会利用磁盘临时文件辅助排序)
4.排序完成后,就得到了一个有序数组
根据有序数组,得到数组里面的不同值,以及每个值的出现次数
这个语句的执行没有再使用临时表,而是直接用了排序算法更多编程相关知识,请访问:编程入门!!
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Anweisungen count(), union() und group by in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!


,%20union()%20und%20group%20by%20in%20MySQL)

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Eine effektive Überwachung von Redis -Datenbanken ist entscheidend für die Aufrechterhaltung einer optimalen Leistung, die Identifizierung potenzieller Engpässe und die Gewährleistung der Zuverlässigkeit des Gesamtsystems. Redis Exporteur Service ist ein leistungsstarkes Dienstprogramm zur Überwachung von Redis -Datenbanken mithilfe von Prometheus. In diesem Tutorial führt Sie die vollständige Setup und Konfiguration des Redis -Exporteur -Dienstes, um sicherzustellen, dass Sie nahtlos Überwachungslösungen erstellen. Durch das Studium dieses Tutorials erhalten Sie voll funktionsfähige Überwachungseinstellungen
