

Was ist Javascript-Hash?

In JavaScript bezieht sich Hash auf eine Hash-Tabelle, bei der es sich um eine Datenstruktur handelt, die basierend auf Schlüsselwörtern direkt auf den Speicherort zugreift. Über die Hash-Tabelle wird eine bestimmte Beziehung zwischen dem Speicherort des Datenelements und dem Schlüsselwort hergestellt Das Datenelement ist eine entsprechende Beziehung und die Funktion, die diese entsprechende Beziehung herstellt, wird als Hash-Funktion bezeichnet.

Die Betriebsumgebung dieses Tutorials: Windows 7-System, JavaScript-Version 1.8.5, Dell G3-Computer.
Grundkonzept von Javascript-Hash:
Hash-Tabelle (Hash-Tabelle) ist eine Datenstruktur, die anhand von Schlüsselwörtern, dem Speicherort der Datenelemente und dem Speicherort direkt auf den Speicherort zugreift der Datenelemente Es wird eine bestimmte Entsprechung zwischen Schlüsselwörtern hergestellt, und die Funktion, die diese Entsprechung herstellt, wird Hash-Funktion genannt. 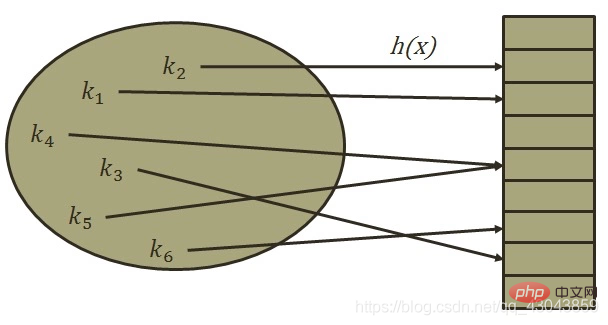
So erstellen Sie eine Hash-Tabelle:
Nehmen Sie an, dass die Anzahl der zu speichernden Datenelemente n beträgt, legen Sie eine kontinuierliche Speichereinheit mit einer Länge von m (m > n) fest und verwenden Sie für jedes das Schlüsselwort Ki ( Datenelement) 0
Aus mathematischer Sicht handelt es sich bei der Hash-Funktion tatsächlich um eine Zuordnung von Schlüsselwörtern zu Speichereinheiten. Daher hoffen wir, dass die von der Hash-Funktion berechnete Huaxi-Adresse durch eine möglichst einfache Operation einem Ort zugeordnet werden kann In einer Reihe von Speichereinheiten gibt es drei Schlüsselpunkte beim Aufbau einer Hash-Funktion: (1) Der Operationsprozess sollte so einfach und effizient wie möglich sein, um die Einfügungs- und Abrufeffizienz der Hash-Tabelle zu verbessern Die Funktion sollte einen guten Hash-Typ haben. Um die Wahrscheinlichkeit einer Hash-Kollision zu verringern, sollte die Hash-Funktion drittens eine stärkere Komprimierung aufweisen, um Speicher zu sparen.
Häufig verwendete Methoden:
- Direkte Adressmethode: Verwenden Sie einen bestimmten linearen Funktionswert des Schlüsselworts als Hash-Adresse, der als Hash (K) = aK + C ausgedrückt werden kann. Der Vorteil besteht darin, dass es keinen Konflikt gibt , aber der Nachteil ist die räumliche Komplexität Kann höher sein, geeignet für Fälle mit weniger Elementen.
- Division mit Rest-Methode: Es handelt sich um die Hash-Adresse, die durch Division des Datenelementschlüsselworts durch eine bestimmte Konstante übrig bleibt. Diese Methode ist einfach zu berechnen und hat ein breites Anwendungsspektrum. Sie ist eine häufig verwendete Hash-Funktion und kann verwendet werden ausgedrückt als :
hash(K=K mod C; Der Schlüssel zu dieser Methode ist die Auswahl der Konstante. Die allgemeine Anforderung besteht darin, dass sie nahe oder gleich der Länge der Hash-Tabelle selbst ist. Die Forschungstheorie zeigt, dass die Konstante Funktioniert am besten bei der Auswahl von Primzahlen - Digitale Analysemethode: Bei dieser Methode werden einige Zahlen mit relativ einheitlichen Werten in den Schlüsselwörtern der Datenelemente als Hash-Adresse verwendet. Dadurch können Konflikte weitestgehend vermieden werden, diese Methode ist es jedoch Nur für Situationen geeignet, in denen alle Schlüsselwörter bekannt sind. Die allgemeinere Hash-Tabelle ist nicht anwendbar.
- Quadratsummenmethode: Konvertieren Sie die aktuelle Zeichenfolge in einen Unicode-Wert und ermitteln Sie das Quadrat dieses Werts Ziffern des quadrierten Werts sind die Hash-Werte der aktuellen Zahl. Konkret hängt die Anzahl der Bits von der Größe der aktuellen Hash-Tabelle ab.
- Segmentierte Summenmethode: Teilen Sie den einzufügenden Wert in mehrere Segmente auf Anzahl der Ziffern in der aktuellen Hash-Tabelle, addieren Sie die Segmente und verwerfen Sie das höchste Bit des Ergebnisses. Dies ist der Hash-Wert dieses Werts Problem: Für zwei verschiedene Schlüsselwörter wird die Hash-Adresse über unsere Hash-Funktion berechnet. Wenn dieselbe Hash-Adresse erhalten wird, nennen wir dieses Phänomen einen Hash-Konflikt ) Füllfaktor, der sich auf den Füllfaktor bezieht, der sich auf das Verhältnis der Anzahl der in der Hash-Tabelle gespeicherten Datenelemente zur Größe des Hash-Adressraums bezieht. Je kleiner a, desto geringer ist die Wahrscheinlichkeit eines Konflikts. Im Gegenteil, die Wahrscheinlichkeit eines Konflikts ist größer. Je kleiner die Raumnutzung, desto kleiner die Raumnutzung. Je größer a, desto höher ist die Raumnutzung normalerweise zwischen 0,6 und 0,9 gesteuert, während HashTable in .net direkt den Maximalwert von a als 0,72 definiert (Obwohl Microsofts offizielles MSDN angibt, dass der Standardfüllfaktor von HashTable 1,0 beträgt, handelt es sich tatsächlich um ein Vielfaches von 0,72) (2) Es hängt mit der verwendeten Hash-Funktion zusammen. Sie können die Hash-Adressen so gleichmäßig wie möglich im Hash-Adressraum verteilen, wodurch das Auftreten von Konflikten verringert wird. Der Erwerb einer guten Hash-Funktion hängt jedoch weitgehend davon ab viel Übung
1) Offene Adressierungsmethode
Hi=(H(key) + di) MOD m i=1,2,…k(k Wobei H(key) der Hash ist Funktion; m ist die Länge der Hash-Tabelle; di ist eine inkrementelle Sequenz. Es gibt 3 inkrementelle Sequenzen:
①Lineare Erkennung und dann Hashing: di=1,2,3,…,m-1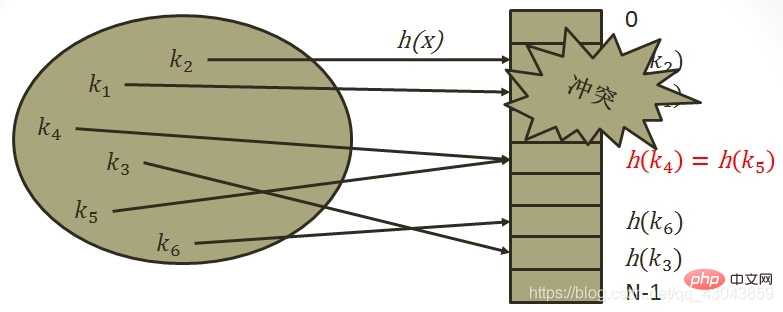 ②Sekundäre Erkennung und dann Hashing: di=1
②Sekundäre Erkennung und dann Hashing: di=1
2,-1
2,-2
2,…±k^2(k ③Pseudozufallserkennung und anschließendes Hashing: di=PseudozufallszahlenfolgeNachteile:
Wir können ein Phänomen beobachten: Wenn Datensätze bereits an den Positionen i, i+1 und i+2 in der Tabelle ausgefüllt sind, werden die Datensätze mit den nächsten Hash-Adressen von i, i+1, i+2 und i+ angezeigt 3 sind alle Die Position von i+3 wird ausgefüllt. Dieses Phänomen, bei dem zwei Datensätze mit unterschiedlichen ersten Hash-Adressen um dieselbe nachfolgende Hash-Adresse konkurrieren, das während der Konfliktverarbeitung auftritt, wird als „sekundäre Aggregation“ bezeichnet, d. h. bei der Verarbeitung von Synonymen In Dem Konfliktprozess kommen nicht-synonyme Konflikte hinzu. Andererseits kann durch die Verwendung linearer Erkennung und anschließendes Hashing zur Bewältigung von Konflikten sichergestellt werden, dass immer eine Adresse Hk gefunden werden kann, die keinen Konflikt verursacht, solange die Hash-Tabelle nicht voll ist. Eine sekundäre Erkennung und Wiederaufbereitung ist nur möglich, wenn die Hash-Tabellenlänge m eine Primzahl der Form 4j+3 ist (j ist eine ganze Zahl). Das heißt, die offene Adressierungsmethode führt zu einer sekundären Aggregation, was sich nachteilig auf die Suche auswirkt.
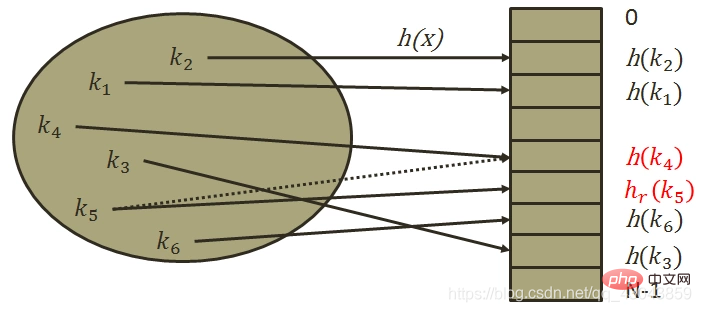
2) Re-Hash-Methode
Hi = RHi (Schlüssel), i=1,2,...k RHi sind alle verschiedene Hash-Funktionen, das heißt, wenn Synonyme Adresskonflikte verursachen, wird die Adresse eines anderen Hashs verwendet Die Funktion wird berechnet, bis keine Konflikte mehr auftreten. Diese Methode ist weniger anfällig für Aggregation, erhöht jedoch die Berechnungszeit.
Nachteile: Erhöhte Berechnungszeit.
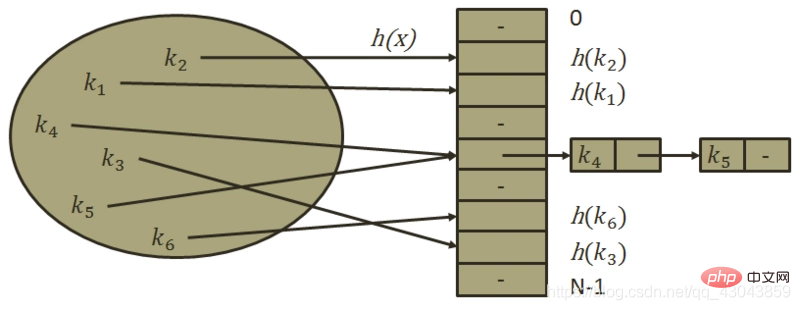
3) Kettenadressmethode (Zipper-Methode)
Speichert alle Datensätze, deren Schlüsselwörter Synonyme sind, in derselben linear verknüpften Liste.
Vorteile:
①Die Zipper-Methode ist einfach mit Konflikten umzugehen und weist kein Akkumulationsphänomen auf, d Die Reißverschlussmethode wird dynamisch angewendet und eignet sich daher besser für Situationen, in denen die Tabellenlänge vor dem Erstellen der Tabelle nicht bestimmt werden kann.
③ Um Konflikte zu reduzieren, erfordert die offene Adressierungsmethode einen kleinen Füllfaktor α Wenn die Größe groß ist, wird viel Platz verschwendet. Bei der Zipper-Methode ist α ≥ 1 akzeptabel, und wenn der Knoten groß ist, ist die in der Zipper-Methode hinzugefügte Zeigerdomäne vernachlässigbar, wodurch Platz gespart wird
④ In einer mit der Zipper-Methode erstellten Hash-Tabelle wird der Vorgang zum Löschen von Knoten ausgeführt ist einfach umzusetzen. Löschen Sie einfach den entsprechenden Knoten in der verknüpften Liste. Bei der mit der offenen Adressmethode erstellten Hash-Tabelle kann beim Löschen eines Knotens der Speicherplatz des gelöschten Knotens nicht einfach leer bleiben, da sonst der Suchpfad des Synonymknotens, der in die Hash-Tabelle eingefügt wird, abgeschnitten wird. Dies liegt daran, dass bei verschiedenen offenen Adressmethoden leere Adresseinheiten (d. h. offene Adressen) Bedingungen für einen Suchfehler sind. Wenn daher ein Löschvorgang für eine Hash-Tabelle ausgeführt wird, der die offene Adressmethode zur Konfliktbehandlung verwendet, kann der gelöschte Knoten nur zum Löschen markiert, der Knoten jedoch nicht tatsächlich gelöscht werden.
class Hash {
constructor() {
this.table = new Array(1024);
}
hash(data) {
//就将字符串中的每个字符的ASCLL码值相加起来,再对数组的长度取余
var total = 0;
for (var i = 0; i < data.length; i++) {
total += data.charCodeAt(i);
}
console.log("Hash Value: " + data + " -> " + total);
return total % this.table.length;
}
insert(key, val) {
var pos = this.hash(key);
this.table[pos] = val;
}
get(key) {
var pos = this.hash(key);
return this.table[pos]
}
show() {
for (var i = 0; i < this.table.length; i++) {
if (this.table[i] != undefined) {
console.log(i + ":" + this.table[i]);
}
}
}
}
var someNames = ["David", "Jennifer", "Donnie", "Raymond", "Cynthia", "Mike", "Clayton", "Danny", "Jonathan"];
var hash = new Hash();
for (var i = 0; i < someNames.length; ++i) {
hash.insert(someNames[i], someNames[i]);
}
hash.show();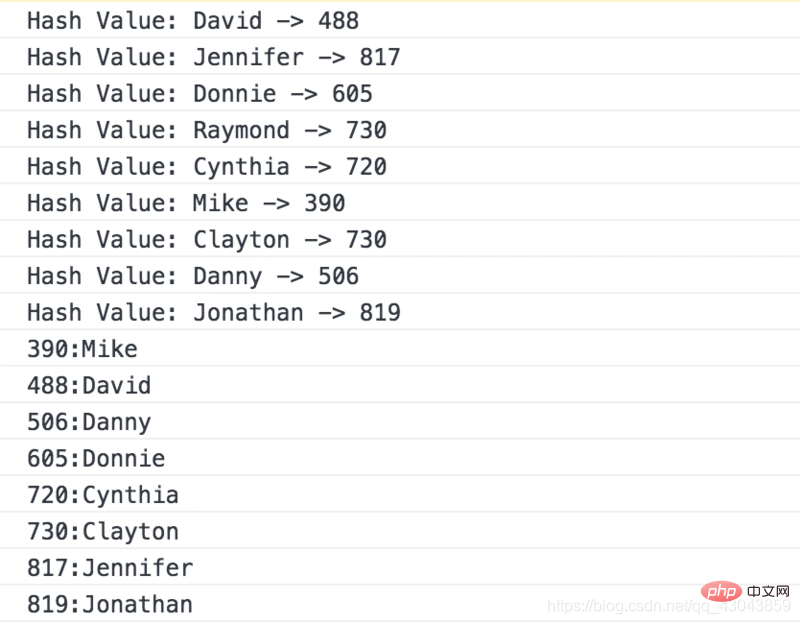 verwendet die quadratische Mid-Step-Methode zum Erstellen der Hash-Funktion und die lineare Erkennungsmethode der offenen Adressmethode zur Lösung von Konflikten.
verwendet die quadratische Mid-Step-Methode zum Erstellen der Hash-Funktion und die lineare Erkennungsmethode der offenen Adressmethode zur Lösung von Konflikten.
class Hash {
constructor() {
this.table = new Array(1000);
}
hash(data) {
var total = 0;
for (var i = 0; i < data.length; i++) {
total += data.charCodeAt(i);
}
//把字符串转化为字符用来求和之后进行平方运算
var s = total * total + ""
//保留中间2位
var index = s.charAt(s.length / 2 - 1) * 10 + s.charAt(s.length / 2) * 1
console.log("Hash Value: " + data + " -> " + index);
return index;
}
solveClash(index, value) {
var table = this.table
//进行线性开放地址法解决冲突
for (var i = 0; index + i < 1000; i++) {
if (table[index + i] == null) {
table[index + i] = value;
break;
}
}
}
insert(key, val) {
var index = this.hash(key);
//把取中当做哈希表中索引
if (this.table[index] == null) {
this.table[index] = val;
} else {
this.solveClash(index, val);
}
}
get(key) {
var pos = this.hash(key);
return this.table[pos]
}
show() {
for (var i = 0; i < this.table.length; i++) {
if (this.table[i] != undefined) {
console.log(i + ":" + this.table[i]);
}
}
}
}
var someNames = ["David", "Jennifer", "Donnie", "Raymond", "Cynthia", "Mike", "Clayton", "Danny", "Jonathan"];
var hash = new Hash();
for (var i = 0; i < someNames.length; ++i) {
hash.insert(someNames[i], someNames[i]);
}
hash.show();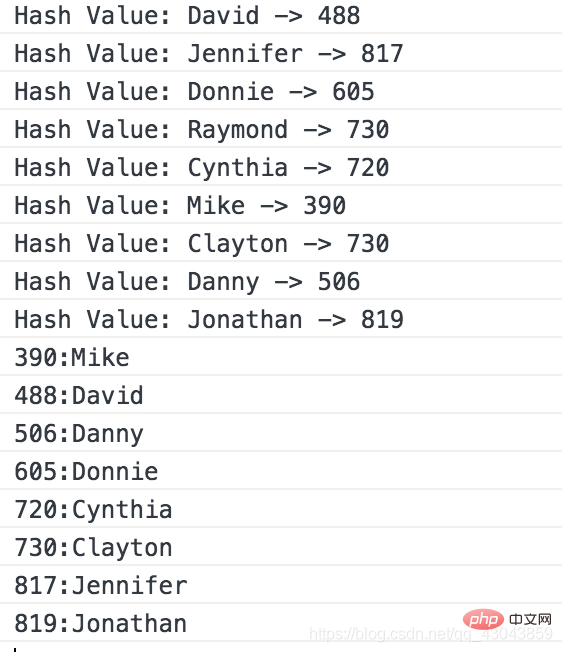
Javascript-Tutorial für Fortgeschrittene】
Das obige ist der detaillierte Inhalt vonWas ist Javascript-Hash?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem. Einführung: Mit der kontinuierlichen Weiterentwicklung der Technologie ist die Spracherkennungstechnologie zu einem wichtigen Bestandteil des Bereichs der künstlichen Intelligenz geworden. Das auf WebSocket und JavaScript basierende Online-Spracherkennungssystem zeichnet sich durch geringe Latenz, Echtzeit und plattformübergreifende Eigenschaften aus und hat sich zu einer weit verbreiteten Lösung entwickelt. In diesem Artikel wird erläutert, wie Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem implementieren.
 WebSocket und JavaScript: Schlüsseltechnologien zur Implementierung von Echtzeitüberwachungssystemen
Dec 17, 2023 pm 05:30 PM
WebSocket und JavaScript: Schlüsseltechnologien zur Implementierung von Echtzeitüberwachungssystemen
Dec 17, 2023 pm 05:30 PM
WebSocket und JavaScript: Schlüsseltechnologien zur Realisierung von Echtzeit-Überwachungssystemen Einführung: Mit der rasanten Entwicklung der Internet-Technologie wurden Echtzeit-Überwachungssysteme in verschiedenen Bereichen weit verbreitet eingesetzt. Eine der Schlüsseltechnologien zur Erzielung einer Echtzeitüberwachung ist die Kombination von WebSocket und JavaScript. In diesem Artikel wird die Anwendung von WebSocket und JavaScript in Echtzeitüberwachungssystemen vorgestellt, Codebeispiele gegeben und deren Implementierungsprinzipien ausführlich erläutert. 1. WebSocket-Technologie
 Verwendung von JavaScript und WebSocket zur Implementierung eines Echtzeit-Online-Bestellsystems
Dec 17, 2023 pm 12:09 PM
Verwendung von JavaScript und WebSocket zur Implementierung eines Echtzeit-Online-Bestellsystems
Dec 17, 2023 pm 12:09 PM
Einführung in die Verwendung von JavaScript und WebSocket zur Implementierung eines Online-Bestellsystems in Echtzeit: Mit der Popularität des Internets und dem Fortschritt der Technologie haben immer mehr Restaurants damit begonnen, Online-Bestelldienste anzubieten. Um ein Echtzeit-Online-Bestellsystem zu implementieren, können wir JavaScript und WebSocket-Technologie verwenden. WebSocket ist ein Vollduplex-Kommunikationsprotokoll, das auf dem TCP-Protokoll basiert und eine bidirektionale Kommunikation zwischen Client und Server in Echtzeit realisieren kann. Im Echtzeit-Online-Bestellsystem, wenn der Benutzer Gerichte auswählt und eine Bestellung aufgibt
 So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript
Dec 17, 2023 am 09:39 AM
So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript
Dec 17, 2023 am 09:39 AM
So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript. Im heutigen digitalen Zeitalter müssen immer mehr Unternehmen und Dienste Online-Reservierungsfunktionen bereitstellen. Es ist von entscheidender Bedeutung, ein effizientes Online-Reservierungssystem in Echtzeit zu implementieren. In diesem Artikel wird erläutert, wie Sie mit WebSocket und JavaScript ein Online-Reservierungssystem implementieren, und es werden spezifische Codebeispiele bereitgestellt. 1. Was ist WebSocket? WebSocket ist eine Vollduplex-Methode für eine einzelne TCP-Verbindung.
 JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems
Dec 17, 2023 pm 05:13 PM
JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems
Dec 17, 2023 pm 05:13 PM
JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems Einführung: Heutzutage ist die Genauigkeit von Wettervorhersagen für das tägliche Leben und die Entscheidungsfindung von großer Bedeutung. Mit der Weiterentwicklung der Technologie können wir genauere und zuverlässigere Wettervorhersagen liefern, indem wir Wetterdaten in Echtzeit erhalten. In diesem Artikel erfahren Sie, wie Sie mit JavaScript und WebSocket-Technologie ein effizientes Echtzeit-Wettervorhersagesystem aufbauen. In diesem Artikel wird der Implementierungsprozess anhand spezifischer Codebeispiele demonstriert. Wir
 So verwenden Sie insertBefore in Javascript
Nov 24, 2023 am 11:56 AM
So verwenden Sie insertBefore in Javascript
Nov 24, 2023 am 11:56 AM
Verwendung: In JavaScript wird die Methode insertBefore() verwendet, um einen neuen Knoten in den DOM-Baum einzufügen. Diese Methode erfordert zwei Parameter: den neuen Knoten, der eingefügt werden soll, und den Referenzknoten (d. h. den Knoten, an dem der neue Knoten eingefügt wird).
 Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
JavaScript-Tutorial: So erhalten Sie HTTP-Statuscode. Es sind spezifische Codebeispiele erforderlich. Vorwort: Bei der Webentwicklung ist häufig die Dateninteraktion mit dem Server erforderlich. Bei der Kommunikation mit dem Server müssen wir häufig den zurückgegebenen HTTP-Statuscode abrufen, um festzustellen, ob der Vorgang erfolgreich ist, und die entsprechende Verarbeitung basierend auf verschiedenen Statuscodes durchführen. In diesem Artikel erfahren Sie, wie Sie mit JavaScript HTTP-Statuscodes abrufen und einige praktische Codebeispiele bereitstellen. Verwenden von XMLHttpRequest
 So erhalten Sie auf einfache Weise HTTP-Statuscode in JavaScript
Jan 05, 2024 pm 01:37 PM
So erhalten Sie auf einfache Weise HTTP-Statuscode in JavaScript
Jan 05, 2024 pm 01:37 PM
Einführung in die Methode zum Abrufen des HTTP-Statuscodes in JavaScript: Bei der Front-End-Entwicklung müssen wir uns häufig mit der Interaktion mit der Back-End-Schnittstelle befassen, und der HTTP-Statuscode ist ein sehr wichtiger Teil davon. Das Verstehen und Abrufen von HTTP-Statuscodes hilft uns, die von der Schnittstelle zurückgegebenen Daten besser zu verarbeiten. In diesem Artikel wird erläutert, wie Sie mithilfe von JavaScript HTTP-Statuscodes erhalten, und es werden spezifische Codebeispiele bereitgestellt. 1. Was ist ein HTTP-Statuscode? HTTP-Statuscode bedeutet, dass der Dienst den Dienst anfordert, wenn er eine Anfrage an den Server initiiert
