
 Datenbank
MySQL-Tutorial
Beherrschen Sie die Indizierungsfähigkeiten von MySQL vollständig (Zusammenfassungsfreigabe).
Datenbank
MySQL-Tutorial
Beherrschen Sie die Indizierungsfähigkeiten von MySQL vollständig (Zusammenfassungsfreigabe).
Beherrschen Sie die Indizierungsfähigkeiten von MySQL vollständig (Zusammenfassungsfreigabe).

Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL-Indizes, einschließlich der logischen Struktur von MySQL und SQL-Ausführungsanweisungen. Ich hoffe, dass er Ihnen hilfreich sein wird.

1. Dreistufige logische MySQL-Architektur
Die Speicher-Engine-Architektur von MySQL trennt die Abfrageverarbeitung von der Datenspeicherung/-abfrage. Das Folgende ist das logische Architekturdiagramm von MySQL:

1 Die erste Schicht ist für die Verbindungsverwaltung, Autorisierungsauthentifizierung, Sicherheit usw. verantwortlich.
Jede Client-Verbindung entspricht einem Thread auf dem Server. Auf dem Server wird ein Thread-Pool verwaltet, um zu vermeiden, dass für jede Verbindung ein Thread erstellt und zerstört wird. Wenn ein Client eine Verbindung zu einem MySQL-Server herstellt, wird er vom Server authentifiziert. Die Authentifizierung kann über Benutzername und Passwort oder über ein SSL-Zertifikat erfolgen. Nachdem die Anmeldeauthentifizierung bestanden wurde, überprüft der Server auch, ob der Client berechtigt ist, eine bestimmte Abfrage auszuführen.
2. Die zweite Ebene ist dafür verantwortlich, die Abfrage zu analysieren, SQL zu kompilieren und zu optimieren (z. B. die Lesereihenfolge der Tabelle anzupassen, geeignete Indizes auszuwählen usw.). Bei SELECT-Anweisungen überprüft der Server vor dem Parsen der Abfrage zunächst den Abfragecache. Wenn das entsprechende Abfrageergebnis darin gefunden werden kann, wird das Abfrageergebnis direkt zurückgegeben, ohne dass eine Abfrageanalyse, Optimierung usw. erforderlich ist. Gespeicherte Prozeduren, Trigger, Ansichten usw. werden alle in dieser Ebene implementiert.
3. Die dritte Schicht ist die Speicher-Engine
Die Speicher-Engine ist für das Speichern von Daten in MySQL, das Extrahieren von Daten, das Starten einer Transaktion usw. verantwortlich. Die Speicher-Engine kommuniziert mit der oberen Ebene über APIs. Diese APIs schirmen die Unterschiede zwischen verschiedenen Speicher-Engines ab und machen diese Unterschiede für den Abfrageprozess der oberen Ebene transparent. Die Speicher-Engine analysiert SQL nicht.
2. Vergleich zwischen InnoDB und MyISAM1. Speicherstruktur
MyISAM wird als drei Dateien auf der Festplatte gespeichert. Dies sind: Tabellendefinitionsdateien, Datendateien und Indexdateien. Der Name der ersten Datei beginnt mit dem Namen der Tabelle und die Erweiterung gibt den Dateityp an. .frm-Dateien speichern Tabellendefinitionen. Die Datendateierweiterung ist .MYD (MYData). Die Erweiterung der Indexdatei ist .MYI (MYIndex).
InnoDB: Alle Tabellen werden in derselben Datendatei (oder mehreren Dateien oder unabhängigen Tabellenbereichsdateien) gespeichert. Die Größe der InnoDB-Tabelle ist nur durch die Größe der Betriebssystemdatei begrenzt, die im Allgemeinen 2 GB beträgt.2. Speicherplatz
MyISAM: MyISAM unterstützt drei verschiedene Speicherformate: statische Tabelle (Standard, aber bitte beachten Sie, dass am Ende der Daten keine Leerzeichen stehen dürfen, diese werden entfernt), dynamische Tabelle und komprimiert Tisch. Nachdem die Tabelle erstellt und die Daten importiert wurden, werden sie nicht mehr geändert. Sie können komprimierte Tabellen verwenden, um den Speicherplatzverbrauch erheblich zu reduzieren.
InnoDB: Benötigt mehr Speicher und Speicherplatz, es wird ein eigener dedizierter Pufferpool im Hauptspeicher zum Zwischenspeichern von Daten und Indizes eingerichtet.3. Portabilität, Sicherung und Wiederherstellung
MyISAM: Daten werden in Form von Dateien gespeichert und sind daher sehr praktisch für die plattformübergreifende Datenübertragung. Während der Sicherung und Wiederherstellung können Sie Vorgänge für eine Tabelle einzeln ausführen.
InnoDB: Zu den kostenlosen Lösungen gehören das Kopieren von Datendateien, das Sichern von Binlog oder die Verwendung von mysqldump, was relativ mühsam ist, wenn das Datenvolumen Dutzende Gigabyte erreicht.4. Transaktionsunterstützung
MyISAM: Der Schwerpunkt liegt auf der Leistung. Jede Abfrage ist atomar und ihre Ausführungszeiten sind schneller als beim InnoDB-Typ, sie bietet jedoch keine Transaktionsunterstützung.
InnoDB: Bietet Transaktionsunterstützung, Fremdschlüssel und andere erweiterte Datenbankfunktionen. Transaktionssichere (ACID-konforme) Tabellen mit Transaktions- (Commit), Rollback- (Rollback) und Crash-Recovery-Funktionen.5. AUTO_INCREMENT
MyISAM: Sie können einen gemeinsamen Index mit anderen Feldern erstellen. Die automatische Wachstumsspalte der Engine muss ein Index sein. Wenn es sich um einen kombinierten Index handelt, muss die automatische Wachstumsspalte nicht die erste Spalte sein. Sie kann nach den vorherigen Spalten sortiert und dann erhöht werden.
InnoDB: InnoDB muss einen Index nur mit diesem Feld enthalten. Die automatisch wachsende Spalte der Engine muss ein Index sein, und wenn es sich um einen zusammengesetzten Index handelt, muss sie auch die erste Spalte des zusammengesetzten Index sein.6. Tabellensperrenunterschiede
MyISAM: Wenn Benutzer Myisam-Tabellen ausführen, wird die Tabelle automatisch gesperrt, wenn die gesperrte Tabelle die Einfügungs-Parallelität erfüllt In diesem Fall können neue Daten am Ende der Tabelle eingefügt werden.
InnoDB: Die Unterstützung von Transaktionen und Sperren auf Zeilenebene ist das größte Merkmal von innodb. Zeilensperren verbessern die Leistung gleichzeitiger Vorgänge mehrerer Benutzer erheblich. Die Zeilensperre von InnoDB gilt jedoch nur für den Primärschlüssel von WHERE, der nicht der Primärschlüssel ist und die gesamte Tabelle sperrt.7. Volltextindex
MyISAM: unterstützt Volltextindex vom Typ FULLTEXT
InnoDB: unterstützt keinen Volltextindex vom Typ FULLTEXT, aber innodb kann das Sphinx-Plug-in verwenden, um Volltext zu unterstützen Index, und der Effekt ist besser.8. Tabellenprimärschlüssel
MyISAM: Ermöglicht die Existenz von Tabellen ohne Indizes und Primärschlüssel. Die Indizes sind die Adressen, in denen Zeilen gespeichert werden.
InnoDB: Wenn kein Primärschlüssel oder nicht leerer eindeutiger Index festgelegt ist, wird automatisch ein 6-Byte-Primärschlüssel (für den Benutzer unsichtbar) generiert. Die Daten sind Teil des Primärindex und der zusätzliche Index speichert den Wert von der Primärindex.
9. Die spezifische Anzahl der Zeilen in der Tabelle
MyISAM: Speichert die Gesamtzahl der Zeilen in der Tabelle. Wenn Sie count() aus der Tabelle auswählen, wird der Wert direkt entnommen.
InnoDB: Die Gesamtzahl der Zeilen in der Tabelle wird nicht gespeichert. Wenn Sie „select count(*) from table“ verwenden, wird die gesamte Tabelle durchlaufen, was jedoch nach dem Hinzufügen der Wehr-Bedingung viel Geld verbraucht. myisam und innodb handhaben es auf die gleiche Weise.
10. CRUD-Operationen
MyISAM: Wenn Sie eine große Anzahl von SELECTs ausführen, ist MyISAM die bessere Wahl.
InnoDB: Wenn Ihre Daten viele INSERT- oder UPDATE-Operationen durchführen, sollten Sie aus Leistungsgründen eine InnoDB-Tabelle verwenden.
11. Fremdschlüssel
InnoDB: Unterstützt
3. Unter welchen Umständen sollte die SQL-Optimierung durchgeführt werden?
Geringe Leistung, zu lange Ausführung Zeit, Wartezeit Zu lang, Verbindungsabfrage, Indexfehler.2. SQL-Anweisungsausführungsprozess
(1) Schreibprozess
select distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit ...
Nach dem Login kopieren
(2) Analyseprozessfrom ... on ... join ... where ... group by ... having ... select distinct ... order by ... limit ...
Nach dem Login kopieren
select distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit ...
from ... on ... join ... where ... group by ... having ... select distinct ... order by ... limit ...
3. Die SQL-Optimierung dient der Optimierung des Index
Der Index entspricht dem Inhaltsverzeichnis des Buches.Die Datenstruktur des Index ist ein B+-Baum. 5. Index Indexbaum Es wird von selbst sortiert, sodass keine erneute Abfrage erforderlich ist, wenn der Index durch nachfolgende Abfragen ausgelöst wird.
2. Nachteile des Index
(1) Der Index selbst ist groß und kann im Speicher oder auf der Festplatte gespeichert werden, normalerweise auf der Festplatte. (2) Indizes werden nicht in allen Situationen verwendet, z. B. ① eine kleine Datenmenge ② sich häufig ändernde Felder ③ selten verwendete Felder(3) Indizes verringern die Effizienz von Hinzufügungen, Löschungen und Änderungen
3. Indexklassifizierung
(1) Einzelwertindex (2) Eindeutiger Index(3) Unionsindex
(4) Primärschlüsselindex Hinweis: Der einzige Unterschied zwischen eindeutigem Index und Primärschlüsselindex: Primärschlüssel Index darf nicht null sein4. Erstellen Sie einen Index
5. MySQL-Indexprinzip –> auf B-Tree, wodurch es besser für die Implementierung einer externen Speicherindexstruktur geeignet ist. Die InnoDB-Speicher-Engine verwendet B+Tree, um ihre Indexstruktur zu implementieren.
Jeder Knoten im B-Tree-Strukturdiagramm enthält nicht nur den Schlüsselwert der Daten, sondern auch den Datenwert. Der Speicherplatz jeder Seite ist begrenzt. Wenn die Datenmenge groß ist, ist die Anzahl der Schlüssel, die in jedem Knoten gespeichert werden können (d. h. eine Seite), sehr gering zu B- Die Tiefe des Baums ist größer, was die Anzahl der Festplatten-E/As während der Abfrage erhöht und sich dadurch auf die Abfrageeffizienz auswirkt. In B+Tree werden alle Datensatzknoten in der Reihenfolge ihres Schlüsselwerts auf Blattknoten gespeichert. Auf Nicht-Blattknoten werden nur Schlüsselwertinformationen gespeichert Knoten. Reduzieren Sie die Höhe von B+Baum.
B+Tree weist im Vergleich zu B-Tree mehrere Unterschiede auf:
Nicht-Blattknoten speichern nur Schlüsselwertinformationen.
Zwischen allen Blattknoten gibt es einen Linkzeiger.Datensätze werden in Blattknoten gespeichert.
Optimieren Sie den B-Baum im vorherigen Abschnitt, da die Nicht-Blattknoten von B + Baum nur Schlüsselwertinformationen speichern. Unter der Annahme, dass jeder Festplattenblock 4 Schlüsselwerte und Zeigerinformationen speichern kann, wird er zur Struktur von B +Baum. Wie in der folgenden Abbildung gezeigt:Normalerweise gibt es in B+Baum zwei Kopfzeiger, einer zeigt auf den Wurzelknoten und der andere zeigt auf den Blattknoten mit dem kleinsten Schlüsselwort, und es gibt eine Art der Beziehung zwischen allen Blattknoten (d. h. Datenknoten). Daher können für B+Tree zwei Suchvorgänge durchgeführt werden: einer ist eine Bereichssuche und eine Paging-Suche nach dem Primärschlüssel und der andere ist eine Zufallssuche ausgehend vom Wurzelknoten.
Vielleicht gibt es im obigen Beispiel nur 22 Datensätze und die Vorteile von B+Tree sind nicht zu erkennen. Hier ist eine Berechnung: 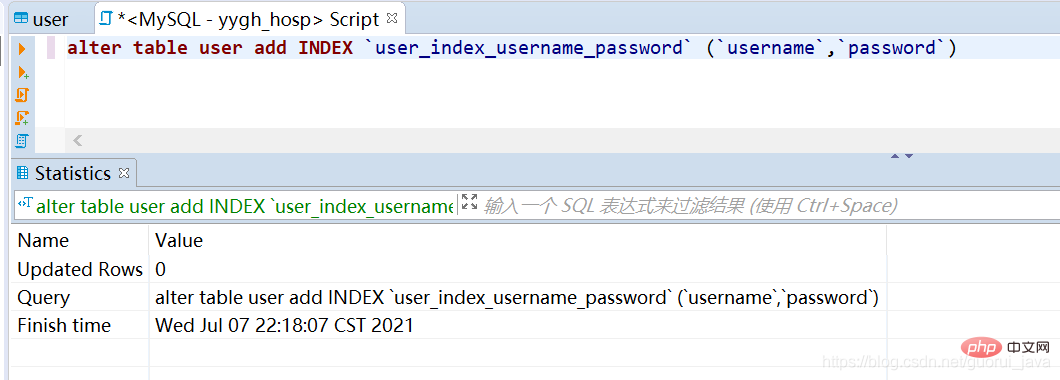
Der B+Tree-Index in der Datenbank kann in Clustered-Index und Sekundärindex unterteilt werden. Das obige B+Tree-Beispieldiagramm ist in der Datenbank als Clustered-Index implementiert. Die Blattknoten im B+Tree des Clustered-Index speichern die Zeilendatensatzdaten der gesamten Tabelle. Der Unterschied zwischen einem Hilfsindex und einem Clustered-Index besteht darin, dass die Blattknoten des Hilfsindex nicht alle Daten des Zeilendatensatzes enthalten, sondern den Clustered-Index-Schlüssel, der die entsprechenden Zeilendaten speichert, also den Primärschlüssel. Beim Abfragen von Daten über einen Sekundärindex durchläuft die InnoDB-Speicher-Engine den Sekundärindex, um den Primärschlüssel zu finden, und findet dann über den Primärschlüssel die vollständigen Zeilendatensatzdaten im Clustered-Index.
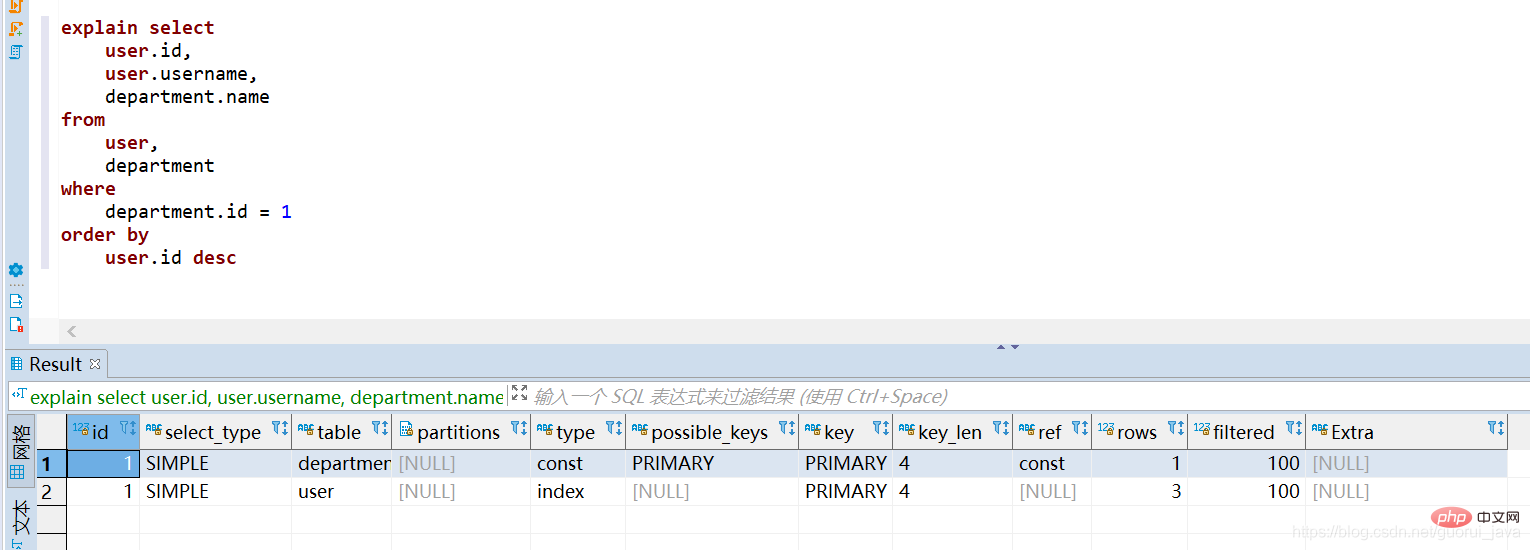
5. So lösen Sie den gemeinsamen Index aus
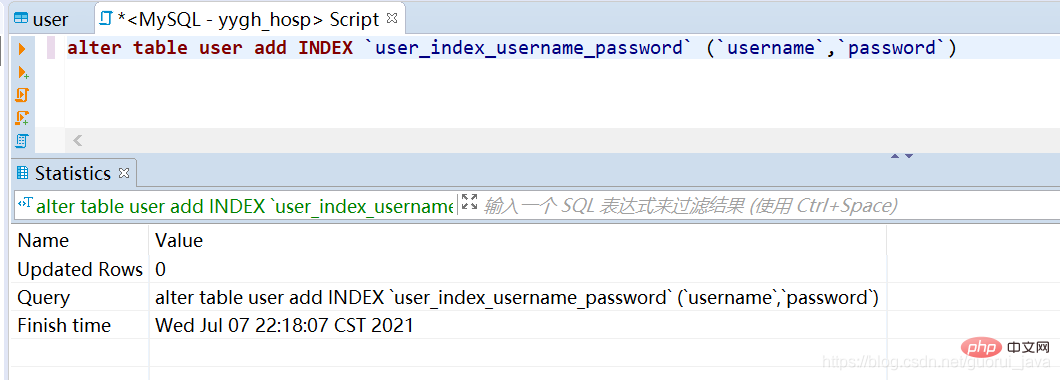
1. Erstellen Sie einen gemeinsamen Index für den Benutzernamen und das Passwort. 2. Lösen Sie den gemeinsamen Index aus. (1) Verwenden Sie alle Indexschlüssel des gemeinsamen Index um den gemeinsamen Index auszulösen Wenn der gemeinsame Index allein verwendet wird, kann der gemeinsame Index ausgelöst werden.
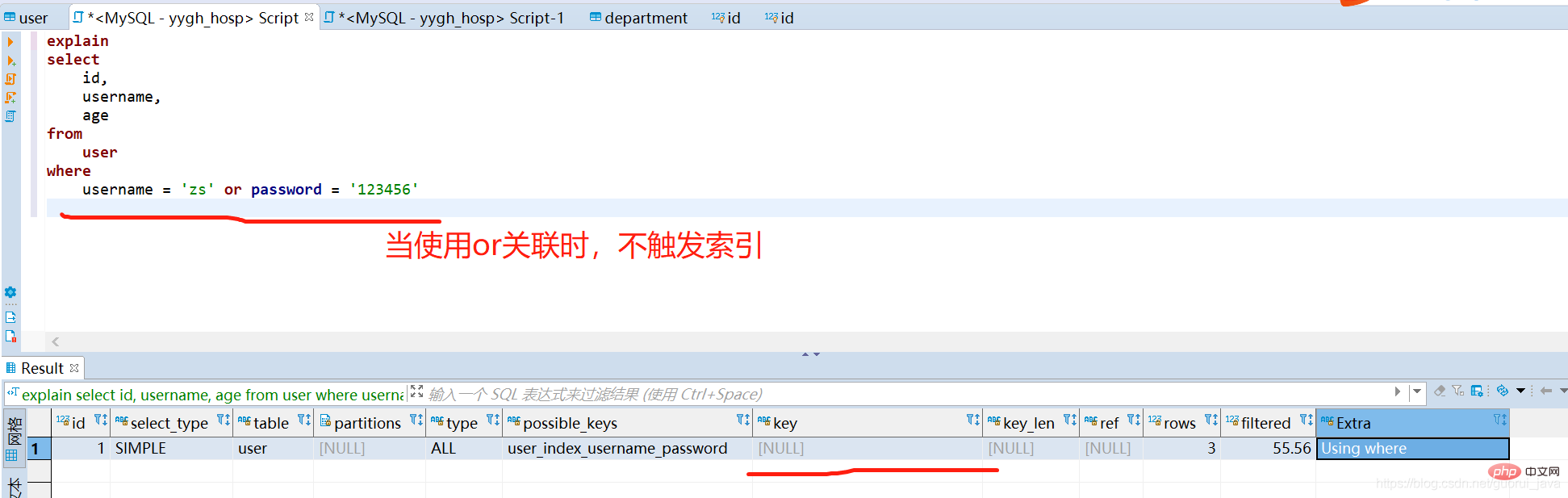
(4) Wenn andere Felder des gemeinsamen Index allein verwendet werden, kann der gemeinsame Index nicht ausgelöst werden. --explain
explain kann SQL simulieren, um die Ausführung von SQL-Anweisungen zu optimieren.
1. Einführung in die Verwendung von EXPLAIN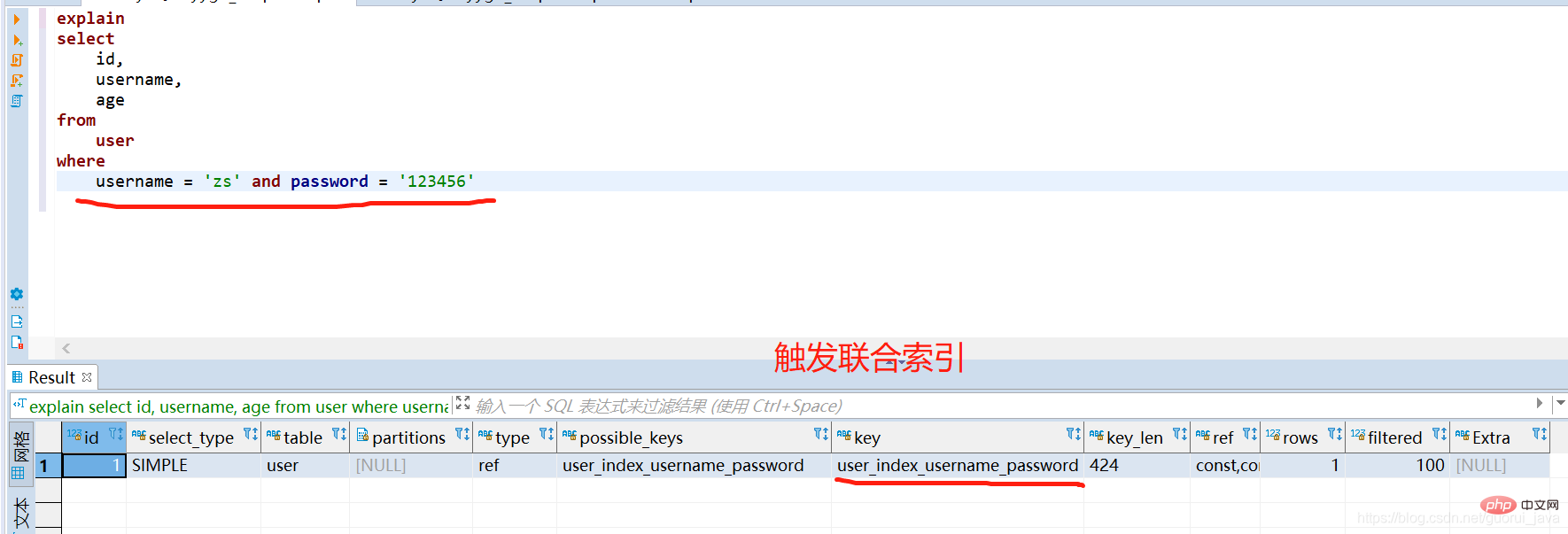


(5) Ergebnisanalyse Die in der ersten Zeile von EXPLAIN angezeigte Tabelle ist die Treibertabelle.
 Wenn die Join-Bedingung angegeben ist, ist die Tabelle mit den wenigen Zeilen, die die Abfragebedingung erfüllen, [Gesteuerte Tabelle]
Wenn die Join-Bedingung angegeben ist, ist die Tabelle mit den wenigen Zeilen, die die Abfragebedingung erfüllen, [Gesteuerte Tabelle]
Wenn die Join-Bedingung nicht angegeben ist, ist die Tabelle mit den wenigen Zeilen [Gesteuerte Tabelle]. ]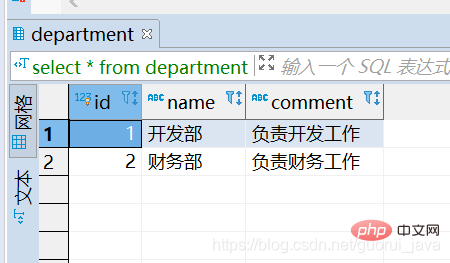
 2. Einführung zur Erläuterung der Abfrageergebnisse
2. Einführung zur Erläuterung der Abfrageergebnisse
(1) id: SELECT-Kennung. Dies ist die Abfragesequenznummer von SELECT.
(2) select_type: SELECT-Typ: 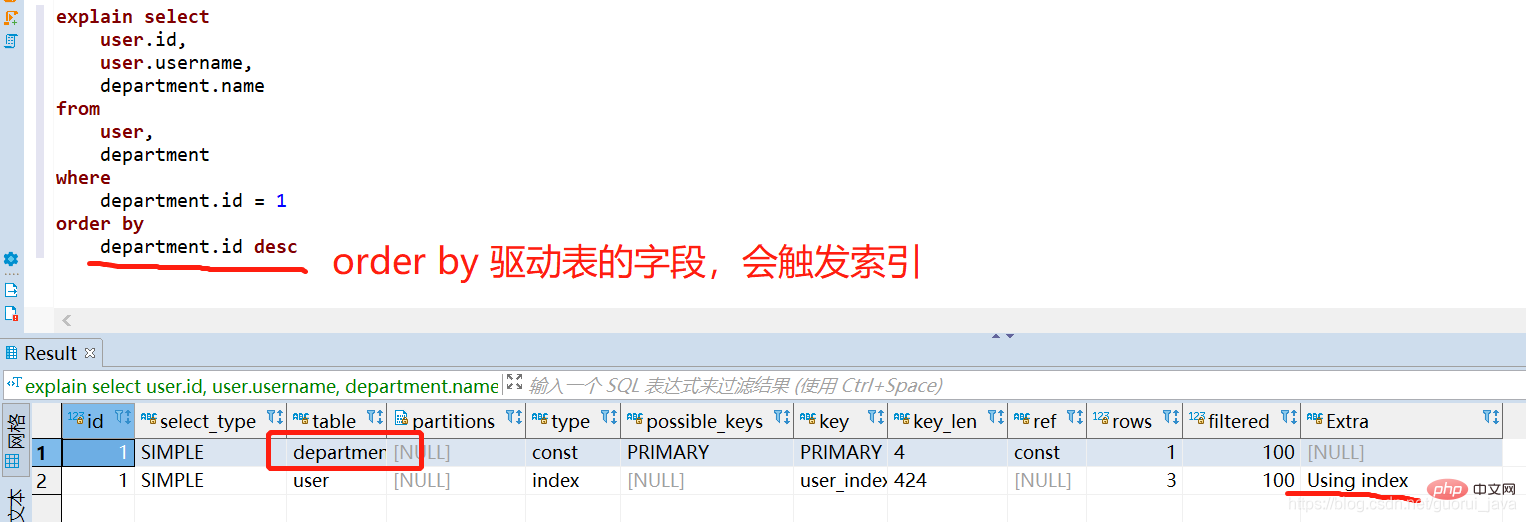
PRIMARY: Äußerstes SELECT
- UNION: Das zweite oder letzte Element in der UNION SELECT-Anweisung
- DEPENDENT UNION: Die zweite oder nachfolgende SELECT-Anweisung in der UNION, abhängig von der äußeren Abfrage
- DEPENDENT UNTERABFRAGE: Das erste SELECT in der Unterabfrage, hängt von der äußeren Abfrage ab
- DERIVED: SELECT der abgeleiteten Tabelle (Unterabfrage der FROM-Klausel)
- (3) Tabelle: Tabellenname (4) Typ: Verbindungstyp
- System: Die Tabelle hat nur eine Zeile (= Systemtabelle). Dies ist ein Sonderfall des const-Join-Typs.
- const: Die Tabelle hat höchstens eine passende Zeile, die zu Beginn der Abfrage gelesen wird. Da es nur eine Zeile gibt, können die Spaltenwerte in dieser Zeile vom Rest des Optimierers als Konstanten behandelt werden. const wird verwendet, wenn alle Teile eines PRIMARY KEY- oder UNIQUE-Index mit einem konstanten Wert verglichen werden.
- eq_ref: Lesen Sie für jede Zeilenkombination aus der vorherigen Tabelle eine Zeile aus dieser Tabelle. Dies ist neben const-Typen wahrscheinlich der beste Join-Typ. Es wird verwendet, wenn alle Teile eines Index im Join verwendet werden und der Index UNIQUE oder PRIMARY KEY ist. eq_ref kann für indizierte Spalten verwendet werden, die mit dem =-Operator verglichen werden. Der Vergleichswert kann eine Konstante oder ein Ausdruck sein, der eine Spalte aus einer Tabelle verwendet, die vor dieser Tabelle gelesen wurde.
- ref: Für jede Zeilenkombination aus der vorherigen Tabelle werden alle Zeilen mit übereinstimmenden Indexwerten aus dieser Tabelle gelesen. Verwenden Sie ref, wenn der Join nur das Präfix ganz links des Schlüssels verwendet oder wenn der Schlüssel nicht UNIQUE oder PRIMARY KEY ist (mit anderen Worten, wenn der Join keine einzelne Zeile basierend auf dem Schlüssel auswählen kann). Dieser Join-Typ eignet sich gut, wenn Sie Schlüssel verwenden, die nur mit einer kleinen Anzahl von Zeilen übereinstimmen. ref kann für indizierte Spalten mit den Operatoren = oder <=> verwendet werden.
- ref_or_null: Dieser Join-Typ ähnelt ref, fügt jedoch MySQL hinzu, um gezielt nach Zeilen zu suchen, die NULL-Werte enthalten. Dieser Join-Optimierungstyp wird häufig zum Lösen von Unterabfragen verwendet.
index_merge: Dieser Join-Typ gibt an, dass die Index-Merge-Optimierungsmethode verwendet wird. In diesem Fall enthält die Schlüsselspalte die Liste der verwendeten Indizes und key_len enthält das längste Schlüsselelement des verwendeten Index.
unique_subquery: Dieser Typ ersetzt die Referenz der IN-Unterabfrage in der folgenden Form: value IN (SELECT Primary_key FROM single_table WHERE some_expr); unique_subquery ist eine Indexsuchfunktion, die die Unterabfrage vollständig ersetzen kann und effizienter ist.
index_subquery: Dieser Join-Typ ähnelt unique_subquery. IN-Unterabfragen können ersetzt werden, aber nur für nicht eindeutige Indizes in Unterabfragen der Form: value IN (SELECT key_column FROM single_table WHERE some_expr)
-
Bereich: Rufen Sie nur einen bestimmten Zeilenbereich ab, verwenden Sie einen Index, um Zeilen auszuwählen. In der Schlüsselspalte wird angezeigt, welcher Index verwendet wurde. key_len enthält das längste Schlüsselelement des verwendeten Index. Die Ref-Spalte ist bei diesem Typ NULL. Wenn Sie die Operatoren =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN oder IN verwenden, können Sie den Bereich
verwenden, wenn Sie Schlüsselspalten mit Konstanten vergleichen -
index: Dieser Join-Typ ist derselbe wie ALL, außer dass nur der Indexbaum gescannt wird. Dies ist normalerweise schneller als ALL, da Indexdateien normalerweise kleiner als Datendateien sind.
alle: Führen Sie einen vollständigen Tabellenscan für jede Zeilenkombination aus der vorherigen Tabelle durch. Dies ist normalerweise nicht gut, wenn die Tabelle die erste ist, die nicht mit const markiert ist, und ist in diesem Fall normalerweise schlecht. Normalerweise ist es möglich, weitere Indizes hinzuzufügen, ohne ALL zu verwenden, sodass Zeilen basierend auf konstanten Werten oder Spaltenwerten in der vorherigen Tabelle abgerufen werden können.
(5) Mögliche Schlüssel: Die Spalte Mögliche Schlüssel gibt an, welchen Index MySQL verwenden kann, um Zeilen in der Tabelle zu finden. Beachten Sie, dass diese Spalte völlig unabhängig von der Reihenfolge der in der EXPLAIN-Ausgabe angezeigten Tabellen ist. Dies bedeutet, dass einige Schlüssel in „posable_keys“ tatsächlich nicht in der generierten Tabellenreihenfolge verwendet werden können.
(6) Schlüssel: Die Schlüsselspalte zeigt den Schlüssel (Index), den MySQL tatsächlich verwendet hat. Wenn kein Index ausgewählt ist, ist der Schlüssel NULL. Um MySQL zu zwingen, den Index für die Spalte „posable_keys“ zu verwenden oder zu ignorieren, verwenden Sie FORCE INDEX, USE INDEX oder IGNORE INDEX in der Abfrage.
(7) key_len: Die Spalte key_len zeigt die Schlüssellänge, die MySQL verwenden möchte. Wenn der Schlüssel NULL ist, ist die Länge NULL. Beachten Sie, dass wir mithilfe des key_len-Werts bestimmen können, welche Teile eines mehrteiligen Schlüsselworts MySQL tatsächlich verwenden wird.
(8) Ref: Die Ref-Spalte zeigt, welche Spalte oder Konstante mit der Taste zum Auswählen von Zeilen aus der Tabelle verwendet wird.
(9) Zeilen: Die Zeilenspalte zeigt die Anzahl der Zeilen an, die MySQL bei der Ausführung der Abfrage überprüfen muss.
(10)Extra: Diese Spalte enthält Details darüber, wie MySQL die Abfrage gelöst hat.
Eindeutig: Nachdem MySQL die erste passende Zeile gefunden hat, stoppt es die Suche nach weiteren Zeilen für die aktuelle Zeilenkombination.
Nicht vorhanden: MySQL kann eine LEFT JOIN-Optimierung für die Abfrage durchführen. Nachdem eine Zeile gefunden wurde, die dem LEFT JOIN-Standard entspricht, werden keine weiteren Zeilen in der Tabelle auf die vorherige Zeilenkombination überprüft.
Bereich für jeden Datensatz überprüft (Indexzuordnung: #): MySQL hat keinen guten Index gefunden, der verwendet werden kann, hat jedoch festgestellt, dass einige Indizes verwendet werden können, wenn die Spaltenwerte aus der vorherigen Tabelle bekannt sind. Für jede Kombination von Zeilen aus der vorherigen Tabelle prüft MySQL, ob die Zeilen mit den Zugriffsmethoden „range“ oder „index_merge“ abgerufen werden können.
Filesort verwenden: MySQL benötigt einen zusätzlichen Durchgang, um herauszufinden, wie die Zeilen in sortierter Reihenfolge abgerufen werden. Die Sortierung erfolgt durch Durchsuchen aller Zeilen basierend auf dem Join-Typ und Speichern des Sortierschlüssels und Zeigers auf die Zeile für alle Zeilen, die der WHERE-Klausel entsprechen. Anschließend werden die Schlüssel sortiert und die Zeilen in sortierter Reihenfolge abgerufen.
Index verwenden: Rufen Sie Spalteninformationen aus einer Tabelle ab, indem Sie die tatsächlichen Zeilen lesen und dabei nur die Informationen im Indexbaum verwenden, ohne weitere Suche. Diese Strategie kann verwendet werden, wenn die Abfrage nur Spalten verwendet, die Teil eines einzelnen Index sind.
Temporär verwenden: Um die Abfrage zu lösen, muss MySQL eine temporäre Tabelle erstellen, um die Ergebnisse aufzunehmen. Eine typische Situation ist, wenn die Abfrage GROUP BY- und ORDER BY-Klauseln enthält, die Spalten je nach Situation auflisten können.
Verwendung von where: WHERE-Klausel wird verwendet, um einzuschränken, welche Zeile mit der nächsten Tabelle übereinstimmt oder an den Kunden gesendet wird. Sofern Sie nicht ausdrücklich alle Zeilen der Tabelle anfordern oder überprüfen, kann die Abfrage einige Fehler aufweisen, wenn der Extra-Wert nicht „Using where“ lautet und der Tabellen-Join-Typ „ALL“ oder „Index“ ist.
Verwendung von sort_union(...), Verwendung von union(...), Verwendung von intersect(...): Diese Funktionen veranschaulichen, wie Indexscans für den Join-Typ index_merge zusammengeführt werden.
Index für Group-by verwenden: Ähnlich wie bei der Methode „Index verwenden“ für den Zugriff auf eine Tabelle bedeutet die Verwendung eines Index für Group-by, dass MySQL einen Index gefunden hat, der zum Abfragen aller Spalten von GROUP BY- oder DISTINCT-Abfragen ohne verwendet werden kann zusätzliche Suchvorgänge. Festplattenzugriff auf die eigentliche Tabelle. Nutzen Sie den Index außerdem möglichst effizient, sodass für jede Gruppe nur wenige Indexeinträge gelesen werden.
Durch Multiplikation aller Werte in der Zeilenspalte der EXPLAIN-Ausgabe erhalten Sie einen Hinweis darauf, wie ein Join funktioniert. Dies sollte Ihnen ungefähr sagen, wie viele Zeilen MySQL überprüfen muss, um die Abfrage auszuführen. Dieses Produkt wird auch verwendet, um zu bestimmen, welche SELECT-Anweisung für mehrere Tabellen ausgeführt werden soll, wenn Sie die Variable max_join_size verwenden, um eine Abfrage einzuschränken.
Empfohlenes Lernen: MySQL-Video-Tutorial
Das obige ist der detaillierte Inhalt vonBeherrschen Sie die Indizierungsfähigkeiten von MySQL vollständig (Zusammenfassungsfreigabe).. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Mehrere Situationen, in denen ein MySQL-Index fehlschlägt
Feb 21, 2024 pm 04:23 PM
Mehrere Situationen, in denen ein MySQL-Index fehlschlägt
Feb 21, 2024 pm 04:23 PM
Häufige Situationen: 1. Verwenden Sie Funktionen oder Operationen; 3. Verwenden Sie ungleich (!= oder <>); Wert; 7. Niedrige Indexselektivität; 8. Prinzip des zusammengesetzten Indexes; 9. Optimierer-Entscheidung;
 Unter welchen Umständen schlägt der MySQL-Index fehl?
Aug 09, 2023 pm 03:38 PM
Unter welchen Umständen schlägt der MySQL-Index fehl?
Aug 09, 2023 pm 03:38 PM
MySQL-Indizes schlagen fehl, wenn Abfragen ohne Verwendung von Indexspalten, nicht übereinstimmenden Datentypen, falscher Verwendung von Präfixindizes, Verwendung von Funktionen oder Ausdrücken für Abfragen, falscher Reihenfolge von Indexspalten, häufigen Datenaktualisierungen und zu vielen oder zu wenigen Indizes erfolgen. 1. Verwenden Sie keine Indexspalten für Abfragen. 2. Bei der Gestaltung der Tabellenstruktur sollten Sie darauf achten, dass die Indexspalten übereinstimmen 3. Bei unsachgemäßer Verwendung des Präfixindex können Sie den Präfixindex verwenden.
 Wann könnte ein vollständiger Tabellen -Scan schneller sein als einen Index in MySQL?
Apr 09, 2025 am 12:05 AM
Wann könnte ein vollständiger Tabellen -Scan schneller sein als einen Index in MySQL?
Apr 09, 2025 am 12:05 AM
Die volle Tabellenscannung kann in MySQL schneller sein als die Verwendung von Indizes. Zu den spezifischen Fällen gehören: 1) das Datenvolumen ist gering; 2) Wenn die Abfrage eine große Datenmenge zurückgibt; 3) wenn die Indexspalte nicht sehr selektiv ist; 4) Wenn die komplexe Abfrage. Durch Analyse von Abfrageplänen, Optimierung von Indizes, Vermeidung von Überindex und regelmäßiger Wartung von Tabellen können Sie in praktischen Anwendungen die besten Auswahlmöglichkeiten treffen.
 Was sind die Klassifizierungen von MySQL-Indizes?
Apr 22, 2024 pm 07:12 PM
Was sind die Klassifizierungen von MySQL-Indizes?
Apr 22, 2024 pm 07:12 PM
MySQL-Indizes werden in die folgenden Typen unterteilt: 1. Gewöhnlicher Index: Übereinstimmung mit Wert, Bereich oder Präfix; 2. Eindeutiger Index: Stellt sicher, dass der Wert eindeutig ist. 3. Primärschlüsselindex: Eindeutiger Index der Primärschlüsselspalte Schlüsselindex: zeigt auf den Primärschlüssel einer anderen Tabelle; 5. Volltextindex: Suche nach gleicher Übereinstimmung; 8. Zusammengesetzter Index: Suche basierend auf mehreren Säulen.
 MySQL-Index-Linkspräfix-Matching-Regeln
Feb 24, 2024 am 10:42 AM
MySQL-Index-Linkspräfix-Matching-Regeln
Feb 24, 2024 am 10:42 AM
Prinzip des MySQL-Index ganz links: Prinzip und Codebeispiele In MySQL ist die Indizierung eines der wichtigsten Mittel zur Verbesserung der Abfrageeffizienz. Unter diesen ist das Indexprinzip ganz links ein wichtiges Prinzip, das wir befolgen müssen, wenn wir Indizes zur Optimierung von Abfragen verwenden. In diesem Artikel wird das Prinzip des MySQL-Index ganz links vorgestellt und einige spezifische Codebeispiele gegeben. 1. Das Prinzip des Index-Prinzips ganz links Das Prinzip des Index ganz links bedeutet, dass in einem Index, wenn die Abfragebedingung aus mehreren Spalten besteht, nur die Spalte ganz links im Index abgefragt werden kann, um die Abfragebedingungen vollständig zu erfüllen.
 Erklären Sie verschiedene Arten von MySQL-Indizes (B-Tree, Hash, Volltext, räumlich).
Apr 02, 2025 pm 07:05 PM
Erklären Sie verschiedene Arten von MySQL-Indizes (B-Tree, Hash, Volltext, räumlich).
Apr 02, 2025 pm 07:05 PM
MySQL unterstützt vier Indextypen: B-Tree, Hash, Volltext und räumlich. 1.B-Tree-Index ist für die gleichwertige Suche, eine Bereichsabfrage und die Sortierung geeignet. 2. Hash -Index ist für gleichwertige Suche geeignet, unterstützt jedoch keine Abfrage und Sortierung von Bereichs. 3. Die Volltextindex wird für die Volltext-Suche verwendet und ist für die Verarbeitung großer Mengen an Textdaten geeignet. 4. Der räumliche Index wird für die Abfrage für Geospatial -Daten verwendet und ist für GIS -Anwendungen geeignet.
 Wie kann man MySQL-Indizes rational nutzen und die Datenbankleistung optimieren? Designprotokolle, die Technikstudenten kennen müssen!
Sep 10, 2023 pm 03:16 PM
Wie kann man MySQL-Indizes rational nutzen und die Datenbankleistung optimieren? Designprotokolle, die Technikstudenten kennen müssen!
Sep 10, 2023 pm 03:16 PM
Wie kann man MySQL-Indizes rational nutzen und die Datenbankleistung optimieren? Designprotokolle, die Technikstudenten kennen müssen! Einleitung: Im heutigen Internetzeitalter wächst die Datenmenge weiter und die Optimierung der Datenbankleistung ist zu einem sehr wichtigen Thema geworden. Als eine der beliebtesten relationalen Datenbanken ist die rationelle Nutzung von Indizes durch MySQL von entscheidender Bedeutung für die Verbesserung der Datenbankleistung. In diesem Artikel erfahren Sie, wie Sie MySQL-Indizes rational nutzen, die Datenbankleistung optimieren und einige Designregeln für Technikstudenten bereitstellen. 1. Warum Indizes verwenden? Ein Index ist eine Datenstruktur, die verwendet
 Strategien zur Leistungsoptimierung für die Datenaktualisierung und Indexpflege von PHP- und MySQL-Indizes und deren Auswirkungen auf die Leistung
Oct 15, 2023 pm 12:15 PM
Strategien zur Leistungsoptimierung für die Datenaktualisierung und Indexpflege von PHP- und MySQL-Indizes und deren Auswirkungen auf die Leistung
Oct 15, 2023 pm 12:15 PM
Strategien zur Leistungsoptimierung für die Datenaktualisierung und Indexpflege von PHP- und MySQL-Indizes und deren Auswirkungen auf die Leistung. Zusammenfassung: In der Entwicklung von PHP und MySQL sind Indizes ein wichtiges Werkzeug zur Optimierung der Datenbankabfrageleistung. In diesem Artikel werden die Grundprinzipien und die Verwendung von Indizes vorgestellt und die Auswirkungen von Indizes auf die Leistung bei der Datenaktualisierung und -wartung untersucht. Gleichzeitig bietet dieser Artikel auch einige Strategien zur Leistungsoptimierung und spezifische Codebeispiele, um Entwicklern zu helfen, Indizes besser zu verstehen und anzuwenden. Grundprinzipien und Verwendung von Indizes In MySQL ist ein Index eine spezielle Zahl
