

Zu den Docker-Speichertreibern gehören: 1. AUFS, ein Speichertreiber auf Dateiebene; 3. Device Mapper, ein Mapping-Framework-Mechanismus; 5. ZFS, ein brandneues Dateisystem.

Die Betriebsumgebung dieses Artikels: Windows 7-System, Docker-Version 20.10.11, Dell G3-Computer.
Was sind die fünf Speichertreiberprinzipien von Docker und ihre Anwendungsszenarien? dass mehrere Container dasselbe Bild teilen können. Da AUFS jedoch nicht in den Linux-Kernel integriert ist und nur Ubuntu unterstützt, wurde in Docker-Version 0.7 ein Speichertreiber eingeführt. Derzeit unterstützt Docker fünf Arten von
AUFS, Btrfs, Device Mapper, OverlayFS und ZFSSpeichertreiber. Wie auf der offiziellen Docker-Website angegeben, ist kein einzelner Treiber für alle Anwendungsszenarien geeignet. Nur durch die Auswahl des geeigneten Speichertreibers entsprechend den verschiedenen Szenarien kann die Leistung von Docker effektiv verbessert werden. Wie wählt man einen geeigneten Speichertreiber aus? Um ein besseres Urteil abgeben zu können, müssen Sie zunächst die Speichertreiberprinzipien verstehen. In diesem Artikel werden die fünf Speichertreiberprinzipien von Docker ausführlich erläutert und Anwendungsszenarien und E/A-Leistungstests verglichen. Bevor wir über die Prinzipien sprechen, sprechen wir über die beiden Technologien Copy-on-Write und Allocation-on-Write.
1. Copy-on-Write (CoW) Eine von allen Fahrern verwendete Technologie – Copy-on-Write (CoW). CoW ist Copy-on-Write, was bedeutet, dass nur dann kopiert wird, wenn ein Schreibvorgang erforderlich ist. Dies gilt für das Änderungsszenario vorhandener Dateien. Wenn beispielsweise mehrere Container basierend auf einem Image gestartet werden und jedem Container ein dem Image ähnliches Dateisystem zugewiesen wird, nimmt dies viel Speicherplatz ein. Die CoW-Technologie ermöglicht es allen Containern, das Dateisystem des Images gemeinsam zu nutzen. Alle Daten werden aus dem Image gelesen. Nur wenn eine Datei geschrieben werden soll, wird die zu schreibende Datei zur Änderung vom Image kopiert. . Unabhängig davon, wie viele Container dasselbe Image nutzen, werden die Schreibvorgänge für die vom Image in das eigene Dateisystem kopierte Kopie ausgeführt. Die Quelldatei des Images wird nicht geändert und es werden mehrere Containervorgänge gleichzeitig ausgeführt. Eine Datei generiert eine Kopie im Dateisystem jedes Containers. Jeder Container ändert seine eigene Kopie, die voneinander isoliert ist und sich nicht gegenseitig beeinflusst. Durch die Verwendung von CoW kann die Festplattennutzung effektiv verbessert werden.
2. Zuweisung nach Bedarf
Zuweisung nach Bedarf wird in Szenarien verwendet, in denen die Datei ursprünglich nicht vorhanden ist, was die Nutzung von Speicherressourcen verbessern kann . . Wenn beispielsweise ein Container gestartet wird, wird dem Container kein Speicherplatz zugewiesen. Stattdessen wird neuer Speicherplatz bei Bedarf zugewiesen, wenn neue Dateien geschrieben werden.2. Fünf Grundprinzipien von Speichertreibern
1.
AUFSAUFS (AnotherUnionFS) ist ein
Speichertreiber auf Dateiebene. AUFS kann ein mehrschichtiges Dateisystem transparent über ein oder mehrere vorhandene Dateisysteme legen und so mehrere Schichten zu einer einschichtigen Darstellung des Dateisystems zusammenführen.
Einfach ausgedrückt unterstützt es das Mounten verschiedener Verzeichnisse im Dateisystem unter demselben virtuellen Dateisystem. Dieses Dateisystem kann Dateien Schicht für Schicht ändern. Unabhängig davon, wie viele Schichten darunter schreibgeschützt sind, ist nur das oberste Dateisystem beschreibbar. Wenn eine Datei geändert werden muss, erstellt AUFS eine Kopie der Datei, kopiert die Datei mithilfe von CoW zur Änderung von der schreibgeschützten Ebene in die beschreibbare Ebene und speichert die Ergebnisse auch in der beschreibbaren Ebene. In Docker ist die schreibgeschützte Ebene darunter das Bild und die beschreibbare Ebene der Container. Die Struktur ist wie in der folgenden Abbildung dargestellt: 2, Overlay
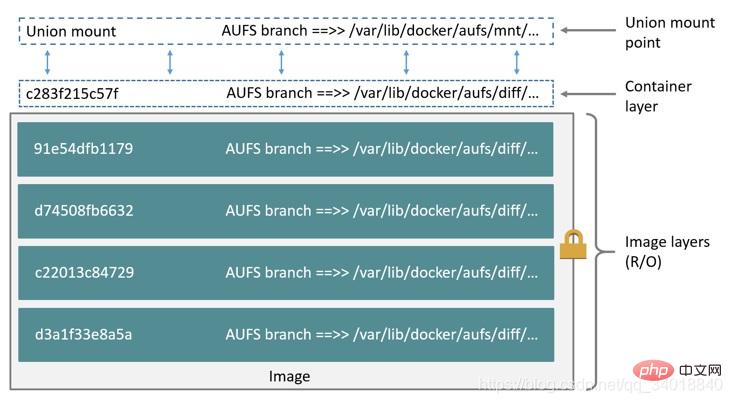
Ein oberes Dateisystem und ein unteres Dateisystem repräsentieren die Image-Ebene bzw. Container-Ebene von Docker. Wenn eine Datei geändert werden muss, wird CoW verwendet, um die Datei zur Änderung von der schreibgeschützten unteren in die beschreibbare obere Ebene zu kopieren, und das Ergebnis wird auch in der oberen Ebene gespeichert. In Docker ist die schreibgeschützte Ebene darunter das Bild und die beschreibbare Ebene der Container. Die Struktur ist in der folgenden Abbildung dargestellt:
3, Gerätezuordnung
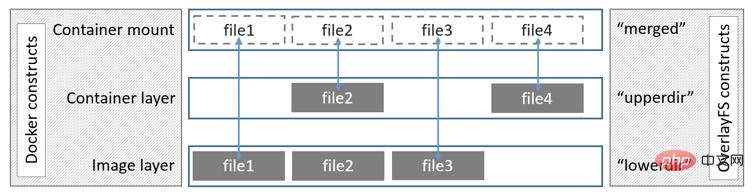
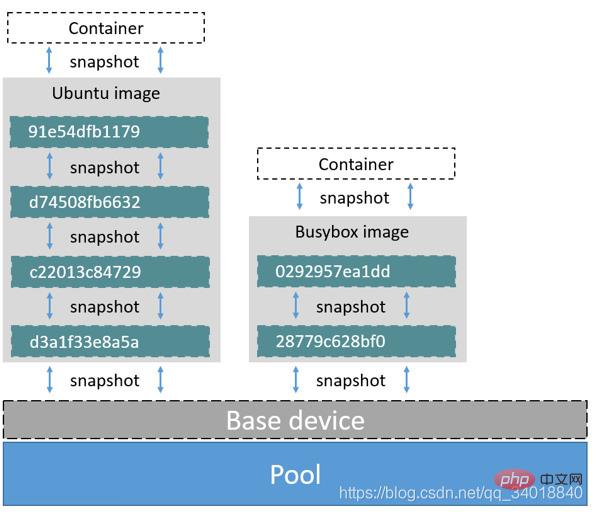
Device Mapper wird vom Linux-Kernel 2.6.9 und höher unterstützt. Er bietet einen Mapping-Framework-Mechanismus von logischen Geräten zu physischen Geräten. Mit diesem Mechanismus können Benutzer ganz einfach Verwaltungsstrategien für Speicherressourcen entsprechend ihren eigenen Anforderungen formulieren. Die zuvor erwähnten AUFS und OverlayFS sind Speicher auf Dateiebene, während der Device Mapper ein Speicher auf Blockebene ist Alle Vorgänge werden direkt auf Blöcken und nicht auf Dateien ausgeführt. Der Device-Mapper-Treiber erstellt zunächst einen Ressourcenpool auf dem Blockgerät und dann ein Basisgerät mit einem Dateisystem auf dem Ressourcenpool. Alle Bilder sind Snapshots dieses Basisgeräts und Container sind Snapshots des Images. Daher ist das im Container angezeigte Dateisystem eine Momentaufnahme des Dateisystems des Basisgeräts im Ressourcenpool, und dem Container wird kein Speicherplatz zugewiesen. Wenn eine neue Datei geschrieben wird, werden ihr im Image des Containers neue Blöcke zugewiesen und Daten geschrieben. Dies wird als Zeitzuweisung bezeichnet. Wenn Sie eine vorhandene Datei ändern möchten, weisen Sie mit CoW Blockspeicherplatz für den Container-Snapshot zu, kopieren die zu ändernden Daten in den neuen Block im Container-Snapshot und ändern ihn dann. Der Device Mapper-Treiber erstellt standardmäßig eine 100G-Datei mit Bildern und Containern. Jeder Container ist auf ein 10G-Volumen begrenzt und kann von Ihnen selbst konfiguriert und angepasst werden. Die Struktur ist in der folgenden Abbildung dargestellt:
4, Btrfs
Btrfs wird als Copy-on-Write-Dateisystem der nächsten Generation bezeichnet, ist in den Linux-Kernel integriert und ebenfalls eine -Datei -Level-Speichertreiber, kann aber wie Device Mapper verwendet werden. Bedienen Sie die zugrunde liegende Ausrüstung immer direkt. Btrfs konfiguriert einen Teil des Dateisystems als vollständiges Unterdateisystem, das als Subvolume bezeichnet wird. Mithilfe von Subvolumes kann ein großes Dateisystem in mehrere Subdateisysteme unterteilt werden. Diese Subdateisysteme teilen sich den zugrunde liegenden Gerätespeicherplatz und werden vom zugrunde liegenden Gerät zugewiesen, wenn Speicherplatz benötigt wird, ähnlich wie eine Anwendung malloc() aufruft Speicher zuweisen. Um den Gerätespeicher flexibel nutzen zu können, teilt Btrfs den Speicherplatz in mehrere Blöcke auf. Jeder Block kann unterschiedliche Strategien zur Speicherplatzzuweisung verwenden. Einige Chunks speichern beispielsweise nur Metadaten und andere Chunks nur Daten. Dieses Modell bietet viele Vorteile, beispielsweise unterstützt Btrfs das dynamische Hinzufügen von Geräten. Nachdem der Benutzer dem System eine neue Festplatte hinzugefügt hat, kann er das Gerät mit dem Befehl Btrfs zum Dateisystem hinzufügen. Btrfs behandelt ein großes Dateisystem als Ressourcenpool und konfiguriert es in mehrere vollständige Unterdateisysteme. Dem Ressourcenpool können auch neue Unterdateisysteme hinzugefügt werden -image und Container Jeder hat seinen eigenen Snapshot, und diese Snapshots sind alle Snapshots des Subvolumes.
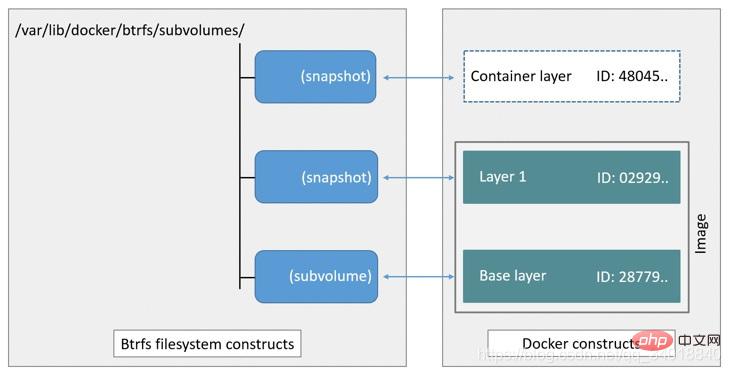
Wenn eine neue Datei geschrieben wird, wird ihr im Snapshot des Containers ein neuer Datenblock zugewiesen und die Datei wird in diesen Bereich geschrieben. Dies wird als Zeitzuordnung bezeichnet. Wenn Sie eine vorhandene Datei ändern möchten, verwenden Sie die CoW-Kopie, um neue Originaldaten und einen neuen Snapshot zuzuweisen, ändern Sie die Daten in diesem neu zugewiesenen Bereich und aktualisieren Sie dann die relevante Datenstruktur so, dass sie auf das neue Unterdateisystem und den neuen Snapshot verweist Original Originaldaten Und der Snapshot hat keinen Zeiger darauf und wird überschrieben.
5, ZFS
ZFS-Dateisystem ist ein revolutionäres neues Dateisystem, das die Art und Weise, wie Dateisysteme verwaltet werden, grundlegend verändert und keine virtuellen Volumes mehr erstellt, sondern alle Geräte zentralisiert in einen Speicherpool für die Verwaltung Verwenden Sie das Konzept des „Speicherpools“, um physischen Speicherplatz zu verwalten. In der Vergangenheit wurden Dateisysteme auf physischen Geräten aufgebaut. Um diese physischen Geräte zu verwalten und Redundanz für Daten bereitzustellen, stellt das Konzept der „Volume-Verwaltung“ ein einzelnes Geräte-Image bereit. ZFS basiert auf virtuellen Speicherpools namens „zpools“. Jeder Speicherpool besteht aus mehreren virtuellen Geräten (vdevs). Bei diesen virtuellen Geräten kann es sich um Raw-Festplatten, ein RAID1-Spiegelgerät oder eine Gruppe mit mehreren Festplatten mit nicht standardmäßigen RAID-Levels handeln. Das Dateisystem auf dem Zpool kann dann die gesamte Speicherkapazität dieser virtuellen Geräte nutzen.
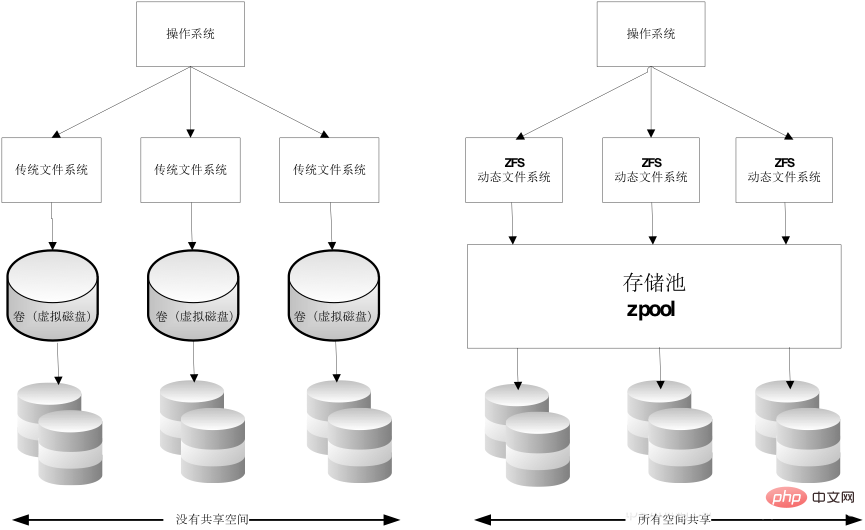
Werfen wir einen Blick auf die Verwendung von ZFS in Docker. Ordnen Sie zunächst ein ZFS-Dateisystem von zpool der Basisebene des Images zu, und andere Image-Ebenen sind Klone dieses ZFS-Dateisystem-Snapshots. Der Snapshot ist schreibgeschützt und der Klon ist beschreibbar im Spiegel Die oberste Ebene erzeugt eine beschreibbare Ebene. Wie im Bild unten gezeigt:
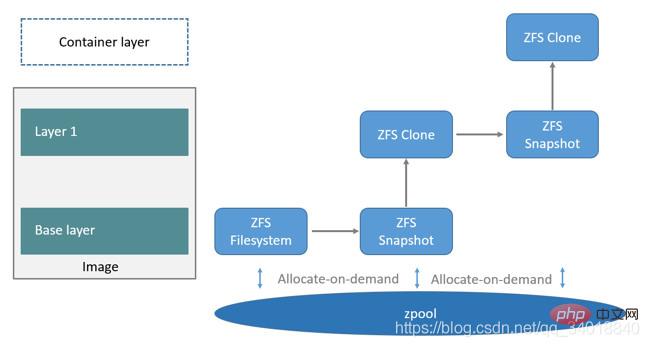
Wenn Sie eine neue Datei schreiben möchten, verwenden Sie die On-Demand-Zuweisung, ein neuer Datenblock wird aus dem Zpool generiert, die neuen Daten werden in diesen Block geschrieben und dieser neue Speicherplatz wird im Container (ZFS-Klon) gespeichert ). Wenn Sie eine vorhandene Datei ändern möchten, verwenden Sie Copy-on-Write, um einen neuen Speicherplatz zuzuweisen und die Originaldaten in den neuen Speicherplatz zu kopieren, um die Änderung abzuschließen.
3. Vergleich der Speichertreiber und Anpassung an Szenarien
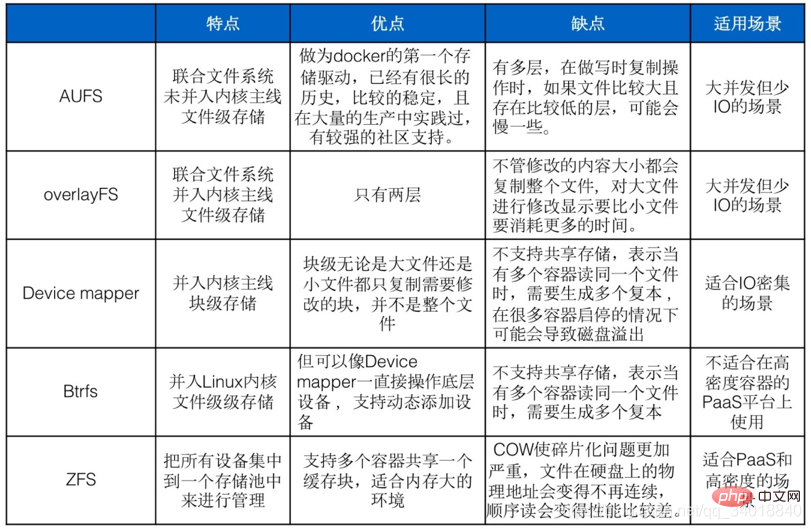
1, AUFS VS Overlay
AUFS und Overlay sind beide gemeinsame Dateisysteme, aber AUFS verfügt über mehrere Ebenen, während Overlay nur über mehrere Ebenen verfügt Wenn die Datei größer ist und niedrigere Ebenen vorhanden sind, ist AUSF möglicherweise langsamer, wenn Kopiervorgänge beim Schreiben ausgeführt werden. Darüber hinaus ist Overlay in die Hauptlinie des Linux-Kernels integriert, AUFS jedoch nicht, sodass es möglicherweise schneller als AUFS ist. Aber Overlay ist noch zu jung und sollte in der Produktion mit Vorsicht eingesetzt werden. Als erster Speichertreiber von Docker hat AUFS eine lange Geschichte, ist relativ stabil, wurde in einer großen Anzahl von Produktionen praktiziert und genießt starke Unterstützung durch die Community. Das aktuelle Open-Source-DC/OS spezifiziert die Verwendung von Overlay.
2, Overlay VS Device Mapper
Overlay ist eine Speicherung auf Dateiebene, und Device Mapper ist eine Speicherung auf Blockebene. Wenn die Datei besonders groß und der geänderte Inhalt klein ist, kopiert Overlay den gesamten Inhalt Unabhängig von der Größe des geänderten Inhalts dauert das Ändern einer großen Datei länger als das Ändern einer kleinen Datei. Auf Blockebene müssen nur die Blöcke geändert werden, unabhängig davon, ob es sich um eine große oder eine kleine Datei handelt werden kopiert, nicht die gesamte Datei. In diesem Szenario ist es offensichtlich, dass der Geräte-Mapper schneller ist. Da die Blockebene direkt auf die logische Festplatte zugreift, eignet sie sich für E/A-intensive Szenarien. Bei Szenarien mit komplexen internen Programmen, großer Parallelität, aber wenig E/A ist die Leistung von Overlay relativ stärker.
3 Es sind mehrere Kopien erforderlich, daher ist dieser Speichertreiber nicht für die Verwendung auf PaaS-Plattformen mit hoher Containerdichte geeignet. Darüber hinaus kann es beim Starten und Stoppen vieler Container zu einem Festplattenüberlauf kommen und dazu führen, dass der Host nicht mehr funktioniert. Device Mapper wird nicht für den Produktionseinsatz empfohlen, Btrfs kann im Docker-Build sehr effizient sein. ZFS wurde ursprünglich für Salaris-Server mit viel Speicher entwickelt, daher wirkt es sich bei der Verwendung auf den Speicher aus und ist für Umgebungen mit großem Speicher geeignet. COW von ZFS verschärft das Fragmentierungsproblem, wenn bei großen Dateien, die durch sequentielles Schreiben generiert werden, in Zukunft ein Teil davon zufällig geändert wird. Die physische Adresse der Datei auf der Festplatte ist nicht mehr kontinuierlich und zukünftige sequentielle Lesevorgänge werden beeinträchtigt wird ärmer werden. ZFS unterstützt mehrere Container, die sich einen Cache-Block teilen, was für PaaS und Benutzerszenarien mit hoher Dichte geeignet ist. Empfohlenes Lernen: „Docker-Tutorial“
Das obige ist der detaillierte Inhalt vonWas sind die Docker-Speichertreiber?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Der Unterschied zwischen k8s und Docker
Der Unterschied zwischen k8s und Docker
 Mit welchen Methoden kann Docker in den Container gelangen?
Mit welchen Methoden kann Docker in den Container gelangen?
 Was soll ich tun, wenn der Docker-Container nicht auf das externe Netzwerk zugreifen kann?
Was soll ich tun, wenn der Docker-Container nicht auf das externe Netzwerk zugreifen kann?
 Wozu dient das Docker-Image?
Wozu dient das Docker-Image?
 Auf welcher Plattform kann ich Ripple-Coins kaufen?
Auf welcher Plattform kann ich Ripple-Coins kaufen?
 Der Unterschied zwischen Arbeitsmappe und Arbeitsblatt
Der Unterschied zwischen Arbeitsmappe und Arbeitsblatt
 Die Rolle der mathematischen Funktion in der C-Sprache
Die Rolle der mathematischen Funktion in der C-Sprache
 Ist Code Red ein Computervirus?
Ist Code Red ein Computervirus?









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



