Dieser Artikel vermittelt Ihnen relevantes Wissen über InnoDB-Datenseiten in MySQL-Prinzipien, einschließlich relevantem Wissen über Seitenverzeichnisse, Seitenkopfzeilen und Dateikopfzeilen. Ich hoffe, dass es für alle hilfreich ist.

Einführung in verschiedene Arten von Seiten
Es ist die Grundeinheit für InnoDB zur Verwaltung des Speicherplatzes. Die Größe einer Seite beträgt im Allgemeinen 16 KB. InnoDB hat viele verschiedene Arten von Seiten für verschiedene Zwecke entworfen, z. B. Seiten, die Tabellenbereichs-Header-Informationen und Insert Buffer-Informationen speichern speichert INODE-Informationen, die Seite, die Rückgängig-Protokollinformationen usw. speichert. Natürlich, wenn Sie keinen der von mir genannten Begriffe gehört haben, denken Sie einfach, dass ich gefurzt habe. Aber es spielt keine Rolle, worauf wir uns heute konzentrieren werden Diese Seitentypen, die Datensätze in unseren Tabellen speichern, werden offiziell Indexseiten (INDEX) genannt, da wir noch nicht verstanden haben, was ein Index ist, und in diesen Tabellen sind die Datensätze das, was wir nennen Daten im täglichen Leben, daher nennen wir diese Seite, auf der Datensätze gespeichert werden, vorerst immer noch Datenseite. InnoDB管理存储空间的基本单位,一个页的大小一般是16KB。InnoDB为了不同的目的而设计了许多种不同类型的页,比如存放表空间头部信息的页,存放Insert Buffer信息的页,存放INODE信息的页,存放undo日志信息的页等等等等。当然了,如果我说的这些名词你一个都没有听过,就当我放了个屁吧~ 不过这没有一毛钱关系,我们今儿个也不准备说这些类型的页,我们聚焦的是那些存放我们表中记录的那种类型的页,官方称这种存放记录的页为索引(INDEX)页,鉴于我们还没有了解过索引是个什么东西,而这些表中的记录就是我们日常口中所称的数据,所以目前还是叫这种存放记录的页为数据页吧。
数据页结构的快速浏览
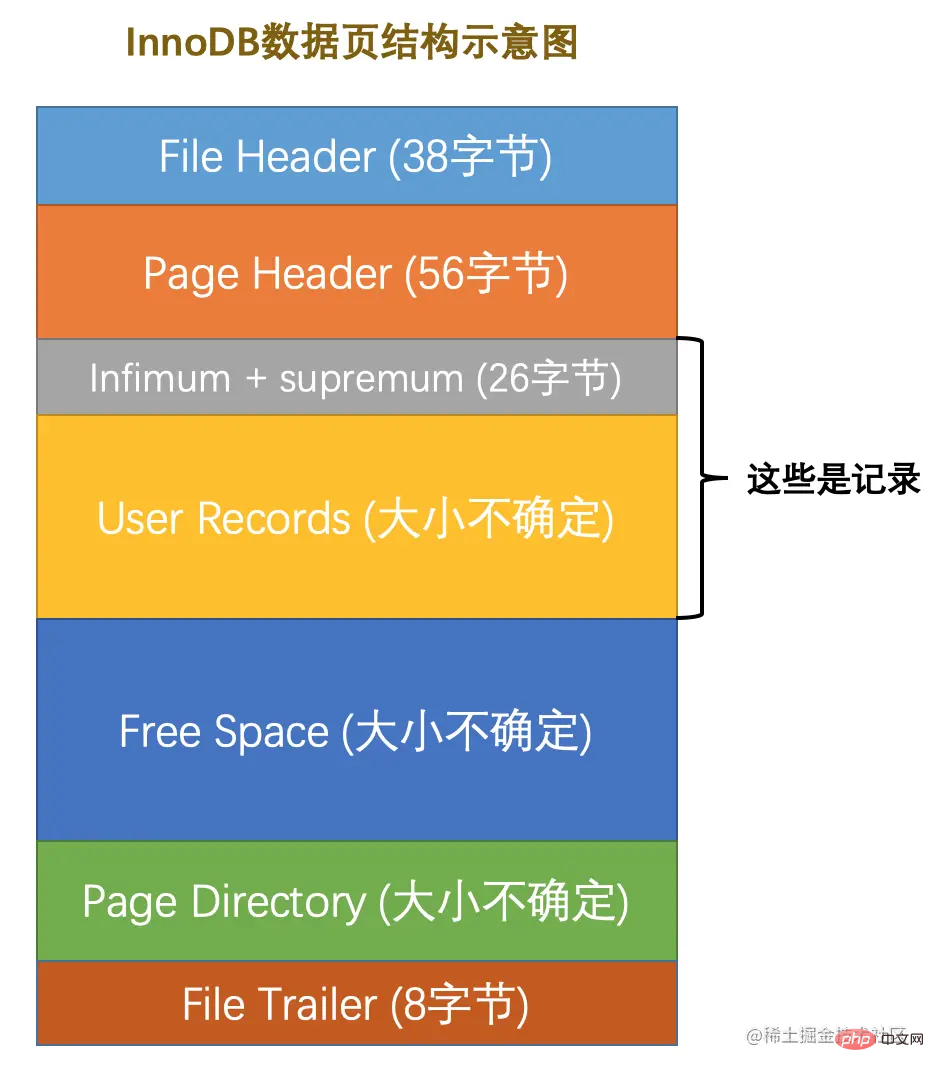
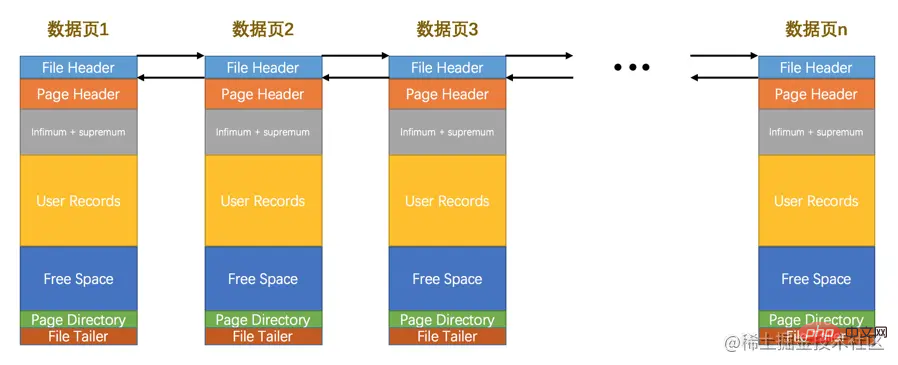
数据页代表的这块16KB大小的存储空间可以被划分为多个部分,不同部分有不同的功能,各个部分如图所示:
从图中可以看出,一个InnoDB数据页的存储空间大致被划分成了7个部分,有的部分占用的字节数是确定的,有的部分占用的字节数是不确定的。下边我们用表格的方式来大致描述一下这7个部分都存储一些啥内容(快速的瞅一眼就行了,后边会详细唠叨的):
| 名称 |
中文名 |
占用空间大小 |
简单描述 |
File Header |
文件头部 |
38字节 |
页的一些通用信息 |
Page Header |
页面头部 |
56字节 |
数据页专有的一些信息 |
Infimum + Supremum |
最小记录和最大记录 |
26字节 |
两个虚拟的行记录 |
User Records |
用户记录 |
不确定 |
实际存储的行记录内容 |
Free Space |
空闲空间 |
不确定 |
页中尚未使用的空间 |
Page Directory |
页面目录 |
不确定 |
页中的某些记录的相对位置 |
File Trailer |
文件尾部 |
8 | Schnelles Durchsuchen der Datenseitenstruktur | Der durch die Datenseite dargestellte 16KB kann in mehrere Teile unterteilt werden, die unterschiedliche Funktionen haben:
Wie aus der Abbildung ersichtlich ist, ist der Speicherplatz einer
InnoDB-Datenseite grob in
7-Teile unterteilt. Die Anzahl der von einigen Teilen belegten Bytes wird bestimmt. Ja, die Anzahl der von einigen Teilen belegten Bytes ist ungewiss. Im Folgenden beschreiben wir anhand einer Tabelle grob, welche Inhalte in diesen 7 Teilen gespeichert sind (werfen Sie einen kurzen Blick darauf, wir werden später ausführlicher darauf eingehen): 🎜
| Name |
Chinesischer Name |
Leerzeichengröße |
Einfache Beschreibung | 🎜
🎜Dateikopfzeile 🎜🎜Dateikopfzeile🎜🎜38Bytes🎜🎜Einige allgemeine Informationen zur Seite🎜🎜
🎜Seitenkopfzeile🎜🎜Seitenkopfzeilenteil 🎜🎜56 Bytes🎜🎜Einige Informationen exklusiv für die Datenseite🎜🎜
🎜Infimum + Supremum🎜🎜Minimaler Datensatz und maximaler Datensatz🎜🎜 26 Bytes🎜🎜Zwei virtuelle Zeilendatensätze🎜🎜
🎜Benutzerdatensätze🎜🎜Benutzerdatensätze🎜🎜Unsicher🎜🎜Der tatsächlich gespeicherte Zeilendatensatzinhalt🎜🎜
🎜Freier Speicherplatz code>🎜🎜Freier Speicherplatz🎜🎜Nicht sicher 🎜🎜Ungenutzter Speicherplatz auf der Seite🎜🎜<tr>🎜<code>Seitenverzeichnis🎜🎜Seitenverzeichnis🎜🎜Nicht sicher 🎜🎜Die relative Position einiger Datensätze in der Seite🎜🎜
🎜File Trailer🎜🎜Das Ende der Datei🎜🎜8 Bytes🎜🎜Überprüfen Sie, ob die Seite vollständig ist🎜 🎜🎜🎜Speicherung von Datensätzen auf der Seite
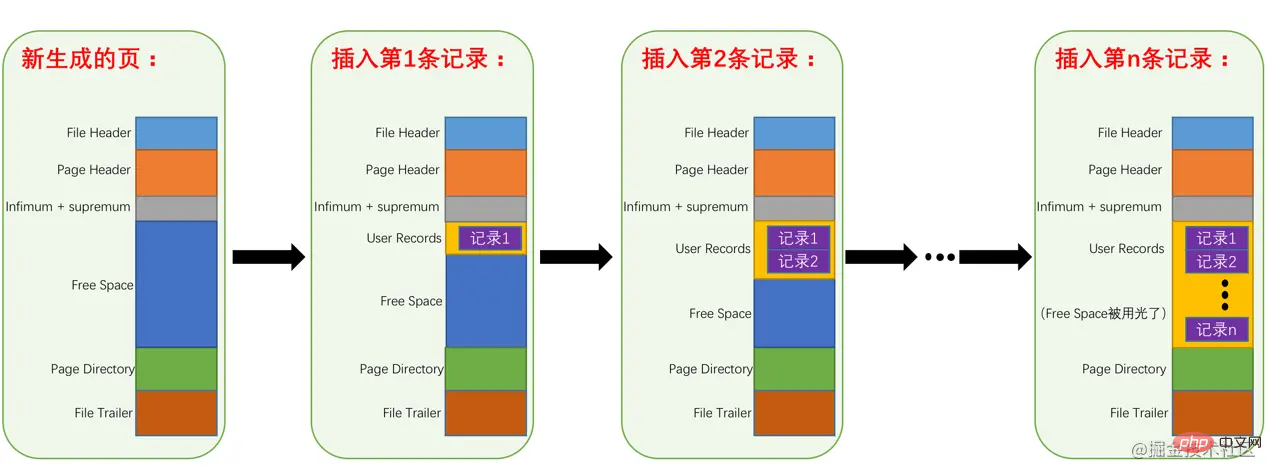
Unter den 7 Komponenten der Seite werden die Datensätze, die wir selbst speichern, in BenutzerdatensätzenZeilenformat gespeichert Wir haben den Abschnitt /code> angegeben. Aber wenn wir die Seite zum ersten Mal generieren, gibt es tatsächlich keinen Abschnitt Benutzerdatensätze. Immer wenn wir einen Datensatz einfügen, wird er aus dem Abschnitt Freier Speicherplatz abgerufen, der ungenutzt ist Beantragen Sie einen Speicherplatz in Datensatzgröße und teilen Sie ihn in den Teil Benutzerdatensätze auf, wenn der gesamte Speicherplatz im Teil Freier Speicherplatz ersetzt wird >Benutzerdatensätze. Dies bedeutet, dass diese Seite aufgebraucht ist. Wenn neue Datensätze eingefügt wurden, müssen Sie eine neue Seite beantragen. Das Diagramm dieses Prozesses ist wie folgt: 行格式存储到User Records部分。但是在一开始生成页的时候,其实并没有User Records这个部分,每当我们插入一条记录,都会从Free Space部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到User Records部分,当Free Space部分的空间全部被User Records部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了,这个过程的图示如下:
为了更好的管理在User Records中的这些记录,InnoDB可费了一番力气呢,在哪费力气了呢?不就是把记录按照指定的行格式一条一条摆在User Records部分么?其实这话还得从记录行格式的记录头信息中说起。
记录头信息的秘密
为了故事的顺利发展,我们先创建一个表:
mysql> CREATE TABLE page_demo(
-> c1 INT,
-> c2 INT,
-> c3 VARCHAR(10000),
-> PRIMARY KEY (c1)
-> ) CHARSET=ascii ROW_FORMAT=Compact;
Query OK, 0 rows affected (0.03 sec)
Nach dem Login kopieren
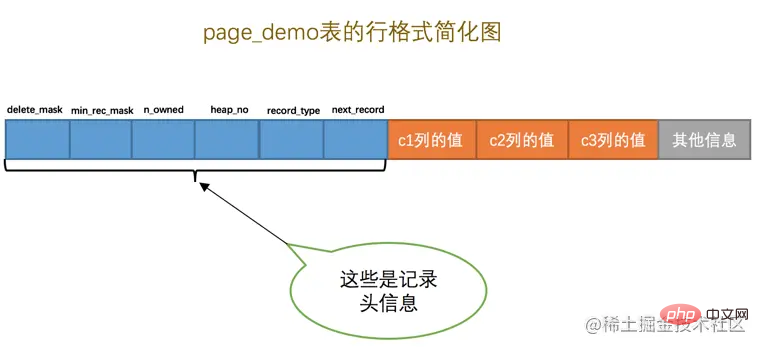
这个新创建的page_demo表有3个列,其中c1和c2列是用来存储整数的,c3列是用来存储字符串的。需要注意的是,我们把 c1 列指定为主键,所以在具体的行格式中InnoDB就没必要为我们去创建那个所谓的 row_id 隐藏列了。而且我们为这个表指定了ascii字符集以及Compact的行格式。所以这个表中记录的行格式示意图就是这样的:
从图中可以看到,我们特意把记录头信息的5个字节的数据给标出来了,说明它很重要,我们再次先把这些记录头信息中各个属性的大体意思浏览一下(我们目前使用Compact行格式进行演示):
| 名称 |
大小(单位:bit) |
描述 |
预留位1 |
1 |
没有使用 |
预留位2 |
1 |
没有使用 |
delete_mask |
1 |
标记该记录是否被删除 |
min_rec_mask |
1 |
B+树的每层非叶子节点中的最小记录都会添加该标记 |
n_owned |
4 |
表示当前记录拥有的记录数 |
heap_no |
13 |
表示当前记录在记录堆的位置信息 |
record_type |
3 |
表示当前记录的类型,0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录 |
next_record |
16
|
Für eine bessere VerwaltungInnoDB hat viel Mühe in diese Datensätze im Code>Benutzerdatensätze gesteckt. Ist es nicht einfach, die Datensätze einzeln im Abschnitt Benutzerdatensätze gemäß dem angegebenen Zeilenformat zu platzieren? Tatsächlich müssen wir mit den Datensatz-Header-Informationen des Datensatzzeilenformats beginnen. |
Das Geheimnis der Aufzeichnung von Header-Informationen
Für die reibungslose Entwicklung der Story erstellen wir zunächst eine Tabelle:
mysql> INSERT INTO page_demo VALUES(1, 100, 'aaaa'), (2, 200, 'bbbb'), (3, 300, 'cccc'), (4, 400, 'dddd');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
Nach dem Login kopieren
Nach dem Login kopieren
Diese neu erstellte page_demo-Tabelle hat 3 Spalten, davon c1 und c2 werden zum Speichern von Ganzzahlen verwendet, und die Spalte c3 wird zum Speichern von Zeichenfolgen verwendet. Es ist zu beachten, dass wir die Spalte 🎜c1🎜 als Primärschlüssel angeben, sodass InnoDB im spezifischen Zeilenformat nicht die sogenannte 🎜row_id🎜erstellen muss > für uns. Spalte ausgeblendet. Und wir haben den Zeichensatz ascii und das Zeilenformat Compact für diese Tabelle angegeben. Das in dieser Tabelle aufgezeichnete Zeilenformatdiagramm sieht also wie folgt aus: 🎜🎜🎜Wie Sie auf dem Bild sehen können, haben wir absichtlich die 5-Byte-Daten von Datensatz-Header-Informationen eingefügt Es ist markiert, was darauf hinweist, dass es sehr wichtig ist. Sehen wir uns noch einmal die allgemeine Bedeutung jedes Attributs in diesen Datensatz-Header-Informationen an (wir verwenden derzeit das Zeilenformat Kompakt). Demonstration): 🎜
| Name |
Größe (Einheit: Bit) |
Beschreibung | 🎜 thead>
🎜Reserviertes Bit 1🎜🎜1🎜🎜 wird nicht verwendet🎜🎜
🎜Reserviertes Bit 2 🎜🎜 1🎜🎜 wird nicht verwendet🎜🎜
🎜delete_mask🎜🎜1🎜🎜markieren, ob der Datensatz gelöscht wird🎜🎜🎜 min_rec_mask🎜🎜1🎜🎜Dem Mindestdatensatz in jeder Ebene von Nicht-Blattknoten des B+-Baums wird diese Markierung hinzugefügt🎜🎜
🎜n_owned 🎜🎜4🎜🎜 gibt die Anzahl der Datensätze an, die dem aktuellen Datensatz gehören 🎜🎜
🎜heap_no🎜🎜13🎜🎜 zeigt an, dass sich der aktuelle Datensatz im Datensatz befindet. Die Standortinformationen des Heaps🎜🎜<tr>🎜<code>record_type🎜🎜3🎜🎜 repräsentieren den Typ von Der aktuelle Datensatz, 0 stellt einen gewöhnlichen Datensatz dar, 1 stellt einen B+-Baum-Nicht-Blattknoten-Datensatz dar, 2 stellt den minimalen Datensatz dar, 3 stellt den maximalen Datensatz dar🎜🎜
🎜next_record🎜🎜16🎜🎜 stellt die relative Position des nächsten Datensatzes dar🎜🎜🎜🎜由于我们现在主要在唠叨记录头信息的作用,所以为了大家理解上的方便,我们只在page_demo表的行格式演示图中画出有关的头信息属性以及c1、c2、c3列的信息(其他信息没画不代表它们不存在啊,只是为了理解上的方便在图中省略了~),简化后的行格式示意图就是这样:
下边我们试着向page_demo表中插入几条记录:
mysql> INSERT INTO page_demo VALUES(1, 100, 'aaaa'), (2, 200, 'bbbb'), (3, 300, 'cccc'), (4, 400, 'dddd');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
Nach dem Login kopieren
Nach dem Login kopieren
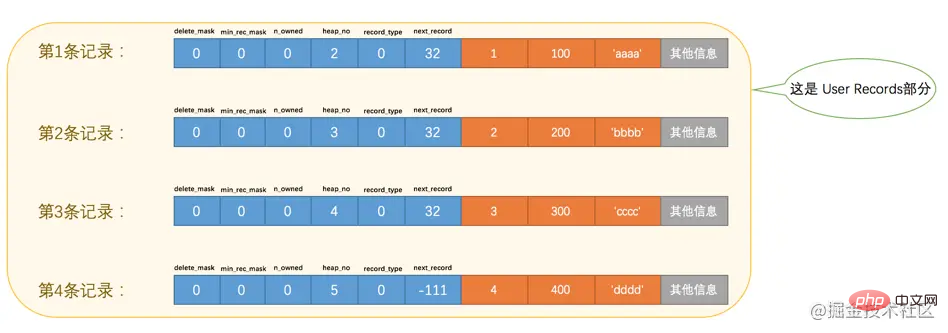
为了方便大家分析这些记录在页的User Records部分中是怎么表示的,我把记录中头信息和实际的列数据都用十进制表示出来了(其实是一堆二进制位),所以这些记录的示意图就是:
看这个图的时候需要注意一下,各条记录在User Records中存储的时候并没有空隙,这里只是为了大家观看方便才把每条记录单独画在一行中。我们对照着这个图来看看记录头信息中的各个属性是啥意思:
-
delete_mask
这个属性标记着当前记录是否被删除,占用1个二进制位,值为0的时候代表记录并没有被删除,为1的时候代表记录被删除掉了。
啥?被删除的记录还在页中么?是的,摆在台面上的和背地里做的可能大相径庭,你以为它删除了,可它还在真实的磁盘上[摊手](忽然想起冠希~)。这些被删除的记录之所以不立即从磁盘上移除,是因为移除它们之后把其他的记录在磁盘上重新排列需要性能消耗,所以只是打一个删除标记而已,所有被删除掉的记录都会组成一个所谓的垃圾链表,在这个链表中的记录占用的空间称之为所谓的可重用空间,之后如果有新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉。
-
min_rec_mask
B+树的每层非叶子节点中的最小记录都会添加该标记,什么是个B+树?什么是个非叶子节点?好吧,等会再聊这个问题。反正我们自己插入的四条记录的min_rec_mask值都是0,意味着它们都不是B+树的非叶子节点中的最小记录。
-
n_owned
这个暂时保密,稍后它是主角~
-
heap_no
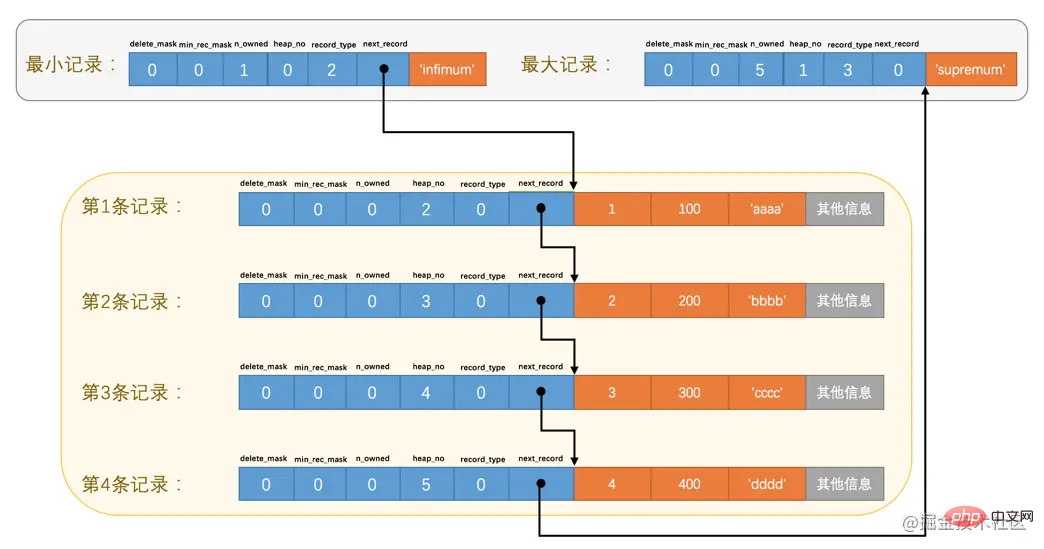
这个属性表示当前记录在本页中的位置,从图中可以看出来,我们插入的4条记录在本页中的位置分别是:2、3、4、5。是不是少了点啥?是的,怎么不见heap_no值为0和1的记录呢?
这其实是设计InnoDB的大叔们玩的一个小把戏,他们自动给每个页里边儿加了两个记录,由于这两个记录并不是我们自己插入的,所以有时候也称为伪记录或者虚拟记录。这两个伪记录一个代表最小记录,一个代表最大记录,等一下哈~,记录可以比大小么?
是的,记录也可以比大小,对于一条完整的记录来说,比较记录的大小就是比较主键的大小。比方说我们插入的4行记录的主键值分别是:1、2、3、4,这也就意味着这4条记录的大小从小到大依次递增。
-
但是不管我们向页中插入了多少自己的记录,设计InnoDB的大叔们都规定他们定义的两条伪记录分别为最小记录与最大记录。这两条记录的构造十分简单,都是由5字节大小的记录头信息和8字节大小的一个固定的部分组成的,如图所示
由于这两条记录不是我们自己定义的记录,所以它们并不存放在页的User Records部分,他们被单独放在一个称为Infimum + Supremum的部分,如图所示:
从图中我们可以看出来,最小记录和最大记录的heap_no值分别是0和1,也就是说它们的位置最靠前。
-
record_type
这个属性表示当前记录的类型,一共有4种类型的记录,0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录。从图中我们也可以看出来,我们自己插入的记录就是普通记录,它们的record_type值都是0,而最小记录和最大记录的record_type值分别为2和3。
至于record_type为1的情况,我们之后在说索引的时候会重点强调的。
-
next_record
这玩意儿非常重要,它表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。比方说第一条记录的next_record值为32,意味着从第一条记录的真实数据的地址处向后找32个字节便是下一条记录的真实数据。如果你熟悉数据结构的话,就立即明白了,这其实是个链表,可以通过一条记录找到它的下一条记录。但是需要注意注意再注意的一点是,下一条记录指得并不是按照我们插入顺序的下一条记录,而是按照主键值由小到大的顺序的下一条记录。而且规定 Infimum记录(也就是最小记录) 的下一条记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的下一条记录就是 Supremum记录(也就是最大记录) ,为了更形象的表示一下这个next_record起到的作用,我们用箭头来替代一下next_record中的地址偏移量:
从图中可以看出来,我们的记录按照主键从小到大的顺序形成了一个单链表。最大记录的next_record的值为0,这也就是说最大记录是没有下一条记录了,它是这个单链表中的最后一个节点。如果从中删除掉一条记录,这个链表也是会跟着变化的,比如我们把第2条记录删掉:
mysql> DELETE FROM page_demo WHERE c1 = 2;
Query OK, 1 row affected (0.02 sec)
Nach dem Login kopieren
删掉第2条记录后的示意图就是:
从图中可以看出来,删除第2条记录前后主要发生了这些变化:
- 第2条记录并没有从存储空间中移除,而是把该条记录的
delete_mask值设置为1。
- 第2条记录的
next_record值变为了0,意味着该记录没有下一条记录了。
- 第1条记录的
next_record指向了第3条记录。
- 还有一点你可能忽略了,就是
最大记录的n_owned值从5变成了4,关于这一点的变化我们稍后会详细说明的。
所以,不论我们怎么对页中的记录做增删改操作,InnoDB始终会维护一条记录的单链表,链表中的各个节点是按照主键值由小到大的顺序连接起来的。
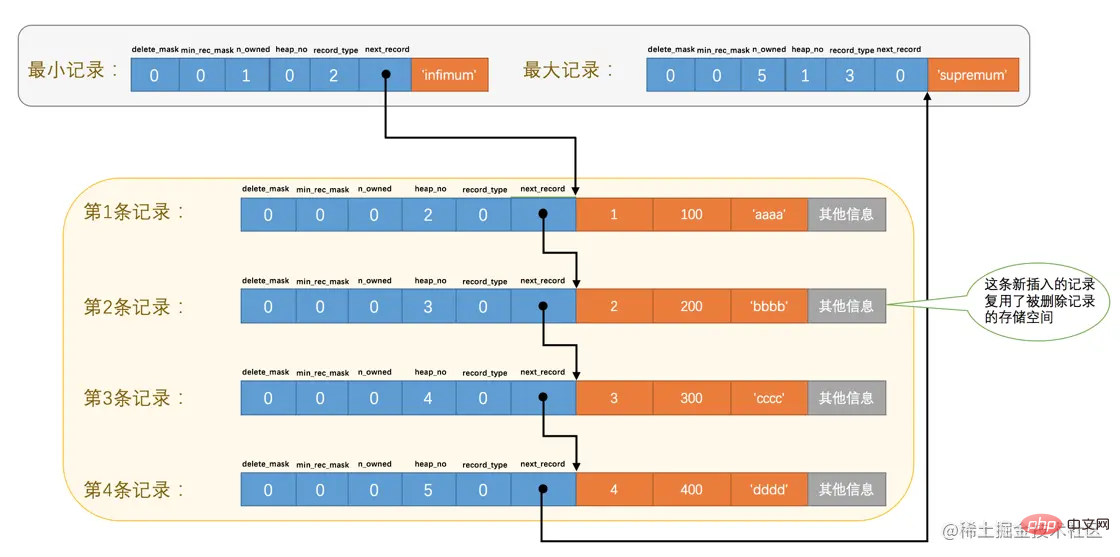
再来看一个有意思的事情,因为主键值为2的记录被我们删掉了,但是存储空间却没有回收,如果我们再次把这条记录插入到表中,会发生什么事呢?
mysql> INSERT INTO page_demo VALUES(2, 200, 'bbbb');
Query OK, 1 row affected (0.00 sec)
Nach dem Login kopieren
我们看一下记录的存储情况:
从图中可以看到,InnoDB并没有因为新记录的插入而为它申请新的存储空间,而是直接复用了原来被删除记录的存储空间。
Page Directory(页目录)
现在我们了解了记录在页中按照主键值由小到大顺序串联成一个单链表,那如果我们想根据主键值查找页中的某条记录该咋办呢?比如说这样的查询语句:
SELECT * FROM page_demo WHERE c1 = 3;
Nach dem Login kopieren
最笨的办法:从Infimum记录(最小记录)开始,沿着链表一直往后找,总有一天会找到(或者找不到[摊手]),在找的时候还能投机取巧,因为链表中各个记录的值是按照从小到大顺序排列的,所以当链表的某个节点代表的记录的主键值大于你想要查找的主键值时,你就可以停止查找了,因为该节点后边的节点的主键值依次递增。
Diese Methode ist kein Problem, wenn die Anzahl der auf der Seite gespeicherten Datensätze relativ gering ist. Unsere Tabelle enthält jetzt beispielsweise nur 4 Datensätze, die wir eingefügt haben, sodass wir 4 unter finden können Meistens können alle Datensätze mal durchlaufen werden, aber wenn eine Seite viele Datensätze speichert, führt eine solche Suche immer noch zu Leistungseinbußen, daher sagen wir, dass diese Art der Durchlaufsuche eine Dummheit way. Aber wer sind die Onkel, die <code>InnoDB entworfen haben? Können sie eine so dumme Methode verwenden? Natürlich haben sie sich vom Inhaltsverzeichnis des Buches inspirieren lassen. 4条自己插入的记录,所以最多找4次就可以把所有记录都遍历一遍,但是如果一个页中存储了非常多的记录,这么查找对性能来说还是有损耗的,所以我们说这种遍历查找这是一个笨办法。但是设计InnoDB的大叔们是什么人,他们能用这么笨的办法么,当然是要设计一种更6的查找方式喽,他们从书的目录中找到了灵感。
我们平常想从一本书中查找某个内容的时候,一般会先看目录,找到需要查找的内容对应的书的页码,然后到对应的页码查看内容。设计InnoDB的大叔们为我们的记录也制作了一个类似的目录,他们的制作过程是这样的:
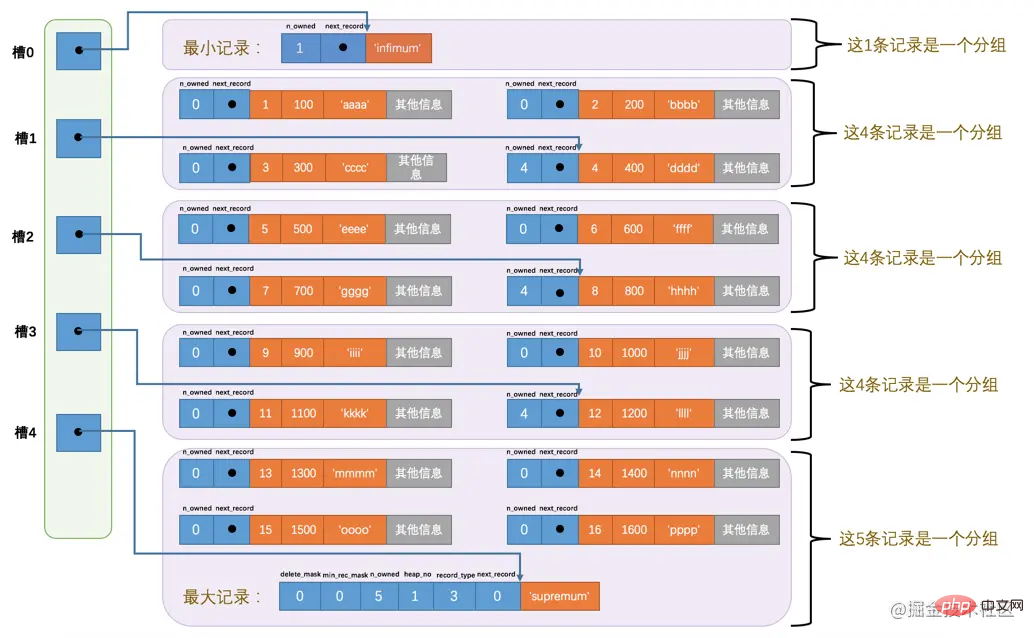
将所有正常的记录(包括最大和最小记录,不包括标记为已删除的记录)划分为几个组。
每个组的最后一条记录(也就是组内最大的那条记录)的头信息中的n_owned属性表示该记录拥有多少条记录,也就是该组内共有几条记录。
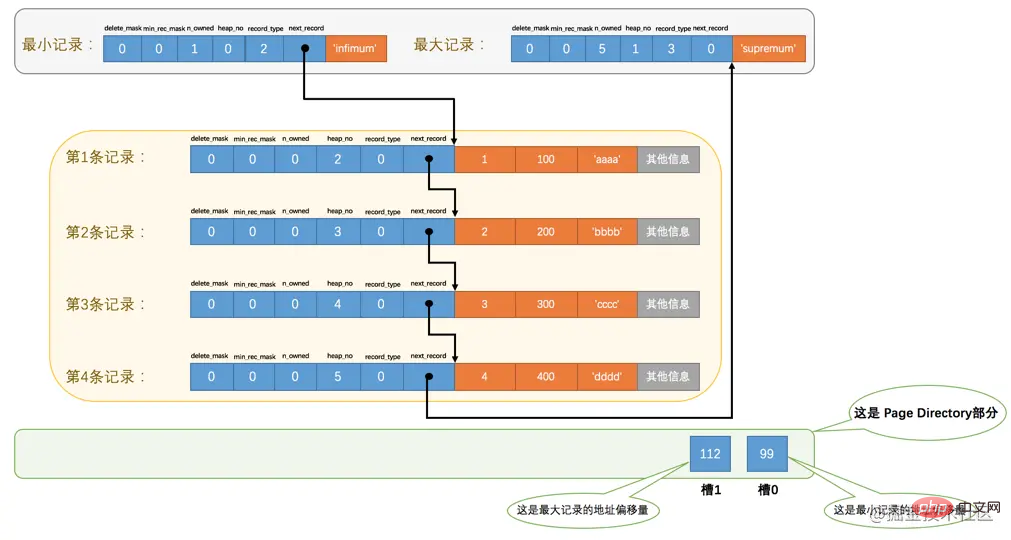
将每个组的最后一条记录的地址偏移量单独提取出来按顺序存储到靠近页的尾部的地方,这个地方就是所谓的Page Directory,也就是页目录(此时应该返回头看看页面各个部分的图)。页面目录中的这些地址偏移量被称为槽(英文名:Slot),所以这个页面目录就是由槽组成的。
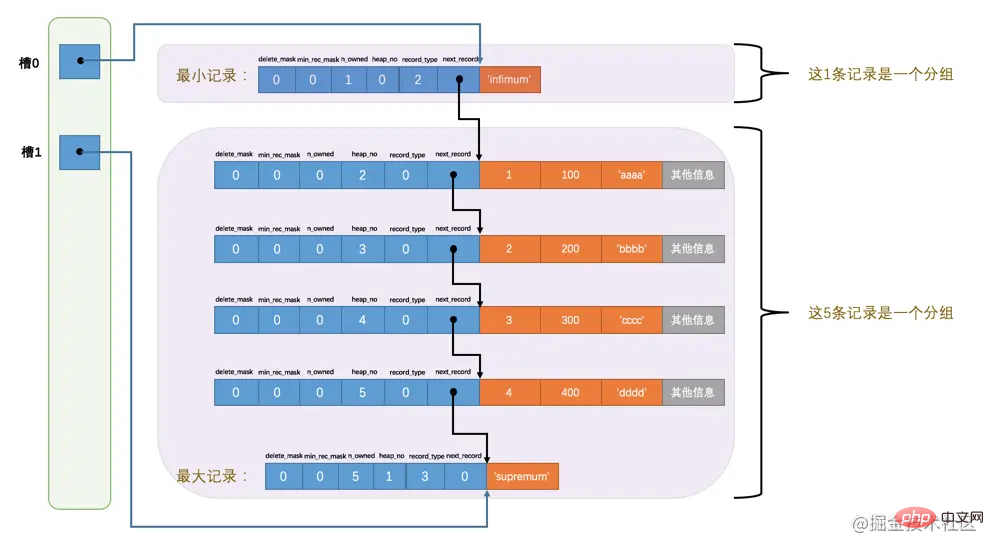
比方说现在的page_demo表中正常的记录共有6条,InnoDB会把它们分成两组,第一组中只有一个最小记录,第二组中是剩余的5条记录,看下边的示意图:
从这个图中我们需要注意这么几点:
99和112这样的地址偏移量很不直观,我们用箭头指向的方式替代数字,这样更易于我们理解,所以修改后的示意图就是这样:
哎呀,咋看上去怪怪的,这么乱的图对于我这个强迫症真是不能忍,那我们就暂时不管各条记录在存储设备上的排列方式了,单纯从逻辑上看一下这些记录和页目录的关系:
这样看就顺眼多了嘛!为什么最小记录的n_owned值为1,而最大记录的n_owned值为5呢,这里头有什么猫腻么?
是的,设计InnoDB的大叔们对每个分组中的记录条数是有规定的:对于最小记录所在的分组只能有 1 条记录,最大记录所在的分组拥有的记录条数只能在 1~8 条之间,剩下的分组中记录的条数范围只能在是 4~8 条之间。所以分组是按照下边的步骤进行的:
初始情况下一个数据页里只有最小记录和最大记录两条记录,它们分属于两个分组。
-
之后每插入一条记录,都会从页目录中找到主键值比本记录的主键值大并且差值最小的槽,然后把该槽对应的记录的n_owned
Wenn wir normalerweise etwas in einem Buch finden möchten, schauen wir uns normalerweise zuerst das Inhaltsverzeichnis an, suchen die Seitenzahl des Buches, die dem Inhalt entspricht, den wir finden möchten, und gehen dann zur entsprechenden Seitenzahl, um das anzuzeigen Inhalt. Die Onkel, die InnoDB entworfen haben, haben auch ein ähnliches Verzeichnis für unsere Datensätze erstellt. Ihr Produktionsprozess ist wie folgt: 🎜
- 🎜Alle normalen Datensätze (einschließlich der größten und kleinsten Datensätze (mit Ausnahme der markierten Datensätze). wie gelöscht) sind in Gruppen unterteilt. 🎜
- 🎜Das Attribut
n_owned in den Header-Informationen des letzten Datensatzes jeder Gruppe (d. h. des größten Datensatzes in der Gruppe) gibt außerdem an, wie viele Datensätze der Datensatz hat Das heißt, wie viele Datensätze es in dieser Gruppe gibt. 🎜
- 🎜Extrahieren Sie den Adressoffset des letzten Datensatzes jeder Gruppe separat und speichern Sie sie nacheinander am Ende der
Seite. Dieser Ort ist der sogenannte Seitenverzeichnis, also Seitenverzeichnis (zu diesem Zeitpunkt sollten Sie zurück nach oben gehen und sich die Bilder jedes Teils der Seite ansehen). Diese Adressoffsets im Seitenverzeichnis werden Slot (englischer Name: Slot) genannt, daher besteht dieses Seitenverzeichnis aus Slot . 🎜
🎜Zum Beispiel gibt es derzeit 6 normale Datensätze in der Tabelle page_demo, die in die erste Gruppe unterteilt werden Es gibt nur einen Mindestdatensatz und die zweite Gruppe enthält die restlichen 5 Datensätze. Siehe das Diagramm unten: 🎜🎜🎜Wir müssen bei diesem Bild auf folgende Punkte achten:🎜
- 🎜Jetzt gibt es zwei Slots im Abschnitt
Seitenverzeichnis, was bedeutet, dass unsere Datensätze in zwei Gruppen unterteilt sind. Der Wert in Slot 1 ist 112Code > stellt den Adressoffset des größten Datensatzes dar (d. h., gezählt von Byte 0 der Seite, gezählt bis 112 Bytes); der Wert in <code>slot 0 ist 99 , Stellt den Adressoffset des kleinsten Datensatzes dar. 🎜
- 🎜Achten Sie auf das Attribut
n_owned in den Header-Informationen der minimalen und maximalen Datensätze. 🎜
- Der
n_owned-Wert von Der Mindestdatensatz ist 1, was bedeutet, dass es nur 1 Datensätze in der Gruppe gibt, die mit dem Mindestdatensatz endet, der der Mindestdatensatz selbst ist.
- Der
n_owned-Wert des größten Datensatzes ist 5, was bedeutet, dass es nur 5 in der Gruppe gibt, die mit endet der größte Datensatz Datensätze, einschließlich des maximalen Datensatzes selbst und von uns eingefügten 4 Datensätzen.
🎜Adressoffsets wie 99 und 112 sind sehr unintuitiv. Wir verwenden Pfeile, um darauf hinzuweisen. Anstelle von Zahlen ist es für uns einfacher zu verstehen, daher sieht das geänderte Diagramm so aus: 🎜🎜🎜Oh, es sieht seltsam aus, so ein unordentliches Bild ist für meine Zwangsstörung wirklich unerträglich, also lasst uns Unabhängig von der vorläufigen Anordnung der Datensätze auf dem Speichergerät betrachten Sie einfach die Beziehung zwischen diesen Datensätzen und dem Seitenverzeichnis logisch: 🎜
🎜🎜Auf diese Weise sieht es für das Auge viel angenehmer aus! Warum ist der n_owned-Wert des kleinsten Datensatzes 1, während der n_owned-Wert des größten Datensatzes 5 ist? Ist hier etwas faul? 🎜🎜Ja, die Onkel, die InnoDB entworfen haben, haben Vorschriften für die Anzahl der Datensätze in jeder Gruppe: Die Gruppe mit dem kleinsten Datensatz darf nur 1haben > Datensätze. Die Anzahl der Datensätze in der Gruppe, in der sich der größte Datensatz befindet, kann nur zwischen 1~8 liegen zwischen 4~8. Daher erfolgt die Gruppierung gemäß den folgenden Schritten: 🎜
由于现在page_demo表中的记录太少,无法演示添加了页目录之后加快查找速度的过程,所以再往page_demo表中添加一些记录:
mysql> INSERT INTO page_demo VALUES(5, 500, 'eeee'), (6, 600, 'ffff'), (7, 700, 'gggg'), (8, 800, 'hhhh'), (9, 900, 'iiii'), (10, 1000, 'jjjj'), (11, 1100, 'kkkk'), (12, 1200, 'llll'), (13, 1300, 'mmmm'), (14, 1400, 'nnnn'), (15, 1500, 'oooo'), (16, 1600, 'pppp');
Query OK, 12 rows affected (0.00 sec)
Records: 12 Duplicates: 0 Warnings: 0
Nach dem Login kopieren
哈,我们一口气又往表中添加了12条记录,现在页里边就一共有18条记录了(包括最小和最大记录),这些记录被分成了5个组,如图所示:
因为把16条记录的全部信息都画在一张图里太占地方,让人眼花缭乱的,所以只保留了用户记录头信息中的n_owned和next_record属性,也省略了各个记录之间的箭头,我没画不等于没有啊!现在看怎么从这个页目录中查找记录。因为各个槽代表的记录的主键值都是从小到大排序的,所以我们可以使用所谓的二分法来进行快速查找。5个槽的编号分别是:0、1、2、3、4,所以初始情况下最低的槽就是low=0,最高的槽就是high=4。比方说我们想找主键值为6的记录,过程是这样的:
计算中间槽的位置:(0+4)/2=2,所以查看槽2对应记录的主键值为8,又因为8 > 6,所以设置high=2,low保持不变。
重新计算中间槽的位置:(0+2)/2=1,所以查看槽1对应的主键值为4,又因为4 ,所以设置<code>low=1,high保持不变。
因为high - low的值为1,所以确定主键值为6的记录在槽2对应的组中。此刻我们需要找到槽2中主键值最小的那条记录,然后沿着单向链表遍历槽2中的记录。但是我们前边又说过,每个槽对应的记录都是该组中主键值最大的记录,这里槽2对应的记录是主键值为8的记录,怎么定位一个组中最小的记录呢?别忘了各个槽都是挨着的,我们可以很轻易的拿到槽1对应的记录(主键值为4),该条记录的下一条记录就是槽2中主键值最小的记录,该记录的主键值为5。所以我们可以从这条主键值为5的记录出发,遍历槽2中的各条记录,直到找到主键值为6的那条记录即可。由于一个组中包含的记录条数只能是1~8条,所以遍历一个组中的记录的代价是很小的。
所以在一个数据页中查找指定主键值的记录的过程分为两步:
通过二分法确定该记录所在的槽,并找到该槽所在分组中主键值最小的那条记录。
通过记录的next_record属性遍历该槽所在的组中的各个记录。
Page Header(页面头部)
设计InnoDB的大叔们为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等,特意在页中定义了一个叫Page Header的部分,它是页结构的第二部分,这个部分占用固定的56个字节,专门存储各种状态信息,具体各个字节都是干嘛的看下表:
| Name |
Speicherplatzgröße |
Beschreibung |
PAGE_N_DIR_SLOTSPAGE_N_DIR_SLOTS
|
2字节 |
在页目录中的槽数量 |
PAGE_HEAP_TOP |
2字节 |
还未使用的空间最小地址,也就是说从该地址之后就是Free Space
|
PAGE_N_HEAP |
2字节 |
本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
PAGE_FREE |
2字节 |
第一个已经标记为删除的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录可以被重新利用) |
PAGE_GARBAGE |
2字节 |
已删除记录占用的字节数 |
PAGE_LAST_INSERT |
2字节 |
最后插入记录的位置 |
PAGE_DIRECTION |
2字节 |
记录插入的方向 |
PAGE_N_DIRECTION |
2字节 |
一个方向连续插入的记录数量 |
PAGE_N_RECS |
2字节 |
该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
PAGE_MAX_TRX_ID |
8字节 |
修改当前页的最大事务ID,该值仅在二级索引中定义 |
PAGE_LEVEL |
2字节 |
当前页在B+树中所处的层级 |
PAGE_INDEX_ID |
8字节 |
索引ID,表示当前页属于哪个索引 |
PAGE_BTR_SEG_LEAF |
10字节 |
B+树叶子段的头部信息,仅在B+树的Root页定义 |
PAGE_BTR_SEG_TOP |
10 |
2 Bytes | Anzahl der Slots im Seitenverzeichnis
.
🎜 PAGE_HEAP_TOP🎜🎜2 Bytes🎜🎜Die minimale Adresse des ungenutzten Speicherplatzes, was bedeutet, dass nach dieser Adresse Freier Speicherplatz🎜 🎜🎜🎜PAGE_N_HEAP🎜🎜2 Bytes 🎜🎜Die Anzahl der Datensätze auf dieser Seite (einschließlich minimaler und maximaler Datensätze und zum Löschen markierter Datensätze) 🎜🎜🎜🎜PAGE_FREE 🎜🎜2Bytes🎜🎜Die erste Datensatzadresse, die zum Löschen markiert wurde (jeder gelöschte Datensatz bildet auch einen Datensatz durch next_record Einfach verknüpfte Liste, Datensätze in dieser einfach verknüpften Liste Liste kann wiederverwendet werden)🎜🎜🎜🎜PAGE_GARBAGE🎜🎜2 Bytes🎜🎜Die Anzahl der Bytes, die von gelöschten Datensätzen belegt werden🎜🎜 🎜🎜PAGE_LAST_INSERT 🎜🎜2Bytes🎜🎜Die letzte Position des eingefügten Datensatzes🎜🎜🎜🎜PAGE_DIRECTION🎜🎜2Byte 🎜🎜Die Richtung der Datensatzeinfügung 🎜🎜🎜🎜PAGE_N_DIRECTION🎜🎜2 Byte 🎜🎜Die Anzahl der kontinuierlich in eine Richtung eingefügten Datensätze🎜🎜🎜🎜PAGE_N_RECS 🎜🎜2 Bytes 🎜🎜Anzahl der Datensätze auf der Seite (mit Ausnahme der minimalen und maximalen Datensätze sowie der zum Löschen markierten Datensätze)🎜🎜🎜🎜PAGE_MAX_TRX_ID🎜🎜8 Bytes 🎜🎜Ändern Sie die maximale Transaktions-ID der aktuellen Seite. Dieser Wert ist nur in sekundären Indizes definiert Seite im B+-Baum🎜🎜🎜🎜PAGE_INDEX_ID🎜🎜8 Bytes🎜🎜Index-ID, die die aktuelle Seite angibt. Zu welchem Index 🎜🎜🎜🎜PAGE_BTR_SEG_LEAF🎜🎜<code>10 Bytes 🎜🎜Header-Informationen des B+-Baumblattsegments, nur auf der Stammseite des B+-Baums definiert🎜🎜🎜🎜 PAGE_BTR_SEG_TOP🎜🎜10 Bytes🎜🎜Header-Informationen von Nicht-Blatt-Segmenten des B+-Baums, nur auf der Stammseite des B+-Baums definiert🎜🎜🎜🎜Wenn Sie den vorherigen Artikel sorgfältig gelesen haben, müssen Sie sich über die Bedeutung von PAGE_N_DIR_SLOTS bis PAGE_LAST_INSERT und PAGE_N_RECS im Klaren sein , Es tut mir leid, Sie sollten zurückgehen und den vorherigen Artikel noch einmal lesen. Machen Sie sich keine Sorgen, wenn Sie die restlichen Statusinformationen nicht verstehen. Sie müssen einen Bissen nach dem anderen essen und die Dinge nach und nach lernen (stellen Sie sicher, dass Sie ruhig sind und sich von diesen Substantiven nicht erschrecken lassen). Hier sprechen wir zunächst über die Bedeutung von PAGE_DIRECTION und PAGE_N_DIRECTION:
-
PAGE_N_DIR_SLOTS到PAGE_LAST_INSERT以及PAGE_N_RECS的意思大家一定是清楚的,如果不清楚,对不起,你应该回头再看一遍前边的文章。剩下的状态信息看不明白不要着急,饭要一口一口吃,东西要一点一点学(一定要稍安勿躁哦,不要被这些名词吓到)。在这里我们先唠叨一下PAGE_DIRECTION和PAGE_N_DIRECTION的意思:
至于我们没提到的那些属性,我没说是因为现在不需要大家知道。不要着急,当我们学完了后边的内容,你再回头看,一切都是那么清晰。
File Header(文件头部)
上边唠叨的Page Header是专门针对数据页记录的各种状态信息,比方说页里头有多少个记录了呀,有多少个槽了呀。我们现在描述的File Header针对各种类型的页都通用,也就是说不同类型的页都会以File Header作为第一个组成部分,它描述了一些针对各种页都通用的一些信息,比方说这个页的编号是多少,它的上一个页、下一个页是谁啦吧啦吧啦~ 这个部分占用固定的38个字节,是由下边这些内容组成的:
| 名称 |
占用空间大小 |
描述 |
FIL_PAGE_SPACE_OR_CHKSUM |
4字节 |
页的校验和(checksum值) |
FIL_PAGE_OFFSET |
4字节 |
页号 |
FIL_PAGE_PREV |
4字节 |
上一个页的页号 |
FIL_PAGE_NEXT |
4字节 |
下一个页的页号 |
FIL_PAGE_LSN |
8字节 |
页面被最后修改时对应的日志序列位置(英文名是:Log Sequence Number) |
FIL_PAGE_TYPE |
2字节 |
该页的类型 |
FIL_PAGE_FILE_FLUSH_LSN |
8字节 |
仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID |
4PAGE_DIRECTION | Wenn der Primärschlüsselwert eines neu eingefügten Datensatzes größer ist als der Primärschlüsselwert des vorherigen Datensatzes, sagen wir, dass die Einfügerichtung dieses Datensatzes nach rechts verläuft und umgekehrt. Der Status zur Angabe der Einfügerichtung des letzten Datensatzes ist PAGE_DIRECTION. -
PAGE_N_DIRECTION | Angenommen, dass die Richtungen beim Einfügen neuer Datensätze mehrmals hintereinander konsistent sind, wird InnoDB dies tun Fügen Sie neue Datensätze entlang der Zeile ein. Erfassen Sie die Anzahl der in derselben Richtung eingefügten Datensätze. Diese Anzahl wird durch den Status PAGE_N_DIRECTION dargestellt. Wenn sich die Einfügerichtung des letzten Datensatzes ändert, wird der Wert dieses Status natürlich gelöscht und erneut gezählt.
Was die Attribute betrifft, die wir nicht erwähnt haben, habe ich sie nicht erwähnt, weil Sie sie jetzt nicht kennen müssen. Machen Sie sich keine Sorgen, wenn wir mit dem Erlernen der folgenden Inhalte fertig sind und Sie zurückblicken, wird alles so klar sein. Dateikopfzeile
Der oben erwähnte Seitenkopf besteht aus den verschiedenen Statusinformationen, die speziell für die Datenseite aufgezeichnet wurden, zum Beispiel wie viele Welche Datensätze sind auf der Seite vorhanden und wie viele Slots gibt es? Der Datei-Header, den wir jetzt beschreiben, ist für verschiedene Seitentypen gleich, was bedeutet, dass verschiedene Seitentypen Datei-Header als erste Komponente verwenden, die einige Informationen beschreibt ist für verschiedene Seiten gleich, z. B. wie lautet die Nummer dieser Seite, wer ist die vorherige Seite und die nächste Seite? Dieser Teil belegt feste 38 Bytes und besteht aus folgendem Inhalt:
| Name |
Platz belegt |
Beschreibung |
🎜FIL_PAGE_SPACE_OR_CHKSUM🎜🎜4 Bytes 🎜🎜Prüfsummenwert der Seite🎜 🎜
🎜FIL_PAGE_OFFSET🎜🎜4 code> Bytes 🎜🎜Seitennummer🎜🎜<tr>🎜<code>FIL_PAGE_PREV🎜🎜4Bytes🎜🎜Die Seitennummer der vorherigen Seite🎜🎜<tr>🎜<code> FIL_PAGE_NEXT🎜🎜4Bytes🎜🎜Die Seitennummer der nächsten Seite🎜🎜🎜FIL_PAGE_LSN🎜🎜8 Bytes 🎜🎜Die entsprechende Protokollsequenzposition, als die Seite zuletzt geändert wurde (englischer Name ist: Protokollsequenznummer)🎜🎜
🎜 FIL_PAGE_TYPE🎜🎜2Bytes🎜🎜Die Typ der Seite🎜🎜
🎜FIL_PAGE_FILE_FLUSH_LSN🎜🎜8 Bytes 🎜🎜 werden nur auf einer Seite des Systemtabellenbereichs definiert, was bedeutet, dass die Datei vorhanden ist mindestens auf den entsprechenden LSN-Wert geleert 🎜🎜
🎜FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID🎜🎜4 Wörter Zu welchem Tabellenbereich gehört der Abschnitt 🎜🎜 Seite 🎜🎜🎜🎜Im Vergleich zu dieser Tabelle schauen wir uns einige derzeit wichtige Teile an:
-
FIL_PAGE_SPACE_OR_CHKSUMFIL_PAGE_SPACE_OR_CHKSUM
这个代表当前页面的校验和(checksum)。啥是个校验和?就是对于一个很长很长的字节串来说,我们会通过某种算法来计算一个比较短的值来代表这个很长的字节串,这个比较短的值就称为校验和。这样在比较两个很长的字节串之前先比较这两个长字节串的校验和,如果校验和都不一样两个长字节串肯定是不同的,所以省去了直接比较两个比较长的字节串的时间损耗。
-
FIL_PAGE_OFFSET
每一个页都有一个单独的页号,就跟你的身份证号码一样,InnoDB通过页号来可以唯一定位一个页。
-
FIL_PAGE_TYPE
这个代表当前页的类型,我们前边说过,InnoDB为了不同的目的而把页分为不同的类型,我们上边介绍的其实都是存储记录的数据页,其实还有很多别的类型的页,具体如下表:
| 类型名称 |
十六进制 |
描述 |
FIL_PAGE_TYPE_ALLOCATED |
0x0000 |
最新分配,还没使用 |
FIL_PAGE_UNDO_LOG |
0x0002 |
Undo日志页 |
FIL_PAGE_INODE |
0x0003 |
段信息节点 |
FIL_PAGE_IBUF_FREE_LIST |
0x0004 |
Insert Buffer空闲列表 |
FIL_PAGE_IBUF_BITMAP |
0x0005 |
Insert Buffer位图 |
FIL_PAGE_TYPE_SYS |
0x0006 |
系统页 |
FIL_PAGE_TYPE_TRX_SYS |
0x0007 |
事务系统数据 |
FIL_PAGE_TYPE_FSP_HDR |
0x0008 |
表空间头部信息 |
FIL_PAGE_TYPE_XDES |
0x0009 |
扩展描述页 |
FIL_PAGE_TYPE_BLOB |
0x000A |
溢出页 |
FIL_PAGE_INDEX |
0x45BF |
索引页,也就是我们所说的数据页
| Dies stellt die Prüfsumme der aktuellen Seite dar. Was ist eine Prüfsumme? Für eine sehr lange Byte-Zeichenfolge verwenden wir einen Algorithmus, um einen kürzeren Wert zur Darstellung der langen Byte-Zeichenfolge zu berechnen. Dieser kürzere Wert wird als check and bezeichnet. Vergleichen Sie auf diese Weise vor dem Vergleich zweier sehr langer Byte-Strings zunächst die Prüfsummen dieser beiden langen Byte-Strings. Wenn die Prüfsummen unterschiedlich sind, müssen die beiden langen Byte-Strings unterschiedlich sein, sodass ein direkter Vergleich entfällt lange Byte-Strings.
FIL_PAGE_OFFSET🎜🎜Jede Seite hat eine separate Seitennummer, genau wie Ihre ID-Nummer, InnoDB code>A <code> page kann durch die Seitenzahl eindeutig lokalisiert werden. 🎜
🎜🎜FIL_PAGE_TYPE🎜🎜Dies stellt den Typ der aktuellen Seite dar. Wie wir bereits sagten, verwendet InnoDB ihn für verschiedene Zwecke Die oben vorgestellten Seiten sind eigentlich Datenseiten, die Datensätze speichern, wie in der folgenden Tabelle aufgeführt: 🎜
| Typname |
Hex |
Beschreibung | 🎜
FIL_PAGE_TYPE_ALLOCATED🎜 |
0x0000🎜 |
Neueste Zuordnung, noch nicht verwendet🎜🎜 |
FIL_PAGE_UNDO_LOG🎜 |
0x0002🎜 |
Protokoll rückgängig machen Seite🎜 🎜 |
FIL_PAGE_INODE🎜 |
0x0003🎜 |
Segmentinformationsknoten🎜🎜 |
FIL_PAGE_IBUF_FREE_LIST🎜 |
0x0004 🎜Pufferfreie Liste einfügen🎜🎜 |
FIL_PAGE_IBUF_BITMAP🎜 |
0x0005🎜 |
Pufferbitmap einfügen🎜🎜 |
FIL_PAGE_TYPE_SYS Code >🎜<td>0x0006🎜</td>
<td>Systemseite🎜🎜</td>
<tr>
<td>
<code>FIL_PAGE_TYPE_TRX_SYS🎜 |
0x0007🎜 |
Transaktionssystemdaten🎜🎜 |
| FIL_PAGE_TYPE_FSP_HDR🎜 |
0x0008🎜 |
Informationen zum Tabellenbereichskopf🎜🎜 |
FIL_PAGE_TYPE_XDES🎜 |
0x0009🎜 |
Erweiterte Beschreibungsseite🎜🎜 |
FIL_PAGE_TYPE_BLOB🎜 |
0x000A🎜 |
Überlaufseite🎜🎜 |
FIL_PAGE_INDEX🎜 |
0x45BF🎜 |
Indexseite, die wir Datenseite nennen🎜🎜🎜🎜Der Typ der Datenseite, auf der wir Datensätze speichern, ist eigentlich FIL_PAGE_INDEX, die sogenannte Indexseite. Was ein Index ist, hören wir uns das nächste Mal die Aufschlüsselung an basiert auf Daten, die in Seiten gespeichert werden. Wenn wir einen bestimmten Datentyp speichern, nimmt er manchmal sehr viel Platz ein (z. B. kann es Tausende von Datensätzen in einer Tabelle geben). code> ist möglicherweise nicht in der Lage, alle Daten auf einmal zu speichern. Wenn sie verstreut und auf mehreren diskontinuierlichen Seiten gespeichert sind, müssen diese Seiten verknüpft werden FIL_PAGE_NEXT repräsentiert jeweils die Seitenzahlen der vorherigen und nächsten Seiten auf dieser Seite. Auf diese Weise werden viele Seiten in Reihe geschaltet, indem eine doppelt verknüpfte Liste erstellt wird, ohne dass diese Seiten physisch verbunden werden müssen. Es ist zu beachten, dass nicht alle Seitentypen die Eigenschaften der vorherigen und nächsten Seiten haben, sondern die Datenseite, über die wir in dieser Episode sprechen (d. h. der Typ ist FIL_PAGE_INDEX page) hat diese beiden Attribute, sodass alle Datenseiten tatsächlich eine doppelt verknüpfte Liste sind, wie folgt: <code>FIL_PAGE_INDEX,也就是所谓的索引页。至于啥是个索引,且听下回分解~
-
FIL_PAGE_PREV和FIL_PAGE_NEXT
我们前边强调过,InnoDB都是以页为单位存放数据的,有时候我们存放某种类型的数据占用的空间非常大(比方说一张表中可以有成千上万条记录),InnoDB可能不可以一次性为这么多数据分配一个非常大的存储空间,如果分散到多个不连续的页中存储的话需要把这些页关联起来,FIL_PAGE_PREV和FIL_PAGE_NEXT就分别代表本页的上一个和下一个页的页号。这样通过建立一个双向链表把许许多多的页就都串联起来了,而无需这些页在物理上真正连着。需要注意的是,并不是所有类型的页都有上一个和下一个页的属性,不过我们本集中唠叨的数据页(也就是类型为FIL_PAGE_INDEX的页)是有这两个属性的,所以所有的数据页其实是一个双链表,就像这样:
关于File Header的其他属性我们暂时用不到,等用到的时候再提哈~
File Trailer
我们知道InnoDB存储引擎会把数据存储到磁盘上,但是磁盘速度太慢,需要以页为单位把数据加载到内存中处理,如果该页中的数据在内存中被修改了,那么在修改后的某个时间需要把数据同步到磁盘中。但是在同步了一半的时候中断电了咋办,这不是莫名尴尬么?为了检测一个页是否完整(也就是在同步的时候有没有发生只同步一半的尴尬情况),设计InnoDB的大叔们在每个页的尾部都加了一个File Trailer部分,这个部分由8个字节组成,可以分成2个小部分:
-
前4个字节代表页的校验和
这个部分是和File Header中的校验和相对应的。每当一个页面在内存中修改了,在同步之前就要把它的校验和算出来,因为File Header在页面的前边,所以校验和会被首先同步到磁盘,当完全写完时,校验和也会被写到页的尾部,如果完全同步成功,则页的首部和尾部的校验和应该是一致的。如果写了一半儿断电了,那么在File Header中的校验和就代表着已经修改过的页,而在File Trailer中的校验和代表着原先的页,二者不同则意味着同步中间出了错。
-
后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
这个部分也是为了校验页的完整性的,只不过我们目前还没说LSN是个什么意思,所以大家可以先不用管这个属性。
这个File Trailer与File Header类似,都是所有类型的页通用的。
总结
InnoDB为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做数据页。 -
一个数据页可以被大致划分为7个部分,分别是
-
File Header,表示页的一些通用信息,占固定的38字节。
-
Page Header,表示数据页专有的一些信息,占固定的56个字节。
-
Infimum + Supremum,两个虚拟的伪记录,分别表示页中的最小和最大记录,占固定的26个字节。
-
User Records:真实存储我们插入的记录的部分,大小不固定。
-
Free Space:页中尚未使用的部分,大小不确定。
-
Page Directory:页中的某些记录相对位置,也就是各个槽在页面中的地址偏移量,大小不固定,插入的记录越多,这个部分占用的空间越多。
-
File Trailer:用于检验页是否完整的部分,占用固定的8个字节。
每个记录的头信息中都有一个next_record属性,从而使页中的所有记录串联成一个单链表。 -
InnoDB会把页中的记录划分为若干个组,每个组的最后一个记录的地址偏移量作为一个槽,存放在Page Directory
- Über
File HeaderWir haben gewonnen' Die anderen Attribute von > werden wir vorerst nicht verwenden, aber wir werden sie erwähnen, wenn wir dies tun.
File TrailerWir wissen, dass die InnoDB-Speicher-Engine Daten auf dem speichert Die Festplattengeschwindigkeit ist jedoch zu langsam und die Daten müssen in Einheiten von page zur Verarbeitung in den Speicher geladen werden zu einem bestimmten Zeitpunkt nach der Änderung in den Speicher geladen werden. Aber was soll ich tun, wenn die Stromversorgung mitten in der Synchronisierung unterbrochen wird? Ist das nicht umständlich? Um zu überprüfen, ob eine Seite vollständig ist (das heißt, ob es eine peinliche Situation gibt, dass während der Synchronisierung nur die Hälfte der Seite synchronisiert wird), haben die Onkel, die InnoDB entworfen haben, eine Datei hinzugefügt am Ende jeder Seite. Trailer-Teil, dieser Teil besteht aus 8 Bytes, die in 2 kleine Teile unterteilt werden können:
-
Die ersten 4 Bytes stellen die Prüfsumme der Seite dar 🎜🎜Dieser Teil entspricht der Prüfsumme im
Dateikopf. Immer wenn eine Seite im Speicher geändert wird, muss ihre Prüfsumme vor der Synchronisierung berechnet werden. Da sich File Header am Anfang der Seite befindet, wird die Prüfsumme zuerst auf die Festplatte synchronisiert auch an das Ende der Seite geschrieben werden. Bei erfolgreicher vollständiger Synchronisierung sollten die Prüfsummen am Anfang und Ende der Seite konsistent sein. Wenn der Strom während des Schreibens unterbrochen wird, stellt die Prüfsumme im File Header die geänderte Seite dar und die Prüfsumme im File Trailer stellt die Originalseite dar. Wenn die beiden unterschiedlich sind, Dies bedeutet, dass während der Synchronisierung ein Fehler aufgetreten ist. 🎜🎜🎜🎜Die letzten 4 Bytes stellen die entsprechende Protokollsequenzposition (LSN) dar, als die Seite zuletzt geändert wurde🎜🎜Dieser Teil dient auch der Überprüfung der Integrität der Seite, aber wir haben noch nicht LSN gesagt Was bedeutet code>? Sie können dieses Attribut also vorerst ignorieren. 🎜🎜🎜Dieser <code>Datei-Trailer ähnelt dem Datei-Header und ist für alle Seitentypen gleich. 🎜Zusammenfassung
🎜🎜InnoDB entwirft verschiedene Arten von Seiten für unterschiedliche Zwecke. Wir nennen die Seite, die zum Speichern von Datensätzen verwendet wird, Datenseite. 🎜🎜🎜🎜Eine Datenseite kann grob in 7 Teile unterteilt werden: 🎜🎜🎜Dateikopf, der einige allgemeine Informationen der Seite darstellt und feste 38 Bytes belegt. 🎜🎜Seitenkopf stellt einige Informationen exklusiv für die Datenseite dar und belegt feste 56 Bytes. 🎜🎜Infimum + Supremum, zwei virtuelle Pseudodatensätze, die jeweils die minimalen und maximalen Datensätze auf der Seite darstellen und feste 26 Bytes belegen. 🎜🎜Benutzerdatensätze: Der Teil, der die von uns eingefügten Datensätze tatsächlich speichert, die Größe ist nicht festgelegt. 🎜🎜Freier Speicherplatz: Der ungenutzte Teil der Seite, die Größe ist ungewiss. 🎜🎜Seitenverzeichnis: Die relative Position bestimmter Datensätze auf der Seite, also der Adressversatz jedes Slots auf der Seite, ist in der Größe nicht festgelegt. Je mehr Datensätze eingefügt werden, desto mehr Platz wird benötigt Teil nimmt viele ein. 🎜🎜File Trailer: Wird verwendet, um zu überprüfen, ob die Seite vollständig ist und feste 8 Bytes belegt. 🎜🎜🎜🎜Die Header-Informationen jedes Datensatzes verfügen über ein next_record-Attribut, sodass alle Datensätze auf der Seite zu einer einfach verknüpften Liste verkettet werden. 🎜🎜🎜🎜InnoDB unterteilt die Datensätze auf der Seite in mehrere Gruppen. Der Adressoffset des letzten Datensatzes in jeder Gruppe wird als Slot verwendet und in Seitenverzeichnis , sodass es sehr schnell ist, einen Datensatz basierend auf dem Primärschlüssel auf einer Seite zu finden. Er ist in zwei Schritte unterteilt: 🎜🎜🎜🎜 Bestimmen Sie den Slot, in dem sich der Datensatz befindet, mithilfe der Dichotomiemethode . 🎜🎜🎜🎜Durchlaufen Sie jeden Datensatz in der Gruppe, in der sich der Slot befindet, über das Attribut next_record des Datensatzes. 🎜
Der Dateikopf-Teil jeder Datenseite enthält die Nummern der vorherigen und nächsten Seiten, sodass alle Datenseiten eine doppelt verknüpfte Liste bilden. File Header部分都有上一个和下一个页的编号,所以所有的数据页会组成一个双链表。 为保证从内存中同步到磁盘的页的完整性,在页的首部和尾部都会存储页中数据的校验和和页面最后修改时对应的LSN值,如果首部和尾部的校验和和LSN Um die Integrität der vom Speicher auf die Festplatte synchronisierten Seiten sicherzustellen, werden am Anfang und am Ende die Prüfsumme der Daten auf der Seite und der entsprechende LSN-Wert zum Zeitpunkt der letzten Änderung der Seite gespeichert Wenn die Prüfsumme und der LSN-Wert des Headers und Trailers nicht erfolgreich überprüft werden, liegt ein Problem mit dem Synchronisierungsprozess vor.
Empfohlenes Lernen: 🎜MySQL-Video-Tutorial🎜🎜 |
Das obige ist der detaillierte Inhalt vonEingehende Untersuchung der InnoDB-Datenseite der MySQL-Prinzipien. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



 🎜🎜Wie Sie auf dem Bild sehen können, haben wir absichtlich die 5-Byte-Daten von
🎜🎜Wie Sie auf dem Bild sehen können, haben wir absichtlich die 5-Byte-Daten von  MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen












![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



