
 Datenbank
MySQL-Tutorial
Lassen Sie uns über Mycats Implementierung der Lese- und Schreibtrennung von MySQL-Clustern sprechen
Datenbank
MySQL-Tutorial
Lassen Sie uns über Mycats Implementierung der Lese- und Schreibtrennung von MySQL-Clustern sprechen
Lassen Sie uns über Mycats Implementierung der Lese- und Schreibtrennung von MySQL-Clustern sprechen

Dieser Artikel führt Sie in das relevante Wissen über die Lese- und Schreibtrennung von MySQL ein und hoffe, dass er Ihnen hilfreich sein wird.

Überblick über die Lese-/Schreibtrennung von MySQL
MySQL ist derzeit die am weitesten verbreitete kostenlose Datenbank der Welt. Ich glaube, dass alle Ingenieure, die sich mit Systembetrieb und -wartung befassen, damit in Berührung gekommen sein müssen.
In einer tatsächlichen Produktionsumgebung kann ein einzelnes MySQL als unabhängige Datenbank die tatsächlichen Anforderungen überhaupt nicht erfüllen, unabhängig von Sicherheit, hoher Verfügbarkeit und hoher Parallelität.
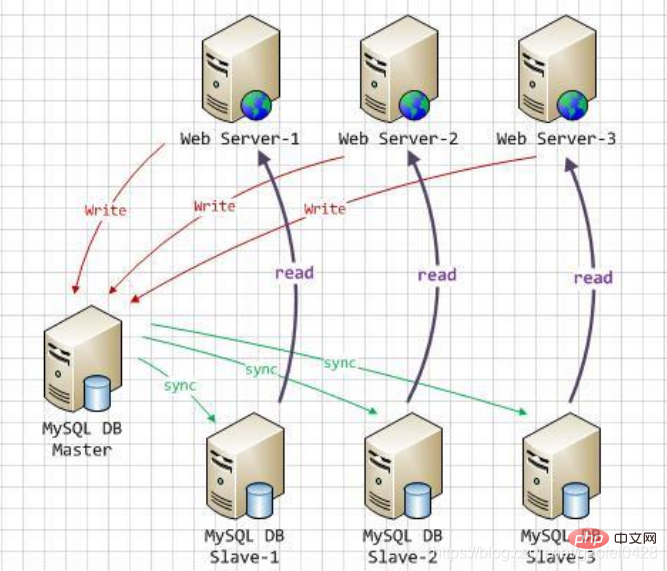
Daher werden Daten im Allgemeinen synchronisiert durch Master-Slave-Replikation und dann durch Lese-Schreib-Trennung (MySQL-Proxy/Amoeba), um die gleichzeitige Belastung der Datenbankfähigkeit zu erhöhen bereitstellen und umsetzen.
Das Funktionsprinzip der Lese- und Schreibtrennung
Das Grundprinzip ist:
-
Die Hauptdatenbank verarbeitet transaktionale Hinzufügungs-, Änderungs- und Löschvorgänge (INSERT, UPDATE, DELETE)
Verarbeitung von SELECT-Abfragevorgängen aus der Datenbank
Datenbankreplikation wird verwendet, um durch Transaktionsvorgänge verursachte Änderungen mit der Slave-Datenbank im Cluster zu synchronisieren.
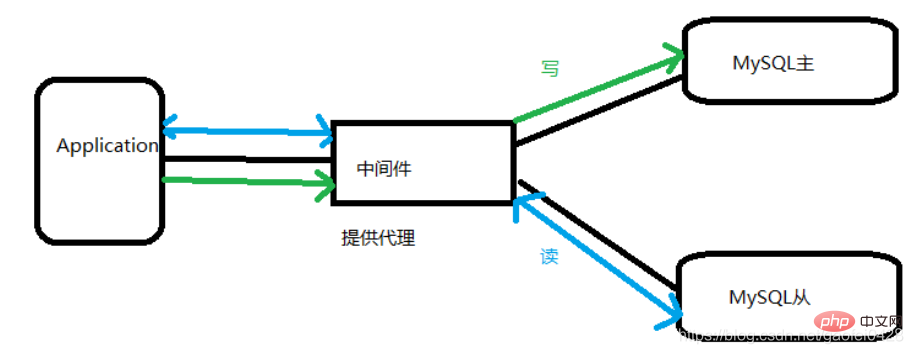
Warum Lese- und Schreibtrennung? Nur Master-Slave. Verantwortlich für das jeweilige Schreiben und Lesen, wodurch X-(Schreib-)Sperren- und S-(Lesen-)Sperrenkonflikte erheblich gemindert werden. Die Myisam-Engine kann über die Datenbank konfiguriert werden, um die Abfrageleistung zu verbessern und Systemaufwand zu sparen Erhöhen Sie die Redundanz, verbessern Sie die Benutzerfreundlichkeit.
- Möglichkeiten, eine Lese-/Schreibtrennung zu erreichen Und die Lese- und Schreibtrennung wird im Connector realisiert
- Vorteile:
- Die Lese- und Schreibtrennung wird innerhalb der Anwendung realisiert und die Installation kann verwendet werden, um bestimmte Bereitstellungsschwierigkeiten zu reduzieren
Der Zugriffsdruck liegt unter einem bestimmten Niveau und die Leistung ist sehr gut.
- Nachteile:
Sobald die Architektur angepasst ist, muss sich der Code entsprechend ändern Es ist schwierig, erweiterte Anwendungen wie automatische Unterbibliotheken und Untertabellen zu implementieren zur gemeinsamen Middleware, die die Lese-Schreib-Trennung in externen Middleware-Programmen implementiert. Es hat den Test in Alibaba bestanden. Aufgrund des Weggangs des Autors wurde Cobar nicht mehr aufrechterhalten, um Cobar zu ersetzen. 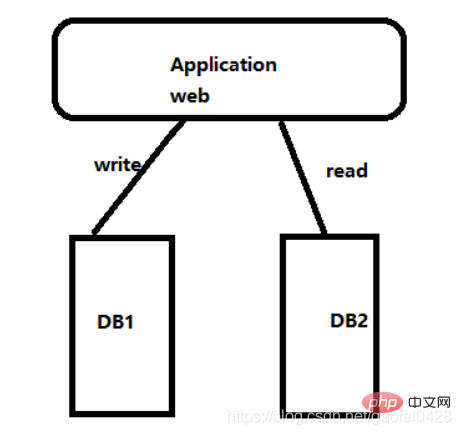
- MyCAT:
- Community-Enthusiasten führten eine Sekundärentwicklung auf Basis von Alibaba Cobar durch, lösten einige Probleme, die Cobar zu dieser Zeit hatte, und fügten viele neue Funktionen hinzu. Derzeit ist die MyCAT-Community sehr aktiv und einige Unternehmen nutzen MyCAT bereits. Im Allgemeinen liegt das Unterstützungsniveau über
und wird weiterhin beibehalten.
OneProxy:
- Ein großer Chef in der Datenbankbranche, der ehemalige Leiter des Alipay-Datenbankteams, Lou Zong, hat OneProxy basierend auf der offiziellen MySQL-Proxy-Idee mit c entwickelt und ist eine kommerzielle kostenpflichtige Middleware, die Lou Zong gegeben hat nach oben Einige Funktionspunkte wurden hinzugefügt, um den Schwerpunkt auf Leistung und Stabilität zu legen. Einige Leute haben es getestet und festgestellt, dass es bei hoher Parallelität sehr stabil ist.
Vitess:
- Diese Middleware wird in der Youtube-Produktion verwendet, aber die Architektur ist sehr komplex. Anders als bei früherer Middleware sind die Anwendungsänderungen bei der Verwendung von Vitess relativ groß. Um die API-Schnittstelle der von ihm bereitgestellten Sprache zu nutzen, können wir von einigen seiner Designideen lernen.
Kingshard:
Kingshard wurde in ihrer Freizeit von Chen Fei vom ehemaligen 360Atlas-Middleware-Entwicklungsteam in der Go-Sprache entwickelt. Derzeit sind etwa drei Personen an der Entwicklung beteiligt kontinuierlich verbessert werden.
Atlas:
360-Team hat Lua in C basierend auf MySQL-Proxy neu geschrieben. Die Originalversion unterstützt Tabellen-Sharding und es wurde eine Shard-Datenbank- und Tabellenversion veröffentlicht. Ich habe einige Freunde im Internet gesehen, die oft sagten, dass es bei hoher Parallelität oft hängen bleibt. Wenn Sie es verwenden möchten, müssen Sie es im Voraus testen.
MaxScale und MySQL Route:
Diese beiden Middlewares gelten als offiziell von mariadb (eine Version, die vom ursprünglichen Autor von MySQL verwaltet wird). Die aktuelle Version unterstützt keine Sharding-Datenbanken und -Tabellen. MySQL Route ist eine Middleware, die jetzt von der offiziellen Oracle-Firma MySQL veröffentlicht wurde.
Vorteile:
Das Architekturdesign ist flexibler
Sie können einige erweiterte Steuerelemente im Programm implementieren, z. B. transparente horizontale Aufteilung, Failover und Überwachung. Sie können sich auf technische Mittel verlassen, um das zu verbessern Auswirkungen der MySQL-Leistung auf den Geschäftscode. Klein und sicher zugleich. Nachteile: Erfordert die Unterstützung eines bestimmten Entwicklungs- und Betriebsteams.
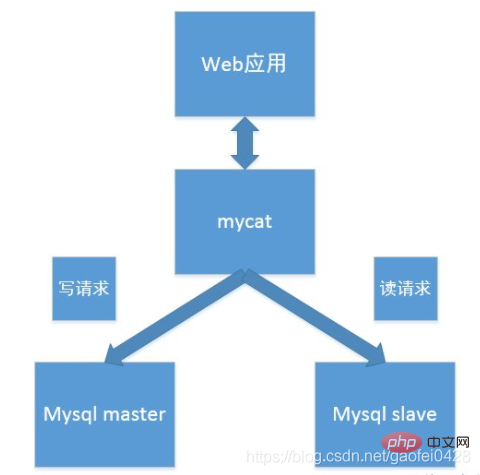
- Was ist MyCAT?? Es kann als MySQL-Cluster-Datenbank auf Unternehmensebene angesehen werden, die teure Oracle-Cluster ersetzt.
Ein neuer SQL Server, der Speicher-Caching-Technologie, NoSQL-Technologie und HDFS-Big Data integriert. Kombiniert traditionelle Datenbanken und neue verteilte Data Warehouses. Eine neue Generation von Datenbankprodukten auf Unternehmensebene. Ein neuartiges Datenbank-Middleware-Produkt. Installation und Konfiguration des MyCat-Dienstes. MyCat bietet kompilierte Installationspakete, die Windows unterstützen und Linux, Mac, Solaris und andere Systeme zum Installieren und Ausführen
Offizielle Download-Homepage http://www.mycat.org.cn/
- Experimentelle Architektur: 192.168. 2.2 Mycat CentOS 8.3.2011
- 192.168.2.3 Hauptserver CentOS 7.6192.168.2.5 Slave-Server CentOS 7.6
- Für die Ausführung von Mycat ist JDK 1.7 oder höher erforderlich
Mycat herunterladen wget http:/ /dl .mycat.org.cn/1.6.7.6/20210303094759/Mycat-server-1.6.7.6-release-20210303094759-linux.tar.gz
- tar xf Mycat-server-1.6.7.6-release-20210303094759-linux. tar. gz -C /usr/local/
sudo useradd -M -N -s /sbin/nologin mycat && echo "123456" |. mycat/
- bin-Programmverzeichnis, zuerst chmod +x *
Hinweis: Mycat unterstützt Befehle { console start |. dump }. Konfigurationsdateien werden im conf-Verzeichnis gespeichert .xml ist die Konfigurationsdatei für die Mycat-Serverparameteranpassung und Benutzerautorisierung. schema.xml ist die Konfigurationsdatei für die Definition der logischen Bibliothek, die Tabellen- und Sharding-Regel.xml ist die Konfigurationsdatei für Sharding-Regeln und einige spezifische Parameterinformationen für das Sharding Speichern Sie es als separate Datei, ebenfalls in diesem Verzeichnis. Wenn die Konfigurationsdatei geändert wird, müssen Sie Mycat neu starten, damit sie wirksam wird.
Im lib-Verzeichnis werden hauptsächlich einige JAR-Dateien gespeichert, von denen mycat abhängt.
Das Protokoll wird in logs/mycat.log gespeichert, eine Datei pro Tag. Je nach Bedarf können Sie die Ausgabeebene auf Debug-Ebene anpassen ausgegeben, um die Fehlersuche zu erleichtern.
MyCat-Dienststart und Starteinstellungen
- Beim Bereitstellen und Starten von MyCAT unter Linux müssen Sie zunächst MYCAT_HOME in der Umgebungsvariablen des Linux-Systems konfigurieren. Die Betriebsmethode ist wie folgt:
- sudo vim /etc/profile.d/mycat.sh
MYCAT_HOME=/usr/local/mycat PATH=$MYCAT_HOME/bin:$PATH
- Umgebungsvariablen werden wirksam
- /etc/profile.d /mycat.sh

- Starten Sie den Dienst
- /usr/local/mycat/bin/mycat start
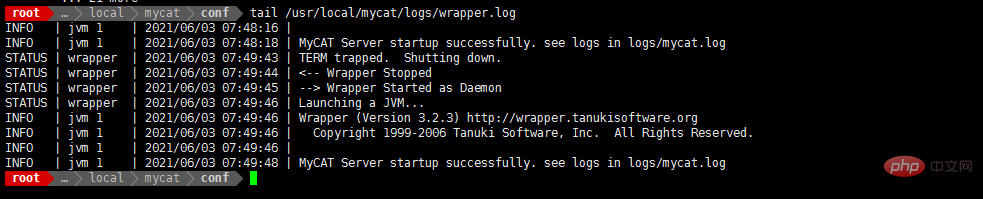
- cat /usr/local/mycat/logs/wrapper.log

mycat der Benutzer. Die Konto- und Autorisierungsinformationen werden in der Datei conf/server.xml konfiguriert Hier können Sie sich unter 192.168.2.2 bei mycat anmelden. Benutzername und Passwort, der Name kann angepasst werden. Der mysqld-Dienst läuft nicht auf 192.168.2.2. Der in den Schemata angegebene Datenbankname ist eine Datenbank, die auf der Serverseite vorhanden sein muss!
MyCAT-Konfigurationsdateischema bearbeiten xml{,.bak}Konfigurationsdatei bearbeiten
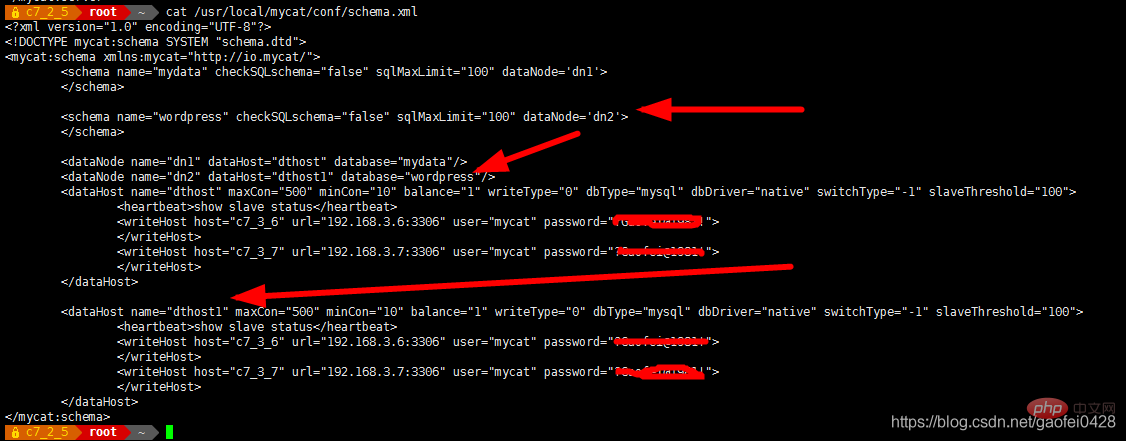
vim /usr/local/mycat/conf/schema.xml
< !DOCTYPE mycat:schema SYSTEM "schema.dtd">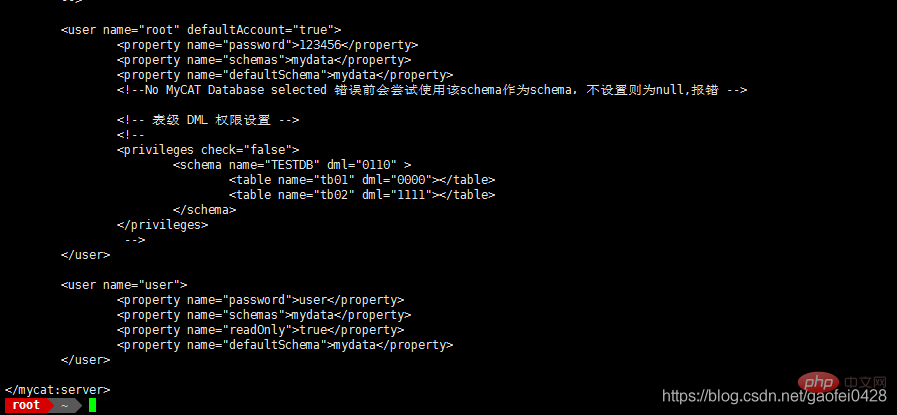
 Achten Sie hier auf die URL, falsches Schreiben führt dazu, dass der Start fehlschlägt!
Achten Sie hier auf die URL, falsches Schreiben führt dazu, dass der Start fehlschlägt!
< "mydata"/>
Erzwingen Sie die Ausführung aller Lesevorgänge auf dem Leseserver und wechseln Sie nur zum Schreibserver, wenn Daten geschrieben werden
Beachten Sie, dass der mycat-Benutzer hier für die Master-Slave-Datenbank 192.168 autorisiert sein muss. 2.3 und 2.5
GEWÄHREN SIE ALLE PRIVILEGIEN FÜR *.* AN 'mycat'@'%' IDENTIFIED BY '123456';
oder ein bestimmtes Netzwerksegment
GEWÄHREN SIE ALLE PRIVILEGIEN FÜR *.* AN 'mycat '@' 192.168.2.%' IDENTIFIED BY '123456';
Flush-Privilegien;
Wenn dieser Fehler gemeldet wird und der Server normal läuft, prüfen Sie zunächst, ob eine Autorisierung vorliegt
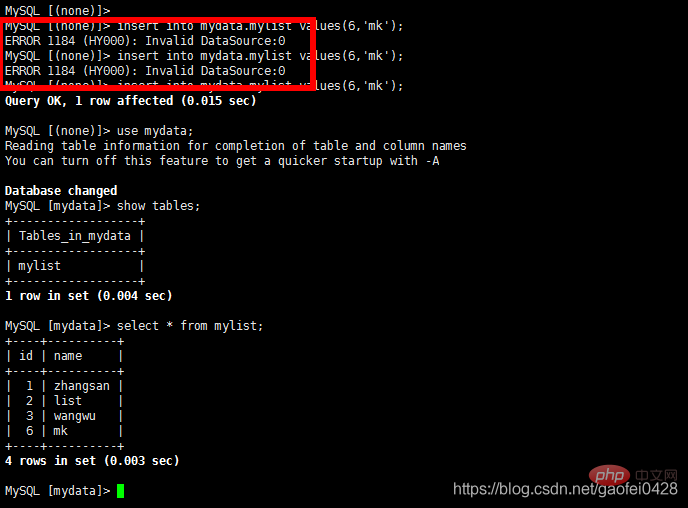
ERR ODER 1184 (HY000): Ungültige Datenquelle: 0
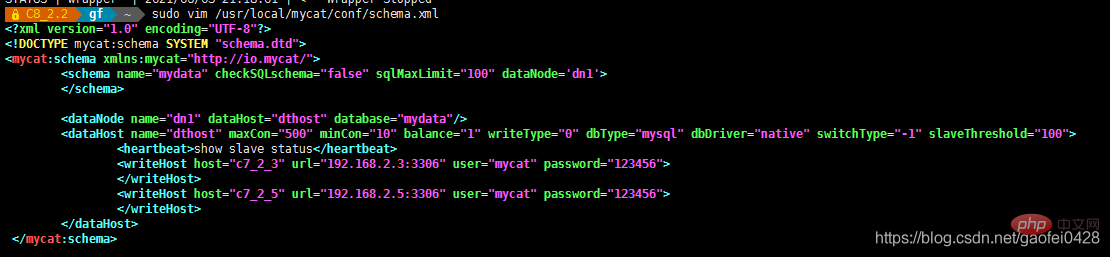

Schema: Logische Bibliothek, entsprechend der Datenbank in MySQL, eine logische Bibliothek, definiert das Eingebundene Tisch .
Tabelle: Tabelle, d. h. eine in einer physischen Datenbank gespeicherte Tabelle. Hier muss die Tabelle den logischen Datenknoten DataNode deklarieren, den sie speichert. Dies wird durch die Definition von Sharding-Regeln für die Tabelle erreicht. Eine Tabelle kann die „childTable“ definieren, zu der sie gehört. Das Sharding der untergeordneten Tabelle hängt von der spezifischen Sharding-Adresse der „übergeordneten Tabelle“ ab. Einfach ausgedrückt handelt es sich um alle untergeordneten Tabellen, die zu einem bestimmten Datensatz A in der übergeordneten Tabelle gehören Die Datensätze werden alle auf demselben Shard wie A gespeichert.
Sharding-Regel: Es handelt sich um eine gebündelte Definition eines Felds und einer Funktion. Basierend auf dem Wert dieses Felds wird die Sequenznummer des gespeicherten Shards (DataNode) zurückgegeben. Jede Tabelle kann eine Sharding-Regel definieren Standardmäßig werden Zahlenbasierte Sharding-Regeln, String-Sharding-Regeln usw. flexibel erweitert.
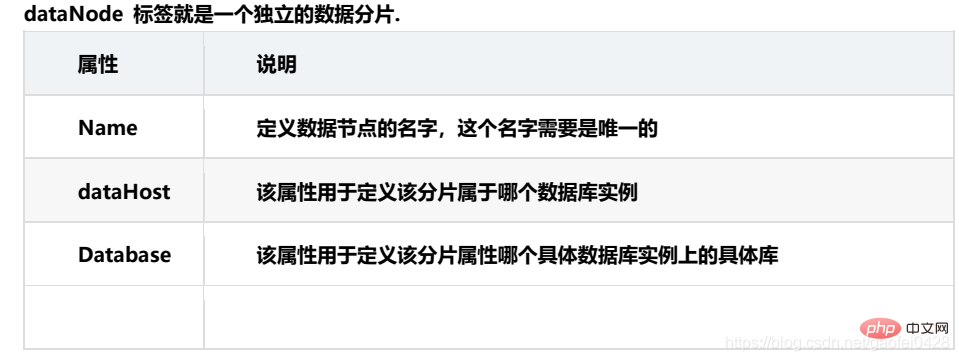
dataNode: Der logische Datenknoten von MyCAT ist ein bestimmter physischer Knoten, der Tabellen speichert. Er wird im Allgemeinen über DataSource mit einer bestimmten Back-End-Datenbank verknüpft ist mit zwei DataSources eingerichtet, einer Master- und einer Slave-Knoten. Wenn der Master-Knoten ausfällt, schaltet das System automatisch auf den Slave-Knoten um.
dataHost: Definieren Sie die Zugriffsadresse einer physischen Bibliothek für die Bindung an dataNode.
MyCAT definiert derzeit logische Bibliotheken und zugehörige Konfigurationen über Konfigurationsdateien:
Logische Bibliotheken, Tabellen, Shard-Knoten und andere Inhalte sind in MYCAT_HOME/conf/schema.xml definiert;
Sharding ist in MYCAT_HOME/conf/rule.xml definiert.
Definieren Sie benutzer- und systembezogene Variablen wie Ports usw. in MYCAT_HOME/conf/server.xml.
Hinweis:
Das Schema-Tag wird verwendet, um den Namen der logischen Bibliothek in der MyCat-Instanz zu definieren: Darauf folgt der Name der logischen Bibliothek, und jede logische Bibliothek verfügt über eine eigene zugehörige Konfiguration. Sie können Schema-Tags verwenden, um diese verschiedenen logischen Bibliotheken zu unterteilen.
Das checkSQLschema-Attribut ist standardmäßig auf „false“ eingestellt. Das offizielle Dokument gibt an, ob der Name der Datenbank vor der Tabelle entfernt werden soll: „select * from db1.testtable“. Wenn der Name von db1 jedoch nicht der Name des Schemas ist, wird er nicht entfernt. Daher wird offiziell empfohlen, diese Syntax nicht zu verwenden. Standardmäßig ebenfalls auf „false“ gesetzt.
sqlMaxLimit Wenn der Wert auf eine bestimmte Zahl gesetzt ist. Wenn für jede ausgeführte SQL-Anweisung keine Limit-Anweisung hinzugefügt wird, fügt MyCat automatisch den entsprechenden Wert hinzu. Wenn Sie beispielsweise den Wert auf 100 setzen und „select * from test_table“ ausführen, ist der Effekt „select * from test_table limit 100“. Das dataNode-Tag definiert die Datenknoten in MyCat, was wir normalerweise als Daten-Sharding bezeichnen .



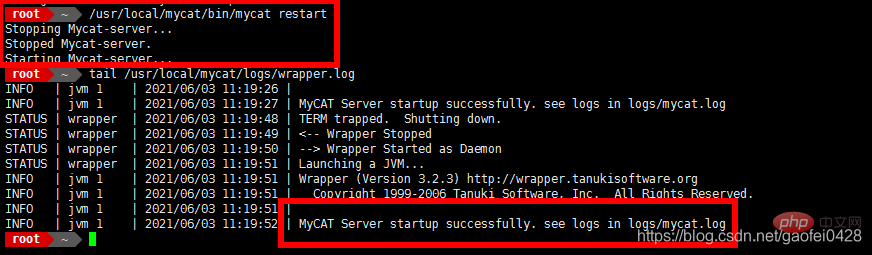
- Starten Sie den Dienst neu
- /usr/local/mycat/bin/mycat restart
Stoppen des Mycat-Servers...
Stoppen des Mycat-Servers.
Starten des Mycat-Servers...
tail /usr/local/ mycat/logs/wrapper.log
MySQL-Master-Slave konfigurieren
- Mariadb auf jeweils 2 Servern installieren und konfigurieren. Weitere Informationen finden Sie unter: https://blog.csdn. net/ gaofei0428/article/details/103829676?spm=1001.2014.3001.5501
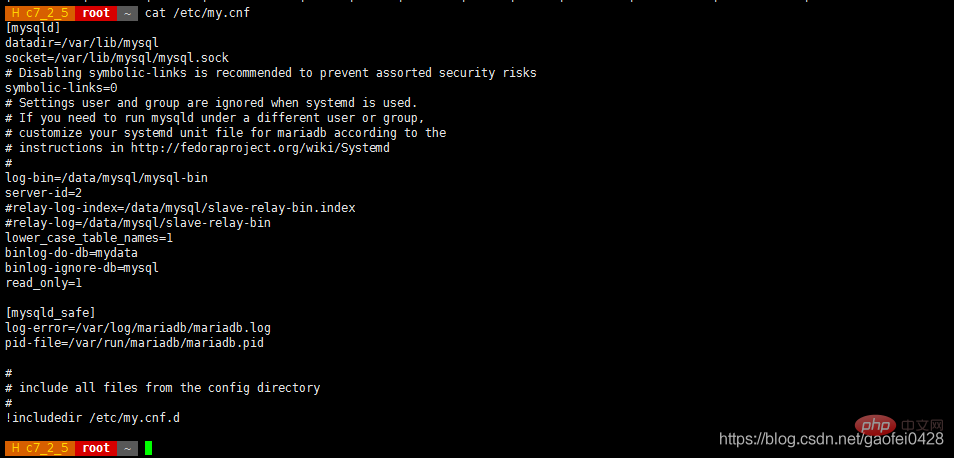
Zuerst auf der Hauptdatenbankseite 192.168.2.3 Edit. /etc/my.cnf
- /etc/my .cn f
[ mysqld]
datadir =/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
symbolic-links=0
log-bin=/data/mysql/mysql-bin
server-id =1 replicate-do- db=mydata
lower_case_table_names=1 Case Matching aktivieren
Beachten Sie, dass die Datenbank, die synchronisiert werden muss, im Voraus vorhanden sein muss
und dann ohne Fehler starten Von Server 192.168.2.5 Konfigurieren Sie /etc/my.cnf 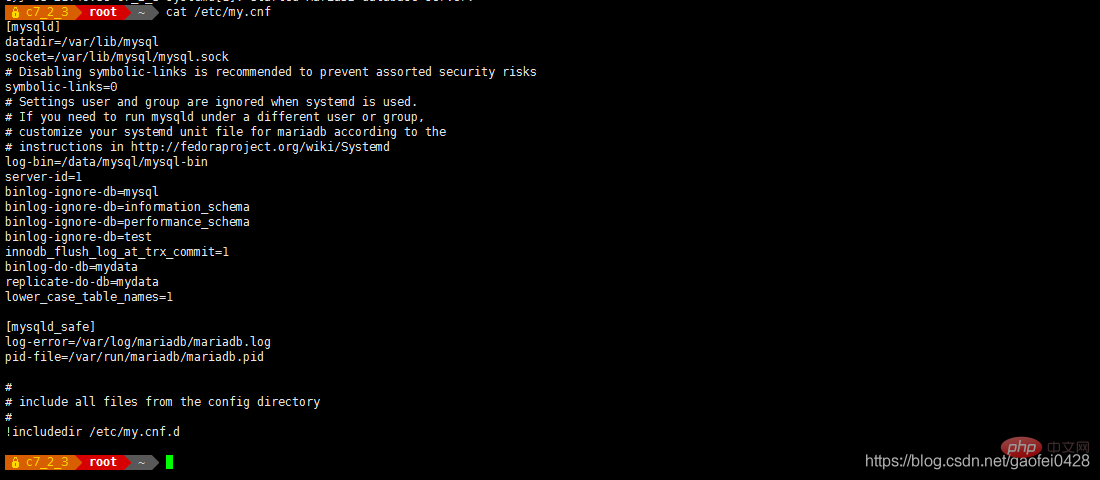

- symbolic-links=0
log-bin=/data/mysql/mysql-bin server-id=2 Relay-log-index=/data/mysql/slave-relay-bin.index Relay-log=/ data/mysql/slave-relay-bin
Lower_case_table_names=1 - read_only=1 Turn im schreibgeschützten Modus, um das Zurückschreiben von Daten zu verhindern und hat keinen Einfluss auf die synchrone Slave-Replikation.
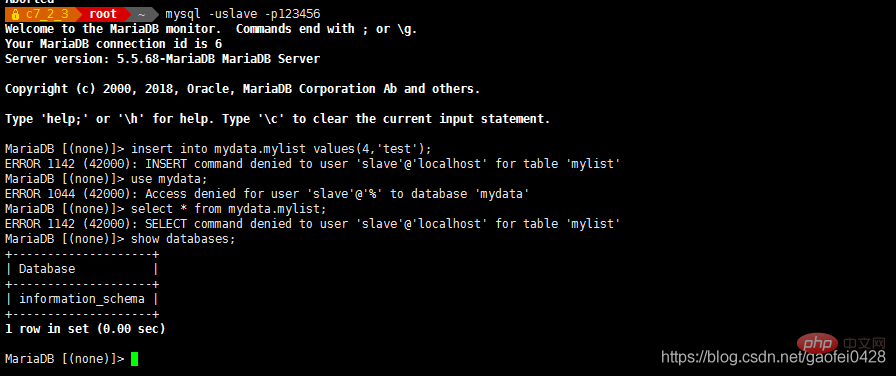
lower_case_table_names=1 Aktivieren Sie den Fallvergleich den Slave des Slave-Servers und erstellen Sie einen Slave-Datenbankbenutzer
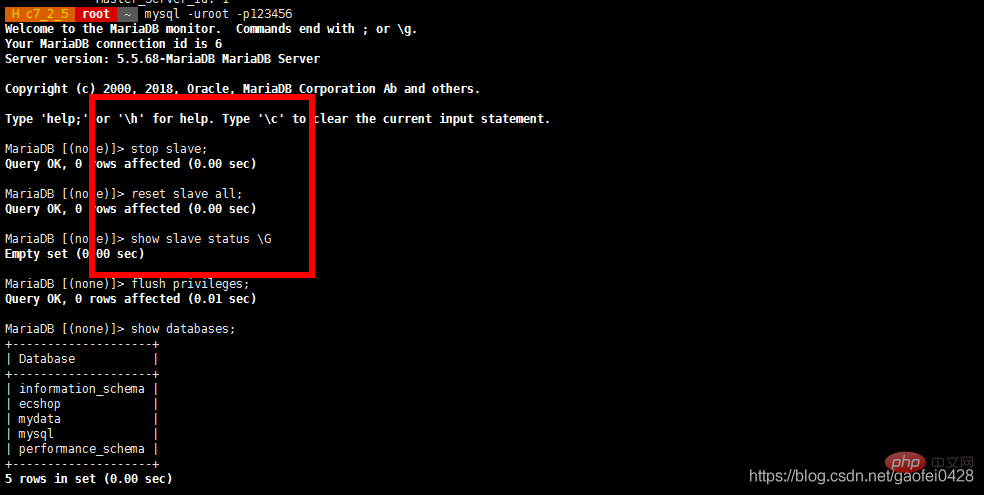
mysql -uroot -p123456 -e "Slave stoppen"
mysql -uroot -p123456 -e "Grant Replication Slave on *.* to 'slave'@'%' identifiziert von '123456'"
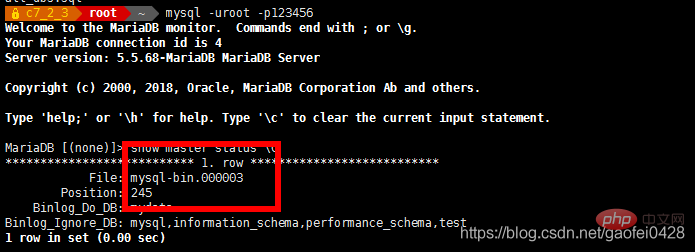
mysql -uroot -p123456 -e "Benutzer und Passwort von mysql.user auswählen" - mysql -uroot -p123456 -e " Master in master_host='192.168.2.3',master_user ändern ='slave',master_password='123456',master_log_file='mysql-bin.000002',master_log_pos=245;" mysql -uroot -p123456 -e "Slave starten"
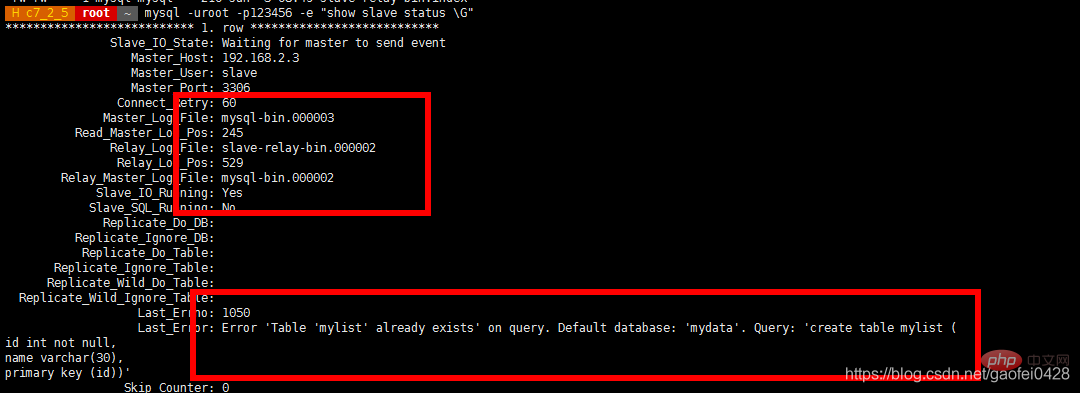
- mysql -uroot -p123456 -e "Slave-Status anzeigen „
Test
Exportieren Sie zunächst das Backup aller Bibliotheken des Hauptservers 192.168.2.3
mysqldump -uroot -p --all-databases > /tmp/ all_dbs .sql
Dann vom Server 192.168.2.5 importieren
mysql -uroot -p < /tmp/all_dbs.sql
- Fügen Sie 192.168.2.3 im Hauptverzeichnis hinzu Datenbankseite Beobachten Sie bei einigen Daten, ob die Slave-Datenbank synchronisiert ist dann den Master erneut wechseln

Versuchen Sie, sich anzumelden
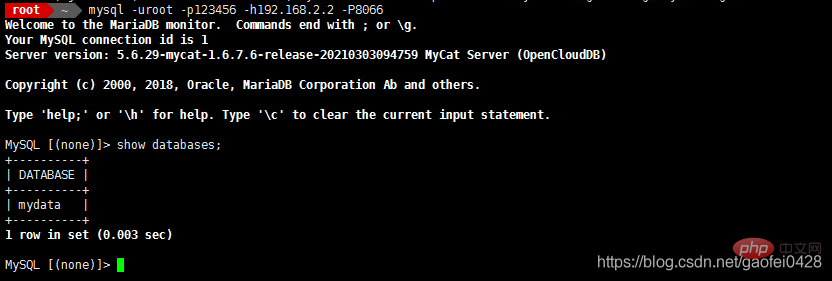
- mysql -uroot - p123456 -h192.168.2.2 -P8066
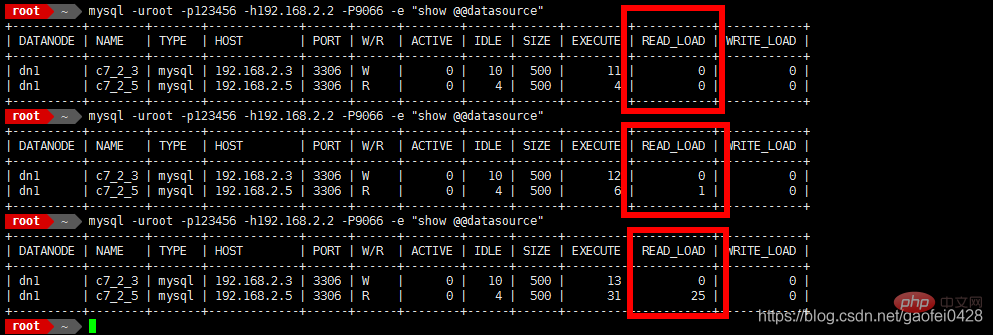
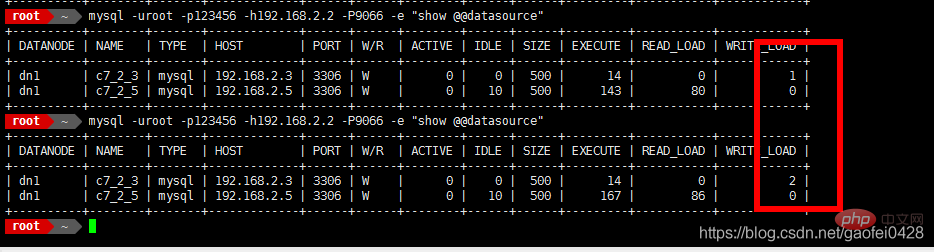
8066 ist die Portnummer, wenn mycat ausgeführt wird- Lese- und Schreibtrennung testen mysql -uroot -p123456 -h192 .168.2.2 -P9066 -e "show @@datasource"
- 9066 ist die Mycat-Verwaltung. Port
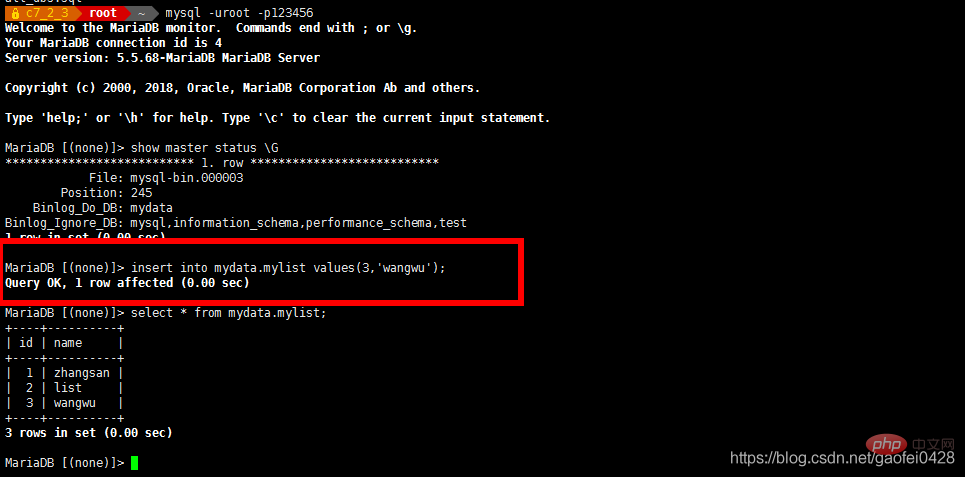
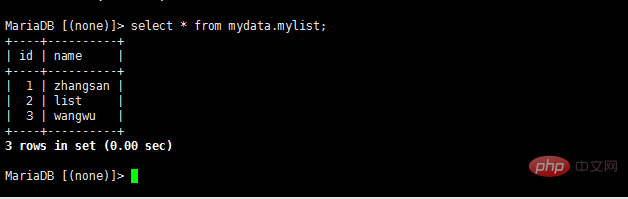
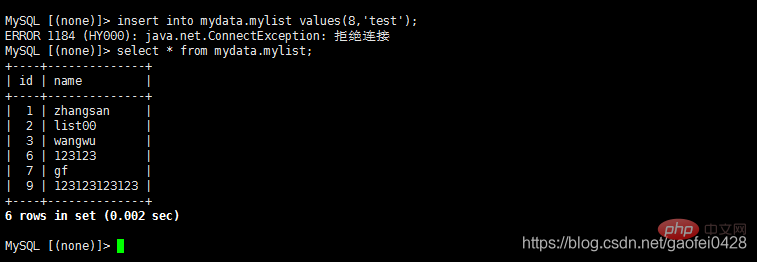
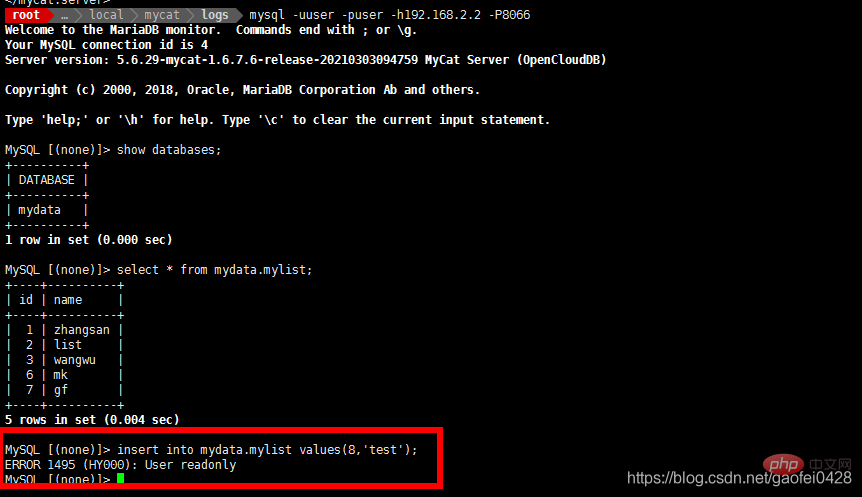
- select * von mydata.mylist;
- Daten schreiben oder Daten ändern
- insert into mydata.mylist Values(10,'test');
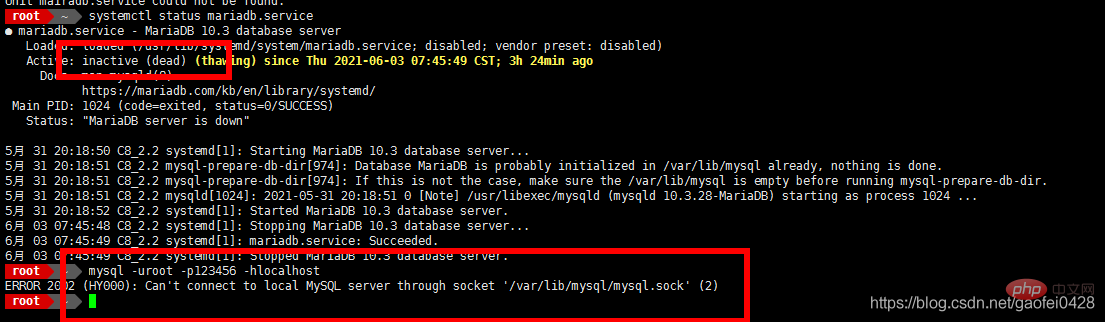
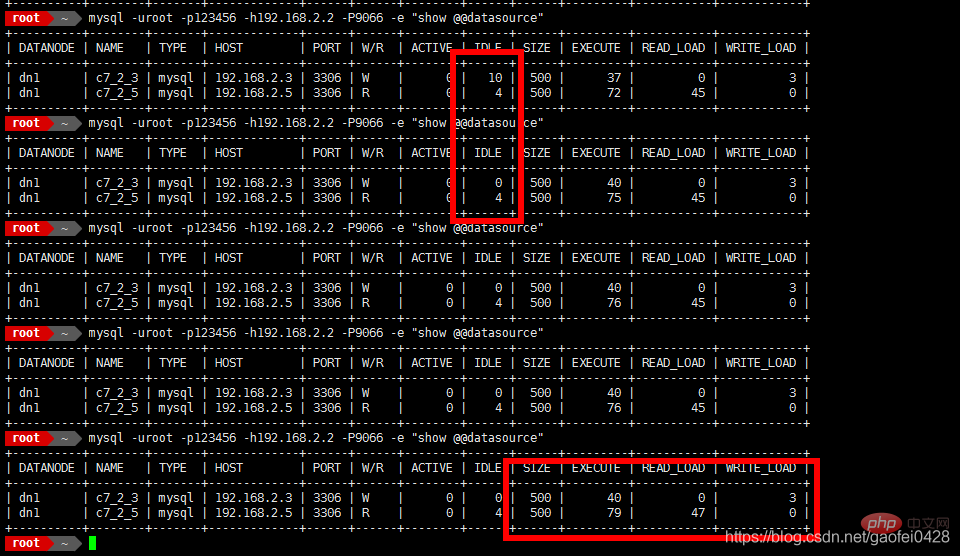
- Simulieren Sie einen Fehler, Stoppen Sie zuerst den Slave-Server 192.168.2.5. systemctl stoppt mariadb.service.
Auf Hauptserver 192.168.2.3 anzeigen
Öffnen Sie den Slave-Server 192.168.2.5Simulieren Sie den Hauptserver. 192.168.2.3 Ausfallzeit
- Die Abfrage ist normal, es wird versucht, Daten zu schreiben.
- Die Abfrage ist normal, kann aber nicht geschrieben werden m cat /usr/ local/mycat /conf/server.xml
vim /usr/local/mycat/conf/schema.xml
< ;dataNode name="dn2" dataHost="dthost1" Database="wordpress"/>
- Nach dem Hinzufügen des Neustartdienstes
/usr/local/ mycat/bin/mycat restart
tail /usr/ local/mycat/logs/wrpper.log
Start fehlgeschlagen: Zeitüberschreitung beim Warten auf ein Signal von der JVM.- JVM wurde auf Anfrage nicht beendet, beendet
- Lösung
wrapper.ping.timeout=120 in wrapper.conf hinzufügen // Timeout 300 Sekunden
- Empfohlen Lernen:
- MySQL-Video-Tutorial


 Öffnen Sie den Slave-Server 192.168.2.5
Öffnen Sie den Slave-Server 192.168.2.5
 < ;dataNode name="dn2" dataHost="dthost1" Database="wordpress"/>
< ;dataNode name="dn2" dataHost="dthost1" Database="wordpress"/>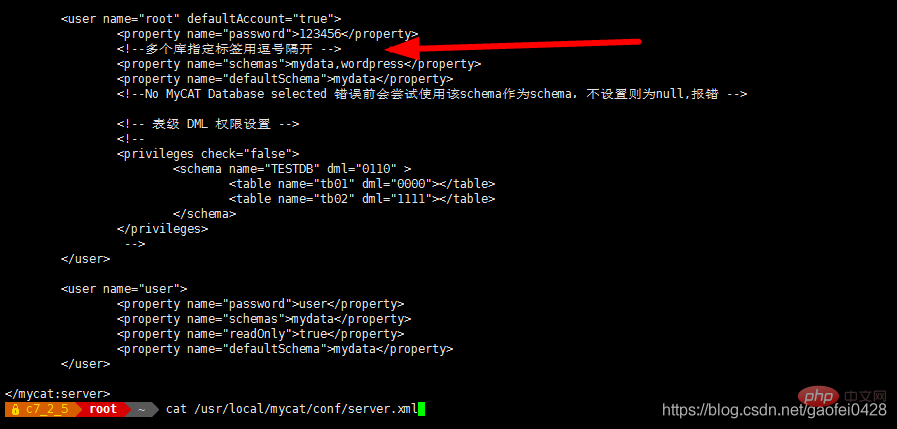
 in wrapper.conf hinzufügen // Timeout 300 Sekunden
in wrapper.conf hinzufügen // Timeout 300 Sekunden 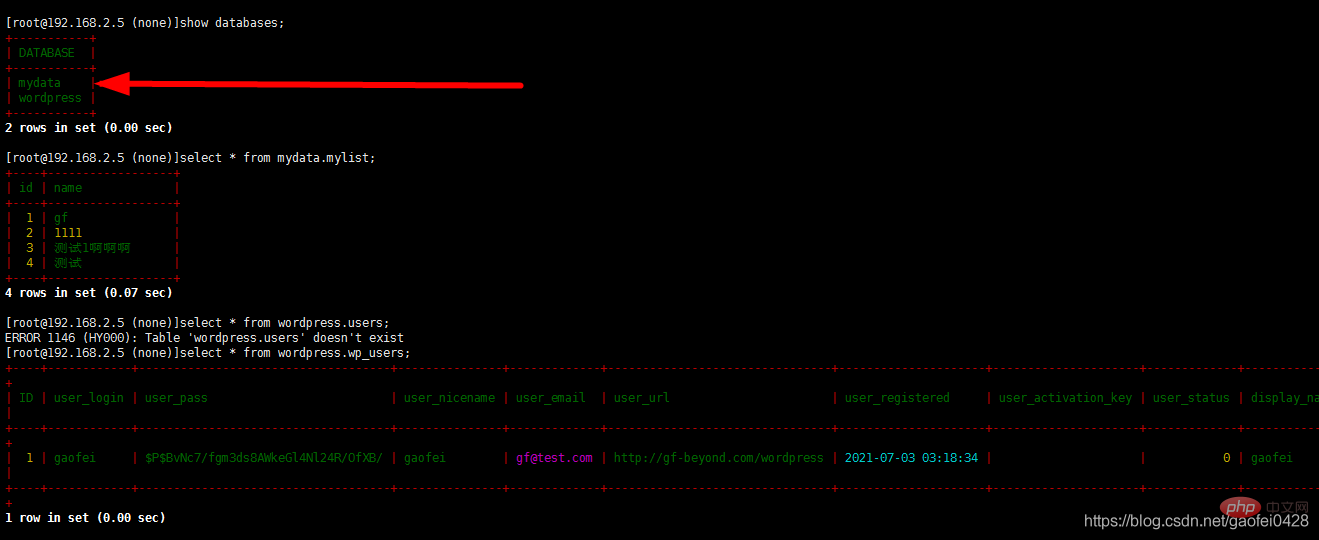
Das obige ist der detaillierte Inhalt vonLassen Sie uns über Mycats Implementierung der Lese- und Schreibtrennung von MySQL-Clustern sprechen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
