

Dieser Artikel vermittelt Ihnen relevantes Wissen über den zugrunde liegenden Index und die Optimierung in MySQL. Ich hoffe, dass er für alle hilfreich ist.

Es gibt verschiedene Erklärungen zum Thema Indizierung, aber einige Konzepte sind sehr vage.
Index wird verwendet, um Zeilen mit einem bestimmten Wert in einer Spalte schnell zu finden Beginnend mit dem ersten Datensatz, bis die relevanten Zeilen gefunden werden, desto länger dauert die Abfrage der Daten. Wenn die Spalte in der Tabelle indiziert ist, kann MySQL schnell an einen Ort gelangen, an dem die Datendatei durchsucht werden kann ohne sich alle Daten ansehen zu müssen. Das spart viel Zeit.
1. Eine Hash-Tabelle ist eine Struktur, die Daten in einem Schlüssel-Wert-Format speichert. Solange wir den zu findenden Schlüssel (Schlüssel) eingeben, können wir den entsprechenden Wert (Wert) finden. Die Idee des Hashings ist sehr einfach. Fügen Sie den Wert in das Array ein, verwenden Sie eine Hash-Funktion, um den Schlüssel an eine bestimmte Position zu konvertieren, und fügen Sie dann den Wert an dieser Position im Array ein.
Nach der Konvertierung durch die Hash-Funktion haben mehrere Schlüsselwerte zwangsläufig denselben Wert. Eine Möglichkeit, mit dieser Situation umzugehen, besteht darin, eine verknüpfte Liste zu erstellen.
2. Wenn wir von bTree sprechen, müssen wir erwähnen, dass Binärbäume in viele Typen unterteilt sind, wie zum Beispiel: Binärer Suchbaum, ausgeglichener Binärbaum usw. Natürlich gibt es auch das Highlight rote und schwarze Bäume.
1) Die Merkmale eines binären Suchbaums sind: Die Werte aller Knoten im linken Teilbaum des übergeordneten Knotens sind kleiner als der Wert des übergeordneten Knotens. Die Werte aller Knoten im rechten Teilbaum sind größer als der Wert des übergeordneten Knotens. Nehmen wir als Beispiel ein Bild, um den binären Suchbaum zu veranschaulichen.
| ID | Name |
|---|---|
| 5 | Zhang Wu |
| 6 | Zhang. Liu |
| 7 | Z Hang Qi |
| 2 | 张二 |
| 1 | Zhang Yi |
| 4 | Zhang Si |
| 3 | Zhang San |
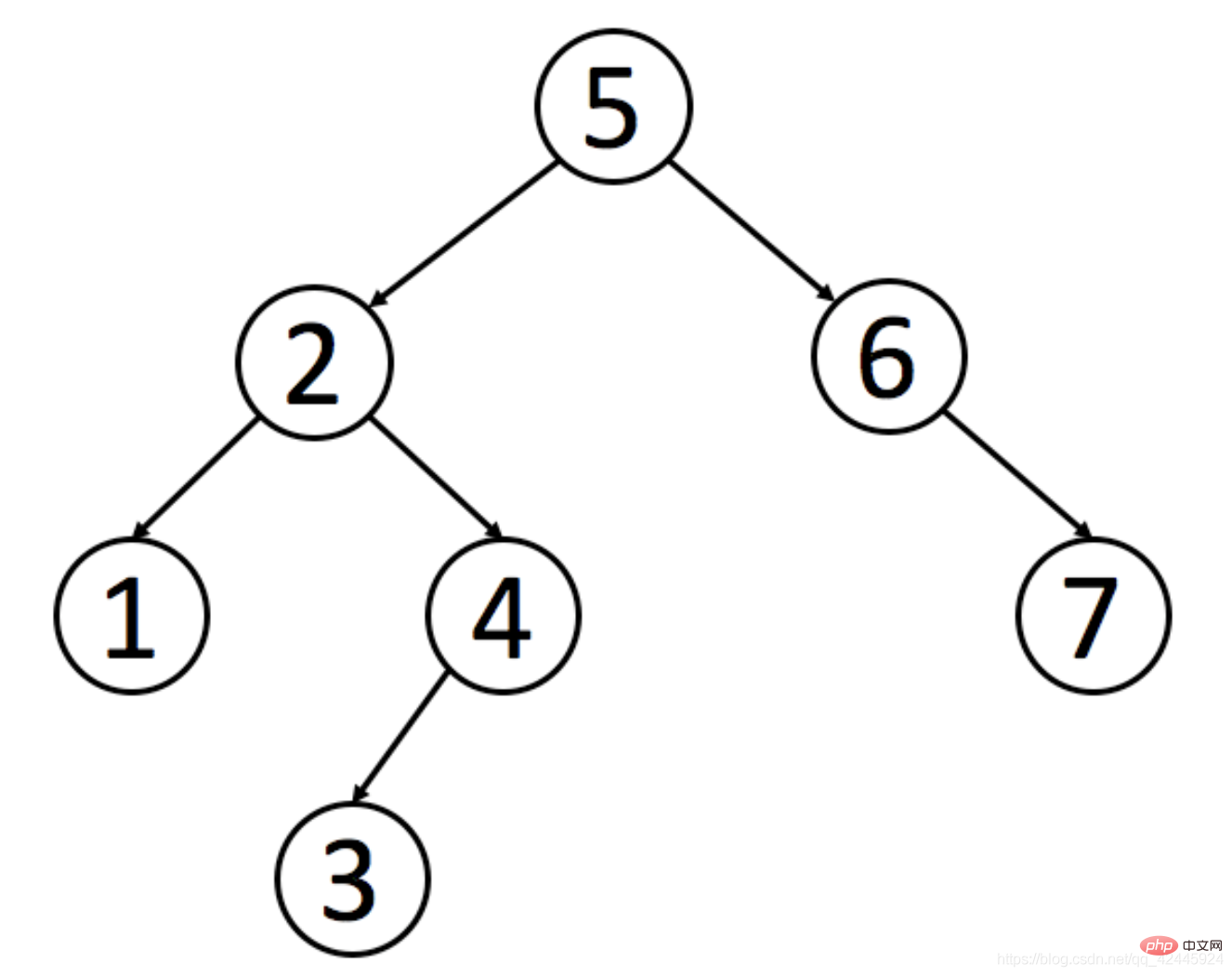 Es ist erforderlich, Zhang San zu finden. Wenn wir den binären Suchbaum nicht verwenden, müssen wir siebenmal suchen, um den gewünschten Wert zu finden.
Es ist erforderlich, Zhang San zu finden. Wenn wir den binären Suchbaum nicht verwenden, müssen wir siebenmal suchen, um den gewünschten Wert zu finden.
Dem oben Gesagten zufolge kann die Verwendung eines binären Suchbaums tatsächlich die Anzahl der Abfragen reduzieren, aber haben Sie jemals darüber nachgedacht, was passiert, wenn die Daten in der Datenbank in der Reihenfolge 1, 2, 3, 4, 5, 6 usw. zunehmen? 7? Weiter verwenden Der binäre Suchbaum wird zu einer verknüpften Liste. Wenn wir also 7 finden wollen, müssen wir sieben Mal suchen und die Tabelle sieben Mal scannen. Dies unterscheidet sich nicht davon, keinen Index zu erstellen, was auch einen der Nachteile darstellt. Die folgende Abbildung ist ein Beispiel. 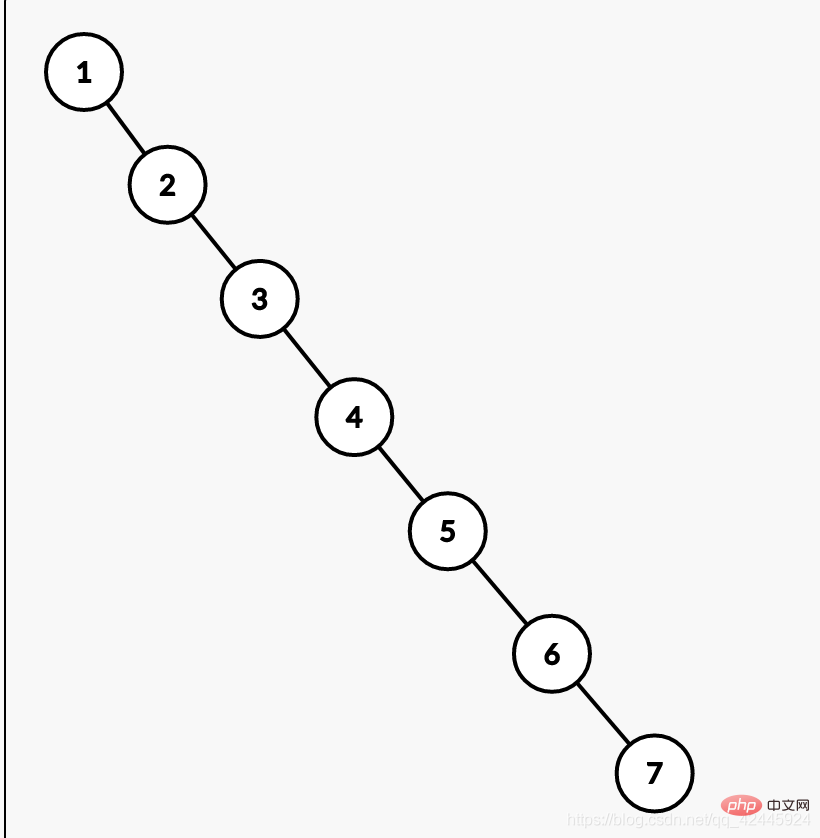
2) Ausgeglichener Binärbaum: Auch als AVL-Baum bekannt, der absolute Wert des Höhenunterschieds zwischen seinem linken und rechten Teilbaum überschreitet nicht 1, und der linke und der rechte Teilbaum sind beide ausgeglichene Binärbäume Der AVL-Baum ist der erste selbstausgleichende binäre Suchbaum, der erfunden wurde. In einem AVL-Baum kann der maximale Höhenunterschied zwischen zwei Teilbäumen eines beliebigen Knotens nur 1 betragen, daher wird er auch als höhenbalancierter Baum bezeichnet. Das Abfragen, Hinzufügen und Löschen beträgt im Durchschnitt und im schlimmsten Fall O(log n). Hinzufügungen und Löschungen erfordern möglicherweise eine oder mehrere Baumrotationen, um den Baum wieder ins Gleichgewicht zu bringen.
Der Zweck der Einführung von Binärbäumen besteht darin, die Effizienz der Binärbaumsuche zu verbessern und dadurch die durchschnittliche Suchlänge des Baums zu reduzieren. Zu diesem Zweck müssen wir die Struktur des Baums anpassen, wenn wir in jeden Binärbaum einen Knoten einfügen Die Binärbaumsuche kann das Gleichgewicht aufrechterhalten, indem die Höhe des Baums verringert wird.
Die Eigenschaften eines ausgeglichenen Binärbaums sind wie folgt:
1. Sein linker Teilbaum und sein rechter Teilbaum sind beide AVL-Bäume
2. Der Höhenunterschied zwischen dem linken Teilbaum und dem rechten Teilbaum darf 1 nicht überschreiten.
Beispiel: 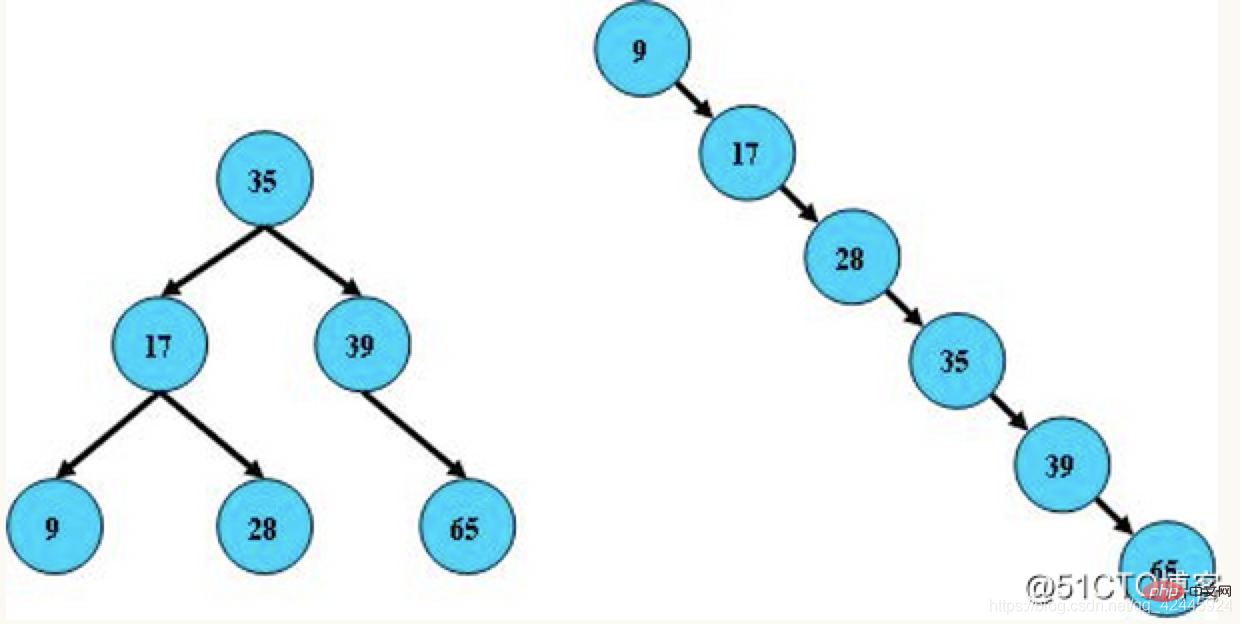 3) Rot-Schwarz-Baum: Es ist verständlich, dass der Rot-Schwarz-Baum ein Baum ist, der dem ausgeglichenen Binärbaum überlegen ist. Der Rot-Schwarz-Baum strebt nur ein teilweises Gleichgewicht an Erfüllen Sie die Gleichgewichtsanforderungen, reduzieren Sie die Anforderungen an die Rotation und verbessern Sie dadurch die Leistung. Darüber hinaus kann aufgrund seiner Konstruktion jede Unwucht innerhalb von drei Umdrehungen behoben werden. In rot-schwarzen Bäumen ist die zeitliche Komplexität des Algorithmus dieselbe wie bei AVL, und die statistische Leistung zwingt AVL-Bäume dazu, höher zu sein. Daher ist der Rot-Schwarz-Baum im Vergleich zum ausgeglichenen Binärbaum kein ausgeglichener Binärbaum im engeren Sinne. Die Einfügungs- und Löscheffizienz des Rot-Schwarz-Baums ist relativ geringer als die der ausgeglichenen Binärstruktur Allerdings ist der Unterschied in der Abfrageeffizienz zwischen den beiden im Grunde vernachlässigbar. Die Merkmale rot-schwarzer Bäume sind wie folgt:
3) Rot-Schwarz-Baum: Es ist verständlich, dass der Rot-Schwarz-Baum ein Baum ist, der dem ausgeglichenen Binärbaum überlegen ist. Der Rot-Schwarz-Baum strebt nur ein teilweises Gleichgewicht an Erfüllen Sie die Gleichgewichtsanforderungen, reduzieren Sie die Anforderungen an die Rotation und verbessern Sie dadurch die Leistung. Darüber hinaus kann aufgrund seiner Konstruktion jede Unwucht innerhalb von drei Umdrehungen behoben werden. In rot-schwarzen Bäumen ist die zeitliche Komplexität des Algorithmus dieselbe wie bei AVL, und die statistische Leistung zwingt AVL-Bäume dazu, höher zu sein. Daher ist der Rot-Schwarz-Baum im Vergleich zum ausgeglichenen Binärbaum kein ausgeglichener Binärbaum im engeren Sinne. Die Einfügungs- und Löscheffizienz des Rot-Schwarz-Baums ist relativ geringer als die der ausgeglichenen Binärstruktur Allerdings ist der Unterschied in der Abfrageeffizienz zwischen den beiden im Grunde vernachlässigbar. Die Merkmale rot-schwarzer Bäume sind wie folgt:
1. Knoten sind rot oder schwarz.
2. Der Wurzelknoten ist schwarz.
3. Die beiden untergeordneten Knoten jedes roten Knotens sind schwarz. (Kinder roter Knoten müssen schwarze Knoten sein)
4. Alle Pfade von jedem Knoten zu jedem seiner Blätter enthalten die gleiche Anzahl schwarzer Knoten. Daher ist der rot-schwarze Baum ein schwarz-ausgeglichener Baum, und der Höhenunterschied zwischen dem linken Teilbaum und dem rechten Teilbaum wird 2 nicht überschreiten. Der übergeordnete und untergeordnete Knoten eines roten Knotens kann nur ein schwarzer Knoten sein.
Beispiel: 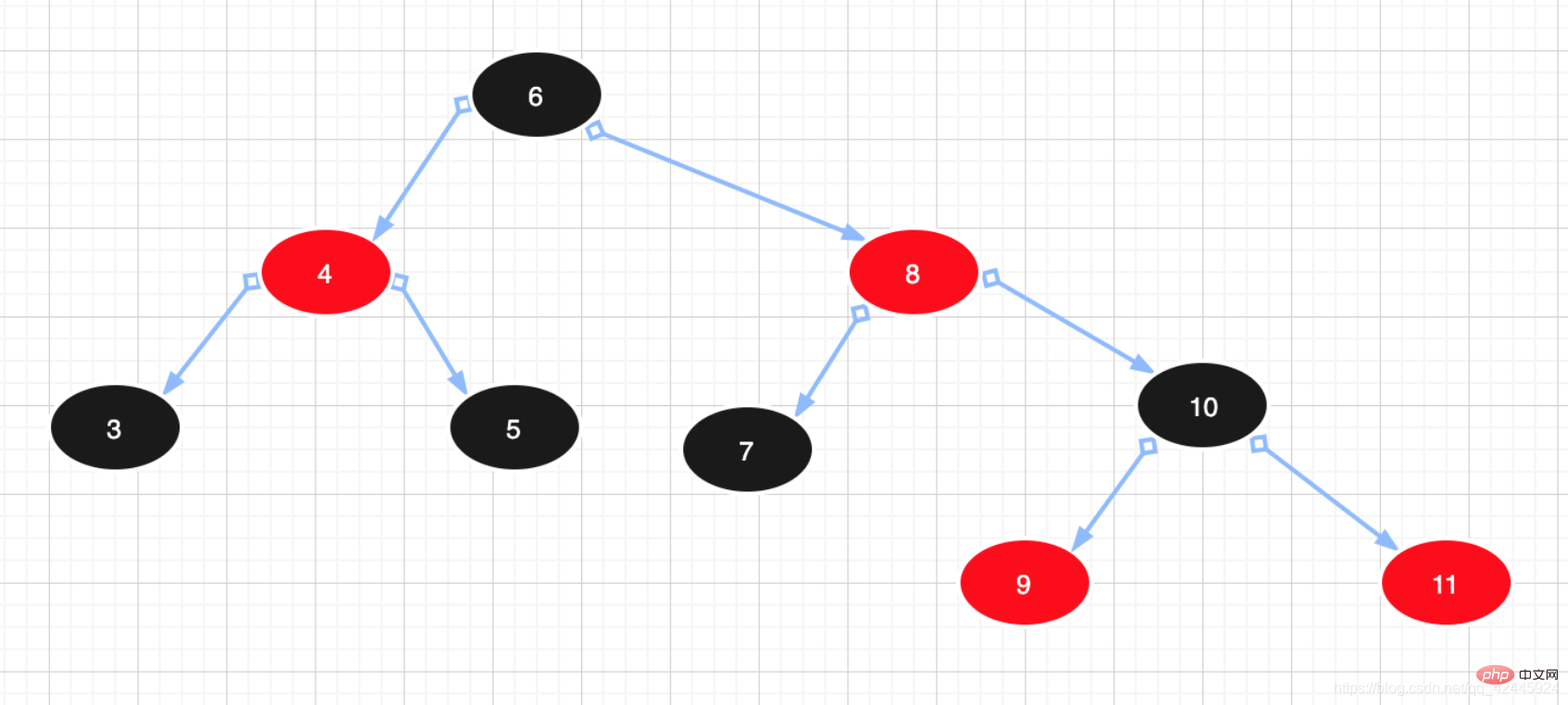
4) BTree (B-Baum): Natürlich der oben erwähnte rot-schwarze Baum, die Leistung ist sehr hoch. Am Beispiel der obigen Abbildung beträgt die maximale Höhe des Baums 4 mit insgesamt 9 Daten. Für die MySQL-Datenbank gibt es jedoch Millionen Daten, zig Millionen Daten usw Die Höhe des Baums ist unermesslich, beispielsweise erfordern Hunderte von zehntausend Daten 30 bis 50 Festplatten-E/A-Zeiten, um die Daten abzufragen, oder sogar noch mehr, was offensichtlich nicht die effiziente Abfrageeffizienz des MySQL-Index erreichen kann. Wenn wir also die Höhe des Baums steuern, wird die Anzahl der Festplatten-IO-Anfragen erheblich reduziert. Wenn die Höhe auf 4 eingestellt ist, sind nur 4 Festplatten-IOs erforderlich, um die Daten abzufragen. Aber wie kann man die Höhe des Baums steuern? Was ist, wenn jeder Knoten mehrere Elemente speichert? Sie alle auf einem Knoten, und der Höhenwert ist 1. Ist das nicht schneller? Es ist definitiv falsch, so zu denken.
Mysql hat bei jeder Interaktion mit Festplatten-IO eine Größenbeschränkung. Schüler, die die Knotengrößenbeschränkung ihres MySQL überprüfen möchten, können das folgende SQL ausführen. globalen Status wie „Innodb_page_size“ anzeigen
Das folgende Bild wird als Beispiel verwendet, um die Eigenschaften von BTree darzustellen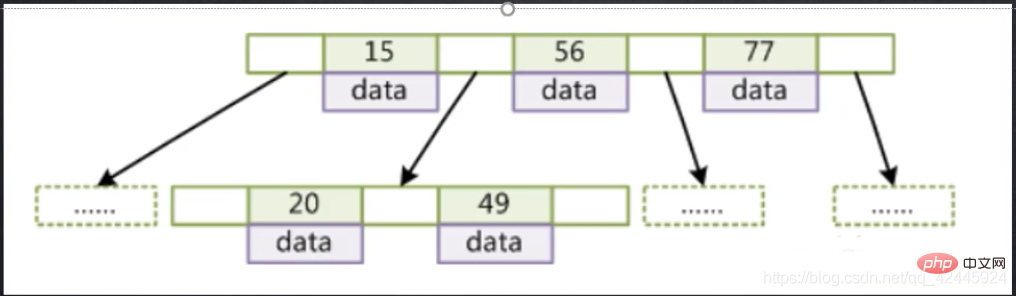 BTree wie folgt: 1. Alle Indexelemente werden nicht wiederholt
BTree wie folgt: 1. Alle Indexelemente werden nicht wiederholt
2. Der Datenindex des Knotens erhöht sich von von links nach rechts
3. Der Blattknoten hat die gleiche Tiefe, die Zeiger der Blattknoten sind leer
4. Sowohl Blattknoten als auch Nicht-Blattknoten speichern Indizes und Daten
5) B+-Baum: Wie oben erwähnt, steuert BTree die Höhe des Baums, was die Indizierungsanforderungen von MySQL erfüllen kann. Letztendlich ist die MySQL-Indeximplementierung jedoch nicht BTree, sondern B+-Baum Ein wenig über den B-Baum. Nach der Transformation wurde der B + -Baum erhalten, der auch als aktualisierte Version des B-Baums verstanden werden kann.
Nehmen wir das Bild als Beispiel: 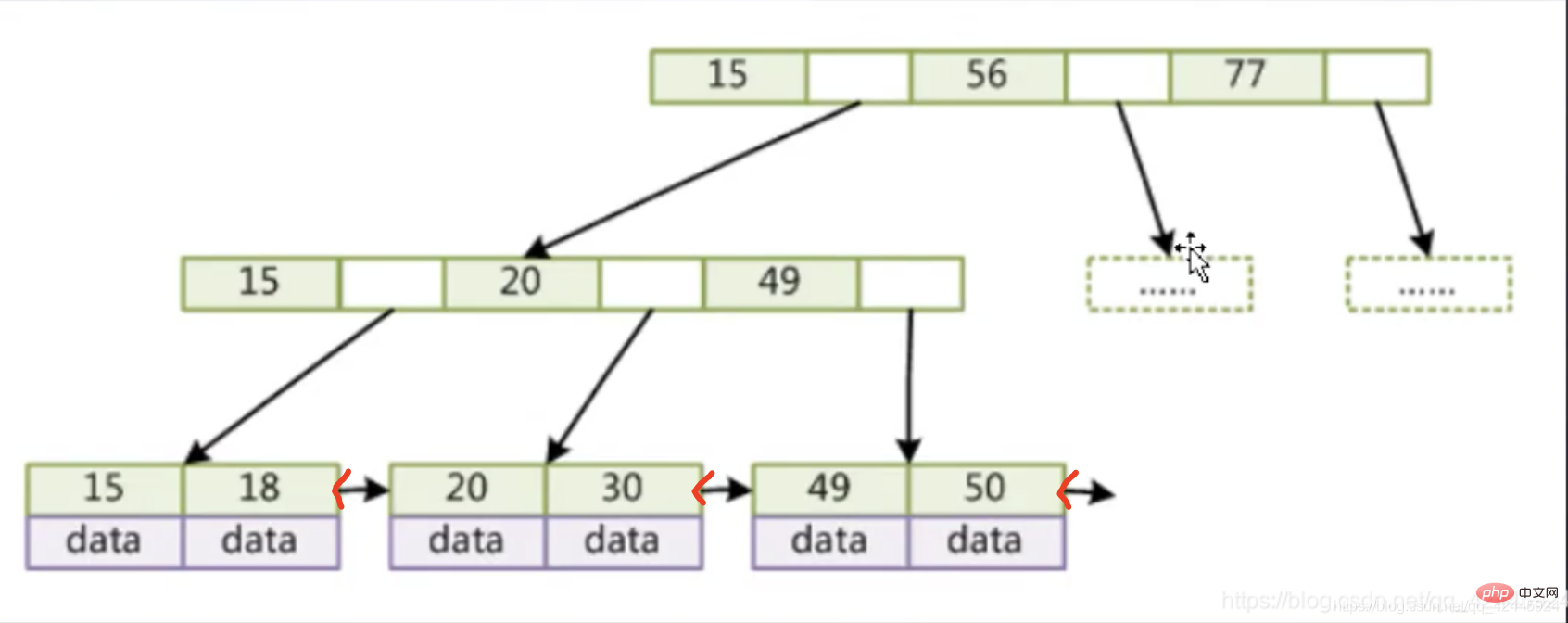
Wie Sie auf diesem Bild sehen können, speichern unsere Nicht-Blattknoten nur Indizes und keine Daten, und die Blattknoten sind mit Zeigern verbunden. Sowohl die Blattknoten als auch die Nicht-Blattknoten des B-Baums speichern Indizes und Daten, und die Zeiger der Blattknoten sind leer. Der B+-Baum platziert die Daten auf den Blattknoten, sodass die Nicht-Blattknoten mehr Indizes speichern können , jedes Mal Weitere Indizes können auch von der Festplatten-E/A abgerufen werden.
B+-Baumfunktionen sind wie folgt:
1. Nicht-Blattknoten speichern keine Daten, nur Indizes (redundant) und untergeordnete Zeiger können platziert werden
2. Blattknoten enthalten alle Indexfelder und Daten
3. Blattknoten sind mit Doppelzeigern verbunden, um die Leistung des Intervallzugriffs zu verbessern.
Der auf Baidu und vielen Blogs gezeichnete B + -Baum ist falsch. Vermeiden Sie unbedingt die Fallstricke.
Wenn Sie daran interessiert sind, die offizielle Erklärung von MySQL zu B+-Bäumen zu sehen, können Sie sie sich ansehen.
Link: Offizielle Website von MySQL Enthält die vollständigen Datensätze, die nicht in die Tabelle zurückgegeben werden müssen.
1.1)
Jeder weiß, dass es zwei häufig verwendete Speicher-Engines für MySQL gibt, MyISAM und InnoDB, aber haben Sie tatsächlich die zugrunde liegenden Datenspeicherstrukturen der beiden Speicher-Engines verstanden? Nehmen wir das Bild als Beispiel zur Erklärung:
Die test.myisam-Tabelle ist die MyISAM-Speicher-Engine und die Actor-Tabelle ist die InnoDB-Speicher-Engine. Sie können sehen, dass die MyISAM-Speicher-Engine drei Dateien hat, nämlich frm, MYD , und MYI. Die Abkürzung frm-frame speichert die Daten und MYI-MYIndex speichert nur Indizes und IBD Die Struktur der Tabelle, in der IBD-Dateien Indizes und Daten speichern, unterscheidet sich von InnoDB und MyISAM. Das folgende Bild dient als Beispiel, um zu veranschaulichen, dass der Primärschlüsselindex der MyISAM-Speicher-Engine eine Tabellenrückgabeoperation erfordert (nicht gruppierter Index
wobei 15 den Primärschlüsselindex und 0x07 die Festplattendatei speichert Der Adresszeiger wird in der Zeile 15 aufgezeichnet, wie zum Beispiel bei uns. Wenn Sie die Daten von 15 finden möchten, sollten Sie zuerst den Zeiger finden, der 15 entspricht, über den Primärschlüssel-Indexbaum, dann den Zeiger finden und dann zur MyD-Datei gehen Um die spezifischen Daten zu finden, ist eine zweite Suche erforderlich.
2.1)
Die folgende Abbildung dient als Beispiel, um zu veranschaulichen, dass der Primärschlüsselindex der InnoDB-Speicher-Engine keine Tabellenrückgabevorgänge erfordert. (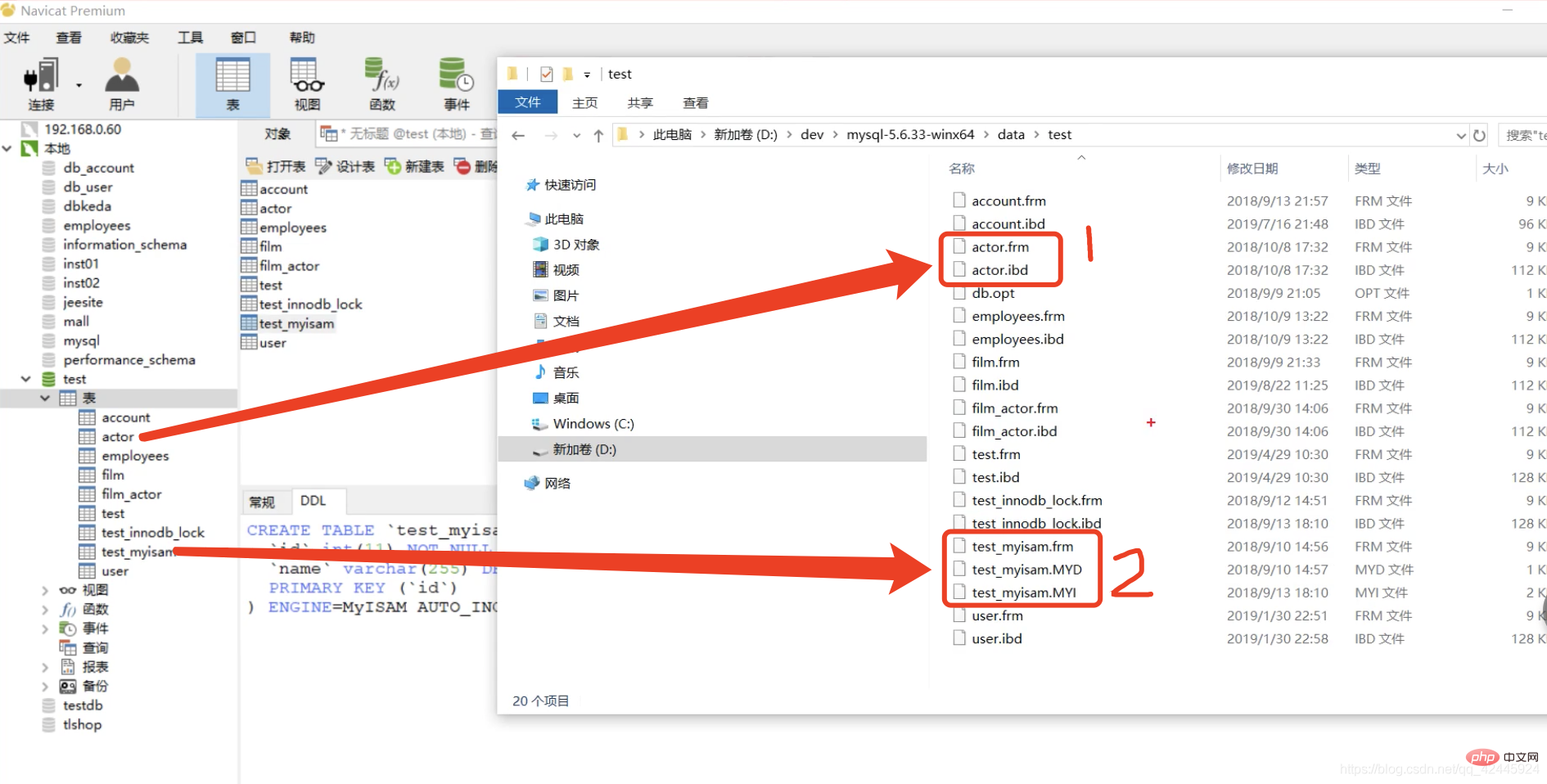 Clustered Index
Clustered Index
)Der Unterknoten der InnoDB-Speicher-Engine speichert zunächst den Index in Zeile 15 und die Spalte unter 15 speichert alle anderen Felder in der Zeile, in der sich der Index befindet. Wenn wir die Daten überprüfen möchten Von 15 können wir es direkt finden, ohne eine zweite Baumsuche durchführen zu müssen. 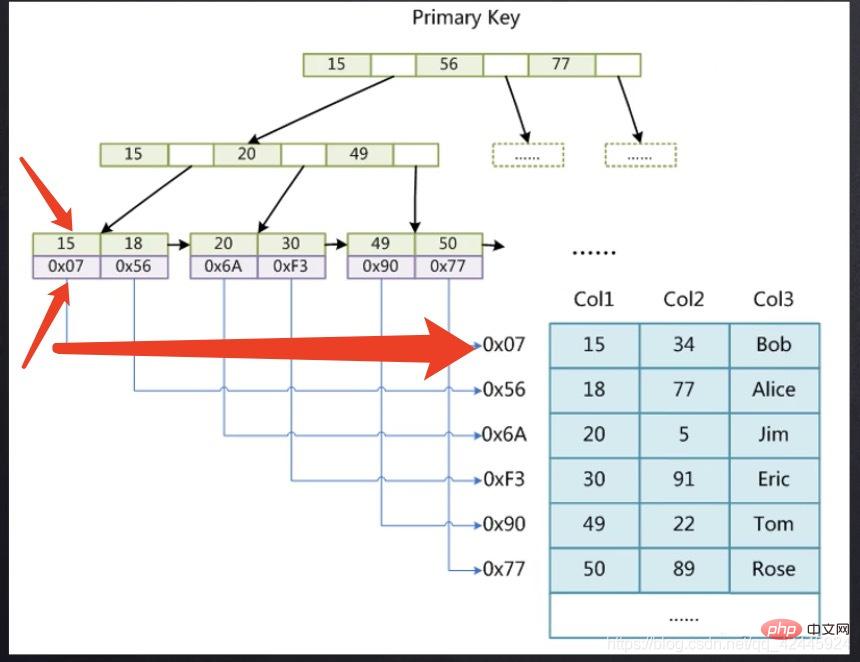
2. Nach Funktion klassifiziert: Hauptsächlich in fünf Kategorien unterteilt2.1 Primärschlüsselindex: Der InnoDB-Primärschlüsselindex erfordert keine Tabellenrückgabeoperation.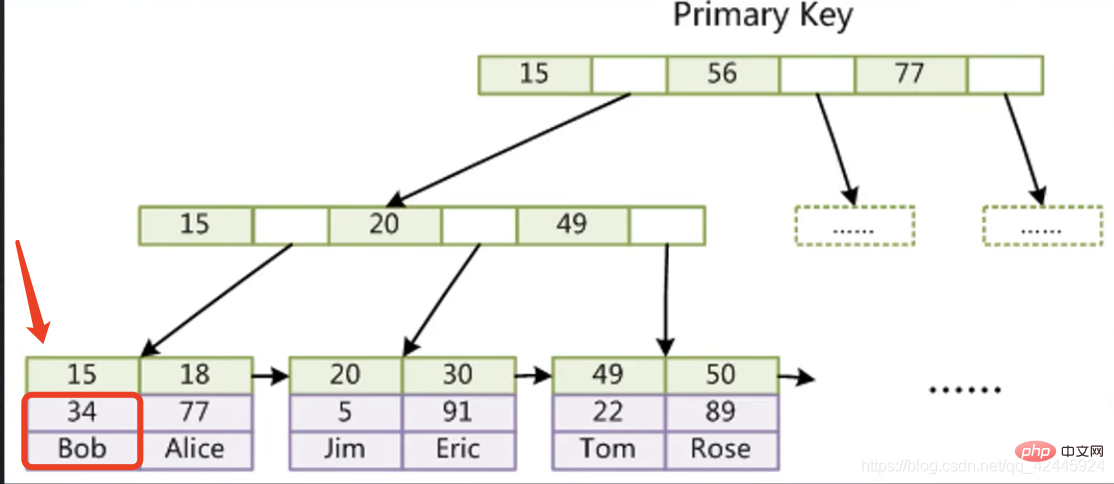 2.2
2.2
2.3 Eindeutiger Index Müssen Tabellen zurückgegeben werden? Bei einer bestimmten Abfrage deckt der Index unsere Abfrageanforderungen ab. Zu diesem Zeitpunkt besteht keine Notwendigkeit, zum Tisch zurückzukehren. Da der Covering-Index die Anzahl der Baumsuchen reduzieren und die Abfrageleistung deutlich verbessern kann, ist die Verwendung des Covering-Index ein gängiges Mittel zur Leistungsoptimierung. Wenn ich in der obigen Tabelle T „select * from T“ ausführe, wobei k zwischen 3 und 5 liegt, wie viele Baumsuchvorgänge müssen durchgeführt werden und wie viele Zeilen werden gescannt? Wenn die ausgeführte Anweisung ID aus T auswählt, wobei k zwischen 3 und 5 liegt, Zu diesem Zeitpunkt müssen Sie nur den Wert von ID überprüfen, und der Wert von ID befindet sich bereits im k-Indexbaum, sodass die Abfrageergebnisse vorliegen kann direkt ohne Rücksendung bereitgestellt werden Tisch 5. Indexoptimierung1. Das Obige beschreibt die grundlegenden Konzepte, Klassifizierungen und zugrunde liegenden strukturbezogenen Kenntnisse von Indizes. Lassen Sie uns über das relevante Wissen zur Indexoptimierung sprechen. 1.) 3 .) Zu den Abfragebedingungen Die Verwendung von Funktionen führt zu Indexfehlern
Zum Beispiel: Das Folgende ist die Initialisierungsanweisung dieser Tabelle. mysql> create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT '',
index k(k))
engine=InnoDB;
insert into T values(100,1, 'aa'),(200,2,'bb'),
(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
Schauen wir uns nun den Ausführungsablauf dieser SQL-Abfrageanweisung an. Schauen Sie sich das Bild unten an. 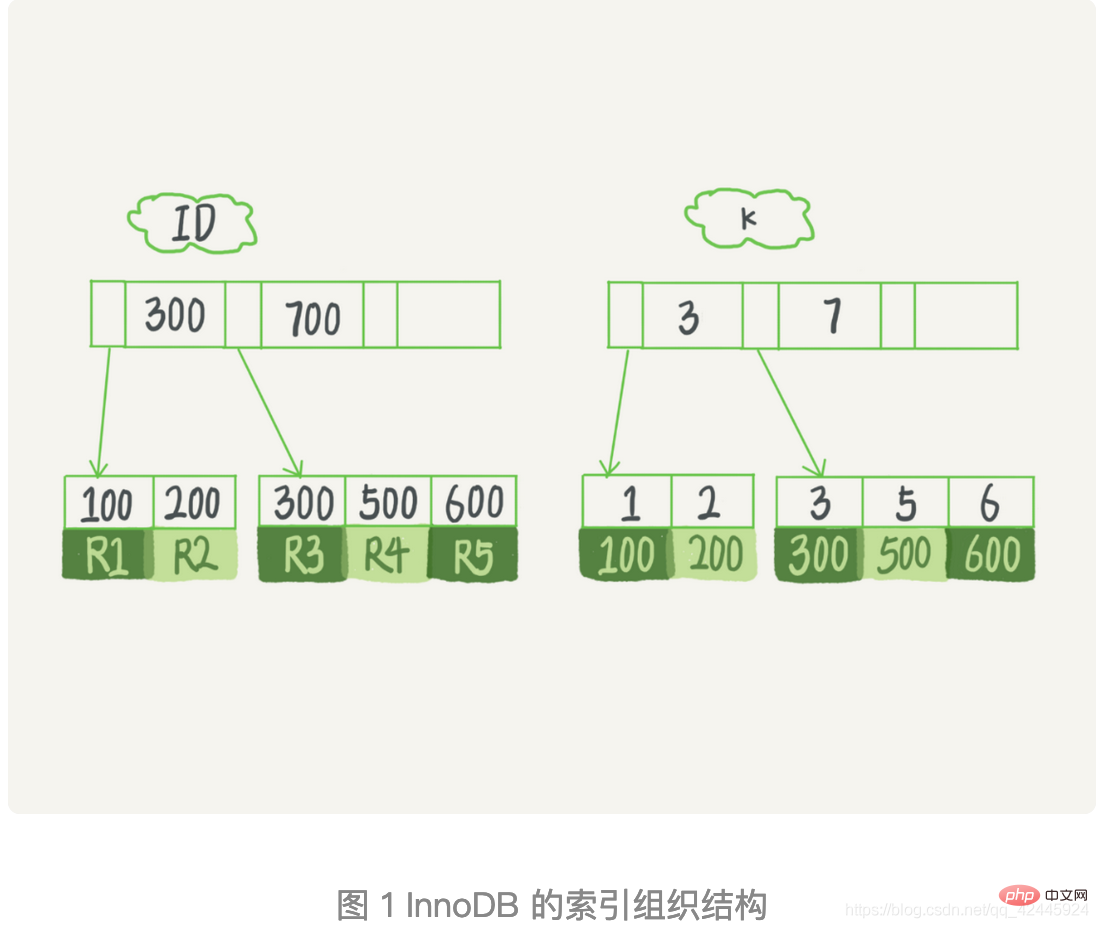
1.) Suchen Sie den Datensatz k=3 im k-Indexbaum und erhalten Sie ID = 300;
2.) Gehen Sie dann zum ID-Indexbaum und suchen Sie den R3, der ID=300;
entspricht 3.) Holen Sie sich den nächsten Wert k=5 im k-Indexbaum und erhalten Sie ID=500;
Holen Sie es in den k-Indexbaum. Der nächste Wert k=6 erfüllt die Bedingung nicht und die Schleife endet. In diesem Prozess kehrt
zum Suchprozess des Primärschlüsselindexbaums zurück, den wir als Tabelle zurück bezeichnen . Es ist ersichtlich, dass dieser Abfrageprozess 3 Datensätze des k-Indexbaums liest (Schritte 1, 3 und 5) und die Tabelle zweimal zurückgibt (Schritte 2 und 4). Der berechnete Index für die Spalte wird ungültig und alle Indizes nach dem Bereich sind ungültig
4.) Verwenden Sie die Operatoren != oder in where-Klauseln, was zu Indexfehlern führt
5.) Vermeiden Sie die Verwendung von oder, da dies zu Indexfehlern führt
6.) Die Verwendung von Fuzzy-Abfragen führt auch zu Indexfehlern. Sie können „like ‚a%‘“ anstelle von „%a%“ verwenden
7.) Versuchen Sie, abdeckende Indizes zu verwenden und select *-Anweisungen zu reduzieren
8 .) Erfüllen Sie die Präfixregel ganz links. Beginnen Sie mit der Spalte ganz links und überspringen Sie keine Spalten im Index
9.) Der Index schlägt fehl, wenn die Zeichenfolge nicht in einfache Anführungszeichen gesetzt wird
2 Erläuterung der Indexoptimierung. Erstellen Sie wie folgt eine neue Mitarbeitertabelle mit 5 Attributen. create table employees(
id int primary key auto_increment comment '主键自增',
name varchar(30) not null default '' comment'名字',
age int not null default 1 comment '年龄',
id_card varchar(40) not null default '' comment '身份证号',
position varchar(40) not null default '' comment '位置'
);
-- 创建联合索引
create index name_index on employees (name,age,position);
-- 插入一条数据
insert into employees(name,age,id_card,position) values('张三',15,
'201124199011035321','北京');-- 下面以10条sql测试,注意建立的联合索引顺序是 name,age,position
1.explain select * from employees where age=15 and position='北京' and name='张三';
2.explain select * from employees where name='张三' and age=15 and position='北京';
3.explain select * from employees where age=15 and name='张三';
4.explain select * from employees where position='北京' and name='张三';
5.explain select * from employees where position='北京' and age=15;
6.explain select * from employees where position='北京' and age>15 and name='张三';
7.explain select * from employees where position='北京';
8.explain select * from employees where age=15;
9.explain select * from employees where name='张三';
10.explain select * from employees where name != '张三';
以上10条sql有哪些是索引失效,有哪些是索引没有失效的呢?
相信同学们已经有了答案,但是答案对不对呢,下面我们一起分析下。
首先说第1条,查询条件把3个索引全部用上了,但是索引的顺序有变化,由name,age,position变成
了age,position,name,想到这里肯定有很多同学给出的答案就是索引失效,但是事实证明这个结果
是错的,索引生效,肯定有很多同学疑惑,为什么呢,这条sql不满足最左原则法则呀,这就要涉及到sql
的执行流程了,这里博主简单说下,sql执行有1个优化器的过程,优化器的作用之一就是索引的选择优化,
所以优化器帮我们把索引的顺序变成正确的了,所以索引生效。
下面是第1条按照索引顺序sql和第2条没有按照索引顺序sql的执行结果。
执行结果入下图:可以发现全部生效。
想学习sql的执行流程的可以看博主的另一篇关于sql执行流程的文章哦。 有的同学有疑问了,那最左原则没有用了吗? 答案:有用的。
现在我们说下第3、4、5条sql 第3条: explain select * from employees where age=15 and name='张三'; sql在执行的时候,优化器替我们把索引的顺序优化了,由 age -> name 变成 name -> age,这时 索引是生效的。 第4条: explain select * from employees where position='北京' and name='张三'; 索引顺序优化为name - > position,但是这时索引只有name索引生效,position没有生效,因为我 们建立的索引顺序是 name -> age - > position,你会发现跳过了age,索引本质也是一棵树,少 了一个节点,下面的索引当然不会生效了,这就没有满足最左原则法则。 第5条: explain select * from employees where position='北京' and age=15; 这就和第4条sql一样的道理了,第一个索引都不见了,后面的不可能生效。 执行结果如下:
Sie können feststellen, dass der Wert des dritten SQL-Typs ref ist, das Byte 126 ist und ref 2 Konstanten hat, die alle wirksam sind. 
Das 4. SQL ist nur 122 Bytes groß und die Referenz hat nur 1 Konstante, nur der Namensindex ist wirksam. 

下面说第6条sql,剩下的sql都是和之前的sql一样的道理。 explain select * from employees where position='北京' and age>15 and name='张三'; 这条sql我们会发现,把索引字段全部使用了并且当作条件查询,不一样的是age是范围查找,优化器替我 们把索引顺序优化成 name -> age - > position ,按照我们索引优化第2条:在列上做计算索引失效,范围之后的索引全部失效,想必答案同学们都知道了。 执行结果如下:
Das 6. SQL ist nur 126 Byte groß und der Wert des Typs ist Bereich, Bereichssuche, nur Namens- und Altersindizes sind wirksam. 
 Empfohlenes Lernen:
Empfohlenes Lernen:
Das obige ist der detaillierte Inhalt vonLassen Sie uns über die unterste Ebene und die Optimierung des MySQL-Index sprechen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



