

Was ist eine Transaktion in MySQL?

In MySQL ist eine Transaktion ein Mechanismus, eine Abfolge von Vorgängen und eine Programmausführungseinheit für den Zugriff auf die Datenbank und deren Aktualisierung. Eine Transaktion enthält einen oder mehrere Datenbankbetriebsbefehle, und alle Befehle werden an das System als Ganzes übermittelt oder widerrufen. Das heißt, dieser Satz von Datenbankbefehlen wird entweder ausgeführt oder keiner von ihnen wird ausgeführt.

Die Betriebsumgebung dieses Tutorials: Windows7-System, MySQL5.6-Version, Dell G3-Computer.
Eine Datenbanktransaktion ist ein Mechanismus, eine Operationssequenz und eine Programmausführungseinheit für den Zugriff auf und die Aktualisierung der Datenbank. Sie umfasst eine Reihe von Datenbankoperationsbefehlen.
Eine Transaktion sendet oder widerruft eine Vorgangsanforderung zusammen mit allen Befehlen als Ganzes an das System, d. h. dieser Satz von Datenbankbefehlen wird entweder ausgeführt oder nicht ausgeführt, sodass die Transaktion eine unteilbare logische Arbeitseinheit ist.
Bei gleichzeitigen Operationen auf einem Datenbanksystem werden Transaktionen als kleinste Steuereinheit verwendet, was sich besonders für Datenbanksysteme eignet, die von mehreren Benutzern gleichzeitig betrieben werden.
Als relationale Datenbank unterstützt MySQL Transaktionen. Dieser Artikel basiert auf MySQL5.6.
Sehen Sie sich zunächst die Grundlagen von MySQL-Transaktionen an.
1. Logische Architektur und Speicher-Engine
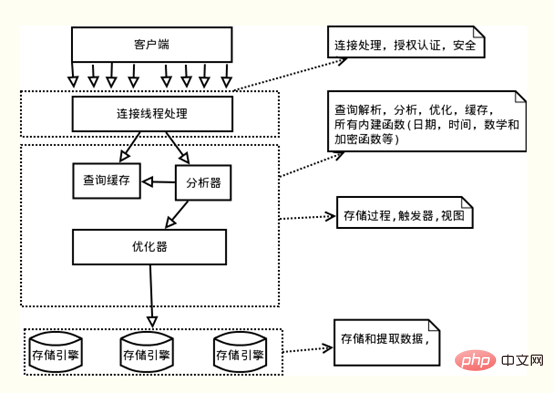
Bildquelle: https://blog.csdn.net/fuzhongmin05/article/details/70904190
Wie in der Abbildung oben gezeigt, der MySQL-Server Die logische Architektur beginnt mit: Sie kann von oben nach unten in drei Schichten unterteilt werden:
(1) Die erste Schicht: behandelt Clientverbindungen, Autorisierungsauthentifizierung usw.
(2) Die zweite Schicht: die Serverschicht, verantwortlich für das Parsen, Optimieren, Zwischenspeichern von Abfrageanweisungen und die Implementierung integrierter Funktionen, gespeicherter Prozeduren usw.
(3) Die dritte Schicht: Speicher-Engine, verantwortlich für die Speicherung und den Abruf von Daten in MySQL. Die Serverschicht in MySQL verwaltet keine Transaktionen und Transaktionen werden von der Speicher-Engine implementiert. Zu den Speicher-Engines von MySQL, die Transaktionen unterstützen, gehören InnoDB, NDB Cluster usw., wobei InnoDB am häufigsten verwendet wird. Andere Speicher-Engines wie MyIsam, Memory usw. unterstützen keine Transaktionen.
Sofern nicht anders angegeben, basieren die im folgenden Artikel beschriebenen Inhalte auf InnoDB.
2. Senden und Rollback
Eine typische MySQL-Transaktion funktioniert wie folgt:
start transaction; …… #一条或多条sql语句 commit;
wobei Starttransaktion den Start der Transaktion identifiziert, Commit die Transaktion festschreibt und die Ausführungsergebnisse in die Datenbank schreibt. Wenn bei der Ausführung von SQL-Anweisungen ein Problem auftritt, wird ein Rollback aufgerufen, um alle erfolgreich ausgeführten SQL-Anweisungen zurückzusetzen. Natürlich können Sie zum Rollback auch die Rollback-Anweisung direkt in der Transaktion verwenden.
Autocommit
MySQL verwendet standardmäßig den Autocommit-Modus, wie unten gezeigt:
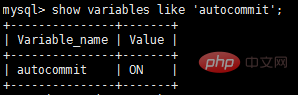
Wenn im Autocommit-Modus keine Starttransaktion zum expliziten Starten einer Transaktion vorhanden ist, werden alle SQL-Anweisungen als Transaktionen behandelt Führen Sie eine Festschreibungsoperation durch.
Sie können die automatische Festschreibung auf folgende Weise deaktivieren. Beachten Sie, dass die Änderung der Parameter in einer Verbindung keine Auswirkungen auf andere Verbindungen hat.
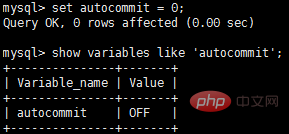
Wenn Autocommit deaktiviert ist, befinden sich alle SQL-Anweisungen in einer Transaktion, bis Commit oder Rollback ausgeführt wird, die Transaktion endet und eine andere Transaktion beginnt.
Spezielle Operationen
In MySQL gibt es einige spezielle Befehle. Wenn diese Befehle in einer Transaktion ausgeführt werden, wird die sofortige Ausführung der Transaktion erzwungen, z. B. DDL-Anweisungen (Tabelle erstellen/Tabelle löschen/Ändern/Tabelle). ), Sperrtabellen-Anweisung usw.
Die häufig verwendeten Befehle zum Auswählen, Einfügen, Aktualisieren und Löschen erzwingen jedoch nicht das Festschreiben der Transaktion.
3. ACID-Merkmale
ACID sind die vier Merkmale, die Transaktionen messen:
- Atomizität (oder Unteilbarkeit)
- Konsistenz (Konsistenz)
- Isolation (Isolation)
- Dauerhaftigkeit
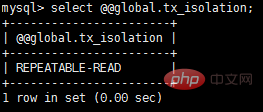
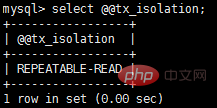
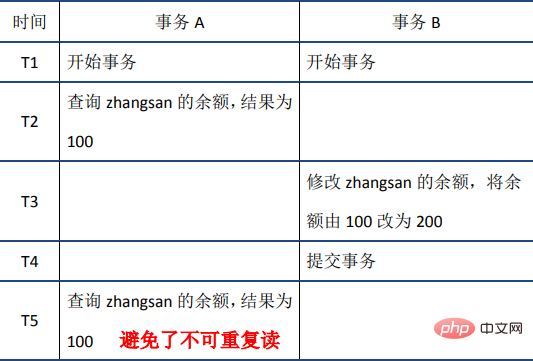
Gemäß streng Gemäß den Standards gelten nur Transaktionen als Transaktionen, die gleichzeitig die ACID-Merkmale erfüllen. In den Implementierungen großer Datenbankanbieter gibt es jedoch nur sehr wenige Transaktionen, die tatsächlich ACID erfüllen. Beispielsweise erfüllt die NDB-Cluster-Transaktion von MySQL nicht die Dauerhaftigkeit und Isolation; die Standard-Transaktionsisolationsstufe von InnoDB ist wiederholbares Lesen, was die Isolation nicht erfüllt; Sprichwort ACID sind die Bedingungen, die Transaktionen erfüllen müssen, sondern die vier Dimensionen der Messung von Transaktionen.
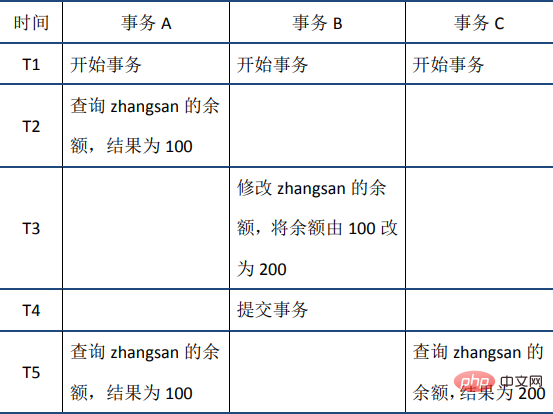
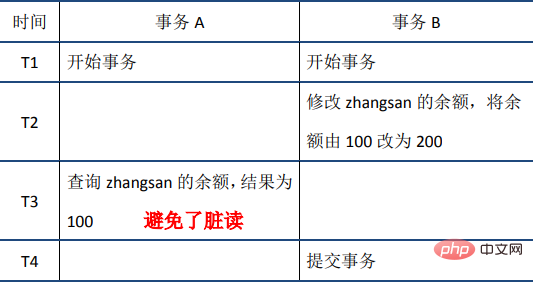
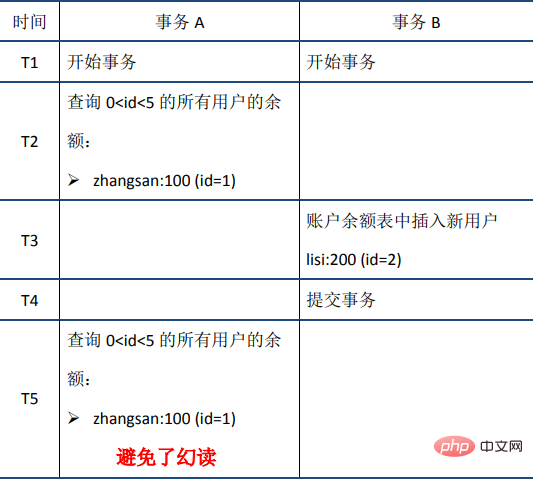
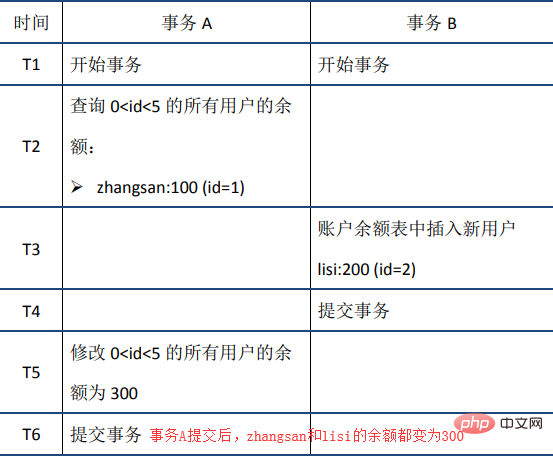
Die ACID-Merkmale und ihre Implementierungsprinzipien werden zum besseren Verständnis im Folgenden ausführlich vorgestellt. Die Reihenfolge der Einführung ist nicht streng A-C-I-D. Atomizität1 Atomizität bedeutet, dass eine Transaktion eine unteilbare Arbeitseinheit ist, in der alle Vorgänge ausgeführt werden oder keine ausgeführt werden. Wenn eine SQL-Anweisung in der Transaktion nicht ausgeführt werden kann, muss auch die ausgeführte Anweisung zurückgesetzt werden und die Datenbank kehrt zur zurück Vorheriger Status der Transaktion. 2. Implementierungsprinzip: Protokoll rückgängig machen Bevor wir das Prinzip der Atomizität erläutern, stellen wir zunächst das MySQL-Transaktionsprotokoll vor. Es gibt viele Arten von MySQL-Protokollen, z. B. Binärprotokolle, Fehlerprotokolle, Abfrageprotokolle, langsame Abfrageprotokolle usw. Darüber hinaus bietet die InnoDB-Speicher-Engine auch zwei Arten von Transaktionsprotokollen: Redo-Protokoll (Redo-Protokoll) und Rückgängig-Protokoll ( Rollback-Protokoll). Das Redo-Log wird verwendet, um die Dauerhaftigkeit der Transaktion sicherzustellen; das Undo-Log ist die Grundlage für die Atomizität und Isolation der Transaktion. Lassen Sie uns über das Rückgängig-Protokoll sprechen. Der Schlüssel zum Erreichen der Atomizität besteht darin, alle erfolgreich ausgeführten SQL-Anweisungen rückgängig machen zu können, wenn die Transaktion zurückgesetzt wird. InnoDB realisiert ein Rollback, indem es sich auf das Rückgängig-Protokoll verlässt: Wenn eine Transaktion die Datenbank ändert, generiert InnoDB das entsprechende Rückgängig-Protokoll. Wenn die Transaktionsausführung fehlschlägt oder ein Rollback aufgerufen wird, muss die Transaktion ausgeführt werden Zum Zurücksetzen können Sie die Informationen im Rückgängig-Protokoll verwenden, um die Daten auf den Zustand vor der Änderung zurückzusetzen. Undo-Protokoll ist ein logisches Protokoll, das Informationen zur SQL-Ausführung aufzeichnet. Wenn ein Rollback auftritt, führt InnoDB basierend auf dem Inhalt des Rückgängig-Protokolls das Gegenteil der vorherigen Arbeit aus: Für jede Einfügung wird während des Rollbacks ein Löschvorgang ausgeführt, für jeden Löschvorgang wird eine Einfügung während des Rollbacks ausgeführt Beim Rollback wird ein Löschvorgang ausgeführt, bei dem eine umgekehrte Aktualisierung durchgeführt wird, um die Daten wieder zu ändern. Nehmen Sie den Aktualisierungsvorgang als Beispiel: Wenn eine Transaktion eine Aktualisierung ausführt, enthält das generierte Rückgängig-Protokoll Informationen wie den Primärschlüssel der geänderten Zeile (um zu wissen, welche Zeilen geändert wurden) und welche Spalten geändert wurden , und die Werte dieser Spalten vor und nach der Änderung können Sie diese Informationen verwenden, um die Daten beim Rollback auf den Zustand vor der Aktualisierung wiederherzustellen. Persistenz 1. Definition Persistenz bedeutet, dass die Änderungen an der Datenbank dauerhaft sein sollten, sobald eine Transaktion festgeschrieben wurde. Nachfolgende Operationen oder Ausfälle sollten keine Auswirkungen darauf haben. 2. Implementierungsprinzip: Redo-Log Sowohl Redo-Log als auch Undo-Log gehören zum InnoDB-Transaktionslog. Lassen Sie uns zunächst über die Hintergründe der Existenz des Redo-Logs sprechen. InnoDB ist die Speicher-Engine von MySQL und die Daten werden auf der Festplatte gespeichert. Wenn jedoch jedes Mal Festplatten-E/A erforderlich ist, um Daten zu lesen und zu schreiben, ist die Effizienz sehr gering. Zu diesem Zweck stellt InnoDB einen Cache (Buffer Pool) bereit. Der Buffer Pool enthält die Zuordnung einiger Datenseiten auf der Festplatte und dient als Puffer für den Zugriff auf die Datenbank: Beim Lesen von Daten aus der Datenbank werden diese zunächst ausgelesen Pufferpool. Wenn der Pufferpool nicht im Pool vorhanden ist, werden sie beim Schreiben von Daten in die Datenbank zuerst in den Pufferpool geschrieben und dann geändert Die Daten im Pufferpool werden regelmäßig auf der Festplatte aktualisiert (dieser Vorgang wird als Dirty Flushing bezeichnet). Die Verwendung des Pufferpools verbessert die Effizienz beim Lesen und Schreiben von Daten erheblich, bringt jedoch auch neue Probleme mit sich: Wenn MySQL ausfällt und die geänderten Daten im Pufferpool nicht auf die Festplatte geleert wurden, führt dies zu Datenverlust. Die Haltbarkeit der Transaktion kann nicht garantiert werden. Um dieses Problem zu lösen, wurde das Redo-Log eingeführt: Wenn die Daten geändert werden, wird der Vorgang zusätzlich zur Änderung der Daten im Pufferpool auch im Redo-Log aufgezeichnet, wenn die Transaktion übermittelt wird wird aufgerufen, um die Redo-Log-Platte zu spülen. Wenn MySQL ausfällt, können Sie die Daten im Redo-Log lesen und die Datenbank beim Neustart wiederherstellen. Das Redo-Protokoll verwendet WAL (Write-Ahead-Protokollierung, Write-Ahead-Protokoll). Alle Änderungen werden zuerst in das Protokoll geschrieben und dann im Pufferpool aktualisiert, um sicherzustellen, dass die Daten nicht aufgrund von MySQL-Ausfallzeiten verloren gehen und somit die Haltbarkeit gewährleistet ist Anforderungen. Da das Redo-Protokoll beim Festschreiben der Transaktion auch das Protokoll auf die Festplatte schreiben muss, warum ist es dann schneller, als die geänderten Daten im Pufferpool direkt auf die Festplatte zu schreiben (d. h. sie zu verschmutzen)? Es gibt hauptsächlich zwei Gründe: (1) Die schmutzige Reinigung ist eine zufällige E/A, da der Datenspeicherort, der jedes Mal geändert wird, zufällig ist, das Schreiben des Redo-Protokolls jedoch eine Anhängeoperation ist und zur sequentiellen E/A gehört. (2) Die Einheit der Verunreinigung ist die Datenseite (Seite). Eine kleine Änderung auf einer Seite erfordert das Schreiben der gesamten Seite; zu schreibende, ungültige E/A wird stark reduziert. 3. Redo-Log und Binlog Wir wissen, dass es in MySQL auch ein Binlog (Binärprotokoll) gibt, das auch Schreibvorgänge aufzeichnen und zur Datenwiederherstellung verwendet werden kann, aber die beiden unterscheiden sich grundlegend: (1) Verschiedene Funktionen: Redo-Log wird für die Wiederherstellung nach einem Absturz verwendet, um sicherzustellen, dass MySQL-Ausfallzeiten die Haltbarkeit nicht beeinträchtigen. Binlog wird für die Point-in-Time-Wiederherstellung verwendet, um sicherzustellen, dass der Server Daten basierend auf Zeitpunkten wiederherstellen kann Wird auch für die Master-Slave-Replikation verwendet. (2) Verschiedene Ebenen: Redo Log wird von der InnoDB-Speicher-Engine implementiert, während Binlog von der MySQL-Serverschicht implementiert wird (siehe Einführung in die logische MySQL-Architektur weiter oben im Artikel) und sowohl InnoDB als auch andere unterstützt Speicher-Engines. (3)内容不同:redo log是物理日志,内容基于磁盘的Page;binlog的内容是二进制的,根据binlog_format参数的不同,可能基于sql语句、基于数据本身或者二者的混合。 (4)写入时机不同:binlog在事务提交时写入;redo log的写入时机相对多元: 1. 定义 与原子性、持久性侧重于研究事务本身不同,隔离性研究的是不同事务之间的相互影响。隔离性是指,事务内部的操作与其他事务是隔离的,并发执行的各个事务之间不能互相干扰。严格的隔离性,对应了事务隔离级别中的Serializable (可串行化),但实际应用中出于性能方面的考虑很少会使用可串行化。 隔离性追求的是并发情形下事务之间互不干扰。简单起见,我们主要考虑最简单的读操作和写操作(加锁读等特殊读操作会特殊说明),那么隔离性的探讨,主要可以分为两个方面: 2. 锁机制 首先来看两个事务的写操作之间的相互影响。隔离性要求同一时刻只能有一个事务对数据进行写操作,InnoDB通过锁机制来保证这一点。 锁机制的基本原理可以概括为:事务在修改数据之前,需要先获得相应的锁;获得锁之后,事务便可以修改数据;该事务操作期间,这部分数据是锁定的,其他事务如果需要修改数据,需要等待当前事务提交或回滚后释放锁。 行锁与表锁 按照粒度,锁可以分为表锁、行锁以及其他位于二者之间的锁。表锁在操作数据时会锁定整张表,并发性能较差;行锁则只锁定需要操作的数据,并发性能好。但是由于加锁本身需要消耗资源(获得锁、检查锁、释放锁等都需要消耗资源),因此在锁定数据较多情况下使用表锁可以节省大量资源。MySQL中不同的存储引擎支持的锁是不一样的,例如MyIsam只支持表锁,而InnoDB同时支持表锁和行锁,且出于性能考虑,绝大多数情况下使用的都是行锁。 如何查看锁信息 有多种方法可以查看InnoDB中锁的情况,例如: 下面来看一个例子: 此时查看锁的情况: show engine innodb status查看锁相关的部分: 通过上述命令可以查看事务24052和24053占用锁的情况;其中lock_type为RECORD,代表锁为行锁(记录锁);lock_mode为X,代表排它锁(写锁)。 除了排它锁(写锁)之外,MySQL中还有共享锁(读锁)的概念。由于本文重点是MySQL事务的实现原理,因此对锁的介绍到此为止,后续会专门写文章分析MySQL中不同锁的区别、使用场景等,欢迎关注。 介绍完写操作之间的相互影响,下面讨论写操作对读操作的影响。 3. 脏读、不可重复读和幻读 首先来看并发情况下,读操作可能存在的三类问题: (1)脏读:当前事务(A)中可以读到其他事务(B)未提交的数据(脏数据),这种现象是脏读。举例如下(以账户余额表为例): (2)不可重复读:在事务A中先后两次读取同一个数据,两次读取的结果不一样,这种现象称为不可重复读。脏读与不可重复读的区别在于:前者读到的是其他事务未提交的数据,后者读到的是其他事务已提交的数据。举例如下: (3) Phantomlesung: In Transaktion A wird die Datenbank gemäß einer bestimmten Bedingung zweimal abgefragt, und die Anzahl der Ergebnisse der beiden Abfragen ist unterschiedlich. Dieses Phänomen wird als Phantomlesung bezeichnet. Der Unterschied zwischen nicht wiederholbarem Lesen und Phantomlesen kann leicht verstanden werden: Ersteres bedeutet, dass sich die Daten geändert haben, während letzteres bedeutet, dass sich die Anzahl der Datenzeilen geändert hat. Zum Beispiel: 4. Transaktionsisolationsstufe Der SQL-Standard definiert vier Isolationsstufen und legt fest, ob die oben genannten Probleme unter jeder Isolationsstufe bestehen. Im Allgemeinen gilt: Je niedriger die Isolationsstufe, desto geringer ist der Systemaufwand, desto höher ist die unterstützte Parallelität, aber desto schlechter ist die Isolation. Die Beziehung zwischen Isolationsstufen und Leseproblemen ist wie folgt: In tatsächlichen Anwendungen verursacht read uncommitted viele Probleme während der Parallelität, aber die Leistungsverbesserung ist im Vergleich zu anderen Isolationsstufen sehr begrenzt, sodass es weniger verwendet wird . SerialisierbarDa die Parallelitätseffizienz erzwungen wird, ist sie sehr gering. Sie kann nur verwendet werden, wenn die Anforderungen an die Datenkonsistenz extrem hoch sind und keine Parallelität akzeptabel ist, sodass sie selten verwendet wird. Daher ist in den meisten Datenbanksystemen die Standardisolationsstufe Read Committed (wie Oracle) oder Repeatable Read (im Folgenden als RR bezeichnet). Sie können die globale Isolationsstufe und die Isolationsstufe dieser Sitzung über die folgenden zwei Befehle anzeigen: Die Standardisolationsstufe von InnoDB ist RR, und wir werden uns später auf RR konzentrieren. Es ist zu beachten, dass RR im SQL-Standard das Phantomleseproblem nicht vermeiden kann, das von InnoDB implementierte RR jedoch das Phantomleseproblem vermeidet. 5. MVCC RR löst Probleme wie Dirty Reads, nicht wiederholbare Lesevorgänge, Phantom Reads usw. Es verwendet MVCC: Der vollständige Name von MVCC ist Multi-Version Concurrency Control, eine Parallelität mit mehreren Versionen Steuerprotokoll. Das folgende Beispiel spiegelt die Eigenschaften von MVCC gut wider: Gleichzeitig können die von verschiedenen Transaktionen gelesenen Daten unterschiedlich sein (d. h. mehrere Versionen) – zum Zeitpunkt T5 können Transaktion A und Transaktion C unterschiedliche Versionen lesen. Der größte Vorteil von MVCC besteht darin, dass das Lesen nicht gesperrt ist, sodass es keinen Konflikt zwischen Lesen und Schreiben gibt und die Parallelitätsleistung gut ist. InnoDB implementiert MVCC und mehrere Datenversionen können koexistieren, hauptsächlich basierend auf den folgenden Technologien und Datenstrukturen: 1) Versteckte Spalten: Jede Datenzeile in InnoDB verfügt über versteckte Spalten, und die versteckten Spalten enthalten die Transaktions-ID und den Zeiger von Diese Datenzeile rückgängig machen usw. 2) Versionskette basierend auf dem Rückgängig-Protokoll: Wie bereits erwähnt, enthält die verborgene Spalte jeder Datenzeile einen Zeiger auf das Rückgängig-Protokoll, und jedes Rückgängig-Protokoll zeigt auch auf eine frühere Version des Rückgängig-Protokolls und bildet so eine Versionskette. 3) ReadView: Durch das Ausblenden von Spalten und Versionsketten kann MySQL Daten in einer bestimmten Version wiederherstellen. Welche Version wiederhergestellt werden soll, muss jedoch anhand von ReadView bestimmt werden. Die sogenannte ReadView bedeutet, dass eine Transaktion (aufgezeichnet als Transaktion A) zu einem bestimmten Zeitpunkt einen Snapshot des gesamten Transaktionssystems (trx_sys) erstellt. Wenn später ein Lesevorgang ausgeführt wird, wird die Transaktions-ID in den gelesenen Daten verglichen der trx_sys-Snapshot, also Bestimmen Sie, ob die Daten für ReadView sichtbar sind, d. h. ob sie für Transaktion A sichtbar sind. Der Hauptinhalt in trx_sys und die Methode zur Beurteilung der Sichtbarkeit lauten wie folgt: Im Folgenden wird die RR-Isolationsstufe als Beispiel genommen und anhand der verschiedenen oben genannten Probleme separat erläutert. (1) Schmutziges Lesen 当事务A在T3时刻读取zhangsan的余额前,会生成ReadView,由于此时事务B没有提交仍然活跃,因此其事务id一定在ReadView的rw_trx_ids中,因此根据前面介绍的规则,事务B的修改对ReadView不可见。接下来,事务A根据指针指向的undo log查询上一版本的数据,得到zhangsan的余额为100。这样事务A就避免了脏读。 (2)不可重复读 当事务A在T2时刻读取zhangsan的余额前,会生成ReadView。此时事务B分两种情况讨论,一种是如图中所示,事务已经开始但没有提交,此时其事务id在ReadView的rw_trx_ids中;一种是事务B还没有开始,此时其事务id大于等于ReadView的low_limit_id。无论是哪种情况,根据前面介绍的规则,事务B的修改对ReadView都不可见。 当事务A在T5时刻再次读取zhangsan的余额时,会根据T2时刻生成的ReadView对数据的可见性进行判断,从而判断出事务B的修改不可见;因此事务A根据指针指向的undo log查询上一版本的数据,得到zhangsan的余额为100,从而避免了不可重复读。 (3)幻读 MVCC避免幻读的机制与避免不可重复读非常类似。 当事务A在T2时刻读取0 当事务A在T5时刻再次读取0 扩展 前面介绍的MVCC,是RR隔离级别下“非加锁读”实现隔离性的方式。下面是一些简单的扩展。 (1)读已提交(RC)隔离级别下的非加锁读 RC与RR一样,都使用了MVCC,其主要区别在于: RR是在事务开始后第一次执行select前创建ReadView,直到事务提交都不会再创建。根据前面的介绍,RR可以避免脏读、不可重复读和幻读。 RC每次执行select前都会重新建立一个新的ReadView,因此如果事务A第一次select之后,事务B对数据进行了修改并提交,那么事务A第二次select时会重新建立新的ReadView,因此事务B的修改对事务A是可见的。因此RC隔离级别可以避免脏读,但是无法避免不可重复读和幻读。 (2)加锁读与next-key lock 按照是否加锁,MySQL的读可以分为两种: 一种是非加锁读,也称作快照读、一致性读,使用普通的select语句,这种情况下使用MVCC避免了脏读、不可重复读、幻读,保证了隔离性。 另一种是加锁读,查询语句有所不同,如下所示: 加锁读在查询时会对查询的数据加锁(共享锁或排它锁)。由于锁的特性,当某事务对数据进行加锁读后,其他事务无法对数据进行写操作,因此可以避免脏读和不可重复读。而避免幻读,则需要通过next-key lock。next-key lock是行锁的一种,实现相当于record lock(记录锁) + gap lock(间隙锁);其特点是不仅会锁住记录本身(record lock的功能),还会锁定一个范围(gap lock的功能)。因此,加锁读同样可以避免脏读、不可重复读和幻读,保证隔离性。 6. 总结 Zusammenfassend lässt sich sagen, dass die von InnoDB implementierte RR durch den Sperrmechanismus (einschließlich Next-Key-Sperre), MVCC (einschließlich versteckter Datenspalten, Versionskette basierend auf Rückgängig-Protokoll, ReadView) usw. ein gewisses Maß an Isolation erreicht erfüllen Erforderlich in den meisten Szenarien. Es sollte jedoch beachtet werden, dass RR zwar das Phantomleseproblem vermeidet, aber doch nicht serialisierbar ist und keine vollständige Isolation garantieren kann: Das erste Beispiel, wenn der erste Lesevorgang in der Transaktion nicht erfolgt. Beim gesperrten Lesen wird beim zweiten Lesen das gesperrte Lesen verwendet. Wenn sich die Daten zwischen den beiden Lesevorgängen ändern, sind die Ergebnisse der beiden Lesevorgänge unterschiedlich, da MVCC beim gesperrten Lesen nicht verwendet wird. Das zweite Beispiel ist wie unten gezeigt, Sie können es selbst überprüfen. 1. Grundkonzept Konsistenz bedeutet, dass nach der Ausführung der Transaktion die Integritätsbeschränkungen der Datenbank nicht zerstört werden und der Datenstatus vor und nach der Ausführung der Transaktion legal ist . Zu den Integritätsbeschränkungen der Datenbank gehören unter anderem: Entitätsintegrität (z. B. der Primärschlüssel der Zeile ist vorhanden und eindeutig), Spaltenintegrität (z. B. Typ, Größe und Länge des Felds müssen den Anforderungen entsprechen) , Fremdschlüsseleinschränkungen und benutzerdefinierte Integrität (z. B. sollte vor und nach der Übertragung die Summe der Salden der beiden Konten unverändert bleiben). 2. Implementierung Das obige ist der detaillierte Inhalt vonWas ist eine Transaktion in MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!四、隔离性
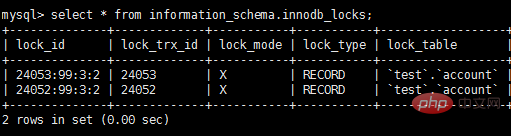
select * from information_schema.innodb_locks; #锁的概况
show engine innodb status; #InnoDB整体状态,其中包括锁的情况
#在事务A中执行:
start transaction;
update account SET balance = 1000 where id = 1;
#在事务B中执行:
start transaction;
update account SET balance = 2000 where id = 1;

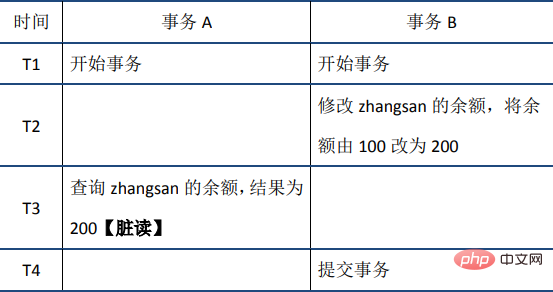
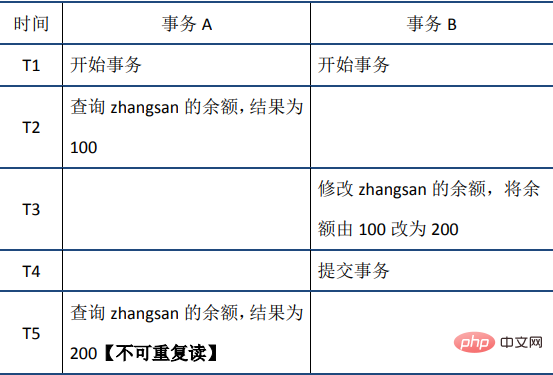
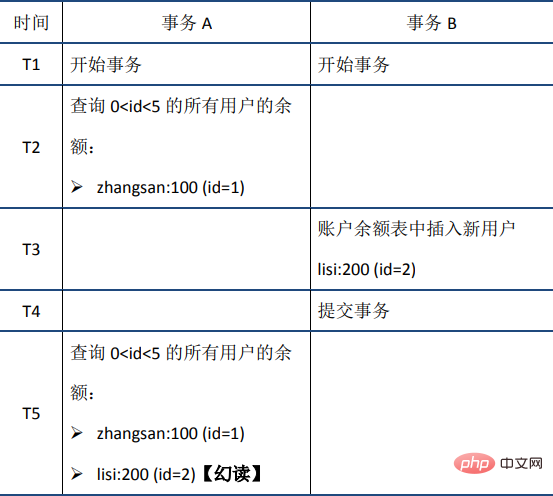
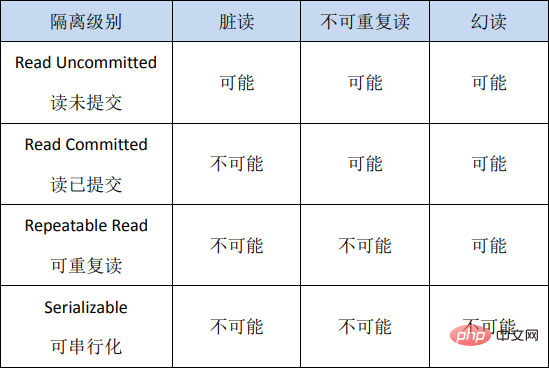
#共享锁读取
select...lock in share mode
#排它锁读取
select...for update
Konsistenz
Garantie der Atomizität, Haltbarkeit und Isolation. Wenn diese Eigenschaften nicht garantiert werden können, kann die Konsistenz der Transaktion nicht garantiert werden.
Konsistenz: Das von Transaktionen verfolgte ultimative Ziel, konsistente Implementierung erfordert sowohl Garantien auf Datenbankebene als auch Garantien auf Anwendungsebene

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
In der MySQL -Datenbank wird die Beziehung zwischen dem Benutzer und der Datenbank durch Berechtigungen und Tabellen definiert. Der Benutzer verfügt über einen Benutzernamen und ein Passwort, um auf die Datenbank zuzugreifen. Die Berechtigungen werden über den Zuschussbefehl erteilt, während die Tabelle durch den Befehl create table erstellt wird. Um eine Beziehung zwischen einem Benutzer und einer Datenbank herzustellen, müssen Sie eine Datenbank erstellen, einen Benutzer erstellen und dann Berechtigungen erfüllen.
 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
1. Verwenden Sie den richtigen Index, um das Abrufen von Daten zu beschleunigen, indem die Menge der skanierten Datenmenge ausgewählt wird. Wenn Sie mehrmals eine Spalte einer Tabelle nachschlagen, erstellen Sie einen Index für diese Spalte. Wenn Sie oder Ihre App Daten aus mehreren Spalten gemäß den Kriterien benötigen, erstellen Sie einen zusammengesetzten Index 2. Vermeiden Sie aus. Auswählen * Nur die erforderlichen Spalten. Wenn Sie alle unerwünschten Spalten auswählen, konsumiert dies nur mehr Serverspeicher und veranlasst den Server bei hoher Last oder Frequenzzeiten, beispielsweise die Auswahl Ihrer Tabelle, wie beispielsweise die Spalten wie innovata und updated_at und Zeitsteuer und dann zu entfernen.
 Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Navicat selbst speichert das Datenbankkennwort nicht und kann das verschlüsselte Passwort nur abrufen. Lösung: 1. Überprüfen Sie den Passwort -Manager. 2. Überprüfen Sie Navicats "Messnot Password" -Funktion; 3.. Setzen Sie das Datenbankkennwort zurück; 4. Kontaktieren Sie den Datenbankadministrator.
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 So kopieren Sie Tabellen in MySQL
Apr 08, 2025 pm 07:24 PM
So kopieren Sie Tabellen in MySQL
Apr 08, 2025 pm 07:24 PM
Durch das Kopieren einer Tabelle in MySQL müssen neue Tabellen erstellt, Daten eingefügt, Fremdschlüssel festgelegt, Indizes, Auslöser, gespeicherte Verfahren und Funktionen kopiert werden. Zu den spezifischen Schritten gehören: Erstellen einer neuen Tabelle mit derselben Struktur. Fügen Sie Daten aus der ursprünglichen Tabelle in eine neue Tabelle ein. Legen Sie die gleiche fremde Schlüsselbeschränkung fest (wenn die Originaltabelle eine hat). Erstellen Sie den gleichen Index. Erstellen Sie denselben Auslöser (wenn die ursprüngliche Tabelle eine hat). Erstellen Sie dieselbe gespeicherte Prozedur oder Funktion (wenn die ursprüngliche Tabelle verwendet wird).
 Wie kann ich das Datenbankkennwort in Navicat für Mariadb anzeigen?
Apr 08, 2025 pm 09:18 PM
Wie kann ich das Datenbankkennwort in Navicat für Mariadb anzeigen?
Apr 08, 2025 pm 09:18 PM
Navicat für MariADB kann das Datenbankkennwort nicht direkt anzeigen, da das Passwort in verschlüsselter Form gespeichert ist. Um die Datenbanksicherheit zu gewährleisten, gibt es drei Möglichkeiten, Ihr Passwort zurückzusetzen: Setzen Sie Ihr Passwort über Navicat zurück und legen Sie ein komplexes Kennwort fest. Zeigen Sie die Konfigurationsdatei an (nicht empfohlen, ein hohes Risiko). Verwenden Sie Systembefehlsleitungs -Tools (nicht empfohlen, Sie müssen die Befehlszeilen -Tools beherrschen).
 Wie man MySQL sieht
Apr 08, 2025 pm 07:21 PM
Wie man MySQL sieht
Apr 08, 2025 pm 07:21 PM
Zeigen Sie die MySQL -Datenbank mit dem folgenden Befehl an: Verbindung zum Server: MySQL -U -Benutzername -P -Kennwort ausführen STEILE -Datenbanken; Befehl zum Abrufen aller vorhandenen Datenbanken auswählen Datenbank: Verwenden Sie den Datenbanknamen. Tabelle Ansicht: Tabellen anzeigen; Tabellenstruktur anzeigen: Beschreiben Sie den Tabellennamen; Daten anzeigen: Wählen Sie * aus Tabellenname;
