
 Datenbank
Redis
Lassen Sie uns darüber sprechen, wie Sie Redis verwenden, um verteilte Sperren zu implementieren
Datenbank
Redis
Lassen Sie uns darüber sprechen, wie Sie Redis verwenden, um verteilte Sperren zu implementieren
Lassen Sie uns darüber sprechen, wie Sie Redis verwenden, um verteilte Sperren zu implementieren

Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis, das hauptsächlich Probleme im Zusammenhang mit verteilten Sperren vorstellt. Wir rufen normalerweise Threads auf, um Sperren aufzurufen und Sperren aufzuheben Der Wert der Sperrvariablen ist 0. Ich hoffe, dass es für alle hilfreich ist.

Empfohlenes Lernen: Redis-Lerntutorial
Der Zusammenhang und der Unterschied zwischen Sperren auf einer einzelnen Maschine und verteilten Sperren
Werfen wir zunächst einen Blick auf die Sperren auf einer einzelnen Maschine.
Für Multithread-Programme, die auf einem einzelnen Computer ausgeführt werden, kann die Sperre selbst durch eine Variable dargestellt werden.
- Wenn der Variablenwert 0 ist, bedeutet dies, dass kein Thread die Sperre erworben hat.
- Wenn der Variablenwert 1 ist, bedeutet dies, dass ein Thread die Sperre bereits erworben hat.
Wir sagen normalerweise, dass ein Thread eine Sperr- und Freigabeoperation aufruft. Wenn ein Thread eine Sperroperation aufruft, prüft er tatsächlich, ob der Wert der Sperrvariable 0 ist. Wenn er 0 ist, setzen Sie den Wert der Sperrvariable auf 1, um anzuzeigen, dass die Sperre erworben wurde. Wenn er nicht 0 ist, wird eine Fehlermeldung zurückgegeben, die darauf hinweist, dass die Sperre fehlgeschlagen ist und ein anderer Thread die Sperre erworben hat. Wenn ein Thread den Sperrfreigabevorgang aufruft, setzt er den Wert der Sperrvariablen tatsächlich auf 0, damit andere Threads die Sperre erwerben können.
Ich verwende einen Code, um die Vorgänge zum Sperren und Freigeben von Sperren zu demonstrieren, wobei lock die Sperrvariable ist.
acquire_lock(){
if lock == 0
lock = 1
return 1
else
return 0
}
release_lock(){
lock = 0
return 1
} Ähnlich wie die Sperre auf einer einzelnen Maschine kann auch die verteilte Sperre mithilfe einer Variablen implementiert werden. Die Betriebslogik zum Sperren und Freigeben von Sperren auf dem Client stimmt auch mit der Betriebslogik zum Sperren und Freigeben von Sperren auf einem einzelnen Computer überein: Beim Sperren müssen Sie auch den Wert der Sperrvariablen beurteilen und beurteilen, ob die Sperre dies kann basierend auf dem Wert der Sperrvariablen erfolgreich gesperrt werden. Beim Freigeben muss der Wert der Sperrvariablen auf 0 gesetzt werden, was angibt, dass der Client die Sperre nicht mehr hält.
Im Gegensatz zu Threads, die Sperren auf einem einzelnen Computer ausführen, müssen Sperrvariablen von einem gemeinsam genutzten Speichersystem verwaltet werden. Nur auf diese Weise können mehrere Clients auf das gemeinsam genutzte Speichersystem zugreifen. Dementsprechend werden die Vorgänge des Sperrens und Freigebens von Sperren zum Lesen, Beurteilen und Festlegen des Sperrvariablenwerts im gemeinsam genutzten Speichersystem. Auf diese Weise können wir die beiden Anforderungen für die Implementierung verteilter Sperren ableiten.
Anforderung 1: Der Prozess des Sperrens und Freigebens der verteilten Sperre umfasst mehrere Vorgänge. Daher müssen wir bei der Implementierung verteilter Sperren die Atomizität dieser Sperrvorgänge sicherstellen.
Anforderung 2: Das gemeinsam genutzte Speichersystem speichert die Sperrvariablen. Wenn das gemeinsam genutzte Speichersystem ausfällt oder ausfällt, kann der Client keine Sperre ausführen Operationen. Bei der Implementierung verteilter Sperren müssen wir die Zuverlässigkeit des gemeinsam genutzten Speichersystems und damit die Zuverlässigkeit der Sperre berücksichtigen.
Okay, jetzt, da wir die spezifischen Anforderungen kennen, wollen wir lernen, wie Redis verteilte Sperren implementiert.
Tatsächlich können wir es basierend auf einem einzelnen Redis-Knoten implementieren oder mehrere Redis-Knoten verwenden. In diesen beiden Fällen ist die Zuverlässigkeit des Schlosses nicht gleich. Schauen wir uns zunächst die Implementierungsmethode basierend auf einem einzelnen Redis-Knoten an.
Implementierung verteilter Sperren basierend auf einem einzelnen Redis-Knoten Als gemeinsames Speichersystem bei der Implementierung verteilter Sperren kann Redis Schlüssel-Wert-Paare verwenden, um Sperrvariablen zu speichern und dann von verschiedenen gesendete Sperren zu empfangen und zu verarbeiten und Sperren freizugeben Betriebsanforderung des Kunden. Wie werden also Schlüssel und Wert des Schlüssel-Wert-Paares bestimmt? Wir müssen der Sperrvariablen einen Variablennamen geben, diesen Variablennamen als Schlüssel des Schlüssel-Wert-Paares verwenden und den Wert der Sperrvariablen als Wert des Schlüssel-Wert-Paares verwenden. Auf diese Weise kann Redis speichern Die Sperrvariable und der Client können Sperroperationen auch über Redis-Befehlsoperationen implementieren.
Um Ihnen das Verständnis zu erleichtern, habe ich ein Bild gezeichnet, das zeigt, wie Redis Schlüssel-Wert-Paare zum Speichern von Sperrvariablen verwendet und wie zwei Clients gleichzeitig Sperren anfordern. 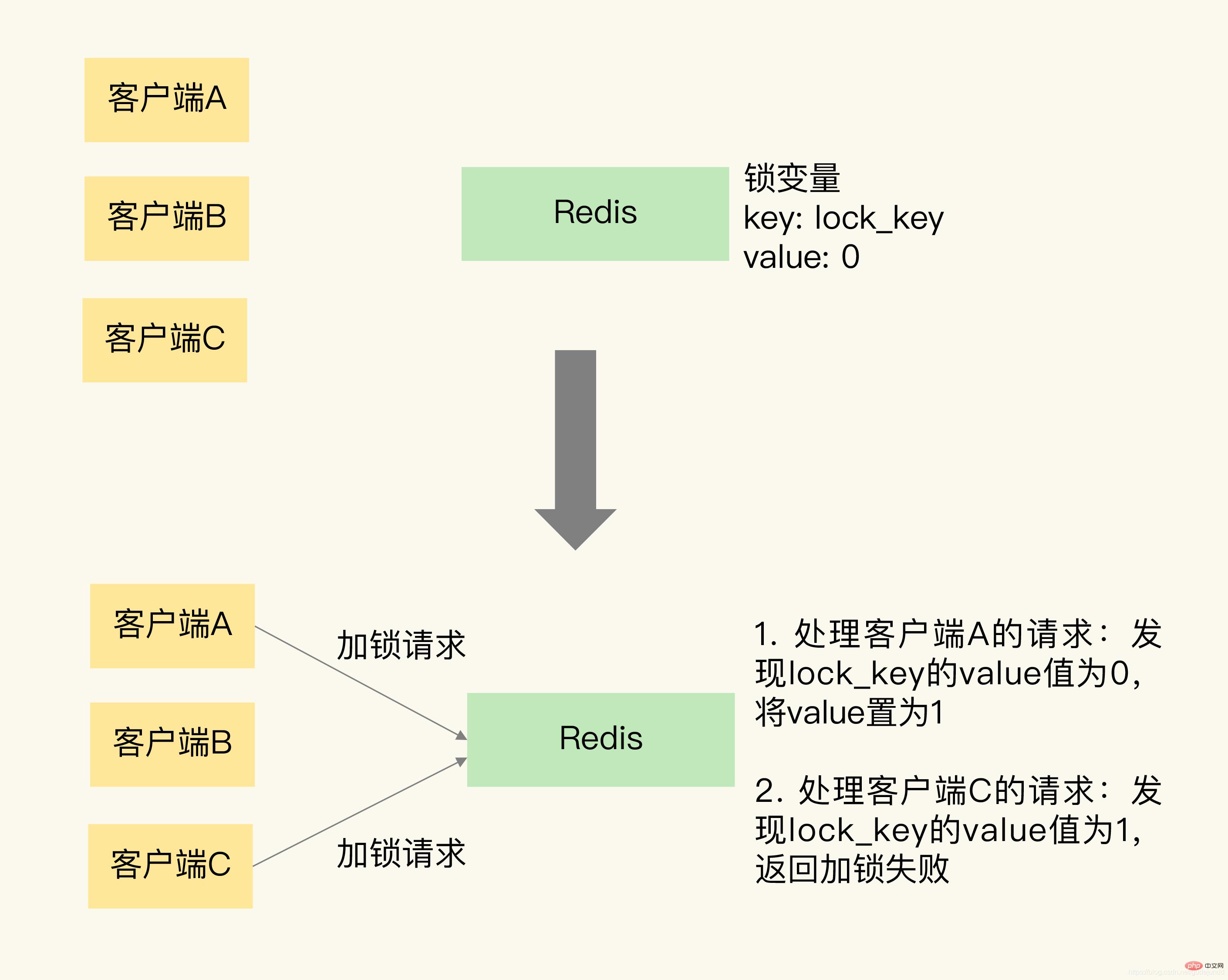 Wie Sie sehen können, kann Redis ein Schlüssel-Wert-Paar lock_key:0 verwenden, um die Sperrvariable zu speichern, wobei der Schlüssel lock_key ist, der auch der Name der Sperrvariablen ist 0.
Wie Sie sehen können, kann Redis ein Schlüssel-Wert-Paar lock_key:0 verwenden, um die Sperrvariable zu speichern, wobei der Schlüssel lock_key ist, der auch der Name der Sperrvariablen ist 0.
Lassen Sie uns den Verriegelungsvorgang noch einmal analysieren.
Im Bild fordern Client A und C gleichzeitig Sperren an. Da Redis einen einzelnen Thread zum Verarbeiten von Anforderungen verwendet, verarbeitet Redis ihre Anforderungen seriell, auch wenn die Clients A und C gleichzeitig Sperranforderungen an Redis senden.
Wir gehen davon aus, dass Redis zuerst die Anfrage von Client A verarbeitet, den Wert von lock_key liest und feststellt, dass lock_key 0 ist. Daher setzt Redis den Wert von lock_key auf 1, was darauf hinweist, dass es gesperrt wurde. Unmittelbar danach verarbeitet Redis die Anfrage von Client C. Zu diesem Zeitpunkt stellt Redis fest, dass der Wert von lock_key bereits 1 ist, und gibt daher Informationen zum Sperrfehler zurück.
Ich habe gerade über den Sperrvorgang gesprochen. Wie kann ich die Sperre lösen? Tatsächlich bedeutet das Aufheben der Sperre, dass der Wert der Sperrvariablen direkt auf 0 gesetzt wird.
我还是借助一张图片来解释一下。这张图片展示了客户端 A 请求释放锁的过程。当客户端 A 持有锁时,锁变量 lock_key 的值为 1。客户端 A 执行释放锁操作后,Redis 将 lock_key 的值置为 0,表明已经没有客户端持有锁了。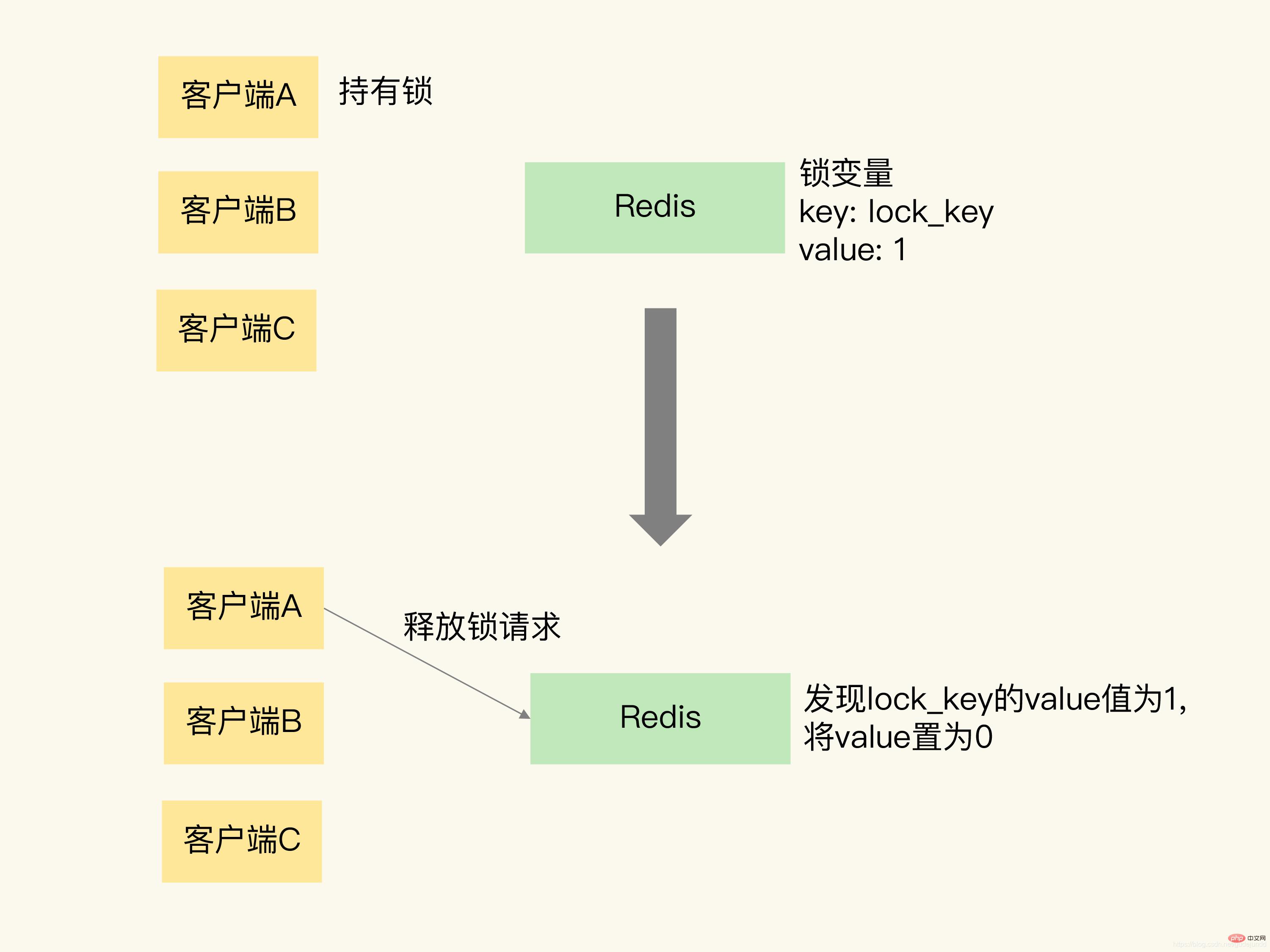
因为加锁包含了三个操作(读取锁变量、判断锁变量值以及把锁变量值设置为 1),而这三个操作在执行时需要保证原子性。那怎么保证原子性呢?
要想保证操作的原子性,有两种通用的方法,分别是使用 Redis 的单命令操作和使用 Lua 脚本。那么,在分布式加锁场景下,该怎么应用这两个方法呢?
我们先来看下,Redis 可以用哪些单命令操作实现加锁操作。
首先是 SETNX 命令,它用于设置键值对的值。具体来说,就是这个命令在执行时会判断键值对是否存在,如果不存在,就设置键值对的值,如果存在,就不做任何设置。
举个例子,如果执行下面的命令时,key 不存在,那么 key 会被创建,并且值会被设置为 value;如果 key 已经存在,SETNX 不做任何赋值操作。
SETNX key value
对于释放锁操作来说,我们可以在执行完业务逻辑后,使用 DEL 命令删除锁变量。不过,你不用担心锁变量被删除后,其他客户端无法请求加锁了。因为 SETNX 命令在执行时,如果要设置的键值对(也就是锁变量)不存在,SETNX 命令会先创建键值对,然后设置它的值。所以,释放锁之后,再有客户端请求加锁时,SETNX 命令会创建保存锁变量的键值对,并设置锁变量的值,完成加锁。
总结来说,我们就可以用 SETNX 和 DEL 命令组合来实现加锁和释放锁操作。下面的伪代码示例显示了锁操作的过程,你可以看下。
// 加锁 SETNX lock_key 1 // 业务逻辑 DO THINGS // 释放锁 DEL lock_key
不过,使用 SETNX 和 DEL 命令组合实现分布锁,存在两个潜在的风险。
第一个风险是,假如某个客户端在执行了 SETNX 命令、加锁之后,紧接着却在操作共享数据时发生了异常,结果一直没有执行最后的 DEL 命令释放锁。因此,锁就一直被这个客户端持有,其它客户端无法拿到锁,也无法访问共享数据和执行后续操作,这会给业务应用带来影响。
针对这个问题,一个有效的解决方法是,给锁变量设置一个过期时间。这样一来,即使持有锁的客户端发生了异常,无法主动地释放锁,Redis 也会根据锁变量的过期时间,在锁变量过期后,把它删除。其它客户端在锁变量过期后,就可以重新请求加锁,这就不会出现无法加锁的问题了。
我们再来看第二个风险。如果客户端 A 执行了 SETNX 命令加锁后,假设客户端 B 执行了 DEL 命令释放锁,此时,客户端 A 的锁就被误释放了。如果客户端 C 正好也在申请加锁,就可以成功获得锁,进而开始操作共享数据。这样一来,客户端 A 和 C 同时在对共享数据进行操作,数据就会被修改错误,这也是业务层不能接受的。
为了应对这个问题,我们需要能区分来自不同客户端的锁操作,具体咋做呢?其实,我们可以在锁变量的值上想想办法。
在使用 SETNX 命令进行加锁的方法中,我们通过把锁变量值设置为 1 或 0,表示是否加锁成功。1 和 0 只有两种状态,无法表示究竟是哪个客户端进行的锁操作。所以,我们在加锁操作时,可以让每个客户端给锁变量设置一个唯一值,这里的唯一值就可以用来标识当前操作的客户端。在释放锁操作时,客户端需要判断,当前锁变量的值是否和自己的唯一标识相等,只有在相等的情况下,才能释放锁。这样一来,就不会出现误释放锁的问题了。
知道了解决方案,那么,在 Redis 中,具体是怎么实现的呢?我们再来了解下。
在查看具体的代码前,我要先带你学习下 Redis 的 SET 命令。
我们刚刚在说 SETNX 命令的时候提到,对于不存在的键值对,它会先创建再设置值(也就是“不存在即设置”),为了能达到和 SETNX 命令一样的效果,Redis 给 SET 命令提供了类似的选项 NX,用来实现“不存在即设置”。如果使用了 NX 选项,SET 命令只有在键值对不存在时,才会进行设置,否则不做赋值操作。此外,SET 命令在执行时还可以带上 EX 或 PX 选项,用来设置键值对的过期时间。
举个例子,执行下面的命令时,只有 key 不存在时,SET 才会创建 key,并对 key 进行赋值。另外,key 的存活时间由 seconds 或者 milliseconds 选项值来决定。
SET key value [EX seconds | PX milliseconds] [NX]
有了 SET 命令的 NX 和 EX/PX 选项后,我们就可以用下面的命令来实现加锁操作了。
// 加锁, unique_value作为客户端唯一性的标识
SET lock_key unique_value NX PX 10000
其中,unique_value 是客户端的唯一标识,可以用一个随机生成的字符串来表示,PX 10000 则表示 lock_key 会在 10s 后过期,以免客户端在这期间发生异常而无法释放锁。
因为在加锁操作中,每个客户端都使用了一个唯一标识,所以在释放锁操作时,我们需要判断锁变量的值,是否等于执行释放锁操作的客户端的唯一标识,如下所示:
//释放锁 比较unique_value是否相等,避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end这是使用 Lua 脚本(unlock.script)实现的释放锁操作的伪代码,其中,KEYS[1]表示 lock_key,ARGV[1]是当前客户端的唯一标识,这两个值都是我们在执行 Lua 脚本时作为参数传入的。
最后,我们执行下面的命令,就可以完成锁释放操作了。
redis-cli --eval unlock.script lock_key , unique_value
你可能也注意到了,在释放锁操作中,我们使用了 Lua 脚本,这是因为,释放锁操作的逻辑也包含了读取锁变量、判断值、删除锁变量的多个操作,而 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
好了,到这里,你了解了如何使用 SET 命令和 Lua 脚本在 Redis 单节点上实现分布式锁。但是,我们现在只用了一个 Redis 实例来保存锁变量,如果这个 Redis 实例发生故障宕机了,那么锁变量就没有了。此时,客户端也无法进行锁操作了,这就会影响到业务的正常执行。所以,我们在实现分布式锁时,还需要保证锁的可靠性。那怎么提高呢?这就要提到基于多个 Redis 节点实现分布式锁的方式了。
基于多个 Redis 节点实现高可靠的分布式锁
当我们要实现高可靠的分布式锁时,就不能只依赖单个的命令操作了,我们需要按照一定的步骤和规则进行加解锁操作,否则,就可能会出现锁无法工作的情况。“一定的步骤和规则”是指啥呢?其实就是分布式锁的算法。
为了避免 Redis 实例故障而导致的锁无法工作的问题,Redis 的开发者 Antirez 提出了分布式锁算法 Redlock。
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 实例依次请求加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁了,否则加锁失败。这样一来,即使有单个 Redis 实例发生故障,因为锁变量在其它实例上也有保存,所以,客户端仍然可以正常地进行锁操作,锁变量并不会丢失。
我们来具体看下 Redlock 算法的执行步骤。Redlock 算法的实现需要有 N 个独立的 Redis 实例。接下来,我们可以分成 3 步来完成加锁操作。
第一步是,客户端获取当前时间。
第二步是,客户端按顺序依次向 N 个 Redis 实例执行加锁操作。
这里的加锁操作和在单实例上执行的加锁操作一样,使用 SET 命令,带上 NX,EX/PX 选项,以及带上客户端的唯一标识。当然,如果某个 Redis 实例发生故障了,为了保证在这种情况下,Redlock 算法能够继续运行,我们需要给加锁操作设置一个超时时间。
如果客户端在和一个 Redis 实例请求加锁时,一直到超时都没有成功,那么此时,客户端会和下一个 Redis 实例继续请求加锁。加锁操作的超时时间需要远远地小于锁的有效时间,一般也就是设置为几十毫秒。
第三步是,一旦客户端完成了和所有 Redis 实例的加锁操作,客户端就要计算整个加锁过程的总耗时。
客户端只有在满足下面的这两个条件时,才能认为是加锁成功。
- 条件一:客户端从超过半数(大于等于 N/2+1)的 Redis 实例上成功获取到了锁;
- 条件二:客户端获取锁的总耗时没有超过锁的有效时间。
在满足了这两个条件后,我们需要重新计算这把锁的有效时间,计算的结果是锁的最初有效时间减去客户端为获取锁的总耗时。如果锁的有效时间已经来不及完成共享数据的操作了,我们可以释放锁,以免出现还没完成数据操作,锁就过期了的情况。
当然,如果客户端在和所有实例执行完加锁操作后,没能同时满足这两个条件,那么,客户端向所有 Redis 节点发起释放锁的操作。
Im Redlock-Algorithmus ist der Vorgang zum Aufheben der Sperre derselbe wie der Vorgang zum Aufheben der Sperre für eine einzelne Instanz. Führen Sie einfach das Lua-Skript aus, das die Sperre aufhebt. Auf diese Weise kann der normale Betrieb der verteilten Sperre gewährleistet werden, solange mehr als die Hälfte der N Redis-Instanzen normal funktionieren.
Wenn Sie also in tatsächlichen Geschäftsanwendungen die Zuverlässigkeit verteilter Sperren verbessern möchten, können Sie dies durch den Redlock-Algorithmus erreichen.
Empfohlenes Lernen: Redis-Lerntutorial
Das obige ist der detaillierte Inhalt vonLassen Sie uns darüber sprechen, wie Sie Redis verwenden, um verteilte Sperren zu implementieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
