
 Datenbank
Redis
Führen Sie Sie Schritt für Schritt durch, um den Hochverfügbarkeitscluster von Redis zu verstehen
Datenbank
Redis
Führen Sie Sie Schritt für Schritt durch, um den Hochverfügbarkeitscluster von Redis zu verstehen
Führen Sie Sie Schritt für Schritt durch, um den Hochverfügbarkeitscluster von Redis zu verstehen

Dieser Artikel bringt Ihnen relevantes Wissen über Redis, das hauptsächlich Cluster-bezogene Probleme vorstellt. Der Cluster ist eine verteilte Datenbanklösung und bietet Replikations- und Fehlerübertragungsfunktionen alle.

Empfohlenes Lernen: Redis-Lerntutorial
Mehrere Redis-Hochverfügbarkeitslösungen. Einschließlich: „Master-Slave-Modus“, „Sentinel-Mechanismus“ und „Sentinel-Cluster“.
- Der „Master-Slave-Modus“ bietet die Vorteile der Trennung von Lesen und Schreiben, der Aufteilung des Lesedrucks, der Datensicherung und der Bereitstellung mehrerer Kopien.
- Der „Sentinel-Mechanismus“ kann den Slave-Knoten automatisch zum Master-Knoten hochstufen, nachdem der Master-Knoten ausgefallen ist, und der Dienst kann ohne manuelles Eingreifen wiederhergestellt werden.
- „Sentinel Cluster“ löst das Problem des Single Point of Failure und der „Fehleinschätzung“, die durch Sentinel mit einer einzigen Maschine verursacht wird.
Redis ist von der einfachsten Standalone-Version zu Datenpersistenz, Master-Slave-Mehrfachkopien und Sentinel-Clustern übergegangen. Durch diese Optimierung sind sowohl Leistung als auch Stabilität immer höher geworden.
Aber im Laufe der Zeit ist das Geschäftsvolumen des Unternehmens explosionsartig gewachsen. Kann das Architekturmodell zu diesem Zeitpunkt noch so viel Verkehr vertragen?
Zum Beispiel gibt es eine solche Anforderung: Verwenden Sie Redis, um 50 Millionen Schlüssel-Wert-Paare zu speichern. Jedes Schlüssel-Wert-Paar ist ungefähr 512B, um eine schnelle Bereitstellung zu ermöglichen Um externe Dienste bereitzustellen, verwenden wir Cloud-Hosts, um Redis-Instanzen auszuführen. Wie wählt man also die Speicherkapazität des Cloud-Hosts aus? 5000 万个键值对,每个键值对大约是 512B,为了能快速部署并对外提供服务,我们采用云主机来运行 Redis 实例,那么,该如何选择云主机的内存容量呢?
通过计算,这些键值对所占的内存空间大约是 25GB(5000 万 *512B)。
想到的第一个方案就是:选择一台 32GB 内存的云主机来部署 Redis。因为 32GB 的内存能保存所有数据,而且还留有 7GB,可以保证系统的正常运行。
同时,还采用 RDB 对数据做持久化,以确保 Redis 实例故障后,还能从 RDB 恢复数据。
但是,在使用的过程中会发现,Redis 的响应有时会非常慢。通过 INFO命令 查看 Redis 的latest_fork_usec指标值(表示最近一次 fork 的耗时),结果发现这个指标值特别高。
这跟 Redis 的持久化机制有关系。
在使用 RDB 进行持久化时,Redis 会 fork 子进程来完成,fork 操作的用时和 Redis 的数据量是正相关的,而 fork 在执行时会阻塞主线程。数据量越大,fork 操作造成的主线程阻塞的时间越长。
所以,在使用 RDB 对 25GB 的数据进行持久化时,数据量较大,后台运行的子进程在 fork 创建时阻塞了主线程,于是就导致 Redis 响应变慢了。
显然这个方案是不可行的,我们必须要寻找其他的方案。
如何保存更多数据?
为了保存大量数据,我们一般有两种方法:「纵向扩展」和「横向扩展」:
- 纵向扩展:升级单个 Redis 实例的资源配置,包括增加内存容量、增加磁盘容量、使用更高配置的 CPU;
- 横向扩展:横向增加当前 Redis 实例的个数。
首先,「纵向扩展」的好处是,实施起来简单、直接。不过,这个方案也面临两个潜在的问题。
- 第一个问题是,当使用 RDB 对数据进行持久化时,如果数据量增加,需要的内存也会增加,主线程
fork子进程时就可能会阻塞。 - 第二个问题:纵向扩展会受到硬件和成本的限制。 这很容易理解,毕竟,把内存从 32GB 扩展到 64GB 还算容易,但是,要想扩充到 1TB,就会面临硬件容量和成本上的限制了。
与「纵向扩展」相比,「横向扩展」是一个扩展性更好的方案。这是因为,要想保存更多的数据,采用这种方案的话,只用增加 Redis 的实例个数就行了,不用担心单个实例的硬件和成本限制。
Redis 集群就是基于「横向扩展」实现的 ,通过启动多个 Redis 实例组成一个集群,然后按照一定的规则,把收到的数据划分成多份,每一份用一个实例来保存。
Redis 集群
Redis 集群是一种分布式数据库方案,集群通过分片(sharding,也可以叫切片
INFO-Befehl, um den Indikatorwert latest_fork_usec von Redis zu überprüfen (der die für die letzte Abzweigung benötigte Zeit angibt). Es wurde festgestellt, dass dieser Indikatorwert besonders hoch ist. 🎜🎜Dies hängt mit dem Persistenzmechanismus von Redis zusammen. 🎜🎜Wenn RDB für die Persistenz verwendet wird, führt Redis einen Fork durch, um den Vorgang abzuschließen. Die Zeit des fork-Vorgangs hängt positiv von der Menge ab Daten in Redis und fork blockieren den Hauptthread während der Ausführung. Je größer die Datenmenge, desto länger wird der Hauptthread aufgrund des Fork-Vorgangs blockiert. 🎜🎜Wenn Sie also RDB verwenden, um 25 GB Daten beizubehalten, ist die Datenmenge groß und der im Hintergrund laufende untergeordnete Prozess wird blockiert, wenn fork Der Hauptthread führt dazu, dass die Redis-Antwort langsamer wird. 🎜🎜Offensichtlich ist diese Lösung nicht machbar und wir müssen andere Lösungen finden. 🎜Wie speichere ich mehr Daten?
🎜Um eine große Datenmenge zu speichern, haben wir im Allgemeinen zwei Methoden: „Vertikale Erweiterung“ und „Horizontale Erweiterung“: 🎜🎜🎜Vertikale Erweiterung : Aktualisieren Sie eine einzelne Redis-Ressourcenkonfiguration der Instanz, einschließlich der Erhöhung der Speicherkapazität, der Erhöhung der Festplattenkapazität und der Verwendung einer CPU mit höherer Konfiguration. 🎜🎜Horizontale Erweiterung: Erhöhen Sie die Anzahl der aktuellen Redis-Instanzen horizontal. 🎜🎜🎜Der Vorteil der „vertikalen Expansion“ liegt zunächst einmal darin, dass sie einfach und unkompliziert umzusetzen ist. Diese Lösung weist jedoch auch zwei potenzielle Probleme auf. 🎜🎜🎜Das erste Problem besteht darin, dass bei Verwendung von RDB zum Beibehalten von Daten mit zunehmender Datenmenge auch der erforderliche Speicher zunimmt und der Hauptthread möglicherweise blockiert wird, wenn der untergeordnete Prozessfork wird. 🎜🎜Zweite Frage:Die vertikale Erweiterung wird durch Hardware und Kosten begrenzt. Das ist leicht zu verstehen. Schließlich ist es einfach, den Speicher von 32 GB auf 64 GB zu erweitern. Wenn Sie jedoch auf 1 TB erweitern möchten, stoßen Sie auf Einschränkungen bei der Hardwarekapazität und den Kosten. 🎜🎜🎜Im Vergleich zur „vertikalen Erweiterung“ ist die „horizontale Erweiterung“ eine bessere Skalierbarkeitslösung. Denn wenn Sie mehr Daten speichern möchten und diese Lösung übernehmen, müssen Sie nur die Anzahl der Redis-Instanzen erhöhen und müssen sich keine Gedanken über die Hardware- und Kostenbeschränkungen einer einzelnen Instanz machen. 🎜🎜Der Redis-Cluster basiert auf der „horizontalen Erweiterung“. Er bildet einen Cluster, indem er mehrere Redis-Instanzen startet, die empfangenen Daten dann nach bestimmten Regeln in mehrere Teile aufteilt und jeden Teil mit einer Instanz speichert. 🎜Redis Cluster
🎜Redis Cluster ist eine verteilte Datenbanklösung. Der Cluster durchläuftsharding (sharding, auch slicing genannt). ), um Daten auszutauschen und Replikations- und Failover-Funktionen bereitzustellen. 🎜🎜Zurück zu dem Szenario, das wir gerade hatten: Wenn die 25-GB-Daten gleichmäßig in 5 Teile aufgeteilt werden (natürlich müssen sie nicht gleichmäßig aufgeteilt werden) und 5 Instanzen zum Speichern verwendet werden, muss jede Instanz nur 5 GB speichern Daten. Wie im Bild unten gezeigt: 🎜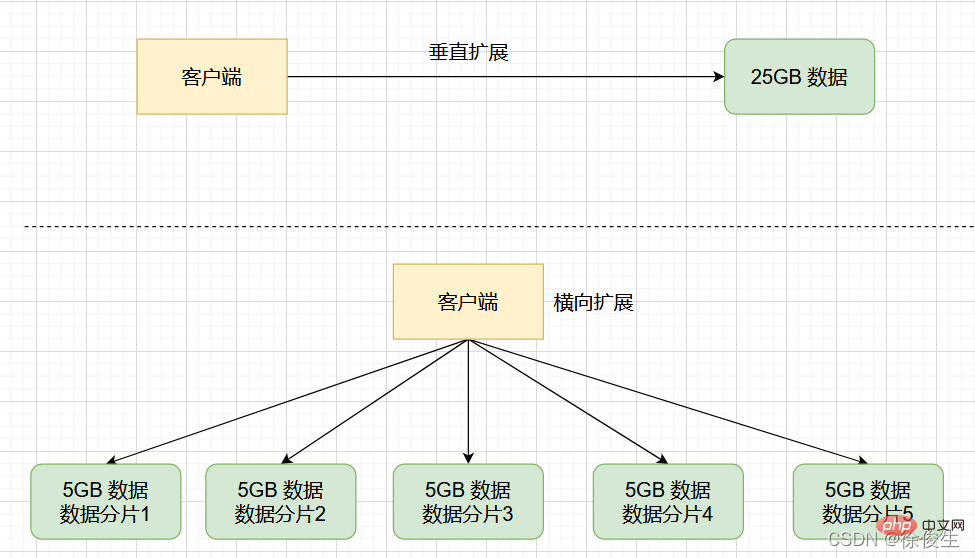
Wenn dann in einem Slicing-Cluster eine Instanz RDB für 5 GB Daten generiert, ist die Datenmenge viel kleiner und der untergeordnete fork-Prozess blockiert den Hauptthread im Allgemeinen nicht für lange Zeit . fork 子进程一般不会给主线程带来较长时间的阻塞。
采用多个实例保存数据切片后,我们既能保存 25GB 数据,又避免了 fork 子进程阻塞主线程而导致的响应突然变慢。
在实际应用 Redis 时,随着业务规模的扩展,保存大量数据的情况通常是无法避免的。而 Redis 集群,就是一个非常好的解决方案。
下面我们开始研究如何搭建一个 Redis 集群?
搭建 Redis 集群
一个 Redis 集群通常由多个节点组成,在刚开始的时候,每个节点都是相互独立地,节点之间没有任何关联。要组建一个可以工作的集群,我们必须将各个独立的节点连接起来,构成一个包含多节点的集群。
我们可以通过 CLUSTER MEET 命令,将各个节点连接起来:
CLUSTER MEET <ip> <port></port></ip>
- ip:待加入集群的节点 ip
- port:待加入集群的节点 port
命令说明:通过向一个节点 A 发送 CLUSTER MEET 命令,可以让接收命令的节点 A 将另一个节点 B 添加到节点 A 所在的集群中。
这么说有点抽象,下面看一个例子。
假设现在有三个独立的节点 127.0.0.1:7001、 127.0.0.1:7002、 127.0.0.1:7003。
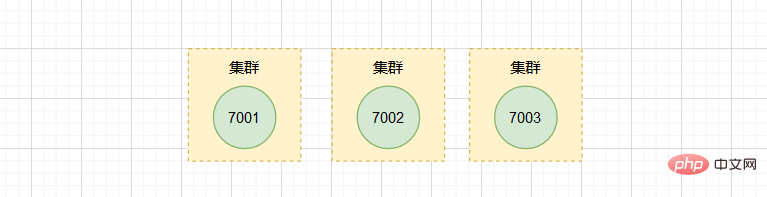
我们首先使用客户端连上节点 7001:
$ redis-cli -c -p 7001
然后向节点 7001 发送命令,将节点 7002 添加到 7001 所在的集群里:
127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7002
同样的,我们向 7003 发送命令,也添加到 7001 和 7002 所在的集群。
127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7003
通过
CLUSTER NODES命令可以查看集群中的节点信息。
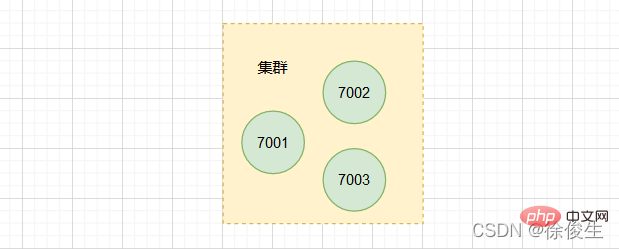
现在集群中已经包含 7001、 7002 和 7003 三个节点。不过,在使用单个实例的时候,数据存在哪儿,客户端访问哪儿,都是非常明确的。但是,切片集群不可避免地涉及到多个实例的分布式管理问题。
要想把切片集群用起来,我们就需要解决两大问题:
- 数据切片后,在多个实例之间如何分布?
- 客户端怎么确定想要访问的数据在哪个实例上?
接下来,我们就一个个地解决。
数据切片和实例的对应分布关系
在切片集群中,数据需要分布在不同实例上,那么,数据和实例之间如何对应呢?
这就和接下来要讲的 Redis Cluster 方案有关了。不过,我们要先弄明白切片集群和 Redis Cluster 的联系与区别。
在 Redis 3.0 之前,官方并没有针对切片集群提供具体的方案。从 3.0 开始,官方提供了一个名为
Redis Cluster的方案,用于实现切片集群。
实际上,切片集群是一种保存大量数据的通用机制,这个机制可以有不同的实现方案。 Redis Cluster 方案中就规定了数据和实例的对应规则。
具体来说, Redis Cluster 方案采用 哈希槽(Hash Slot),来处理数据和实例之间的映射关系。
哈希槽与 Redis 实例映射
在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽(2^14),这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。
在上面我们分析的,通过 CLUSTER MEET 命令将 7001、7002、7003 三个节点连接到同一个集群里面,但是这个集群目前是处于下线状态的,因为集群中的三个节点没有分配任何槽。
那么,这些哈希槽又是如何被映射到具体的 Redis 实例上的呢?
我们可以使用 CLUSTER MEET 命令手动建立实例间的连接,形成集群,再使用CLUSTER ADDSLOTS 命令,指定每个实例上的哈希槽个数。
CLUSTER ADDSLOTS <slot> [slot ...]</slot>
🎜Redis5.0 提供
Nachdem wir mehrere Instanzen zum Speichern von Datenabschnitten verwendet haben, können wir nicht nur 25 GB Daten speichern, sondern auch die plötzliche Verlangsamung der Reaktion vermeiden, die dadurch verursacht wird, dass der untergeordneteCLUSTER CREATEfork-Prozess den Hauptthread blockiert. 🎜🎜Bei der tatsächlichen Anwendung von Redis ist es mit zunehmender Geschäftsgröße normalerweise unvermeidlich, große Datenmengen zu speichern. Und der Redis-Cluster ist eine sehr gute Lösung. 🎜🎜Beginnen wir mit der Untersuchung, wie man einen Redis-Cluster aufbaut? 🎜Erstellen Sie einen Redis-Cluster
🎜Ein Redis-Cluster besteht normalerweise aus mehreren Knoten. Zu Beginn ist jeder Knoten unabhängig voneinander und es besteht keine Beziehung zwischen den Knoten. Um einen funktionierenden Cluster zu bilden, müssen wir unabhängige Knoten verbinden, um einen Cluster mit mehreren Knoten zu bilden. 🎜🎜Wir können jeden Knoten über den BefehlCLUSTER MEETverbinden: 🎜127.0.0.1:7001> CLUSTER ADDSLOTS 0 1 2 3 4 ... 5000Nach dem Login kopierenNach dem Login kopieren🎜Befehlsbeschreibung: Durch Senden des Befehls
- ip: die IP des Knotens, der dem Cluster hinzugefügt werden soll
- Port: zum Knotenport des Clusters hinzugefügt werden
CLUSTER MEETan einen Knoten A kann der Knoten A, der den Befehl empfängt, einen weiteren Knoten B hinzufügen zum Knoten A. im Cluster. 🎜🎜Das ist etwas abstrakt, schauen wir uns ein Beispiel an. 🎜🎜Angenommen, es gibt jetzt drei unabhängige Knoten127.0.0.1:7001,127.0.0.1:7002,127.0.0.1:7003. 🎜🎜🎜🎜Wir verwenden zuerst den Client Verbinden Sie das Terminal mit Knoten
7001: 🎜🎜 Senden Sie dann einen Befehl an Knoten127.0.0.1:7002> CLUSTER ADDSLOTS 5001 5002 5003 5004 ... 10000Nach dem Login kopierenNach dem Login kopieren7001, um Knoten7002zu7001hinzuzufügen > In dem Cluster, in dem es sich befindet: 🎜🎜Ähnlich senden wir den Befehl an127.0.0.1:7003> CLUSTER ADDSLOTS 10001 10002 10003 10004 ... 16383Nach dem Login kopierenNach dem Login kopieren7003und fügen ihn auch dem Cluster hinzu, wo7001und7002 Code> befinden. 🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">crc16(key,keylen) & 0x3FFF;</pre><div class="contentsignin">Nach dem Login kopieren</div></div><div class="contentsignin">Nach dem Login kopieren</div></div> <blockquote>🎜Sie können die Knoteninformationen im Cluster über den Befehl <code>CLUSTER NODESanzeigen. 🎜
🎜 Now The Der Cluster enthält bereits drei Knoten: 7001, 7002 und 7003. Bei Verwendung einer einzelnen Instanz ist jedoch sehr klar, wo die Daten vorhanden sind und wo der Client darauf zugreift. Das Slicing von Clustern bringt jedoch zwangsläufig das Problem der verteilten Verwaltung mehrerer Instanzen mit sich. 🎜🎜Um Slicing-Cluster zu verwenden, müssen wir zwei Hauptprobleme lösen: 🎜- Wie werden die Daten nach dem Slicing auf mehrere Instanzen verteilt?
- Wie bestimmt der Client, auf welcher Instanz sich die Daten befinden, auf die er zugreifen möchte?
Entsprechende Verteilungsbeziehung zwischen Daten-Slices und Instanzen
🎜In einem Slicing-Cluster müssen Daten auf verschiedene Instanzen verteilt werden. Wie ist also die Korrespondenz zwischen Daten und Instanzen? 🎜🎜Dies hängt mit derRedis Cluster-Lösung zusammen, über die ich als nächstes sprechen werde. Allerdings müssen wir zunächst den Zusammenhang und den Unterschied zwischen Slicing-Clustern und Redis Cluster verstehen. 🎜🎜Vor Redis 3.0 stellte der Beamte keine spezifischen Lösungen für das Slicing von Clustern bereit. Ab 3.0 wird die offizielle Lösung namens Redis Cluster zur Implementierung von Slicing-Clustern verwendet. 🎜🎜Tatsächlich ist das Slicing-Cluster ein allgemeiner Mechanismus zum Speichern großer Datenmengen. Für diesen Mechanismus gibt es unterschiedliche Implementierungslösungen. Das Schema Redis Cluster legt die entsprechenden Regeln für Daten und Instanzen fest. 🎜🎜Konkret verwendet die Redis Cluster-Lösung Hash Slot (Hash Slot), um die Zuordnungsbeziehung zwischen Daten und Instanzen zu verwalten. 🎜Hash-Slots und Redis-Instanzzuordnung
🎜In derRedis Cluster-Lösung verfügt ein Slice-Cluster über insgesamt 16384 Hash-Slots (2^14) Diese Hash-Slots ähneln Datenpartitionen. Jedes Schlüssel-Wert-Paar wird entsprechend seinem Schlüssel einem Hash-Slot zugeordnet. 🎜🎜In unserer obigen Analyse sind die drei Knoten 7001, 7002 und 7003 durch das CLUSTER MEET verbunden Befehl Wechseln Sie zum selben Cluster, aber dieser Cluster befindet sich derzeit im Offline-Status, da den drei Knoten im Cluster keine Slots zugewiesen sind. 🎜🎜Wie werden diese Hash-Slots bestimmten Redis-Instanzen zugeordnet? 🎜🎜Wir können den Befehl CLUSTER MEET verwenden, um manuell Verbindungen zwischen Instanzen herzustellen, um einen Cluster zu bilden, und dann den Befehl CLUSTER ADDSLOTS verwenden, um die Anzahl der Hash-Slots für jede Instanz anzugeben Beispiel. 🎜MOVED <slot> <ip>:<port></port></ip></slot>
🎜Redis5.0 bietet den Befehl CLUSTER CREATE zum Erstellen eines Clusters. Mit diesem Befehl verteilt Redis diese Slots automatisch gleichmäßig auf die Clusterinstanzen. 🎜
举个例子,我们通过以下命令,给 7001、7002、7003 三个节点分别指派槽。
将槽 0 ~ 槽5000 指派给 给 7001 :
127.0.0.1:7001> CLUSTER ADDSLOTS 0 1 2 3 4 ... 5000
将槽 5001 ~ 槽10000 指派给 给 7002 :
127.0.0.1:7002> CLUSTER ADDSLOTS 5001 5002 5003 5004 ... 10000
将槽 10001~ 槽 16383 指派给 给 7003 :
127.0.0.1:7003> CLUSTER ADDSLOTS 10001 10002 10003 10004 ... 16383
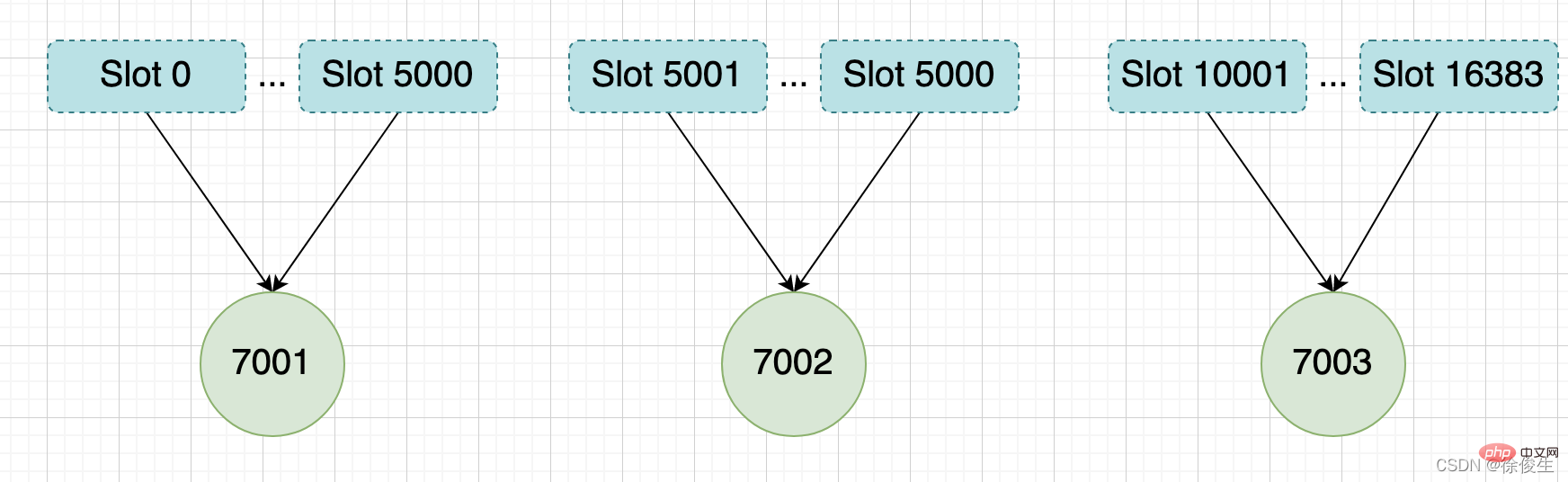
当三个 CLUSTER ADDSLOTS 命令都执行完毕之后,数据库中的 16384 个槽都已经被指派给了对应的节点,此时集群进入上线状态。
通过哈希槽,切片集群就实现了数据到哈希槽、哈希槽再到实例的分配。
但是,即使实例有了哈希槽的映射信息,客户端又是怎么知道要访问的数据在哪个实例上呢?
客户端如何定位数据?
一般来说,客户端和集群实例建立连接后,实例就会把哈希槽的分配信息发给客户端。但是,在集群刚刚创建的时候,每个实例只知道自己被分配了哪些哈希槽,是不知道其他实例拥有的哈希槽信息的。
那么,客户端是如何可以在访问任何一个实例时,就能获得所有的哈希槽信息呢?
Redis 实例会把自己的哈希槽信息发给和它相连接的其它实例,来完成哈希槽分配信息的扩散。当实例之间相互连接后,每个实例就有所有哈希槽的映射关系了。
客户端收到哈希槽信息后,会把哈希槽信息缓存在本地。当客户端请求键值对时,会先计算键所对应的哈希槽,然后就可以给相应的实例发送请求了。
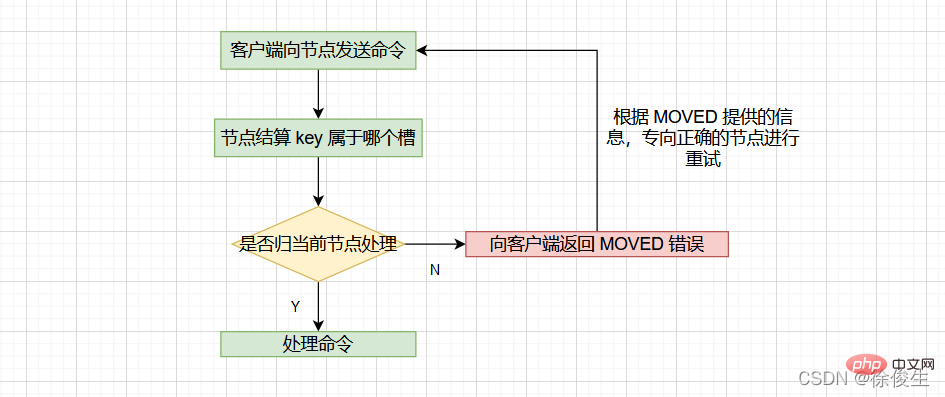
当客户端向节点请求键值对时,接收命令的节点会计算出命令要处理的数据库键属于哪个槽,并检查这个槽是否指派给了自己:
- 如果键所在的槽刚好指派给了当前节点,那么节点会直接执行这个命令;
- 如果没有指派给当前节点,那么节点会向客户端返回一个
MOVED错误,然后重定向(redirect)到正确的节点,并再次发送之前待执行的命令。
计算键属于哪个槽
节点通过以下算法来定义 key 属于哪个槽:
crc16(key,keylen) & 0x3FFF;
- crc16:用于计算 key 的 CRC-16 校验和
- 0x3FFF:换算成 10 进制是 16383
- & 0x3FFF:用于计算出一个介于 0~16383 之间的整数作为 key 的槽号。
通过
CLUSTER KEYSLOT <key></key>命令可以查看 key 属于哪个槽。
判断槽是否由当前节点负责处理
当节点计算出 key 所属的 槽 i 之后,节点会判断 槽 i 是否被指派了自己。那么如何判断呢?
每个节点会维护一个 「slots数组」,节点通过检查 slots[i] ,判断 槽 i 是否由自己负责:
- 如果说
slots[i]对应的节点是当前节点的话,那么说明槽 i由当前节点负责,节点可以执行客户端发送的命令; - 如果说
slots[i]对应的不是当前节点,节点会根据slots[i]所指向的节点向客户端返回MOVED错误,指引客户端转到正确的节点。
MOVED 错误
格式:
MOVED <slot> <ip>:<port></port></ip></slot>
- slot:键所在的槽
- ip:负责处理槽 slot 节点的 ip
- port:负责处理槽 slot 节点的 port
比如:MOVED 10086 127.0.0.1:7002,表示,客户端请求的键值对所在的哈希槽 10086,实际是在 127.0.0.1:7002 这个实例上。
通过返回的 MOVED 命令,就相当于把哈希槽所在的新实例的信息告诉给客户端了。
这样一来,客户端就可以直接和 7002 连接,并发送操作请求了。
同时,客户端还会更新本地缓存,将该槽与 Redis 实例对应关系更新正确。
集群模式的
redis-cli客户端在接收到MOVED错误时,并不会打印出MOVED错误,而是根据MOVED错误自动进行节点转向,并打印出转向信息,所以我们是看不见节点返回的MOVED错误的。而使用单机模式的redis-cli客户端可以打印MOVED错误。
其实,Redis 告知客户端重定向访问新实例分两种情况:MOVED 和 ASK 。下面我们分析下 ASK 重定向命令的使用方法。
重新分片
在集群中,实例和哈希槽的对应关系并不是一成不变的,最常见的变化有两个:
- 在集群中,实例有新增或删除,Redis 需要重新分配哈希槽;
- 为了负载均衡,Redis 需要把哈希槽在所有实例上重新分布一遍。
重新分片可以在线进行,也就是说,重新分片的过程中,集群不需要下线。
举个例子,上面提到,我们组成了 7001、7002、7003 三个节点的集群,我们可以向这个集群添加一个新节点127.0.0.1:7004。
$ redis-cli -c -p 7001 127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7004 OK
然后通过重新分片,将原本指派给节点 7003 的槽 15001 ~ 槽 16383 改为指派给 7004。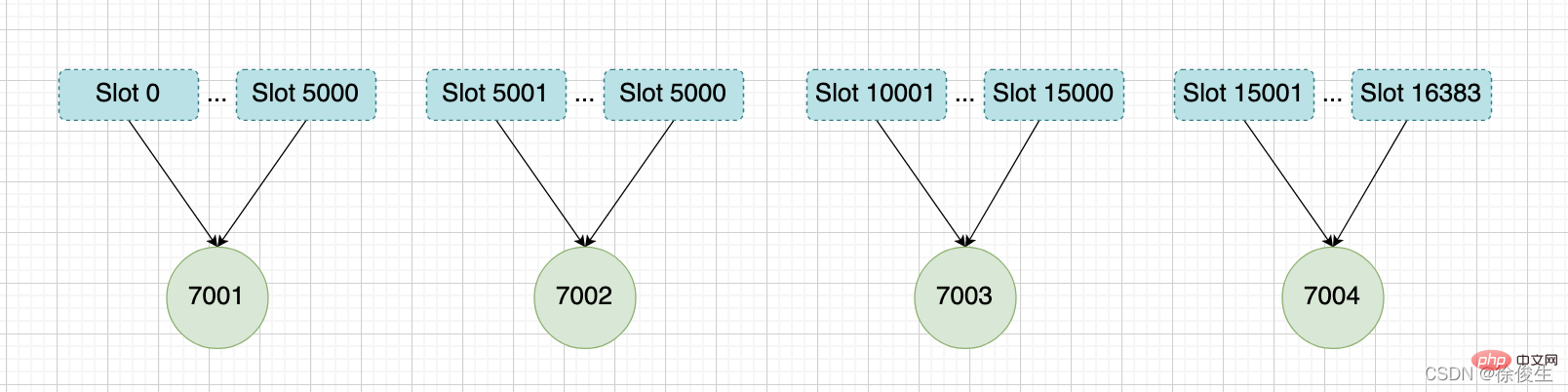
在重新分片的期间,源节点向目标节点迁移槽的过程中,可能会出现这样一种情况:如果某个槽的数据比较多,部分迁移到新实例,还有一部分没有迁移咋办?
在这种迁移部分完成的情况下,客户端就会收到一条 ASK 报错信息。
ASK 错误
如果客户端向目标节点发送一个与数据库键有关的命令,并且这个命令要处理的键正好属于被迁移的槽时:
- 源节点会先在自己的数据库里查找指定的键,如果找到的话,直接执行命令;
- 相反,如果源节点没有找到,那么这个键就有可能已经迁移到了目标节点,源节点就会向客户端发送一个
ASK错误,指引客户端转向目标节点,并再次发送之前要执行的命令。
看起来好像有点复杂,我们举个例子来解释一下。
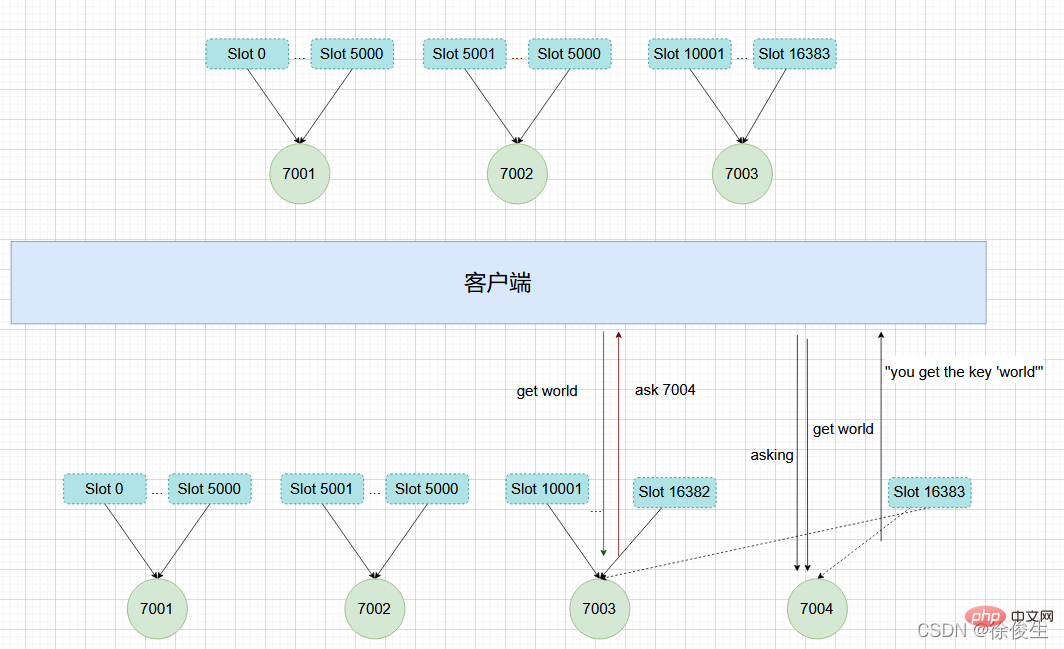
如上图所示,节点 7003 正在向 7004 迁移 槽 16383,这个槽包含 hello 和 world,其中键 hello 还留在节点 7003,而 world 已经迁移到 7004。
我们向节点 7003 发送关于 hello 的命令 这个命令会直接执行:
127.0.0.1:7003> GET "hello" "you get the key 'hello'"
如果我们向节点 7003 发送 world 那么客户端就会被重定向到 7004:
127.0.0.1:7003> GET "world" -> (error) ASK 16383 127.0.0.1:7004
客户端在接收到 ASK 错误之后,先发送一个 ASKING 命令,然后在发送 GET "world" 命令。
ASKING命令用于打开节点的ASKING标识,打开之后才可以执行命令。
ASK 和 MOVED 的区别
ASK 错误和 MOVED 错误都会导致客户端重定向,它们的区别在于:
- MOVED 错误代表槽的负责权已经从一个节点转移到了另一个节点:在客户端收到关于
槽 i的MOVED错误之后,客户端每次遇到关于槽 i的命令请求时,都可以直接将命令请求发送至MOVED错误指向的节点,因为该节点就是目前负责槽 i的节点。 - 而 ASK 只是两个节点迁移槽的过程中的一种临时措施:在客户端收到关于
槽 i的ASK错误之后,客户端只会在接下来的一次命令请求中将关于槽 i的命令请求发送到ASK错误指向的节点,但是 ,如果客户端再次请求槽 i中的数据,它还是会给原来负责槽 i的节点发送请求。
这也就是说,ASK 命令的作用只是让客户端能给新实例发送一次请求,而且也不会更新客户端缓存的哈希槽分配信息。而不像 MOVED 命令那样,会更改本地缓存,让后续所有命令都发往新实例。
我们现在知道了 Redis 集群的实现原理。下面我们再来分析下,Redis 集群如何实现高可用的呢?
复制与故障转移
Redis 集群中的节点也是分为主节点和从节点。
- 主节点用于处理槽
- 从节点用于复制主节点,如果被复制的主节点下线,可以代替主节点继续提供服务。
举个例子,对于包含 7001 ~ 7004 的四个主节点的集群,可以添加两个节点:7005、7006。并将这两个节点设置为 7001 的从节点。
设置从节点命令:
CLUSTER REPLICATE <node_id></node_id>
如图:
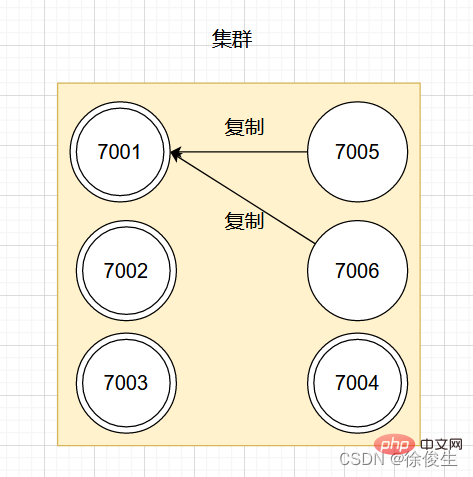
如果此时,主节点 7001 下线,那么集群中剩余正常工作的主节点将在 7001 的两个从节点中选出一个作为新的主节点。
例如,节点 7005 被选中,那么原来由节点 7001 负责处理的槽会交给节点 7005 处理。而节点 7006 会改为复制新主节点 7005。如果后续 7001 重新上线,那么它将成为 7005 的从节点。如下图所示:
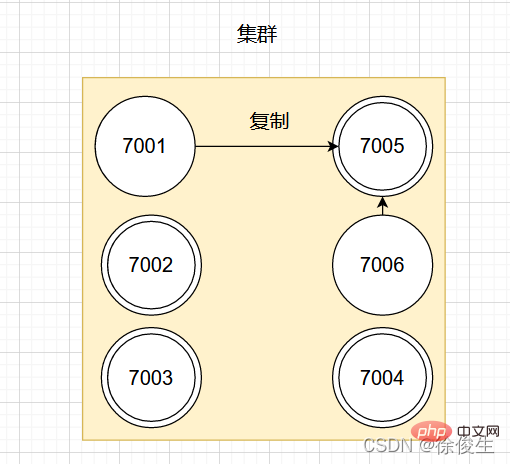
故障检测
集群中每个节点会定期向其他节点发送 PING 消息,来检测对方是否在线。如果接收消息的一方没有在规定时间内返回 PONG 消息,那么接收消息的一方就会被发送方标记为「疑似下线」。
集群中的各个节点会通过互相发消息的方式来交换各节点的状态信息。
节点的三种状态:
- 在线状态
- 疑似下线状态 PFAIL
- 已下线状态 FAIL
一个节点认为某个节点失联了并不代表所有的节点都认为它失联了。在一个集群中,半数以上负责处理槽的主节点都认定了某个主节点下线了,集群才认为该节点需要进行主从切换。
Redis 集群节点采用 Gossip 协议来广播自己的状态以及自己对整个集群认知的改变。比如一个节点发现某个节点失联了 (PFail),它会将这条信息向整个集群广播,其它节点也就可以收到这点失联信息。
我们都知道,哨兵机制可以通过监控、自动切换主库、通知客户端实现故障自动切换。那么 Redis Cluster 又是如何实现故障自动转移呢?
故障转移
当一个从节点发现自己正在复制的主节点进入了「已下线」状态时,从节点将开始对下线主节点进行故障切换。
故障转移的执行步骤:
- 在复制下线主节点的所有从节点里,选中一个从节点
- 被选中的从节点执行
SLAVEOF no one命令,成为主节点 - 新的主节点会撤销所有对已下线主节点的槽指派,将这些槽全部指派给自己
- 新的主节点向集群广播一条
PONG消息,让集群中其他节点知道,该节点已经由从节点变为主节点,且已经接管了原主节点负责的槽 - 新的主节点开始接收自己负责处理槽有关的命令请求,故障转移完成。
选主
这个选主方法和哨兵的很相似,两者都是基于 Raft算法 的领头算法实现的。流程如下:
- 集群的配置纪元是一个自增计数器,初始值为0;
- 当集群里的某个节点开始一次故障转移操作时,集群配置纪元加 1;
- 对于每个配置纪元,集群里每个负责处理槽的主节点都有一次投票的机会,第一个向主节点要求投票的从节点将获得主节点的投票;
- 当从节点发现自己复制的主节点进入「已下线」状态时,会向集群广播一条消息,要求收到这条消息,并且具有投票权的主节点为自己投票;
- 如果一个主节点具有投票权,且尚未投票给其他从节点,那么该主节点会返回一条消息给要求投票的从节点,表示支持从节点成为新的主节点;
- 每个参与选举的从节点会计算获得了多少主节点的支持;
- 如果集群中有 N 个具有投票权的主节点,当一个从节点收到的支持票
大于等于 N/2 + 1时,该从节点就会当选为新的主节点; - 如果在一个配置纪元里没有从节点收集到足够多的票数,那么集群会进入一个新的配置纪元,并再次进行选主。
消息
集群中的各个节点通过发送和接收消息来进行通信,我们把发送消息的节点称为发送者,接收消息的称为接收者。
节点发送的消息主要有五种:
- MEET-Nachricht
- PING-Nachricht
- PONG-Nachricht
- FAIL-Nachricht
- PUBLISH-Nachricht
Jeder Knoten im Cluster tauscht Statusinformationen verschiedener Knoten über das Gossip-Protokoll, Gossip, aus besteht aus drei Nachrichten: MEET, PING und PONG. Gossip 协议交换不同节点的状态信息, Gossip 是由 MEET、PING、PONG 三种消息组成。
发送者每次发送 MEET、PING、PONG 消息时,都会从自己已知的节点列表中随机选出两个节点(可以是主节点或者从节点)一并发送给接收者。
接收者收到 MEET、PING、PONG
MEET-, PING-, PONG-Nachricht sendet, wählt er zufällig zwei aus der Liste der bekannten Knoten aus (der ein Master-Knoten oder ein Slave-Knoten sein kann) werden zusammen an den Empfänger gesendet. - Wenn der Empfänger die Nachrichten
MEET,PINGundPONGempfängt, führt er eine unterschiedliche Verarbeitung durch, je nachdem, ob er diese beiden Knoten kennt: - Wenn der ausgewählte Knoten nicht existiert und die Liste bekannter Knoten empfängt, bedeutet dies, dass es sich um den ersten Kontakt handelt, und der Empfänger kommuniziert basierend auf der IP- und Portnummer des ausgewählten Knotens
Wenn er bereits existiert Dies bedeutet, dass die Kommunikation bereits abgeschlossen wurde. Anschließend werden die Informationen des ursprünglich ausgewählten Knotens aktualisiert.
Empfohlenes Lernen: 🎜Redis-Tutorial🎜🎜Das obige ist der detaillierte Inhalt vonFühren Sie Sie Schritt für Schritt durch, um den Hochverfügbarkeitscluster von Redis zu verstehen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
