

Fassen Sie 10 Tipps zur Verbesserung der Redis-Leistung zusammen

Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis. Er stellt hauptsächlich einige Tipps zur Verbesserung der Redis-Leistung vor, einschließlich der Pipeline, der Aktivierung von IO-Multithreading, der Vermeidung großer Schlüssel usw. Ich hoffe, dass er für alle hilfreich ist.

Empfohlenes Lernen: Redis-Tutorial
01 Pipeline verwenden
Redis ist ein TCP-Server, der auf dem Request-Response-Modell basiert. Bedeutet Single Request RTT (Round Trip Time), abhängig von den aktuellen Netzwerkbedingungen . Dies führt dazu, dass eine einzelne Redis-Anfrage möglicherweise sehr schnell ist, z. B. über eine lokale Netzwerkkarte. Kann sehr langsam sein, beispielsweise in einer schlechten Netzwerkumgebung.
Andererseits beinhaltet jede Redis-Anfrage-Antwort Lese- und Schreibsystemaufrufe. Es kann sogar mehrere epoll_wait-Systemaufrufe auslösen (Linux-Plattform). Dies führt dazu, dass Redis ständig zwischen Benutzermodus und Kernelmodus wechselt.
static int connSocketRead(connection *conn, void *buf, size_t buf_len) {
// read 系统调用
int ret = read(conn->fd, buf, buf_len);}static int connSocketWrite(connection *conn, const void *data, size_t data_len) {
// write 系统调用
int ret = write(conn->fd, data, data_len);}int aeProcessEvents(aeEventLoop *eventLoop, int flags) {
// 事件触发,Linux 下为 epoll_wait 系统调用
numevents = aeApiPoll(eventLoop, tvp);}Also, wie kann man Roundtrip-Zeit und Systemaufrufe sparen? Eine Stapelverarbeitung ist eine gute Idee.
Zu diesem Zweck stellt Redis eine „Pipeline“ bereit. Das Prinzip der Pipeline ist sehr einfach. Mehrere Befehle werden in „einen Befehl“ gepackt und gesendet. Nachdem Redis es empfangen hat, analysiert es es zur Ausführung in mehrere Befehle. Schließlich werden mehrere Ergebnisse verpackt und zurückgegeben.
「Pipeline kann die Redis-Leistung effektiv verbessern」.
Bei der Verwendung von Pipelines müssen Sie jedoch einige Dinge beachten
„Pipeline kann keine Atomizität garantieren“. Während der Ausführung eines Pipeline-Befehls können von anderen Clients initiierte Befehle ausgeführt werden. Denken Sie daran, dass eine Pipeline nur Befehle stapelt. Um die Atomizität sicherzustellen, verwenden Sie MULTI- oder Lua-Skripte.
「Verfügen Sie nicht zu viele Pipeline-Befehle gleichzeitig」. Bei Verwendung einer Pipeline speichert Redis vorübergehend die Antwortergebnisse von Pipeline-Befehlen im Antwortpuffer des Speichers und wartet, bis alle Befehle ausgeführt wurden, bevor es zurückkehrt. Wenn zu viele Pipeline-Befehle vorhanden sind, belegt dies möglicherweise mehr Speicher. Eine einzelne Pipeline kann in mehrere Pipelines aufgeteilt werden.
02 E/A-Multithreading aktivieren
Vor der „Redis 6“-Version war Redis „Single-Threaded“ zum Lesen, Parsen und Ausführen von Befehlen. Ab Redis 6 wurde IO-Multithreading eingeführt.
Der E/A-Thread ist für das Lesen von Befehlen, das Parsen von Befehlen und die Rückgabe von Ergebnissen verantwortlich. Wenn es aktiviert ist, kann es die E/A-Leistung effektiv verbessern. Ich habe ein schematisches Diagramm als Referenz gezeichnet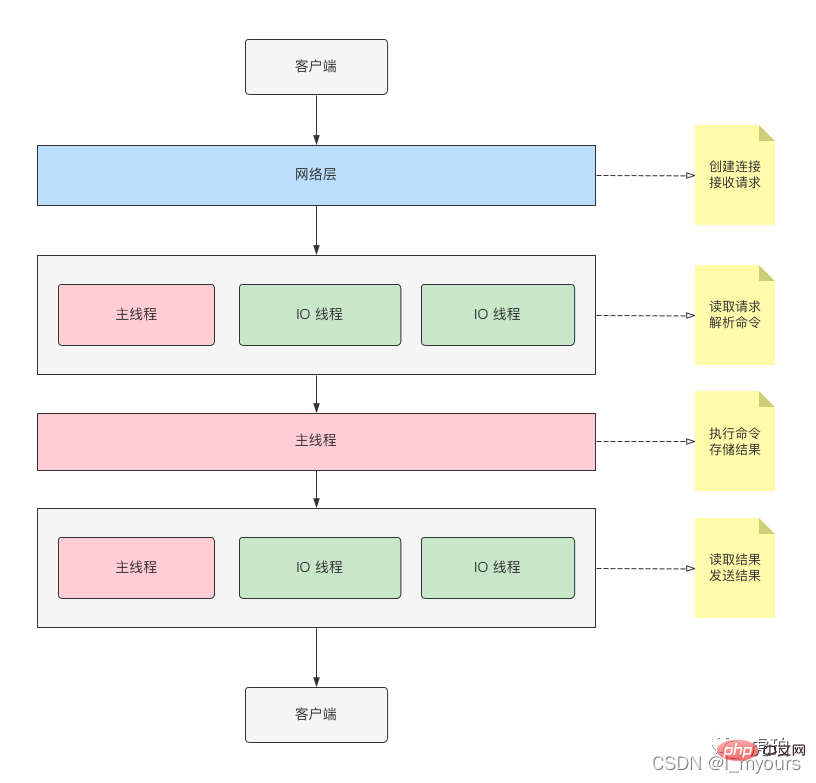 Wie im Bild oben gezeigt, sind der Hauptthread und der E/A-Thread gemeinsam am Lesen, Analysieren und Ergebnisantworten von Befehlen beteiligt.
Wie im Bild oben gezeigt, sind der Hauptthread und der E/A-Thread gemeinsam am Lesen, Analysieren und Ergebnisantworten von Befehlen beteiligt.
„Hauptthread“.
Der IO-Thread ist standardmäßig geschlossen. Sie können die folgende Konfiguration in redis.conf ändern, um ihn zu aktivieren.io-threads 4 io-threads-do-reads yes
03 Big Key vermeidenDer Redis-Ausführungsbefehl ist Single-Threaded, was bedeutet, dass die Gefahr einer Blockierung besteht, wenn Redis den „Big Key“ ausführt. Großer Schlüssel bezieht sich normalerweise darauf, dass der in Redis gespeicherte Wert zu groß ist. Einschließlich:
- Ein einzelner Wert ist zu groß. Zum Beispiel eine 200-M-String-Größe.
- Zu viele Sammlungselemente. Beispielsweise gibt es Hunderte oder Dutzende Millionen Daten in List, Hash, Set und ZSet.
127.0.0.1:6379> GET foo
void _addReplyProtoToList(client *c, const char *s, size_t len) {
...
if (len) {
/* Create a new node, make sure it is allocated to at
* least PROTO_REPLY_CHUNK_BYTES */
size_t size = len size = zmalloc_usable_size(tail) - sizeof(clientReplyBlock);
tail->used = len;
// 内存拷贝
memcpy(tail->buf, s, len);
listAddNodeTail(c->reply, tail);
c->reply_bytes += tail->size;
closeClientOnOutputBufferLimitReached(c, 1);
}}// server.h#define PROTO_REPLY_CHUNK_BYTES (16*1024) /* 16k output buffer */typedef struct client {
...
char buf[PROTO_REPLY_CHUNK_BYTES];} client;- Großen Speicher zuweisen (kann auch Speicher freigeben, z. B. DEL-Befehl)
- Mehrere beschreibbare Ereignisse auslösen (häufig Systemaufrufe ausführen, z. B. write, epoll_wait)
127.0.0.1:6379> SLOWLOG GET 3) (integer) 201323 // 单位微妙 4) 1) "GET" 2) "foo"
$ redis-cli --bigkeys -i 0.1 ... [00.00%] Biggest string found so far '"foo"' with 209715200 bytes -------- summary ------- Sampled 1 keys in the keyspace! Total key length in bytes is 3 (avg len 3.00) Biggest string found '"foo"' has 209715200 bytes 1 strings with 209715200 bytes (100.00% of keys, avg size 209715200.00) 0 lists with 0 items (00.00% of keys, avg size 0.00) 0 hashs with 0 fields (00.00% of keys, avg size 0.00) 0 streams with 0 entries (00.00% of keys, avg size 0.00) 0 sets with 0 members (00.00% of keys, avg size 0.00) 0 zsets with 0 members (00.00% of keys, avg size 0.00)
- Wenn die Redis-Version größer als 4.0 ist, können Sie den UNLINK-Befehl anstelle von DEL verwenden. Wenn die Redis-Version größer als 6.0 ist, kann der Lazy-Free-Mechanismus aktiviert werden. Der Speicherfreigabevorgang wird im Hintergrundthread ausgeführt.
- LRANGE, HGETALL usw. werden durch LSCAN, HSCAN ersetzt, um sie stapelweise abzurufen.
Aber ich empfehle trotzdem, im Geschäftsleben auf große Schlüssel zu verzichten.
04 Vermeiden Sie die Ausführung von Befehlen mit hoher zeitlicher Komplexität. Wir wissen, dass Redis Befehle in einem „einzelnen Thread“ ausführt. Das Ausführen von Befehlen mit hoher zeitlicher Komplexität blockiert wahrscheinlich andere Anfragen.
复杂度高的命令和元素数量有关。通常有以下两种场景。
元素太多,消耗 IO 资源。如 HGETALL、LRANGE,时间复杂度为 O(N)。
计算过于复杂,消费 CPU 资源。如 ZUNIONSTORE,时间复杂度为 O(N)+O(M log(M))
Redis 官方手册,标记了命令执行的时间复杂度。建议你在使用不熟悉的命令前,先查看手册,留意时间复杂度。
实际业务中,你应该尽量避免时间复杂度高的命令。如果必须要用,有两点建议
保证操作的元素数量,尽可能少。
读写分离。复杂命令通常是读请求,可以放到「slave」结点执行。
05 使用惰性删除 Lazy free
key 过期或是使用 DEL 删除命令时,Redis 除了从全局 hash 表移除对象外,还会将对象分配的内存释放。当遇到 big key 时,释放内存会造成主线程阻塞。
为此,Redis 4.0 引入了 UNLINK 命令,将释放对象内存操作放入 bio 后台线程执行。从而有效减少主线程阻塞。
Redis 6.0 更进一步,引入了 Lazy-free 相关配置。当开启配置后,key 过期和 DEL 命令内部,会将「释放对象」操作「异步执行」。
void delCommand(client *c) {
delGenericCommand(c,server.lazyfree_lazy_user_del);}void delGenericCommand(client *c, int lazy) {
int numdel = 0, j;
for (j = 1; j argc; j++) {
expireIfNeeded(c->db,c->argv[j]);
// 开启 lazy free 则使用异步删除
int deleted = lazy ? dbAsyncDelete(c->db,c->argv[j]) :
dbSyncDelete(c->db,c->argv[j]);
...
}}建议至少升级到 Redis 6,并开启 Lazy-free。
06 读写分离
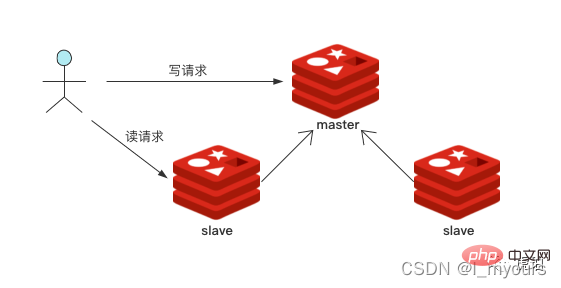
Redis 通过副本,实现「主-从」运行模式,是故障切换的基石,用来提高系统运行可靠性。也支持读写分离,提高读性能。
你可以部署一个主结点,多个从结点。将读命令分散到从结点中,从而减轻主结点压力,提升性能。
07 绑定 CPU
Redis 6.0 开始支持绑定 CPU,可以有效减少线程上下文切换。
CPU 亲和性(CPU Affinity)是一种调度属性,它将一个进程或线程,「绑定」到一个或一组 CPU 上。也称为 CPU 绑定。
设置 CPU 亲和性可以一定程度避免 CPU 上下文切换,提高 CPU L1、L2 Cache 命中率。
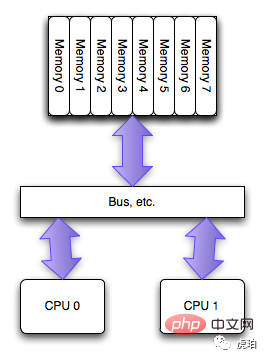
早期「SMP」架构下,每个 CPU 通过 BUS 总线共享资源。CPU 绑定意义不大。
而在当前主流的「NUMA」架构下,每个 CPU 有自己的本地内存。访问本地内存有更快的速度。而访问其他 CPU 内存会导致较大的延迟。这时,CPU 绑定对系统运行速度的提升有较大的意义。
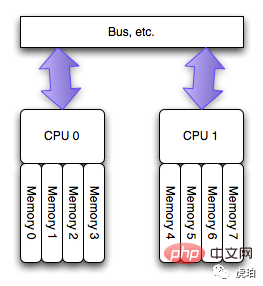
现实中的 NUMA 架构比上图更复杂,通常会将 CPU 分组,若干个 CPU 分配一组内存,称为 「node」。
你可以通过 「numactl -H 」 命令来查看 NUMA 硬件信息。
$ numactl -H available: 2 nodes (0-1)node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 node 0 size: 32143 MB node 0 free: 26681 MB node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 node 1 size: 32309 MB node 1 free: 24958 MB node distances: node 0 1 0: 10 21 1: 21 10
上图中可以得知该机器有 40 个 CPU,分组为 2 个 node。
node distances 是一个二维矩阵,表示 node 之间 「访问距离」,10 为基准值。上述命令中可以得知,node 自身访问,距离是 10。跨 node 访问,如 node 0 访问 node 1 距离为 21。说明该机器「跨 node 访问速度」比「node 自身访问速度」慢 2.1 倍。
其实,早在 2015 年,有人提出 Redis 需要支持设置 CPU 亲和性,而当时的 Redis 还没有支持 IO 多线程,该提议搁置。
而 Redis 6.0 引入 IO 多线程。同时,也支持了设置 CPU 亲和性。
我画了一张 Redis 6.0 线程家族供你参考。

上图可分为 3 个模块
- 主线程和 IO 线程:负责命令读取、解析、结果返回。命令执行由主线程完成。
- bio 线程:负责执行耗时的异步任务,如 close fd。
- 后台进程:fork 子进程来执行耗时的命令。
Redis 支持分别配置上述模块的 CPU 亲和度。你可以在 redis.conf 找到以下配置(该配置需手动开启)。
# IO 线程(包含主线程)绑定到 CPU 0、2、4、6 server_cpulist 0-7:2 # bio 线程绑定到 CPU 1、3 bio_cpulist 1,3 # aof rewrite 后台进程绑定到 CPU 8、9、10、11 aof_rewrite_cpulist 8-11 # bgsave 后台进程绑定到 CPU 1、10、11 bgsave_cpulist 1,10-11
我在上述机器,针对 IO 线程和主线程,进行如下测试:
首先,开启 IO 线程配置。
io-threads 4 # 主线程 + 3 个 IO 线程io-threads-do-reads yes # IO 线程开启读和解析命令功能
测试如下三种场景:
不开启 CPU 绑定配置。
绑定到不同 node。
「server_cpulist 0,1,2,3」绑定到相同 node。
「server_cpulist 0,2,4,6」
通过 redis-benchmark 对 get 命令进行基准测试,每种场景执行 3 次。
$ redis-benchmark -n 5000000 -c 50 -t get --threads 4
结果如下:
1.不开启 CPU 绑定配置
throughput summary: 248818.11 requests per second throughput summary: 248694.36 requests per second throughput summary: 249004.00 requests per second
2.绑定不同 node
throughput summary: 248880.03 requests per second throughput summary: 248447.20 requests per second throughput summary: 248818.11 requests per second
3.绑定相同 node
throughput summary: 284414.09 requests per second throughput summary: 284333.25 requests per second throughput summary: 265252.00 requests per second
根据测试结果,绑定到同一个 node,qps 大约提升 15%
使用绑定 CPU,你需要注意以下几点:
Linux 下,你可以使用 「numactl --hardware」 查看硬件布局,确保支持并开启 NUMA。
线程要尽可能分布在 「不同的 CPU,相同的 node」,设置 CPU 亲和度才有效。否则会造成频繁上下文切换和远距离内存访问。
你要熟悉 CPU 架构,做好充分的测试。否则可能适得其反,导致 Redis 性能下降。
08 合理配置持久化策略
Redis 支持两种持久化策略,RDB 和 AOF。
RDB 通过 fork 子进程,生成数据快照,二进制格式。
AOF 是增量日志,文本格式,通常较大。会通过 AOF rewrite 重写日志,节省空间。
除了手动执行「BGREWRITEAOF」命令外,以下 4 点也会触发 AOF 重写
执行「config set appendonly yes」命令
AOF 文件大小比例超出阈值,「auto-aof-rewrite-percentage」
AOF 文件大小绝对值超出阈值,「auto-aof-rewrite-min-size」
主从复制完成 RDB 加载
RDB 和 AOF,都是在主线程中触发执行。虽然具体执行,会通过 fork 交给后台子进程。但 fork 操作,会拷贝进程数据结构、页表等,当实例内存较大时,会影响性能。
AOF 支持以下三种策略。
appendfsync no:由操作系统决定执行 fsync 时机。 对 Linux 来说,通常每 30 秒执行一次 fsync,将缓冲区中的数据刷到磁盘上。如果 Redis qps 过高或写 big key,可能导致 buffer 写满,从而频繁触发 fsync。
appendfsync everysec: 每秒执行一次 fsync。
appendfsync always: 每次「写」会调用一次 fsync,性能影响较大。
AOF 和 RDB 都会对磁盘 IO 造成较高的压力。其中,AOF rewrite 会将 Redis hash 表所有数据进行遍历并写磁盘。对性能会产生一定的影响。
线上业务 Redis 通常是高可用的。如果对缓存数据丢失不敏感。考虑关闭 RDB 和 AOF 以提升性能。
如果无法关闭,有以下几点建议:
RDB 选择业务低峰期做,通常为凌晨。保持单个实例内存不超过 32 G。太大的内存会导致 fork 耗时增加。
AOF 选择 appendfsync no 或者 appendfsync everysec。
AOF auto-aof-rewrite-min-size 配置大一些,如 2G。避免频繁触发 rewrite。
AOF 可以仅在从节点开启,减轻主节点压力。
根据本地测试,不开启 AOF,写性能大约能提升 20% 左右。
09 使用长连接
Redis 是基于 TCP 协议,请求-响应式服务器。使用短连接会导致频繁的创建连接。
短连接有以下几个慢速操作:
创建连接时,TCP 会执行三次握手、慢启动等策略。
Redis 会触发新建/断开连接事件,执行分配/销毁客户端等耗时操作。
如果你使用的是 Redis Cluster,新建连接时,客户端会拉取 slots 信息初始化。建立连接速度更慢。
所以,相对于性能快速的 Redis,创建连接是十分慢速的操作。
「建议使用连接池,并合理设置连接池大小」。
但使用长连接时,需要留意一点,要有「自动重连」策略。避免因网络异常,导致连接失效,影响正常业务。
10 关闭 SWAP
SWAP 是内存交换技术。将内存按页,复制到预先设定的磁盘空间上。
内存是快速的,昂贵的。而磁盘是低速的,廉价的。
通常使用 SWAP 越多,系统性能越低。
Redis 是内存数据库,使用 SWAP 会导致性能快速下降。
建议留有足够内存,并关闭 SWAP。
总结
以上就是今天为大家分享的 「提升 Redis 性能的 10 个手段」。
我绘制了思维导图,方便大家记忆。
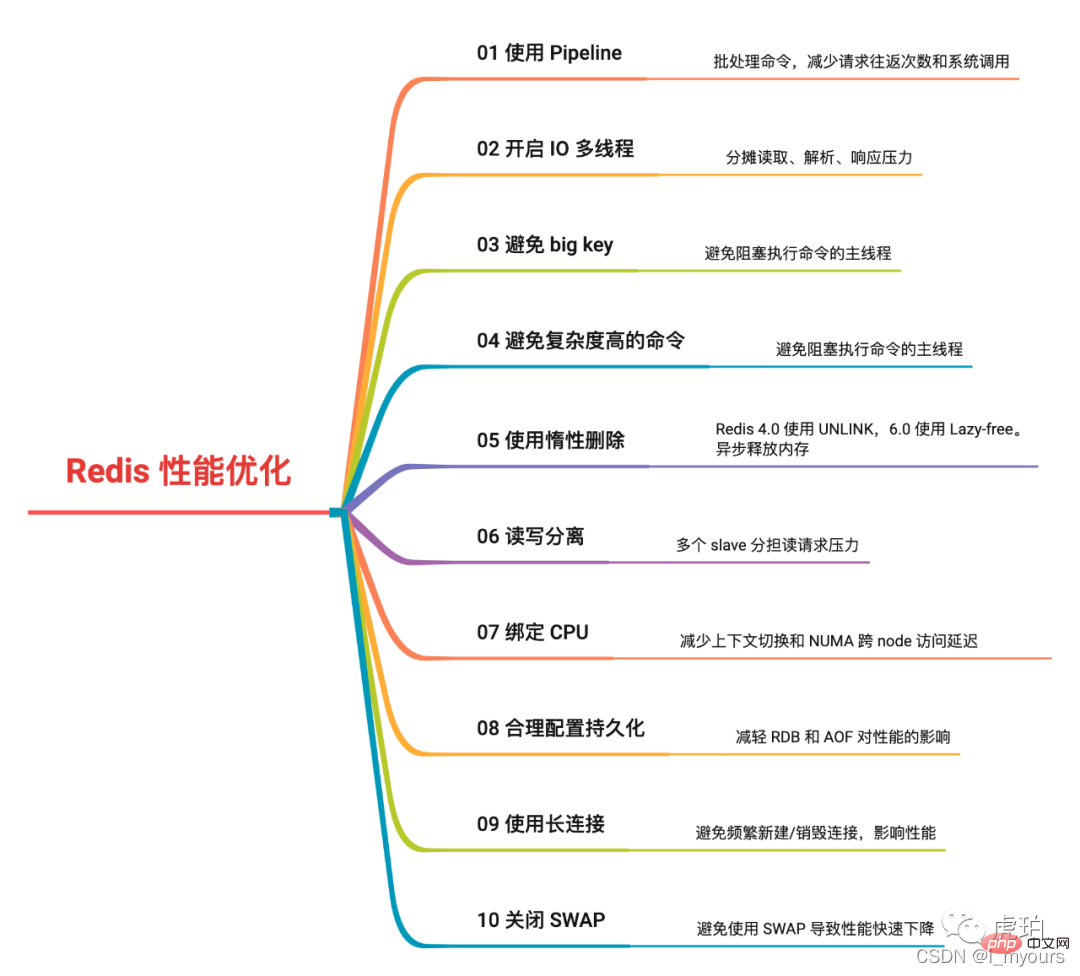
可以看到,性能优化并不容易,需要我们了解很多底层知识,并做出充分测试。在不同机器、不同系统、不同配置下,Redis 都会有不同的性能表现。
推荐学习:Redis学习教程
Das obige ist der detaillierte Inhalt vonFassen Sie 10 Tipps zur Verbesserung der Redis-Leistung zusammen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
