

Vermitteln Sie ein umfassendes Verständnis der verteilten Sperren in Redis

Verstehen Sie die verteilten Redis-Sperren wirklich? Der folgende Artikel gibt Ihnen eine ausführliche Einführung in verteilte Sperren in Redis und spricht über die Implementierung von Sperren, das Freigeben von Sperren, Fehler verteilter Sperren usw. Ich hoffe, er wird Ihnen hilfreich sein!

Was ist eine verteilte Sperre? Apropos Redis: Die erste Funktion, an die wir denken, ist die Fähigkeit, Daten zwischenzuspeichern, da Redis aufgrund seines Einzelprozess- und Hochleistungsstils häufig verwendet wird sperren. [Verwandte Empfehlungen:
Redis-Video-Tutorial]Wir alle wissen, dass Sperren in Programmen als Synchronisierungstool fungieren, um sicherzustellen, dass nur ein Thread gleichzeitig auf freigegebene Ressourcen zugreifen kann. Wir alle sind mit Sperren in Java vertraut. Wir verwenden beide häufig Synchronized und Lock, aber die Wirksamkeit der Java-Sperren kann nur auf einer einzelnen Maschine garantiert werden und ist in einer verteilten Clusterumgebung machtlos. Zu diesem Zeitpunkt müssen wir verteilte Sperren verwenden.
Verteilte Sperren sind, wie der Name schon sagt, Sperren, die in der verteilten Projektentwicklung verwendet werden. Sie können verwendet werden, um den synchronen Zugriff auf gemeinsam genutzte Ressourcen zwischen verteilten Systemen zu steuern:
1 Exklusivität: Zu jedem Zeitpunkt kann nur eine Anwendung die verteilte Sperre erhalten.
2: In einem verteilten Szenario hat die Ausfallzeit einer kleinen Anzahl von Servern keinen Einfluss auf die normale Nutzung In diesem Fall muss der Dienst, der verteilte Sperren bereitstellt, in einem Cluster bereitgestellt werden Der Client kann nicht ausfallen. Oder es kommt zu einem Deadlock, wenn das Netzwerk nicht erreichbar ist.
4. Exklusivität: Das Sperren und Entsperren muss vom selben Server erfolgen, d sperren und jemand anderes entsperrt es für Sie ;
Es gibt viele Tools in der Branche, die verteilte Sperreffekte erzielen können, aber die Vorgänge sind nur die folgenden: Sperren, Entsperren und Verhindern von Sperrzeitüberschreitungen.
Da es in diesem Artikel um die verteilte Redis-Sperre geht, ist es für uns selbstverständlich, sie mit den Wissenspunkten von Redis zu erweitern.
Befehle zum Implementieren von Sperren
Führen Sie zunächst einige Befehle von Redis ein:
1 existieren, die Abkürzung für SET) gibt 1 zurück, wenn die Einstellung erfolgreich ist, andernfalls wird 0 zurückgegeben.

setnx-VerwendungSETNX key value
SETNX是『 SET if Not eXists』(如果不存在,则 SET)的简写,设置成功就返回1,否则返回0。
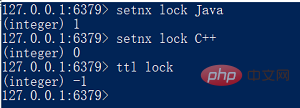
setnx用法
可以看出,当把key为lock的值设置为"Java"后,再设置成别的值就会失败,看上去很简单,也好像独占了锁,但有个致命的问题,就是key没有过期时间,这样一来,除非手动删除key或者获取锁后设置过期时间,不然其他线程永远拿不到锁。
既然这样,我们给key加个过期时间总可以吧,直接让线程获取锁的时候执行两步操作:
`SETNX Key 1` `EXPIRE Key Seconds`
这个方案也有问题,因为获取锁和设置过期时间分成两步了,不是原子性操作,有可能获取锁成功但设置时间失败,那样不就白干了吗。
不过也不用急,这种事情Redis官方早为我们考虑到了,所以就引出了下面这个命令
2、SETEX,用法SETEX key seconds value
将值 value 关联到 key ,并将 key 的生存时间设为 seconds (以秒为单位)。如果 key 已经存在,SETEX 命令将覆写旧值。
这个命令类似于以下两个命令:
`SET key value` `EXPIRE key seconds # 设置生存时间`
这两步动作是原子性的,会在同一时间完成。
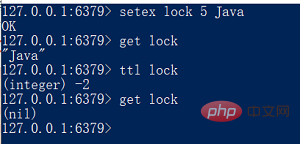
setex用法
3、PSETEX ,用法PSETEX key milliseconds value
这个命令和SETEX命令相似,但它以毫秒为单位设置 key
`SET key value NX EX seconds`
SETEX-SchlüsselsekundenwertÄndern Sie den Wert < code> value ist mit key verknüpft und legt die Lebensdauer des key auf seconds (in Sekunden) fest. Wenn key bereits vorhanden ist, überschreibt der SETEX-Befehl den alten Wert. Dieser Befehl ähnelt den folgenden beiden Befehlen: 🎜`if redis.call("get",KEYS[1]) == ARGV[1]`
`then`
`return redis.call("del",KEYS[1])`
`else`
`return 0`
`end` 🎜🎜setex-Nutzung🎜🎜3. PSETEX, Verwendung
🎜🎜setex-Nutzung🎜🎜3. PSETEX, Verwendung PSETEX-Schlüssel-Millisekundenwert🎜🎜Dieser Befehl ähnelt SETEX Aber er legt die Lebensdauer von key in Millisekunden fest, nicht in Sekunden wie der SETEX-Befehl. 🎜🎜Ab Redis Version 2.6.12 kann der SET-Befehl jedoch Parameter verwenden, um den gleichen Effekt zu erzielen wie die drei Befehle SETNX, SETEX und PSETEX. 🎜🎜Zum Beispiel dieser Befehl🎜`public class RedisLockUtil {`
`private String LOCK_KEY = "redis_lock";`
`// key的持有时间,5ms`
`private long EXPIRE_TIME = 5;`
`// 等待超时时间,1s`
`private long TIME_OUT = 1000;`
`// redis命令参数,相当于nx和px的命令合集`
`private SetParams params = SetParams.setParams().nx().px(EXPIRE_TIME);`
`// redis连接池,连的是本地的redis客户端`
`JedisPool jedisPool = new JedisPool("127.0.0.1", 6379);`
`/**`
`* 加锁`
`*`
`* @param id`
`* 线程的id,或者其他可识别当前线程且不重复的字段`
`* @return`
`*/`
`public boolean lock(String id) {`
`Long start = System.currentTimeMillis();`
`Jedis jedis = jedisPool.getResource();`
`try {`
`for (;;) {`
`// SET命令返回OK ,则证明获取锁成功`
`String lock = jedis.set(LOCK_KEY, id, params);`
`if ("OK".equals(lock)) {`
`return true;`
`}`
`// 否则循环等待,在TIME_OUT时间内仍未获取到锁,则获取失败`
`long l = System.currentTimeMillis() - start;`
`if (l >= TIME_OUT) {`
`return false;`
`}`
`try {`
`// 休眠一会,不然反复执行循环会一直失败`
`Thread.sleep(100);`
`} catch (InterruptedException e) {`
`e.printStackTrace();`
`}`
`}`
`} finally {`
`jedis.close();`
`}`
`}`
`/**`
`* 解锁`
`*`
`* @param id`
`* 线程的id,或者其他可识别当前线程且不重复的字段`
`* @return`
`*/`
`public boolean unlock(String id) {`
`Jedis jedis = jedisPool.getResource();`
`// 删除key的lua脚本`
`String script = "if redis.call('get',KEYS[1]) == ARGV[1] then" + " return redis.call('del',KEYS[1]) " + "else"`
`+ " return 0 " + "end";`
`try {`
`String result =`
`jedis.eval(script, Collections.singletonList(LOCK_KEY), Collections.singletonList(id)).toString();`
`return "1".equals(result);`
`} finally {`
`jedis.close();`
`}`
`}`
`}``if redis.call("get",KEYS[1]) == ARGV[1]`
`then`
`return redis.call("del",KEYS[1])`
`else`
`return 0`
`end`KEYS[1]是当前key的名称,ARGV[1]可以是当前线程的ID(或者其他不固定的值,能识别所属线程即可),这样就可以防止持有过期锁的线程,或者其他线程误删现有锁的情况出现。
代码实现
知道了原理后,我们就可以手写代码来实现Redis分布式锁的功能了,因为本文的目的主要是为了讲解原理,不是为了教大家怎么写分布式锁,所以我就用伪代码实现了。
首先是redis锁的工具类,包含了加锁和解锁的基础方法:
`public class RedisLockUtil {`
`private String LOCK_KEY = "redis_lock";`
`// key的持有时间,5ms`
`private long EXPIRE_TIME = 5;`
`// 等待超时时间,1s`
`private long TIME_OUT = 1000;`
`// redis命令参数,相当于nx和px的命令合集`
`private SetParams params = SetParams.setParams().nx().px(EXPIRE_TIME);`
`// redis连接池,连的是本地的redis客户端`
`JedisPool jedisPool = new JedisPool("127.0.0.1", 6379);`
`/**`
`* 加锁`
`*`
`* @param id`
`* 线程的id,或者其他可识别当前线程且不重复的字段`
`* @return`
`*/`
`public boolean lock(String id) {`
`Long start = System.currentTimeMillis();`
`Jedis jedis = jedisPool.getResource();`
`try {`
`for (;;) {`
`// SET命令返回OK ,则证明获取锁成功`
`String lock = jedis.set(LOCK_KEY, id, params);`
`if ("OK".equals(lock)) {`
`return true;`
`}`
`// 否则循环等待,在TIME_OUT时间内仍未获取到锁,则获取失败`
`long l = System.currentTimeMillis() - start;`
`if (l >= TIME_OUT) {`
`return false;`
`}`
`try {`
`// 休眠一会,不然反复执行循环会一直失败`
`Thread.sleep(100);`
`} catch (InterruptedException e) {`
`e.printStackTrace();`
`}`
`}`
`} finally {`
`jedis.close();`
`}`
`}`
`/**`
`* 解锁`
`*`
`* @param id`
`* 线程的id,或者其他可识别当前线程且不重复的字段`
`* @return`
`*/`
`public boolean unlock(String id) {`
`Jedis jedis = jedisPool.getResource();`
`// 删除key的lua脚本`
`String script = "if redis.call('get',KEYS[1]) == ARGV[1] then" + " return redis.call('del',KEYS[1]) " + "else"`
`+ " return 0 " + "end";`
`try {`
`String result =`
`jedis.eval(script, Collections.singletonList(LOCK_KEY), Collections.singletonList(id)).toString();`
`return "1".equals(result);`
`} finally {`
`jedis.close();`
`}`
`}`
`}`具体的代码作用注释已经写得很清楚了,然后我们就可以写一个demo类来测试一下效果:
`public class RedisLockTest {`
`private static RedisLockUtil demo = new RedisLockUtil();`
`private static Integer NUM = 101;`
`public static void main(String[] args) {`
`for (int i = 0; i < 100; i++) {`
`new Thread(() -> {`
`String id = Thread.currentThread().getId() + "";`
`boolean isLock = demo.lock(id);`
`try {`
`// 拿到锁的话,就对共享参数减一`
`if (isLock) {`
`NUM--;`
`System.out.println(NUM);`
`}`
`} finally {`
`// 释放锁一定要注意放在finally`
`demo.unlock(id);`
`}`
`}).start();`
`}`
`}`
`}`我们创建100个线程来模拟并发的情况,执行后的结果是这样的:
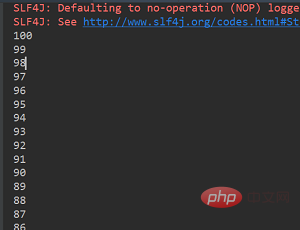
代码执行结果
可以看出,锁的效果达到了,线程安全是可以保证的。
当然,上面的代码只是简单的实现了效果,功能肯定是不完整的,一个健全的分布式锁要考虑的方面还有很多,实际设计起来不是那么容易的。
我们的目的只是为了学习和了解原理,手写一个工业级的分布式锁工具不现实,也没必要,类似的开源工具一大堆(Redisson),原理都差不多,而且早已经过业界同行的检验,直接拿来用就行。
虽然功能是实现了,但其实从设计上来说,这样的分布式锁存在着很大的缺陷,这也是本篇文章想重点探讨的内容。
分布式锁的缺陷
一、客户端长时间阻塞导致锁失效问题
客户端1得到了锁,因为网络问题或者GC等原因导致长时间阻塞,然后业务程序还没执行完锁就过期了,这时候客户端2也能正常拿到锁,可能会导致线程安全的问题。
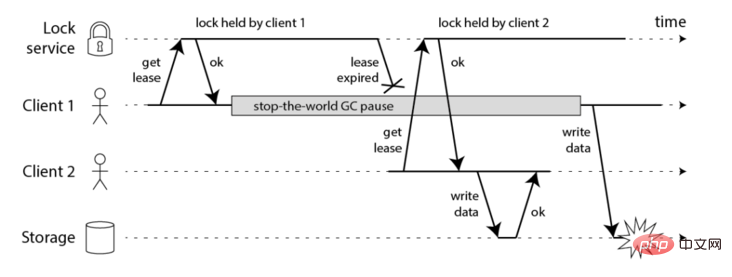
客户端长时间阻塞
那么该如何防止这样的异常呢?我们先不说解决方案,介绍完其他的缺陷后再来讨论。
二、redis服务器时钟漂移问题
如果redis服务器的机器时钟发生了向前跳跃,就会导致这个key过早超时失效,比如说客户端1拿到锁后,key的过期时间是12:02分,但redis服务器本身的时钟比客户端快了2分钟,导致key在12:00的时候就失效了,这时候,如果客户端1还没有释放锁的话,就可能导致多个客户端同时持有同一把锁的问题。
三、单点实例安全问题
如果redis是单master模式的,当这台机宕机的时候,那么所有的客户端都获取不到锁了,为了提高可用性,可能就会给这个master加一个slave,但是因为redis的主从同步是异步进行的,可能会出现客户端1设置完锁后,master挂掉,slave提升为master,因为异步复制的特性,客户端1设置的锁丢失了,这时候客户端2设置锁也能够成功,导致客户端1和客户端2同时拥有锁。
为了解决Redis单点问题,redis的作者提出了RedLock算法。
RedLock算法
该算法的实现前提在于Redis必须是多节点部署的,可以有效防止单点故障,具体的实现思路是这样的:
1、获取当前时间戳(ms);
2、先设定key的有效时长(TTL),超出这个时间就会自动释放,然后client(客户端)尝试使用相同的key和value对所有redis实例进行设置,每次链接redis实例时设置一个比TTL短很多的超时时间,这是为了不要过长时间等待已经关闭的redis服务。并且试着获取下一个redis实例。
比如:TTL(也就是过期时间)为5s,那获取锁的超时时间就可以设置成50ms,所以如果50ms内无法获取锁,就放弃获取这个锁,从而尝试获取下个锁;
3、client通过获取所有能获取的锁后的时间减去第一步的时间,还有redis服务器的时钟漂移误差,然后这个时间差要小于TTL时间并且成功设置锁的实例数>= N/2 + 1(N为Redis实例的数量),那么加锁成功
比如TTL是5s,连接redis获取所有锁用了2s,然后再减去时钟漂移(假设误差是1s左右),那么锁的真正有效时长就只有2s了;
4、如果客户端由于某些原因获取锁失败,便会开始解锁所有redis实例。
根据这样的算法,我们假设有5个Redis实例的话,那么client只要获取其中3台以上的锁就算是成功了,用流程图演示大概就像这样:
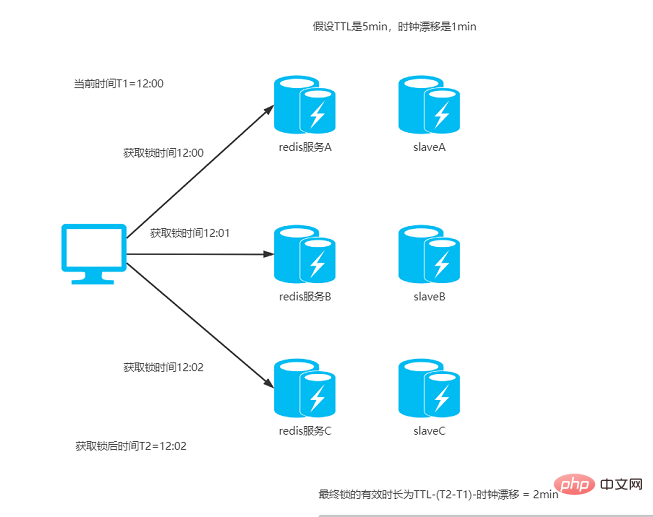
Schlüsselgültigkeitszeit
Okay, der Algorithmus wurde eingeführt. Aus gestalterischer Sicht besteht kein Zweifel daran, dass die Idee des RedLock-Algorithmus hauptsächlich darin besteht, das Problem von Redis wirksam zu verhindern Einzelpunktfehler und beim Entwerfen von TTL Der Fehler der Serveruhrdrift wird ebenfalls berücksichtigt, was die Sicherheit verteilter Sperren erheblich verbessert.
Aber ist das wirklich so? Wie auch immer, ich persönlich bin der Meinung, dass der Effekt durchschnittlich ist.
Zunächst können wir sehen, dass im RedLock-Algorithmus die effektive Zeit der Sperre um die Zeit reduziert wird, die für die Verbindung mit der Redis-Instanz benötigt wird dauert aufgrund von Netzwerkproblemen zu lange. In diesem Fall wird die für die Sperre verbleibende effektive Zeit stark verkürzt. Die Zeit für den Zugriff des Clients auf die gemeinsam genutzten Ressourcen ist sehr kurz und es ist sehr wahrscheinlich, dass die Sperre währenddessen abläuft Programmbearbeitung. Darüber hinaus muss die effektive Zeit der Sperre von der Taktabweichung des Servers abgezogen werden, aber wie viel sollte abgezogen werden, wenn dieser Wert nicht richtig eingestellt ist, kann es leicht zu Problemen kommen.
Dann ist der zweite Punkt, dass dieser Algorithmus zwar die Verwendung mehrerer Knoten berücksichtigt, um Redis Single Point of Failure zu verhindern, es aber dennoch möglich ist, dass mehrere Clients gleichzeitig Sperren erwerben, wenn ein Knoten abstürzt und neu startet.
Angenommen, es gibt insgesamt 5 Redis-Knoten: A, B, C, D, E. Client 1 und 2 sind jeweils gesperrt.
Client 1 hat A, B, C erfolgreich gesperrt und die Sperre erfolgreich erhalten (aber D und E sind nicht gesperrt).
Der Master von Knoten C ist ausgefallen und die Sperre wurde nicht mit dem Slave synchronisiert. Nachdem der Slave zum Master aktualisiert wurde, verlor er die von Client 1 hinzugefügte Sperre.
Client 2 hat zu diesem Zeitpunkt die Sperre erworben, C, D und E gesperrt und die Sperre erfolgreich erworben.
Auf diese Weise erhalten Client 1 und Client 2 gleichzeitig die Sperre, und die versteckte Gefahr der Programmsicherheit besteht weiterhin. Wenn in einem dieser Knoten außerdem eine Zeitverschiebung auftritt, kann dies auch zu Problemen mit der Sperrsicherheit führen.
Obwohl die Verfügbarkeit und Zuverlässigkeit durch die Bereitstellung mehrerer Instanzen verbessert werden, beseitigt RedLock weder die versteckte Gefahr eines Redis-Single-Point-of-Failure vollständig, noch löst es den Sperr-Timeout-Fehler, der durch Taktabweichung und langfristige Client-Blockierung verursacht wird. Es bestehen weiterhin Probleme und Sicherheitsrisiken bei Schlössern.
Fazit
Einige Leute möchten vielleicht weiter fragen: Was sollte getan werden, um die absolute Sicherheit des Schlosses zu gewährleisten?
Ich kann nur sagen, dass Sie Redis nicht gleichzeitig als verteiltes Sperrwerkzeug verwenden können, weil es selbst in Szenarien mit hoher Parallelität eine hohe Effizienz und Einzelprozesseigenschaften aufweist. Unter bestimmten Umständen kann die Leistung auch gut gewährleistet werden, aber in vielen Fällen können Leistung und Sicherheit nicht vollständig ausgeglichen werden. Wenn Sie die Sicherheit der Sperre gewährleisten müssen, können Sie zur Steuerung andere Middleware wie DB und Zookeeper verwenden Ein gutes Schloss kann die Sicherheit des Schlosses gewährleisten, aber seine Leistung kann nur als unbefriedigend bezeichnet werden, sonst hätte es schon längst jeder benutzt.
Wenn Redis zur Steuerung gemeinsam genutzter Ressourcen verwendet wird und hohe Datensicherheitsanforderungen erforderlich sind, besteht die endgültige Garantielösung darin, eine idempotente Kontrolle über Geschäftsdaten zu implementieren. Auf diese Weise hat dies keine Auswirkungen, selbst wenn mehrere Clients Sperren erhalten Datenkonsistenz. Natürlich sind nicht alle Szenen dafür geeignet. Die konkrete Wahl bleibt jedem selbst überlassen. Schließlich gibt es keine perfekte Technik, nur die passende ist die beste.
Weitere Kenntnisse zum Thema Programmierung finden Sie unter: Einführung in die Programmierung! !
Das obige ist der detaillierte Inhalt vonVermitteln Sie ein umfassendes Verständnis der verteilten Sperren in Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
Zu den Schritten zum Starten eines Redis -Servers gehören: Installieren von Redis gemäß dem Betriebssystem. Starten Sie den Redis-Dienst über Redis-Server (Linux/macOS) oder redis-server.exe (Windows). Verwenden Sie den Befehl redis-cli ping (linux/macOS) oder redis-cli.exe ping (Windows), um den Dienststatus zu überprüfen. Verwenden Sie einen Redis-Client wie Redis-Cli, Python oder Node.js, um auf den Server zuzugreifen.
