

Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL, das hauptsächlich auf Probleme im Zusammenhang mit MySQL-Transaktionen eingeht. Transaktionen sind ein wichtiges Merkmal, das MySQL von NoSQL unterscheidet und eine Schlüsseltechnologie zur Gewährleistung der Datenkonsistenz in relationalen Datenbanken darstellt.

Empfohlenes Lernen: MySQL-Lernvideo-Tutorial
Transaktionen sind ein wichtiges Merkmal, das MySQL von NoSQL unterscheidet, und eine Schlüsseltechnologie zur Gewährleistung der Datenkonsistenz in relationalen Datenbanken. Eine Transaktion kann als grundlegende Ausführungseinheit von Datenbankoperationen betrachtet werden, die eine oder mehrere SQL-Anweisungen umfassen kann. Wenn diese Anweisungen ausgeführt werden, werden entweder alle oder keine davon ausgeführt.
Die Ausführung einer Transaktion umfasst hauptsächlich zwei Vorgänge: Commit und Rollback.
Senden: Festschreiben, die Ergebnisse der Transaktionsausführung in die Datenbank schreiben.
Rollback: Rollback, Rollback aller ausgeführten Anweisungen und Rückgabe der Daten vor der Änderung.
MySQL-Transaktionen enthalten vier Merkmale, die als die vier ACID-Könige bekannt sind.
Atomizität: Anweisungen werden entweder vollständig ausgeführt oder gar nicht ausgeführt. Dies ist das Kernmerkmal einer Transaktion. Die Implementierung selbst basiert hauptsächlich auf dem Undo-Protokoll.
Dauerhaftigkeit: stellt sicher, dass Daten aufgrund von Ausfallzeiten und anderen Gründen nach der Transaktionseinreichung nicht verloren gehen;
Isolation: stellt sicher, dass die Transaktionsausführung so weit wie möglich nicht durch andere Transaktionen beeinträchtigt wird; Standardmäßig ist die Isolationsstufe RR. Die Implementierung von RR basiert hauptsächlich auf dem Sperrmechanismus, dem Rückgängig-Protokoll und dem Sperrmechanismus für den nächsten Schlüssel.
Konsistenz (Konsistenz): Das von der Transaktion verfolgte Endziel Die Konsistenz erfordert sowohl die Datenbank als auch die Datenbank.
Die Atomizität einer Transaktion ist wie eine atomare Operation, was bedeutet, dass die Transaktion nicht unterteilt werden kann Wenn die Ausführung einer SQL-Anweisung fehlschlägt, werden entweder alle oder keine Operationen ausgeführt. Die ausgeführte Anweisung muss ebenfalls zurückgesetzt werden und die Datenbank kehrt in den Zustand vor der Transaktion zurück. Es gibt nur 0 und 1 , und es gibt keine anderen Werte. Die Atomizität der Transaktion zeigt an, dass die Transaktion nicht erfolgreich ist. Während der Ausführung müssen alle ausgeführten Anweisungen in der Transaktion zurückgesetzt werden, damit die Datenbank in den Status zurückkehrt Wenn die Transaktion nicht gestartet wurde, wird die Atomizität der Transaktion durch das Rückgängigmachen der Transaktion erreicht. Wenn die Transaktion rückgängig gemacht werden muss, ruft die InnoDB-Engine das Rückgängigmachen der SQL-Anweisung auf und implementiert das Daten-Rollback
PersistenzDie Dauerhaftigkeit der Transaktion bedeutet, dass die Datenbankänderungen nach der Übermittlung dauerhaft sein sollten. Dies bedeutet, dass nach dem Festschreiben der Transaktion keine anderen Vorgänge oder sogar Systemfehler Auswirkungen haben Ausführungsergebnisse der ursprünglichen Transaktion.
Atomizität und Haltbarkeit sind Eigenschaften einer einzelnen Transaktion , während sich Isolation auf die Isolationsanforderungen bezieht, die zwischen Transaktionen eingehalten werden sollten, und die Operationen einer Transaktion sind von anderen Transaktionen isoliert
Unterteilt nach Idee: pessimistisches Schloss, optimistisches Schloss
Kenntnis des Schlossmechanismus Es gibt viele Punkte, aber aus Platzgründen werde ich sie alle besprechen. Hier finden Sie eine kurze Einführung in Sperren, unterteilt nach Granularität.
Granularität: bezieht sich auf den Grad der Verfeinerung oder Vollständigkeit der in der Dateneinheit des Data Warehouse gespeicherten Daten. Je höher der Verfeinerungsgrad, desto kleiner der Granularitätsgrad; umgekehrt gilt: Je niedriger der Verfeinerungsgrad, desto größer der Granularitätsgrad.MySQL kann entsprechend der Granularität der Sperren in Zeilensperren, Tabellensperren und Seitensperren unterteilt werden.Tabellensperre: Die Sperre mit der größten Granularität, was bedeutet, dass die aktuelle Operation die gesamte Tabelle sperrt ;Zeilensperre: Die Sperre mit der kleinsten Granularität, was bedeutet, dass nur die Zeile der aktuellen Operation gesperrt ist;
Seitensperre: Eine Sperre mit einer Granularität zwischen Sperren auf Zeilenebene und Sperren auf Tabellenebene, was bedeutet, dass die Seite gesperrt wird.
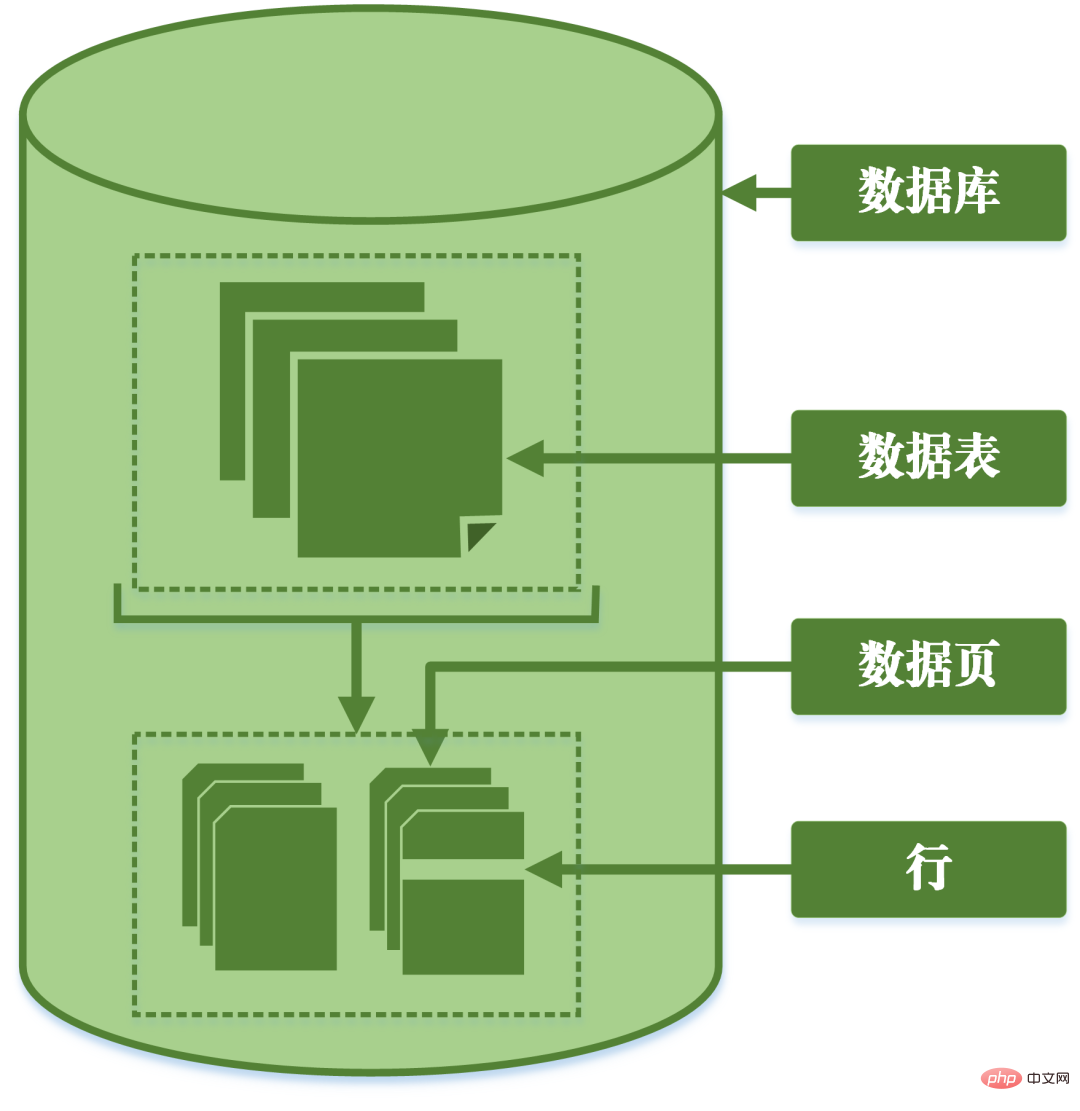
Granulare Aufteilung der Datenbank
Diese drei Arten von Sperren sperren Daten auf unterschiedlichen Ebenen und bringen unterschiedliche Vor- und Nachteile mit sich.
Die Tabellensperre sperrt beim Bearbeiten von Daten die gesamte Tabelle, sodass die Parallelitätsleistung schlecht ist.
Die Zeilensperre sperrt nur die Daten, die bearbeitet werden müssen, und die Parallelitätsleistung ist gut. Da das Sperren selbst jedoch Ressourcen verbraucht (das Erhalten von Sperren, das Überprüfen von Sperren, das Freigeben von Sperren usw. verbraucht alle Ressourcen), kann die Verwendung von Tabellensperren viele Ressourcen einsparen, wenn viele gesperrte Daten vorhanden sind.
Verschiedene Speicher-Engines in MySQL unterstützen unterschiedliche Sperren. MyIsam unterstützt nur Tabellensperren, während InnoDB sowohl Tabellensperren als auch Zeilensperren unterstützt. Aus Leistungsgründen werden in den meisten Fällen Zeilensperren verwendet.
Gleichzeitige Lese- und Schreibprobleme
In einer gleichzeitigen Situation kann das gleichzeitige Lesen und Schreiben von MySQL drei Arten von Problemen verursachen: Dirty Reads, Nichtwiederholbarkeit und Phantom Reads.
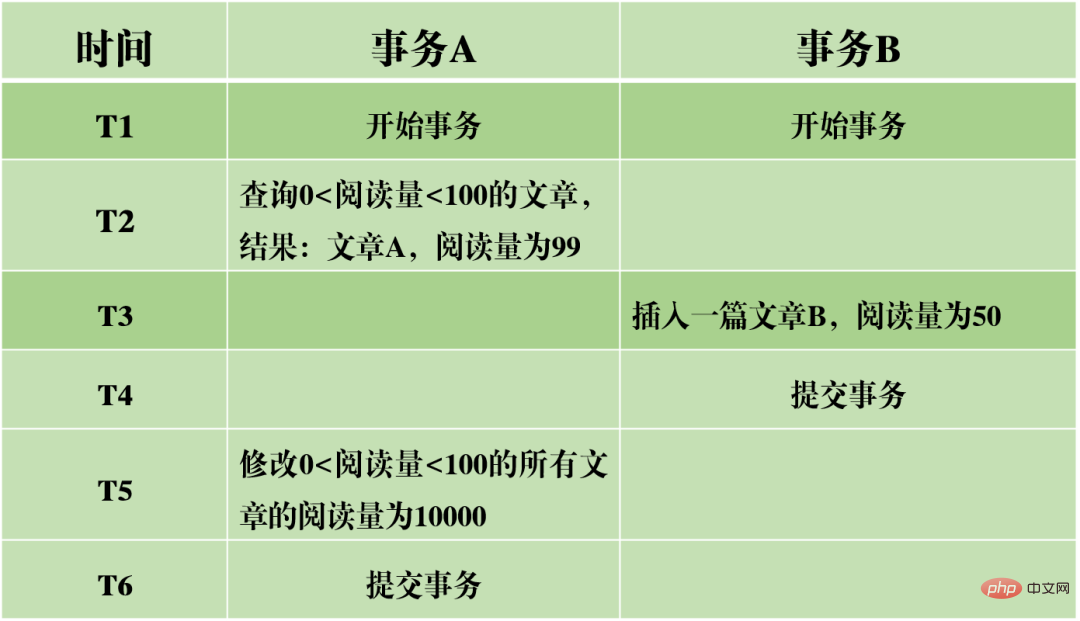
(1) Dirty Reading: Die aktuelle Transaktion liest nicht festgeschriebene Daten aus anderen Transaktionen, bei denen es sich um Dirty Data handelt.
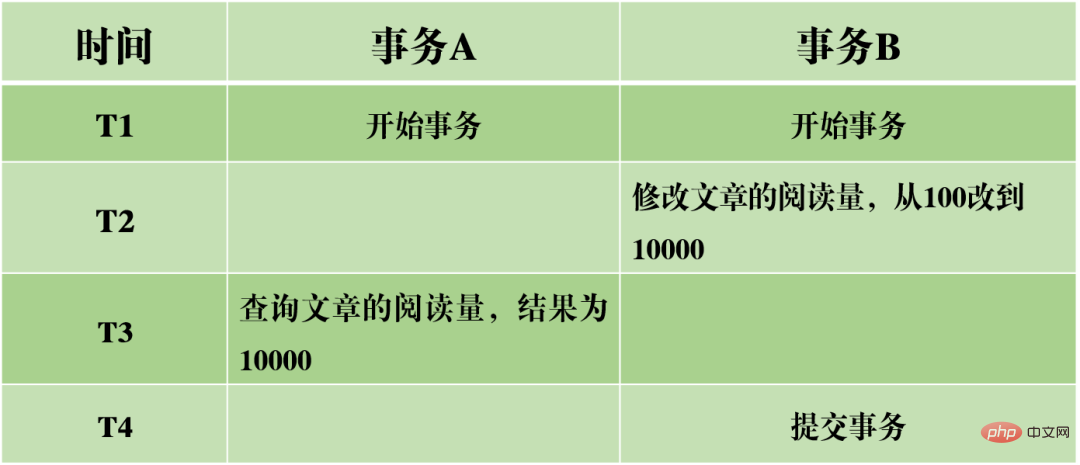
Nehmen wir das obige Bild als Beispiel: Wenn Transaktion A das Lesevolumen des Artikels liest, liest sie die von Transaktion B übermittelten Daten. Wenn Transaktion B am Ende nicht erfolgreich übermittelt wird und die Transaktion zurückgesetzt wird, wird der Lesebetrag nicht tatsächlich erfolgreich geändert, sondern der geänderte Wert wird in Transaktion A gelesen, was offensichtlich unangemessen ist.
(2) Nicht wiederholbares Lesen: Dieselben Daten werden in Transaktion A zweimal gelesen, aber die Ergebnisse der beiden Lesevorgänge sind unterschiedlich. Der Unterschied zwischen Dirty Read und Non-Repeatable Read besteht darin, dass ersteres nicht festgeschriebene Daten von anderen Transaktionen liest, während letzteres Daten liest, die von anderen Transaktionen übermittelt wurden.
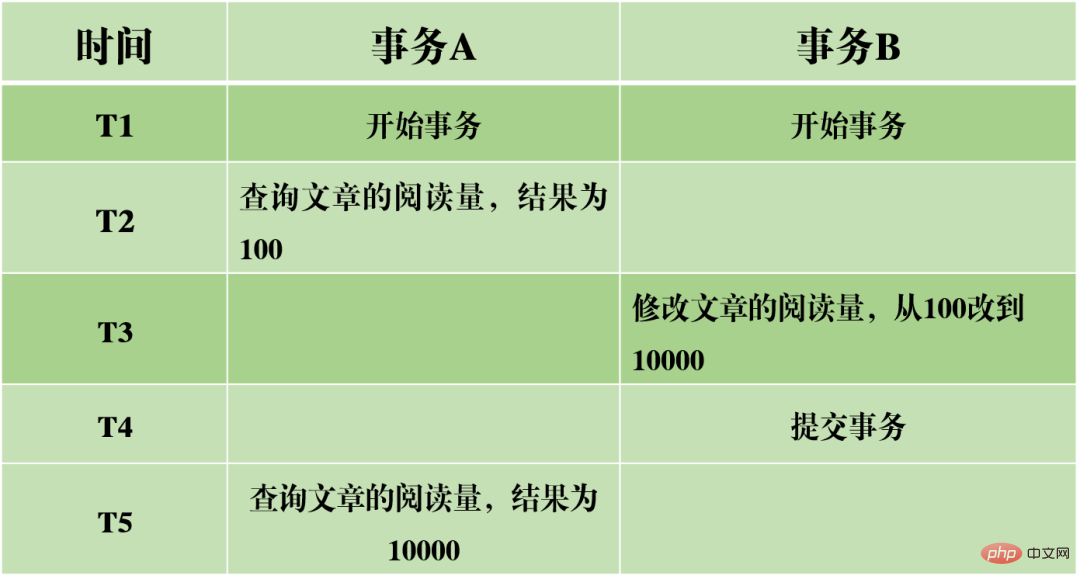
Nehmen wir das obige Bild als Beispiel: Wenn Transaktion A die Daten des Artikellesevolumens nacheinander liest, sind die Ergebnisse unterschiedlich. Dies bedeutet, dass während der Ausführung von Transaktion A der Wert des Lesevolumens durch andere Transaktionen geändert wurde. Dadurch sind die Ergebnisse der Datenabfrage nicht mehr zuverlässig und auch unrealistisch.
(3) Phantomlesung: In Transaktion A wird die Datenbank gemäß einer bestimmten Bedingung zweimal abgefragt. Die Anzahl der Zeilen in den beiden Abfrageergebnissen ist unterschiedlich. Der Unterschied zwischen nicht wiederholbarem Lesen und Phantomlesen kann leicht verstanden werden: Ersteres bedeutet, dass sich die Daten geändert haben, während letzteres bedeutet, dass sich die Anzahl der Datenzeilen geändert hat.
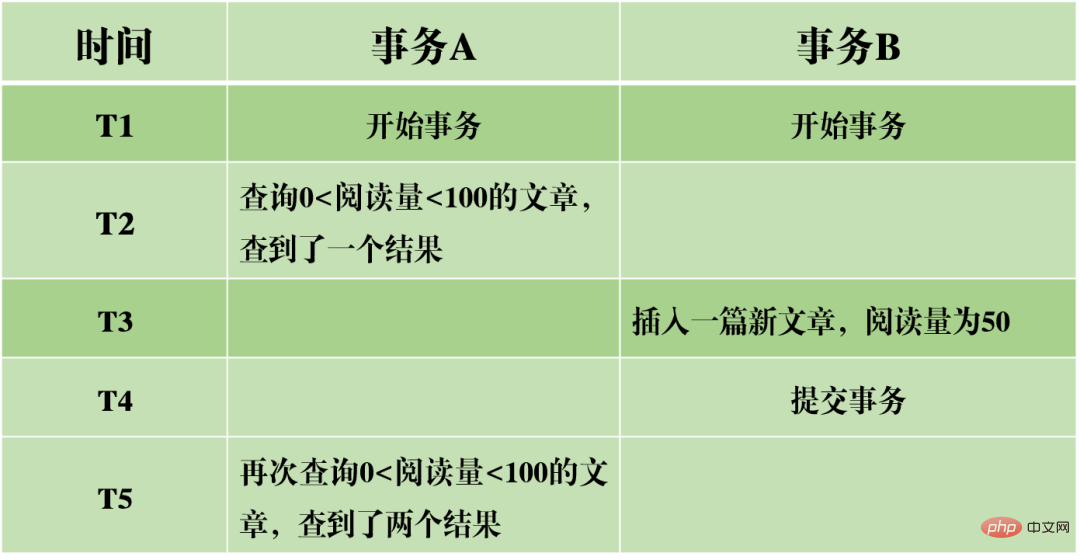
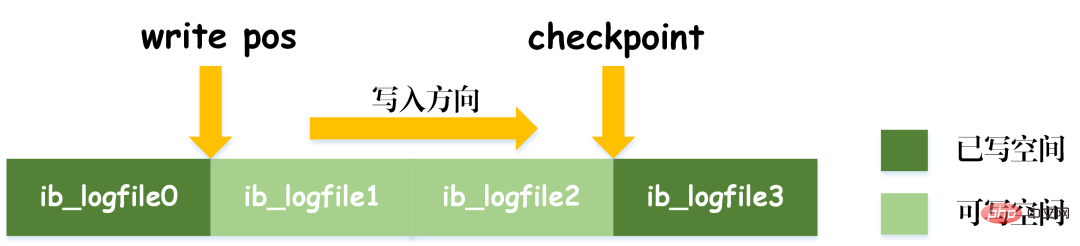
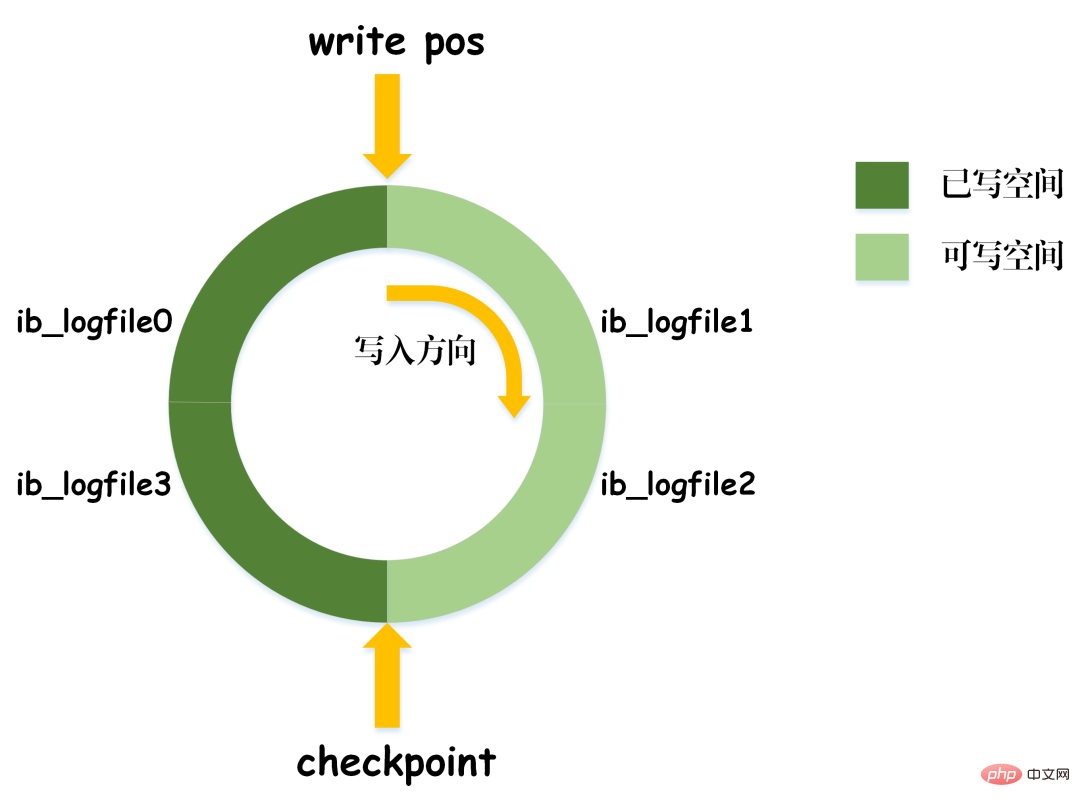
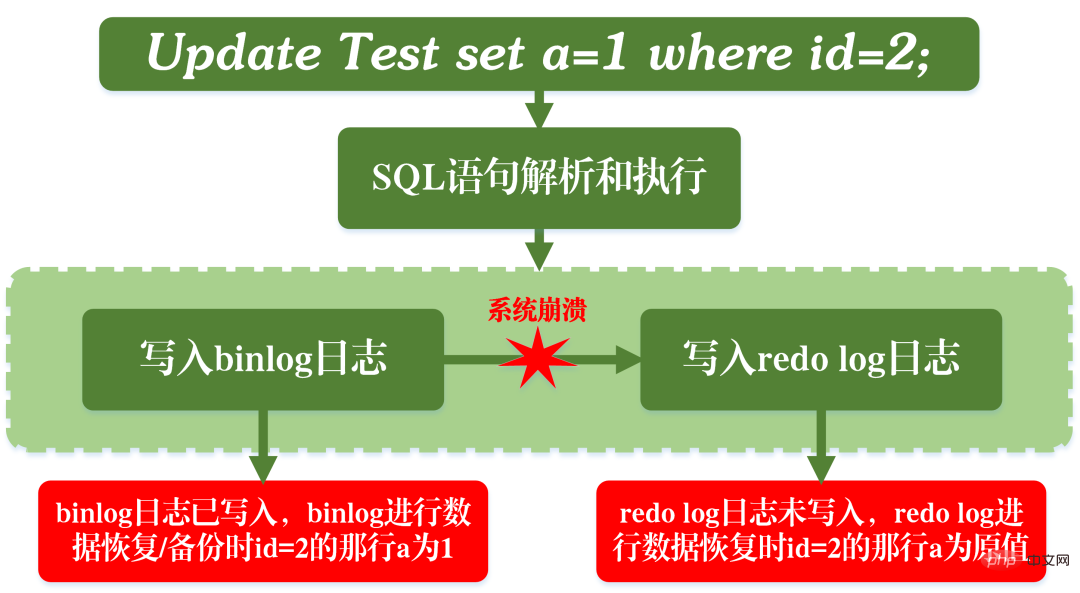
Nehmen wir das obige Bild als Beispiel: Bei der Abfrage von Artikeln mit 0 Isolationsstufen Basierend auf den oben genannten drei Problemen werden vier Isolationsstufen generiert, die unterschiedliche Grade der Isolationseigenschaften der Datenbank angeben. Im tatsächlichen Datenbankdesign gilt: Je höher die Isolationsstufe, desto geringer ist die Parallelitätseffizienz der Datenbank. Wenn die Isolationsstufe zu niedrig ist, treten während des Lese- und Schreibvorgangs verschiedene Probleme auf. In den meisten Datenbanksystemen ist die Standardisolationsstufe also „Read Committed“ (z. B. Oracle) oder „Repeatable Read RR“ (InnoDB-Engine von MySQL). MVCC Ein weiterer großer Brocken, der schwer zu kauen ist. MVCC wird verwendet, um die dritte Isolationsebene oben zu implementieren, die RR wiederholt lesen kann. MVCC: Multi-Version Concurrency Control, ein Protokoll zur Steuerung der Parallelität mehrerer Versionen. Das Merkmal von MVCC besteht darin, dass verschiedene Transaktionen gleichzeitig unterschiedliche Datenversionen lesen können, wodurch die Probleme von Dirty Reads und nicht wiederholbaren Lesevorgängen gelöst werden. MVCC erreicht tatsächlich die Koexistenz mehrerer Datenversionen durch versteckte Datenspalten und Rollback-Protokolle (Rückgängig-Protokoll). Dies hat den Vorteil, dass bei Verwendung von MVCC zum Lesen von Daten keine Sperre erforderlich ist, wodurch Konflikte beim gleichzeitigen Lesen und Schreiben vermieden werden. Bei der Implementierung von MVCC werden in jeder Datenzeile mehrere zusätzliche ausgeblendete Spalten gespeichert, z. B. die Versionsnummer und der Löschzeitpunkt, als die aktuelle Zeile erstellt wurde, sowie der Rollback-Zeiger auf das Rückgängig-Protokoll. Die Versionsnummer ist hier nicht der tatsächliche Zeitwert, sondern die Systemversionsnummer. Bei jedem Start einer neuen Transaktion wird die Systemversionsnummer automatisch erhöht. Die Systemversionsnummer zu Beginn der Transaktion wird als Versionsnummer der Transaktion verwendet und zum Vergleich mit der Versionsnummer jeder Datensatzzeile in der Abfrage verwendet. Jede Transaktion hat ihre eigene Versionsnummer. Wenn Datenoperationen innerhalb der Transaktion ausgeführt werden, wird der Zweck der Datenversionskontrolle durch den Vergleich der Versionsnummern erreicht. Darüber hinaus kann die von InnoDB implementierte Isolationsstufe RR das Phänomen des Phantomlesens vermeiden, was durch den Next-Key-Sperrmechanismus erreicht wird. Next-Key-Sperre ist eigentlich eine Art Zeilensperre, sperrt jedoch nicht nur den aktuellen Zeilendatensatz selbst, sondern auch einen Bereich. Wenn Sie beispielsweise im obigen Beispiel einer Phantomlesung mit der Abfrage von Artikeln mit 0 Lückensperre: Lücken in Indexdatensätzen blockieren Obwohl InnoDB die Next-Key-Sperre verwendet, um Phantomleseprobleme zu vermeiden, handelt es sich dabei nicht um eine wirklich serialisierbare Isolation. Schauen wir uns ein anderes Beispiel an. Lassen Sie mich zunächst eine Frage stellen: Schätzen Sie zum Zeitpunkt T6, nachdem Transaktion A die Transaktion festgeschrieben hat, wie hoch das Lesevolumen von Artikel A und Artikel B ist? Die Antwort ist, dass das Lesevolumen des Artikels AB auf 10.000 geändert wurde. Dies bedeutet, dass die Übermittlung von Transaktion B tatsächlich Auswirkungen auf die Ausführung von Transaktion A hat, was darauf hinweist, dass die beiden Transaktionen nicht vollständig isoliert sind. Obwohl das Phänomen des Phantomlesens vermieden werden kann, erreicht es nicht das Niveau der Serialisierbarkeit. Dies zeigt auch, dass die Vermeidung von Dirty Reads, nicht wiederholbaren Reads und Phantom Reads eine notwendige, aber nicht ausreichende Bedingung ist, um eine serialisierbare Isolationsstufe zu erreichen. Durch die Serialisierbarkeit können Dirty Reads, nicht wiederholbare Lesevorgänge und Phantom Reads vermieden werden. Durch die Vermeidung von Dirty Reads, nicht wiederholbaren Lesevorgängen und Phantom Reads wird jedoch nicht unbedingt Serialisierbarkeit erreicht. Konsistenz Konsistenz bedeutet, dass nach der Ausführung der Transaktion die Integritätsbeschränkungen der Datenbank nicht zerstört werden und der Datenstatus vor und nach der Ausführung der Transaktion legal ist. Konsistenz ist das ultimative Ziel von Transaktionen. Atomarität, Haltbarkeit und Isolation dienen tatsächlich dazu, die Konsistenz des Datenbankstatus sicherzustellen. Mehr gibt es nicht zu sagen. Sie probieren sorgfältig. Nachdem Sie die grundlegende Architektur von MySQL verstanden haben, können Sie im Allgemeinen den Ausführungsprozess von MySQL besser verstehen. Als nächstes werde ich Ihnen das Protokollierungssystem vorstellen. Das MySQL-Protokollierungssystem ist ein wichtiger Bestandteil der Datenbank und wird zum Aufzeichnen von Aktualisierungen und Änderungen an der Datenbank verwendet. Bei einem Datenbankausfall können die Originaldaten der Datenbank über verschiedene Protokolldatensätze wiederhergestellt werden. Daher bestimmt das Protokollsystem tatsächlich direkt die Robustheit und Robustheit des MySQL-Betriebs. MySQL verfügt über viele Arten von Protokollen, z. B. Binärprotokolle (Binlog), Fehlerprotokolle, Abfrageprotokolle, langsame Abfrageprotokolle usw. Darüber hinaus bietet die InnoDB-Speicher-Engine zwei Arten von Protokollen: Redo-Protokolle (Redo-Protokolle) und Protokoll rückgängig machen (Protokoll zurückgeben). Hier konzentrieren wir uns auf die InnoDB-Engine und analysieren die drei Arten von Redo-Logs, Rollback-Logs und Binärlogs. Redo-Protokoll (Redo-Protokoll) Das Redo-Protokoll (Redo-Protokoll) ist das Protokoll der InnoDB-Engine-Schicht. Es wird zum Aufzeichnen von Datenänderungen verwendet, die durch Transaktionsvorgänge verursacht werden, und zeichnet die physische Änderung von Datenseiten auf. Die Funktion des Redo-Tagebuchs ist eigentlich leicht zu verstehen, lassen Sie mich eine Analogie verwenden. Die Änderung von Daten in der Datenbank ist wie eine Arbeit, die Sie geschrieben haben. Was passiert, wenn die Arbeit eines Tages verloren geht? Um diesem unglücklichen Vorfall vorzubeugen, können wir beim Verfassen einer Arbeit ein kleines Notizbuch führen, in dem wir jede Änderung aufzeichnen und aufzeichnen, wann und welche Art von Änderungen an einer bestimmten Seite vorgenommen wurden. Dies ist das Redo-Log. Die InnoDB-Engine aktualisiert Daten, indem sie zunächst den Aktualisierungsdatensatz in das Redo-Protokoll schreibt und dann den Inhalt des Protokolls auf die Festplatte aktualisiert, wenn das System inaktiv ist oder gemäß der festgelegten Aktualisierungsstrategie. Hierbei handelt es sich um die sogenannte Write-Ahead-Technologie (Write-Ahead-Protokollierung). Diese Technologie kann die Häufigkeit von E/A-Vorgängen erheblich reduzieren und die Effizienz der Datenaktualisierung verbessern. Dirty Data Flushing Es ist zu beachten, dass die Größe des Redo-Logs festgelegt ist. Um kontinuierlich Aktualisierungsdatensätze zu schreiben, sind im Redo-Log zwei Flag-Positionen festgelegt: checkpoint und write_pos, die jeweils die Position darstellen Die Löschung wird aufgezeichnet und die Position, an der geschrieben wird, wird aufgezeichnet. Das Datenschreibdiagramm des Redo-Logs ist in der folgenden Abbildung zu sehen. Wenn das write_pos-Flag das Ende des Protokolls erreicht, springt es vom Ende zum Kopf des Protokolls, um es wieder in Umlauf zu bringen. Daher ist die logische Struktur des Redo-Protokolls nicht linear, sondern kann als kreisförmige Bewegung betrachtet werden. Der Raum zwischen write_pos und checkpoint kann zum Schreiben neuer Daten genutzt werden. Das Schreiben und Löschen erfolgt zyklisch hin und her. Wenn write_pos den Checkpoint einholt, bedeutet dies, dass das Redo-Log voll ist. Zu diesem Zeitpunkt können Sie keine weiteren Datenbankaktualisierungsanweisungen ausführen. Sie müssen zuerst einige Datensätze anhalten und löschen und Prüfpunktregeln ausführen, um beschreibbaren Speicherplatz freizugeben. Checkpoint-Regeln: Nachdem der Checkpoint ausgelöst wurde, werden sowohl fehlerhafte Datenseiten als auch fehlerhafte Protokollseiten im Puffer auf die Festplatte geleert. Verschmutzte Daten: Bezieht sich auf die Daten im Speicher, die nicht auf die Festplatte geleert wurden. Das wichtigste Konzept im Redo-Log ist der Pufferpool. Dabei handelt es sich um einen im Speicher zugewiesenen Bereich, der die Zuordnung einiger Datenseiten auf der Festplatte enthält und als Puffer für den Zugriff auf die Datenbank dient. Wenn eine Anfrage zum Lesen von Daten gestellt wird, wird zunächst festgestellt, ob ein Treffer im Pufferpool vorliegt. Wenn ein Treffer fehlschlägt, wird er auf der Festplatte abgerufen und in den Pufferpool gestellt Wenn eine Anforderung zum Schreiben von Daten gestellt wird, werden diese zuerst in den Pufferpool geschrieben. Die geänderten Daten im Pufferpool werden regelmäßig auf die Festplatte geleert. Dieser Vorgang wird auch Bürsten genannt. Zusätzlich zum oben erwähnten Flushen von Dirty-Daten ist es bei der Aufzeichnung des Redo-Logs tatsächlich auch erforderlich, die Protokolldatensätze zu schreiben, um die Persistenz der Protokolldatei sicherzustellen vom Speicher zum Festplattenprozess. Das Redo-Log-Protokoll kann in zwei Teile unterteilt werden: der Cache-Log-Redo-Log-Buff, der im flüchtigen Speicher vorhanden ist, und der andere Teil ist die auf der Festplatte gespeicherte Redo-Log-Datei. Um sicherzustellen, dass jeder Datensatz in das Protokoll auf der Festplatte geschrieben werden kann, wird der fsync-Vorgang des Betriebssystems jedes Mal aufgerufen, wenn das Protokoll im Redo-Log-Puffer in die Redo-Log-Datei geschrieben wird. Binärprotokoll Binlog ist ein Protokoll der Serviceschicht und wird auch als Archivprotokoll bezeichnet. Binlog zeichnet hauptsächlich Änderungen in der Datenbank auf, einschließlich aller Aktualisierungsvorgänge der Datenbank. Alle Vorgänge mit Datenänderungen müssen im Binärprotokoll aufgezeichnet werden. Daher kann Binlog problemlos Daten kopieren und sichern und wird daher häufig zur Synchronisierung von Master-Slave-Bibliotheken verwendet. Der hier im Binlog gespeicherte Inhalt scheint dem Redo-Log sehr ähnlich zu sein, ist es aber nicht. Das Redo-Protokoll ist ein physisches Protokoll, das die tatsächlichen Änderungen an bestimmten Daten aufzeichnet, während das Binlog ein logisches Protokoll ist, das die ursprüngliche Logik der SQL-Anweisung aufzeichnet, z. B. „Geben Sie ein Feld der Zeile mit der ID=2 an.“ 1" hinzufügen. Der Inhalt des Binlog-Protokolls ist binär. Abhängig von den Protokollformatparametern kann er auf SQL-Anweisungen, den Daten selbst oder einer Mischung aus beidem basieren. Im Allgemeinen werden häufig verwendete Datensätze SQL-Anweisungen verwendet. Mein persönliches Verständnis der Konzepte der Physik und Logik hier ist: Ausführungsprozess der MySQL-Update-Anweisung Wie aus der obigen Abbildung ersichtlich ist, analysiert und führt MySQL die Anweisung in der Serviceschicht aus, extrahiert und speichert Daten in der Engine-Schicht Gleichzeitig schreibt die Schicht im Dienst das Binlog und das Redo-Log in InnoDB. Darüber hinaus gibt es beim Schreiben des Redo-Logs zwei Phasen der Übermittlung: Zum einen wird der Vorbereitungsstatus geschrieben, bevor das Binlog geschrieben wird, und zum anderen wird der Commit-Status geschrieben, nachdem das Binlog geschrieben wird. Der Grund, warum eine solche zweistufige Einreichung angeordnet ist, ist natürlich vernünftig. Jetzt können wir davon ausgehen, dass wir anstelle der zweistufigen Übermittlung eine „einstufige“ Übermittlung übernehmen, d. h. entweder zuerst das Redo-Protokoll schreiben und dann das Binlog schreiben oder zuerst das Binlog schreiben und dann das Redo-Protokoll schreiben. Die Übermittlung auf diese beiden Arten führt dazu, dass der Status der Originaldatenbank nicht mit dem Status der wiederhergestellten Datenbank übereinstimmt. Schreiben Sie zuerst das Redo-Protokoll und dann das Binlog: Nach dem Schreiben des Redo-Protokolls sind die Daten zu diesem Zeitpunkt absturzsicher, sodass das System abstürzt und die Daten in den Zustand vor Beginn der Transaktion zurückversetzt werden. Wenn das System jedoch abstürzt, wenn das Redo-Log abgeschlossen ist und bevor das Binlog geschrieben wird, stürzt das System ab. Zu diesem Zeitpunkt speichert binlog die obige Aktualisierungsanweisung nicht, was dazu führt, dass die obige Aktualisierungsanweisung fehlt, wenn binlog zum Sichern oder Wiederherstellen der Datenbank verwendet wird. Infolgedessen werden die Daten in der Zeile id=2 nicht aktualisiert. Das Problem besteht darin, zuerst das Redo-Protokoll und dann das Binlog zu schreiben Die Zeilen-ID=2 in der Datenbank wird auf a=1 aktualisiert. Wenn das System jedoch abstürzt, bevor das Redo-Protokoll geschrieben wird, ist die im Redo-Protokoll aufgezeichnete Transaktion ungültig, was dazu führt, dass die Daten in der Zeile id=2 in der tatsächlichen Datenbank nicht aktualisiert werden. Das Problem besteht darin, zuerst Binlog und dann Redo-Log zu schreiben Es ist ersichtlich, dass die zweistufige Übermittlung dazu dient, die oben genannten Probleme zu vermeiden und die im Binlog und Redo-Log gespeicherten Informationen konsistent zu machen. Das Rollback-Protokoll ist ebenfalls ein von der InnoDB-Engine bereitgestelltes Protokoll. Wie der Name schon sagt, besteht die Funktion des Rollback-Protokolls darin, die Daten zurückzusetzen. Wenn eine Transaktion die Datenbank ändert, zeichnet die InnoDB-Engine nicht nur das Redo-Protokoll auf, sondern generiert auch das entsprechende Rückgängig-Protokoll. Wenn die Transaktion fehlschlägt oder ein Rollback aufgerufen wird, wird die Transaktion zurückgesetzt, die Informationen im Rückgängig-Protokoll Mit dieser Funktion können Sie die Daten so wiederherstellen, wie sie vor der Änderung aussahen. Master-Slave-Replikation Das Konzept der Master-Slave-Replikation besteht darin, eine identische Datenbank aus der Originaldatenbank zu kopieren und die kopierte Datenbank zu kopieren die Slave-Datenbank. Die Slave-Datenbank synchronisiert die Daten mit der Master-Datenbank, um die Datenkonsistenz zwischen beiden aufrechtzuerhalten. Der Grund, warum eine Master-Slave-Replikation implementiert werden muss, hängt tatsächlich vom tatsächlichen Anwendungsszenario ab. Die Vorteile, die die Master-Slave-Replikation mit sich bringen kann, sind: 2. Wenn das Geschäftsvolumen größer wird und die E/A-Zugriffsfrequenz zu hoch ist, kann Multidatenbankspeicher verwendet werden, um die Häufigkeit des Festplatten-E/A-Zugriffs zu reduzieren und die E/A-Leistung zu verbessern einer einzelnen Maschine. 3. Es kann die Trennung von Lesen und Schreiben realisieren, sodass die Datenbank eine größere Parallelität unterstützen kann. 4. Implementieren Sie einen Server-Lastausgleich, indem Sie die Last der Kundenanfragen zwischen dem Master-Server und dem Slave-Server aufteilen. MySQL-Datenbanken sollten als eine der Technologien angesehen werden, die Programmierer beherrschen müssen. Ob im Projektprozess oder im Vorstellungsgespräch, MySQL ist ein sehr wichtiges Grundwissen. Allerdings gibt es wirklich zu viele Dinge für MySQL. Als ich diesen Artikel schrieb, habe ich viele Informationen konsultiert und festgestellt, dass ich umso mehr nicht verstehen konnte, je mehr ich nicht verstehen konnte. Es passt wirklich zu dem Sprichwort: Je mehr du weißt, desto mehr weißt du nicht. Dieser Artikel konzentriert sich auf die Analyse der Grundprinzipien des grundlegenden Transaktions- und Protokollierungssystems von MySQL aus theoretischer Sicht. Ich versuche, bei der Beschreibung die Verwendung von tatsächlichem Code zu vermeiden. Selbst dieser Artikel mit fast 10.000 Wörtern und fast 20 handgezeichneten Abbildungen kann die Breite und Tiefe von MySQL nicht vollständig analysieren. Aber ich glaube, dass diese Theorien Anfängern einen umfassenden Überblick über MySQL vermitteln und Ihnen ein klareres Verständnis der Frage „Was ist eine relationale Datenbank“ vermitteln können, und für diejenigen, die sich mit MySQL auskennen, vielleicht Dieser Artikel kann auch Ihr lange verlorenes theoretisches Fundament wiedererwecken und wird auch für Ihre nachfolgenden Interviews hilfreich sein. Es gibt kein absolutes Richtig oder Falsch in der Technik. Bitte verzeihen Sie mir, wenn der Artikel Fehler enthält, und besprechen Sie dies gerne mit mir. Unabhängiges Denken ist immer effektiver als passives Akzeptieren. Empfohlenes Lernen: MySQL-Video-Tutorial Das obige ist der detaillierte Inhalt vonLassen Sie uns gemeinsam das MySQL-Transaktionsprotokoll analysieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!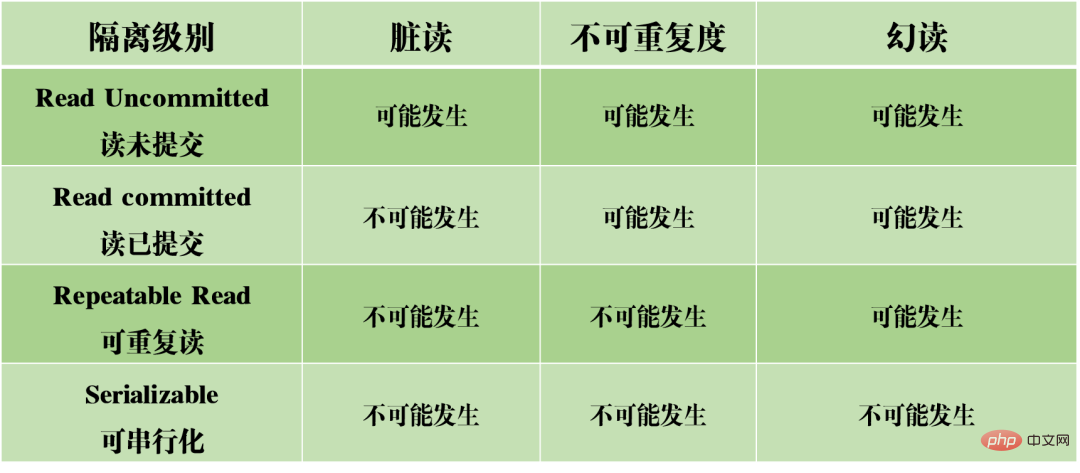
2. MySQL-Protokollsystem
Wenn die Daten geändert werden, wird der Vorgang daher zusätzlich zur Änderung der Daten im Pufferpool auch im Redo-Protokoll aufgezeichnet, wenn die Transaktion übermittelt wird. Die Daten werden basierend auf den Redo-Log-Datensätzen geleert . Sollte MySQL ausfallen, können beim Neustart die Daten im Redo-Log ausgelesen und die Datenbank wiederhergestellt werden, wodurch die Haltbarkeit der Transaktionen gewährleistet und die Datenbank absturzsicher gemacht wird.
Dirty-Log-FlushingWährend des Schreibvorgangs muss es auch den Betriebssystempuffer des Betriebssystem-Kernelraums durchlaufen. Der Schreibvorgang des Redo-Protokolls ist in der folgenden Abbildung dargestellt.
Redo-Log-Flushing-Prozess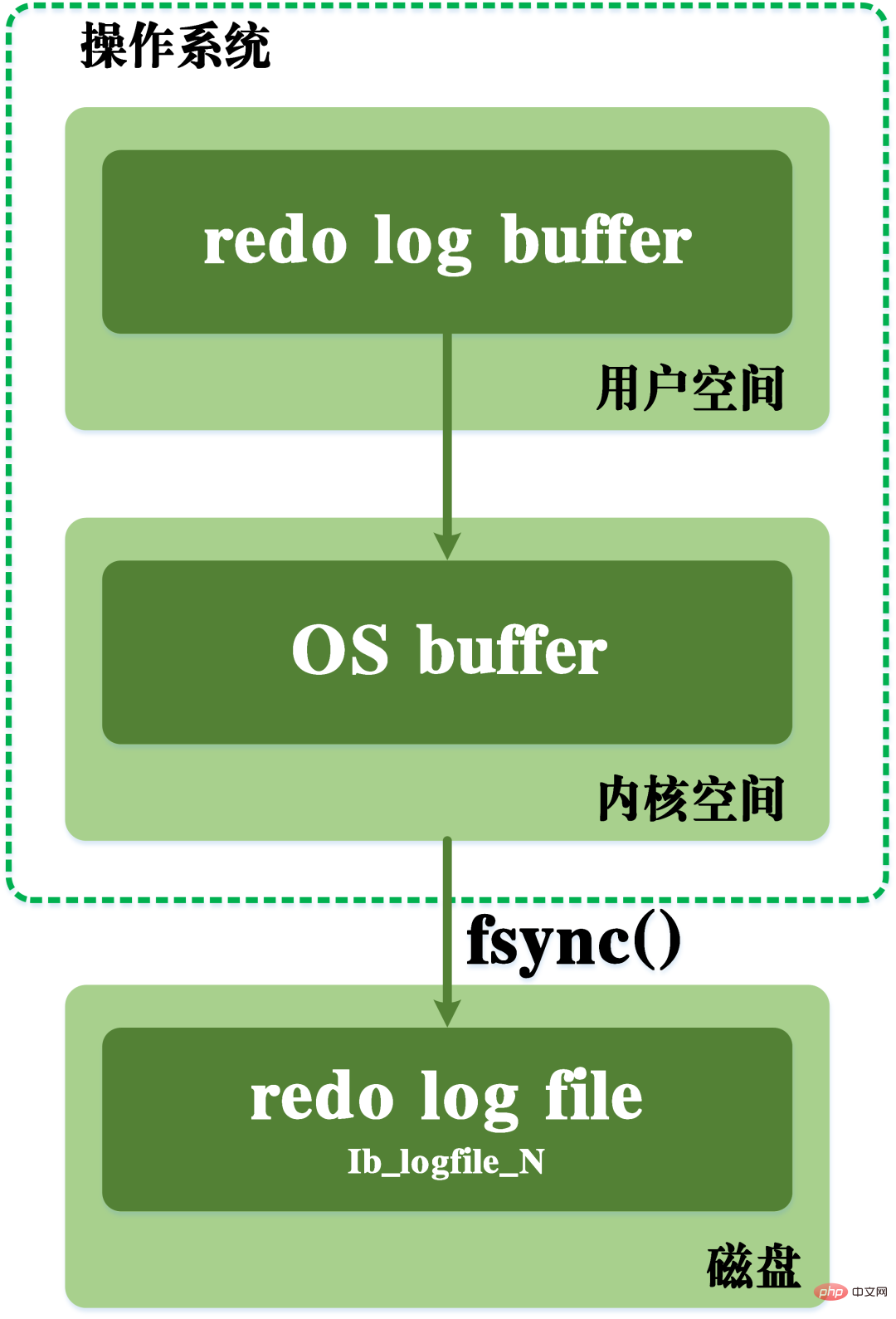
Gleichzeitig basiert das Redo-Log auf der Wiederherstellung nach einem Absturz, um die Datenwiederherstellung nach einem MySQL-Absturz sicherzustellen, während Binlog auf einer zeitpunktbezogenen Wiederherstellung basiert, um sicherzustellen, dass der Server Daten basierend auf Zeitpunkten wiederherstellen oder Daten sichern kann . Tatsächlich hatte MySQL zunächst kein Redo-Log. Da MySQL zunächst keine InnoDB-Engine hatte, war die integrierte Engine MyISAM. Binlog ist ein Service-Layer-Protokoll und kann daher von allen Engines verwendet werden. Binlog-Protokolle allein können jedoch nur Archivierungsfunktionen und keine absturzsicheren Funktionen bereitstellen. Daher verwendet die InnoDB-Engine eine von Oracle erlernte Technologie, nämlich Redo Log, um absturzsichere Funktionen zu erreichen. Hier ist ein Vergleich der Eigenschaften von Redo-Log bzw. Binlog-Protokoll:
Vergleich der Eigenschaften von Redo-Log und Binlog 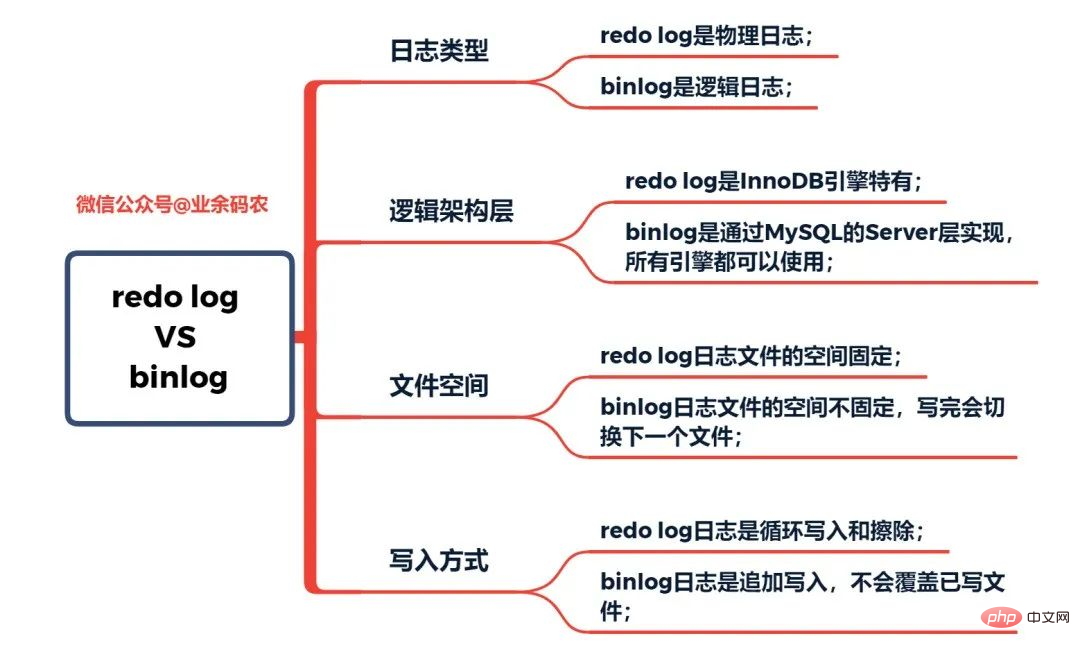 Wenn MySQL Aktualisierungsanweisungen ausführt, sind das Lesen und Schreiben von Redo-Log und Binlog-Protokoll beteiligt. Der Ausführungsprozess einer Update-Anweisung ist wie folgt:
Wenn MySQL Aktualisierungsanweisungen ausführt, sind das Lesen und Schreiben von Redo-Log und Binlog-Protokoll beteiligt. Der Ausführungsprozess einer Update-Anweisung ist wie folgt: 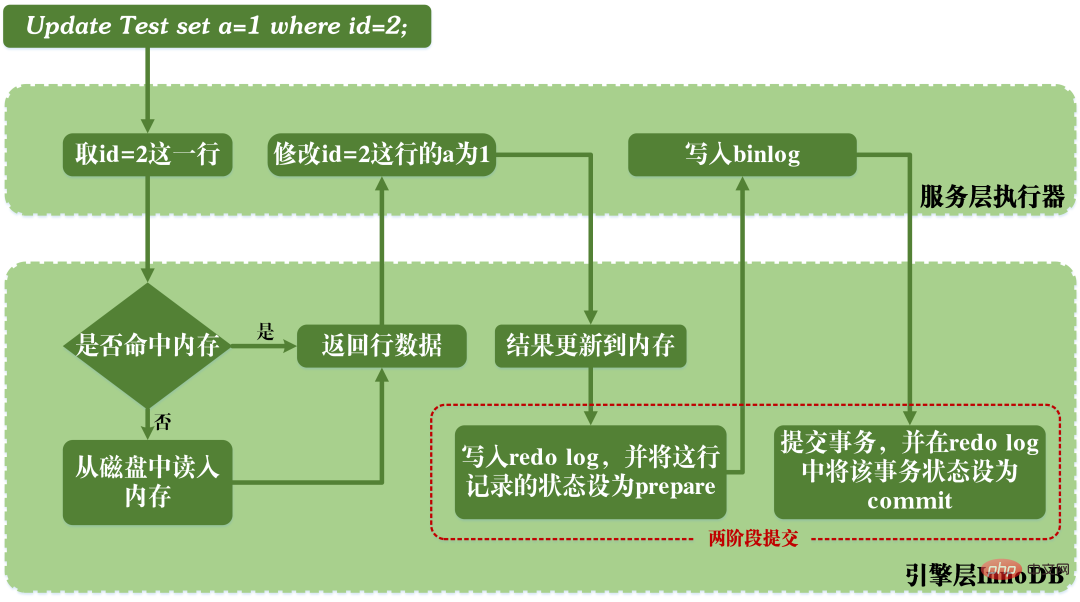
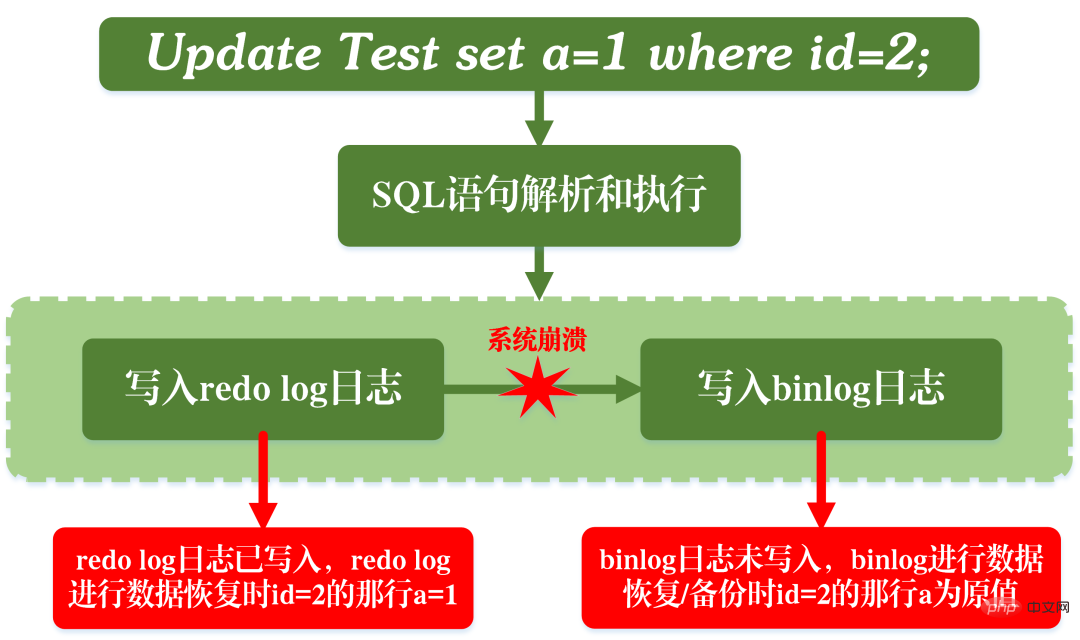
Prinzip der Master-Slave-Replikation
Zusammenfassung
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



