

Ausführliche Erläuterung der klassischen Oracle-Fähigkeiten RAC

Dieser Artikel vermittelt Ihnen relevantes Wissen über Oracle, das hauptsächlich RAC-bezogene Probleme vorstellt. Oracle Real Application Cluster wird verwendet, um eine gemeinsame Datenbank mit mehreren Computern in einer Clusterumgebung zu realisieren, um eine hohe Verfügbarkeit von Anwendungen sicherzustellen.

Empfohlenes Tutorial: „Oracle Tutorial“
Um dem steigenden Geschäftsvolumen gerecht zu werden, gibt es normalerweise zwei allgemeine Richtungen, nämlich die Erhöhung der CPU-Rechenleistung, der Speicherkapazität und der Speicherkapazität eines einzelnen Servers usw.; die andere ist die horizontale Erweiterung, die darin besteht, die Verarbeitungsleistung durch Erhöhung der Anzahl der Server zu erhöhen. Ersteres weist viele Probleme wie Betriebsunterbrechungen und Erweiterungsbeschränkungen auf. Insbesondere bei der schnellen Entwicklung von Internetdiensten kann ein einzelner Server die Anforderungen an die Geschäftslast kaum erfüllen. Daher ist die horizontale Erweiterung derzeit die beliebteste Methode.
Was ist Oracle RAC?
Oracle Real Application Cluster (RAC, Echtzeit-Anwendungscluster) wird verwendet, um eine gemeinsam genutzte Datenbank mit mehreren Maschinen in einer Clusterumgebung zu realisieren, um gleichzeitig die hohe Verfügbarkeit von Anwendungen sicherzustellen und gleichzeitig parallele Verarbeitung und Last zu realisieren Ausgleich und kann den Datenbankausfall bei Fehlertoleranz und haltepunktfreier Wiederherstellung realisieren. Es handelt sich um die Kerntechnologie der Oracle-Datenbank zur Unterstützung der Netzwerk-Computing-Umgebung.
Multiaktiver Cluster mit gemeinsam genutztem Speicher
In dieser Architektur führen mehrere Knoten im Cluster dieselbe Datenbankinstanz aus, die Daten sind vollständig konsistent und die erhaltenen Daten sind dieselben, unabhängig davon, von welchem Knoten aus der Benutzer zugreift. Die folgende Abbildung ist ein schematisches Diagramm von Oracle RAC. Ein Cluster besteht aus drei Knoten, die Daten gemeinsam nutzen. 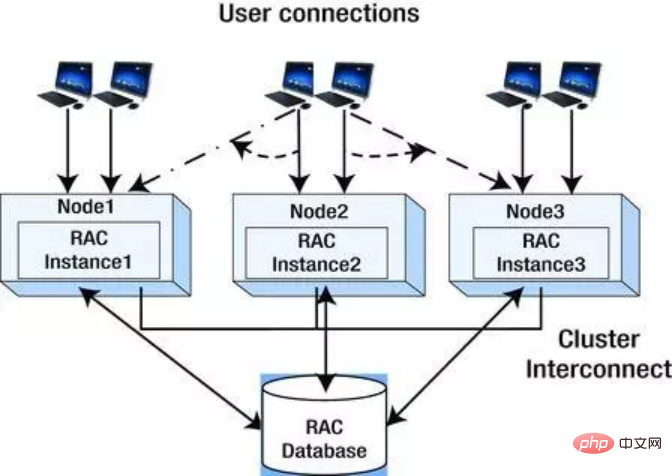
Die Eigenschaften von RAC können wie folgt zusammengefasst werden:
- Knoten sind miteinander verbunden und erscheinen als ein Server;
- Die Festplatte wird gemeinsam genutzt;
- Jede Maschine verwendet dasselbe Betriebssystem ;
- Mehrere Instanzen greifen auf dieselbe Datenbank zu;
- Datenbankdateien unterstützen den physischen oder logischen Zugriff;
- Das Lesen und Schreiben von Daten wird durch Software gesteuert.
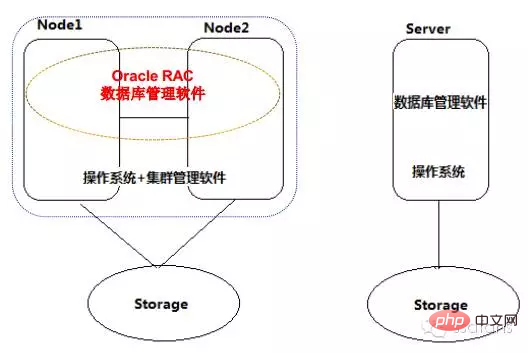
 Der Unterschied zwischen Oracle RAC und einem einzelnen Datenbankserver
Der Unterschied zwischen Oracle RAC und einem einzelnen Datenbankserver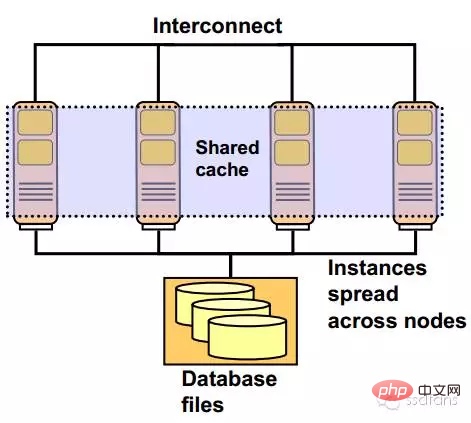 Wie unten gezeigt, besteht der Hauptunterschied darin, dass RAC eine Cluster-Datenbank ist und über Cluster-Software verwaltet wird.
Wie unten gezeigt, besteht der Hauptunterschied darin, dass RAC eine Cluster-Datenbank ist und über Cluster-Software verwaltet wird.
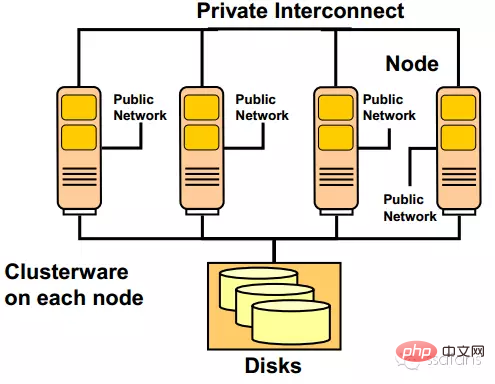
 Oracle RAC-Hardwarearchitektur
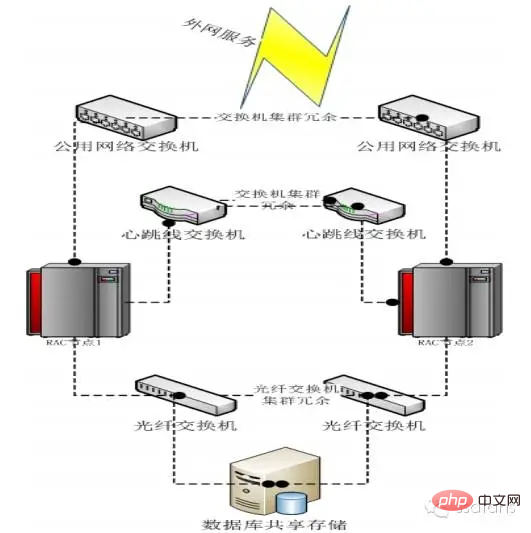
Oracle RAC-Hardwarearchitektur 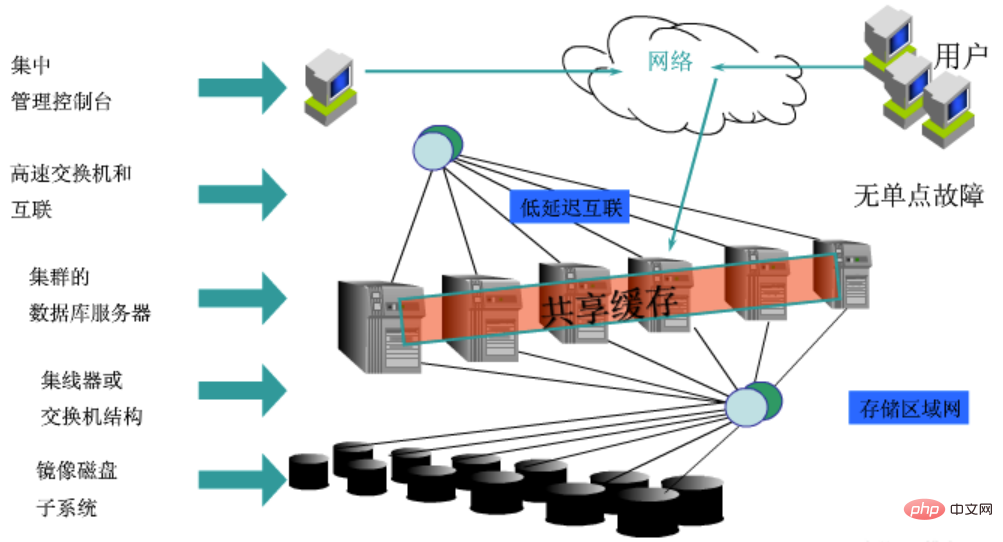 Um die Verfügbarkeit des gesamten Clusters sicherzustellen, stellt Oracle RAC während der Bereitstellung viele Anforderungen an die Hardware. Auf Netzwerkebene verfügt Oracle RAC über insgesamt drei Netzwerksysteme, nämlich das externe Zugangsnetzwerk, das interne private Netzwerk und das Speichernetzwerk.
Um die Verfügbarkeit des gesamten Clusters sicherzustellen, stellt Oracle RAC während der Bereitstellung viele Anforderungen an die Hardware. Auf Netzwerkebene verfügt Oracle RAC über insgesamt drei Netzwerksysteme, nämlich das externe Zugangsnetzwerk, das interne private Netzwerk und das Speichernetzwerk.
Der externe Zugriff auf das Netzwerk ist selbstverständlich, ich glaube, das versteht jeder. Das interne private Netzwerk wird hauptsächlich für die interne Nutzung des Oracle-Clusters verwendet, einschließlich Datenübertragung, Heartbeat und Cluster-Management. Dieser Teil des Netzwerks erfordert während der Bereitstellung zwei Switches und zwei physische Verbindungen, um sicherzustellen, dass Cluster-Anomalien nicht durch Verbindungsausfälle verursacht werden. Dahinter befindet sich das Speichernetzwerk, über das der RAC-Cluster auf Speicherressourcen zugreift. Auch dieser Teil ist Link-redundant.
Ein weiteres Beispiel ist das Bild unten, bei dem es sich um ein RAC-System mit zwei Knoten handelt. Es ist ersichtlich, dass die Redundanz vom Host bis zum Switch implementiert ist, das Geschäft wird nicht beeinträchtigt. Gemeinsamer Speicher verfügt über RAID-Redundanz. 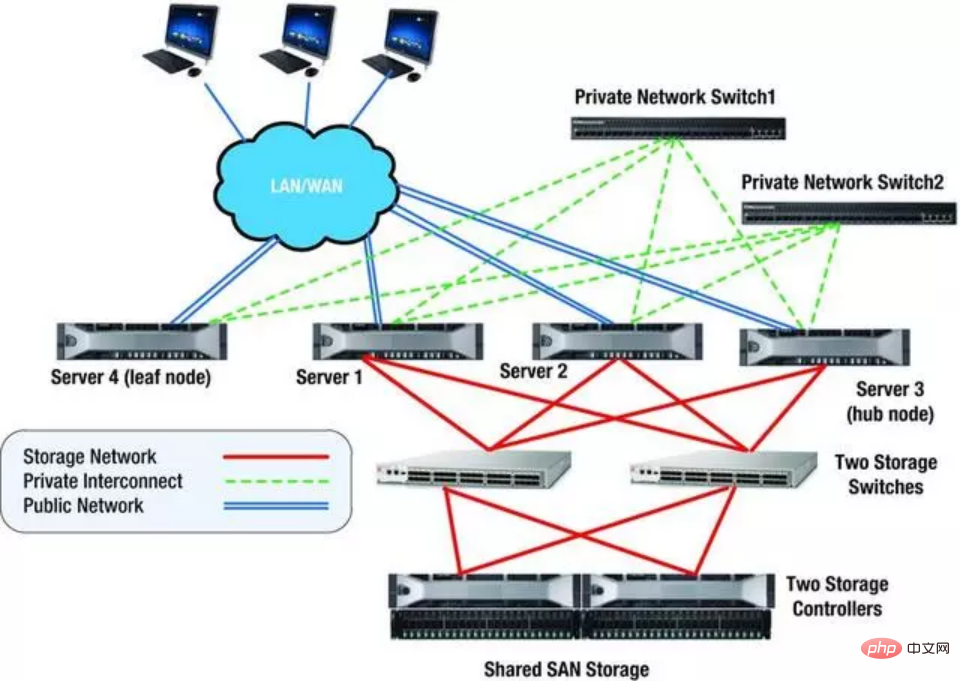
Oracle RAC-Softwarearchitektur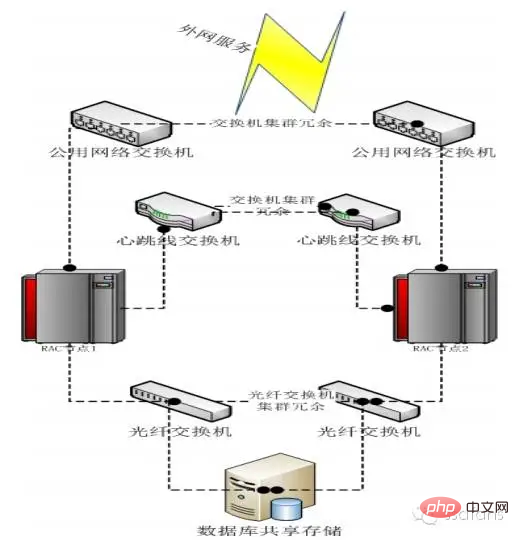
Wie unten gezeigt, handelt es sich um ein RAC-System mit zwei Knoten. Oracle RDBMS ist die Datenbanksoftware und Oracle Clusterware ist die Clustersoftware. Bei den Treibern handelt es sich hauptsächlich um Netzwerkkarten, HBA-Karten, ASMLib usw.
Jeder Knoten muss über das gleiche Betriebssystem verfügen und die Version muss konsistent sein, einschließlich Patch-Nummern usw. Beispiel: Betriebssystem: RHEL AS 4.8 64bit, Linux-Kernelversion: 2.6.9-89.EL. 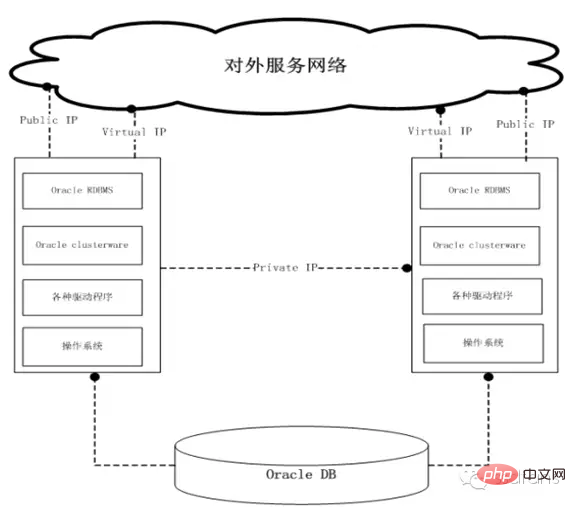
Um Oracle RAC besser zu verstehen, werfen wir einen Blick auf die Zusammensetzung seiner internen Softwaremodule. Auf der gesamten Datenbankebene gibt es nicht viele Unterschiede. Die wichtigsten Ergänzungen sind die folgenden: virtuelle IP (VIP), ASM, Clusterware und Quorum-Disk. Diese neuen Komponenten arbeiten zusammen, um die Multi-Active-Cluster-Funktion von Oracle zu vervollständigen.
Virtuelle IP ist der Zugang für Anwendungen zum Zugriff auf die Datenbank. Diese IP ist an keinen Server gebunden, sondern kann zwischen allen Servern im Cluster wechseln. Dank dieser Funktion kann der Datenbankcluster bei einem Serverabsturz sicherstellen, dass Dienste über dieselbe Schnittstelle für die Außenwelt bereitgestellt werden. 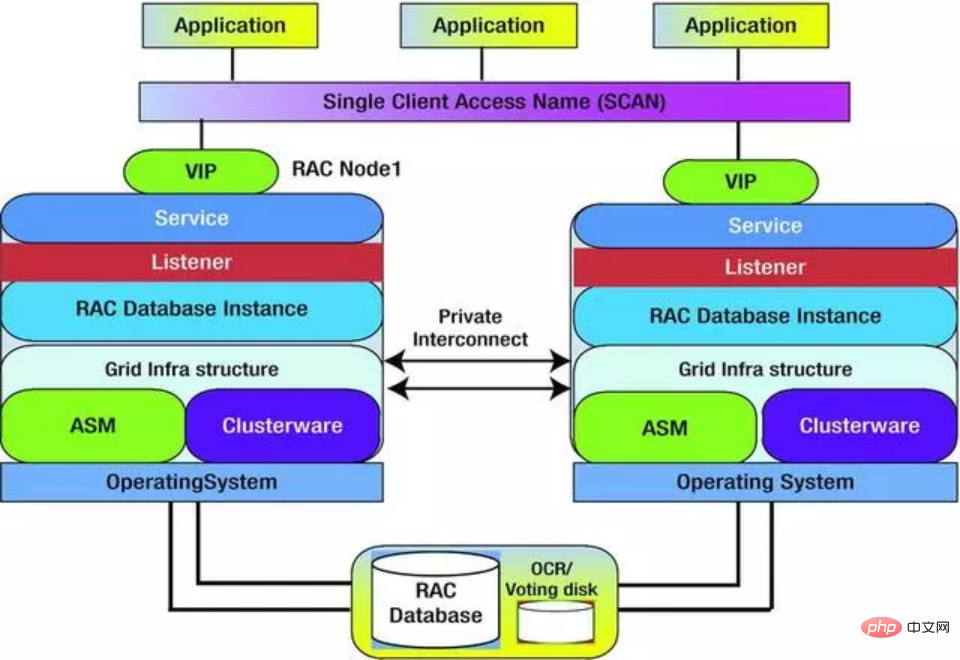
ASM und Clusterware implementieren Clusterverwaltungsfunktionen, um das Risiko von Dateninkonsistenzen durch gleichzeitigen Festplattenzugriff zu vermeiden, während Clusterware zur Verwaltung der Softwareprozesse und Ressourcenplanung von Oracle-Clustern verwendet wird.
Die Quorum-Festplatte wird verwendet, um die Anomalie der Server im Cluster zu ermitteln. Die Knoten im Cluster markieren ihren eigenen Gesundheitsstatus, indem sie die Daten in bestimmten Bereichen der Quorum-Festplatte regelmäßig aktualisieren. Andere Knoten können anhand dieser Daten feststellen, ob der Knoten ausgefallen ist.
Logische Struktur
Die folgende Abbildung zeigt die logische Struktur von Oracle RAC, und jede darin enthaltene Komponente wird nacheinander vorgestellt. 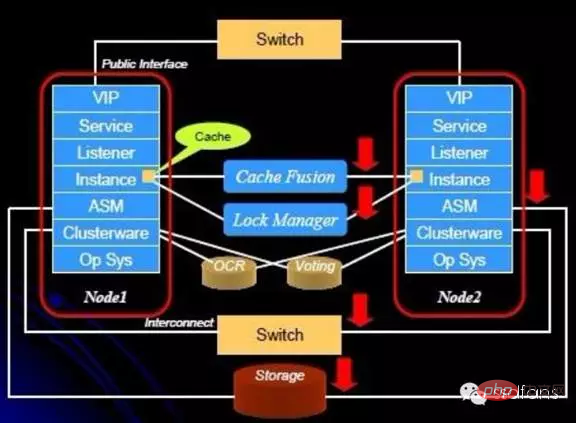
DLM: Parallelitätskontrolle
Jeder Knoten hat gleiche Rechte für den Zugriff auf gemeinsam genutzte Speicherdaten. Oracle RAC verwendet Distribute Lock Management (DLM), um den gleichzeitigen Zugriff zwischen mehreren Knoten zu steuern. Der verteilte Sperrmanager ist für die Koordinierung des Wettbewerbs um gemeinsam genutzte Ressourcen zwischen Knoten verantwortlich. Wenn ein Knoten auf Daten zugreift, muss er sich zunächst über DLM bewerben und bestätigen, dass es nicht zu Konflikten mit anderen Knoten kommt, bevor diese verwendet werden können.
OCR: Amnesie
Amnesie: Wenn jeder Knoten über eine Kopie der Cluster-Konfigurationsinformationen verfügt, tritt ein Fehler auf, wenn nach der Änderung der Konfiguration keine Synchronisierung erfolgt.
Der Cluster kann also nur eine Konfigurationsinformation haben, die von allen Knoten gemeinsam genutzt wird. Oracle RAC verwendet OCR-Disk-Dateien, um Amnesie zu lösen.
OCR-Datenträger können nur vom Master-Knoten geändert werden. Jeder Knoten hat eine Kopie im OCR-Cache-Speicher. Wenn ein Knoten die OCR-Festplatte ändern möchte, fordert er den Master-Knoten an, und der OCR-Prozess auf diesem Knoten aktualisiert den lokalen und anderen Knoten-OCR-Cache-Inhalt. OCR Disk wird regelmäßig alle paar Stunden gesichert.
Voting Disk: Split Brain
Split Brain: Die Knoten im Cluster nutzen die Heartbeat-Erkennung, um zu erkennen, ob die andere Partei gut funktioniert. Wenn es ein Problem mit dem Heartbeat gibt, gehen beide Knoten davon aus, dass die andere Partei einen Fehler gemacht hat , und sie werden um die ausschließliche Nutzung der Daten bitten. Dadurch wird die Datenkonsistenz zerstört.
Voting Disk wird verwendet, um den Status von Mitgliedern zwischen Knoten aufzuzeichnen. Wenn ein Split-Brain auftritt, wird derjenige mit der höchsten Stimmenzahl ausgewählt, um die Kontrolle zu erlangen, und andere Knoten werden rausgeschmissen.
IO-Isolation: Der rausgeschmissene Knoten kann nicht mehr auf Daten zugreifen, daher ist eine IO-Isolation erforderlich. Der Mechanismus von Oracle RAC besteht darin, den ausgefallenen Knoten neu zu starten.
Cache Fusion Lock
Datenbankdateien werden gemeinsam genutzt, und Cache Fusion Lock löst die Speicherfreigabe und gleichzeitige Zugriffskontrolle außerhalb der Clusterebene.
Vier Arten von Netzwerken
1.Öffentliches Netzwerk: Verwenden Sie öffentliche IP, um externe Datenabfragen, Datenbankwartung und Serverwartung bereitzustellen.
2.Virtuelles Netzwerk: Verwenden Sie virtuelle IP, um eine Anwendungsverbindung bereitzustellen, und die Anwendung verwendet diese IP.
Im TCP/IP-Protokoll enthält der TCP-Header die Quell- und Ziel-Ports, der IP-Header enthält die Quell- und Ziel-IPs und der Datenbankmonitor der Anwendungsschicht zeichnet die IP und den Port auf. Wenn das TCP-Timeout abläuft, ist dies bekannt dass ein Problem mit der Datenbank oder dem Monitor vorliegt. Die Zeitüberschreitung des TCP/IP-Protokollstapels wird vom Betriebssystem bestimmt und jedes Betriebssystem hat unterschiedliche Definitionen. Um die Zeit zum Erkennen von Fehlern zu verkürzen, verwendet Oracle RAC VIP. Die virtuelle IP ist schwebend und nicht an die physische Netzwerkkarte gebunden. Wenn ein Knoten ausfällt, wird die VIP in der Überwachung des guten Knotens nicht gefunden und wechseln Sie zu „Andere VIPs senden Verbindungsanfragen“.
3.Privates Netzwerk: Verwenden Sie private IP für die RAC-Heartbeat-Erkennung und Cache Fusion Lock, was eine hohe Geschwindigkeit erfordert.
4. Speichernetzwerk: bestehend aus Speichergeräten, HBA-Karten und FC-Netzwerken.
Oracle Clusterware
Auf einem einzelnen Computer kann nur das Betriebssystem Anforderungen der oberen Ebene verarbeiten. Wenn jedoch mehrere Computer vorhanden sind, fängt die Clusterverwaltungssoftware Oracle Clusterware Anforderungen für andere Knoten vor dem Betriebssystemkern ab und kommuniziert mit dem Clusterware von andere Knoten, um die Anforderungen abzuschließen.
Anwendungsschicht: RDBMS
Die Anwendungsschicht besteht aus mehreren CRS-Ressourcen. Jede Ressource ist ein vollständiger Dienst, der aus mehreren Prozessen besteht. LMON (Lock Monitor) überwacht die CRS-Ressource und startet neu und schaltet um, wenn eine Anomalie auftritt, um die hohe Verfügbarkeit des Oracle RAC-Dienstes sicherzustellen.
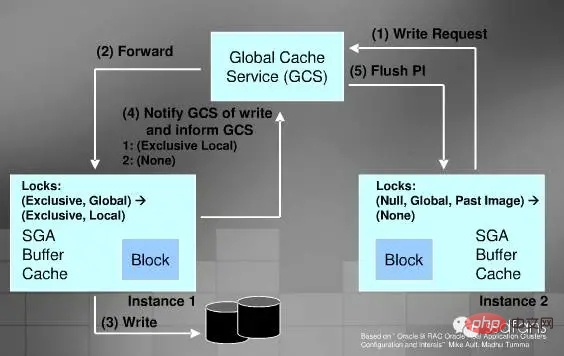
Cache Fusion
Cache Fusion kann wörtlich verstanden werden – Cache Fusion verwaltet tatsächlich den Cache jedes Knotens auf einheitliche Weise, wodurch vermieden wird, dass die Festplatte jedes Mal bedient werden muss, wenn sie gelesen wird, und die E/A-Leistung beschleunigt wird. Da das private Netzwerk sehr schnell ist, ist es schneller als das Lesen der Festplatte. Zeit, Datenblöcke von verschiedenen Orten zu lesen:
- Lokaler Cache: 0,01 ms
- Netzwerkzugriff auf anderen Knoten-Cache: 2,5 ms
- Festplatte: 14 ms. Mit SSD- oder All-Flash-Arrays auf der Speicherseite liegt die Latenz jedoch bei etwa 1 ms. Beim All-Flash-Array ist Cache Fusion also wahrscheinlich bedeutungslos.
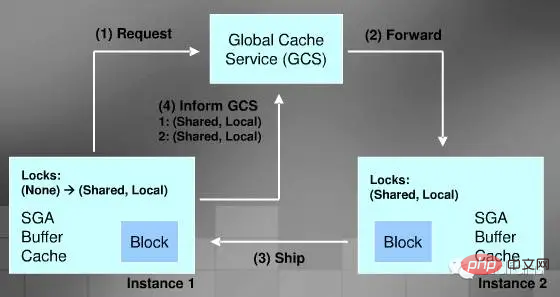
Cache Fusion wird über GCS (Global Cache Service) verwaltet, der Ihren Cache als einen großen Cache behandelt.
Lese-Cache-Prozess
Schreib-Cache-Prozess
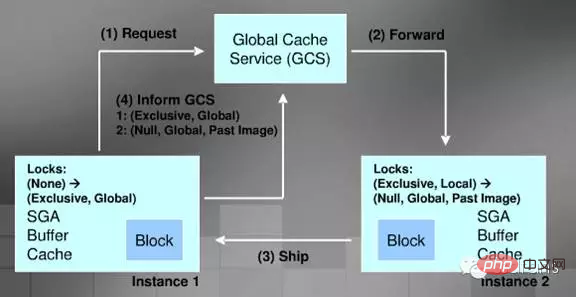
Schreibfestplatten-Prozess
Lastausgleich
Wenn Benutzer verschiedene Anforderungen wie RAC initiieren, ist der Lastausgleich dafür verantwortlich, die Aufgaben gleichmäßig auf verschiedene Maschinen zu verteilen Vorgesetzter.
Verteilung nach Benutzer
Ist es eine zufällige Auswahl aus mehreren Maschinen? NEIN! Das ist zu niedrig. RAC weist Aufgaben dynamisch basierend auf dem Status jeder Maschine zu. Wenn die Datenbank ausgeführt wird, werden die Ladeinformationen des PMON-Hintergrundprozessknotens beim Listener registriert und alle 1–10 Minuten aktualisiert. Der Listener jedes Knotens kennt den Auslastungsstatus aller Knoten und sendet Client-Anfragen an den am stärksten ausgelasteten Knoten.
Zuweisung nach Dienst
Die Zuweisung nach Benutzer hat den Nachteil, dass Cache Fusion dadurch möglicherweise ausgelastet ist. Da RAC-Knotendaten gemeinsam genutzt werden, synchronisiert jeder die Daten über Cache Fusion. Die Leistung von RAC wird weitgehend durch die Leistung von Cache Fusion begrenzt. Entweder wird das private Netzwerk leistungsfähiger gemacht, beispielsweise durch die Verwendung von teurem InfiniBand, oder die andere Möglichkeit besteht darin, den Datenverkehr von Cache Fusion zu reduzieren, wodurch tatsächlich die Abhängigkeit zwischen Knoteninstanzen verringert wird. Der Mechanismus der Zuordnung nach Nutzern ist für die nachfolgenden Lösungen nicht förderlich.
Daher unterstützt RAC die Zuordnung von Knoten nach Diensten. Beispielsweise werden unterschiedliche Knoten für Produktion und Vertrieb verwendet. Ihre eigenen Daten befinden sich in Ihrem eigenen Cache, sodass Sie nicht auf andere Knoten zugreifen müssen. Die Leistung wird verbessert.
Drei Arten von Clustern
- Lastausgleichscluster: Weisen Sie Anforderungen gemäß einem bestimmten Algorithmus verschiedenen Mitgliedern zu.
- Hochleistungscluster (HPC, High Performance Cluster): eine fantastische Maschine, die aus spezialisierter Software und Hardware wie Vektorprozessoren besteht , Computing Leistungsstarke Leistung, super teuer, wie Tianhe Computer;
- Cluster mit hoher Zuverlässigkeit (HAC: High Available Cluster, Failover Cluster): Sehr gute Zuverlässigkeit, starke Fehlertoleranz von Hardware und Software, Datenbankcluster für den täglichen Gebrauch fallen in diese Kategorie.
Hochzuverlässiger Cluster
Dual-Machine-Hot-Standby
Normalerweise ist einer von ihnen im Leerlauf und im Standby-Modus. Wenn der funktionierende Cluster ausfällt, übernimmt der andere. 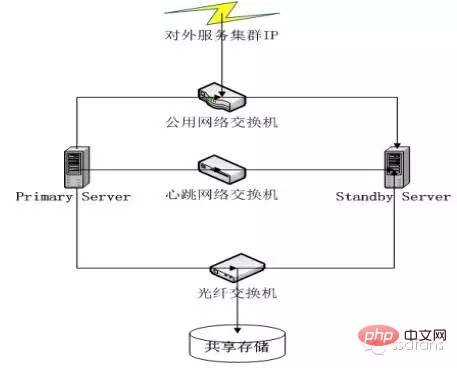
Dual-Machine-Backup
Normalerweise erledigen beide Maschinen ihre eigene Arbeit, es müssen jedoch einige Ressourcen reserviert werden, denn wenn einer ausfällt, muss der andere die Arbeit von zwei Personen erledigen. 
Doppelmaschinen-Duplex
Zum Beispiel:
Der Chef verkauft normalerweise gemeinsam ein Geschäft, und der zweite Bruder verkauft hauptsächlich Sojamilch , der zweite Bruder verkauft wieder Dampfbrötchen und dann wieder Dampfbrötchen Sojamilch, dem zweiten Kind geht es nicht mehr, also verkauft der Chef Dampfbrötchen und Sojamilch.
Baozi-Sojamilch besteht aus Daten, die sich umeinander kümmern, nennt man Heartbeat-Erkennung, und die Übernahme der Arbeit des anderen nennt man Failover. Wenn zwei Brüder plötzlich blind und taub sind und nicht wissen, ob der andere gerade arbeitet, und beide denken, sie müssten die Arbeit des anderen übernehmen, spricht man von Split Brain und dann einem Dritten, etwa dem Vater , ist erforderlich, um das Problem zu lösen, oder ihre beiden Frauen zu bitten, eine von ihnen mitzunehmen. Dies wird als IO-Isolation bezeichnet. Oracle RAC gehört zu dieser Kategorie mit der besten Leistung und dem komplexesten System.
Empfohlenes Tutorial: „Oracle Learning Tutorial“
Das obige ist der detaillierte Inhalt vonAusführliche Erläuterung der klassischen Oracle-Fähigkeiten RAC. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1662
1662
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 Was tun, wenn das Orakel nicht geöffnet werden kann
Apr 11, 2025 pm 10:06 PM
Was tun, wenn das Orakel nicht geöffnet werden kann
Apr 11, 2025 pm 10:06 PM
Lösungen für Oracle können nicht geöffnet werden, einschließlich: 1. Starten Sie den Datenbankdienst; 2. Starten Sie den Zuhörer; 3.. Hafenkonflikte prüfen; 4. Umgebungsvariablen korrekt einstellen; 5. Stellen Sie sicher, dass die Firewall- oder Antivirus -Software die Verbindung nicht blockiert. 6. Überprüfen Sie, ob der Server geschlossen ist. 7. Verwenden Sie RMAN, um korrupte Dateien wiederherzustellen. 8. Überprüfen Sie, ob der TNS -Dienstname korrekt ist. 9. Netzwerkverbindung prüfen; 10. Oracle Software neu installieren.
 So lösen Sie das Problem des Schließens von Oracle Cursor
Apr 11, 2025 pm 10:18 PM
So lösen Sie das Problem des Schließens von Oracle Cursor
Apr 11, 2025 pm 10:18 PM
Die Methode zur Lösung des Oracle Cursor Closeure -Problems umfasst: explizit den Cursor mithilfe der Close -Anweisung schließen. Deklarieren Sie den Cursor in der für Aktualisierungsklausel so, dass er nach Beendigung des Umfangs automatisch schließt. Deklarieren Sie den Cursor in der Verwendung der Verwendung so, dass er automatisch schließt, wenn die zugehörige PL/SQL -Variable geschlossen ist. Verwenden Sie die Ausnahmebehandlung, um sicherzustellen, dass der Cursor in jeder Ausnahmesituation geschlossen ist. Verwenden Sie den Verbindungspool, um den Cursor automatisch zu schließen. Deaktivieren Sie die Automatikübermittlung und Verzögerung des Cursors Schließen.
 So erstellen Sie Cursor in Oracle Loop
Apr 12, 2025 am 06:18 AM
So erstellen Sie Cursor in Oracle Loop
Apr 12, 2025 am 06:18 AM
In Oracle kann die For -Loop -Schleife Cursors dynamisch erzeugen. Die Schritte sind: 1. Definieren Sie den Cursortyp; 2. Erstellen Sie die Schleife; 3.. Erstellen Sie den Cursor dynamisch; 4. Führen Sie den Cursor aus; 5. Schließen Sie den Cursor. Beispiel: Ein Cursor kann mit dem Zyklus für Kreislauf erstellt werden, um die Namen und Gehälter der Top 10 Mitarbeiter anzuzeigen.
 Was tun, wenn das Oracle -Protokoll voll ist
Apr 12, 2025 am 06:09 AM
Was tun, wenn das Oracle -Protokoll voll ist
Apr 12, 2025 am 06:09 AM
Wenn Oracle -Protokolldateien voll sind, können die folgenden Lösungen übernommen werden: 1) alte Protokolldateien reinigen; 2) die Größe der Protokolldatei erhöhen; 3) die Protokolldateigruppe erhöhen; 4) automatische Protokollverwaltung einrichten; 5) die Datenbank neu initialisieren. Vor der Implementierung einer Lösung wird empfohlen, die Datenbank zu sichern, um den Datenverlust zu verhindern.
 Welche Schritte sind erforderlich, um CentOs in HDFs zu konfigurieren
Apr 14, 2025 pm 06:42 PM
Welche Schritte sind erforderlich, um CentOs in HDFs zu konfigurieren
Apr 14, 2025 pm 06:42 PM
Das Erstellen eines Hadoop -verteilten Dateisystems (HDFS) auf einem CentOS -System erfordert mehrere Schritte. Dieser Artikel enthält einen kurzen Konfigurationshandbuch. 1. Bereiten Sie sich auf die Installation von JDK in der frühen Stufe vor: Installieren Sie JavadevelopmentKit (JDK) auf allen Knoten, und die Version muss mit Hadoop kompatibel sein. Das Installationspaket kann von der offiziellen Oracle -Website heruntergeladen werden. Konfiguration der Umgebungsvariablen: Bearbeiten /etc /Profildatei, setzen Sie Java- und Hadoop -Umgebungsvariablen, damit das System den Installationspfad von JDK und Hadoop ermittelt. 2. Sicherheitskonfiguration: SSH-Kennwortfreie Anmeldung zum Generieren von SSH-Schlüssel: Verwenden Sie den Befehl ssh-keygen auf jedem Knoten
 Orakels Rolle in der Geschäftswelt
Apr 23, 2025 am 12:01 AM
Orakels Rolle in der Geschäftswelt
Apr 23, 2025 am 12:01 AM
Oracle ist nicht nur ein Datenbankunternehmen, sondern auch ein führender Anbieter von Cloud -Computing- und ERP -Systemen. 1. Oracle bietet umfassende Lösungen von der Datenbank bis zu Cloud -Diensten und ERP -Systemen. 2. Oraclecloud fordert AWS und Azure heraus und liefert IaaS-, PaaS- und SaaS -Dienste. 3. ERP-Systeme von Oracle wie E-Businesssuite und Fusion Applications helfen Unternehmen dabei, den Betrieb zu optimieren.
 So stoppen Sie die Oracle -Datenbank
Apr 12, 2025 am 06:12 AM
So stoppen Sie die Oracle -Datenbank
Apr 12, 2025 am 06:12 AM
Führen Sie die folgenden Schritte aus, um eine Oracle -Datenbank zu stoppen: 1. Eine Verbindung zur Datenbank herstellen; 2. Sofort herunterfahren; 3.. Herunterfahren vollständig.
 So erstellen Sie Oracle Dynamic SQL
Apr 12, 2025 am 06:06 AM
So erstellen Sie Oracle Dynamic SQL
Apr 12, 2025 am 06:06 AM
SQL -Anweisungen können basierend auf der Laufzeiteingabe erstellt und ausgeführt werden, indem die dynamische SQL von Oracle verwendet wird. Zu den Schritten gehören: Vorbereitung einer leeren Zeichenfolgenvariable zum Speichern von dynamisch generierten SQL -Anweisungen. Verwenden Sie die sofortige Ausführung oder Vorbereitung, um dynamische SQL -Anweisungen zu kompilieren und auszuführen. Verwenden Sie die Bind -Variable, um die Benutzereingabe oder andere dynamische Werte an dynamische SQL zu übergeben. Verwenden Sie sofortige Ausführung oder führen Sie aus, um dynamische SQL -Anweisungen auszuführen.
