
 Datenbank
Redis
Beherrschen Sie die Implementierung des LRU-Cache-Eliminierungsalgorithmus von Redis vollständig
Datenbank
Redis
Beherrschen Sie die Implementierung des LRU-Cache-Eliminierungsalgorithmus von Redis vollständig
Beherrschen Sie die Implementierung des LRU-Cache-Eliminierungsalgorithmus von Redis vollständig

Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis. Er stellt hauptsächlich die Implementierung des LRU-Cache-Eliminierungsalgorithmus vor, einschließlich der Implementierung des ungefähren LRU-Algorithmus von Redis, der tatsächlichen Ausführung des ungefähren LRU-Algorithmus usw. Ich hoffe, dass dies der Fall ist sei für alle hilfreich.

Empfohlenes Lernen: Redis-Lerntutorial
1 Das Implementierungsprinzip von Standard-LRU
LRU, Least Latest Used (Least Latest Used, LRU), klassischer Cache-Algorithmus.
LRU verwendet eine verknüpfte Liste, um den Zugriffsstatus aller Daten im Cache aufrechtzuerhalten, passt die Position der Daten in der verknüpften Liste basierend auf dem Echtzeitzugriff auf die Daten an und verwendet dann die Position der Daten in der verknüpften Liste, um anzugeben, ob auf die Daten kürzlich zugegriffen wurde oder nicht.
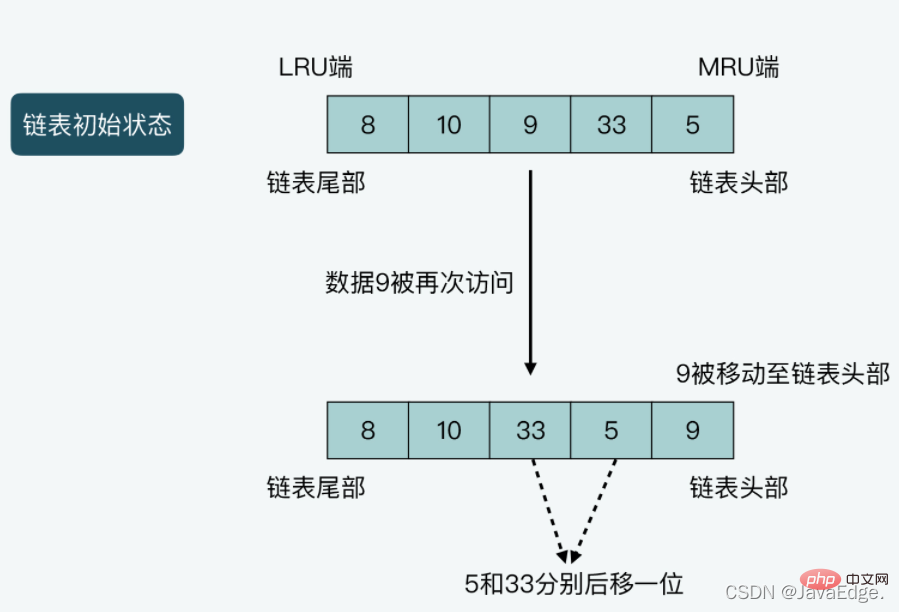
LRU setzt den Kopf und das Ende der Kette auf das MRU-Ende bzw. das LRU-Ende:
- MRU, die Abkürzung für Most Latest Used, was anzeigt, dass auf die Daten hier gerade erst zugegriffen wurde.
- LRU-Ende, die Daten hier sind die Daten, auf die am längsten nicht zugegriffen wurde Daten am Anfang der ursprünglichen verknüpften Liste und die Daten danach am Ende des Bits
case2
: Wenn auf die Daten gerade einmal zugegriffen wurde, verschiebt LRU die Daten von ihrer aktuellen Position in der verknüpften Liste an den Anfang die Kette. Verschieben Sie alle anderen Daten vom Kopf der verknüpften Liste an ihre aktuelle Position ein Bit in Richtung Ende.- Fall 3: Wenn die Länge der verknüpften Liste nicht mehr Daten aufnehmen kann und neue Daten eingefügt werden, entfernt LRU die Daten am Ende Dies entspricht auch dem Entfernen von Daten aus dem Cache.
- Abbildung von Fall 2: Die Länge der verknüpften Liste beträgt 5, und die vom Kopf bis zum Ende der verknüpften Liste gespeicherten Daten betragen 5. 33, 9, 10 und 8. Angenommen, auf Daten 9 wird einmal zugegriffen, dann wird 9 an den Anfang der verknüpften Liste verschoben, und gleichzeitig werden die Daten 5 und 33 beide um eine Position an das Ende der verknüpften Liste verschoben.
- Wenn es also streng nach LRU implementiert wird und Redis viele Daten speichert, muss es im Code implementiert werden:
 Zusätzlicher Speicherplatz zum Speichern der verknüpften Liste
Zusätzlicher Speicherplatz zum Speichern der verknüpften Liste
- Jedes Mal, wenn neue Daten eingefügt oder auf vorhandene Daten erneut zugegriffen wird, müssen mehrere verknüpfte Listenoperationen ausgeführt werden
-
Beim Zugriff auf Daten Redis wird durch den Overhead der Datenverschiebung und verknüpfter Listenoperationen beeinträchtigt
Letztendlich führt dies zu einer verringerten Redis-Zugriffsleistung. -
Ob es darum geht, Speicher zu sparen oder die hohe Leistung von Redis aufrechtzuerhalten, Redis wird nicht streng nach den Grundprinzipien von LRU implementiert, sondern
bietet eine ungefähre LRU-Algorithmus-Implementierung.
2 Implementierung des ungefähren LRU-Algorithmus in Redis
Wie ermöglicht der Speichereliminierungsmechanismus von Redis den ungefähren LRU-Algorithmus? Die folgenden Konfigurationsparameter in redis.conf:
maxmemory
, legen Sie die maximale Speicherkapazität fest, die der Redis-Server verwenden kann. Sobald der tatsächlich vom Server verwendete Speicher den Schwellenwert überschreitet, führt der Server eine Speichereliminierung entsprechend durch Betreiben Sie
- maxmemory-policy
, um die Speichereliminierungsstrategie des Redis-Servers festzulegen, einschließlich ungefährer LRU, LFU, Eliminierung nach TTL-Wert und zufälliger Eliminierung usw.
Also, Sobald die Option maxmemory festgelegt ist und maxmemory-policy als allkeys-lru oder volatile-lru konfiguriert ist, ist ungefähr LRU aktiviert. Sowohl allkeys-lru als auch volatile-lru verwenden ungefähre LRU, um Daten zu eliminieren. Der Unterschied ist:
allkeys-lru filtert die zu eliminierenden Daten in allen KV-Paaren.
volatile-lru filtert in KV-Paaren mit eingestellter TTL wird eliminiert
Wie implementiert Redis den ungefähren LRU-Algorithmus?
- Berechnung des globalen LRU-Uhrwerts
So berechnen Sie den globalen LRU-Uhrwert, um die Aktualität des Datenzugriffs zu beurteilen
-
Schlüsselwertinitialisierung und Aktualisierung des LRU-Uhrwerts
Was in der Funktion, Der LRU-Uhrwert, der jedem Schlüssel-Wert-Paar entspricht, wird initialisiert und aktualisiert. Die tatsächliche Ausführung des ungefähren LRU-Algorithmus Tatsächlicher Eliminierungsmechanismus Zur Implementierung
-
2.1 Berechnung des globalen LRU-TaktwertsDer ungefähre LRU-Algorithmus muss weiterhin die Zugriffsaktualität verschiedener Daten unterscheiden, dh Redis muss die neueste Zugriffszeit der Daten kennen. Daher zeichnet die LRU-Uhr den Zeitstempel jedes Zugriffs auf Daten auf.
Redis verwendet eine redisObject-Struktur, um den Zeiger auf V für V in jedem KV-Paar zu speichern. Zusätzlich zum Zeiger, der den Wert aufzeichnet, verwendet redisObject auch 24 Bit, um die LRU-Taktinformationen zu speichern, die der LRU-Mitgliedsvariablen entsprechen. Auf diese Weise zeichnet jedes KV-Paar den Zeitstempel seines letzten Zugriffs in der lru-Variablen auf.
redisObject-Definition enthält die Definition von LRU-Mitgliedsvariablen: -
Wie wird der LRU-Taktwert jedes KV-Paares berechnet? Redis Server verwendet eine globale LRU-Uhr auf Instanzebene, und die LRU-Zeit jedes KV-Paares wird entsprechend der globalen LRU-Uhr eingestellt.
Diese globale LRU-Uhr wird in der Mitgliedsvariablen des globalen Redis-Variablenservers gespeichert lruclock:
 Daher muss man beachten, dass wenn der Zeitabstand zwischen zwei Zugriffen auf ein Datenstück
Daher muss man beachten, dass wenn der Zeitabstand zwischen zwei Zugriffen auf ein Datenstück Die Funktion getLRUClock dividiert den von LRU_CLOCK_RESOLUTION erhaltenen UNIX-Zeitstempel, um den mit der LRU-Uhrgenauigkeit berechneten UNIX-Zeitstempel zu erhalten, der den aktuellen LRU-Uhrwert darstellt.
getLRUClock führt eine UND-Verknüpfung zwischen dem LRU-Uhrwert und der Makrodefinition LRU_CLOCK_MAX (dem Maximalwert, den die LRU-Uhr darstellen kann) durch.
Standardmäßig ist der globale LRU-Uhrwert ein UNIX-Zeitstempel, der mit einer Genauigkeit von 1 Sekunde berechnet und in initServerConfig initialisiert wird.
Wie wird der globale LRU-Uhrwert aktualisiert, wenn Redis Server ausgeführt wird? Es bezieht sich auf serverCron, das dem regelmäßig laufenden Zeitereignis von Redis Server im ereignisgesteuerten Framework entspricht.
serverCron wird als Rückruffunktion für Zeitereignisse regelmäßig ausgeführt. Sein Häufigkeitswert wird durch das
in redis.conf bestimmt. Der Standardwert ist 10, d. h. die serverCron-Funktion wird alle 100 ms ausgeführt (1s/10 = 100ms). In serverCron wird der Wert der globalen LRU-Uhr regelmäßig entsprechend der Ausführungshäufigkeit dieser Funktion durch Aufrufen von getLRUClock aktualisiert:hz-KonfigurationselementAuf diese Weise kann jedes KV-Paar den neuesten Zugriffszeitstempel von der globalen LRU-Uhr erhalten. In welchen Funktionen wird für jedes KV-Paar die entsprechende redisObject.lru initialisiert und aktualisiert?
2.2 Initialisierung und Aktualisierung des LRU-Uhrwerts des Schlüssel-Wert-Paares
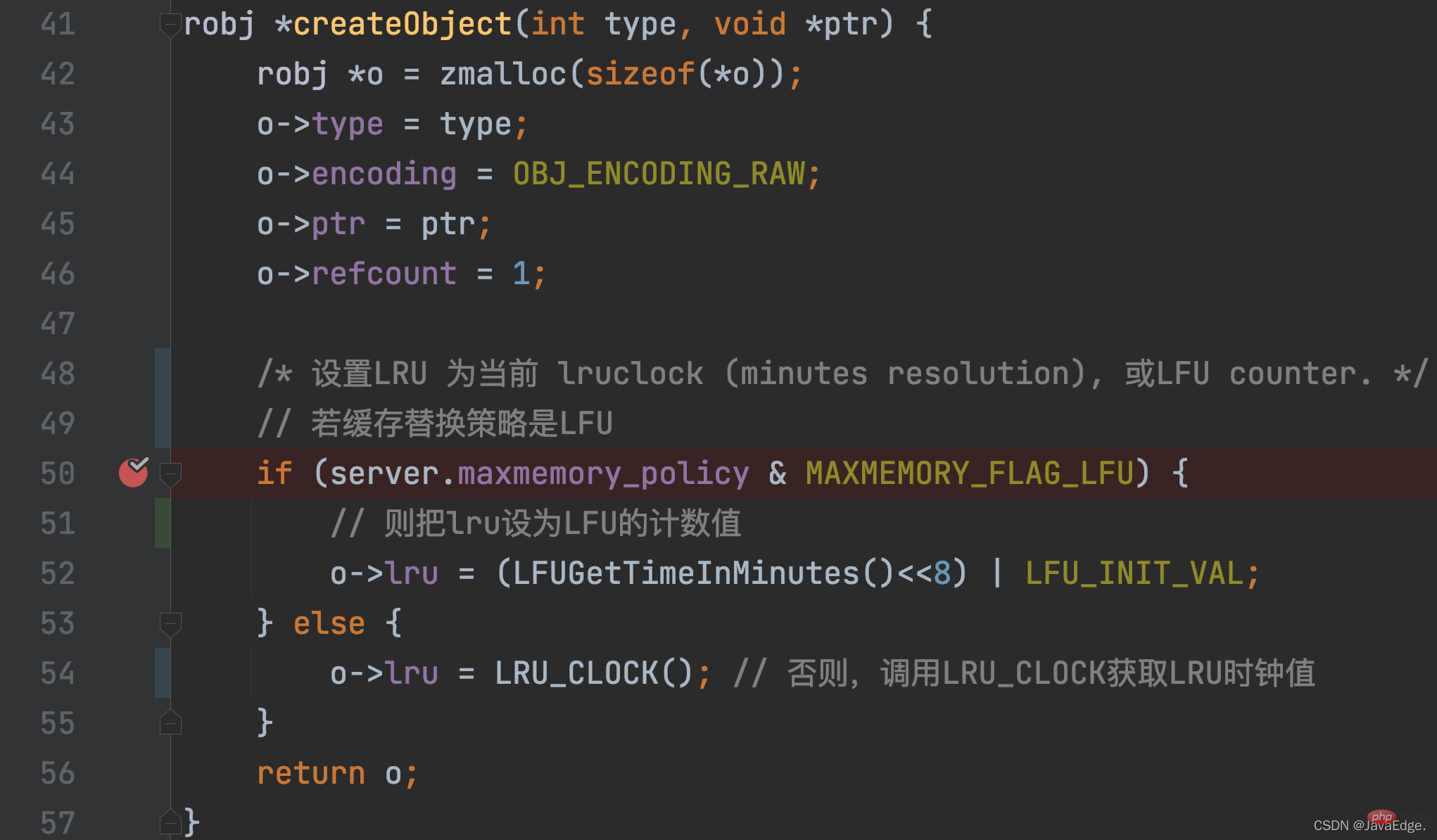
Für ein KV-Paar wird der LRU-Uhrwert zunächst festgelegt, wenn das KV-Paar erstellt wird. Dieser Initialisierungsvorgang wird in der Funktion „createObject“ aufgerufen wird aufgerufen, wenn Redis ein KV-Paar erstellen möchte. Zusätzlich zur Zuweisung von Speicherplatz für redisObject initialisiert createObject auch redisObject.lru gemäß der maxmemory_policy-Konfiguration.Wenn maxmemory_policy=LFU, wird der LRU-Variablenwert initialisiert und auf den berechneten Wert des LFU-Algorithmus
maxmemory_policy≠LFU gesetzt, dann ruft createObject LRU_CLOCK auf, um den LRU-Wert festzulegen, der dem LRU-Uhrwert entspricht KV-Paar.
LRU_CLOCK gibt den aktuellen globalen LRU-Uhrwert zurück. Denn sobald ein KV-Paar erstellt wurde, entspricht es einem Zugriff und sein entsprechender LRU-Uhrwert stellt seinen Zugriffszeitstempel dar:- Wann wird der LRU-Uhrwert dieses KV-Paares erneut aktualisiert?
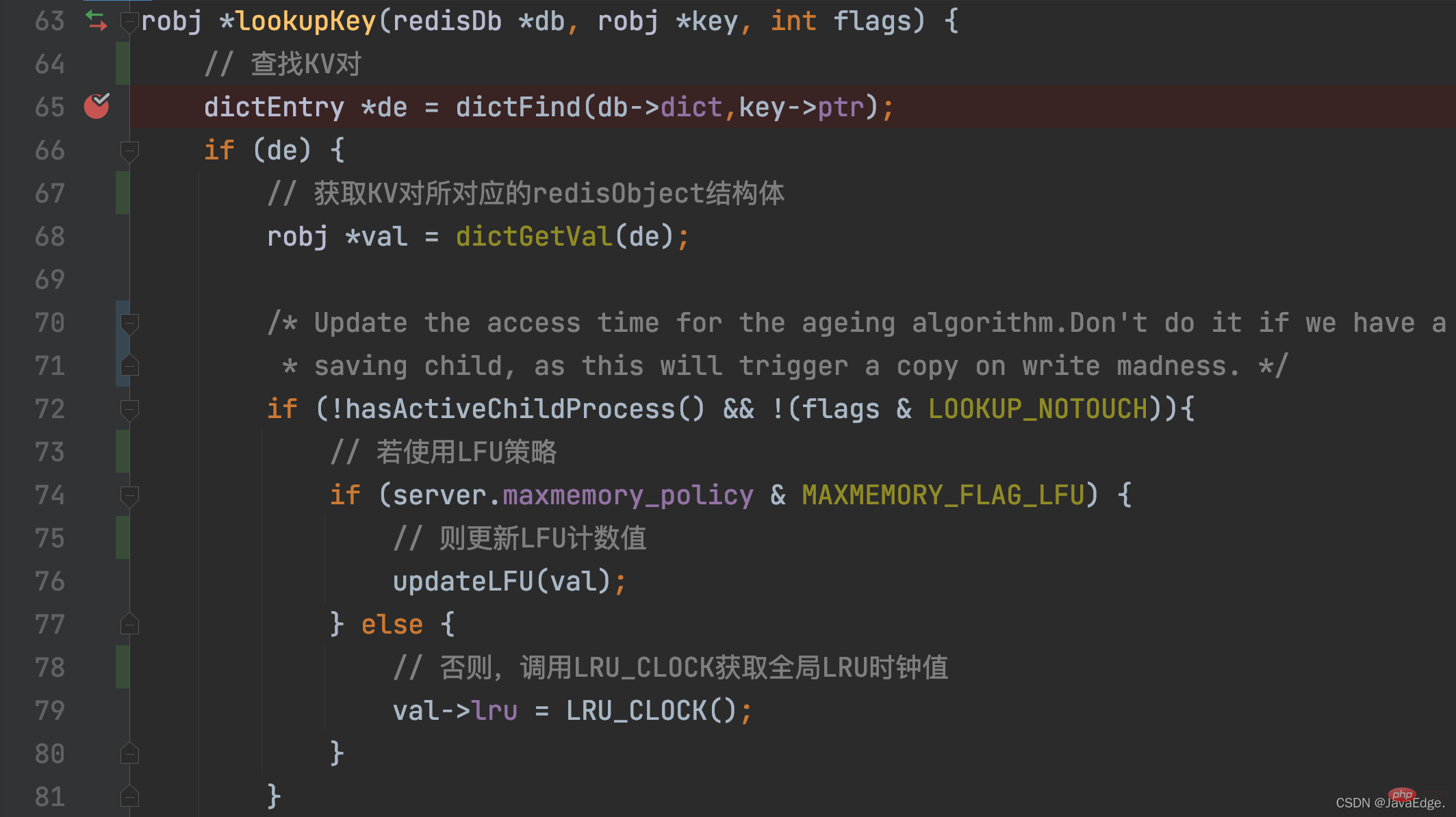
- Solange auf ein KV-Paar zugegriffen wird, wird sein LRU-Uhrwert aktualisiert! Wenn auf ein KV-Paar zugegriffen wird, ruft der Zugriffsvorgang schließlich „lookupKey“ auf.
lookupKey sucht in der globalen Hash-Tabelle nach dem KV-Paar, auf das zugegriffen werden soll. Wenn das KV-Paar vorhanden ist, aktualisiert lookupKey den LRU-Uhrwert des Schlüssel-Wert-Paares, der dessen Zugriffszeitstempel ist, basierend auf dem Konfigurationswert von maxmemory_policy.
Wenn maxmemory_policy nicht als LFU-Richtlinie konfiguriert ist, ruft die Funktion „lookupKey“ die Funktion „LRU_CLOCK“ auf, um den aktuellen globalen LRU-Uhrwert abzurufen und ihn der LRU-Variablen in der redisObject-Struktur des Schlüssel-Wert-Paares zuzuweisen.
In Auf diese Weise kann jedes KV-Paar nach dem Zugriff den neuesten Zugriffszeitstempel erhalten. Aber Sie sind vielleicht neugierig: Wie werden diese Zugriffszeitstempel letztendlich verwendet, um den LRU-Algorithmus zur Dateneliminierung anzunähern? 2.3 Tatsächliche Ausführung des ungefähren LRU-Algorithmus
Der Grund, warum Redis ungefähres LRU implementiert, besteht darin, den Overhead an Speicherressourcen und Betriebszeit zu reduzieren.
2.3.1 Wann wird die Algorithmusausführung ausgelöst?
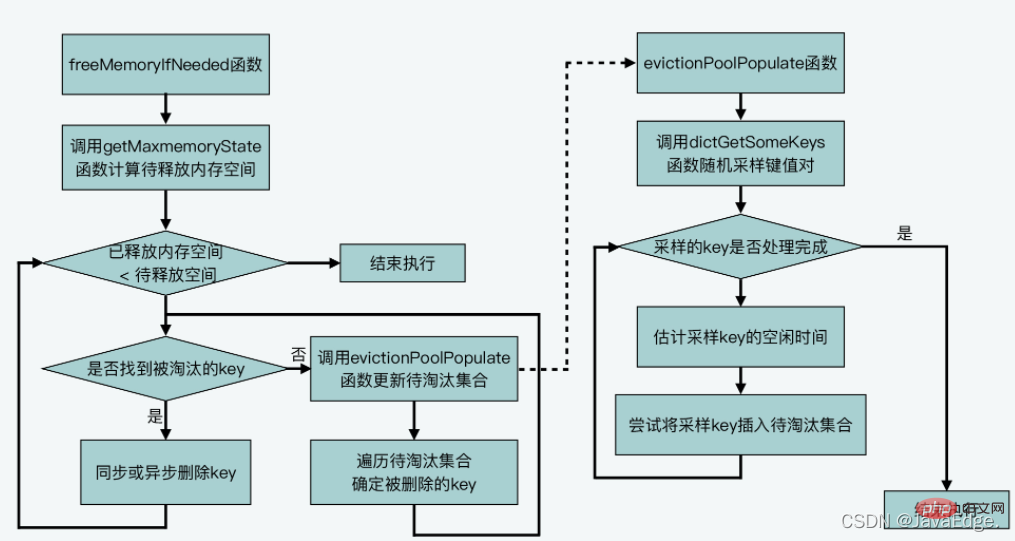
Die Hauptlogik der ungefähren LRU liegt in performEvictions. performEvictions wird von evictionTimeProc aufgerufen, und die Funktion evictionTimeProc wird von ProcessCommand aufgerufen. processCommand, Redis ruft bei der Verarbeitung jedes Befehls auf:Dann beurteilt isSafeToPerformEvictions erneut, ob performEvictions weiterhin ausgeführt werden soll, basierend auf den folgenden Bedingungen:
Sobald performEvictions aufgerufen wird und maxmemory-policy auf allkeys-lru oder volatile-lru gesetzt ist, wird die ungefähre LRU-Ausführung ausgelöst.
2.3.2 Ungefährer LRU-spezifischer Ausführungsprozess
Die Ausführung kann in die folgenden Schritte unterteilt werden:
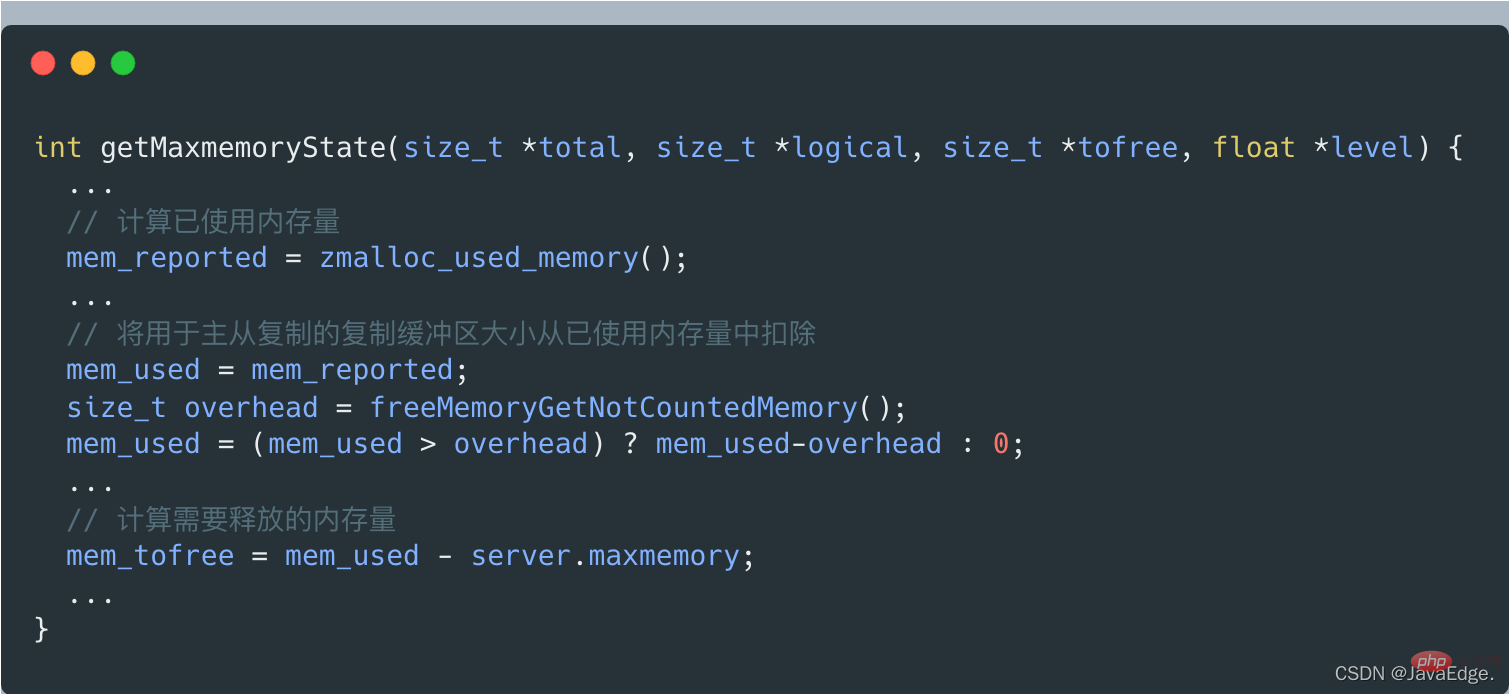
2.3.2.1 Bestimmen Sie die aktuelle Speichernutzung Der aktuelle Redis-Server verwendet Speicherkapazität. Der Konfigurationswert „maxmemory“ wurde überschritten.
Wenn maxmemory nicht überschritten wird
, wird C_OK zurückgegeben und performEvictions wird ebenfalls direkt zurückgegeben.Wenn getMaxmemoryState die aktuelle Speichernutzung auswertet und feststellt, dass der verwendete Speicher maxmemory überschreitet, berechnet es die Menge an Speicher, die freigegeben werden muss. Die Größe dieses freigegebenen Speichers = die Menge des verwendeten Speichers – maxmemory.
Aber die Menge des verwendeten Speichers beinhaltet nicht die für die Master-Slave-Replikation verwendete Kopierpuffergröße, die von getMaxmemoryState durch Aufruf von freeMemoryGetNotCountedMemory berechnet wird.
, führt performEvictions eine While-Schleife aus, um Daten zu löschen und Speicher freizugeben.Wenn die aktuell vom Server genutzte Speichermenge die Obergrenze von maxmemory überschreitetFür Eliminierungsdaten definiert Redis das Array EvictionPoolLRU, um die zu eliminierenden Kandidaten-KV-Paare zu speichern. Der Elementtyp ist die Struktur evictionPoolEntry, die die Leerlaufzeit, das entsprechende K und andere Informationen der zu eliminierenden KV-Paare speichert:
Wenn Redis Server zur Initialisierung initSever ausführt, ruft er evictionPoolAlloc auf, um Speicherplatz für das EvictionPoolLRU-Array zuzuweisen. Standardmäßig können 16 Kandidaten gespeichert werden KV-Paare scheiden aus.
PerformEvictions aktualisiert den Satz der zu eliminierenden Kandidaten-KV-Paare, das EvictionPoolLRU-Array, während des zyklischen Prozesses der Dateneliminierung.2.3.2.2 Aktualisieren Sie den Satz der zu eliminierenden Kandidaten-KV-Paare.
performEvictions ruft evictionPoolPopulate auf, das zunächst dictGetSomeKeys aufruft, um zufällig eine bestimmte Zahl K aus der abzutastenden Hash-Tabelle abzurufen:
dictGetSomeKeys abgetastete Hash-Tabelle , durch Das Konfigurationselement maxmemory_policy bestimmt:
- Wenn maxmemory_policy = allkeys_lru, ist die abzutastende Hash-Tabelle die globale Hash-Tabelle von Redis Server, das heißt, sie wird in allen KV-Paaren abgetastet
- Andernfalls die abzutastende Hash-Tabelle wird mit der TTL-Set-K-Hash-Tabelle gespeichert.
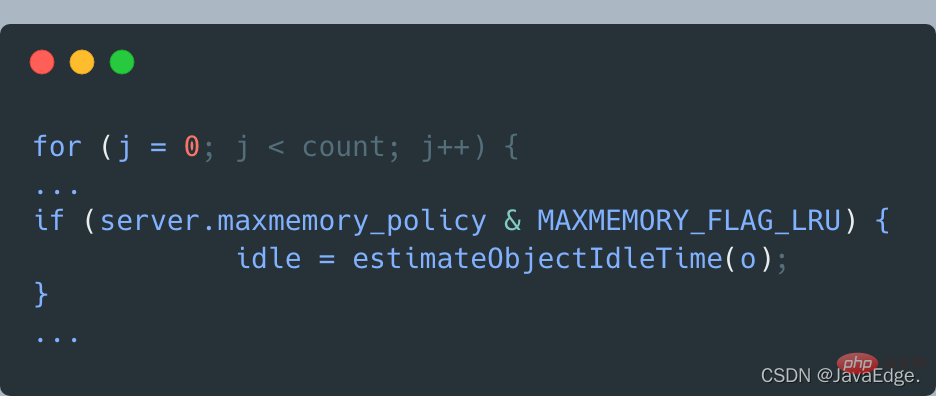
Die Anzahl der von dictGetSomeKeys abgetasteten K wird durch das Konfigurationselement „maxmemory-samples“ bestimmt. Der Standardwert ist 5: Daher gibt dictGetSomeKeys den abgetasteten KV-Paarsatz zurück. evictionPoolPopulate führt eine Schleife basierend auf der tatsächlichen Anzahl der abgetasteten KV-Paare aus: Rufen Sie estimateObjectIdleTime auf, um die Leerlaufzeit jedes KV-Paars im Stichprobensatz zu berechnen:
Dann durchläuft evictionPoolPopulate den Satz der zu eliminierenden Kandidaten-KV-Paare. Das heißt, das EvictionPoolLRU-Array. Versuchen Sie, jedes abgetastete KV-Paar in das EvictionPoolLRU-Array einzufügen, abhängig von einer der folgenden Bedingungen:
kann einen leeren Steckplatz im Array finden, in den noch kein KV-Paar eingefügt wurde
- kann finden ein KV-Paar im Array mit Leerlaufzeit
Als nächstes beginnt performEvictions mit der Auswahl des KV-Paares, das schließlich eliminiert wird. - 2.3.2.3 Wählen Sie das eliminierte KV-Paar aus und löschen Sie es
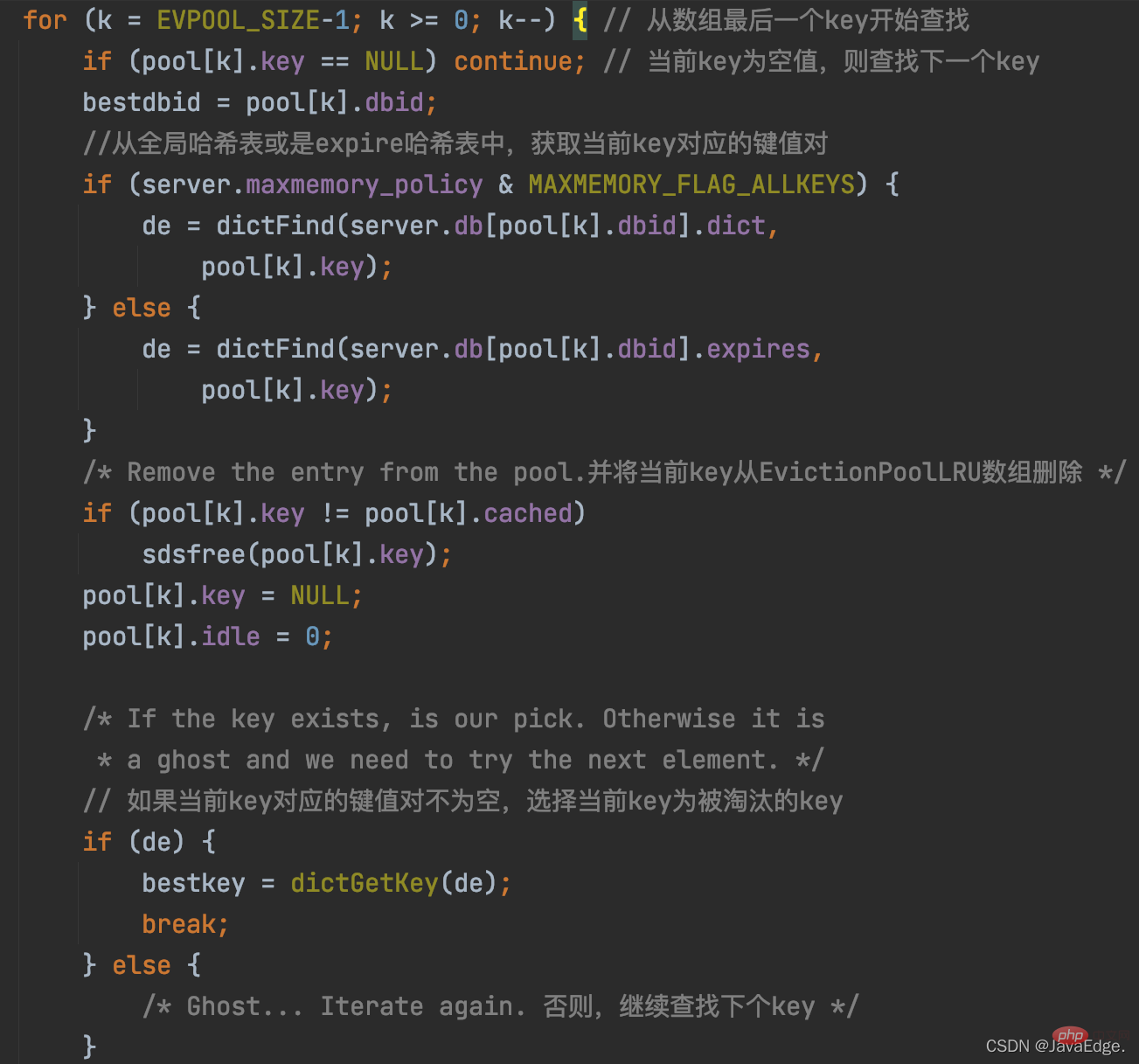
Weil evictionPoolPopulate das EvictionPoolLRU-Array aktualisiert hat und die Ks im Array in der Leerlaufzeit von klein nach groß sortiert werden. Daher durchläuft performEvictions das EvictionPoolLRU-Array einmal und beginnt mit der Auswahl ab dem letzten K im Array. Wenn das ausgewählte K nicht leer ist, wird es als letztes K verwendet, das eliminiert wird.
Die Ausführungslogik dieses Prozesses:
Sobald das eliminierte K ausgewählt ist, führt performEvictions ein synchrones oder asynchrones Löschen gemäß der Lazy-Deletion-Konfiguration des Redis-Servers durch:
An diesem Punkt führt performEvictions aus hat einen K eliminiert. Wenn der zu diesem Zeitpunkt freigegebene Speicherplatz nicht ausreicht, d Der freizugebende Platz ist erfüllt. Evictions-Prozess durchführen:Der ungefähre LRU-Algorithmus verwendet keine zeitaufwändige und platzraubende verknüpfte Liste, sondern einen zu eliminierenden Datensatz mit fester Größe und wählt zufällig einige K aus, die dem Datensatz hinzugefügt werden sollen jedes Mal eliminiert. Löschen Sie schließlich entsprechend der Länge der Leerlaufzeit von K in der zu eliminierenden Menge das K mit der längsten Leerlaufzeit.
Zusammenfassung
Gemäß den Grundprinzipien des LRU-Algorithmus wurde festgestellt, dass das entwickelte System zusätzlichen Speicherplatz zum Speichern der LRU-verknüpften Liste und des Systems benötigt, wenn der LRU-Algorithmus streng nach den Grundprinzipien implementiert wird Der Vorgang wird auch durch den Overhead der LRU-Linked-List-Operationen beeinträchtigt.
Die Speicherressourcen und die Leistung von Redis sind beide wichtig, daher implementiert Redis den ungefähren LRU-Algorithmus:
Stellen Sie zunächst die- globale LRU-Uhr
- ein und erhalten Sie den globalen LRU-Uhrwert als Zugriffszeitstempel, wenn das KV-Paar vorhanden ist erstellt und erhält bei jedem Zugriff den globalen LRU-Uhrwert und aktualisiert den Zugriffszeitstempel Wenn Redis dann einen Befehl verarbeitet, wird performEvictions aufgerufen, um zu bestimmen, ob Speicher freigegeben werden muss. Wenn der verwendete Speicher den maximalen Speicher überschreitet, wählen Sie zufällig einige KV-Paare aus, um einen zu eliminierenden Kandidatensatz zu bilden, und wählen Sie die ältesten Daten zur Eliminierung basierend auf ihren Zugriffszeitstempeln aus
- Das Grundprinzip eines Algorithmus und die tatsächliche Ausführung des Algorithmus sind im System Während der Entwicklung wird es bestimmte Kompromisse geben, und die Ressourcen- und Leistungsanforderungen des entwickelten Systems müssen umfassend berücksichtigt werden, um einen Ressourcen- und Leistungsaufwand zu vermeiden, der durch die strikte Implementierung des Algorithmus verursacht wird.
Empfohlenes Lernen:
Redis-Tutorial
 Daher muss man beachten, dass wenn der Zeitabstand zwischen zwei Zugriffen auf ein Datenstück
Daher muss man beachten, dass wenn der Zeitabstand zwischen zwei Zugriffen auf ein Datenstück 
 hz-Konfigurationselement
hz-Konfigurationselement

 Wenn die aktuell vom Server genutzte Speichermenge die Obergrenze von maxmemory überschreitet
Wenn die aktuell vom Server genutzte Speichermenge die Obergrenze von maxmemory überschreitet

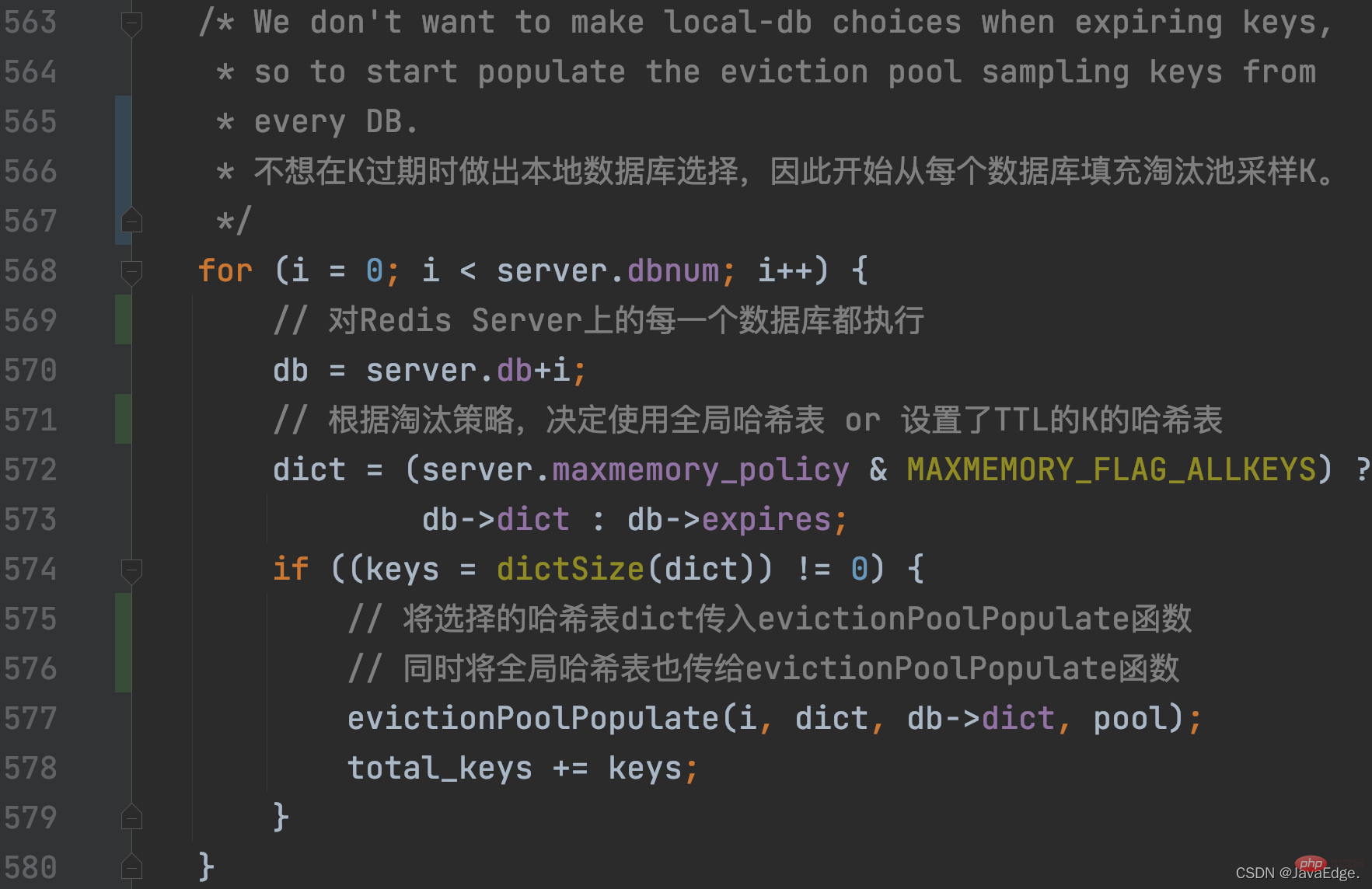 Die Anzahl der von dictGetSomeKeys abgetasteten K wird durch das Konfigurationselement „maxmemory-samples“ bestimmt. Der Standardwert ist 5:
Die Anzahl der von dictGetSomeKeys abgetasteten K wird durch das Konfigurationselement „maxmemory-samples“ bestimmt. Der Standardwert ist 5: 
Das obige ist der detaillierte Inhalt vonBeherrschen Sie die Implementierung des LRU-Cache-Eliminierungsalgorithmus von Redis vollständig. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1387
1387
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So lösen Sie Datenverlust mit Redis
Apr 10, 2025 pm 08:24 PM
So lösen Sie Datenverlust mit Redis
Apr 10, 2025 pm 08:24 PM
Zu den Ursachen für Datenverluste gehören Speicherausfälle, Stromausfälle, menschliche Fehler und Hardwarefehler. Die Lösungen sind: 1. Speichern Sie Daten auf Festplatten mit RDB oder AOF Persistenz; 2. Kopieren Sie auf mehrere Server, um eine hohe Verfügbarkeit zu erhalten. 3. Ha mit Redis Sentinel oder Redis Cluster; 4. Erstellen Sie Schnappschüsse, um Daten zu sichern. 5. Implementieren Sie Best Practices wie Persistenz, Replikation, Schnappschüsse, Überwachung und Sicherheitsmaßnahmen.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
