
 Datenbank
MySQL-Tutorial
Sammlung von Fragen und Antworten zu MySQL-Interviews (Zusammenfassung)
Datenbank
MySQL-Tutorial
Sammlung von Fragen und Antworten zu MySQL-Interviews (Zusammenfassung)
Sammlung von Fragen und Antworten zu MySQL-Interviews (Zusammenfassung)

Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL. Er stellt hauptsächlich einige häufig gestellte Fragen in Interviews zusammen, darunter Datenbankarchitektur, Indizierung und SQL-Optimierung usw. Ich hoffe, dass er für alle hilfreich ist.

Empfohlenes Lernen: MySQL-Tutorial
1. Sprechen Sie über das Infrastrukturdiagramm von MySQL
Erzählen Sie dem Interviewer von der logischen Architektur von MySQL. Wenn Sie ein Whiteboard haben, können Sie zeichnen Das folgende Bild stammt aus dem Internet.
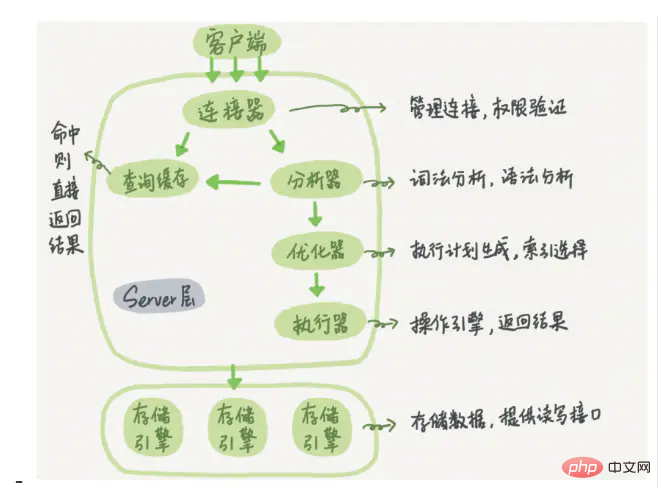 Das logische Architekturdiagramm von MySQL ist hauptsächlich in drei Schichten unterteilt:
Das logische Architekturdiagramm von MySQL ist hauptsächlich in drei Schichten unterteilt:
(1) Die erste Schicht ist für die Verbindungsverarbeitung, Autorisierungsauthentifizierung, Sicherheit usw. verantwortlich.
(2) Die zweite Schicht ist für das Kompilieren und verantwortlich Optimierung von SQL
(3) Die dritte Schicht ist die Speicher-Engine.
1.2. Wie wird eine SQL-Abfrageanweisung in MySQL ausgeführt?
- Überprüfen Sie zunächst, ob die Anweisung
是否有权限,如果没有权限,直接返回错误信息,如果有权限会先查询缓存(MySQL8.0 版本以前)。如果没有缓存,分析器进行
词法分析,提取 sql 语句中 select 等关键元素,然后判断 sql 语句是否有语法错误,比如关键词是否正确等等。-
最后优化器确定执行方案进行权限校验,如果没有权限就直接返回错误信息,如果有权限就会
Wenn kein Cache vorhanden ist, führt der Analysator eine调用数据库引擎接口lexikalische Analysedurch, extrahiert Schlüsselelemente wie „select“ in der SQL-Anweisung und bestimmt dann, ob die SQL-Anweisung grammatikalische Fehler aufweist, z. B. ob die Schlüsselwörter sind richtig usw.
eine Berechtigung hat. Wenn keine Berechtigung vorliegt, wird direkt eine Fehlermeldung zurückgegeben. Wenn eine Berechtigung vorliegt, wird zuerst der Cache abgefragt (vor MySQL8.0-Version). ). 2.1 Wie optimiert man SQL in der täglichen Arbeit?
Sie können diese Frage anhand dieser Dimensionen beantworten: 2.1.1,Tabellenstruktur optimieren
(1) Versuchen Sie, numerische Felder zu verwenden. Wenn Felder, die nur numerische Informationen enthalten, versuchen Sie, sie nicht als Zeichentypen zu entwerfen. Es reduziert die Abfrage- und Join-Leistung und erhöht den Speicheraufwand. Dies liegt daran, dass die Engine bei der Verarbeitung von Abfragen und Verbindungen jedes Zeichen in der Zeichenfolge einzeln vergleicht und für numerische Typen nur ein Vergleich ausreicht. (2) Verwenden Sie so oft wie möglich varchar anstelle von charFelder mit variabler Länge haben wenig Speicherplatz und können Speicherplatz sparen.(3) Wenn die Indexspalte eine große Menge doppelter Daten enthält, kann der Index gelöscht werden. Wenn es beispielsweise eine Spalte für das Geschlecht gibt, die fast nur männlich, weiblich und unbekannt ist, ist ein solcher Index ungültig.
2.1.2,- Abfragen optimieren
- Sie sollten versuchen, die Verwendung von !=- oder -Operatoren in where-Klauseln zu vermeiden.
- Sie sollten versuchen, die Verwendung von or in where-Klauseln zum Verbinden von Bedingungen zu vermeiden Verwenden Sie select * in keiner Abfrage. Vermeiden Sie es, zu viele Indizes zu erstellen, und verwenden Sie kombinierte Indizes. 2.2 So lesen Sie den Ausführungsplan (erklären) und wie versteht man die Bedeutung der einzelnen Felder?
- Fügen Sie das Schlüsselwort „explain“ vor der select-Anweisung hinzu, um Informationen zum Ausführungsplan zurückzugeben.
(1) ID-Spalte: Dies ist die Seriennummer der Select-Anweisung. MySQL unterteilt Select-Abfragen in einfache Abfragen und komplexe Abfragen. (2) Spalte „select_type“: Gibt an, ob die entsprechende Zeile eine einfache oder komplexe Abfrage ist.
- (3) Tabellenspalte: Gibt an, auf welche Tabelle eine Zeile von EXPLAIN zugreift.
(4) Typspalte: eine der wichtigsten Spalten. Stellt die Art der Zuordnung oder den Zugriffstyp dar, mit dem MySQL bestimmt, wie Zeilen in der Tabelle gefunden werden. Vom besten zum schlechtesten: System > ref_or_null > index_subquery > Die Abfrage könnte zum Suchen verwendet werden.
(6) Schlüsselspalte: Diese Spalte zeigt, welchen Index MySQL tatsächlich verwendet, um den Zugriff auf die Tabelle zu optimieren. (7) Spalte „key_len“: Zeigt die Anzahl der von MySQL im Index verwendeten Bytes an. Mit diesem Wert kann berechnet werden, welche Spalten im Index verwendet werden.
(8) ref-Spalte: Diese Spalte zeigt die Spalten oder Konstanten an, die von der Tabelle zum Nachschlagen von Werten im Index des Schlüsselspaltendatensatzes verwendet werden: const (Konstante), func, NULL und Feldnamen .
(9) Zeilenspalte: Diese Spalte gibt die Anzahl der Zeilen an, die MySQL voraussichtlich lesen und erkennen soll. Beachten Sie, dass dies nicht die Anzahl der Zeilen im Ergebnissatz ist.
(10) Zusätzliche Spalte: Zusätzliche Informationen anzeigen. Es gibt zum Beispiel „Index verwenden“, „Wo verwenden“, „Temporär verwenden“ usw.
2.3. Haben Sie sich jemals Gedanken über das zeitaufwändige SQL im Geschäftssystem gemacht? Ist die Abfragestatistik zu langsam? Wie haben Sie langsame Abfragen optimiert?
Wenn wir normalerweise SQL schreiben, müssen wir uns angewöhnen, Erklärungsanalysen zu verwenden. Statistiken über langsame Abfragen, Betrieb und Wartung liefern uns regelmäßige Statistiken.
Optimierung langsamer Abfrageideen:
Analysieren Sie die Anweisung, ob unnötige Felder/Daten geladen werden.
-
Analysieren Sie den SQL-Ausführungssatz, ob er den Index erreicht usw.
Wenn die SQL sehr komplex ist, optimieren Sie die SQL-Struktur
Wenn die Menge der Tabellendaten zu groß ist, berücksichtigen Sie Untertabellen
3. Der Unterschied zwischen Clustered-Indizes und Nicht-Clustered-Indizes
können in die folgenden vier Tabellen unterteilt werden. Antwort aus mehreren Dimensionen:
(1) Eine Tabelle kann nur einen Clustered-Index haben, während eine Tabelle mehrere Nicht-Clustered-Indizes haben kann.
(2) Clustered-Index, die logische Reihenfolge der Schlüsselwerte im Index bestimmt die physische Reihenfolge der entsprechenden Zeilen in der Tabelle, die logische Reihenfolge des Index im Index unterscheidet sich von der physische Speicherreihenfolge der Zeilen auf der Festplatte.
(3) Der Index wird durch die Datenstruktur eines Binärbaums beschrieben. Wir können den Clustered-Index folgendermaßen verstehen: Die Blattknoten des Index sind die Datenknoten. Die Blattknoten von nicht gruppierten Indizes sind immer noch Indexknoten, verfügen jedoch über einen Zeiger, der auf den entsprechenden Datenblock zeigt.
(4) Clustered-Index: Physischer Speicher wird nach Index sortiert; Nicht-Cluster-Index: Physischer Speicher wird nicht nach Index sortiert
3.2 Warum B+-Baum verwenden?
Sie können dieses Problem aus mehreren Dimensionen betrachten: ob die Abfrage schnell genug ist, ob die Effizienz stabil ist, wie viele Daten gespeichert werden und wie viele Festplattensuchen es gibt. Warum ist es kein gewöhnlicher Binärbaum? Kein ausgeglichener Binärbaum, warum ist es kein B-Baum, sondern ein B+-Baum?
3.2.1. Warum nicht ein gewöhnlicher Binärbaum?
Wenn der Binärbaum auf eine verknüpfte Liste spezialisiert ist, entspricht dies einem vollständigen Tabellenscan. Im Vergleich zu binären Suchbäumen weisen ausgeglichene Binärbäume eine stabilere Sucheffizienz und eine schnellere Gesamtsuchgeschwindigkeit auf.
3.2.2. Warum nicht ein ausgeglichener Binärbaum?
Wir wissen, dass die Abfrage von Daten im Speicher viel schneller ist als auf der Festplatte. Wenn eine Datenstruktur wie ein Baum als Index verwendet wird, müssen wir jedes Mal, wenn wir nach Daten suchen, einen Knoten von der Festplatte lesen, was wir als Festplattenblock bezeichnen, aber ein ausgeglichener Binärbaum speichert nur einen Schlüsselwert und Daten pro Knoten. Wenn es sich um einen B-Baum handelt, können mehr Knotendaten gespeichert werden, und die Höhe des Baums wird ebenfalls reduziert, sodass die Anzahl der Festplattenlesevorgänge verringert wird und die Abfrageeffizienz schneller wird.
3.2.3. Warum nicht B-Baum, sondern B+-Baum?
B+-Baum speichert keine Daten auf Nicht-Blattknoten, sondern nur Schlüsselwerte, während B-Baumknoten nicht nur Schlüsselwerte, sondern auch Daten speichern. Die Standardgröße einer Seite in innodb beträgt 16 KB. Wenn keine Daten gespeichert werden, werden mehr Schlüsselwerte gespeichert, und die Reihenfolge des entsprechenden Baums (des untergeordneten Knotenbaums des Knotens) wird größer kürzer und dicker Auf diese Weise wird die Anzahl der Festplatten-E/A-Zeiten, die wir für die Suche nach Daten benötigen, erneut reduziert und die Effizienz der Datenabfrage wird schneller.
B+ Alle Daten im Baumindex werden in Blattknoten gespeichert, und die Daten werden der Reihe nach angeordnet und mit der verknüpften Liste verknüpft. Dann macht B+ Tree die Bereichssuche, Sortiersuche, Gruppensuche und Deduplizierungssuche extrem einfach.
3.3. Was ist der Unterschied zwischen Hash-Index und B+-Baum-Index? Wie haben Sie sich für die Gestaltung des Index entschieden?
- B+-Baum kann Bereichsabfragen durchführen, Hash-Index nicht.
- Der B+-Baum unterstützt das Prinzip des gemeinsamen Index ganz links, der Hash-Index unterstützt es nicht.
- B+-Baum unterstützt die Reihenfolge durch Sortieren, der Hash-Index unterstützt dies jedoch nicht.
- Der Hash-Index ist bei entsprechenden Abfragen effizienter als der B+-Baum.
- B+-Baum Wenn Like für Fuzzy-Abfragen verwendet wird, können die Wörter nach Like (z. B. beginnend mit %) eine Optimierungsrolle spielen und der Hash-Index kann überhaupt keine Fuzzy-Abfrage durchführen.
- 3.4. Was ist das Prinzip des Präfixes ganz links? Was ist das Leftmost-Matching-Prinzip?
Das Präfixprinzip ganz links bedeutet, dass bei der Erstellung eines mehrspaltigen Index die am häufigsten verwendete Spalte in der Where-Klausel ganz links platziert werden soll.
Wenn wir einen kombinierten Index wie (a1, a2, a3) erstellen, entspricht dies der Erstellung von drei Indizes (a1), (a1, a2) und (a1, a2, a3), die am weitesten links übereinstimmen Prinzip.
3.5. Welche Szenarien sind nicht für die Indizierung geeignet?
- Dinge mit kleinen Datenmengen sind nicht für die Indizierung geeignet
- Felder mit häufigen Aktualisierungen sind nicht für die Indizierung geeignet = Felder mit geringer Differenzierung sind nicht für die Indizierung geeignet (z. B. Geschlecht)
- 3.6 Was sind die Vor- und Nachteile der Indexierung?
(1) Vorteile:
- Einzigartiger Index kann die Eindeutigkeit jeder Datenzeile in der Datenbanktabelle sicherstellen
- Der Index kann die Datenabfrage beschleunigen und die Abfragezeit verkürzen
- (2) Nachteil:
- Das Erstellen und Verwalten von Indizes nimmt Zeit in Anspruch.
- Indizes müssen zusätzlich zum von der Datentabelle belegten Datenspeicherplatz auch eine bestimmte Menge an physischem Speicherplatz belegen Daten in der Tabelle Beim Löschen oder Ändern muss der Index auch dynamisch gepflegt werden.
- 4. Sperren
4.1 Sind Sie jemals auf ein Deadlock-Problem in MySQL gestoßen?
Ich bin darauf gestoßen. Meine allgemeinen Schritte zur Fehlerbehebung bei Deadlocks lauten wie folgt:
(1) Überprüfen Sie das Deadlock-Protokoll und zeigen Sie den Innodb-Status der Engine an.
(2) Finden Sie den Deadlock-Sql heraus.
(3) Analysieren Sie die SQL-Sperrsituation Sperrprotokoll
(6) Analyse der Deadlock-Ergebnisse
4.2. Was sind optimistische Sperren und pessimistische Sperren in der Datenbank und ihre Unterschiede?
(1) Pessimistische Sperre:
Pessimistische Sperre ist zielstrebig und unsicher. Ihr Herz gehört nur der aktuellen Transaktion und sie ist immer besorgt, dass ihre geliebten Daten durch andere Transaktionen geändert werden könnten, sodass eine Transaktion nach dem Besitz von ( Durch die Erlangung einer pessimistischen Sperre kann keine andere Transaktion die Daten ändern und kann nur warten, bis die Sperre aufgehoben wird, bevor sie ausgeführt wird.
(2) Optimistische Sperre:
Der „Optimismus“ der optimistischen Sperre spiegelt sich in der Tatsache wider, dass davon ausgegangen wird, dass sich die Daten nicht zu häufig ändern. Daher ist es möglich, dass mehrere Transaktionen gleichzeitig Änderungen an den Daten vornehmen.
Implementierungsmethode: Optimistisches Sperren wird im Allgemeinen mithilfe des Versionsnummernmechanismus oder des CAS-Algorithmus implementiert.
4.3. Kennen Sie MVCC und kennen die zugrunde liegenden Prinzipien?
MVCC (Multiversion Concurrency Control), eine Technologie zur Steuerung der Parallelität mehrerer Versionen.
Die Implementierung von MVCC in MySQL InnoDB dient hauptsächlich dazu, die Leistung der Datenbank-Parallelität zu verbessern und eine bessere Methode zur Behandlung von Lese-Schreib-Konflikten zu verwenden, sodass selbst bei Lese-Schreib-Konflikten kein sperrendes und nicht blockierendes gleichzeitiges Lesen erreicht werden kann . 5. Transaktionen 5.1 Die vier Hauptmerkmale und Implementierungsprinzipien von MySQL-Transaktionen
Konsistenz: bedeutet, dass die Daten vor Beginn und nach Ende der Transaktion nicht zerstört werden. Wenn Konto A 10 Yuan auf Konto B überweist, bleibt der Gesamtbetrag von A und B unabhängig von Erfolg oder Misserfolg unverändert.
Isolation: Wenn mehrere Transaktionen gleichzeitig zugreifen, sind die Transaktionen voneinander isoliert, das heißt, eine Transaktion hat keinen Einfluss auf die laufenden Auswirkungen anderer Transaktionen. Kurz gesagt bedeutet dies, dass es keinen Konflikt zwischen Angelegenheiten gibt.
Persistenz: Gibt an, dass nach Abschluss der Transaktion die durch die Transaktion an der Datenbank vorgenommenen betrieblichen Änderungen dauerhaft in der Datenbank gespeichert werden.
5.2. Was sind die Isolationsstufen von Transaktionen? Was ist die Standardisolationsstufe von MySQL?
... 3. Was sind Phantom Reads, Dirty Reads und Non? -wiederholbare Lesevorgänge? Transaktionen A und B werden abwechselnd ausgeführt. Transaktion A wird durch Transaktion B gestört, da Transaktion A nicht festgeschriebene Daten von Transaktion B liest. Dies ist ein Dirty Read.
Im Rahmen einer Transaktion lesen zwei identische Abfragen denselben Datensatz, geben jedoch unterschiedliche Daten zurück. Dies ist ein nicht wiederholbarer Lesevorgang. Transaktion A fragt die Ergebnismenge eines Bereichs ab, und eine andere gleichzeitige Transaktion B fügt Daten in diesen Bereich ein bzw. löscht sie und schreibt sie stillschweigend fest. Anschließend fragt Transaktion A denselben Bereich erneut ab, und die durch die beiden Lesevorgänge erhaltenen Ergebnismengen sind unterschiedlich. Das Gleiche gilt für Phantomlesung.
6. Praktischer Kampf
6.1 Wenn die CPU der MySQL-Datenbank überlastet ist, wie geht man damit um?
- Fehlerbehebungsprozess:
(1) Verwenden Sie den oberen Befehl, um zu beobachten und festzustellen, ob die Ursache auf MySQL oder andere Gründe zurückzuführen ist.
(2) Wenn es durch mysqld verursacht wird, zeigen Sie die Prozessliste an, überprüfen Sie den Sitzungsstatus und stellen Sie fest, ob ressourcenintensives SQL ausgeführt wird. (3) Finden Sie die SQL mit hohem Verbrauch heraus und prüfen Sie, ob der Ausführungsplan korrekt ist, ob der Index fehlt und ob die Datenmenge zu groß ist.
Verarbeitung:(1) Beenden Sie diese Threads (und beobachten Sie, ob die CPU-Auslastung abnimmt)
(2) Nehmen Sie entsprechende Anpassungen vor (z. B. Hinzufügen von Indizes, Ändern von SQL, Ändern von Speicherparametern)(3) Neustart Führen Sie diese aus SQLs.
Andere Situationen:
Es ist auch möglich, dass jede SQL-Anweisung nicht viele Ressourcen verbraucht, aber plötzlich eine große Anzahl von Sitzungsverbindungen eingeht, was zu einem CPU-Anstieg führt. In diesem Fall müssen Sie mit der Anwendung arbeiten Um zu analysieren, warum die Anzahl der Verbindungen ansteigt, nehmen Sie dann entsprechende Anpassungen vor, z. B. die Begrenzung der Anzahl der Verbindungen usw.
6.2 Wie lösen Sie die Master-Slave-Verzögerung von MYSQL?
Die Master-Slave-Replikation erfolgt in fünf Schritten: (Bilder aus dem Internet) Schritt 1: Die Update-Ereignisse (Update, Einfügen, Löschen) der Hauptbibliothek werden in das Binlog geschrieben Schritt 2: Initiieren Sie eine Verbindung von der Slave-Bibliothek zur Hauptbibliothek. Schritt 3: Zu diesem Zeitpunkt erstellt die Hauptbibliothek einen Binlog-Dump-Thread und sendet den Inhalt des Binlogs an die Slave-Bibliothek. Schritt 4: Erstellen Sie nach dem Start in der Bibliothek einen E/A-Thread, lesen Sie den von der Hauptbibliothek übergebenen Binlog-Inhalt und schreiben Sie ihn in das Relay-Protokoll. Schritt 5: Außerdem wird ein SQL-Thread erstellt vom Relais Lesen Sie den Inhalt im Protokoll, führen Sie das Leseaktualisierungsereignis ab der Position Exec_Master_Log_Pos aus und schreiben Sie den aktualisierten Inhalt in die Slave-DatenbankDer Grund für die Master-Slave-Synchronisationsverzögerung
Ein Server öffnet N Links für die Verbindung von Clients, sodass große gleichzeitige Aktualisierungsvorgänge stattfinden, aber es gibt nur einen Thread zum Lesen des Binlogs vom Server. Wenn ein bestimmtes SQL auf dem Slave-Server ausgeführt wird, dauert es etwas länger Es kann lange dauern oder weil eine bestimmte SQL die Tabelle sperren muss, was zu einem großen SQL-Rückstand auf dem Master-Server führt und nicht mit dem Slave-Server synchronisiert wird. Dies führt zu einer Master-Slave-Inkonsistenz, also einer Master-Slave-Verzögerung.
Lösung für die Master-Slave-Synchronisationsverzögerung
Der Master-Server ist für den Aktualisierungsvorgang verantwortlich und hat höhere Sicherheitsanforderungen als der Slave-Server, daher können einige Einstellungsparameter geändert werden, wie z. B. sync_binlog=1, innodb_flush_log_at_trx_commit = 1 usw. Einstellungen usw.
Wählen Sie ein besseres Hardwaregerät als Slave.
Verwenden Sie einen Slave-Server als Backup, ohne Abfragen bereitzustellen. Die Belastung auf dieser Seite wird reduziert und die Effizienz der Ausführung des SQL im Relay-Protokoll ist natürlich höher.
Der Zweck des Hinzufügens von Slave-Servern besteht darin, den Lesedruck zu verteilen und dadurch die Serverlast zu reduzieren.
6.3 Wenn Sie gebeten würden, Unterdatenbanken und Untertabellen zu entwerfen, sagen Sie mir kurz, was Sie tun würden?
Subdatenbank- und Table-Sharding-Schema:
Horizontale Subdatenbank: Teilen Sie die Daten in einer Datenbank basierend auf Feldern und nach bestimmten Strategien (Hash, Bereich usw.) in mehrere Datenbanken auf.
Horizontale Tabellenaufteilung: Teilen Sie die Daten in einer Tabelle basierend auf Feldern und nach bestimmten Strategien (Hash, Bereich usw.) in mehrere Tabellen auf.
Vertikale Unterdatenbank: Basierend auf Tabellen werden verschiedene Tabellen je nach Unternehmenseigentum in verschiedene Datenbanken aufgeteilt.
Vertikale Tabellenaufteilung: Basierend auf den Feldern und entsprechend der Aktivität der Felder werden die Felder in der Tabelle in verschiedene Tabellen (Haupttabelle und erweiterte Tabelle) aufgeteilt.
Häufig verwendete Sharding-JDBC-Middleware:
Sharding-JDBC
Mycat
Probleme, die beim Sharding auftreten können.
-
Transaktionsfrage: Erforderlich. Verwenden Sie verteilte Transaktionen
Knotenübergreifendes Verknüpfungsproblem: Dieses Problem kann durch zwei Abfragen gelöst werden
Knotenübergreifende Zähl-, Sortier-, Gruppierungs- und Aggregationsfunktionsprobleme: jeweils auf jedem Knoten abrufen. Die Ergebnisse werden dann auf der Anwendungsseite zusammengeführt.
Datenmigration, Kapazitätsplanung, Erweiterung und andere Probleme
ID-Problem: Nach der Aufteilung der Datenbank können Sie sich nicht mehr auf den Primärschlüsselgenerierungsmechanismus der Datenbank selbst verlassen. Der einfachste Weg ist die Berücksichtigung der UUID
Cross-Sharding Sortier-Paging-Problem
Empfohlenes Lernen: MySQL-Lerntutorial
Das obige ist der detaillierte Inhalt vonSammlung von Fragen und Antworten zu MySQL-Interviews (Zusammenfassung). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 PhpMyAdmin Connection MySQL
Apr 10, 2025 pm 10:57 PM
PhpMyAdmin Connection MySQL
Apr 10, 2025 pm 10:57 PM
Wie verbinde ich mit PhpMyAdmin mit MySQL? Die URL zum Zugriff auf phpmyadmin ist normalerweise http: // localhost/phpmyadmin oder http: // [Ihre Server -IP -Adresse]/Phpmyadmin. Geben Sie Ihren MySQL -Benutzernamen und Ihr Passwort ein. Wählen Sie die Datenbank aus, mit der Sie eine Verbindung herstellen möchten. Klicken Sie auf die Schaltfläche "Verbindung", um eine Verbindung herzustellen.
