
 🎜
🎜  Datenbank
MySQL-Tutorial
Super detaillierte Zusammenfassung der praktischen Fähigkeiten zur MySQL-Optimierung
Datenbank
MySQL-Tutorial
Super detaillierte Zusammenfassung der praktischen Fähigkeiten zur MySQL-Optimierung
Super detaillierte Zusammenfassung der praktischen Fähigkeiten zur MySQL-Optimierung

Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL und fasst hauptsächlich 21 praktische Fähigkeiten zur MySQL-Optimierung zusammen. Ich hoffe, dass sie für alle hilfreich sind.

Empfohlenes Lernen: MySQL-Video-Tutorial
Heutzutage sind Datenbankoperationen zunehmend zum Leistungsengpass der gesamten Anwendung geworden, was besonders bei Webanwendungen offensichtlich ist. Was die Leistung der Datenbank betrifft, ist dies nicht nur etwas, worüber sich Datenbankadministratoren Sorgen machen müssen, sondern auch wir Programmierer müssen darauf achten. Wenn wir die Datenbanktabellenstruktur entwerfen und die Datenbank betreiben (insbesondere SQL-Anweisungen beim Nachschlagen von Tabellen), müssen wir auf die Leistung von Datenoperationen achten. Hier werden wir nicht zu viel über die Optimierung von SQL-Anweisungen sprechen, sondern nur für MySQL, die am häufigsten verwendete Datenbank im Web. Ich hoffe, dass die folgenden Optimierungstipps für Sie hilfreich sind
1 Optimieren Sie Ihre Abfragen für den Abfrage-Cache
Auf den meisten MySQL-Servern ist der Abfrage-Cache aktiviert. Dies ist eine der effektivsten Möglichkeiten zur Leistungsverbesserung und wird von der MySQL-Datenbank-Engine verwaltet. Wenn viele der gleichen Abfragen mehrmals ausgeführt werden, werden die Abfrageergebnisse in einem Cache abgelegt, sodass nachfolgende identische Abfragen die Tabelle nicht bedienen müssen, sondern direkt auf die zwischengespeicherten Ergebnisse zugreifen.
Das Hauptproblem hierbei ist, dass Programmierer diese Angelegenheit leicht übersehen. Weil einige unserer Abfrageanweisungen dazu führen, dass MySQL den Cache nicht verwendet . Bitte sehen Sie sich das folgende Beispiel an:

Der Unterschied zwischen den beiden oben genannten SQL-Anweisungen besteht darin, dass
CURDATE()bei dieser Funktion nicht funktioniert. Daher ermöglichen SQL-Funktionen wieNOW()undRAND()oder andere derartige Funktionen kein Abfrage-Caching, da die Rückgaben dieser Funktionen flüchtig sind. Sie müssen also lediglich die MySQL-Funktion durch eine Variable ersetzen, um das Caching zu aktivieren.CURDATE(),MySQL 的查询缓存对这个函数不起作用。所以,像NOW()和RAND()或是其它的诸如此类的 SQL 函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替 MySQL 的函数,从而开启缓存。
2. EXPLAIN 你的 SELECT 查询
使用
EXPLAIN关键字可以让你知道 MySQL 是如何处理你的 SQL 语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。EXPLAIN的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的……等等,等等。
挑一个你的SELECT语句(推荐挑选那个最复杂的,有多表联接的),把关键字EXPLAIN加到前面。你可以使用phpmyadmin来做这个事。然后,你会看到一张表格。下面的这个示例中,我们忘记加上了group_id索引,并且有表联接:
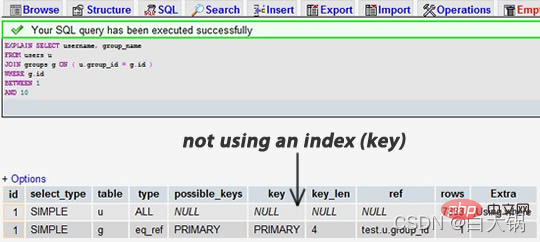
当我们为 group_id 字段加上索引后: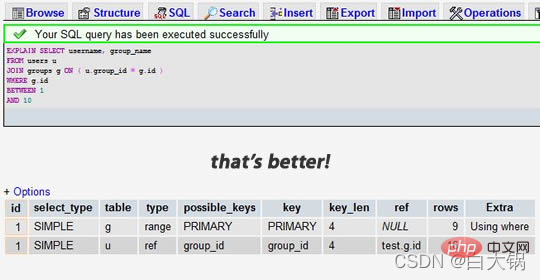
我们可以看到,前一个结果显示搜索了 7883 行,而后一个只是搜索了两个表的 9 和 16 行。查看 rows 列可以让我们找到潜在的性能问题。
3. 当只要一行数据时使用 LIMIT 1 1
2. EXPLAIN Ihre SELECT-Abfrage当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去
fetch游标,或是你也许会去检查返回的记录数。
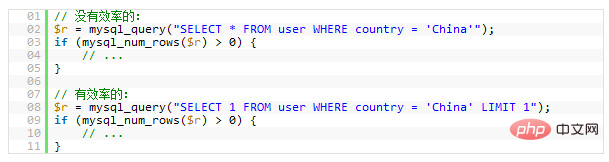
在这种情况下,加上LIMIT 1可以增加性能。这样一样,MySQL 数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
下面的示例,只是为了找一下是否有“中国”的用户,很明显,后面的会比前面的更有效率。(请注意,第一条中是Select *,第二条是Select 1
EXPLAIN erfahren Sie, wie MySQL Ihre SQL-Anweisung verarbeitet. Dies kann Ihnen bei der Analyse der Leistungsengpässe Ihrer Abfrageanweisungen oder Tabellenstrukturen helfen. Die Abfrageergebnisse von EXPLAIN zeigen Ihnen auch, wie Ihr Index-Primärschlüssel verwendet wird, wie Ihre Datentabelle durchsucht und sortiert wird usw. usw.
Wählen Sie eine Ihrer SELECT-Anweisungen aus (es wird empfohlen, die komplexeste mit mehreren Tabellenverknüpfungen auszuwählen) und fügen Sie das Schlüsselwort EXPLAIN vorne hinzu. Sie können dazu phpmyadmin verwenden. Dann sehen Sie ein Formular. Im folgenden Beispiel haben wir vergessen, den group_id-Index hinzuzufügen und einen Tabellen-Join zu haben:
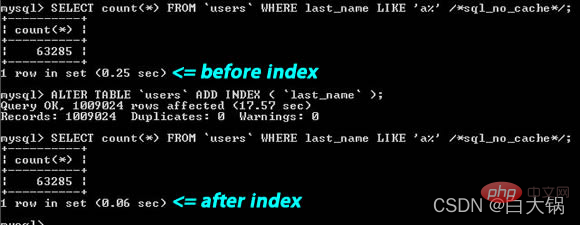
 🎜 Wir können sehen, dass das erstere Ergebnis zeigt, dass 7883 Zeilen durchsucht wurden, während das letztere nur nach zwei Tabellen suchte. Zeilen 9 und 16. Wenn wir uns die Zeilenspalte ansehen, können wir potenzielle Leistungsprobleme finden. 🎜🎜3. Verwenden Sie LIMIT 1 1, wenn nur eine Datenzeile vorhanden ist. 🎜🎜🎜Manchmal wissen Sie beim Abfragen einer Tabelle bereits, dass das Ergebnis nur ein Ergebnis sein wird, aber Sie müssen möglicherweise zum
🎜 Wir können sehen, dass das erstere Ergebnis zeigt, dass 7883 Zeilen durchsucht wurden, während das letztere nur nach zwei Tabellen suchte. Zeilen 9 und 16. Wenn wir uns die Zeilenspalte ansehen, können wir potenzielle Leistungsprobleme finden. 🎜🎜3. Verwenden Sie LIMIT 1 1, wenn nur eine Datenzeile vorhanden ist. 🎜🎜🎜Manchmal wissen Sie beim Abfragen einer Tabelle bereits, dass das Ergebnis nur ein Ergebnis sein wird, aber Sie müssen möglicherweise zum gehen fetch Cursor, Oder Sie können die Anzahl der zurückgegebenen Datensätze überprüfen. 🎜 In diesem Fall kann das Hinzufügen von LIMIT 1 🎜die Leistung steigern🎜. Auf diese Weise stoppt die MySQL-Datenbank-Engine die Suche, nachdem sie ein Datenelement gefunden hat, anstatt weiter nach dem nächsten Datenelement zu suchen, das mit dem Datensatz übereinstimmt. 🎜 Das folgende Beispiel dient nur dazu, herauszufinden, ob es „China“-Benutzer gibt. Offensichtlich ist letzteres effizienter als ersteres. (Bitte beachten Sie, dass das erste Element Select * und das zweite Element Select 1 ist)🎜🎜🎜🎜🎜🎜4. Indexieren Sie das Suchfeld🎜🎜index bedeutet nicht unbedingt, dass der Primärschlüssel oder das einzige Feld angegeben wird. Wenn es in Ihrer Tabelle ein Feld gibt, das Sie immer zum Suchen verwenden, dann erstellen Sie bitte einen Index dafür🎜🎜🎜🎜Auf dem Bild oben können Sie sehen, dass bei der Suchzeichenfolge „
last_name LIKE 'a%‘“ einer indiziert ist, der andere nicht indiziert ist. Die Leistung ist viermal schlechter Code> stark>Links und rechts.
Darüber hinaus sollten Sie auch wissen, bei welchen Suchvorgängen keine normalen Indizes verwendet werden können. Wenn Sie beispielsweise in einem großen Artikel nach einem Wort suchen müssen, wie zum Beispiel: „WHERE post_content LIKE '%apple%'“, ist der Index möglicherweise nicht sinnvoll. Möglicherweise müssen Sie den MySQL-Volltextindex verwenden oder selbst einen Index erstellen (zum Beispiel: Suche nach Schlüsselwörtern oder Tags)last_name LIKE ‘a%’”,一个是建了索引,一个是没有索引,性能差了 4 倍左右。
另外,你应该也需要知道什么样的搜索是不能使用正常的索引的。例如,当你需要在一篇大的文章中搜索一个词时,如: “WHERE post_content LIKE ‘%apple%’”,索引可能是没有意义的。你可能需要使用 MySQL 全文索引 或是自己做一个索引(比如说:搜索关键词或是 Tag 什么的)
5. 在 Join 表的时候使用相同类型的例
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中 Join 的字段是被建过索引的。这样,MySQL 内部会启动为你优化 Join 的 SQL 语句的机制。
而且,这些被用来 Join 的字段,应该是相同的类型的。例如:如果你要把DECIMAL字段和一个 INT 字段Join在一起,MySQL 就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样)
6. 千万不要 ORDER BY RAND()
想打乱返回的数据行?随机挑一个数据?真不知道谁发明了这种用法,但很多新手很喜欢这样用。但你确不了解这样做有多么可怕的性能问题。
如果你真的想把返回的数据行打乱了,你有 N 种方法可以达到这个目的。这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL 会不得不去执行RAND()函数(很耗 CPU 时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
下面的示例是随机挑一条记录: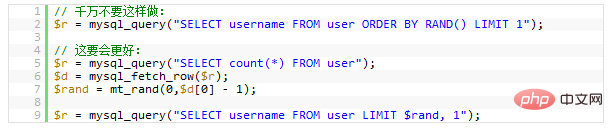
7.避免 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和 WEB 服务器是两台独立的服务器的话,这还会增加网络传输的负载。所以,你应该养成一个需要什么就取什么的好的习惯。
8. 永远为每张表设置一个 ID
我们应该为数据库里的每张表都设置一个 ID 做为其主键,而且最好的是一个
INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志。
就算是你 users 表有一个主键叫 “VARCHAR类型来当主键会使用得性能下降。另外,在你的程序中,你应该使用表的 ID 来构造你的数据结构。
而且,在 MySQL 数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要,比如,集群,分区……
在这里,只有一个情况是例外,那就是“关联表”的“外键”,也就是说,这个表的主键,通过若干个别的表的主键构成。我们把这个情况叫做“外键”。比如:有一个“学生表”有学生的 ID,有一个“课程表”有课程 ID,那么,“成绩表”就是“关联表”了,其关联了学生表和课程表,在成绩表中,学生 ID 和课程 ID 叫“外键”其共同组成主键。
9. 使用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。在实际上,其保存的是
TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用ENUM而不是VARCHAR。
MySQL 也有一个“建议”(见第十条)告诉你怎么去重新组织你的表结构。当你有一个VARCHAR字段时,这个建议会告诉你把其改成ENUM类型。使用PROCEDURE ANALYSE()
5 Verwenden Sie beim Verknüpfen der Tabelle die gleiche Art von Beispiel
🎜Wenn Ihre Anwendung viele JOIN-Abfragen enthält, sollten Sie bestätigen, dass die Join-Felder in beiden Tabellen indiziert sind. Auf diese Weise startet MySQL einen Mechanismus zur Optimierung der Join-SQL-Anweisung für Sie.Darüber hinaus sollten diese für den Join verwendeten Felder vom gleichen Typ sein. Beispiel: Wenn Sie ein
DECIMAL-Feld mit einem INT-Feld verknüpfen, kann MySQL deren Indizes nicht verwenden. Für diese STRING-Typen ist ebenfalls derselbe Zeichensatz erforderlich. (Die Zeichensätze der beiden Tabellen können unterschiedlich sein)🎜🎜🎜6. Niemals NACH RAND() sortieren
🎜🎜Möchten Sie die zurückgegebenen Datenzeilen zufällig auswählen? Ich weiß wirklich nicht, wer das erfunden hat ist eine andere Verwendung, aber viele Anfänger verwenden sie gerne auf diese Weise. Aber Sie verstehen wirklich nicht, was für ein schreckliches Leistungsproblem das mit sich bringt.Wenn Sie die zurückgegebenen Datenzeilen wirklich verschlüsseln möchten, gibt es N Möglichkeiten, dies zu erreichen. Wenn Sie dies verwenden, sinkt die Leistung Ihrer Datenbank nur exponentiell. Das Problem hierbei ist: MySQL muss die Funktion
RAND() ausführen (was sehr zeitaufwändig für die CPU ist), und zwar dazu, sich die Zeilen für jede Datensatzzeile zu merken und sie dann zu sortieren ihnen. Selbst wenn Sie Limit 1 verwenden, hilft es nicht (da es sortiert werden muss)🎜🎜Das folgende Beispiel wählt zufällig einen Datensatz aus:🎜
7. Vermeiden Sie SELECT *🎜 🎜Je mehr Daten aus der Datenbank gelesen werden, desto langsamer wird die Abfrage. Wenn Ihr Datenbankserver und Ihr WEB-Server außerdem zwei unabhängige Server sind, erhöht dies auch die Last der Netzwerkübertragung. Deshalb sollten Sie sich angewöhnen, alles zu sich zu nehmen, was Sie brauchen.
 🎜
🎜 8. Legen Sie immer eine ID für jede Tabelle fest
🎜🎜Wir sollten für jede Tabelle in der Datenbank eine ID als Primärschlüssel festlegen, und am besten ist ein INT code>-Typ (UNSIGNED wird empfohlen) und setzen Sie das automatisch hinzugefügte Flag AUTO_INCREMENT.
Auch wenn Ihre Benutzertabelle ein Feld mit einem Primärschlüssel namens „email“ enthält, machen Sie es nicht zum Primärschlüssel. Die Verwendung des Typs VARCHAR als Primärschlüssel beeinträchtigt die Leistung. Darüber hinaus sollten Sie in Ihrem Programm Tabellen-IDs verwenden, um Ihre Datenstrukturen aufzubauen.
Darüber hinaus gibt es unter der MySQL-Daten-Engine einige Vorgänge, die die Verwendung von Primärschlüsseln erfordern. In diesen Fällen werden die Leistung und die Einstellungen von Primärschlüsseln sehr wichtig, wie z. B. Clustering, Partitionierung usw. Hier gibt es nur eine Ausnahme, und das ist der „Fremdschlüssel“ der „zugehörigen Tabelle“, das heißt, der Primärschlüssel dieser Tabelle setzt sich aus den Primärschlüsseln mehrerer zusammen einzelne Tische. Wir nennen diese Situation „Fremdschlüssel“. Beispiel: Es gibt eine „Studententabelle“ mit Studenten-IDs und eine „Lehrplantabelle“ mit Kurs-IDs. Dann ist die „Notentabelle“ eine „Zuordnungstabelle“, die die Studententabelle und die Kurstabelle in der Note verknüpft Tabelle: Die Studenten-ID und die Kurs-ID werden als „Fremdschlüssel“ bezeichnet und bilden zusammen den Primärschlüssel. 🎜9. Verwenden Sie ENUM anstelle von VARCHAR
🎜🎜Der ENUM-Typ ist sehr schnell und kompakt. Tatsächlich speichert es TINYINT, erscheint jedoch als Zeichenfolge. Auf diese Weise ist es ideal, dieses Feld zum Erstellen einiger Auswahllisten zu verwenden.
Wenn Sie ein Feld wie „Geschlecht“, „Land“, „Ethnizität“, „Status“ oder „Abteilung“ haben und wissen, dass die Werte dieser Felder begrenzt und fest sind, dann sind Sie hier genau richtig sollte ENUM anstelle von VARCHAR verwenden.
MySQL hat auch einen „Vorschlag“ (siehe Punkt 10), der Ihnen sagt, wie Sie Ihre Tabellenstruktur neu organisieren können. Wenn Sie über ein Feld vom Typ VARCHAR verfügen, empfiehlt Ihnen dieser Rat, es in einen Typ vom Typ ENUM zu ändern. Verwenden Sie PROCEDURE ANALYSE() und Sie können relevante Vorschläge erhalten🎜10. Holen Sie sich Vorschläge von PROCEDURE ANALYSE()
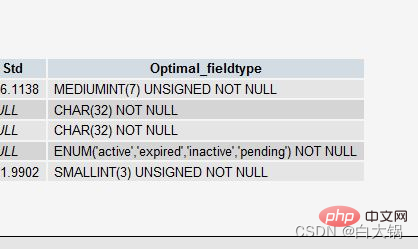
PROCEDURE ANALYSE() hilft Ihnen bei der Analyse Ihrer Felder und ihrer tatsächlichen Daten und gibt Ihnen einige nützliche Vorschläge. Diese Vorschläge sind nur dann nützlich, wenn die Tabelle tatsächliche Daten enthält, da für einige wichtige Entscheidungen Daten als Grundlage erforderlich sind.
Wenn Sie beispielsweise ein INT-Feld als Ihren Primärschlüssel erstellen, aber nicht viele Daten vorhanden sind, schlägt PROCEDURE ANALYSE() vor, dass Sie den Typ dieses Felds in MITTELINT. Oder wenn Sie ein VARCHAR-Feld verwenden, weil nicht viele Daten vorhanden sind, erhalten Sie möglicherweise den Vorschlag, es
in ENUM zu ändern. Diese Vorschläge sind alle möglich, da nicht genügend Daten vorliegen und die Entscheidungsfindung daher nicht genau genug ist.
In phpmyadmin können Sie beim Anzeigen der Tabelle auf "Tabellenstruktur vorschlagen" klicken, um diese Vorschläge anzuzeigenPROCEDURE ANALYSE() 会让 MySQL 帮你去分析你的字段和其实际的数据,并会给你一些有用的建议。只有表中有实际的数据,这些建议才会变得有用,因为要做一些大的决定是需要有数据作为基础的。
例如,如果你创建了一个 INT 字段作为你的主键,然而并没有太多的数据,那么,PROCEDURE ANALYSE()会建议你把这个字段的类型改成 MEDIUMINT 。或是你使用了一个 VARCHAR 字段,因为数据不多,你可能会得到一个让你把它
改成 ENUM 的建议。这些建议,都是可能因为数据不够多,所以决策做得就不够准。
在 phpmyadmin 里,你可以在查看表时,点击 “Propose table structure” 来查看这些建议
PROCEDURE ANALYSE() hilft Ihnen bei der Analyse Ihrer Felder und ihrer tatsächlichen Daten und gibt Ihnen einige nützliche Vorschläge. Diese Vorschläge sind nur dann nützlich, wenn die Tabelle tatsächliche Daten enthält, da für einige wichtige Entscheidungen Daten als Grundlage erforderlich sind.
Wenn Sie beispielsweise ein INT-Feld als Ihren Primärschlüssel erstellen, aber nicht viele Daten vorhanden sind, schlägt PROCEDURE ANALYSE() vor, dass Sie den Typ dieses Felds in MITTELINT. Oder wenn Sie ein VARCHAR-Feld verwenden, weil nicht viele Daten vorhanden sind, erhalten Sie möglicherweise den Vorschlag, es
in ENUM zu ändern. Diese Vorschläge sind alle möglich, da nicht genügend Daten vorliegen und die Entscheidungsfindung daher nicht genau genug ist.
In phpmyadmin können Sie beim Anzeigen der Tabelle auf "Tabellenstruktur vorschlagen" klicken, um diese Vorschläge anzuzeigenPROCEDURE ANALYSE() 会让 MySQL 帮你去分析你的字段和其实际的数据,并会给你一些有用的建议。只有表中有实际的数据,这些建议才会变得有用,因为要做一些大的决定是需要有数据作为基础的。
例如,如果你创建了一个 INT 字段作为你的主键,然而并没有太多的数据,那么,PROCEDURE ANALYSE()会建议你把这个字段的类型改成 MEDIUMINT 。或是你使用了一个 VARCHAR 字段,因为数据不多,你可能会得到一个让你把它
改成 ENUM 的建议。这些建议,都是可能因为数据不够多,所以决策做得就不够准。
在 phpmyadmin 里,你可以在查看表时,点击 “Propose table structure” 来查看这些建议
一定要注意,这些只是建议,只有当你的表里的数据越来越多时,这些建议才会变得准确。一定要记住,你才是最终做决定的人
11. 尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用
NULL值,你应该总是让你的字段保持NOT NULL。这看起来好像有点争议,请往下看。
首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是 0 和 NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL和Empty的字符串是一样的!)
不要以为NULL不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用 NULL 值。
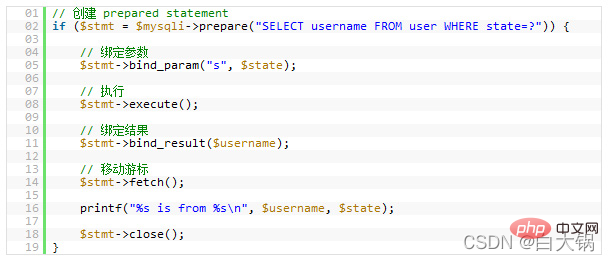
12.Prepared Statements
Prepared Statements很像存储过程,是一种运行在后台的 SQL 语句集合,我们可以从使用prepared statements获得很多好处,无论是性能问题还是安全问题。Prepared Statements可以检查一些你绑定好的变量,这样可以保护你的程序不会受到“SQL 注入式”攻击。当然,你也可以手动地检查你的这些变量,然而,手动的检查容易出问题,而且很经常会被程序员忘了。当我们使用一些framework或是ORM的时候,这样的问题会好一些。
性能方面,当一个相同的查询被使用多次的时候,这会为你带来可观的性能优势。你可以给这些Prepared Statements定义一些参数,而 MySQL 只会解析一次。
虽然最新版本的 MySQL 在传输Prepared Statements是使用二进制形式,所以这会使得网络传输非常有效率。
当然,也有一些情况下,我们需要避免使用Prepared Statements,因为其不支持查询缓存。但据说版本 5.1 后支持了。
在 PHP 中要使用 prepared statements,你可以查看其使用手册:mysql扩展 或是使用数据库抽象层,如: PDO.
13. 无缓冲的查询
正常的情况下,当你在当你在你的脚本中执行一个 SQL 语句的时候,你的程序会停在那里直到没这个 SQL 语句返回,然后你的程序再往下继续执行。你可以使用无缓冲查询来改变这个行为。
🎜mysql_unbuffered_query()发送一个 SQL 语句到 MySQL 而并不像mysql_query()一样去自动fethch和缓存结果。这会相当节约很多可观的内存,尤其是那些会产生大量结果的查询语句,并且,你不需要等到所有的结果都返回,只需要第一行数据返回的时候,你就可以开始马上开始工作于查询结果了。
然而,这会有一些限制。因为你要么把所有行都读走,或是你要在进行下一次的查询前调用mysql_free_result()清除结果。而且,mysql_num_rows()或 mysql_data_seek()NULLzu verwenden Wert angeben, sollten Sie Ihre Felder immerNOT NULLhalten. Das mag etwas kontrovers erscheinen, bitte lesen Sie weiter.
Fragen Sie sich zunächst, was der Unterschied zwischen „Empty“ und „NULL“ ist (wenn esINTist, ist das ). 0 und NULL)? Wenn Sie der Meinung sind, dass es keinen Unterschied zwischen ihnen gibt, sollten SieNULLnicht verwenden. (Wussten Sie schon? In Oracle sind die Zeichenfolgen vonNULLundEmptygleich!)
Nicht Denken Sie, dassNULLkeinen Platz benötigt, es benötigt zusätzlichen Platz und Ihr Programm wird komplexer, wenn Sie Vergleiche durchführen. Dies bedeutet natürlich nicht, dass SieNULLnicht verwenden können. Die Realität ist sehr kompliziert und es wird immer noch Situationen geben, in denen Sie NULL-Werte verwenden müssen. 🎜🎜🎜12.Prepared Statements🎜🎜🎜Prepared Statementsist einer gespeicherten Prozedur sehr ähnlich. Es handelt sich um eine Sammlung von SQL-Anweisungen, die im Hintergrund ausgeführt werden Anweisungen Vorteile, egal ob es sich um einLeistungsproblem oder ein Sicherheitsproblem handelt.Vorbereitete Anweisungenkönnen einige von Ihnen gebundene Variablen überprüfen, was Ihr Programm vor „SQL-Injection“-Angriffen schützen kann. Natürlich können Sie Ihre Variablen auch manuell überprüfen. Manuelle Überprüfungen sind jedoch problematisch und werden von Programmierern oft vergessen. Dieses Problem wird besser, wenn wir einFrameworkoderORMverwenden.
In Bezug auf die Leistung ergeben sich bei mehrfacher Verwendung derselben Abfrage erhebliche Leistungsvorteile. Sie können einige Parameter für diesePrepared Statementsdefinieren und MySQL analysiert sie nur einmal.
Obwohl die neueste Version von MySQL bei der Übertragung vonvorbereiteten AnweisungenBinärform verwendet, wird dies die Netzwerkübertragung sehr effizient machen.
Natürlich gibt es einige Fälle, in denen wir die Verwendung vonPrepared Statementsvermeiden müssen, da das Abfrage-Caching nicht unterstützt wird. Es soll aber ab Version 5.1 unterstützt werden.
Um vorbereitete Anweisungen in PHP zu verwenden, können Sie das Handbuch lesen: MySQL-Erweiterung oder die Datenbankabstraktionsschicht verwenden, wie zum Beispiel: PDO.🎜🎜🎜mysql_unbuffered_query()sendet eine SQL-Anweisung an MySQL, ohne automatischfethchund die Ergebnisse zwischenzuspeichern, wie dies beimysql_query()der Fall ist. Dadurch wird insbesondere bei Abfragen, die eine große Anzahl von Ergebnissen generieren, viel Speicher gespart, und Sie müssen nicht warten, bis alle Ergebnisse zurückgegeben werden. Sie müssen nur die erste Datenzeile zurückgeben und können mit der Arbeit beginnen Sofort sind die Abfrageergebnisse verfügbar.
Dies hat jedoch einige Einschränkungen. Denn Sie müssen entweder alle Zeilen lesen odermysql_free_result()aufrufen, um die Ergebnisse vor der nächsten Abfrage zu löschen. Außerdem funktionierenmysql_num_rows() oder mysql_data_seek()nicht. Daher müssen Sie sorgfältig überlegen, ob Sie ungepufferte Abfragen verwenden. 🎜
 🎜🎜Beachten Sie unbedingt, dass dies nur Vorschläge sind, nur wenn Ihre Tabelle mehr Daten enthält verfügbar wird, werden diese Empfehlungen genauer. Denken Sie immer daran: Sie sind derjenige, der die endgültige Entscheidung trifft🎜🎜11 Verwenden Sie NOT NULL so oft wie möglich🎜🎜🎜Es sei denn, Sie haben einen ganz besonderen Grund,
🎜🎜Beachten Sie unbedingt, dass dies nur Vorschläge sind, nur wenn Ihre Tabelle mehr Daten enthält verfügbar wird, werden diese Empfehlungen genauer. Denken Sie immer daran: Sie sind derjenige, der die endgültige Entscheidung trifft🎜🎜11 Verwenden Sie NOT NULL so oft wie möglich🎜🎜🎜Es sei denn, Sie haben einen ganz besonderen Grund, 14. Speichern Sie die IP-Adresse als UNSIGNED INT
Viele Programmierer erstellen ein
VARCHAR(15)-Feld, um die IP in Stringform anstelle der ganzzahligen IP zu speichern. Wenn Sie zum Speichern eine Ganzzahl verwenden, sind nur 4 Bytes erforderlich, und Sie können Felder mit fester Länge haben. Darüber hinaus erhalten Sie dadurch Vorteile bei der Abfrage, insbesondere wenn SieWHERE-Bedingungen wie diese verwenden müssen:IP zwischen ip1 und ip2.
Wir müssenUNSIGNED INTverwenden, da die IP-Adresse den gesamten 32-Bit-Ganzzahltyp ohne Vorzeichen verwendet.
Für Ihre Abfrage können Sie mitINET_ATON()eine Zeichenfolge IP in eine Ganzzahl umwandeln und mitINET_NTOA()eine Ganzzahl in umwandeln eine String-IP. In PHP gibt es auch solche Funktionenip2long() und long2ip().VARCHAR(15)字段来存放字符串形式的 IP 而不是整形的 IP。如果你用整形来存放,只需要 4 个字节,并且你可以有定长的字段。而且,这会为你带来查询上的优势,尤其是当你需要使用这样的WHERE条件:IP between ip1 and ip2。
我们必需要使用UNSIGNED INT,因为 IP 地址会使用整个 32 位的无符号整型。
而你的查询,你可以使用INET_ATON()来把一个字符串 IP 转成一个整型,并使用INET_NTOA()把一个整形转成一个字符串 IP。在 PHP 中,也有这样的函数ip2long() 和 long2ip()。
15. 固定长度的表会更快
如果表中的所有字段都是“固定长度”的,整个表会被认为是 “
static”或 “fixed-length”。 例如,表中没有如下类型的字段:VARCHAR,TEXT。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,因为 MySQL 搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
使用“垂直分割”技术(见下一条),你可以分割你的表成为两个一个是定长的,一个则是不定长的。
16. 垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。(以前,在银行做过项目,见过一张表有 100 多个字段,很恐怖)
示例一:在 Users 表中有一个字段是家庭地址,这个字段是可选字段,相比起,而且你在数据库操作的时候除了个人信息外,你并不需要经常读取或是改写这个字段。那么,为什么不把他放到另外一张表中呢? 这样会让你的表有更好的性能,大家想想是不是,大量的时候,我对于用户表来说,只有用户ID,用户名,口令,用户角色等会被经常使用。小一点的表总是会有好的性
能。
示例二: 你有一个叫 “last_login” 的字段,它会在每次用户登录时被更新。但是,每次更新时会导致该表的查询缓存被清空。所以,你可以把这个字段放到另一个表中,这样就不会影响你对用户 ID,用户名,用户角色的不停地读取了,因为查询缓存会帮你增加很多性能。
另外,你需要注意的是,这些被分出去的字段所形成的表,你不会经常性地去 Join 他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降
17.拆分大的 DELETE 或 INSERT 语句
15 . Tabellen mit fester Länge sind schneller如果你需要在一个在线的网站上去执行一个大的
DELETE或INSERT查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。
Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如 30 秒钟,那么对于一个有很高访问量的站点来说,这 30 秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你泊 WEB 服务Crash,还可能会让你的整台服务器马上掛了。
所以,如果你有一个大的处理,你定你一定把其拆分,使用LIMIT
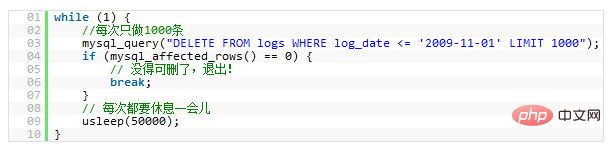
statisch“ oder „feste Länge". Beispielsweise gibt es in der Tabelle keine Felder der folgenden Typen: <code>VARCHAR, TEXT. Solange Sie eines dieser Felder einschließen, ist die Tabelle keine „statische Tabelle fester Länge“ mehr und die MySQL-Engine verarbeitet sie auf andere Weise. Tabellen mit fester Länge verbessern die Leistung, da MySQL schneller sucht. Da diese festen Längen die Berechnung des Offsets der nächsten Daten erleichtern, erfolgt das Lesen natürlich schneller. Und wenn das Feld keine feste Länge hat, muss das Programm jedes Mal, wenn Sie das nächste finden möchten, den Primärschlüssel finden.
Außerdem lassen sich Tabellen mit fester Länge einfacher zwischenspeichern und neu erstellen. Der einzige Nebeneffekt besteht jedoch darin, dass Felder mit fester Länge etwas Platz verschwenden, da Felder mit fester Länge so viel Platz für die Zuweisung erfordern, unabhängig davon, ob Sie sie verwenden oder nicht. 🎜🎜🎜Mit der „Vertical Split“-Technologie (siehe nächster Punkt) können Sie Ihren Tisch in zwei Teile aufteilen, einen mit fester Länge und einen mit variabler Länge. 🎜🎜16. Vertikale Aufteilung🎜🎜🎜 „Vertikale Aufteilung“ ist eine Methode zum Umwandeln der Tabellen in der Datenbank in mehrere Tabellen nach Spalten, wodurch die Komplexität der Tabelle und die Anzahl der Felder reduziert und so Optimierungszwecke erreicht werden können. (Ich habe früher Projekte in einer Bank durchgeführt und eine Tabelle mit mehr als 100 Feldern gesehen, was beängstigend war) 🎜🎜🎜🎜Beispiel 1: Es gibt ein Feld in der Benutzertabelle, das die Privatadresse ist. Im Vergleich zu , und wenn Sie die Datenbank betreiben, müssen Sie dieses Feld mit Ausnahme persönlicher Informationen nicht häufig lesen oder neu schreiben. Warum also nicht in eine andere Tabelle einfügen? Dadurch wird die Leistung Ihrer Tabelle verbessert. Für die Benutzertabelle habe ich nur die Benutzer-ID, den Benutzernamen und die Benutzerrollen. usw. werden häufig verwendet. Kleinere Tabellen bieten immer eine bessere Leistung. 🎜🎜🎜🎜Beispiel 2: Sie haben ein Feld namens „last_login“, das jedes Mal aktualisiert wird, wenn sich der Benutzer anmeldet. Allerdings führt jede Aktualisierung dazu, dass der Abfragecache der Tabelle geleert wird. Daher können Sie dieses Feld in eine andere Tabelle einfügen, sodass es Ihr kontinuierliches Lesen von Benutzer-ID, Benutzername und Benutzerrolle nicht beeinträchtigt, da der Abfrage-Cache Ihnen dabei hilft, die Leistung erheblich zu steigern. 🎜🎜🎜Darüber hinaus müssen Sie darauf achten, dass Sie die durch diese getrennten Felder gebildeten Tabellen nicht häufig verbinden. Andernfalls ist die Leistung schlechter als bei Nichtteilung und es kommt zu einem exponentiellen Rückgang🎜🎜17 . Teilen Sie eine große DELETE- oder INSERT-Anweisung auf. 🎜🎜🎜Wenn Sie eine große
DELETE- oder INSERT-Abfrage auf einer Online-Website ausführen müssen, müssen Sie sehr vorsichtig sein, um dies zu vermeiden Vorgänge, die dazu führen, dass Ihre gesamte Website nicht mehr reagiert. Da diese beiden Vorgänge die Tabelle sperren, können nach dem Sperren der Tabelle keine anderen Vorgänge mehr eingegeben werden. Apache wird viele untergeordnete Prozesse oder Threads haben. Daher arbeitet es recht effizient und unser Server möchte nicht zu viele untergeordnete Prozesse, Threads und Datenbankverknüpfungen haben. Dies beansprucht viele Serverressourcen, insbesondere Speicher.
Wenn Sie Ihre Tabelle für einen bestimmten Zeitraum, z. B. 30 Sekunden, sperren, werden bei einer Site mit hohem Verkehrsaufkommen in diesen 30 Sekunden mehrere Zugriffsprozesse/Threads, Datenbankverknüpfungen und geöffnete Dateien angesammelt Manchmal kann es nicht nur zum
Absturz Ihres WEB-Dienstes kommen, sondern auch dazu, dass sich Ihr gesamter Server sofort aufhängt. Wenn Sie also einen großen Prozess haben und ihn unbedingt aufteilen möchten, ist die Verwendung der Bedingung
LIMIT ein guter Ansatz. Hier ein Beispiel: 🎜🎜🎜🎜🎜18. Kleinere Spalten sind schneller
Für die meisten Datenbank-Engines stellen Festplattenvorgänge möglicherweise den größten Engpass dar. Daher kann es in dieser Situation sehr hilfreich sein, Ihre Daten zu komprimieren, da dadurch der Zugriff auf die Festplatte verringert wird.
Sehen Sie sich die MySQL-DokumentationSpeicheranforderungenan, um alle Datentypen anzuzeigen.Storage Requirements查看所有的数据类型。
如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用INT来做主键,使用MEDIUMINT, SMALLINT或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用DATE要比DATETIME好得多。
当然,你也需要留够足够的扩展空间,不然,你日后来干这个事,你会死的很难看,参看Slashdot的例子(2009 年 11 月 06 日),一个简单的ALTER TABLE语句花了 3 个多小时,因为里面有一千六百万条数据。
19. 选择正确的存储引擎
在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。酷壳以前文章《MySQL: InnoDB 还是 MyISAM?》讨论和这个事情。
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要 update 一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于SELECT COUNT(*)这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比MyISAM还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
20. 使用一个对象关系映射器 (Object Relational Mapper)
使用 ORM (
Object Relational Mapper),你能够获得可靠的性能增涨。一个ORM 可以做的所有事情,也能被手动的编写出来。但是,这需要一个高级专家。
ORM 的最重要的是“Lazy Loading”,也就是说,只有在需要的去取值的时候才会去真正的去做。但你也需要小心这种机制的副作用,因为这很有可能会因为要去创建很多很多小的查询反而会降低性能。
ORM 还可以把你的 SQL 语句打包成一个事务,这会比单独执行他们快得多得多。
目前,个人最喜欢的 PHP 的 ORM 是:Doctrine
21. 小心 “ 永久链接 ”
“永久链接”的目的是用来减少重新创建 MySQL 链接的次数。当一个链接被创建了,它会永远处在连接的状态,就算是数据库操作已经结束了。而且,自从我们的 Apache 开始重用它的子进程后——也就是说,下一次的 HTTP 请求会重用 Apache 的子进程,并重用相同的 MySQL 链接。
在理论上来说,这听起来非常的不错。但是从个人经验(也是大多数人的)上来说,这个功能制造出来的麻烦事更多。因为,你只有有限的链接数,内存问题,文件句柄数,等等。
而且,Apache 运行在极端并行的环境中,会创建很多很多的了进程。这就是为什么这种“永久链接”的机制工作地不好的原因。在你决定要使用“永久链接”之前,你需要好好地考虑一下你的整个系统的架构
22.sql优化之索引优化
1.独立的列
在进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。
例如下面的查询不能使用 actor_id 列的索引:
#这是错误的SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
优化方式:可以将表达式、函数操作移动到等号右侧。如下:
SELECT actor_id FROM sakila.actor WHERE actor_id = 5 - 1;
2.多列索引
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。
例如下面的语句中,最好把actor_id 和 film_id 设置为多列索引。猿辅导有道题,详见链接,可以让理解更深刻。
SELECT film_id, actor_ id FROM sakila.film_actorWHERE actor_id = 1 AND film_id = 1;
3.索引列的顺序
让选择性最强的索引列放在前面。
索引的选择性是指:不重复的索引值和记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,每个记录的区分度越高,查询效率也越高。
例如下面显示的结果中 customer_id 的选择性比 staff_id 更高,因此最好把 customer_id 列放在多列索引的前面。
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity, COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity, COUNT(*) FROM payment; #结果如下 staff_id_selectivity: 0.0001 customer_id_selectivity: 0.0373 COUNT(*): 16049
4.前缀索引
对于 BLOB、TEXT 和 VARCHAR Wenn eine Tabelle nur wenige Spalten hat (z. B. Wörterbuchtabelle, Konfigurationstabelle), dann haben wir keinen Grund, INT als Primärschlüssel zu verwenden und MEDIUMINT, SMALLINT zu verwenden Oder ein kleinerer TINYINT wäre wirtschaftlicher. Wenn Sie keine Zeiterfassung benötigen, ist es viel besser, DATE als DATETIME zu verwenden.
Slashdot (06. November 2009), einem einfachen Die ALTER TABLE-Anweisung dauerte mehr als 3 Stunden, da sie 16 Millionen Datensätze enthielt. 19. Wählen Sie die richtige Speicher-Engine 🎜🎜🎜Es gibt zwei Speicher-Engines in MySQL, MyISAM und InnoDB, und jede Engine hat Vor- und Nachteile. Im vorherigen Artikel von Cool Shell „MySQL: InnoDB oder MyISAM?“ wurde dieses Thema besprochen. 🎜 MyISAM eignet sich für einige Anwendungen, die eine große Anzahl von Abfragen erfordern, ist jedoch für eine große Anzahl von Schreibvorgängen nicht sehr gut. Selbst wenn Sie nur ein Feld aktualisieren müssen, wird die gesamte Tabelle gesperrt und andere Prozesse, auch der Lesevorgang, können nicht ausgeführt werden, bis der Lesevorgang abgeschlossen ist. Darüber hinaus ist MyISAM extrem schnell für Berechnungen wie SELECT COUNT(*). 🎜 Der Trend von InnoDB wird eine sehr komplexe Speicher-Engine sein, die für einige kleine Anwendungen langsamer sein wird als MyISAM. Der andere Grund ist, dass es die „Zeilensperre“ unterstützt, sodass es besser ist, wenn mehr Schreibvorgänge ausgeführt werden. Darüber hinaus werden auch fortgeschrittenere Anwendungen wie Transaktionen unterstützt. 🎜🎜20. Verwenden Sie einen Object Relational Mapper🎜🎜🎜Mit einem ORM (Object Relational Mapper) können Sie zuverlässige Leistungssteigerungen erzielen. Alles, was ein ORM kann, kann auch manuell geschrieben werden. Dies erfordert jedoch einen hochrangigen Experten. 🎜 Das Wichtigste an ORM ist „Lazy Loading“, das heißt, es wird nur dann tatsächlich durchgeführt, wenn es notwendig ist, den Wert zu erhalten. Aber Sie müssen auch auf die Nebenwirkungen dieses Mechanismus achten, da er wahrscheinlich die Leistung verringert, indem er viele, viele kleine Abfragen erstellt. 🎜 ORM kann Ihre SQL-Anweisungen auch in eine Transaktion packen, was viel schneller ist, als sie einzeln auszuführen. 🎜 Mein Lieblings-ORM für PHP ist derzeit: Doctrine🎜🎜21 Seien Sie vorsichtig mit „permanenten Links“🎜🎜🎜Der Zweck von „permanenten Links“ besteht darin, die Notwendigkeit einer Neuerstellung zu reduzieren MySQL verlinkt mehrmals. Wenn eine Verknüpfung erstellt wird, bleibt diese dauerhaft verbunden, auch nach Beendigung des Datenbankvorgangs. Da unser Apache außerdem damit begonnen hat, seinen untergeordneten Prozess wiederzuverwenden, wird die nächste HTTP-Anfrage den untergeordneten Apache-Prozess und dieselbe MySQL-Verbindung wiederverwenden. 🎜 Theoretisch klingt das großartig. Aus persönlicher Erfahrung (und der der meisten Menschen) geht jedoch hervor, dass diese Funktion mehr Probleme bereitet. Denn Sie haben nur eine begrenzte Anzahl an Links, Speicherproblemen, Dateihandles usw. 🎜 Darüber hinaus läuft Apache in einer extrem parallelen Umgebung und erstellt viele, viele Prozesse. Aus diesem Grund funktioniert dieser „Permalink“-Mechanismus nicht gut. Bevor Sie sich für die Verwendung von „permanenten Links“ entscheiden, müssen Sie die Architektur Ihres gesamten Systems sorgfältig prüfen Teil eines Ausdrucks oder Parameter einer Funktion, andernfalls kann der Index nicht verwendet werden. 🎜 Beispielsweise kann die folgende Abfrage nicht den Index der Spalte „actor_id“ verwenden: 🎜#进行全表查询,没有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_%'; EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_'; #有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE 'ptd_%';
SELECT * FROM `user` WHERE username LIKE '张%';
actor_id und film_id als mehrspaltige Indizes festzulegen. Yuanfudao hat eine Frage. Weitere Informationen finden Sie unter dem Link. Dies kann Ihnen helfen, die Frage besser zu verstehen. 🎜SELECT * FROM t WHERE id IN (2,3)SELECT * FROM t1 WHERE username IN (SELECT username FROM t2)
customer_id selektiver als staff_id, daher ist es am besten, die Spalte customer_id vor dem mehrspaltigen Index zu platzieren. 🎜SELECT * FROM t WHERE id BETWEEN 2 AND 3
BLOB, TEXT und VARCHAR müssen Präfixindizes verwendet werden, um nur die Anfangszeichen zu indizieren. 🎜🎜Die Auswahl der Präfixlänge muss basierend auf der Indexselektivität bestimmt werden. 🎜5.覆盖索引
索引包含所有需要查询的字段的值。具有以下优点:
1.索引通常远小于数据行的大小,只读取索引能大大减少数据访问量。
2.一些存储引擎(例如 MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
3.对于 InnoDB 引擎,若辅助索引能够覆盖查询,则无需访问主索引。
6.优先使用索引,避免全表扫描
mysql在使用like进行模糊查询的时候把%放后面,避免开头模糊查询
因为mysql在使用like查询的时候只有使用后面的%时,才会使用到索引。
如:’%ptd_’ 和 ‘%ptd_%’ 都没有用到索引;而 ‘ptd_%’ 使用了索引。
#进行全表查询,没有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_%'; EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_'; #有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE 'ptd_%';
再比如:经常用到的查询数据库中姓张的所有人:
SELECT * FROM `user` WHERE username LIKE '张%';
7.尽量避免使用in 和not in,会导致数据库引擎放弃索引进行全表扫描。
比如:
SELECT * FROM t WHERE id IN (2,3)SELECT * FROM t1 WHERE username IN (SELECT username FROM t2)
优化方式:如果是连续数值,可以用between代替。如下:
SELECT * FROM t WHERE id BETWEEN 2 AND 3
如果是子查询,可以用exists代替。如下:
SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 WHERE t1.username = t2.username)
8.尽量避免使用or,会导致数据库引擎放弃索引进行全表扫描
如:
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1UNIONSELECT * FROM t WHERE id = 3
9.尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描
SELECT * FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT * FROM t WHERE score = 0
10.尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描
同第1个,单独的列;
SELECT * FROM t2 WHERE score/10 = 9SELECT * FROM t2 WHERE SUBSTR(username,1,2) = 'li'
优化方式:可以将表达式、函数操作移动到等号右侧。如下:
SELECT * FROM t2 WHERE score = 10*9SELECT * FROM t2 WHERE username LIKE 'li%'
11.当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描
SELECT * FROM t WHERE 1=1
优化方式:用代码拼装sql时进行判断,没where加where,有where加and。
索引的好处:建立索引后,查询时不会扫描全表,而会查询索引表锁定结果。索引的缺点:在数据库进行DML操作的时候,除了维护数据表之外,还需要维护索引表,运维成本增加。应用场景:数据量比较大,查询字段较多的情况。
索引规则:
1.选用选择性高的字段作为索引,一般unique的选择性最高;
2.复合索引:选择性越高的排在越前面。(左前缀原则);
3.如果查询条件中两个条件都是选择性高的,最好都建索引;
23.SQL优化之查询优化
1.使用Explain进行分析
Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
比较重要的字段有:
select_type: 查询类型,有简单查询、联合查询、子查询等;key: 使用的索引;rows: 扫描的行数;
2.优化数据访问
1.减少请求的数据量
只返回必要的列:最好不要使用
SELECT *语句。
只返回必要的行:使用LIMIT语句来限制返回的数据。
缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
2.减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
3.重构查询方式
1.切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
2.分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
Machen Sie das Caching effizienter: Wenn sich bei Join-Abfragen eine der Tabellen ändert, kann nicht der gesamte Abfrage-Cache verwendet werden. Bei mehreren Abfragen nach der Zerlegung kann der Abfragecache für andere Tabellen weiterhin verwendet werden, auch wenn sich eine Tabelle ändert.
Zerlegen Sie es in mehrere Einzeltabellenabfragen. Die zwischengespeicherten Ergebnisse dieser Einzeltabellenabfragen werden mit größerer Wahrscheinlichkeit von anderen Abfragen verwendet, wodurch redundante Datensatzabfragen reduziert werden.
Reduzieren Sie Sperrenkonflikte.
Durch die Verbindung auf Anwendungsebene lässt sich die Datenbank einfacher aufteilen, wodurch eine hohe Leistung und Skalierbarkeit erreicht wird.
Auch die Effizienz der Abfrage selbst kann verbessert werden. Im folgenden Beispiel ermöglicht die Verwendung von IN() anstelle einer Join-Abfrage beispielsweise, dass MySQL in ID-Reihenfolge abfragt, was möglicherweise effizienter ist als ein zufälliger Join.
SELECT * FROM tab JOIN tag_post ON tag_post.tag_id=tag.id JOIN post ON tag_post.post_id=post.id WHERE tag.tag='mysql'; SELECT * FROM tag WHERE tag='mysql'; SELECT * FROM tag_post WHERE tag_id=1234; SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
24.分析查询语句
通过对查询语句的分析,可以了解查询语句执行的情况,找出查询语句执行的瓶颈,从而优化查询语句。mysql中提供了EXPLAIN语句和
DESCRIBE语句,用来分析查询语句。EXPLAIN语句的基本语法如下:
EXPLAIN [EXTENDED] SELECT select_options;
使用EXTENED关键字,EXPLAIN语句将产生附加信息。select_options是select语句的查询选项,包括from where子句等等。
执行该语句,可以分析EXPLAIN后面的select语句的执行情况,并且能够分析出所查询的表的一些特征。
例如:EXPLAIN SELECT * FROM user;
查询结果进行解释说明:
a、id:select识别符,这是select的查询序列号。
b、select_type:标识select语句的类型。
它可以是以下几种取值:
b1、SIMPLE(simple)表示简单查询,其中不包括连接查询和子查询。
b2、PRIMARY(primary)表示主查询,或者是最外层的查询语句。
b3、UNION(union)表示连接查询的第2个或者后面的查询语句。
b4、DEPENDENT UNION(dependent union)连接查询中的第2个或者后面的select语句。取决于外面的查询。
b5、UNION RESULT(union result)连接查询的结果。
b6、SUBQUERY(subquery)子查询的第1个select语句。
b7、DEPENDENT SUBQUERY(dependent subquery)子查询的第1个select,取决于外面的查询。
b8、DERIVED(derived)导出表的SELECT(FROM子句的子查询)。
c、table:表示查询的表。
d、type:表示表的连接类型。
下面按照从最佳类型到最差类型的顺序给出各种连接类型。
d1、system,该表是仅有一行的系统表。这是const连接类型的一个特例。
d2、const,数据表最多只有一个匹配行,它将在查询开始时被读取,并在余下的查询优化中作为常量对待。const表查询速度很快,因为它们只读一次。const用于使用常数值比较primary key或者unique索引的所有部分的场合。
例如:EXPLAIN SELECT * FROM user WHERE id=1;
d3、eq_ref,对于每个来自前面的表的行组合,从该表中读取一行。当一个索引的所有部分都在查询中使用并且索引是UNIQUE或者PRIMARY KEY时候,即可使用这种类型。eq_ref可以用于使用“=”操作符比较带索引的列。比较值可以为常量或者一个在该表前面所读取的表的列的表达式。
例如:EXPLAIN SELECT * FROM user,db_company WHERE user.company_id = db_company.id;
d4、ref对于来自前面的表的任意行组合,将从该表中读取所有匹配的行。这种类型用于所以既不是UNION也不是primaey key的情况,或者查询中使用了索引列的左子集,即索引中左边的部分组合。ref可以用于使用=或者操作符的带索引的列。
d5、ref_or_null,该连接类型如果ref,但是如果添加了mysql可以专门搜索包含null值的行,在解决子查询中经常使用该连接类型的优化。
d6、index_merge,该连接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
d7、unique_subquery,该类型替换了下面形式的in子查询的ref。是一个索引查询函数,可以完全替代子查询,效率更高。
d8、index_subquery,该连接类型类似于unique_subquery,可以替换in子查询,但是只适合下列形式的子查询中非唯一索引。
d9、range,只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。key_len包含所使用索引的最长关键元素。当使用=,,>,>=,,between或者in操作符,用常量比较关键字列时,类型为range。
d10、index,该连接类型与all相同,除了只扫描索引树。着通常比all快,引文索引问价通常比数据文件小。
d11、all,对于前面的表的任意行组合,进行完整的表扫描。如果表是第一个没有标记const的表,这样不好,并且在其他情况下很差。通常可以增加更多的索引来避免使用all连接。
e.possible_keys:possible_keys列指出mysql能使用那个索引在该表中找到行。如果该列是null,则没有相关的索引。在这种情况下,可以通过检查where子句看它是否引起某些列或者适合索引的列来提高查询性能。如果是这样,可以创建适合的索引来提高查询的性能。
f、key:表示查询实际使用到的索引,如果没有选择索引,该列的值是null,要想强制mysql使用或者忽视possible_key列中的索引,在查询中使用force index、use index或者ignore index。
g、key_len:表示mysql选择索引字段按照字节计算的长度,如果健是null,则长度为null。注意通过key_len值可以确定mysql将实际使用一个多列索引中的几个字段。
h、ref:表示使用那个列或者常数或者索引一起来查询记录。
i、rows:显示mysql在表中进行查询必须检查的行数。
j、Extra: Die detaillierten Informationen dieser Spalte, wenn MySQL die Abfrage verarbeitet.
Empfohlenes Lernen: MySQL-Video-Tutorial
Das obige ist der detaillierte Inhalt vonSuper detaillierte Zusammenfassung der praktischen Fähigkeiten zur MySQL-Optimierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 So installieren Sie MySQL in CentOS7
Apr 14, 2025 pm 08:30 PM
So installieren Sie MySQL in CentOS7
Apr 14, 2025 pm 08:30 PM
Der Schlüssel zur eleganten Installation von MySQL liegt darin, das offizielle MySQL -Repository hinzuzufügen. Die spezifischen Schritte sind wie folgt: Laden Sie den offiziellen GPG -Schlüssel von MySQL herunter, um Phishing -Angriffe zu verhindern. Add MySQL repository file: rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm Update yum repository cache: yum update installation MySQL: yum install mysql-server startup MySQL service: systemctl start mysqld set up booting
