
Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis, das hauptsächlich Probleme im Zusammenhang mit konsistentem Hashing und Hash-Slots vorstellt. Wenn eine Erweiterung auftritt oder Knoten verloren gehen, werden Sie auf eine große Anzahl von Problemen bei der Datenmigration und Konsistenz stoßen Vermeiden Sie dieses Problem. Ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: Redis-Lerntutorial
Wenn wir jetzt x Cache-Geräte haben, können wir %x eingeben, um zu entscheiden, auf welchem Cache-Gerät die Daten abgelegt werden sollen. Wenn jedoch eine Erweiterung erfolgt oder der Knoten verloren geht, können Sie %x eingeben Sie benötigen den Schlüssel % (x ± y), sodass Sie auf viele Probleme bei der Datenmigration stoßen können. Konsistentes Hashing und Hash-Slots können dieses Problem vermeiden.
Ein gewöhnlicher Hash besteht darin, den Rest einer bestimmten Anzahl (2^32) zu übernehmen Wir vergleichen die IP des Servers oder andere. Der Rest der eindeutigen Kennung wird verwendet, um einen Wert zu erhalten. Dieser Wert ist die Position des Servers auf dem Hash-Ring. Anschließend wird das auf dem Server platzierte Objekt gehasht, um einen Wert zu erhalten. Ändern Sie den Hash, um den entsprechenden Server zu finden. Wenn sich an dem Ort, an dem sich der Wert befindet, kein Server befindet, suchen Sie nach einem Ort, an dem die Server wissen, wo sich der Speicher befindet.
Hashen Sie den entsprechenden Schlüssel gemäß dem häufig verwendeten Hash-Algorithmus in einen Raum mit 2 hoch 32 Knoten, also in einen digitalen Raum von 0 ~ (2 bis 32)-1 . Wir können uns dieses Ding als etwas vorstellen, das sich in den Schwanz beißt und einen geschlossenen Kreislauf bildet. 
Da der Ring nun da ist, müssen wir den Server an den Ring anschließen. Wir können die Nummer und andere eindeutige Kennungen basierend auf der IP-Adresse des Servers ermitteln , nimm das Haschisch und stecke es auf den Ring. 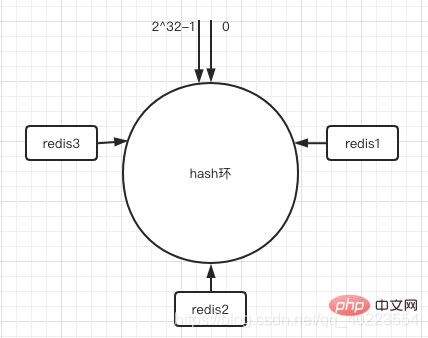
Wenn wir Daten auf den Server legen müssen, müssen wir zuerst den Hashwert der Daten berechnen und dann den Restwert ermitteln auf dem Ring Der Server fügt es direkt ein. Wenn es nicht vorhanden ist, wird eine Rückwärtssuche durchgeführt. 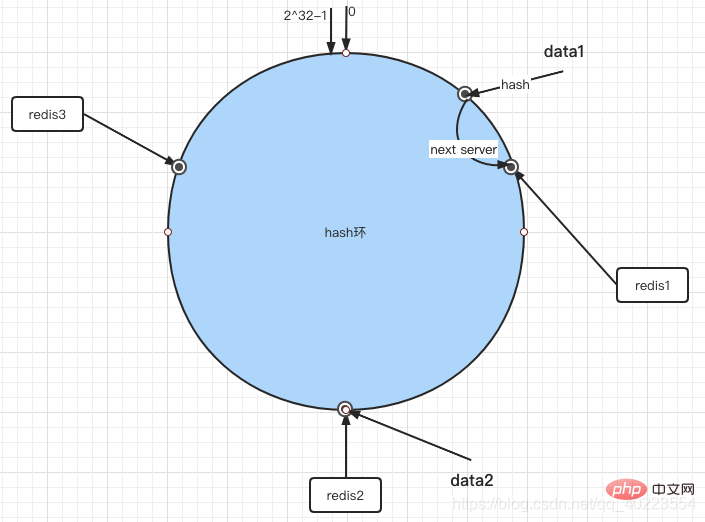
Endlich sind Daten1 in Redis1 und Daten2 in Redis2. Wenn wir Daten erhalten, führen wir denselben Prozess durch, berechnen den Hash-Wert des Schlüssels und rufen dann den gespeicherten Server nach denselben Regeln ab.
Wenn ein Redis-Knoten jetzt hängt, sind die Daten in anderen Knoten weiterhin vorhanden und die Daten im ursprünglichen Knoten werden auf den nächsten Knoten umverteilt.
Wenn Sie der Umgebung einen neuen Server RedisNeo hinzufügen, RedisNeo über den Hash-Algorithmus dem Ring zuordnen und die Migrationsregeln im Uhrzeigersinn befolgen, werden die Daten mit dem vorherigen Hash-Wert zwischen Redis2 und RedisNeo zu RedisNeo migriert (in der Abbildung). unten) RedisNeo steht neben Redis2) und andere Objekte behalten weiterhin ihre ursprünglichen Speicherorte. Durch die Analyse des Hinzufügens und Löschens von Knoten behält der konsistente Hash-Algorithmus die Monotonie bei und minimiert gleichzeitig die Datenmigration. Ein solcher Algorithmus eignet sich sehr gut für verteilte Cluster und vermeidet eine große Datenmigration, wodurch der Druck auf den Server verringert wird. 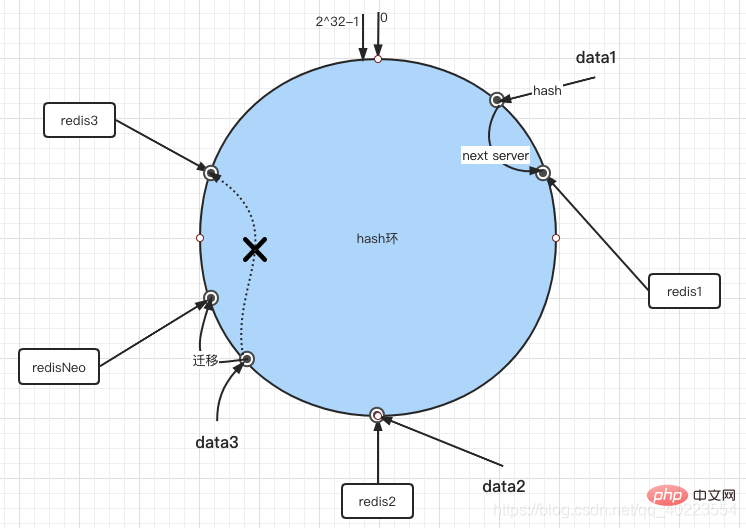
Nachdem also redisNeo hinzugefügt wurde, gehen data3 in redisNeo. 5. Balance Aus der folgenden Abbildung können wir ersehen, dass bei relativ wenigen Serverknoten ein Problem auftritt, das heißt, dass sich zwangsläufig eine große Datenmenge auf einen Knoten konzentriert. Wenn Sie beispielsweise nur zwei Knoten haben, einen 1 und der andere bei 10, dann wird es sehr schwierig sein, den Druck auf Knoten 1 unendlich groß zu machen, da nur diejenigen mit Hash-Werten zwischen [2,10] zu Knoten 10 gehen und die anderen zu Knoten 1 gehen Knoten 1. Um dieses Datenversatzproblem zu lösen, konsistentes Hashing Der Algorithmus führt einen virtuellen Knotenmechanismus ein, dh für jeden Dienstknoten werden mehrere Hashes berechnet und an jeder Berechnungsergebnisposition, die als a bezeichnet wird, ein Dienstknoten platziert virtueller Knoten. Die spezifische Methode kann darin bestehen, zunächst die Anzahl der jedem physischen Knoten zugeordneten virtuellen Knoten zu ermitteln und diese dann nach der IP oder dem Hostnamen hinzuzufügen. Gleichzeitig bleibt der Datenpositionierungsalgorithmus bis auf die Zuordnung virtueller Knoten unverändert zu tatsächlichen Knoten.
Der Hash-Slot wird im Redis-Cluster-Cluster-Schema verwendet. Der Redis-Cluster-Cluster verwendet kein konsistentes Hash-Schema, sondern verwendet den Hash-Slot im Daten-Sharding für die Datenspeicherung und das Lesen. Der Redis-Cluster verwendet Hash-Slots von Daten-Shards zur Datenspeicherung und zum Datenlesen. Der Redis-Cluster verfügt über insgesamt 2^14 (16384) Slots. Alle Master-Knoten haben einen Slot-Bereich wie 0~1000. Der Slave-Knoten des Master-Knotens weist keine Slots zu und hat nur Leserechte. Beachten Sie jedoch, dass der Redis-Cluster im Code Lese- und Schreibvorgänge auf dem Masterknoten ausführt. Es ist nicht der Slave-Knoten, der liest, und der Master-Knoten, der schreibt. Wenn ein Redis-Cluster zum ersten Mal erstellt wird, werden 16384 Slots vom Masterknoten gleichmäßig verteilt. 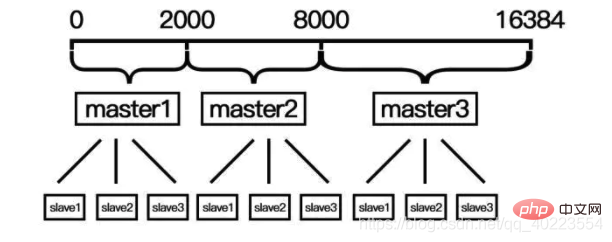
Im Vergleich zum konsistenten Hashing müssen Sie beim Erweitern und Verkleinern Hash-Slots manuell zuweisen, und beim Löschen des Master-Knotens müssen Sie seine Slave-Knoten und Hash-Slots an andere Master-Knoten weitergeben. Bestimmen Sie, zu welchem Slot er gehört basierend auf dem Wert von CRC-16(key)%16384.
Empfohlenes Lernen: Redis-Tutorial
Das obige ist der detaillierte Inhalt vonRedis-Cache lernt konsistenten Hash und Hash-Slot. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?












![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



