
 Datenbank
MySQL-Tutorial
Was ist die Implementierungsmethode der MySQL-Lese- und Schreibtrennung?
Datenbank
MySQL-Tutorial
Was ist die Implementierungsmethode der MySQL-Lese- und Schreibtrennung?
Was ist die Implementierungsmethode der MySQL-Lese- und Schreibtrennung?

In MySQL können Sie „MySQL-Proxy“ verwenden, um eine Lese-/Schreibtrennung zu erreichen. „MySQL-Proxy“ ist eine von MySQL offiziell bereitgestellte Software zur Implementierung einer Lese-/Schreibtrennung, die auch als Middleware bezeichnet wird und die Verarbeitung durch die Hauptdatenbank ermöglicht Bei der Verarbeitung von Abfragen aus der Datenbank wird die Datenbankkonsistenz durch Master-Slave-Replikation erreicht.

Die Betriebsumgebung dieses Tutorials: Windows10-System, MySQL8.0.22-Version, Dell G3-Computer.
Was ist die Implementierungsmethode der MySQL-Lese- und Schreibtrennung?
Zu den Plug-Ins in MySQL, die die Lese- und Schreibtrennung realisieren können, gehört MySQL-Proxy / Mycat / Amoeba Dieses Experiment wird hauptsächlich verwendet, um dies zu erreichen. MySQL-Proxy ist eine Software, die „Lese-/Schreibsplitting“ implementiert (offiziell von MySQL bereitgestellt, auch Middleware genannt). Die Datenbank verarbeitet Schreibvorgänge (Einfügen, Aktualisieren, Löschen) und verarbeitet gleichzeitig den Abfragevorgang (Auswählen) aus der Datenbank. Die Konsistenz der Datenbank wird durch Master-Slave-Replikation erreicht.
MySQL-Proxy kann die Unterscheidung zwischen Lese- und Schreibanweisungen hauptsächlich mithilfe eines internen Lua-Skripts realisieren (das die Beurteilung von Lese- und Schreibanweisungen realisieren kann)
Wenn ja Nur auf dem Hauptserver (Schreibvorgang ist auf dem Server abgeschlossen. Zu diesem Zeitpunkt wird der Schreibvorgang nicht auf dem Slave-Server ausgeführt. Zu diesem Zeitpunkt muss keine andere Technologie verwendet werden.) Um Datenkonsistenz zwischen Master- und Slave-Servern zu erreichen, ist die Master-Slave-Replikation die Grundlage der Lese-Schreib-Trennung (MySQL-Proxy). Der Master übernimmt den Schreibvorgang und lässt den Slave den Lesevorgang übernehmen. Dies eignet sich sehr gut für Szenarien mit relativ vielen Lesevorgängen und kann die Arbeitsbelastung des Masters reduzieren.
Verwenden Sie MySQL-Proxy, um die Lese-/Schreib-Trennung von MySQL zu realisieren MySQL-Proxy fungiert tatsächlich als Proxy für den Back-End-MySQL-Master-Slave-Server. Er nimmt die Anfrage des Clients direkt an, analysiert die SQL-Anweisung und bestimmt, ob es sich um eine Leseoperation oder eine Schreiboperation handelt zum entsprechenden MySQL-Server
Da der Schreibvorgang der Datenbank zeitaufwändiger ist als der Lesevorgang, löst die Trennung von Lesen und Schreiben der Datenbank das Problem des Schreibens in die Datenbank, was sich auf die Effizienz der Abfrage auswirkt
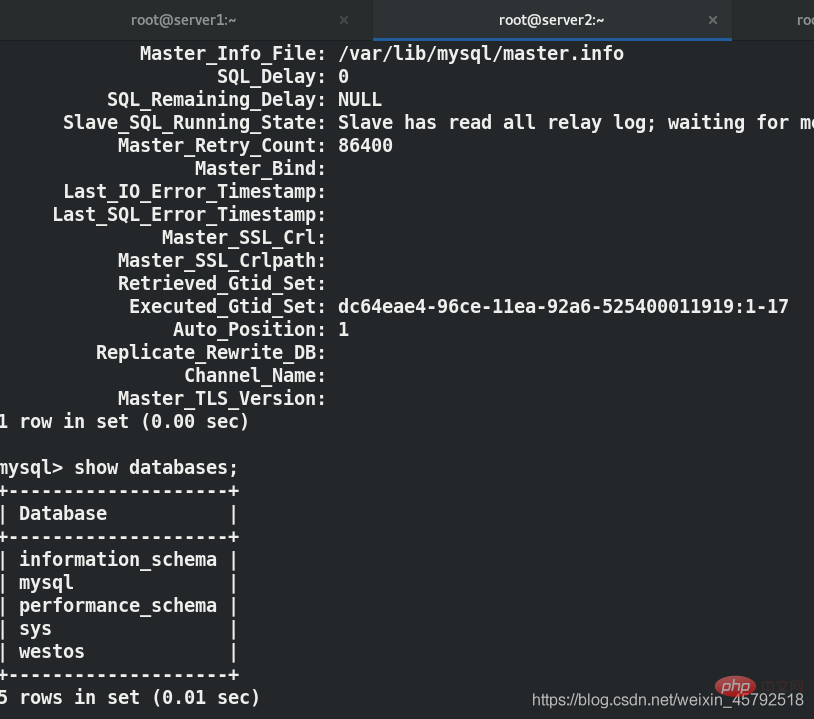
In Server1 konfigurieren Sie zuerst die GTID-Master-Slave-Replikation mit Server2.
GTID-Master-Slave-Replikation wurde im vorherigen Blog erklärt, daher werde ich hier nicht auf Details eingehen, sondern nur den endgültigen Effekt zeigen.
Sie können sehen, dass es sich um eine Westos-Datenbank handelt wird auf Server1 eingerichtet und der entsprechende Server2 wird synchronisiert.(1) Besorgen Sie sich die MySQL-Proxy-Installation von der physischen Maschine. Paket an Server3
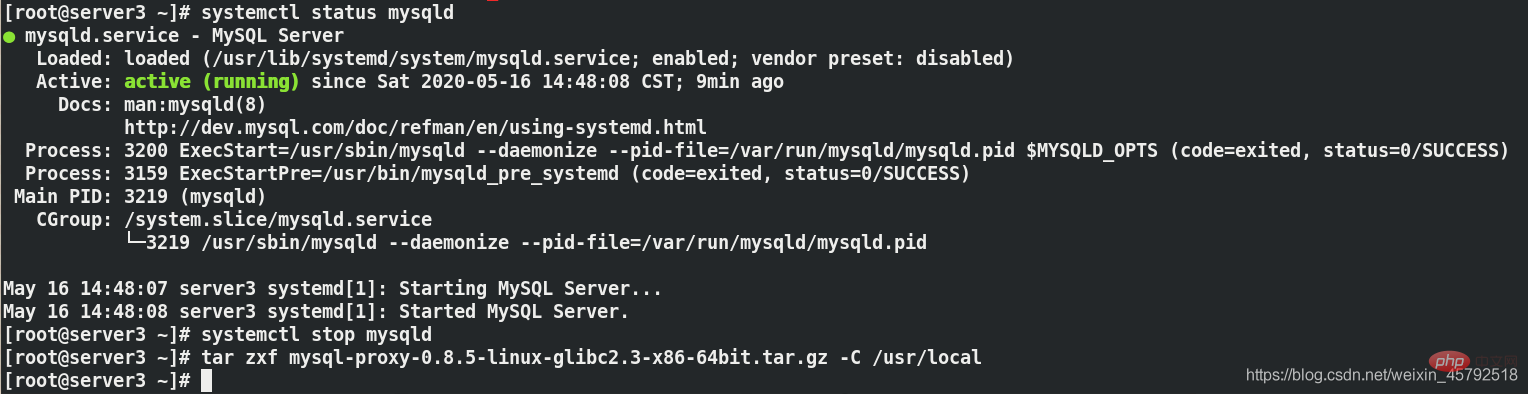
(2) Konfigurieren Sie auf Server3[root@server3 ~]# systemctl status mysqld ##查看mysqld服务状态 [root@server3 ~]# systemctl stop mysqld ##关闭mysqld服务,因为代理服务器要用3306端口 [root@server3 ~]# tar zxf mysql-proxy-0.8.5-linux-glibc2-x86-64bit.tar.gz -C /usr/local/ ##解压到/usr/local/目录下
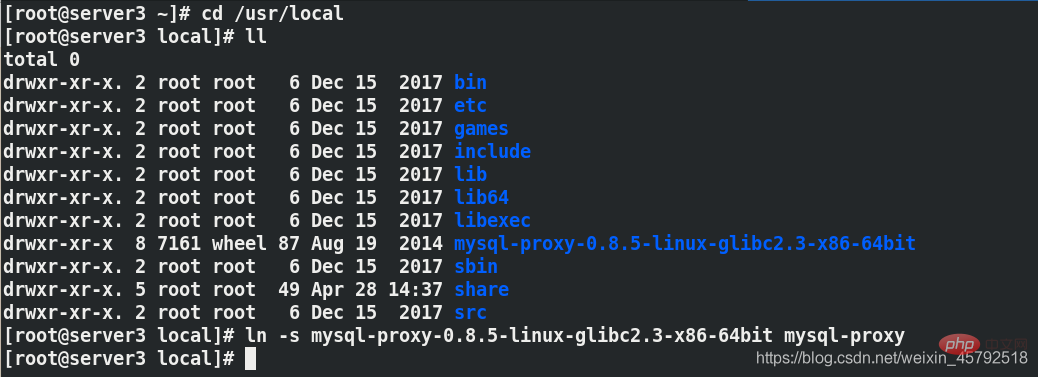
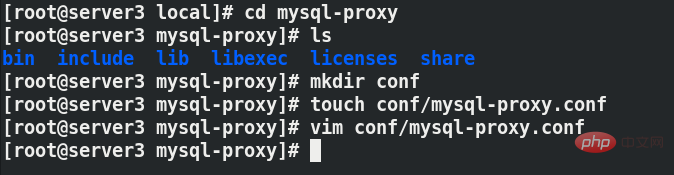
 Stellen Sie eine Soft-Verbindung für die Verwaltung her
Stellen Sie eine Soft-Verbindung für die Verwaltung herln -s mysql-proxy-0.8.5-linux-glibc2-x86-64bit mysql-proxy
 Es gibt keine Konfigurationsdatei im MySQL-Proxy-Verzeichnis, daher müssen Sie selbst eine Konfigurationsdatei erstellen. Verzeichnis, erstellen Sie die Konfigurationsdatei Um die Berechtigungen der Konfigurationsdatei auf 660 zu ändern, müssen Sie ein Protokollverzeichnis erstellen
Es gibt keine Konfigurationsdatei im MySQL-Proxy-Verzeichnis, daher müssen Sie selbst eine Konfigurationsdatei erstellen. Verzeichnis, erstellen Sie die Konfigurationsdatei Um die Berechtigungen der Konfigurationsdatei auf 660 zu ändern, müssen Sie ein Protokollverzeichnis erstellen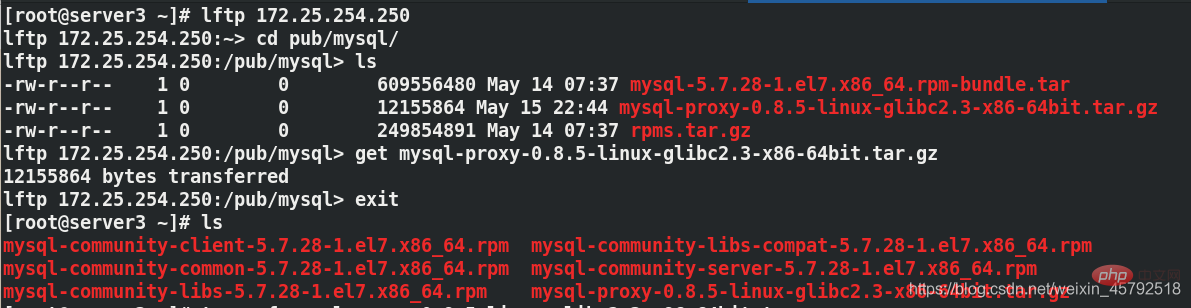
Ändern Sie die maximale und minimale Anzahl von Verbindungen, wenn in der Datenbank eine Lese-/Schreibtrennung auftritt
[root@server3 bin]# ./mysql-proxy --help [root@server3 bin]# ./mysql-proxy --help-proxy
(3) Starten Sie mysql-proxy
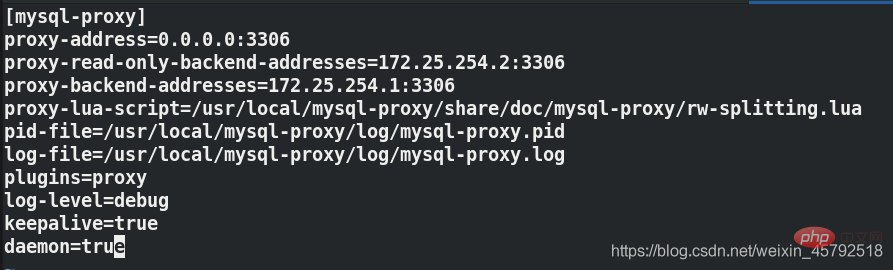
[mysql-proxy] ##指定语句块 proxy-address=0.0.0.0:3306 ##指定proxy访问的主机和端口,3306是一个对外的通用端口 proxy-read-only-backend-addresses=172.25.254.2:3306 ##读主机的ip和端口 proxy-backend-addresses=172.25.254.1:3306 ##执行写主机的ip和端口 proxy-lua-script=/usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua ##指定读写分离操作使用的lua文件路径 pid-file=/usr/local/mysql-proxy/log/mysql-proxy.pid ##pid存放路径 log-file=/usr/local/mysql-proxy/log/mysql-proxy.log ##日志存放路径 plugins=proxy ##指定使用的插件 log-level=debug ##日志的等级 keepalive=true ##开启守护进程 daemon=true ##使用后台方式运行
Lese-Schreib-Trennung testen
 (1) Erstellen Sie einen neuen Server auf Server1 Benutzer und autorisiert
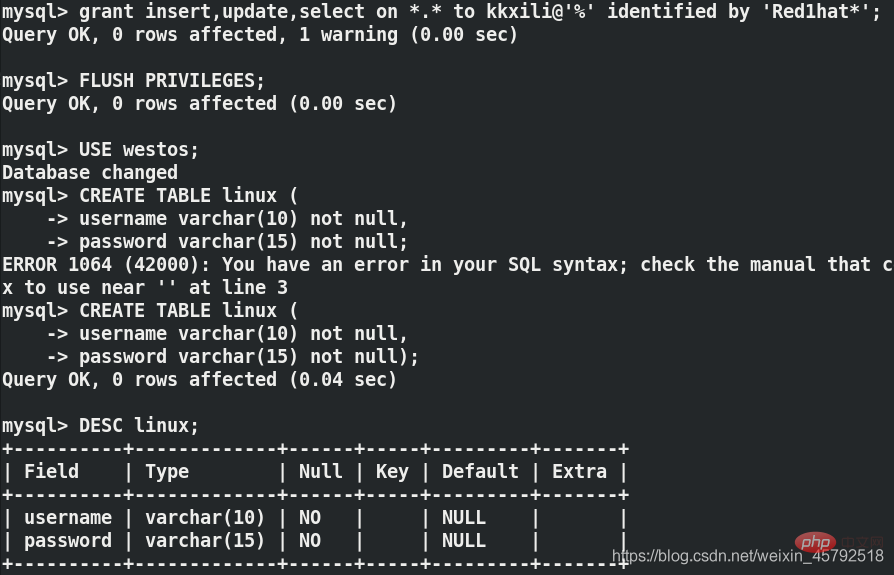
(1) Erstellen Sie einen neuen Server auf Server1 Benutzer und autorisiert
mysql> grant insert,update,select on *.* to kkxili@'%' identified by 'Red1hat*'; mysql> FLUSH PRIVILEGES; ##刷新授权表 mysql> USE westos; Database changed mysql> CREATE TABLE linux ( -> username varchar(10) not null, -> password varchar(15) not null); mysql>DESC linux;
(2)server3安装lsof

(3)在用户端虚拟机server4上第一次连接数据库代理server3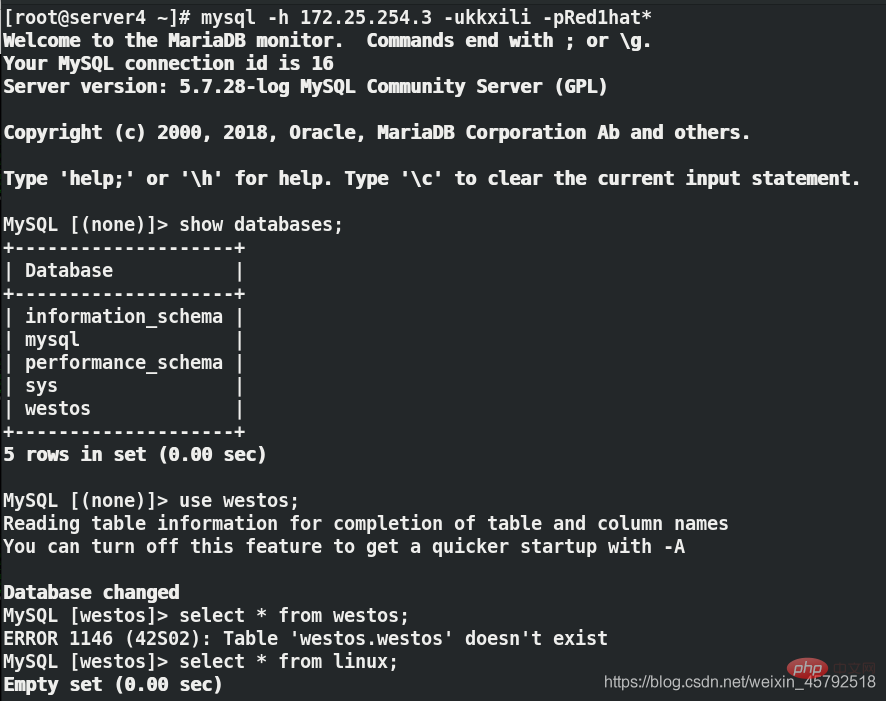
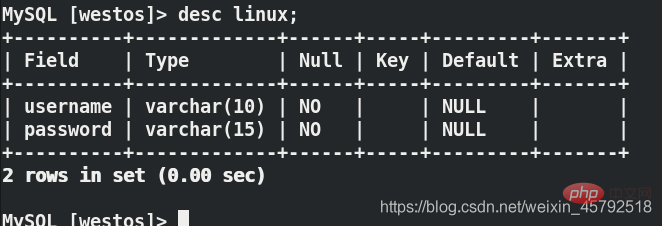
在server3上面:lsof -i:3306

(4)在用户端虚拟机server4上第二次连接数据库代理server3
在server3上面:lsof -i:3306

(5)在用户端虚拟机server4上第三次连接数据库代理server3
在server3上面:lsof -i:3306
开始读写分离
 上面是读写分离的读访问测试
上面是读写分离的读访问测试
写测试
在用户端插入数据
use westos;
insert into linux values('user1','123');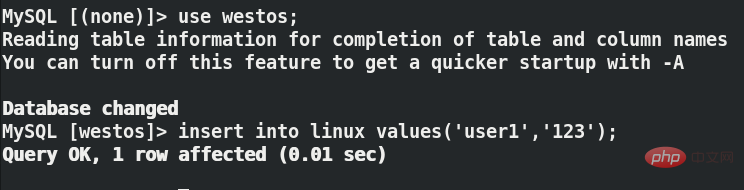
server1和server2都可以看到插入的数据
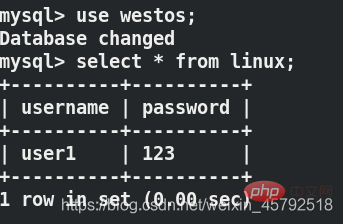
在server2中关闭主从复制
用户端再次写入数据,看不到刚刚写的数据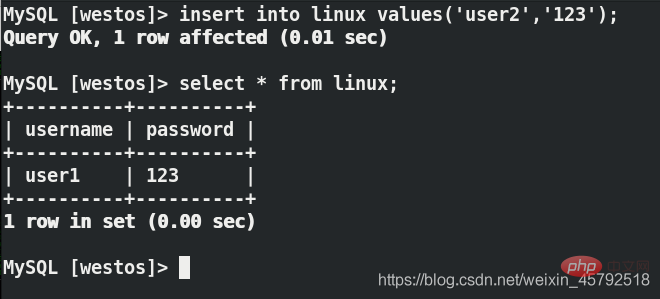
写在server1上,可以查看到数据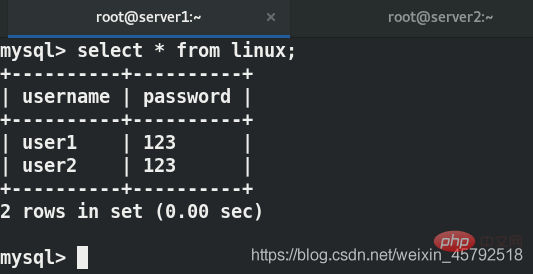
在server2上实现了读写分离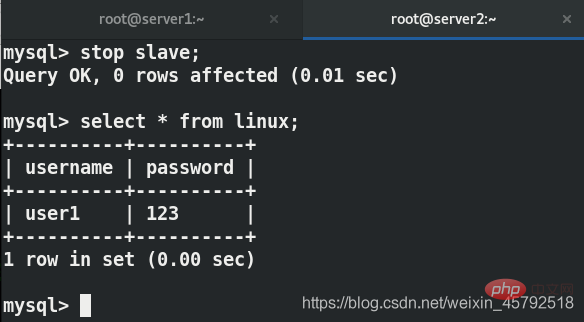
server2重新开启主从复制可以看到数据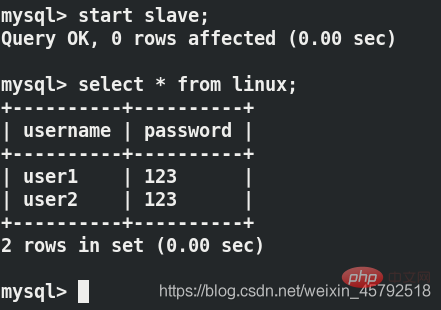
客户端读的是server2,server2只能读,不能写,因此看不到刚才写进去的东西,server1可以看到
实现了客户端(虚拟机)对server1的写,对server2的读
当访问数据库的用户数量很多时,数据库的代理就把后端的数据库实现读写分离
server1是写的数据库、server2是读的数据库
当server1和server2满足gtid的主从复制时,用户往数据库写入的数据其实是写入了server1,并没有写入server2,server2上面的数据是复制过去的,因此server1、server2、客户机上面都能查到刚刚写进去的数据,其实客户机查的是server2(读)
当关闭server1和server2的异步复制时,客户机往数据库写入的数据只写进了server1,没有写进去server2,server2也没有复制一份
因此server1可以查看到,server2和客户机上面都查不到刚刚写进去的数据,此时的客户机读的是server2
推荐学习:mysql视频教程
Das obige ist der detaillierte Inhalt vonWas ist die Implementierungsmethode der MySQL-Lese- und Schreibtrennung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
