

Detaillierte Erläuterung des Redis-Datenstrukturwissens mit Bildern und Texten

Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis. Er stellt hauptsächlich verwandte Themen zu Datenstrukturen vor, einschließlich Zeichenfolgen, Listen, Hashes, geordneten Mengen usw. Ich hoffe, dass er für alle nützlich sein wird.

Empfohlenes Lernen: Redis-Lerntutorial
Redis-Datenstruktur: String (Zeichenfolge), Liste (Liste), Hash (Hash), Set (Satz), Shorted Set (geordneter Satz)
Zugrunde liegende Datenstruktur : einfache dynamische Zeichenfolge, doppelt verknüpfte Liste, komprimierte Liste, Hash-Tabelle, Sprungliste, Ganzzahl-Array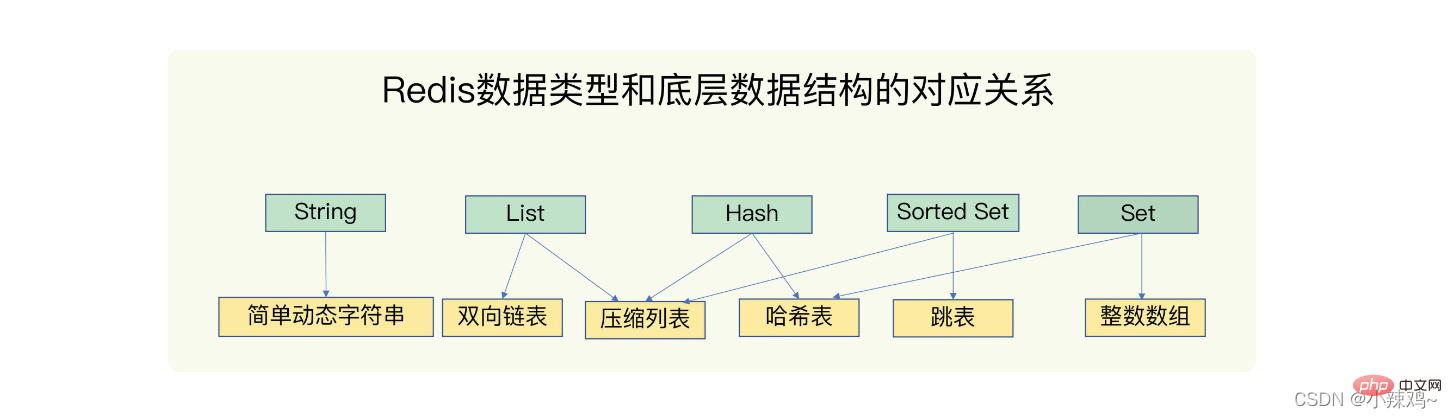
1. Hash-Tabelle: Eine Hash-Tabelle ist eigentlich ein Array, und jedes Element im Array wird als Hash-Bucket bezeichnet. 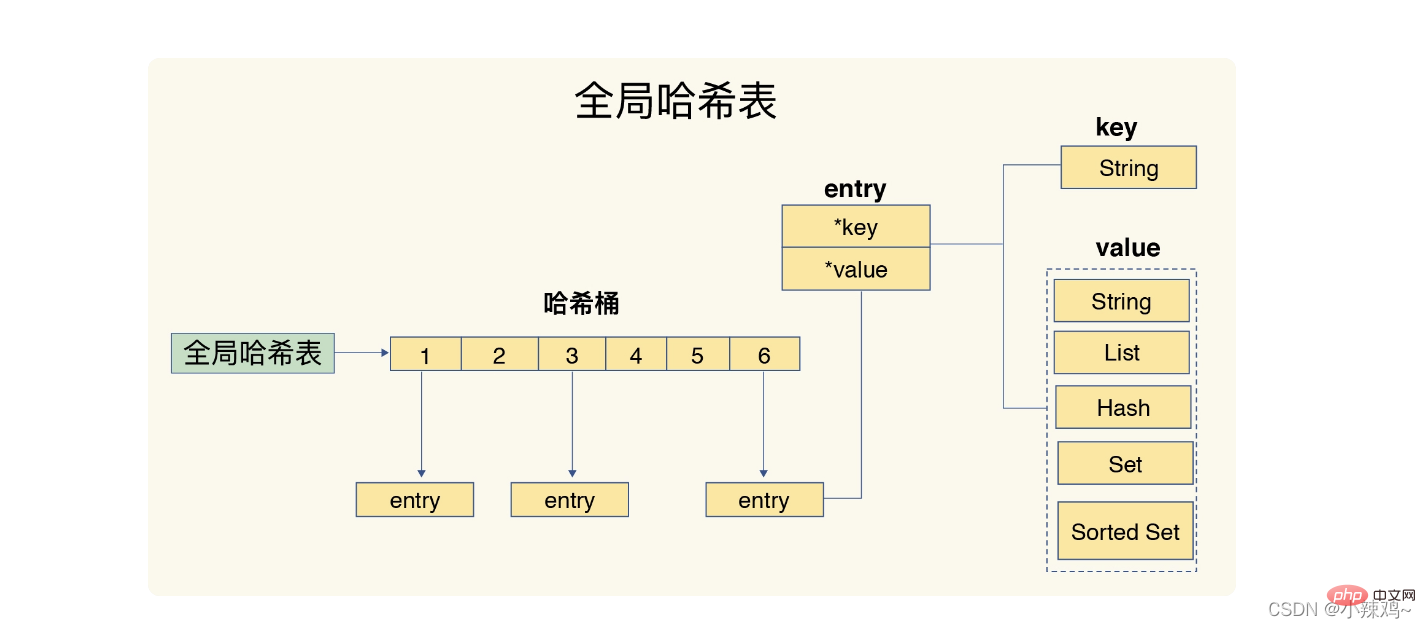
Hash-Konflikte und Rehash können zu einer Blockierung des Betriebs führen.
Die Methode von Redis zur Lösung von Hash-Konflikten ist das Ketten-Hashing, während Rehash darin besteht, die Anzahl vorhandener Hash-Buckets zu erhöhen. 🔜 Speicherplatz der Hash-Tabelle 1
Der zweite Schritt umfasst eine große Anzahl von Datenkopiervorgängen. Wenn alle Daten in der Hash-Tabelle 1 auf einmal migriert werden, wird der Thread blockiert und andere Anforderungen werden nicht bedient. Um dieses Problem zu vermeiden, verwendet Redis progressives Rehash Das Ende der Liste und die Liste Die Anzahl der Einträge in der Mitte 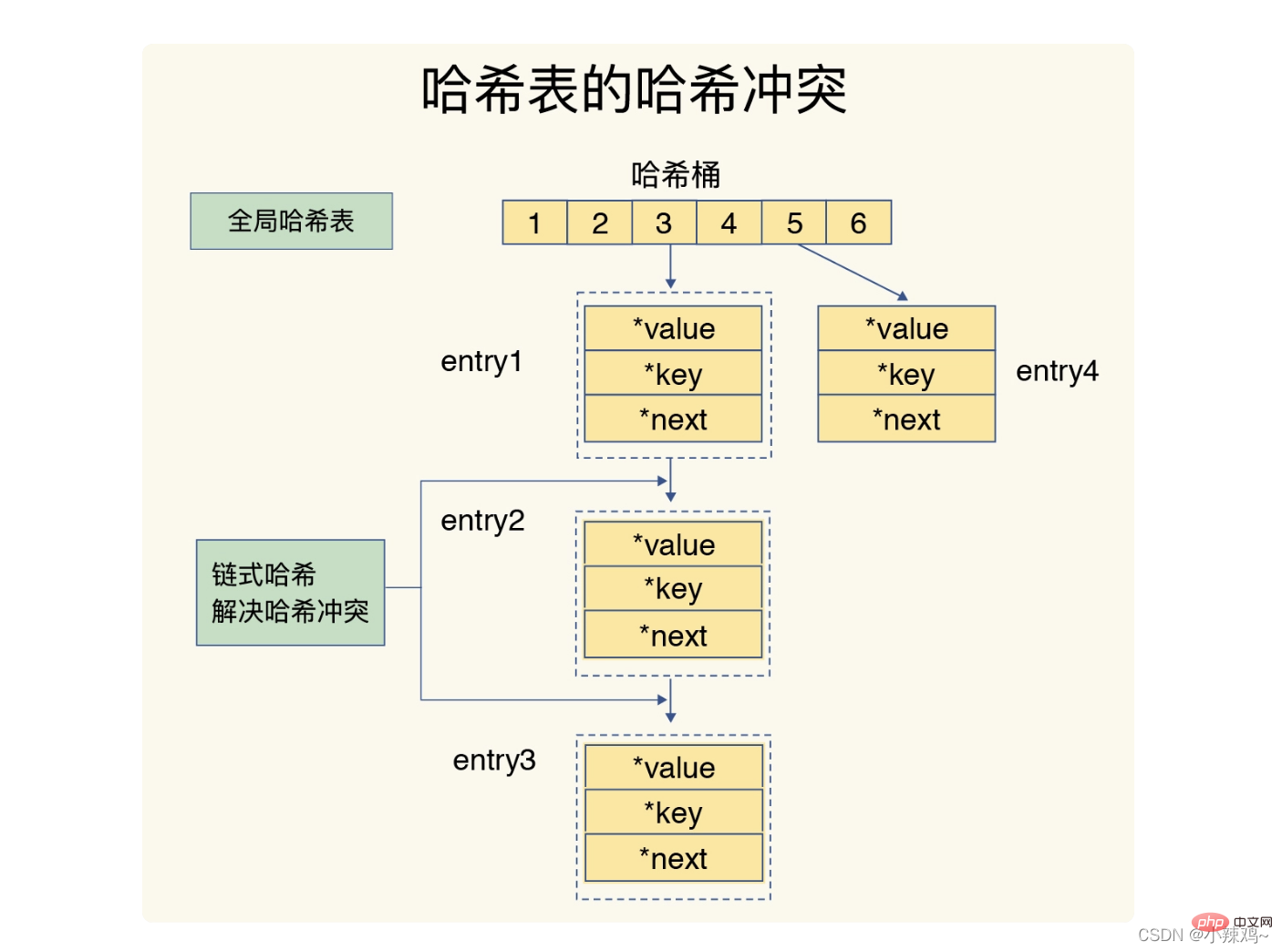 Die komprimierte Liste hat auch ein Element zlend am Ende der Tabelle, um das Ende der Liste darzustellen
Die komprimierte Liste hat auch ein Element zlend am Ende der Tabelle, um das Ende der Liste darzustellen
Liste überspringen: Eine geordnete verknüpfte Liste kann nur gefunden werden Elemente nacheinander, während eine Sprungliste einen mehrstufigen Index auf der Grundlage der verknüpften Liste hinzufügt. Durch mehrere Sprünge wird eine schnelle Positionierung der Daten erreicht
Die zeitliche Komplexität der folgenden fünf Strukturen 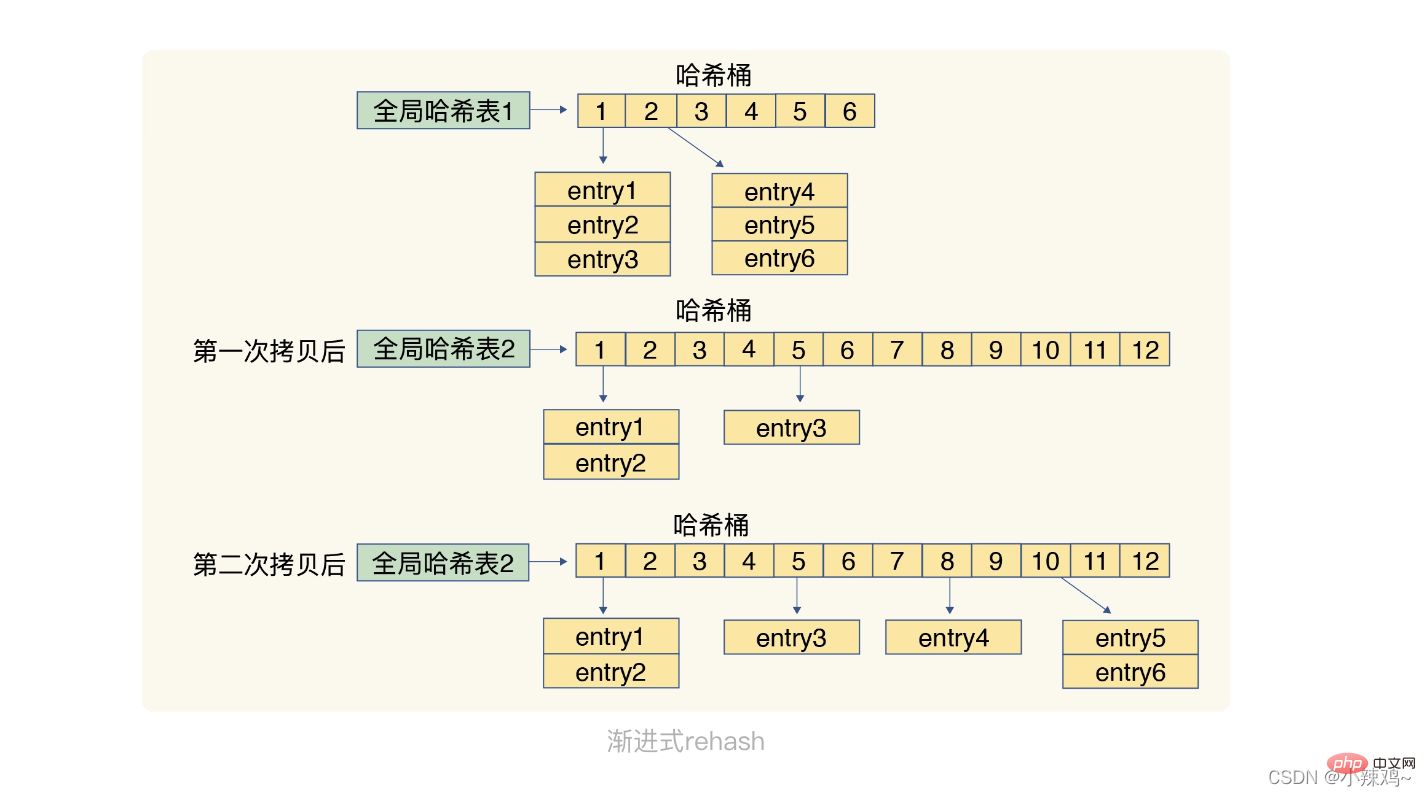
String Typ  String-Typ ist nicht für alle Szenarien geeignet. Er weist einen offensichtlichen Mangel beim Speichern von Daten auf. Da der String-Typ zusätzlichen Speicherplatz benötigt, um Datenlänge, Speicherplatznutzung und andere Informationen aufzuzeichnen, werden diese Informationen auch als Metadaten bezeichnet.
String-Typ ist nicht für alle Szenarien geeignet. Er weist einen offensichtlichen Mangel beim Speichern von Daten auf. Da der String-Typ zusätzlichen Speicherplatz benötigt, um Datenlänge, Speicherplatznutzung und andere Informationen aufzuzeichnen, werden diese Informationen auch als Metadaten bezeichnet.
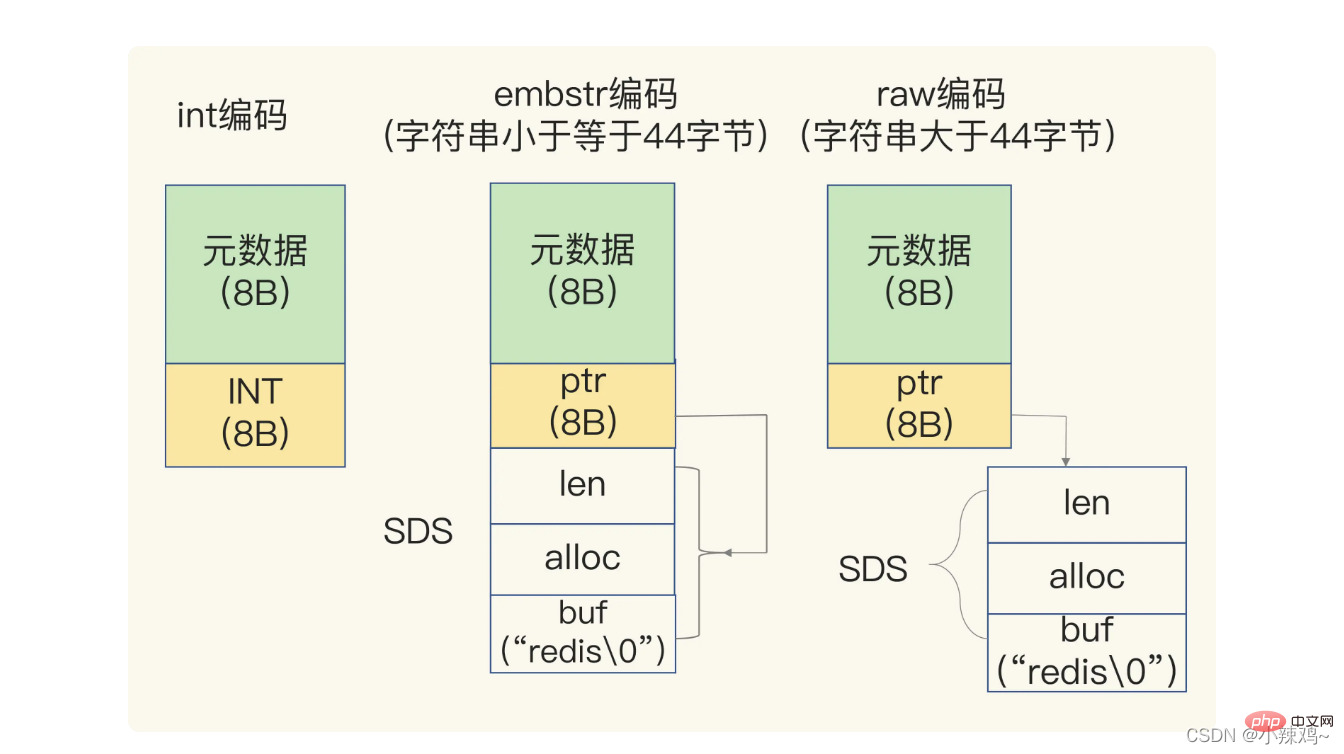
Wenn die gespeicherten Daten Zeichen enthalten, wird die Zeichenfolge mithilfe einer einfachen dynamischen Zeichenfolgen-SDS-Struktur gespeichert. 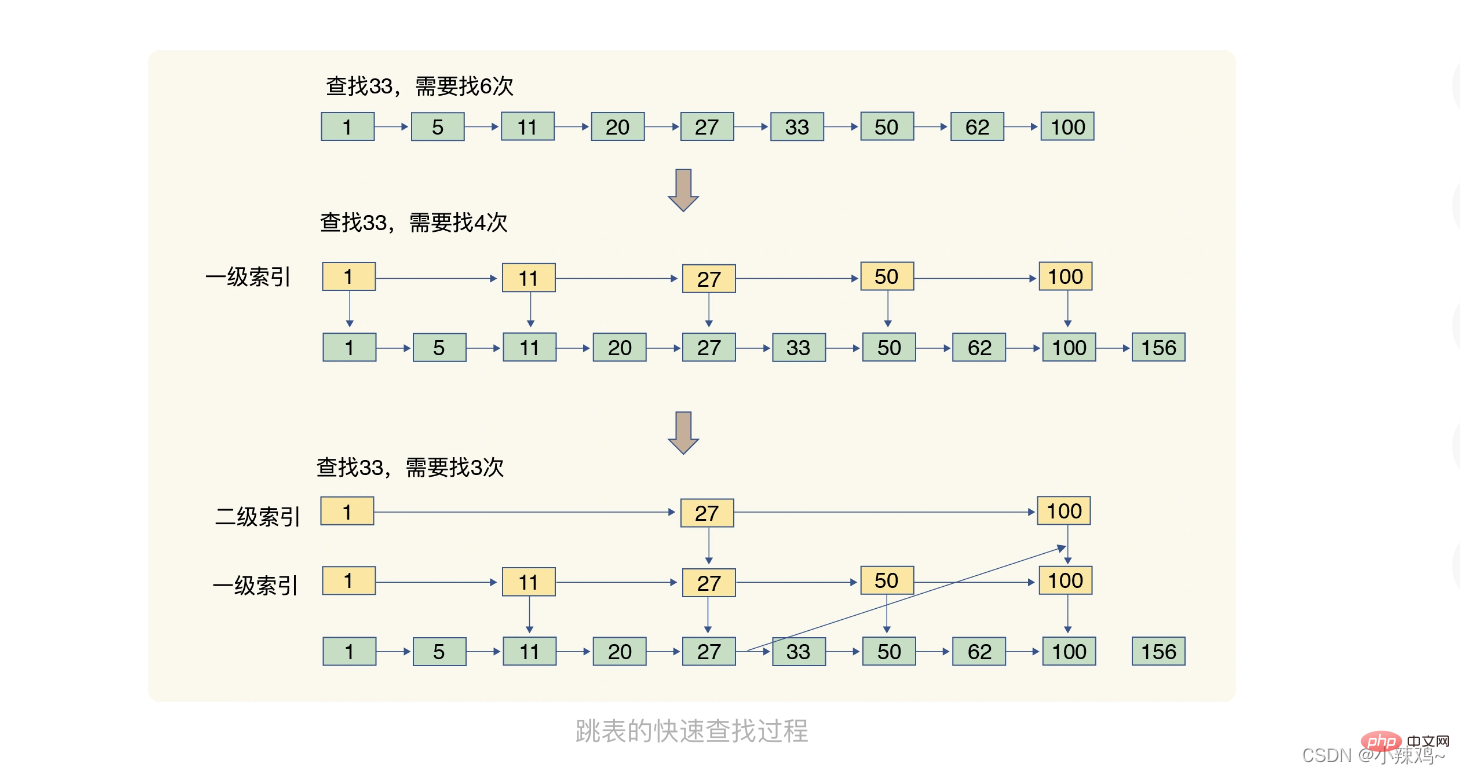
len ist die verwendete Länge von buf und alloc ist die tatsächlich zugewiesene Länge von buf. 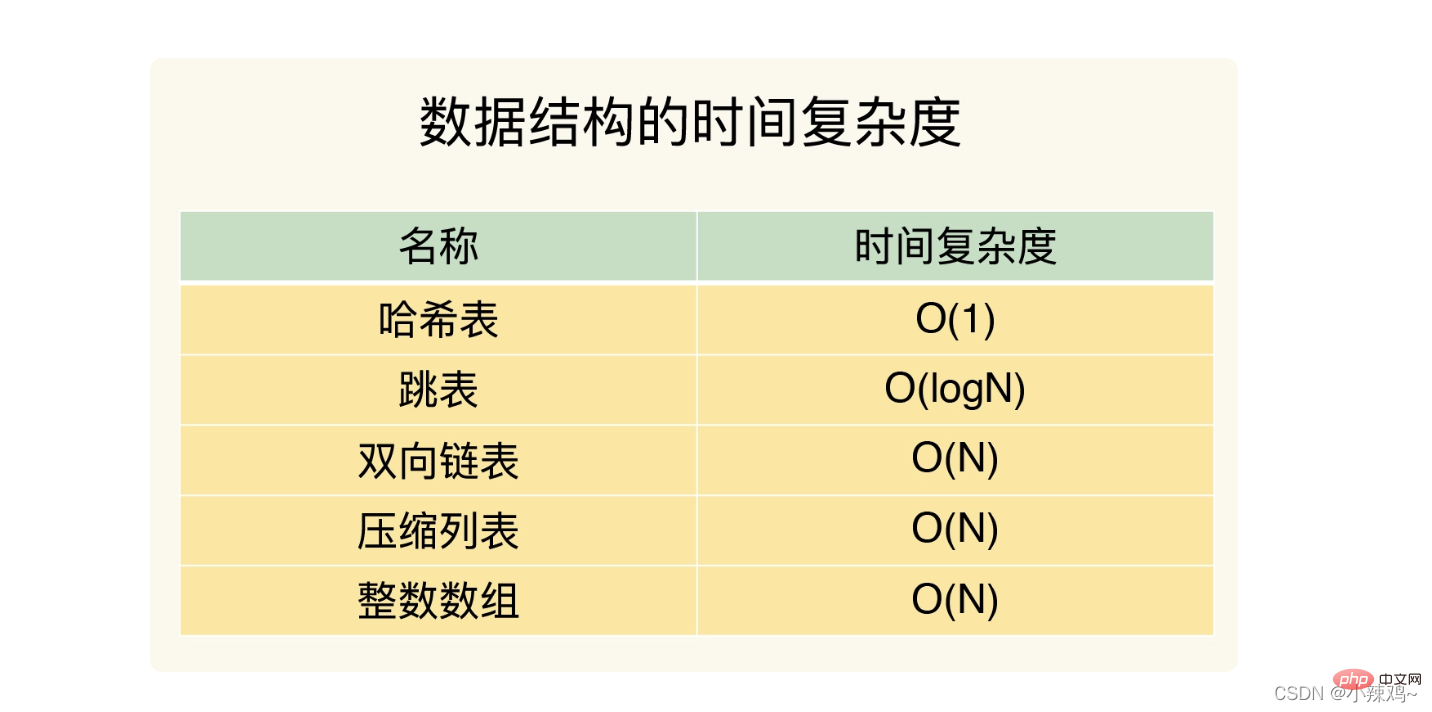 Da es viele Redis-Datentypen gibt, unterschiedliche Datentypen Es müssen dieselben Metadaten aufgezeichnet werden, daher verwendet Redis eine RedisObject-Struktur, um diese Metadaten einheitlich aufzuzeichnen.
Da es viele Redis-Datentypen gibt, unterschiedliche Datentypen Es müssen dieselben Metadaten aufgezeichnet werden, daher verwendet Redis eine RedisObject-Struktur, um diese Metadaten einheitlich aufzuzeichnen.
Wenn die gespeicherte Zeichenfolge weniger als 44 Bytes beträgt, werden SDS und Metadaten einem kontinuierlichen Speicherbereich zugewiesen, der als Embstr-Codierung bezeichnet wird.
Wenn die gespeicherte Zeichenfolge größer als 44 Bytes ist, werden SDS und Metadaten separat gespeichert und als Rohcodierung bezeichnet
Darüber hinaus verwendet Redis eine globale Hash-Tabelle, um alle Schlüssel-Wert-Paare zu speichern. Jedes Element in der Hash-Tabelle ist eine dictEntry-Struktur, die verwendet wird, um auf ein Schlüssel-Wert-Paar zu verweisen value+next verwendet 24 Bytes, belegt aber tatsächlich 32 Bytes. Dies liegt daran, dass jemalloc eine Potenz von 2 findet, die größer als N ist, aber N am nächsten kommt, basierend auf der Anzahl der von uns angewendeten Bytes für N, also Kann die Anzahl häufiger Zuweisungen reduzieren. 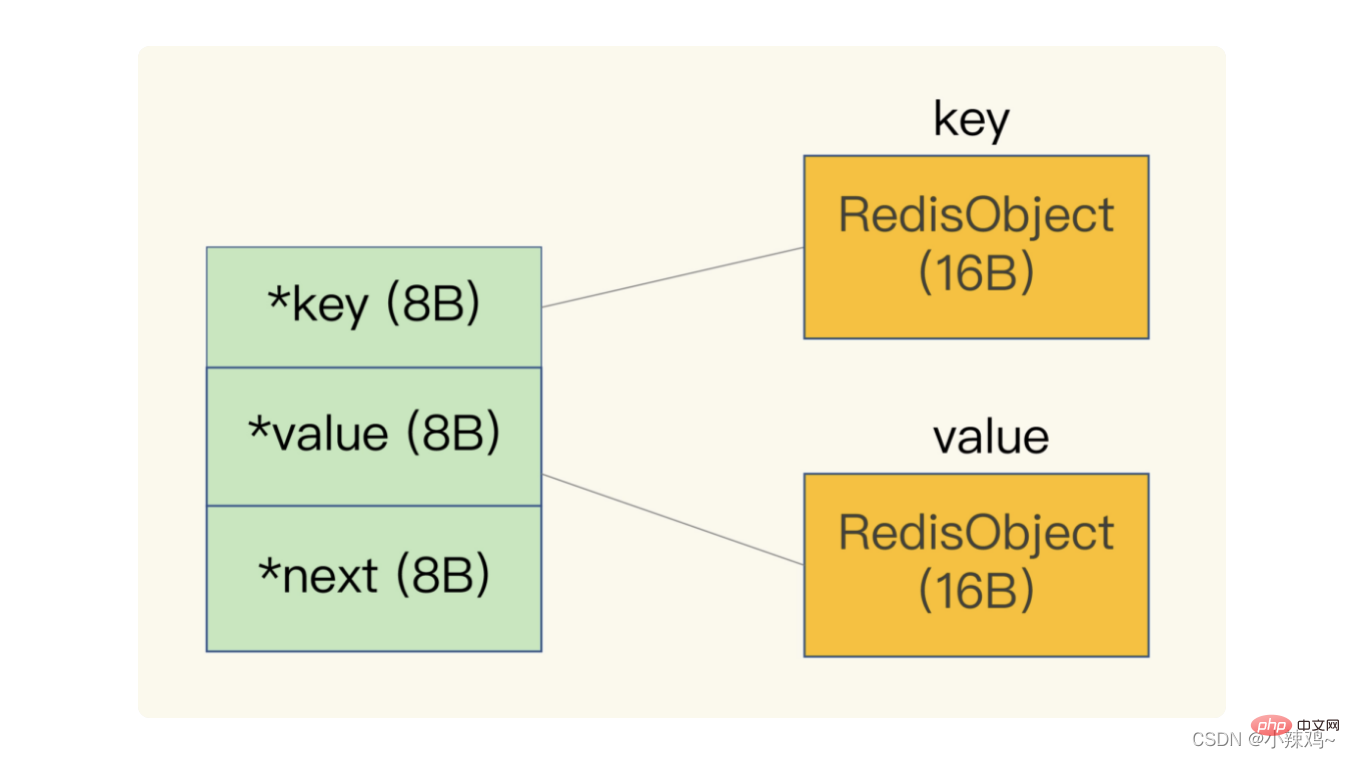
Welche Datenstruktur kann verwendet werden, um Speicherplatz zu sparen?
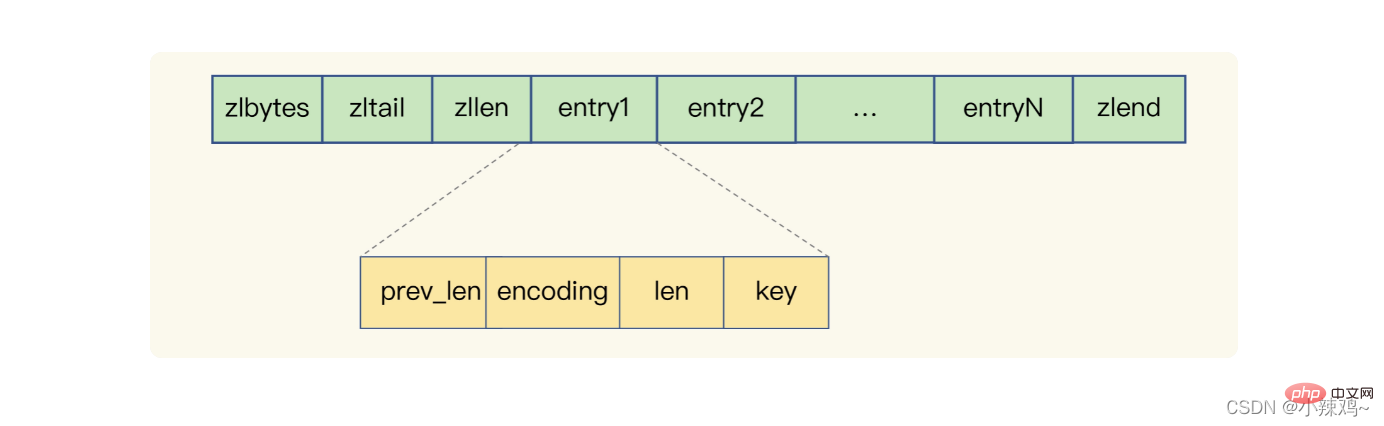
Komprimierte Liste: zlbytes repräsentiert die Länge der Liste, zltail repräsentiert den Endoffset der Liste, zllen repräsentiert die Anzahl der Einträge in der Liste, zlend repräsentiert das Ende der Liste, perv_len repräsentiert die Länge des vorherigen Eintrags, Kodierung stellt die Kodierungsmethode dar, len stellt seine eigene Länge dar, Schlüssel sind die tatsächlich gespeicherten Daten. Redis implementiert Liste, Hash und sortierte Menge basierend auf einer komprimierten Liste
Wie speichere ich einwertige Schlüssel-Wert-Paare mithilfe von Satztypen?
Beim Speichern von Einzelwert-Schlüssel-Wert-Paaren können Sie die sekundäre Codierung von Hash verwenden, bei der der Einzelwertwert in zwei Teile aufgeteilt wird. Der erste Teil wird als Schlüssel des Hash verwendet und der zweite Teil wird verwendet als Wert des Hash
以图片 ID 1101000060 和图片存储对象 ID 3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。127.0.0.1:6379> info memory# Memoryused_memory:1039120127.0.0.1:6379> hset 1101000 060 3302000080(integer) 1127.0.0.1:6379> info memory# Memoryused_memory:1039136
Hash Der Typ hat zwei zugrunde liegende Implementierungsstrukturen: 1. Komprimierte Liste 2. Hash-Tabelle
Es gibt zwei Schwellenwerte in der Hash-Liste. Sobald diese beiden Schwellenwerte überschritten werden, wird sie aus der komprimierten Liste konvertiert list zu einer Hash-Tabelle
Dargestellt durch hash-max-ziplist-entries Die maximale Anzahl von Elementen in der Hash-Liste, die beim Speichern mit einer komprimierten Liste festgelegt wird
hash-max-ziplist-value gibt die maximale Länge eines einzelnen Elements des Hashs an Wird beim Speichern mit einer komprimierten Liste festgelegt.
Statistikmodus festlegen. 1. Aggregationsstatistik 2.HyperLogLog
3.GEO:
GEO-Datentyp für LBS-Anwendungen
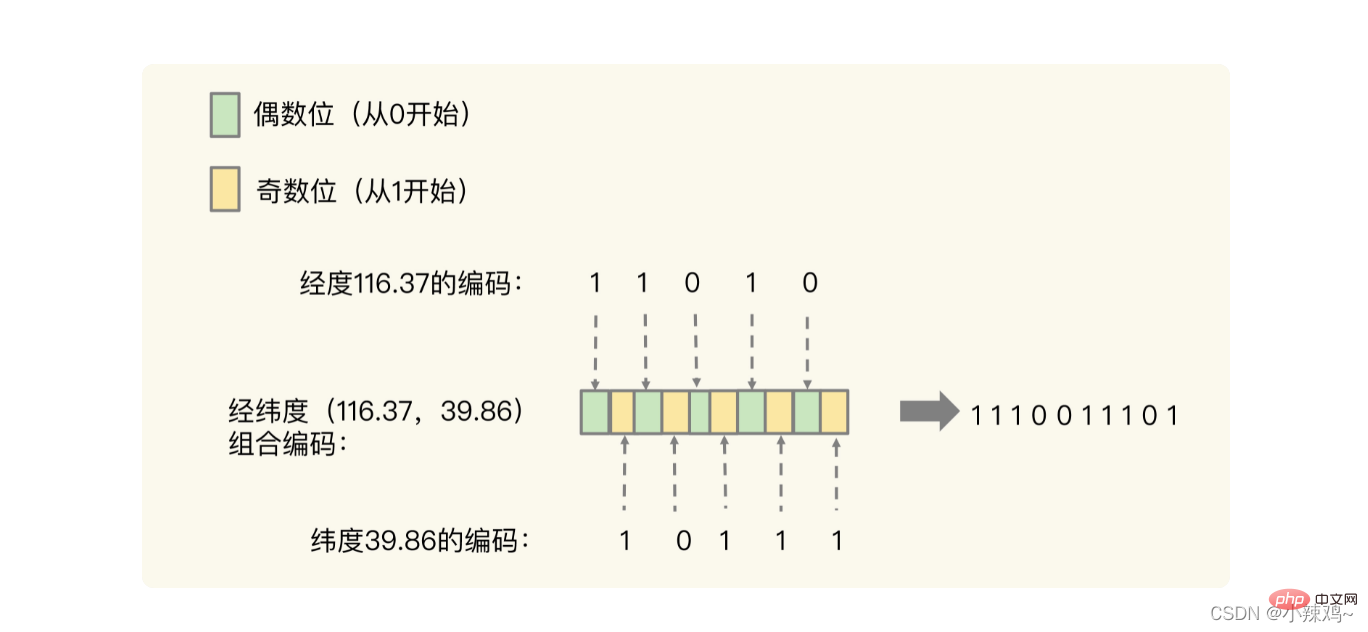
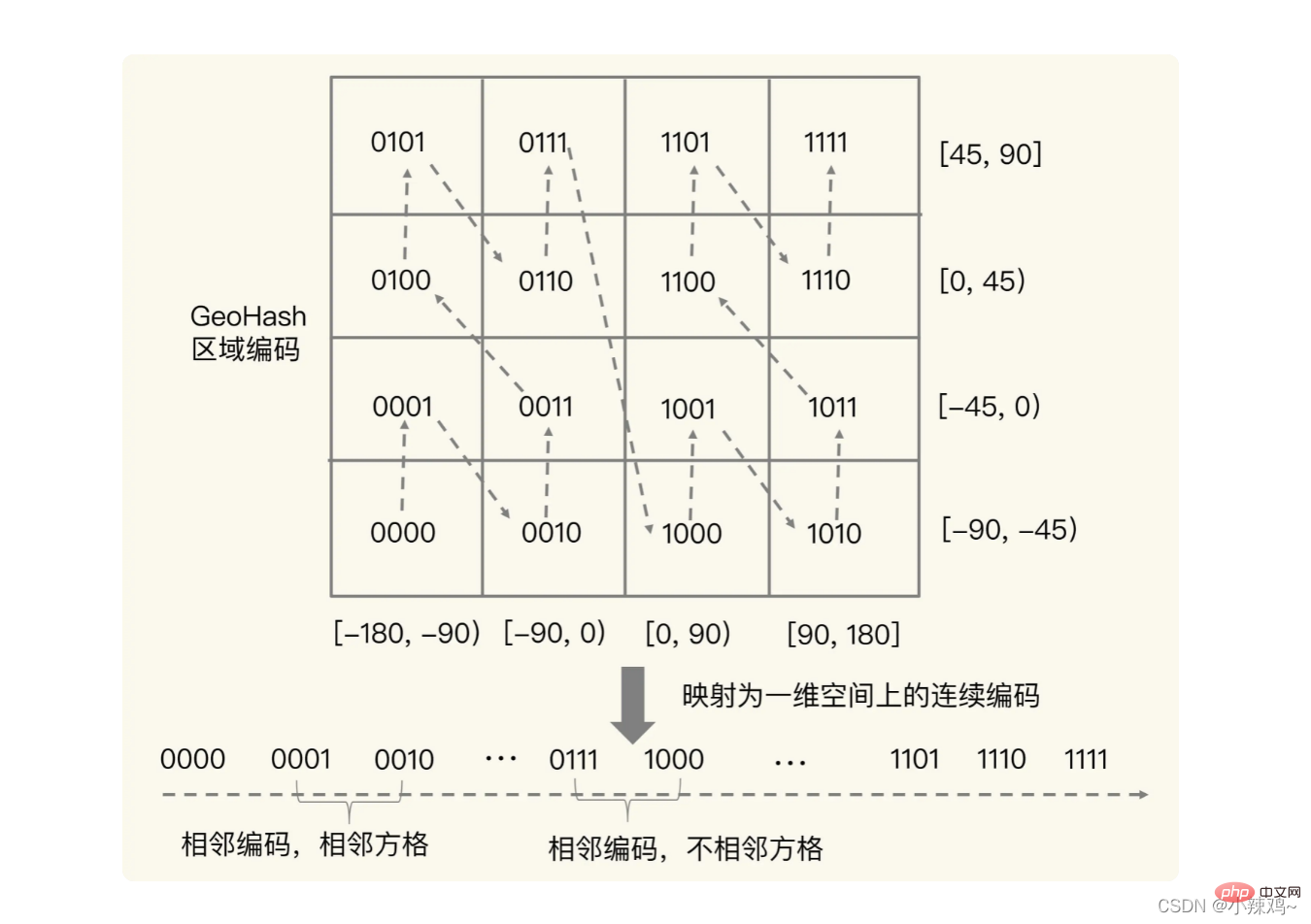
Die zugrunde liegende Struktur von GEO basiert auf Sorted Set, das nach der Gewichtung von Elementen sortiert werden kann und die Gewichtsbewertung unterstützt sortiert Set ist eine Gleitkommazahl (Float-Typ), und der Längen- und Breitengrad sind zwei Zahlen, daher ist GeoHash-Kodierung erforderlich.
Konvertieren Sie zuerst den Längen- und Breitengrad in ein codiertes Format und führen Sie dann den Crossover durch.
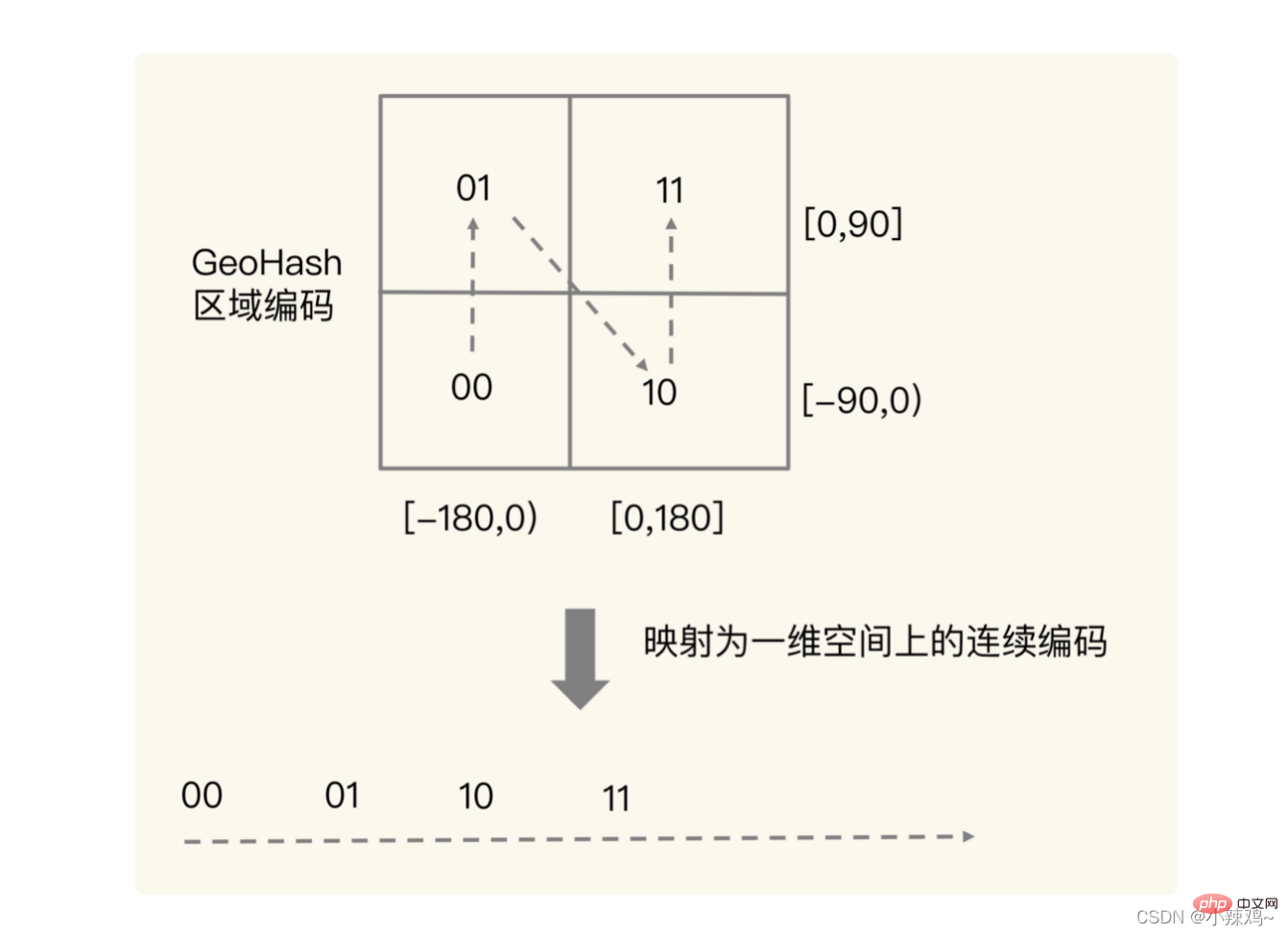
Tatsächlich ist der Zweck des Crossovers das in der Abbildung unten gezeigte Konzept. Nach dem Crossover können Sie tatsächlich ein Quadrat in den beiden lokalisieren Wir verwenden die Bereichsabfrage „Sorted Set“, um ähnliche Codierungswerte zu erhalten. Im tatsächlichen geografischen Raum sind beispielsweise 1110011101 benachbarte Codierungen vorhanden tatsächliche Quadrate nicht benachbarter Situationen. Um diese Situation zu vermeiden, können wir 4 oder 8 Quadrate um einen bestimmten Längen- und Breitengrad gleichzeitig abfragen.
Wie bedient man den GEO-Typ?
Bei der Verwendung von GEO-Typen verwenden wir häufig die beiden Befehle GEOADD und GEORADIUS.
GEOADD: Wird zum Aufzeichnen eines Satzes von Längen- und Breitengradinformationen und einer entsprechenden ID in einer GEO-Typensammlung verwendet. 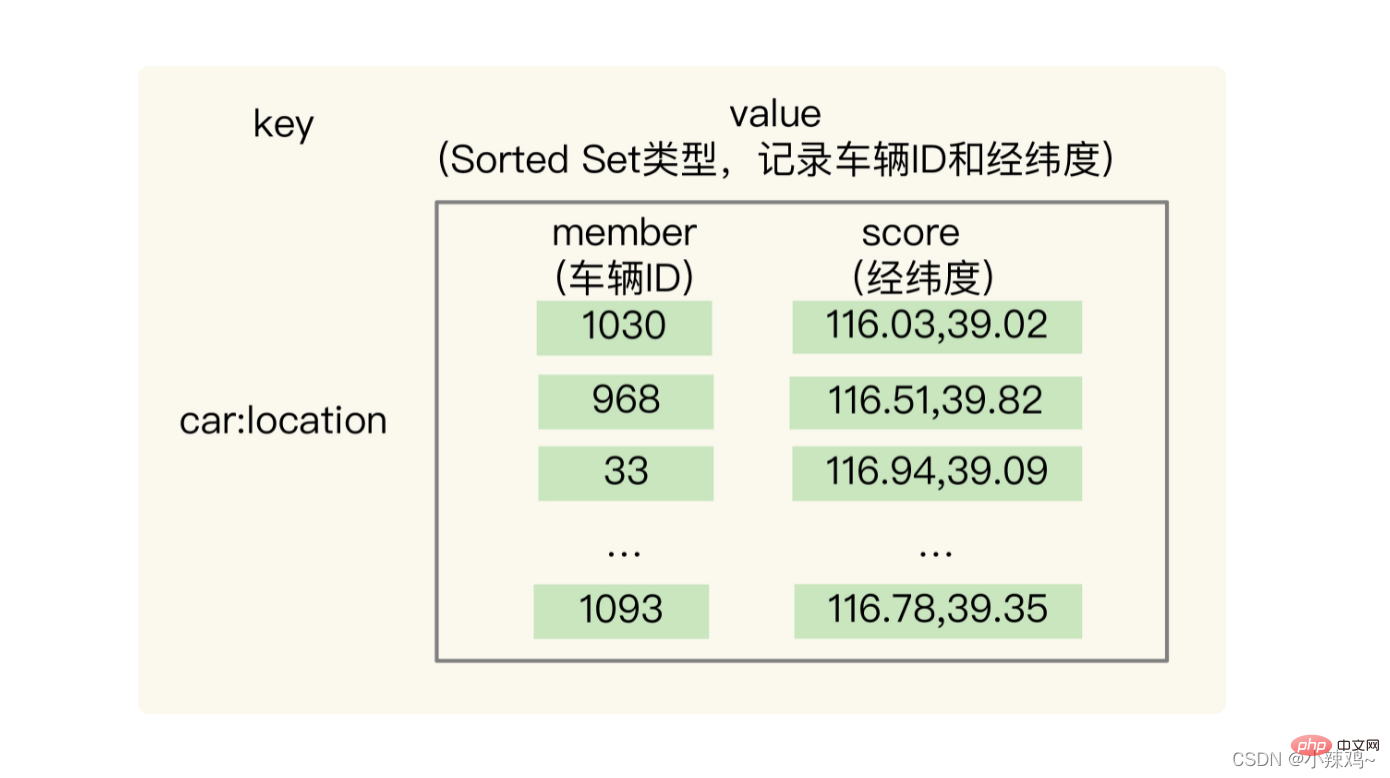 Verwendung: Gehen Sie davon aus, dass die Fahrzeug-ID 33 und der Breiten- und Längengrad (116.034579, 39.030452) ist. Wir können eine GEO-Sammlung verwenden, um den Breiten- und Längengrad aller Fahrzeuge zu speichern. Sie müssen lediglich den folgenden Befehl ausführen, um die aktuelle Längen- und Breitenposition des Fahrzeugs mit der ID-Nummer 33 in GEO zu speichern.
Verwendung: Gehen Sie davon aus, dass die Fahrzeug-ID 33 und der Breiten- und Längengrad (116.034579, 39.030452) ist. Wir können eine GEO-Sammlung verwenden, um den Breiten- und Längengrad aller Fahrzeuge zu speichern. Sie müssen lediglich den folgenden Befehl ausführen, um die aktuelle Längen- und Breitenposition des Fahrzeugs mit der ID-Nummer 33 in GEO zu speichern.
GEOADD cars:locations 116.034579 39.030452 33
GEORADIUS: Fragen Sie basierend auf der Position des eingegebenen Längen- und Breitengrads andere Elemente innerhalb eines bestimmten Bereichs ab, der auf diesem Längen- und Breitengrad zentriert ist.
Wie kann der Datentyp angepasst werden?
Die grundlegende Objektstruktur von Redis umfasst Typ, Codierung, LRU und Refcount, *ptr
Entwickeln Sie eine Datenstruktur mit dem Namen NewTypeObject, die die folgenden vier Schritte umfasst
Wie speichere ich Zeitreihendaten in Redis?
1. Speichern basierend auf Hash und sortiertem Satz: Warum sollten wir basierend auf zwei Datenstrukturen abfragen?
Der Hash-Typ kann eine schnelle Einzelschlüsselabfrage realisieren, die den Anforderungen der Zeitreihen-Einzelschlüsselabfrage entspricht. 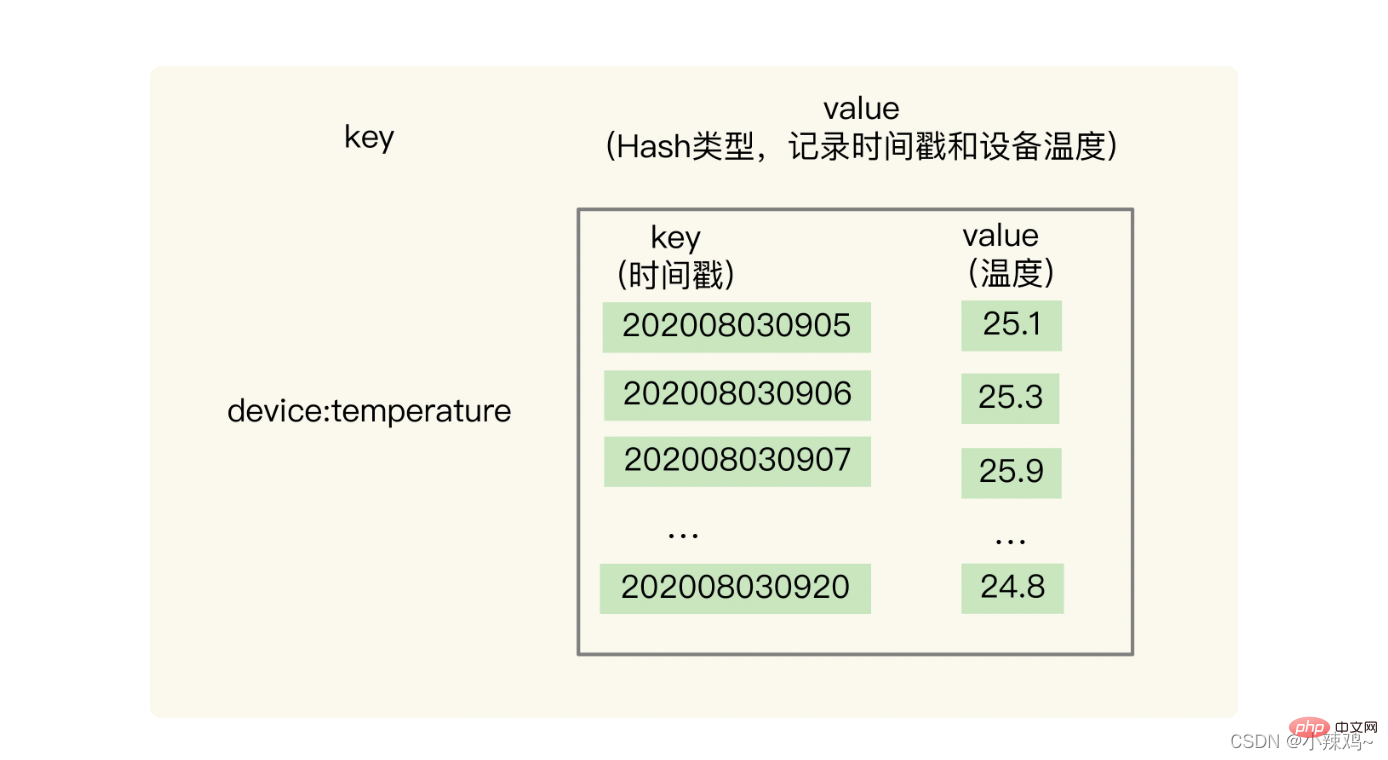
Der Hash-Typ hat jedoch den Nachteil, dass er keine Bereichsabfrage unterstützt. Wir müssen Sorted Set verwenden, da es nach der Gewichtsbewertung der Elemente sortiert wird. 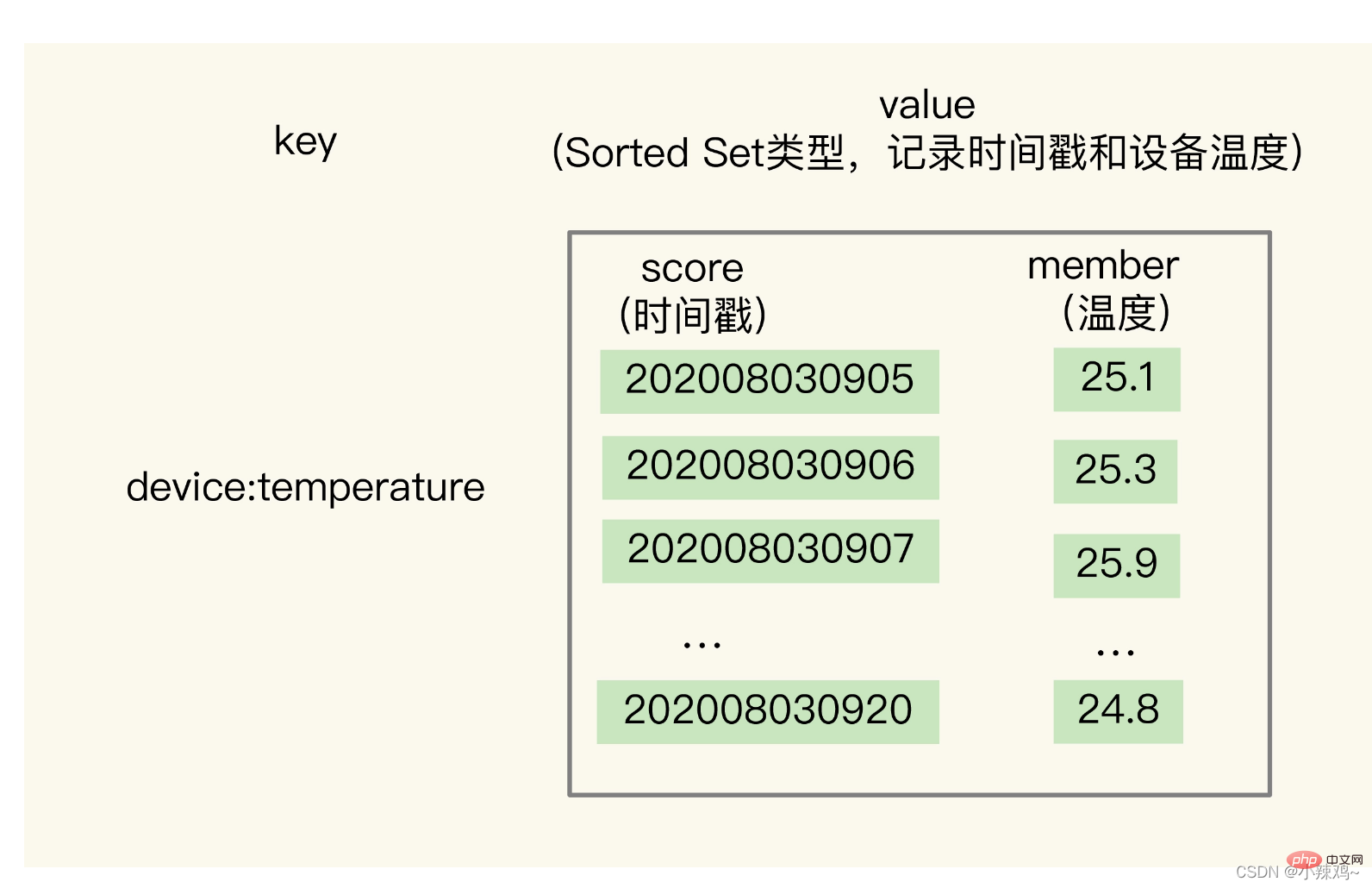
Wie stellen wir also die Atomizität dieser beiden Operationen sicher?
Sie müssen zwei Befehle übergeben: MULTI und EXEC:
MULTI bedeutet Start. Nach Erhalt dieses Befehls stellt Redis den Befehl in die Warteschlange.
EXEC bedeutet Ende. Nach Erhalt dieses Befehls beginnt es mit der Ausführung der Befehle in der Warteschlange 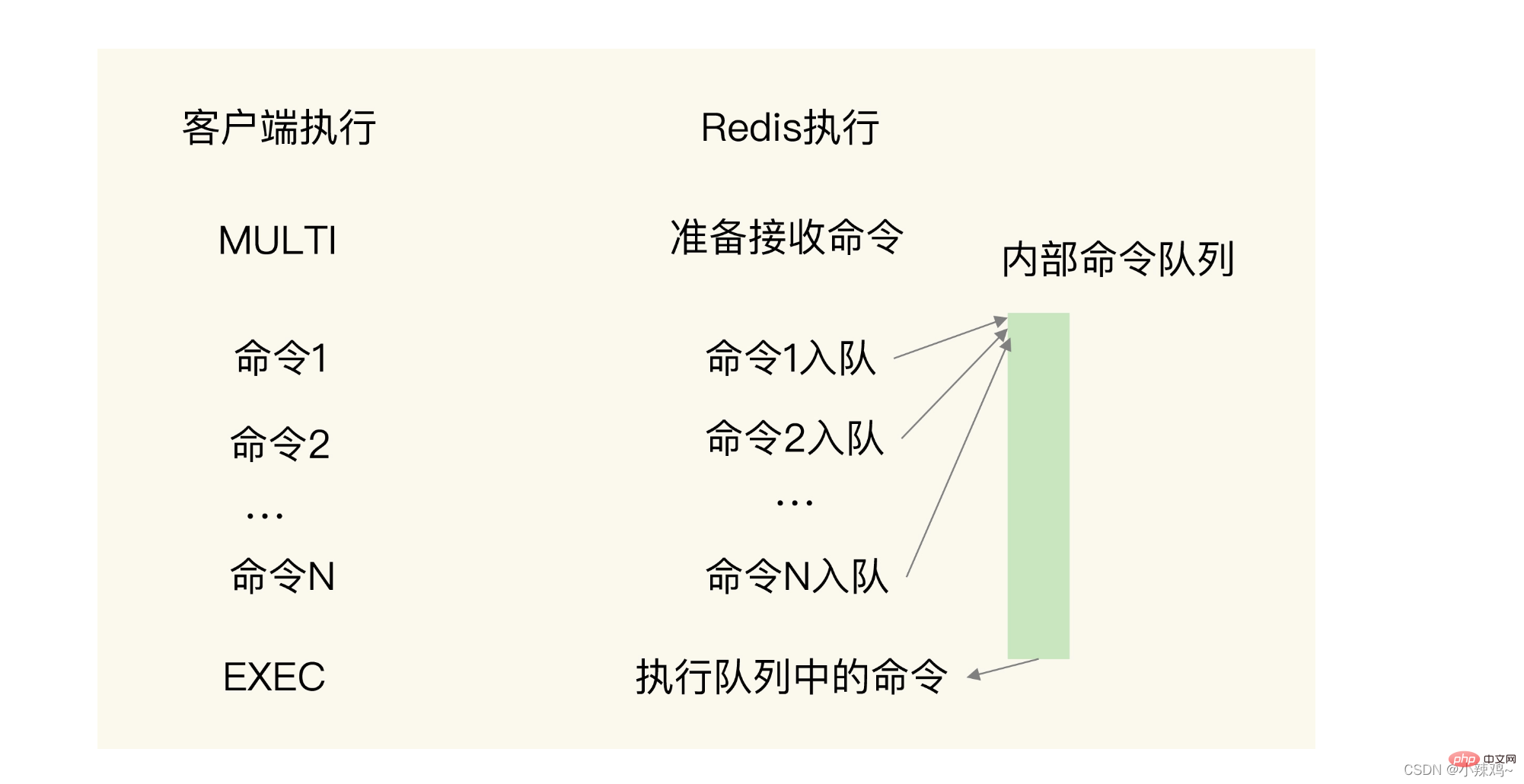 Aber wenn Hash und Sorted Set verwendet werden, werden nur Bereichsabfragen, aber keine Aggregatberechnungen unterstützt. Wenn Aggregationsberechnungen auf dem Client durchgeführt werden, kommt es zu einer großen Menge an Netzwerkübertragungen. Daher können aggregierte Berechnungen für Redis über RedisTimeSeries durchgeführt werden.
Aber wenn Hash und Sorted Set verwendet werden, werden nur Bereichsabfragen, aber keine Aggregatberechnungen unterstützt. Wenn Aggregationsberechnungen auf dem Client durchgeführt werden, kommt es zu einer großen Menge an Netzwerkübertragungen. Daher können aggregierte Berechnungen für Redis über RedisTimeSeries durchgeführt werden.
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung des Redis-Datenstrukturwissens mit Bildern und Texten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So sehen Sie die Versionsnummer der Redis
Apr 10, 2025 pm 05:57 PM
So sehen Sie die Versionsnummer der Redis
Apr 10, 2025 pm 05:57 PM
Um die Redis -Versionsnummer anzuzeigen, können Sie die folgenden drei Methoden verwenden: (1) Geben Sie den Info -Befehl ein, (2) Starten Sie den Server mit der Option --version und (3) die Konfigurationsdatei anzeigen.
 Was tun, wenn Redis-Server nicht gefunden werden kann
Apr 10, 2025 pm 06:54 PM
Was tun, wenn Redis-Server nicht gefunden werden kann
Apr 10, 2025 pm 06:54 PM
Schritte zur Lösung des Problems, das Redis-Server nicht finden kann: Überprüfen Sie die Installation, um sicherzustellen, dass Redis korrekt installiert ist. Setzen Sie die Umgebungsvariablen Redis_host und Redis_port; Starten Sie den Redis-Server Redis-Server; Überprüfen Sie, ob der Server Redis-Cli Ping ausführt.
 Wie ist der Schlüssel für die Redis -Abfrage eindeutig
Apr 10, 2025 pm 07:03 PM
Wie ist der Schlüssel für die Redis -Abfrage eindeutig
Apr 10, 2025 pm 07:03 PM
Redis verwendet fünf Strategien, um die Einzigartigkeit von Schlüssel zu gewährleisten: 1. Namespace -Trennung; 2. Hash -Datenstruktur; 3.. Datenstruktur festlegen; 4. Sonderzeichen von Stringschlüssel; 5. Lua -Skriptüberprüfung. Die Auswahl spezifischer Strategien hängt von Datenorganisationen, Leistung und Skalierbarkeit ab.
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
 So verwenden Sie Redis Zset
Apr 10, 2025 pm 07:27 PM
So verwenden Sie Redis Zset
Apr 10, 2025 pm 07:27 PM
Redis bestellte Sets (ZSETs) werden verwendet, um bestellte Elemente und Sortieren nach zugehörigen Bewertungen zu speichern. Die Schritte zur Verwendung von ZSET umfassen: 1. Erstellen Sie ein Zset; 2. Fügen Sie ein Mitglied hinzu; 3.. Holen Sie sich eine Mitgliederbewertung; 4. Holen Sie sich eine Rangliste; 5. Holen Sie sich ein Mitglied in der Rangliste; 6. Ein Mitglied löschen; 7. Holen Sie sich die Anzahl der Elemente; 8. Holen Sie sich die Anzahl der Mitglieder im Score -Bereich.
 Wie wird der Redis -Cluster implementiert?
Apr 10, 2025 pm 05:27 PM
Wie wird der Redis -Cluster implementiert?
Apr 10, 2025 pm 05:27 PM
Redis Cluster ist ein verteiltes Bereitstellungsmodell, das die horizontale Expansion von Redis-Instanzen ermöglicht und durch Kommunikation zwischen Noten, Hash-Slot-Abteilung Schlüsselraum, Knotenwahlen, Master-Slave-Replikation und Befehlsumleitung implementiert wird: Inter-Node-Kommunikation: Virtuelle Netzwerkkommunikation wird durch Cluster-Bus realisiert. Hash -Slot: Teilen Sie den Schlüsselraum in Hash -Slots, um den für den Schlüssel verantwortlichen Knoten zu bestimmen. Knotenwahlen: Es sind mindestens drei Master -Knoten erforderlich, und nur ein aktiver Masterknoten wird durch den Wahlmechanismus sichergestellt. Master-Slave-Replikation: Der Masterknoten ist für das Schreiben von Anforderungen verantwortlich und der Slaveknoten ist für das Lesen von Anforderungen und Datenreplikation verantwortlich. Befehlsumleitung: Der Client stellt eine Verbindung zum für den Schlüssel verantwortlichen Knoten her, und der Knoten leitet falsche Anforderungen weiter. Fehlerbehebung: Fehlererkennung, Off-Linie markieren und neu
