

MySQL fasst das MVCC-Prinzip von InnoDB zusammen

Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL, das hauptsächlich Probleme im Zusammenhang mit dem MVCC-Prinzip von InnoDB vorstellt, der Parallelitätskontrolle mehrerer Versionen, hauptsächlich zur Verbesserung der Parallelitätsleistung der Datenbank hoffe es hilft allen.

Empfohlenes Lernen: MySQL-Video-Tutorial
MVCC steht für Multi-Version Concurrency Control, eine Parallelitätskontrolle für mehrere Versionen, die hauptsächlich der Verbesserung der Parallelitätsleistung der Datenbank dient. Wenn eine Lese- oder Schreibanforderung für dieselbe Datenzeile auftritt, wird diese gesperrt und blockiert. MVCC verwendet jedoch eine bessere Methode zur Verarbeitung von Lese-/Schreibanforderungen, sodass keine Sperrung auftritt, wenn ein Konflikt mit Lese-/Schreibanforderungen auftritt. Dieser Lesevorgang bezieht sich auf den Snapshot-Lesevorgang, nicht auf den aktuellen Lesevorgang. Der aktuelle Lesevorgang ist ein Sperrvorgang und eine pessimistische Sperre. Wie wird also Lesen und Schreiben ohne Sperren erreicht? Was bedeuten Snapshot-Lesen und aktuelles Lesen? Das werden wir alle später erfahren.
MySQL kann Phantom-Leseprobleme unter der Isolationsstufe REPEATABLE READ weitgehend vermeiden.
Versionskette
Wir wissen, dass für Tabellen, die die InnoDB-Speicher-Engine verwenden, die Clustered-Index-Datensätze zwei erforderliche versteckte Spalten enthalten (row_id ist nicht erforderlich, die von uns erstellte Tabelle verfügt über einen Primärschlüssel oder einen nicht NULL UNIQUE-Schlüssel die Spalte „row_id“ nicht einschließen):
trx_id: Jedes Mal, wenn eine Transaktion einen Clustered-Index-Datensatz ändert, wird die Transaktions-ID der Transaktion der ausgeblendeten Spalte „trx_id“ zugewiesen.
roll_pointer: Jedes Mal, wenn ein Clustered-Index-Datensatz geändert wird, wird die alte Version in das Rückgängig-Protokoll geschrieben. Dann entspricht diese versteckte Spalte einem Zeiger, der verwendet werden kann, um den Datensatz vor der Änderung zu finden.
Um dieses Problem zu veranschaulichen, erstellen wir eine Demotabelle:
CREATE TABLE `teacher` ( `number` int(11) NOT NULL, `name` varchar(100) DEFAULT NULL, `domain` varchar(100) DEFAULT NULL, PRIMARY KEY (`number`)) ENGINE=InnoDB DEFAULT CHARSET=utf8
Fügen Sie dann ein Datenelement in diese Tabelle ein:
mysql> insert into teacher values(1, 'J', 'Java');Query OK, 1 row affected (0.01 sec)
Die Daten sehen jetzt so aus:
mysql> select * from teacher; +--------+------+--------+ | number | name | domain | +--------+------+--------+ | 1 | J | Java | +--------+------+--------+ 1 row in set (0.00 sec)
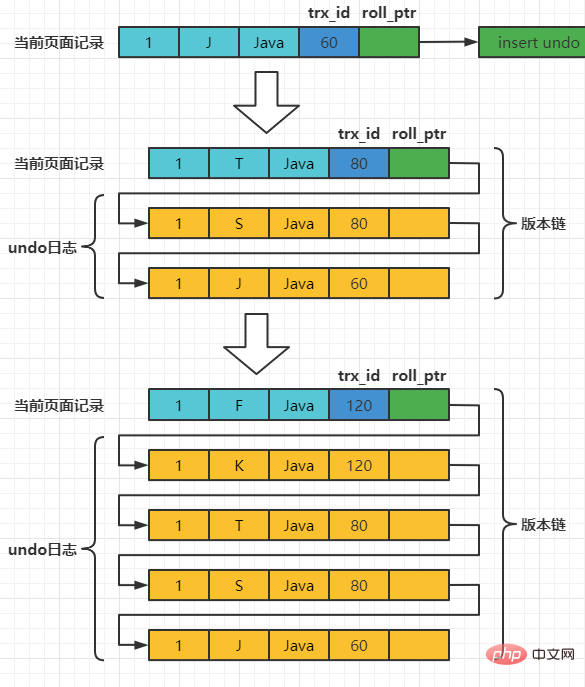
Angenommen, die Transaktions-ID des eingefügten Datensatzes ist 60, dann sieht das schematische Diagramm des Datensatzes in diesem Moment wie folgt aus:

Angenommen, zwei Transaktionen mit den Transaktions-IDs 80 und 120 führen UPDATE-Vorgänge für diesen Datensatz aus. Der Vorgang ist wie folgt:
| Trx80 | Trx120 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| beginnen | ||||||||||||||
| beginnen | ||||||||||||||
| Lehrersatzname='S' aktualisieren, wo. Nummer= 1; | ||||||||||||||
| Lehrer aktualisieren set name='T ' where number=1; | ||||||||||||||
| commit | ||||||||||||||
| update teacher set name = 'K' where number=1; =' F' where number=1 ; | ||||||||||||||
| commit | ||||||||||||||
|
每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个roll_pointer属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些undo日志都连起来,串成一个链表,所以现在的情况就像下图一样:
对该记录每次更新后,都会将旧值放到一条undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被roll_pointer属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id。于是可以利用这个记录的版本链来控制并发事务访问相同记录的行为,那么这种机制就被称之为多版本并发控制(Mulit-Version Concurrency Control MVCC)。 ReadView对于使用READ UNCOMMITTED隔离级别的事务来说,由于可以读到未提交事务修改过的记录,所以直接读取记录的最新版本就好了。 对于使用SERIALIZABLE隔离级别的事务来说,InnoDB使用加锁的方式来访问记录。 对于使用READ COMMITTED和REPEATABLE READ隔离级别的事务来说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是:READ COMMITTED和REPEATABLE READ隔离级别在不可重复读和幻读上的区别,这两种隔离级别关键是需要判断一下版本链中的哪个版本是当前事务可见的。 为此,InnoDB提出了一个ReadView的概念,这个ReadView中主要包含4个比较重要的内容:
有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
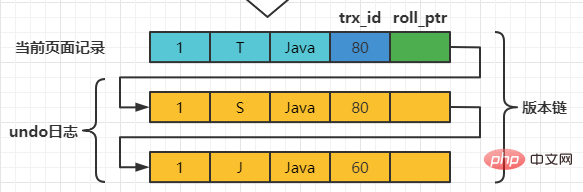
在MySQL中,READ COMMITTED和REPEATABLE READ隔离级别的的一个非常大的区别就是它们生成ReadView的时机不同。 我们还是以表teacher为例,假设现在表teacher中只有一条由事务id为60的事务插入的一条记录,接下来看一下READ COMMITTED和REPEATABLE READ所谓的生成ReadView的时机不同到底不同在哪里。 READ COMMITTED每次读取数据前都生成一个ReadView假设现在系统里有两个事务id分别为80、120的事务在执行: # Transaction 80 set session transaction isolation level read committed; begin update teacher set name='S' where number=1; update teacher set name='T' where number=1; Nach dem Login kopieren 此刻,表teacher中number为1的记录得到的版本链表如下所示:
假设现在有一个使用READ COMMITTED隔离级别的事务开始执行: set session transaction isolation level read committed; # 使用READ COMMITTED隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' Nach dem Login kopieren 这个SELECE1的执行过程如下:
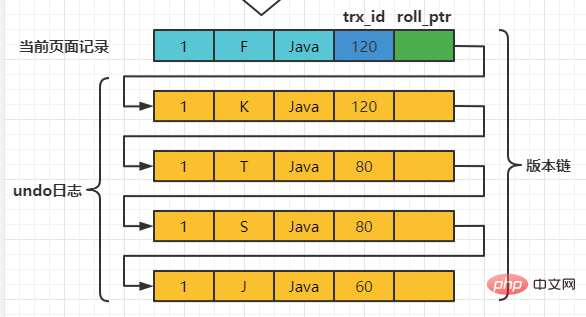
之后,我们把事务id为80的事务提交一下,然后再到事务id为120的事务中更新一下表teacher 中number为1的记录: set session transaction isolation level read committed; # Transaction 120 begin update teacher set name='K' where number=1; update teacher set name='F' where number=1; Nach dem Login kopieren 此刻,表teacher 中number为1的记录的版本链就长这样:
然后再到刚才使用READ COMMITTED隔离级别的事务中继续查找这个number 为1的记录,如下: # 使用READ COMMITTED隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' # SELECE2:Transaction 80提交、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'T' Nach dem Login kopieren 这个SELECE2 的执行过程如下:
以此类推,如果之后事务id为120的记录也提交了,再次在使用READCOMMITTED隔离级别的事务中查询表teacher中number值为1的记录时,得到的结果就是’F’了,具体流程我们就不分析了。 总结一下就是:使用READCOMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。 REPEATABLE READ —— 在第一次读取数据时生成一个ReadView对于使用REPEATABLE READ隔离级别的事务来说,只会在第一次执行查询语句时生成一个ReadView,之后的查询就不会重复生成了。我们还是用例子看一下是什么效果。 假设现在系统里有两个事务id分别为80、120的事务在执行: # Transaction 80 begin update teacher set name='S' where number=1; update teacher set name='T' where number=1; Nach dem Login kopieren 此刻,表teacher中number为1的记录得到的版本链表如下所示:
假设现在有一个使用REPEATABLE READ隔离级别的事务开始执行: # 使用REPEATABLE READ隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' Nach dem Login kopieren 这个SELECE1的执行过程如下(与READ COMMITTED的过程一致):
之后,我们把事务id为80的事务提交一下,然后再到事务id为120的事务中更新一下表teacher 中number为1的记录: # Transaction 80 begin update teacher set name='K' where number=1; update teacher set name='F' where number=1; Nach dem Login kopieren 此刻,表teacher 中number为1的记录的版本链就长这样:
然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,如下: # 使用REPEATABLE READ隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' # SELECE2:Transaction 80提交、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' Nach dem Login kopieren 这个SELECE2的执行过程如下:
Das heißt, die durch die beiden SELECT-Abfragen erhaltenen Ergebnisse werden wiederholt und die aufgezeichneten Spaltenwerte sind alle „J“. Dies ist die Bedeutung von wiederholbarem Lesen. Wenn wir den Datensatz mit der Transaktions-ID 120 später übermitteln und dann in der Transaktion, die gerade die Isolationsstufe REPEATABLE READ verwendet hat, weiter nach dem Datensatz mit der Nummer 1 suchen, lautet das Ergebnis immer noch „J“. Sie können das Spezifische überprüfen Ausführungsprozess Analysieren Sie es selbst. Phantom-Lese-Phänomen und Phantom-Lese-Lösung unter MVCCWir wissen bereits, dass MVCC das Problem des nicht wiederholbaren Lesens unter der Isolationsstufe REPEATABLE READ lösen kann, aber was ist mit Phantom-Lesen? Wie wird MVCC gelöst? Beim Phantomlesen liest eine Transaktion Datensätze mehrmals unter denselben Bedingungen. Der letzte Lesevorgang liest einen Datensatz, der zuvor noch nicht gelesen wurde, und dieser Datensatz stammt aus einem neuen Datensatz, der von einer anderen Transaktion hinzugefügt wurde. Wir können darüber nachdenken: Transaktion T1 unter der Isolationsstufe REPEATABLE READ liest zuerst mehrere Datensätze basierend auf einer bestimmten Suchbedingung, dann fügt Transaktion T2 einen Datensatz ein, der die entsprechende Suchbedingung erfüllt, und sendet ihn, und dann sucht Transaktion T1 basierend darauf die gleiche bedingte Ausführung der Abfrage. Was wird das Ergebnis sein? Gemäß den Vergleichsregeln in ReadView: Unabhängig davon, ob Transaktion T2 vor Transaktion T1 geöffnet wird, kann Transaktion T1 die Übermittlung von T2 nicht sehen. Bitte analysieren Sie es selbst gemäß den oben eingeführten Regeln für Versionskette, ReadView und Sichtbarkeitsbeurteilung. Allerdings kann MVCC in InnoDB unter der Isolationsstufe REPEATABLE READ das Phantomlesen weitgehend vermeiden, anstatt das Phantomlesen vollständig zu verbieten. Was ist los? Schauen wir uns die folgende Situation an:
|
Das obige ist der detaillierte Inhalt vonMySQL fasst das MVCC-Prinzip von InnoDB zusammen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 So installieren Sie MySQL in CentOS7
Apr 14, 2025 pm 08:30 PM
So installieren Sie MySQL in CentOS7
Apr 14, 2025 pm 08:30 PM
Der Schlüssel zur eleganten Installation von MySQL liegt darin, das offizielle MySQL -Repository hinzuzufügen. Die spezifischen Schritte sind wie folgt: Laden Sie den offiziellen GPG -Schlüssel von MySQL herunter, um Phishing -Angriffe zu verhindern. Add MySQL repository file: rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm Update yum repository cache: yum update installation MySQL: yum install mysql-server startup MySQL service: systemctl start mysqld set up booting
