
 Backend-Entwicklung
Python-Tutorial
Detaillierte Python-Analyse von Multithread-Crawlern und gängigen Suchalgorithmen
Backend-Entwicklung
Python-Tutorial
Detaillierte Python-Analyse von Multithread-Crawlern und gängigen Suchalgorithmen
Detaillierte Python-Analyse von Multithread-Crawlern und gängigen Suchalgorithmen

Dieser Artikel vermittelt Ihnen relevantes Wissen über Python, das hauptsächlich Probleme im Zusammenhang mit der Entwicklung von Multithread-Crawlern und gängigen Suchalgorithmen behandelt. Ich hoffe, dass es für alle hilfreich ist.

Empfohlenes Lernen: Python-Video-Tutorial
Multithread-Crawler
Vorteile von Multithreading
Nachdem Sie Anforderungen und reguläre Ausdrücke beherrschen, können Sie damit beginnen, tatsächlich einige einfache URLs zu crawlen.
Allerdings verfügt der Crawler derzeit nur über einen Prozess und einen Thread, daher wird er als Single-Thread-Crawler bezeichnet . Single-Thread-Crawler besuchen jeweils nur eine Seite und können die Netzwerkbandbreite des Computers nicht vollständig nutzen. Eine Seite ist höchstens ein paar hundert KB groß. Wenn also ein Crawler eine Seite crawlt, werden die zusätzliche Netzwerkgeschwindigkeit und die Zeit zwischen dem Einleiten der Anfrage und dem Abrufen des Quellcodes verschwendet. Wenn der Crawler gleichzeitig auf 10 Seiten zugreifen kann, entspricht dies einer Erhöhung der Crawling-Geschwindigkeit um das Zehnfache. Um diesen Zweck zu erreichen, ist der Einsatz der Multithreading-Technologie erforderlich.
Die Python-Sprache verfügt über eine Global Interpreter Lock (GIL). Dies führt dazu, dass Pythons Multithreading ein Pseudo-Multithreading ist, das heißt, es ist im Wesentlichen ein Thread, aber dieser Thread führt alles nur für ein paar Millisekunden aus. Nach ein paar Millisekunden speichert er die Szene und führt andere Dinge aus Dann führt er nach ein paar Millisekunden andere Dinge aus, kehrt zum ersten Ding zurück, setzt die Szene fort, arbeitet ein paar Millisekunden lang und ändert sich weiter ... Ein einzelner Thread im Mikromaßstab ist so, als würde man mehrere Dinge gleichzeitig tun gleichzeitig auf einer Makroskala. Dieser Mechanismus hat nur geringe Auswirkungen auf I/O-intensive Vorgänge (Eingabe/Ausgabe, Eingabe/Ausgabe). Da jedoch nur ein Kern der CPU verwendet werden kann, hat er erhebliche Auswirkungen auf die Leistung Auswirkungen. Wenn Sie also an rechenintensiven Programmen beteiligt sind, müssen Sie mehrere Prozesse verwenden. Die Multiprozesse von Python sind von der GIL nicht betroffen. Crawler sind I/O-intensive Programme, daher kann die Verwendung von Multithreading die Crawling-Effizienz erheblich verbessern.
Multiprocess-Bibliothek: Multiprocessing
Multiprocessing selbst ist die Multiprozessbibliothek von Python, die zur Verarbeitung von Vorgängen im Zusammenhang mit Multiprozessen verwendet wird. Da Speicher- und Stapelressourcen jedoch nicht direkt zwischen Prozessen gemeinsam genutzt werden können und die Kosten für das Starten eines neuen Prozesses viel höher sind als die von Threads, bietet die Verwendung von Multithreads zum Crawlen mehr Vorteile als die Verwendung mehrerer Prozesse.
Unter Multiprocessing gibt es ein Dummy-Modul, das es Python-Threads ermöglicht, verschiedene Methoden der Multiprocessing zu verwenden.
Unter Dummy befindet sich eine Pool-Klasse, mit der der Thread-Pool implementiert wird.
Dieser Thread-Pool verfügt über eine Map()-Methode, die es allen Threads im Thread-Pool ermöglicht, eine Funktion „gleichzeitig“ auszuführen.
Zum Beispiel:
Nach dem Erlernen der for-Schleife
for i in range(10): print(i*i)
Natürlich können Sie mit dieser Schreibmethode Ergebnisse erzielen, aber der Code wird einzeln berechnet, was nicht sehr effizient ist. Wenn Sie Multithreading-Technologie verwenden, damit der Code die Quadrate vieler Zahlen gleichzeitig berechnen kann, müssen Sie dazu multiprocessing.dummy verwenden:
Verwendungsbeispiel für Multithreading:
from multiprocessing.dummy import Pooldef cal_pow(num):
return num*num
pool=Pool(3)num=[x for x in range(10)]result=pool.map(cal_pow,num)print('{}'.format(result))Im obigen Code , definiert zunächst eine Funktion zur Berechnung von Quadraten und initialisiert dann einen Thread-Pool mit 3 Threads. Diese drei Threads sind für die Berechnung des Quadrats von 10 Zahlen verantwortlich. Wer zuerst mit der Berechnung der vorliegenden Zahl fertig ist, nimmt die nächste Zahl und rechnet weiter, bis alle Zahlen berechnet sind.
In diesem Beispiel Die Methode „map()“ des Thread-Pools empfängt zwei Parameter. Der erste Parameter ist der Funktionsname und der zweite Parameter ist eine Liste. Hinweis: Der erste Parameter ist nur der Name der Funktion und darf keine Klammern enthalten. Der zweite Parameter ist ein iterierbares Objekt. Jedes Element in diesem iterierbaren Objekt wird von der Funktion clac_power2() als Parameter empfangen. Als zweiter Parameter von map() können neben Listen auch Tupel, Mengen oder Wörterbücher verwendet werden.
Multithread-Crawler-Entwicklung
Da Crawler E/A-intensive Vorgänge sind, insbesondere beim Anfordern von Webseiten-Quellcode, verschwendet die Verwendung eines einzelnen Threads zum Entwickeln viel Zeit mit dem Warten auf die Rückkehr der Webseite , also Multithreading Die Anwendung der Technologie auf Crawler kann die Betriebseffizienz von Crawlern erheblich verbessern. Geben Sie ein Beispiel. Das Waschen von Kleidung in der Waschmaschine dauert 50 Minuten, das Kochen von Wasser im Wasserkocher 15 Minuten und das Auswendiglernen von Vokabeln 1 Stunde. Wenn Sie darauf warten, dass die Waschmaschine zuerst die Wäsche wäscht, dann nach dem Waschen der Wäsche das Wasser abkochen und dann nach dem Abkochen des Wassers die Vokabeln aufsagen, dauert es insgesamt 125 Minuten.
Aber wenn man es anders ausdrückt, können drei Dinge gleichzeitig laufen. Angenommen, Sie haben plötzlich zwei andere Personen, die dafür verantwortlich sind, die Kleidung in die Waschmaschine zu legen und darauf zu warten die Waschmaschine ist fertig, und die andere Person ist dafür verantwortlich, Wasser zu kochen und darauf zu warten, dass es kocht, und Sie müssen sich nur die Wörter merken. Wenn das Wasser kocht, verschwindet zuerst der Klon, der für das Kochen des Wassers verantwortlich ist. Wenn die Waschmaschine mit dem Waschen der Kleidung fertig ist, verschwindet der Klon, der für das Waschen der Kleidung verantwortlich ist. Zum Schluss merken Sie sich die Wörter selbst. Es dauert nur 60 Minuten, drei Dinge gleichzeitig zu erledigen.
Natürlich werden Sie auf jeden Fall feststellen, dass das obige Beispiel nicht die tatsächliche Situation im Leben darstellt. In Wirklichkeit ist niemand getrennt. Was im wirklichen Leben passiert, ist, dass Menschen sich darauf konzentrieren, sich Wörter zu merken. Wenn das Wasser kocht, gibt der Wasserkocher ein Geräusch von sich, um Sie daran zu erinnern, dass die Waschmaschine ein „Didi“-Geräusch von sich gibt . Ergreifen Sie also einfach die entsprechenden Maßnahmen, wenn die Erinnerung eintrifft. Es ist nicht nötig, jede Minute zu überprüfen. Die beiden oben genannten Unterschiede sind tatsächlich die Unterschiede zwischen Multithreading und ereignisgesteuerten asynchronen Modellen. In diesem Abschnitt geht es um Multithread-Vorgänge, und wir werden später auf das Crawler-Framework mit asynchronen Vorgängen eingehen. Jetzt müssen Sie nur noch bedenken, dass es keinen Unterschied in der Leistung der beiden Methoden gibt, wenn die Anzahl der auszuführenden Aktionen nicht groß ist. Sobald jedoch die Anzahl der Aktionen erheblich zunimmt, wird die Effizienz durch Multithreading verbessert verringern, sogar schlimmer als Single-Threading. Und zu diesem Zeitpunkt sind nur noch asynchrone Operationen die Lösung des Problems.
Die folgenden zwei Codeteile werden verwendet, um die Leistungsunterschiede zwischen Single-Thread-Crawlern und Multi-Thread-Crawlern zum Crawlen der BD-Homepage zu vergleichen: 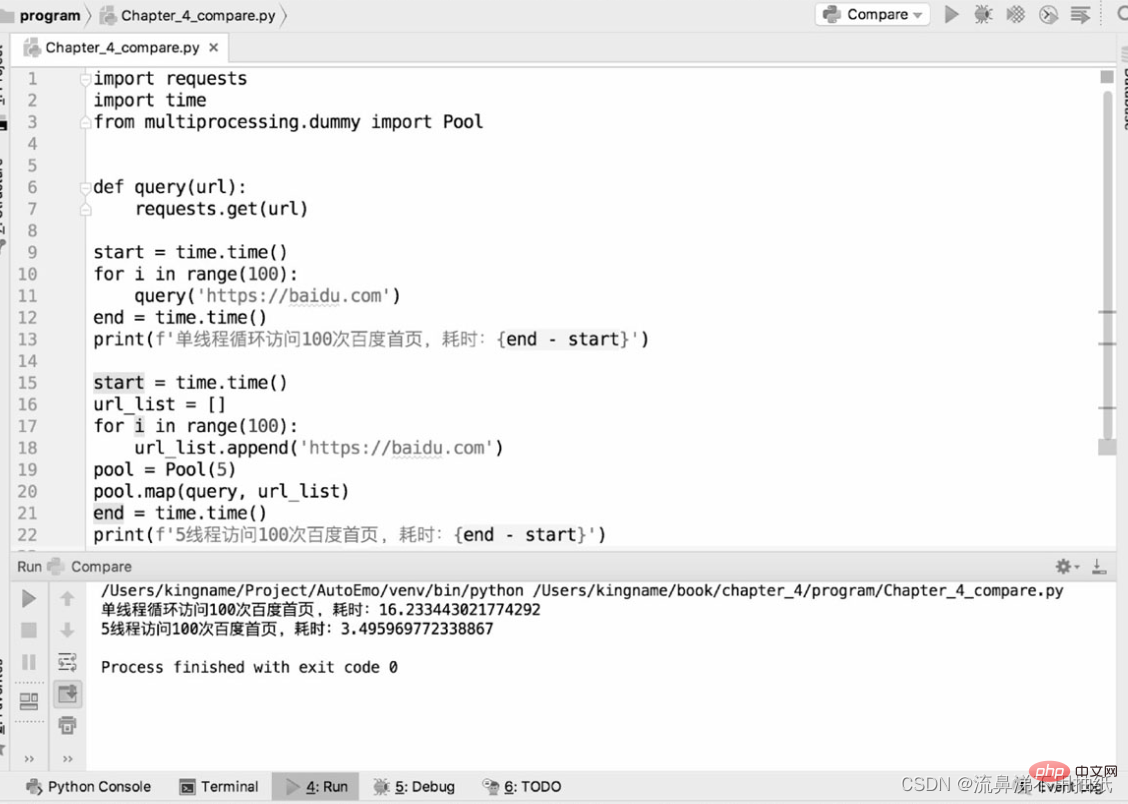
Aus den laufenden Ergebnissen können wir ersehen, dass ein Thread etwa 16,2 Sekunden benötigt 5 Threads dauern etwa 3,5 Sekunden. Die Zeit beträgt etwa ein Fünftel der eines einzelnen Threads. Sie können den Effekt von fünf Threads, die „gleichzeitig laufen“, auch aus der Zeitperspektive sehen. Dies bedeutet jedoch nicht, dass es umso besser ist, je größer der Thread-Pool ist. Aus den obigen Ergebnissen ist auch ersichtlich, dass die Laufzeit von fünf Threads tatsächlich etwas mehr als ein Fünftel der Laufzeit eines Threads beträgt. Der zusätzliche Punkt ist tatsächlich die Zeit des Threadwechsels. Dies spiegelt auch von der Seite her wider, dass Pythons Multithreading auf Mikroebene immer noch seriell ist. Wenn der Thread-Pool daher zu groß eingestellt ist, kann der durch den Thread-Wechsel verursachte Overhead die durch Multithreading erzielte Leistungsverbesserung ausgleichen. Die Größe des Thread-Pools muss anhand der tatsächlichen Situation ermittelt werden und es liegen keine genauen Daten vor. Leser können unterschiedliche Größen zum Testen und Vergleichen in bestimmten Anwendungsszenarien festlegen, um die am besten geeigneten Daten zu finden.
Gemeinsame Suchalgorithmen für Crawler
Tiefensuche
Die Kursklassifizierung einer Online-Bildungswebsite erfordert das Crawlen der oben genannten Kursinformationen. Ausgehend von der Startseite sind die Kurse je nach Sprache in mehrere Hauptkategorien unterteilt, z. B. Python, Node.js und Golang. Es gibt viele Kurse in jeder Hauptkategorie, wie zum Beispiel Crawler, Django und maschinelles Lernen unter Python. Jeder Kurs ist in viele Unterrichtsstunden unterteilt.
Bei der Tiefensuche ist die Kriechroute wie in der Abbildung dargestellt (Seriennummer von klein nach groß) 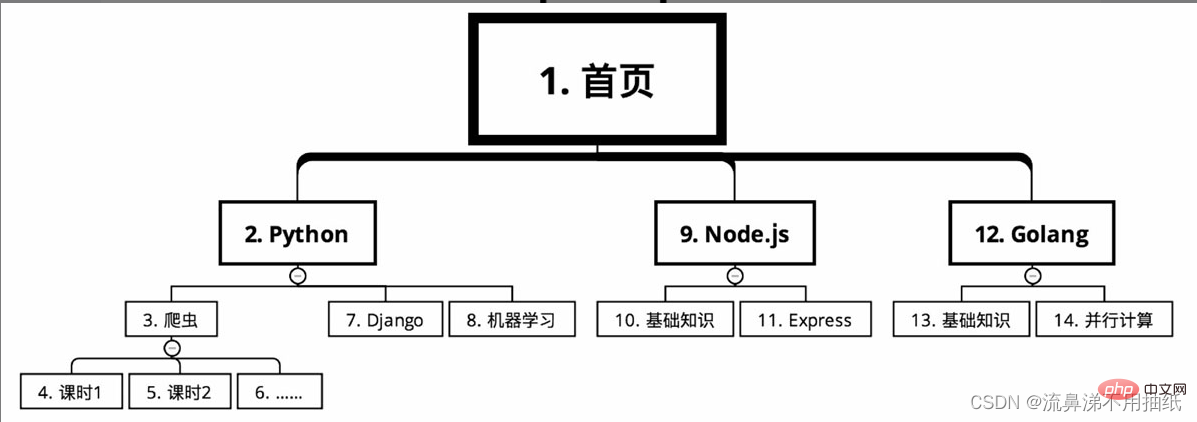
Breitensuche
Die Reihenfolge ist wie folgt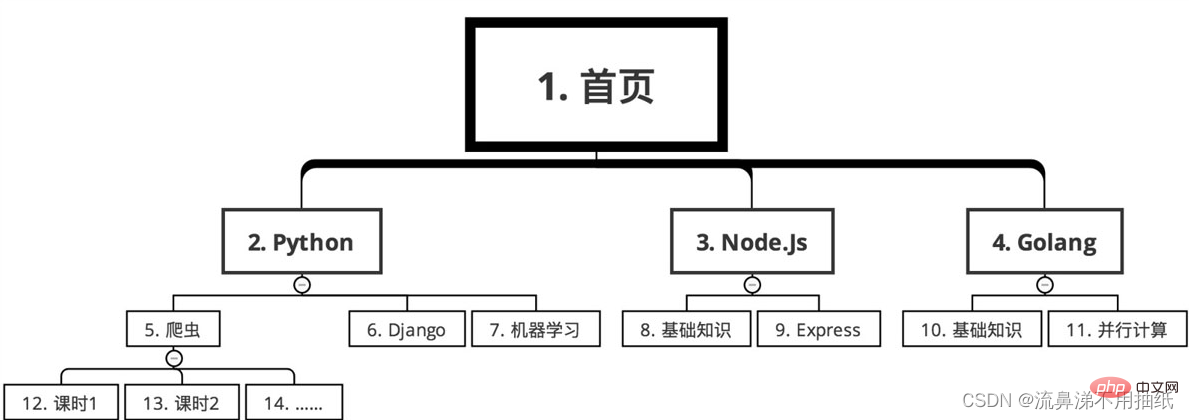
Algorithmusauswahl
Zum Beispiel, wenn Sie eine Website landesweit crawlen möchten. Alle Restaurantinformationen und Bestellinformationen für jedes Restaurant. Unter der Annahme, dass der Tiefenalgorithmus verwendet wird, crawlen Sie zuerst von einem bestimmten Link aus zu Restaurant A und crawlen Sie dann sofort die Bestellinformationen von Restaurant A. Da es im ganzen Land Hunderttausende Restaurants gibt, kann es 12 Stunden dauern, sie alle zu erklimmen. Das dadurch verursachte Problem besteht darin, dass das Bestellvolumen von Restaurant A 8 Uhr morgens erreichen kann, während das Bestellvolumen von Restaurant B 8 Uhr abends erreichen kann. Ihr Bestellvolumen unterscheidet sich um 12 Stunden. Für beliebte Restaurants können 12 Stunden zu einer Umsatzlücke in Millionenhöhe führen. Auf diese Weise wird es bei der Datenanalyse aufgrund des Zeitunterschieds von 12 Stunden schwierig sein, die Verkaufsleistung der Restaurants A und B zu vergleichen. Im Verhältnis zum Bestellvolumen sind die Änderungen im Restaurantvolumen viel geringer. Wenn Sie also die Breitensuche verwenden, crawlen Sie zunächst alle Restaurants von 0:00 Uhr mitten in der Nacht bis 12:00 Uhr mittags am nächsten Tag und konzentrieren sich dann darauf, das Bestellvolumen jedes Restaurants von 14:00 Uhr bis 20:00 Uhr zu crawlen :00 am nächsten Tag. Auf diese Weise dauerte die Auftragsdurchforstung nur 6 Stunden, wodurch der durch den Zeitunterschied verursachte Unterschied im Auftragsvolumen verringert wurde. Da das Crawlen des Shops alle paar Tage kaum Auswirkungen hat, konnte gleichzeitig auch die Anzahl der Anfragen reduziert werden, wodurch es für Crawler schwieriger wird, von der Website entdeckt zu werden.
Ein weiteres Beispiel: Um die öffentliche Meinung in Echtzeit zu analysieren, müssen Sie Baidu Tieba crawlen. Ein beliebtes Forum kann Zehntausende Seiten mit Beiträgen umfassen, vorausgesetzt, die frühesten Beiträge stammen aus dem Jahr 2010. Wenn die Breitensuche verwendet wird, rufen Sie zunächst die Titel und URLs aller Beiträge in diesem Tieba ab und geben Sie dann jeden Beitrag basierend auf diesen URLs ein, um Informationen zu jeder Etage zu erhalten. Da es sich jedoch um die öffentliche Meinung in Echtzeit handelt, sind Beiträge von vor 7 Jahren für die aktuelle Analyse von geringer Bedeutung. Wichtiger sind neue Beiträge, daher sollten neue Inhalte zuerst erfasst werden. Im Vergleich zu früheren Inhalten sind Echtzeitinhalte am wichtigsten. Daher sollte zum Crawlen von Tieba-Inhalten die Tiefensuche verwendet werden. Wenn Sie einen Beitrag sehen, gehen Sie schnell hinein und crawlen Sie die Informationen zu jeder Etage. Nachdem Sie einen Beitrag gecrawlt haben, können Sie zum nächsten Beitrag crawlen. Natürlich sind diese beiden Suchalgorithmen nicht entweder/oder. Sie müssen flexibel entsprechend der tatsächlichen Situation ausgewählt werden. In vielen Fällen können sie gleichzeitig verwendet werden.
Empfohlenes Lernen: Python-Video-Tutorial
Das obige ist der detaillierte Inhalt vonDetaillierte Python-Analyse von Multithread-Crawlern und gängigen Suchalgorithmen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Effizientes Training von Pytorch -Modellen auf CentOS -Systemen erfordert Schritte, und dieser Artikel bietet detaillierte Anleitungen. 1.. Es wird empfohlen, YUM oder DNF zu verwenden, um Python 3 und Upgrade PIP zu installieren: Sudoyumupdatepython3 (oder sudodnfupdatepython3), PIP3Install-upgradepip. CUDA und CUDNN (GPU -Beschleunigung): Wenn Sie Nvidiagpu verwenden, müssen Sie Cudatool installieren
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
Bei der Auswahl einer Pytorch -Version unter CentOS müssen die folgenden Schlüsselfaktoren berücksichtigt werden: 1. Cuda -Version Kompatibilität GPU -Unterstützung: Wenn Sie NVIDIA -GPU haben und die GPU -Beschleunigung verwenden möchten, müssen Sie Pytorch auswählen, der die entsprechende CUDA -Version unterstützt. Sie können die CUDA-Version anzeigen, die unterstützt wird, indem Sie den Befehl nvidia-smi ausführen. CPU -Version: Wenn Sie keine GPU haben oder keine GPU verwenden möchten, können Sie eine CPU -Version von Pytorch auswählen. 2. Python Version Pytorch
 Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Minio-Objektspeicherung: Hochleistungs-Bereitstellung im Rahmen von CentOS System Minio ist ein hochleistungsfähiges, verteiltes Objektspeichersystem, das auf der GO-Sprache entwickelt wurde und mit Amazons3 kompatibel ist. Es unterstützt eine Vielzahl von Kundensprachen, darunter Java, Python, JavaScript und Go. In diesem Artikel wird kurz die Installation und Kompatibilität von Minio zu CentOS -Systemen vorgestellt. CentOS -Versionskompatibilitätsminio wurde in mehreren CentOS -Versionen verifiziert, einschließlich, aber nicht beschränkt auf: CentOS7.9: Bietet einen vollständigen Installationshandbuch für die Clusterkonfiguration, die Umgebungsvorbereitung, die Einstellungen von Konfigurationsdateien, eine Festplattenpartitionierung und Mini
 So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
Die Installation von CentOS-Installationen erfordert die folgenden Schritte: Installieren von Abhängigkeiten wie Entwicklungstools, PCRE-Devel und OpenSSL-Devel. Laden Sie das Nginx -Quellcode -Paket herunter, entpacken Sie es, kompilieren Sie es und installieren Sie es und geben Sie den Installationspfad als/usr/local/nginx an. Erstellen Sie NGINX -Benutzer und Benutzergruppen und setzen Sie Berechtigungen. Ändern Sie die Konfigurationsdatei nginx.conf und konfigurieren Sie den Hörport und den Domänennamen/die IP -Adresse. Starten Sie den Nginx -Dienst. Häufige Fehler müssen beachtet werden, z. B. Abhängigkeitsprobleme, Portkonflikte und Konfigurationsdateifehler. Die Leistungsoptimierung muss entsprechend der spezifischen Situation angepasst werden, z. B. das Einschalten des Cache und die Anpassung der Anzahl der Arbeitsprozesse.
