

Führt Sie durch den MySQL-Index

Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL. Er stellt hauptsächlich einige Probleme in der erweiterten Version von MySQL vor, einschließlich der Frage, was ein Index ist, die zugrunde liegende Implementierung des Index usw. Schauen wir uns das hoffentlich gemeinsam an wird für alle hilfreich sein.

Empfohlenes Lernen: MySQL-Video-Tutorial
MySQL, ein vertrauter und unbekannter Begriff, als wir Javaweb lernten, verwendeten wir zu diesem Zeitpunkt MySQL Ein gutes Tool zum Speichern von Daten. Beim Abfragen handelt es sich auch um eine blinde vollständige Tabellenabfrage (ohne ein wenig Optimierung).
Wir täuschen uns immer selbst und denken, dass wir durch andere Aspekte optimieren können. Wir zögern, uns mit „MySQL Advanced“ auseinanderzusetzen, und lernen stattdessen etwas, das „fortgeschrittener“ zu sein scheint. Lernen Sie Redis und teilen Sie den Druck von MySQL. Lernen Sie Middleware wie MyCat und implementieren Sie Master-Slave-Replikation, Lese-Schreib-Trennung, Unterdatenbank und Untertabelle usw. (Ich spreche von Melo, das ist richtig)
Als ich mich auf das Interview vorbereitete, stellte ich fest, dass ich in den Interviewfragen nicht alle Fragen zu MySQL kannte~
Und über die hochmoderne Middleware, die ich gelernt, ich habe nur sehr wenige Fragen gestellt! ! Ich weiß nur, wie man es verwendet. Beim Schreiben meines Lebenslaufs kann ich nur schwach schreiben, wie man die xxx-Middleware versteht Optimierung ist sehr wichtig, nachdem Sie Serverausfälle erlebt haben, können Sie nur stillschweigend...
Beginnen Sie jetzt, es ist noch zu spät, um an Land zu gehen! ! ! Nutzen Sie die goldene Drei und die silberne Vier, ergänzen Sie die Wissenspunkte des MySQL Advanced-Kapitels und beginnen Sie die Reise des MySQL Advanced-Kapitels unter den folgenden Aspekten:
Es wird empfohlen, durch die Teile zu suchen, die für Sie hilfreich sind
Sidebar-Verzeichnis, darunter
Das Emoji-Präfix ist ein wichtiger Teil. Wenn Sie es hilfreich finden, wird der Herausgeber diesen Artikel und die MySQL-Kolumne weiter verbessern. 
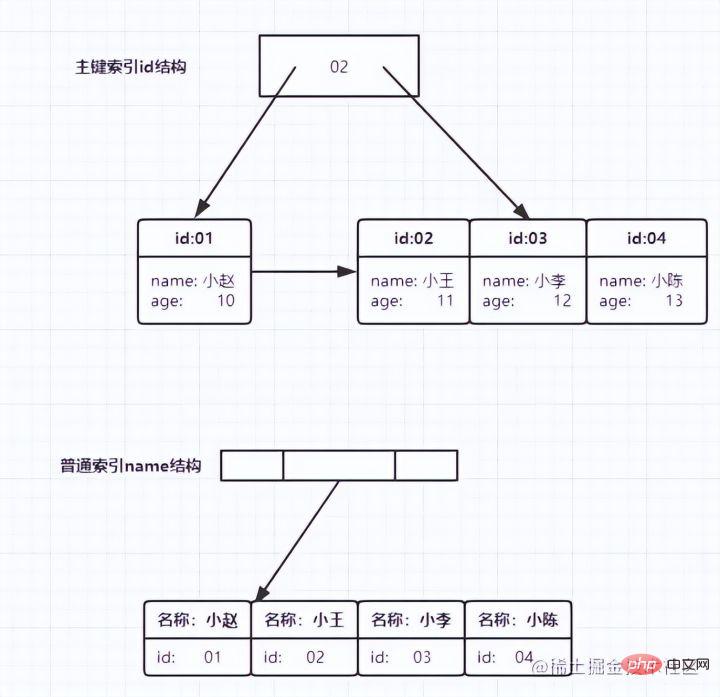
IndexdefinitionMySQLs offizielle Indexdefinition lautet: Index (Index) ist eine Datenstruktur (geordnet), die MySQL dabei hilft, Daten effizient zu erhalten. Feldern in Datenbanktabellen werden Indizes hinzugefügt, um die Abfrageeffizienz zu verbessern. Zusätzlich zu den Daten verwaltet das Datenbanksystem auch Datenstrukturen, die bestimmte Suchalgorithmen erfüllen. Diese Datenstrukturen verweisen auf die Daten, sodass erweiterte Suchalgorithmen auf diesen Datenstrukturen implementiert werden können Index. Wie im Diagramm unten gezeigt:
Tatsächlich ist ein Index, einfach ausgedrückt, eine sortierte Datenstruktur
Die linke Seite ist die Datentabelle mit insgesamt zwei Spalten und sieben Datensätzen und die ganz linke Seite Eine davon ist die physische Struktur der Datensatzadresse (beachten Sie, dass logisch benachbarte Datensätze nicht unbedingt physisch benachbart auf der Festplatte liegen). Um die Suche nach Col2 zu beschleunigen, können Sie einen binären Suchbaum pflegen, wie rechts gezeigt. Jeder Knoten enthält eineneinen Zeiger auf die physische Adresse des entsprechenden DatensatzesIndexschlüsselwert
und
Verwenden Sie die binäre Suche, um schnell an die entsprechenden Daten zu gelangen. 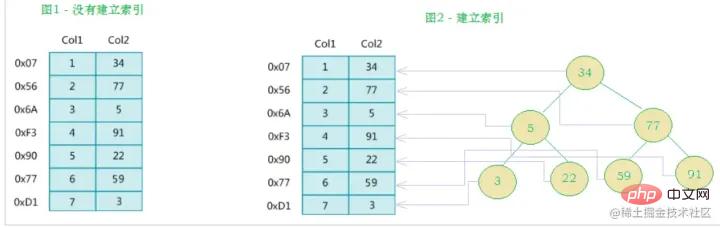
Beschleunigen Sie die Suche und
Sortierraten, reduzieren Sie die Datenbank-IO-Kosten und den CPU-VerbrauchDurch die Erstellung eines eindeutigen Indexes können Sie die Eindeutigkeit jeder Datenzeile in der Datenbanktabelle sicherstellen.- Nachteile des IndexDer Index ist eigentlich eine Tabelle
- , die den Primärschlüssel und das Indexfeld speichert und auf die Datensätze der Entitätsklasse verweist. Er selbst muss Platz belegen
Zeigerung
des mittleren Knotens muss möglicherweise geändert werden- Aber tatsächlich verwenden wir nicht den binären Suchbaum
- , um ihn in MySQL zu speichern . Warum? Sie müssen wissen, dass in einem binären Suchbaum ein Knoten hier nur ein Datenelement speichern kann und ein Knoten einem Festplattenblock in MySQL entspricht. Auf diese Weise können wir jedes Mal einen Festplattenblock lesen Um ein einzelnes Datenelement zu erhalten, ist die Effizienz besonders gering, daher werden wir darüber nachdenken, eine
-Struktur zu verwenden, um es zu speichern.Indexstruktur
Indizes werden in der Speicher-Engine-Schicht von MySQL implementiert, nicht in der Serverschicht. Daher sind die Indizes der einzelnen Speicher-Engines nicht unbedingt identisch und nicht alle Engines unterstützen alle Indextypen.
- BTREE-Index: Der häufigste Indextyp. Die meisten Indizes unterstützen B-Tree-Indizes.
- HASH-Index: Wird nur von der Speicher-Engine unterstützt, das Nutzungsszenario ist einfach.
- R-Tree-Index (räumlicher Index): Der räumliche Index ist ein spezieller Indextyp der MyISAM-Engine. Er wird hauptsächlich für Geodatentypen verwendet. Er wird normalerweise weniger verwendet und nicht speziell eingeführt.
- Volltext (Volltextindex): Der Volltextindex ist ebenfalls ein spezieller Indextyp von MyISAM, der hauptsächlich für den Volltextindex verwendet wird. InnoDB unterstützt den Volltextindex ab der Mysql5.6-Version.
MyISAM-, InnoDB- und Memory-Speicher-Engines unterstützen verschiedene Indextypen
| BTREE Index | Unterstützt | Unterstützt Nicht unterstützt |
Unterstützt |
|||||||||
R-Tree-Index |
Nicht unterstützt |
Unterstützt |
Nicht unterstützt |
|||||||||
Volltext |
Unterstützt nach Version 5.6 |
Unterstützt |
Nicht unterstützt |
|||||||||
|
Was wir normalerweise als Indizes bezeichnen, bezieht sich, sofern nicht anders angegeben, auf Indizes, die in einer B+-Baumstruktur (Mehrwege-Suchbaum, nicht unbedingt binär) organisiert sind. Unter diesen verwenden Clustered-Index, Compound-Index, Präfix-Index und Unique-Index standardmäßig alle den B+Tree-Index, der gemeinsam als Index bezeichnet wird. BTREE m/2)-1 bis m-1 ceil bedeutet Aufrunden, ceil(2.3)=3
, um sicherzustellen, dass die Eigenschaften des B-Baums m-Ordnung vorliegen nicht zerstört Da Level 3 höchstens 2 Knoten haben kann, sind 26 und 30 am Anfang zusammen, und dann beginnt 85, sich zu teilen, 26 bleibt übrig und 85 geht an rechts Das heißt: Wenn 70 erneut in das Bild eingefügt wird, ist zufällig 70 drin In der mittleren Position wird 62 beibehalten und 85 wird in einen neuen Knoten unterteilt Vorteile B+-Baum hat zwei Arten von Knoten: interne Knoten (auchIndexknoten genannt) und klein bis großJeder Blattknoten speichert Zeiger auf benachbarte Blattknoten. Die Blattknoten selbst sind in der Reihenfolge von klein nach groß Der übergeordnete Knoten speichert den Indexdes ersten Elements desrechten untergeordneten Knotens.
Beim Übergang vom
IndexprinzipBBaumindex:
|
 Die obere Position in der Mitte
Die obere Position in der Mitte 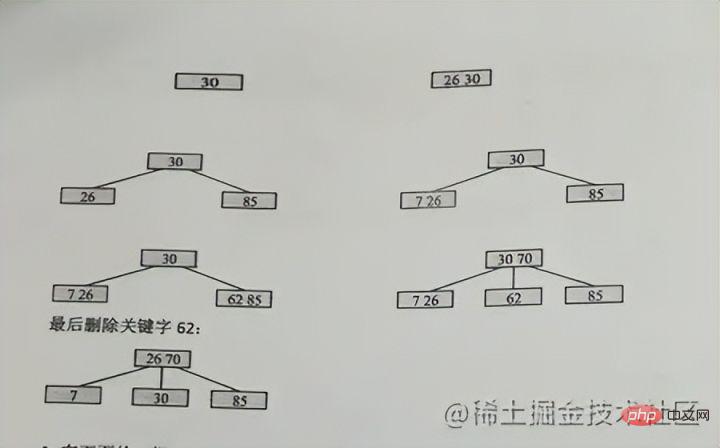 Blattknoten
Blattknoten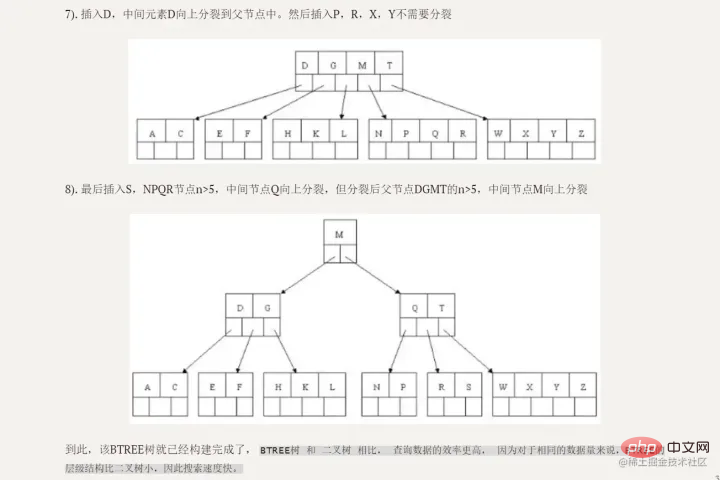 entsprechend der Größe der Schlüsselwörter verbunden.
entsprechend der Größe der Schlüsselwörter verbunden. 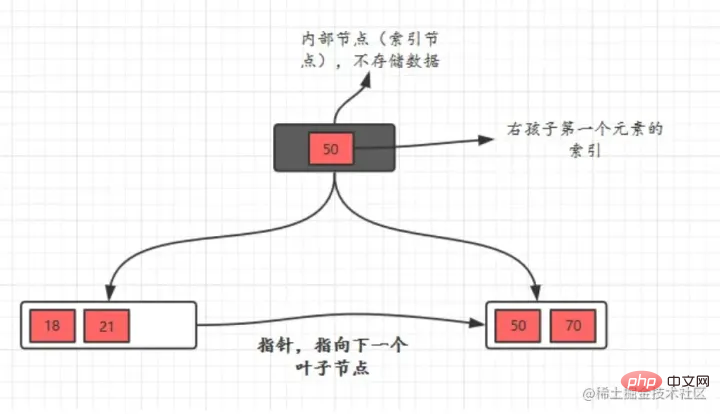 binären Suchbaum zum B-Baum
binären Suchbaum zum B-Baum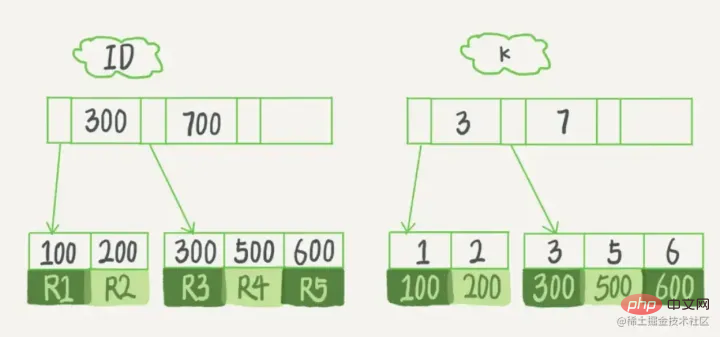


Das obige ist der detaillierte Inhalt vonFührt Sie durch den MySQL-Index. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
In der MySQL -Datenbank wird die Beziehung zwischen dem Benutzer und der Datenbank durch Berechtigungen und Tabellen definiert. Der Benutzer verfügt über einen Benutzernamen und ein Passwort, um auf die Datenbank zuzugreifen. Die Berechtigungen werden über den Zuschussbefehl erteilt, während die Tabelle durch den Befehl create table erstellt wird. Um eine Beziehung zwischen einem Benutzer und einer Datenbank herzustellen, müssen Sie eine Datenbank erstellen, einen Benutzer erstellen und dann Berechtigungen erfüllen.
 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 So füllen Sie MySQL Benutzername und Passwort aus
Apr 08, 2025 pm 07:09 PM
So füllen Sie MySQL Benutzername und Passwort aus
Apr 08, 2025 pm 07:09 PM
Ausfüllen des MySQL -Benutzernamens und des Kennworts: 1. Bestimmen Sie den Benutzernamen und das Passwort; 2. Verbinden Sie eine Verbindung zur Datenbank; 3. Verwenden Sie den Benutzernamen und das Passwort, um Abfragen und Befehle auszuführen.
 Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Navicat selbst speichert das Datenbankkennwort nicht und kann das verschlüsselte Passwort nur abrufen. Lösung: 1. Überprüfen Sie den Passwort -Manager. 2. Überprüfen Sie Navicats "Messnot Password" -Funktion; 3.. Setzen Sie das Datenbankkennwort zurück; 4. Kontaktieren Sie den Datenbankadministrator.
 Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
1. Verwenden Sie den richtigen Index, um das Abrufen von Daten zu beschleunigen, indem die Menge der skanierten Datenmenge ausgewählt wird. Wenn Sie mehrmals eine Spalte einer Tabelle nachschlagen, erstellen Sie einen Index für diese Spalte. Wenn Sie oder Ihre App Daten aus mehreren Spalten gemäß den Kriterien benötigen, erstellen Sie einen zusammengesetzten Index 2. Vermeiden Sie aus. Auswählen * Nur die erforderlichen Spalten. Wenn Sie alle unerwünschten Spalten auswählen, konsumiert dies nur mehr Serverspeicher und veranlasst den Server bei hoher Last oder Frequenzzeiten, beispielsweise die Auswahl Ihrer Tabelle, wie beispielsweise die Spalten wie innovata und updated_at und Zeitsteuer und dann zu entfernen.
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 Wie man MySQL sieht
Apr 08, 2025 pm 07:21 PM
Wie man MySQL sieht
Apr 08, 2025 pm 07:21 PM
Zeigen Sie die MySQL -Datenbank mit dem folgenden Befehl an: Verbindung zum Server: MySQL -U -Benutzername -P -Kennwort ausführen STEILE -Datenbanken; Befehl zum Abrufen aller vorhandenen Datenbanken auswählen Datenbank: Verwenden Sie den Datenbanknamen. Tabelle Ansicht: Tabellen anzeigen; Tabellenstruktur anzeigen: Beschreiben Sie den Tabellennamen; Daten anzeigen: Wählen Sie * aus Tabellenname;
 So kopieren Sie Tabellen in MySQL
Apr 08, 2025 pm 07:24 PM
So kopieren Sie Tabellen in MySQL
Apr 08, 2025 pm 07:24 PM
Durch das Kopieren einer Tabelle in MySQL müssen neue Tabellen erstellt, Daten eingefügt, Fremdschlüssel festgelegt, Indizes, Auslöser, gespeicherte Verfahren und Funktionen kopiert werden. Zu den spezifischen Schritten gehören: Erstellen einer neuen Tabelle mit derselben Struktur. Fügen Sie Daten aus der ursprünglichen Tabelle in eine neue Tabelle ein. Legen Sie die gleiche fremde Schlüsselbeschränkung fest (wenn die Originaltabelle eine hat). Erstellen Sie den gleichen Index. Erstellen Sie denselben Auslöser (wenn die ursprüngliche Tabelle eine hat). Erstellen Sie dieselbe gespeicherte Prozedur oder Funktion (wenn die ursprüngliche Tabelle verwendet wird).
