
 Backend-Entwicklung
Python-Tutorial
Erfahren Sie mehr über Python-Prozesspools und Prozesssperren
Backend-Entwicklung
Python-Tutorial
Erfahren Sie mehr über Python-Prozesspools und Prozesssperren
Erfahren Sie mehr über Python-Prozesspools und Prozesssperren

Dieser Artikel vermittelt Ihnen relevantes Wissen über Python. Er stellt hauptsächlich Probleme im Zusammenhang mit Prozesspools und Prozesssperren vor, einschließlich Prozesspool-Erstellungsmodulen, Prozesspoolfunktionen usw. Wir hoffen, dass es allen hilft.

Empfohlenes Lernen: Python-Video-Tutorial
Prozesspool
Was ist ein Prozesspool? Wir haben im vorherigen Kapitel über Prozesse erwähnt, dass Ressourcen verbraucht werden, wenn zu viele Prozesse erstellt werden. Zu groß. Um diese Situation zu vermeiden, müssen wir die Anzahl der Prozesse festlegen und benötigen zu diesem Zeitpunkt die Hilfe des Prozesspools.
Wir können uns den Prozesspool als einen Pool vorstellen, in dem im Voraus eine bestimmte Anzahl von Prozessen erstellt wird. Siehe das Bild unten:

Unser Prozess wird beim Erstellen und Herunterfahren auch vom Speichermanager recycelt. Dies gilt für jeden Prozess, der nach dem Herunterfahren erstellt wird. Die Prozesse im Prozesspool werden nach ihrer Erstellung nicht geschlossen und können jederzeit wiederverwendet werden, wodurch der Ressourcenverbrauch beim Erstellen und Schließen sowie wiederholte Erstellungs- und Schließvorgänge vermieden werden, was die Effizienz verbessert.
Wenn wir mit der Ausführung des Programms fertig sind und der Prozesspool geschlossen ist, wird natürlich auch der Prozess geschlossen.
Wenn wir eine Aufgabe haben, die ausgeführt werden muss, ermitteln wir, ob sich im aktuellen Prozesspool Leerlaufprozesse befinden (die sogenannten Leerlaufprozesse sind tatsächlich Prozesse im Prozesspool, die keine Aufgaben ausführen). Wenn ein Prozess inaktiv ist, findet die Aufgabe den Prozess, der die Aufgabe ausführt. Wenn sich alle Prozesse im aktuellen Prozesspool in einem nicht inaktiven Zustand befinden, wechselt die Aufgabe in den Wartezustand. Sie tritt nicht in den Prozesspool ein oder verlässt ihn, bis ein Prozess im Prozesspool inaktiv ist, um die Aufgabe auszuführen.
Dies ist die Rolle des Prozesspools.
Erstellungsmodul des Prozesspools – MultiprocessingProzesspoolfunktion erstellen – Pool
| Einführung | Parameter | Rückgabewert | |
|---|---|---|---|
| Prozesspool Erstellen Sie ein | Processcount | Prozesspoolobjekt |
Pool功能介绍:通过调用 "multiprocessing" 模块的 "Pool" 函数来帮助我们创建 "进程池对象" ,它有一个参数 "Processcount" (一个整数),代表我们这个进程池中创建几个进程。
Nachdem wir ein Prozesspoolobjekt erstellt haben, müssen wir einen Blick auf die gängigen Methoden werfen Methode (Funktion).
| Einführung | Parameter | Rückgabewert | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Aufgabe zum Prozesspool hinzugefügt (asynchron) | func, args | Keine | ||||||||||
Schließen Sie den Prozesspool
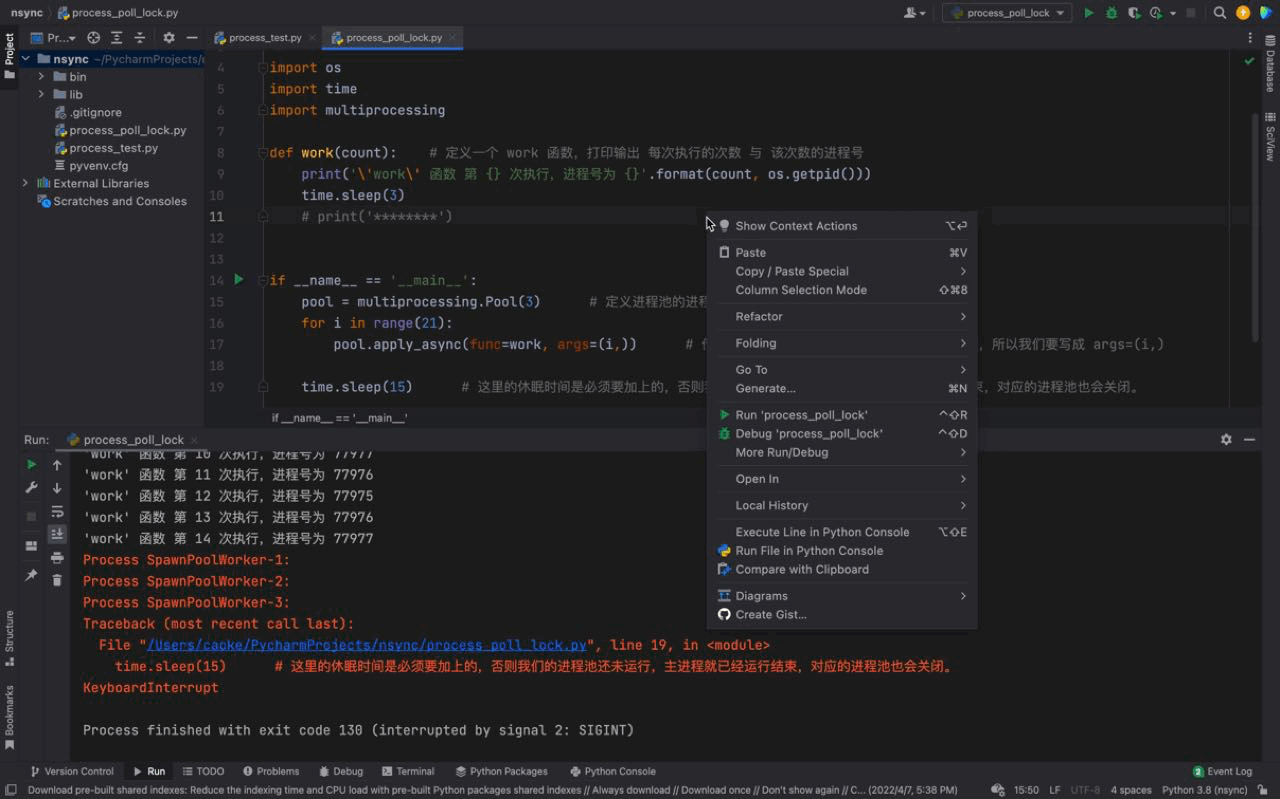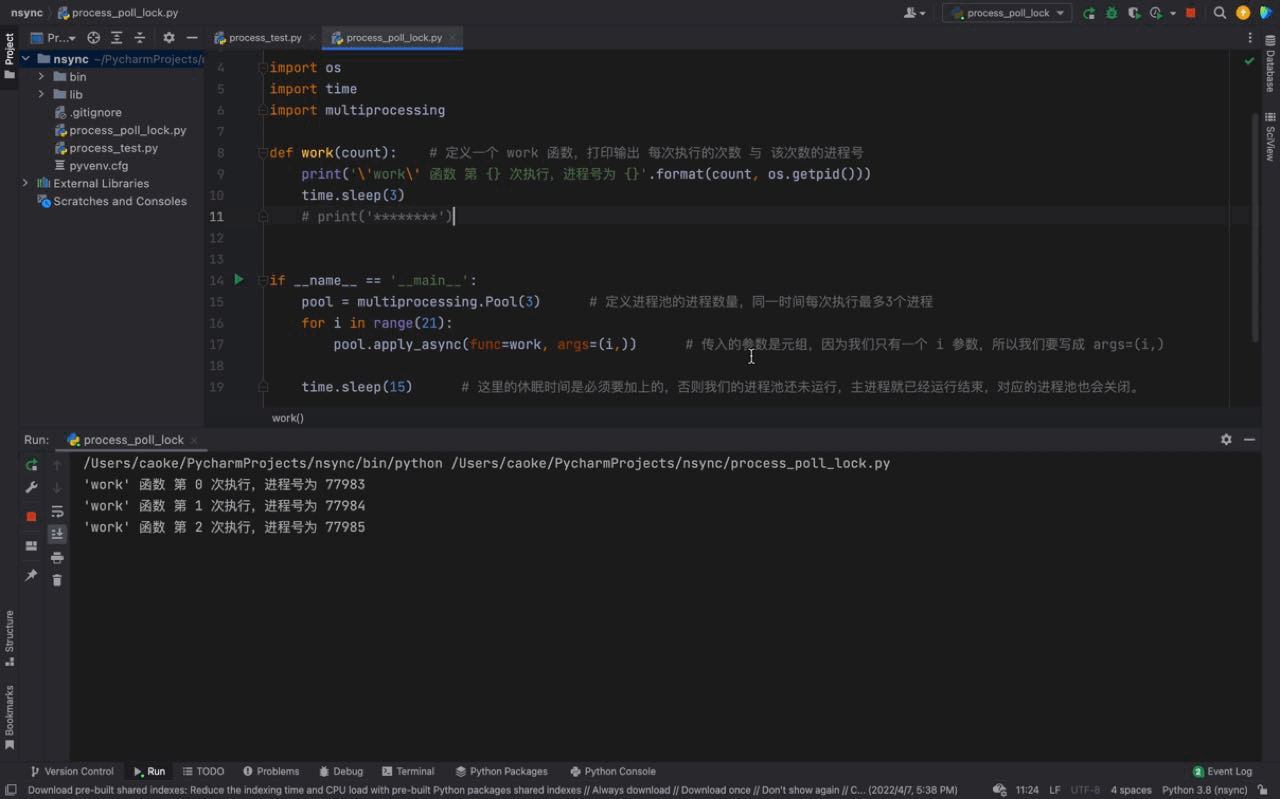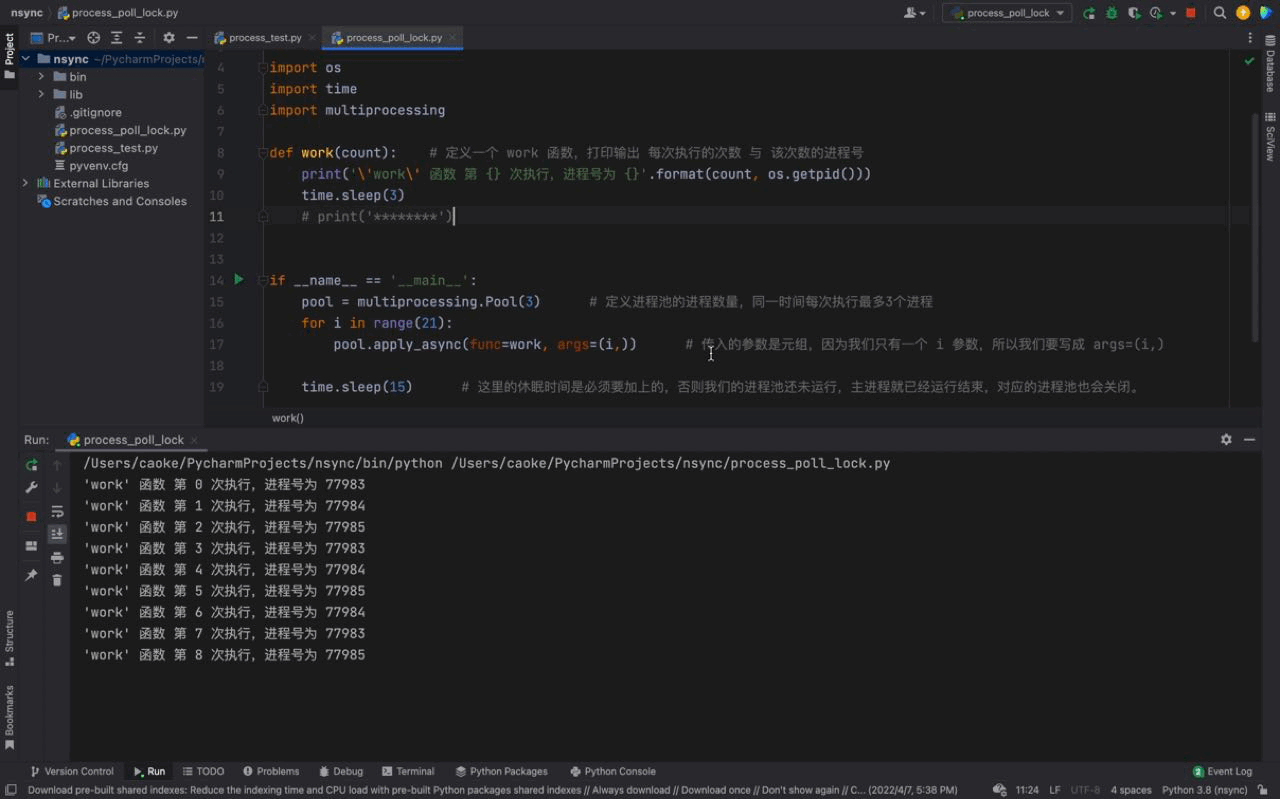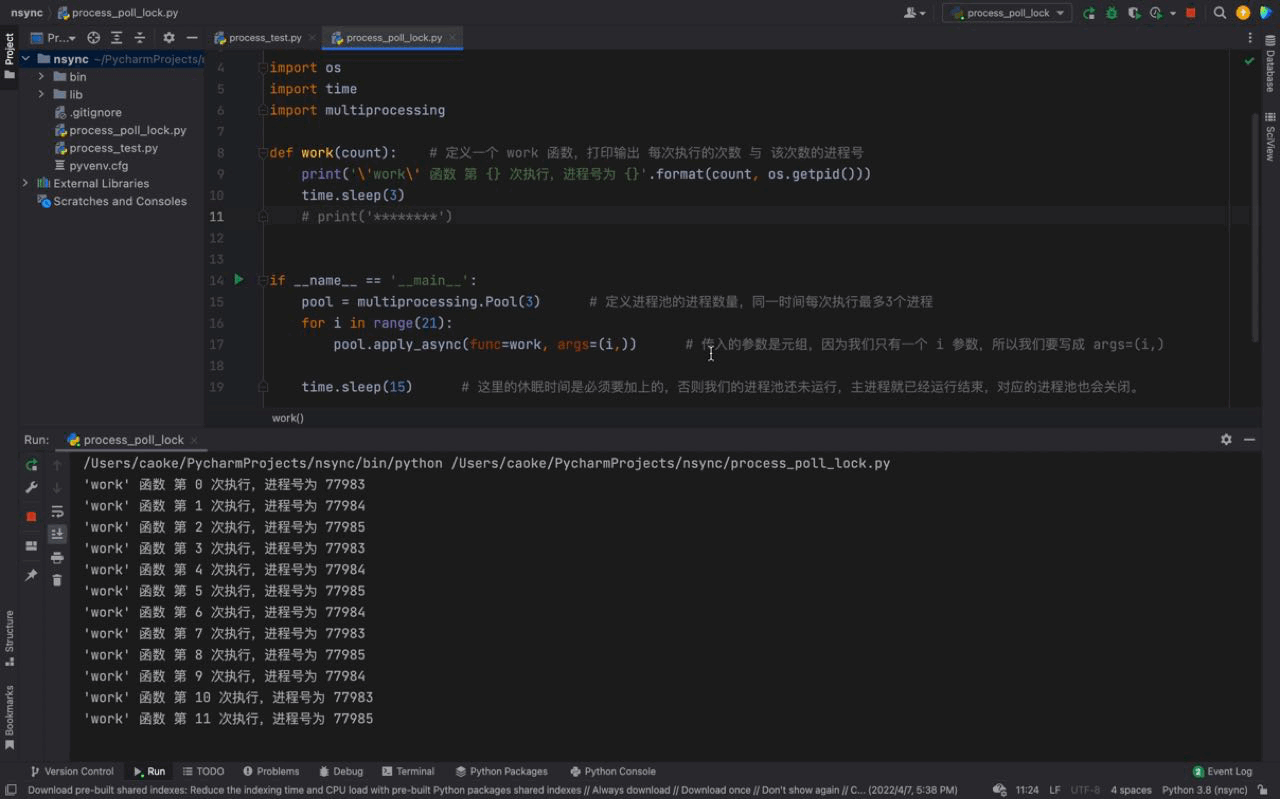
apply_async 函数演示案例接下里我们在 Pycharm 中创建一个脚本,练习一下关于进程池的使用方法。
示例代码如下: # coding:utf-8import osimport timeimport multiprocessingdef work(count):
# 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
# print('********')if __name__ == '__main__':
pool = multiprocessing.Pool(3)
# 定义进程池的进程数量,同一时间每次执行最多3个进程
for i in range(21):
pool.apply_async(func=work, args=(i,))
# 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
time.sleep(15)
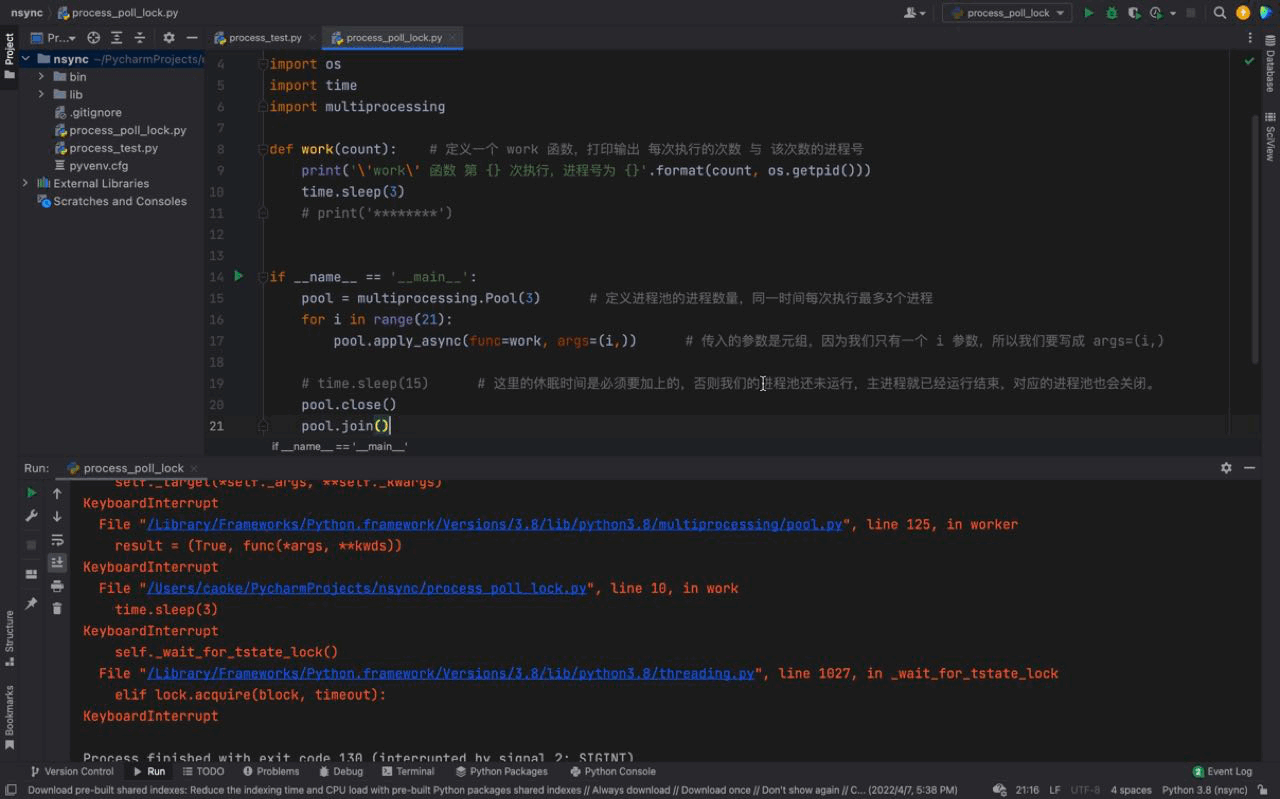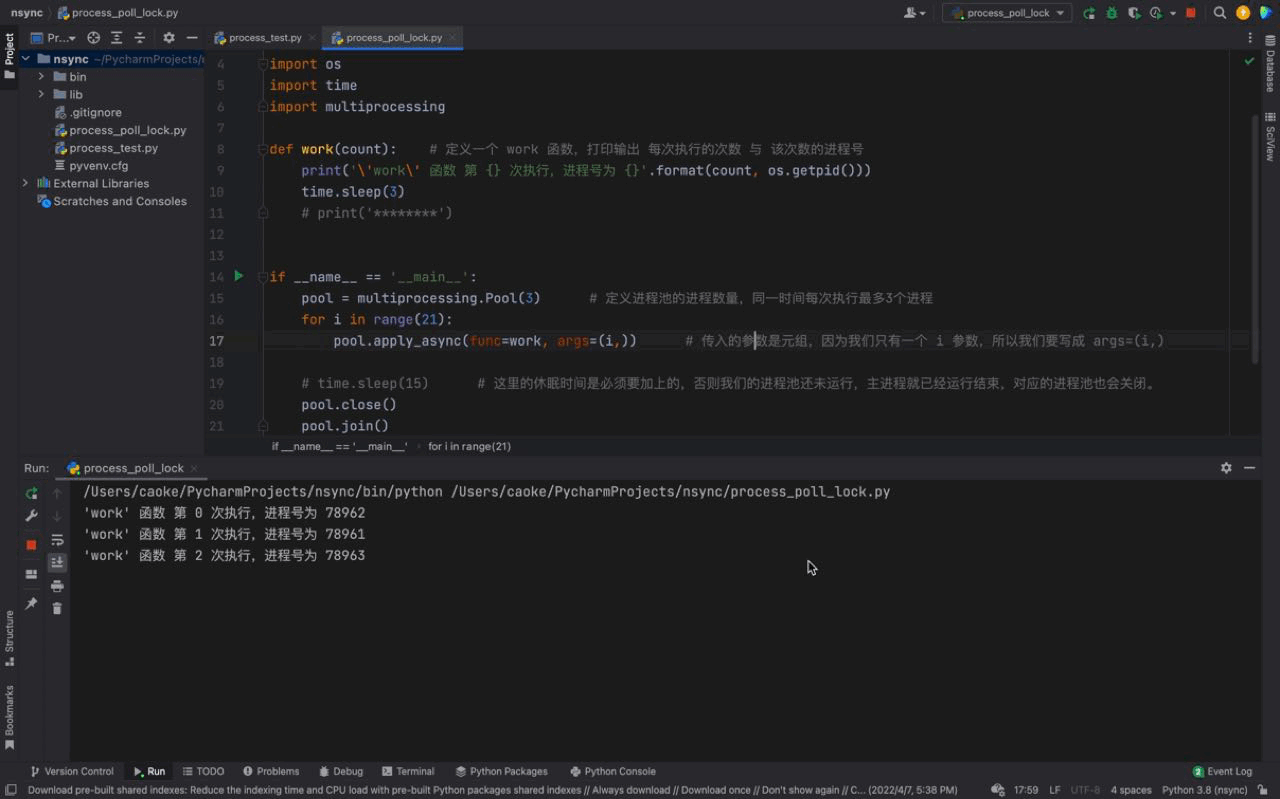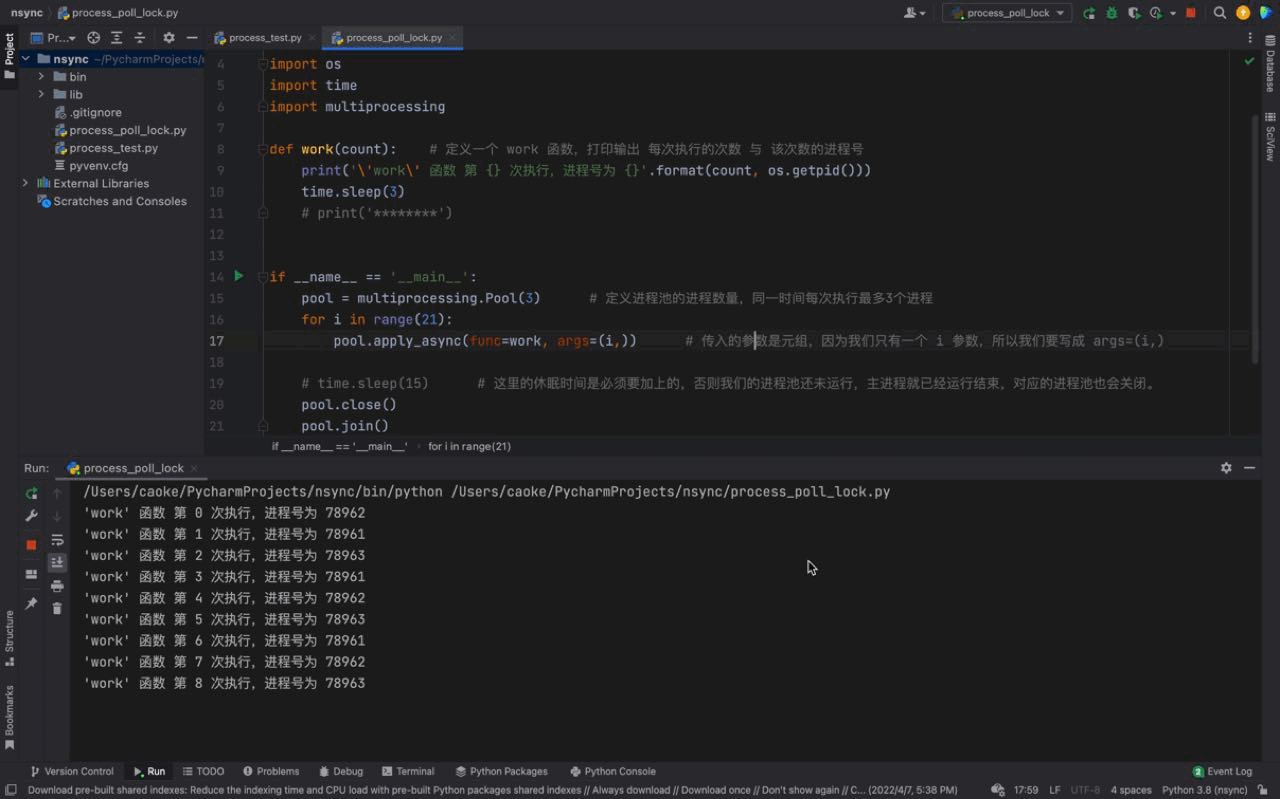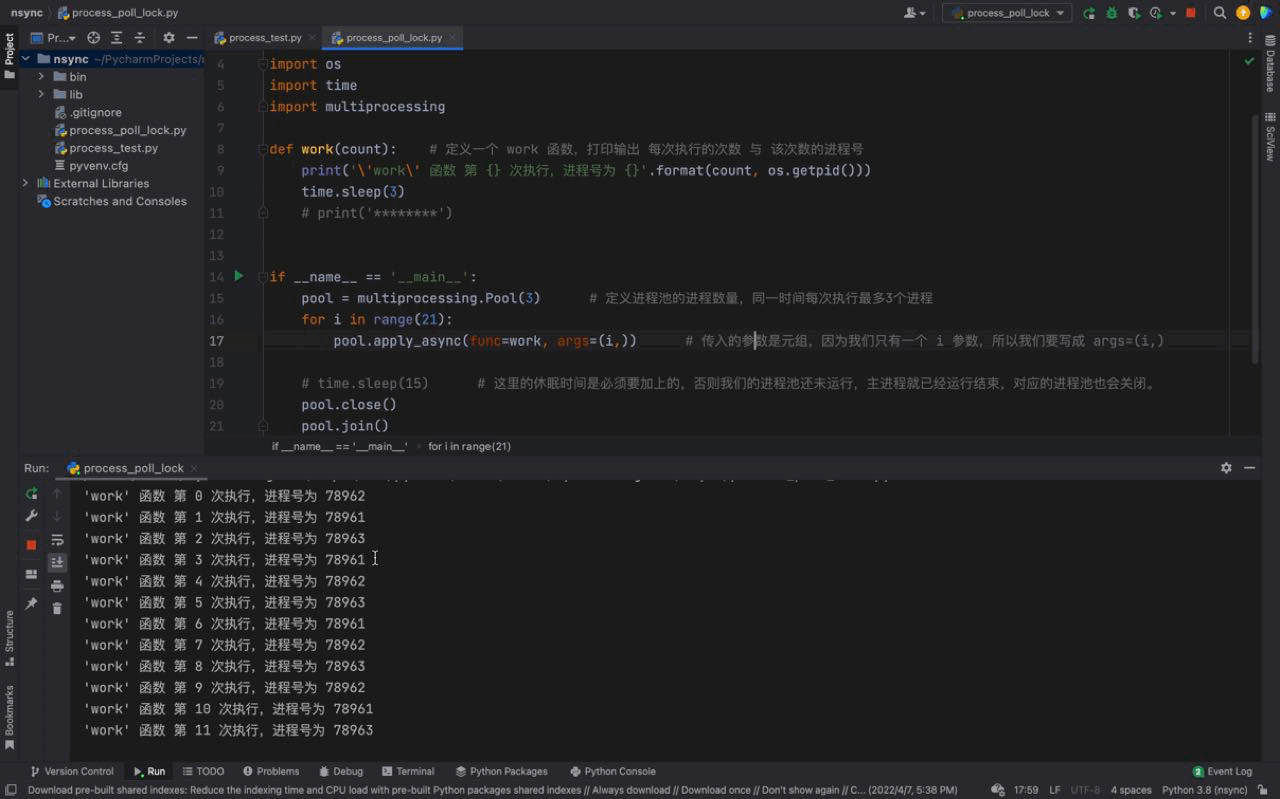
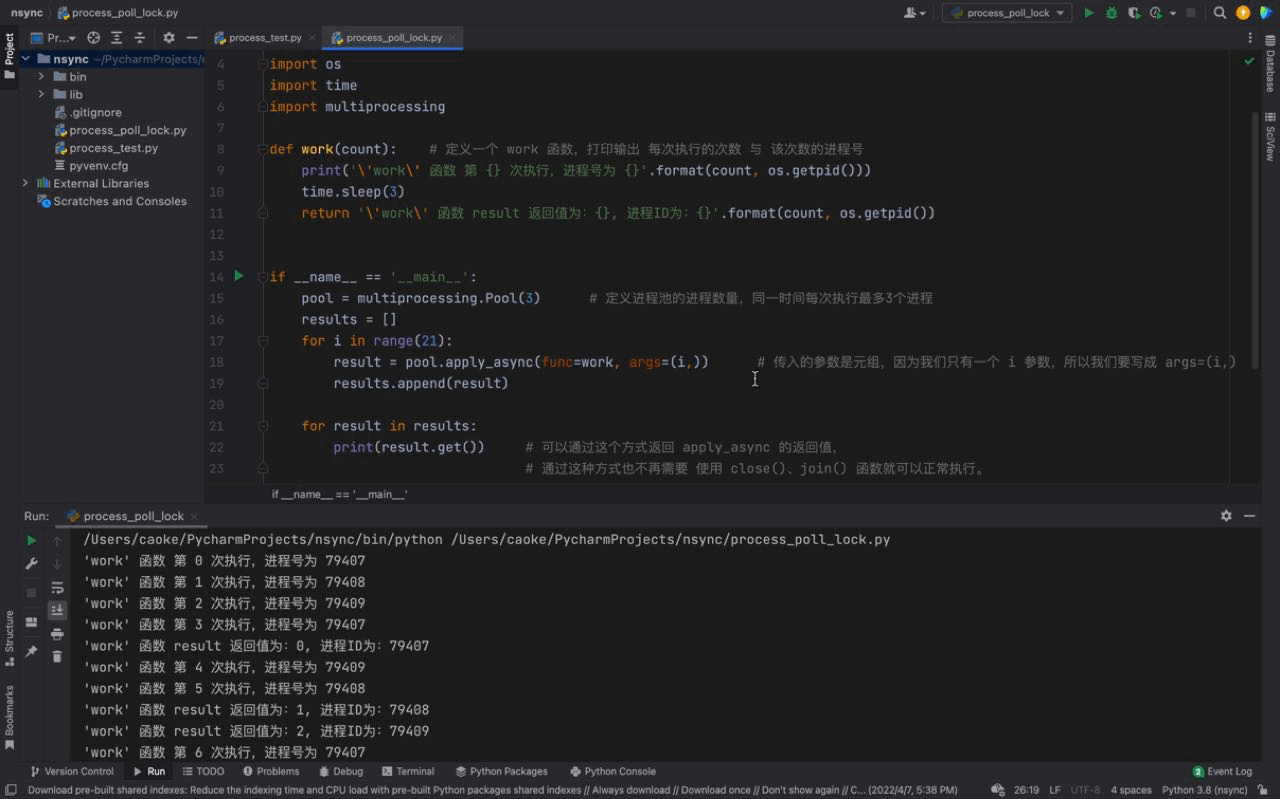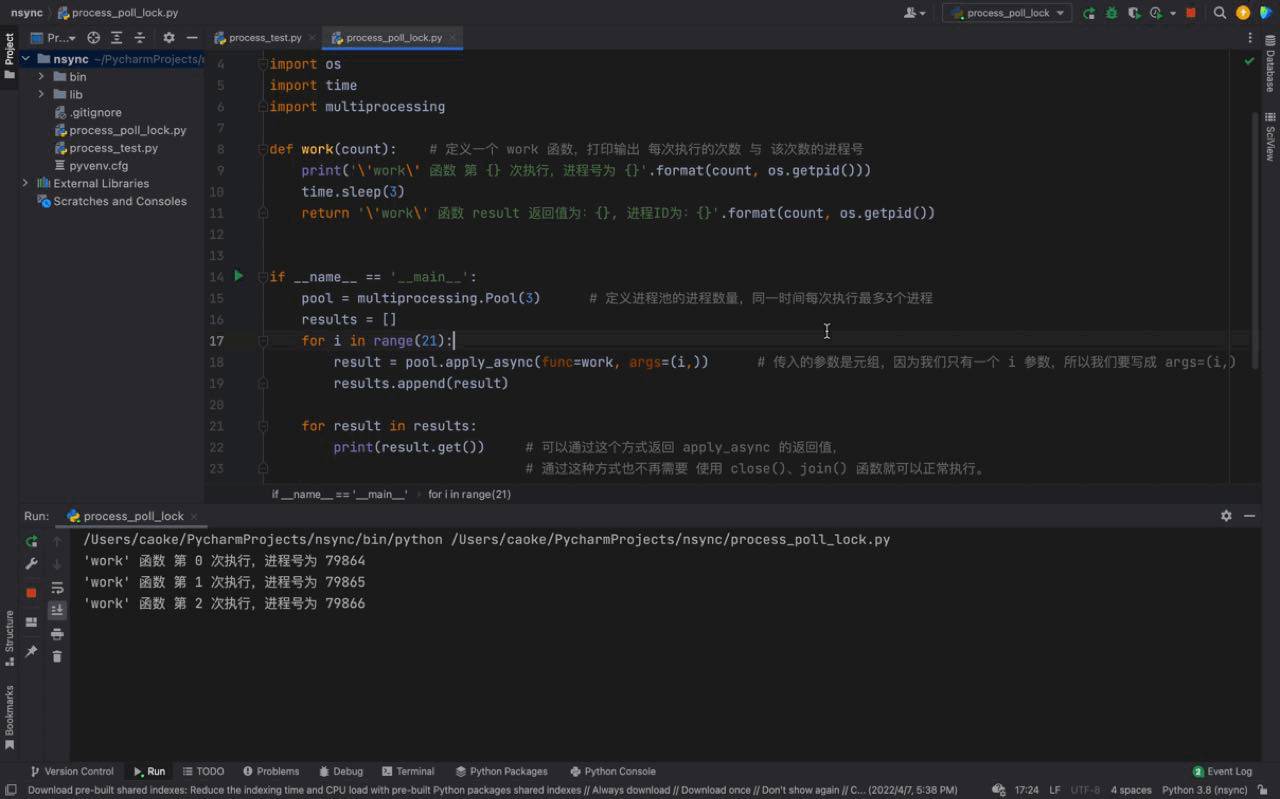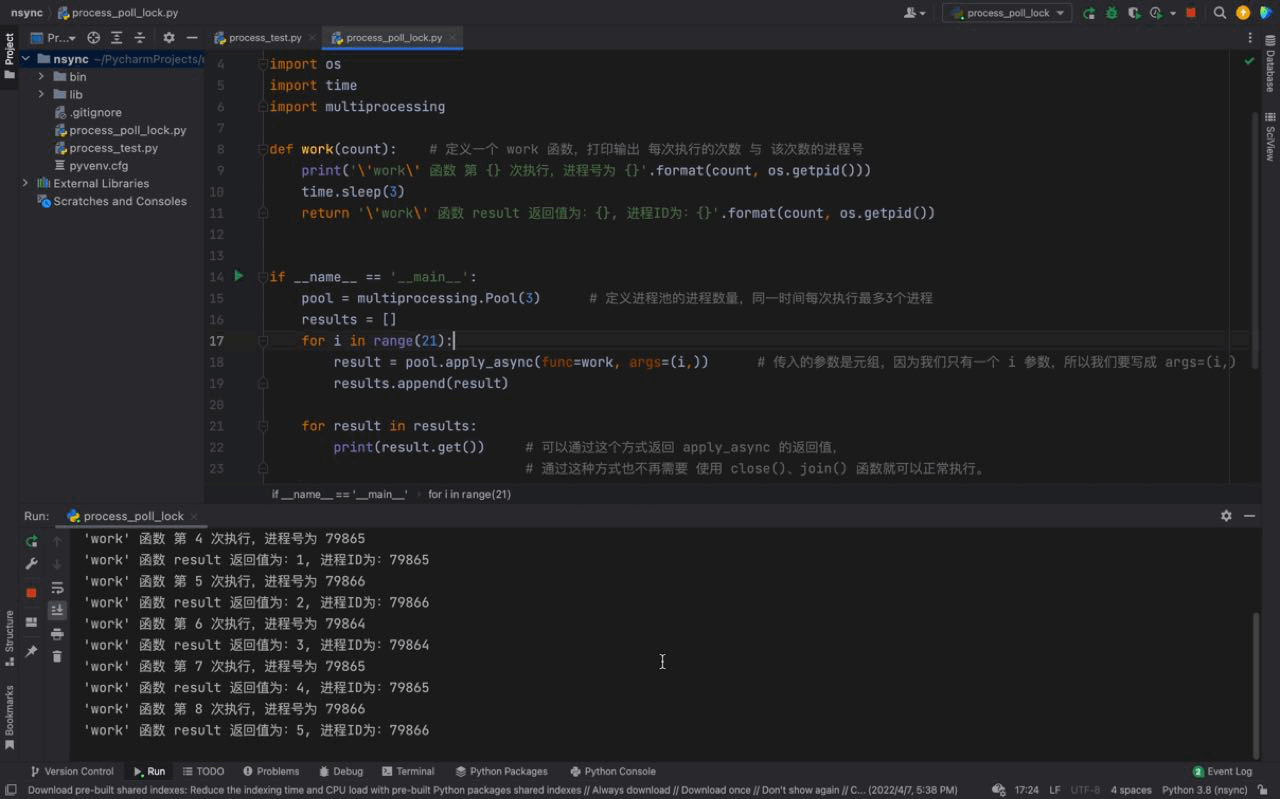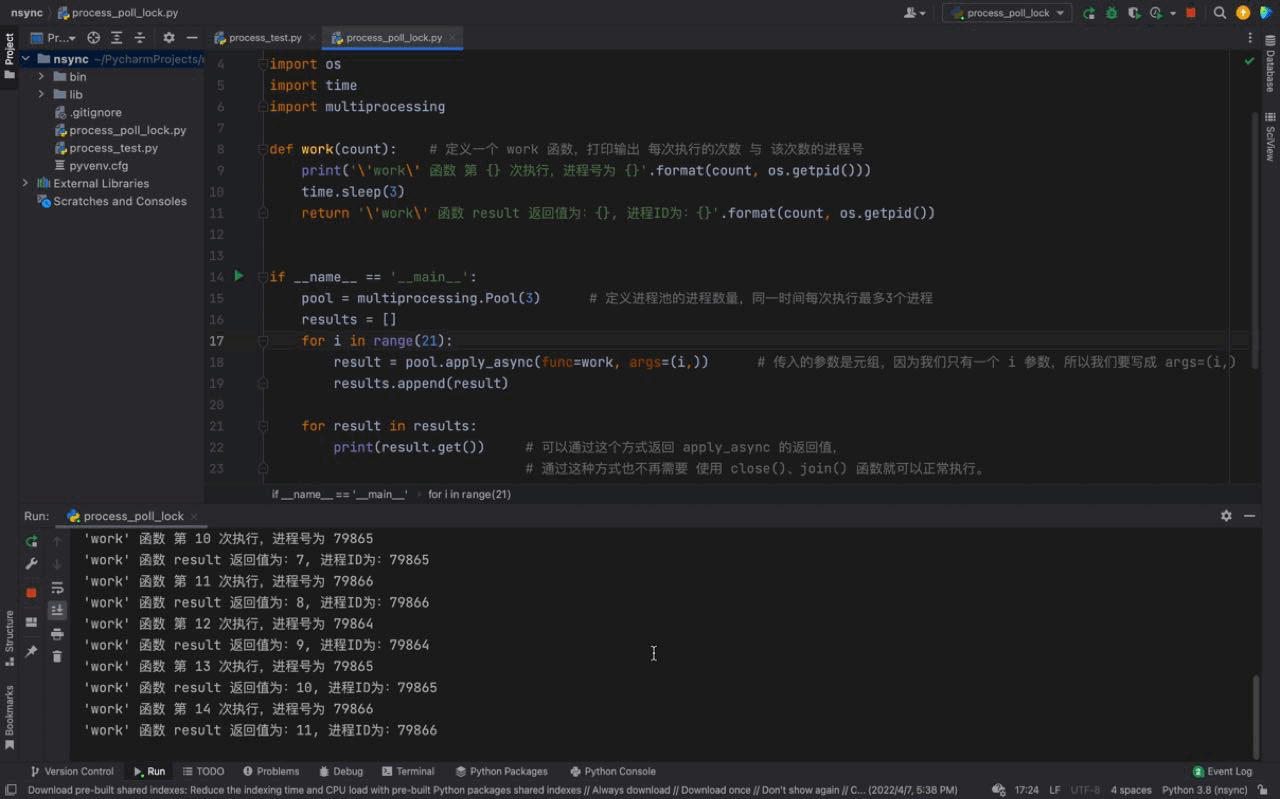
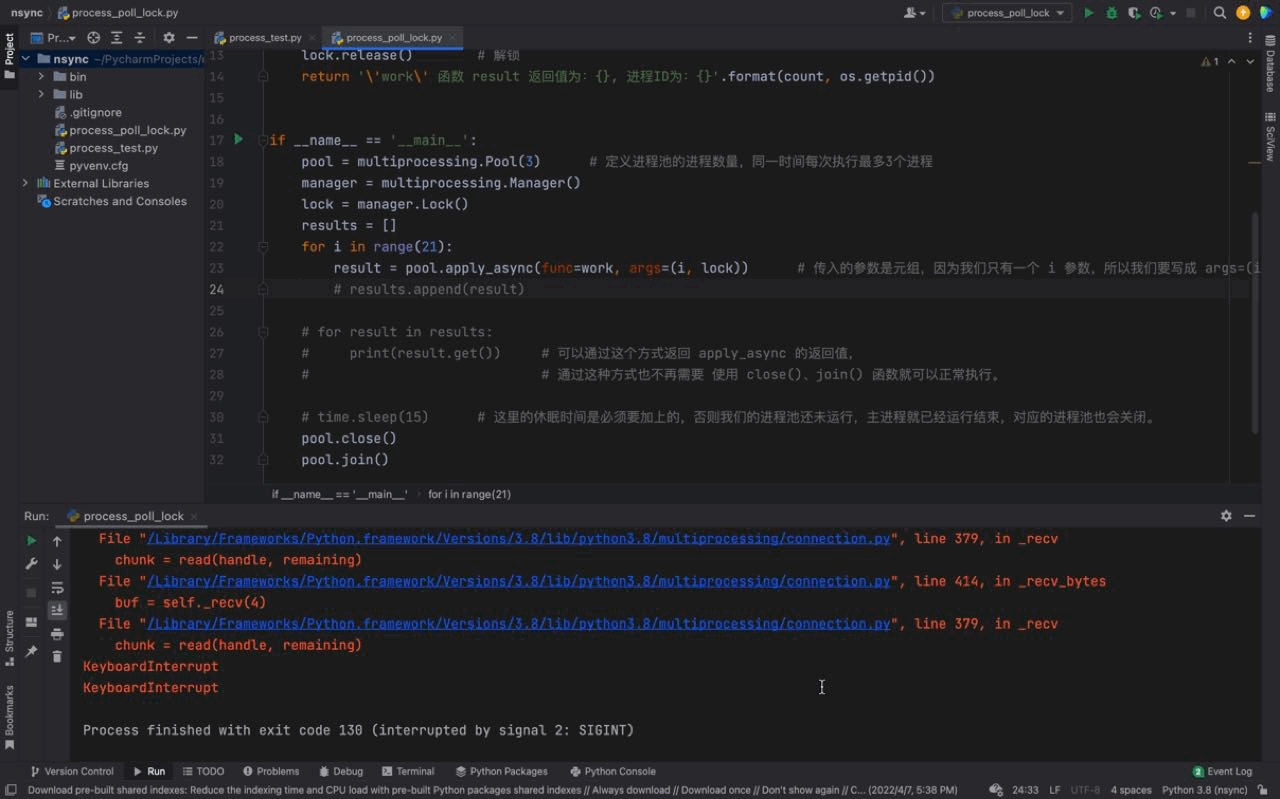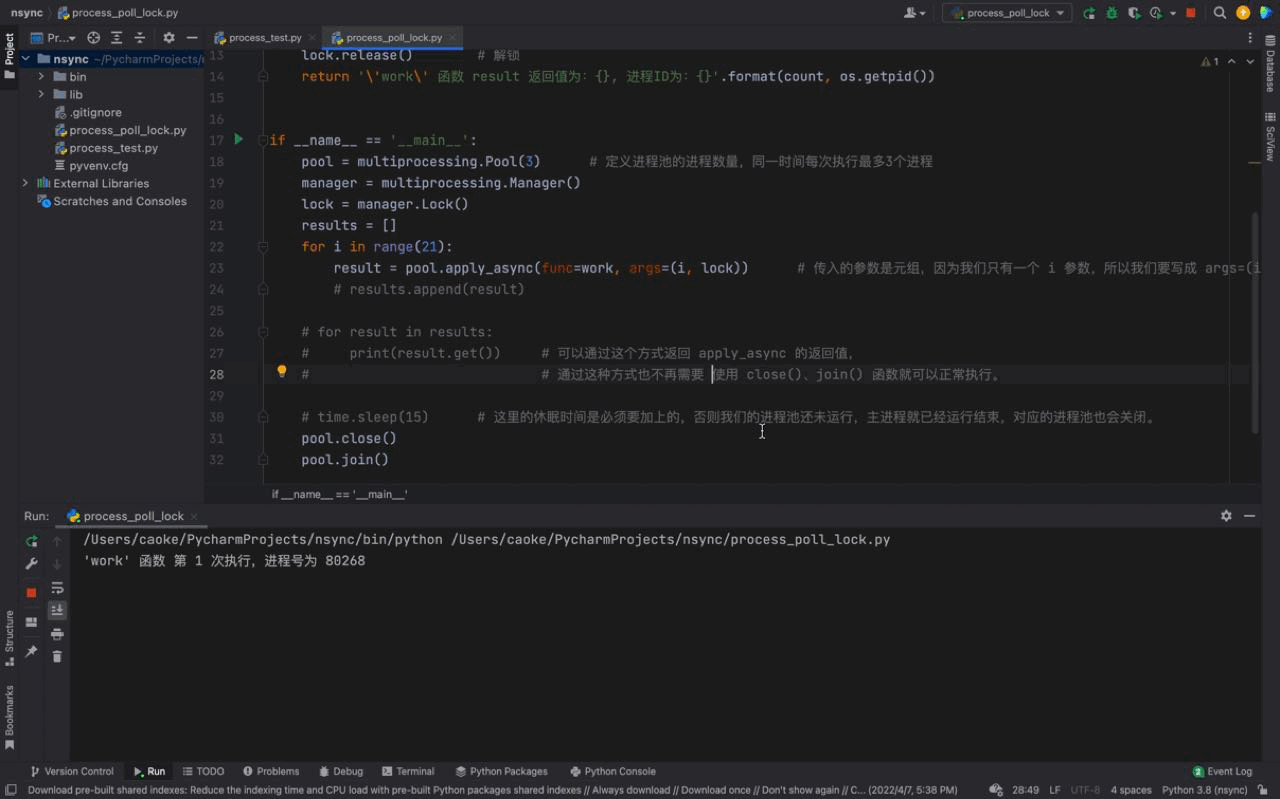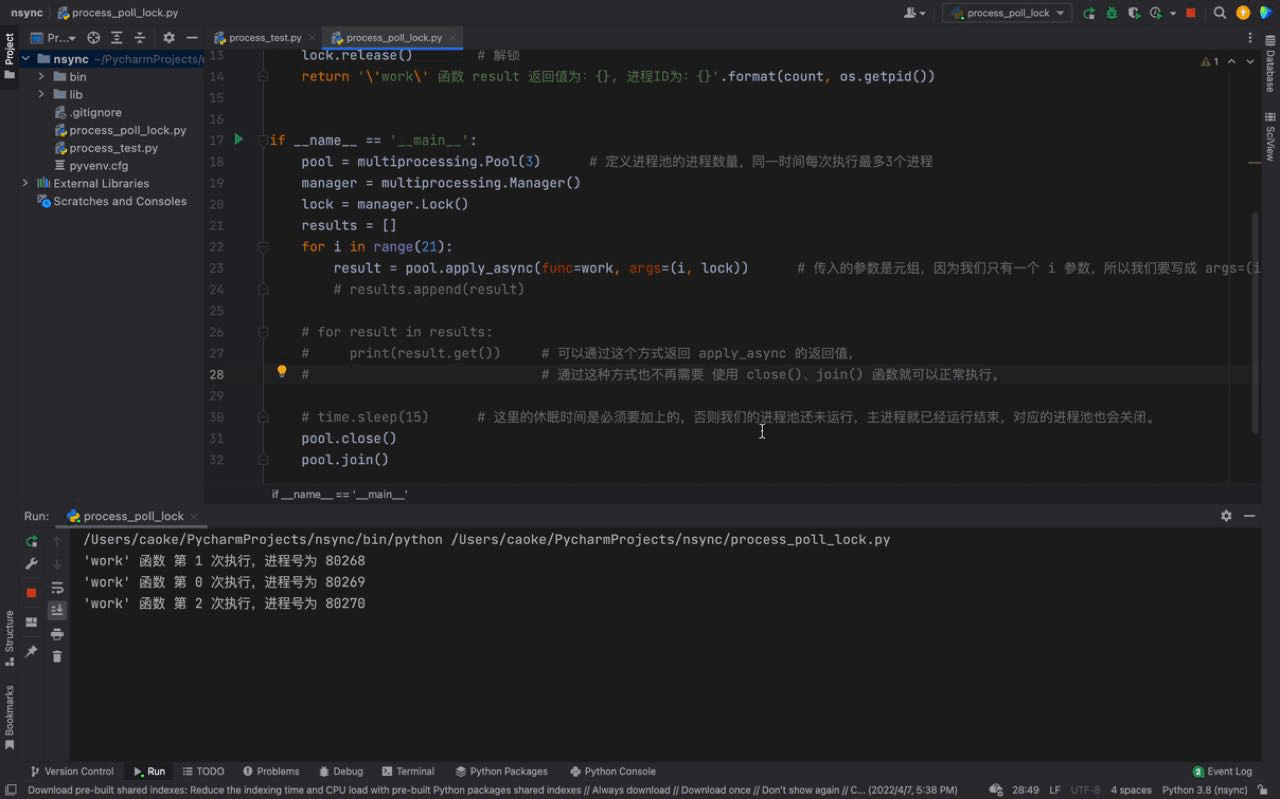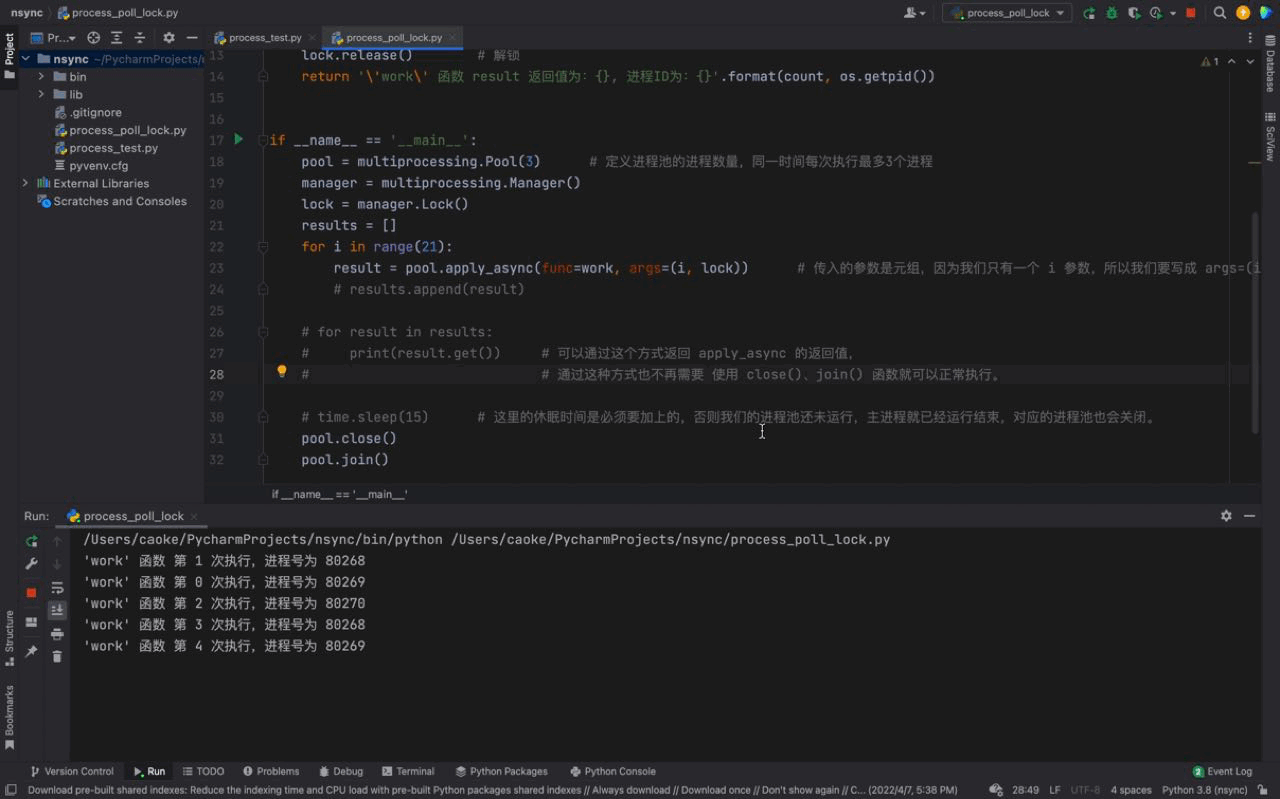
# 这里的休眠时间是必须要加上的,否则我们的进程池还未运行,主进程就已经运行结束,对应的进程池也会关闭。Nach dem Login kopieren 运行结果如下:
从上图中我们可以看到每一次都是一次性运行三个进程,每一个进程的进程号是不一样的,但仔细看会发现存在相同的进程号,这说明进程池的进程号在被重复利用。这证明我们上文介绍的内容,进程池中的进程不会被关闭,可以反复使用。 而且我们还可以看到每隔3秒都会执行3个进程,原因是我们的进程池中只有3个进程;虽然我们的 同样的,进程号在顺序上回出现一定的区别,原因是因为我们使用的是一种
close 函数与 join 函数 演示在上文的脚本中, 我们使用 如果没有 示例代码如下: # coding:utf-8import osimport timeimport multiprocessingdef work(count):
# 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
# print('********')if __name__ == '__main__':
pool = multiprocessing.Pool(3) # 定义进程池的进程数量,同一时间每次执行最多3个进程
for i in range(21):
pool.apply_async(func=work, args=(i,))
# 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
# time.sleep(15)
pool.close()
pool.join()Nach dem Login kopieren 运行结果如下:
从上面的动图我们可以看出, PS:如果我们的主进程会一直执行,不会退出。那么我们并不需要添加 在后面学习 WEB 开发之后,不退出主进程进行工作是家常便饭。还有一些需要长期执行的任务也不会关闭,但要是只有一次性执行的脚本,就需要添加
Demonstrationsfall für die Funktion „Apply_async“Als nächstes erstellen wir ein Skript in Pycharm, um die Verwendung des Prozesspools zu üben. 🎜🎜🎜🎜Definieren Sie eine Funktion und geben Sie aus, wie oft die Funktion jedes Mal ausgeführt wird, sowie die Prozessnummer dieser Anzahl.🎜Definieren Sie die Anzahl der Prozesspools, die jeweils ausgeführt werden die Anzahl der für den Prozesspool festgelegten Prozesse. Anzahl Der Beispielcode lautet wie folgt: 🎜 # coding:utf-8import osimport timeimport multiprocessingdef work(count): # 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
return '\'work\' 函数 result 返回值为:{}, 进程ID为:{}'.format(count, os.getpid())if __name__ == '__main__':
pool = multiprocessing.Pool(3) # 定义进程池的进程数量,同一时间每次执行最多3个进程
results = []
for i in range(21):
result = pool.apply_async(func=work, args=(i,)) # 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
results.append(result)
for result in results:
print(result.get()) # 可以通过这个方式返回 apply_async 的返回值,
# 通过这种方式也不再需要 使用 close()、join() 函数就可以正常执行。
# time.sleep(15) # 这里的休眠时间是必须要加上的,否则我们的进程池还未运行,主进程就已经运行结束,对应的进程池也会关闭。
# pool.close()
# pool.join()Nach dem Login kopieren Nach dem Login kopieren Das laufende Ergebnis lautet wie folgt: 🎜
Auf dem Bild oben können wir sehen, dass jedes Mal, wenn drei Prozesse gleichzeitig ausgeführt werden, die Prozessnummer jedes Prozesses unterschiedlich ist. Wenn Sie jedoch genau hinsehen, werden Sie feststellen, dass dieselbe Prozessnummer vorhanden ist zeigt an, dass die Prozessnummer des Prozesspools wiederverwendet wird. Dies beweist, was wir oben eingeführt haben: Die Prozesse im Prozesspool werden nicht geschlossen und können wiederholt verwendet werden. 🎜 Und wir können auch sehen, dass alle 3 Sekunden 3 Prozesse ausgeführt werden, da sich in unserem Prozesspool nur 3 Prozesse befinden, obwohl sich in unserer Ebenso gibt es einen gewissen Unterschied in der Reihenfolge der Prozessnummern. Der Grund dafür ist, dass wir eine
Funktion schließen und Funktionsdemonstration beitretenIm obigen Skript verwenden wir Der Beispielcode lautet wie folgt: 🎜 # coding:utf-8import osimport timeimport multiprocessingdef work(count, lock): # 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号,增加线程锁。
lock.acquire() # 上锁
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
lock.release() # 解锁
return '\'work\' 函数 result 返回值为:{}, 进程ID为:{}'.format(count, os.getpid())if __name__ == '__main__':
pool = multiprocessing.Pool(3) # 定义进程池的进程数量,同一时间每次执行最多3个进程
manager = multiprocessing.Manager()
lock = manager.Lock()
results = []
for i in range(21):
result = pool.apply_async(func=work, args=(i, lock)) # 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
# results.append(result)
# time.sleep(15) # 这里的休眠时间是必须要加上的,否则我们的进程池还未运行,主进程就已经运行结束,对应的进程池也会关闭。
pool.close()
pool.join()Nach dem Login kopieren Nach dem Login kopieren Das laufende Ergebnis lautet wie folgt: 🎜
Aus der obigen Animation können wir sehen, dass die Aufgaben des PS: Wenn unser Hauptprozess immer ausgeführt wird, wird er nicht beendet. Dann müssen wir die Funktionen Nachdem man später die WEB-Entwicklung erlernt hat, ist es üblich, zu arbeiten, ohne den Hauptprozess zu verlassen. Es gibt auch einige Aufgaben, die über einen längeren Zeitraum ausgeführt werden müssen und nicht geschlossen werden. Wenn jedoch nur einmal ausgeführte Skripte vorhanden sind, müssen Sie die Funktionen Möglicherweise haben Sie hier eine Frage. Im vorherigen Kapitel wurde im Wissenspunkt zum Prozess klar angegeben, dass 其实不然,在我们的使用进程池的 示例代码如下: # coding:utf-8import osimport timeimport multiprocessingdef work(count): # 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
return '\'work\' 函数 result 返回值为:{}, 进程ID为:{}'.format(count, os.getpid())if __name__ == '__main__':
pool = multiprocessing.Pool(3) # 定义进程池的进程数量,同一时间每次执行最多3个进程
results = []
for i in range(21):
result = pool.apply_async(func=work, args=(i,)) # 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
results.append(result)
for result in results:
print(result.get()) # 可以通过这个方式返回 apply_async 的返回值,
# 通过这种方式也不再需要 使用 close()、join() 函数就可以正常执行。
# time.sleep(15) # 这里的休眠时间是必须要加上的,否则我们的进程池还未运行,主进程就已经运行结束,对应的进程池也会关闭。
# pool.close()
# pool.join()Nach dem Login kopieren Nach dem Login kopieren 运行结果如下:
从运行结果可以看出,首先 这些都是主要依赖于 进程锁进程锁的概念锁:大家都知道,我们可以给一个大门上锁。 结合这个场景来举一个例子:比如现在有多个进程同时冲向一个 而 进程锁的加锁与解锁进程锁的使用方法:
代码示例如下: # coding:utf-8import osimport timeimport multiprocessingdef work(count, lock): # 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号,增加线程锁。
lock.acquire() # 上锁
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
lock.release() # 解锁
return '\'work\' 函数 result 返回值为:{}, 进程ID为:{}'.format(count, os.getpid())if __name__ == '__main__':
pool = multiprocessing.Pool(3) # 定义进程池的进程数量,同一时间每次执行最多3个进程
manager = multiprocessing.Manager()
lock = manager.Lock()
results = []
for i in range(21):
result = pool.apply_async(func=work, args=(i, lock)) # 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
# results.append(result)
# time.sleep(15) # 这里的休眠时间是必须要加上的,否则我们的进程池还未运行,主进程就已经运行结束,对应的进程池也会关闭。
pool.close()
pool.join()Nach dem Login kopieren Nach dem Login kopieren 执行结果如下:
从上图中,可以看到每一次只有一个任务会被执行。由于每一个进程会被阻塞 3秒钟,所以我们的进程执行的非常慢。这是因为每一个进程进入到 work() 函数中,都会执行 其实进程锁还有很多种方法,在
因为 推荐学习:python视频教程 |
 🎜
🎜
Das obige ist der detaillierte Inhalt vonErfahren Sie mehr über Python-Prozesspools und Prozesssperren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, hochrangige skalierbare Python-Datenbank Hadidb (HadIDB) ist eine leichte Datenbank in Python mit einem hohen Maß an Skalierbarkeit. Installieren Sie HadIDB mithilfe der PIP -Installation: PipinstallHadIDB -Benutzerverwaltung erstellen Benutzer: createUser (), um einen neuen Benutzer zu erstellen. Die Authentication () -Methode authentifiziert die Identität des Benutzers. fromHadidb.operationImportUseruser_obj = user ("admin", "admin") user_obj.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Wie man AWS -Kleber mit Amazon Athena verwendet
Apr 09, 2025 pm 03:09 PM
Wie man AWS -Kleber mit Amazon Athena verwendet
Apr 09, 2025 pm 03:09 PM
Als Datenprofi müssen Sie große Datenmengen aus verschiedenen Quellen verarbeiten. Dies kann Herausforderungen für das Datenmanagement und die Analyse darstellen. Glücklicherweise können zwei AWS -Dienste helfen: AWS -Kleber und Amazon Athena.
 Python: Erforschen der primären Anwendungen
Apr 10, 2025 am 09:41 AM
Python: Erforschen der primären Anwendungen
Apr 10, 2025 am 09:41 AM
Python wird in den Bereichen Webentwicklung, Datenwissenschaft, maschinelles Lernen, Automatisierung und Skripten häufig verwendet. 1) In der Webentwicklung vereinfachen Django und Flask Frameworks den Entwicklungsprozess. 2) In den Bereichen Datenwissenschaft und maschinelles Lernen bieten Numpy-, Pandas-, Scikit-Learn- und TensorFlow-Bibliotheken eine starke Unterstützung. 3) In Bezug auf Automatisierung und Skript ist Python für Aufgaben wie automatisiertes Test und Systemmanagement geeignet.
 Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Sie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Kann MySQL mit dem SQL -Server eine Verbindung herstellen?
Apr 08, 2025 pm 05:54 PM
Kann MySQL mit dem SQL -Server eine Verbindung herstellen?
Apr 08, 2025 pm 05:54 PM
Nein, MySQL kann keine direkt zu SQL Server herstellen. Sie können jedoch die folgenden Methoden verwenden, um die Dateninteraktion zu implementieren: Verwenden Sie Middleware: Exportieren Sie Daten von MySQL in das Zwischenformat und importieren sie dann über Middleware in SQL Server. Verwenden von Datenbank -Linker: Business -Tools bieten eine freundlichere Oberfläche und erweiterte Funktionen, die im Wesentlichen weiterhin über Middleware implementiert werden.
