Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL, das hauptsächlich die relevanten Inhalte zu den Architekturprinzipien vorstellt. Die MySQL-Server-Architektur kann von oben nach unten grob in Netzwerkverbindungsschicht, Serviceschicht, Speicher-Engine-Schicht und System unterteilt werden Werfen Sie einen Blick auf die Dateiebene. Ich hoffe, sie wird für alle hilfreich sein.

Empfohlenes Lernen: MySQL-Video-Tutorial
MySQL-Architekturprinzipien
1. MySQL-Architektur
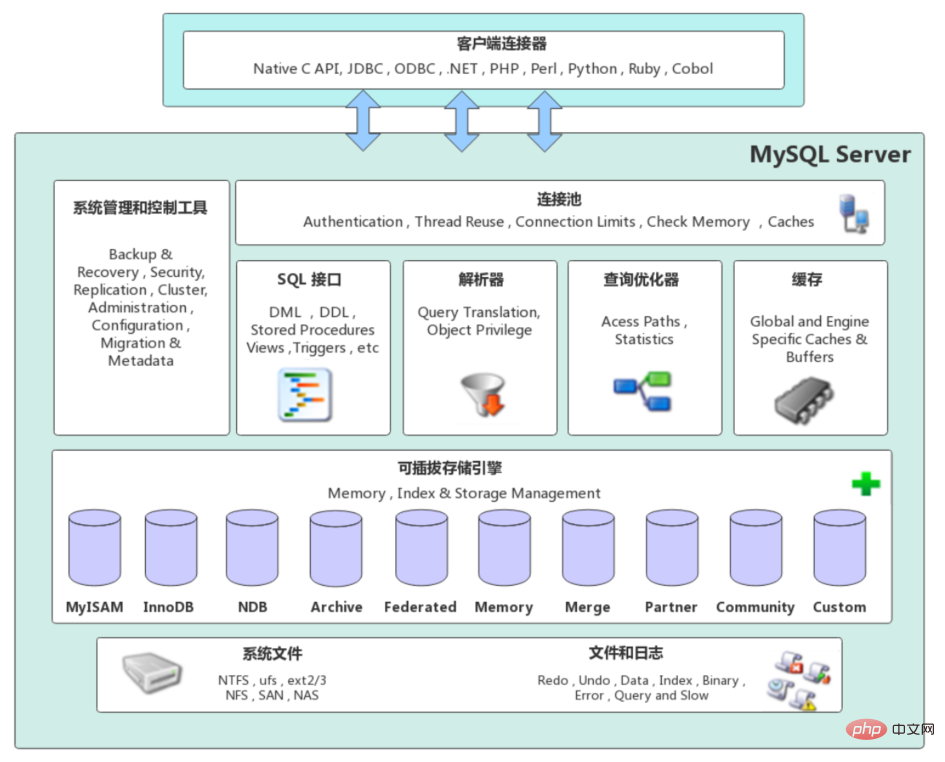
Die MySQL-Server-Architektur kann von oben nach unten grob in Netzwerkverbindungsschicht, Serviceschicht und Speicher-Engine-Schicht unterteilt werden und Systemdateischicht.
Netzwerkverbindungsschicht
- Client-Anschlüsse: Bietet Unterstützung für die Einrichtung mit dem MySQL-Server. Derzeit unterstützt es fast alle gängigen serverseitigen Programmiertechnologien, wie etwa gängiges Java, C, Python, .NET usw., die über ihre jeweiligen API-Technologien Verbindungen mit MySQL herstellen.
Serviceschicht (MySQL Server)
Die Serviceschicht ist der Kern von MySQL Server und besteht hauptsächlich aus sechs Teilen: Systemverwaltungs- und Kontrolltools, Verbindungspool, SQL-Schnittstelle, Parser, Abfrageoptimierer und Cache.
Verbindungspool: Verantwortlich für die Speicherung und Verwaltung der Verbindung zwischen dem Client und der Datenbank. Ein Thread ist für die Verwaltung einer Verbindung verantwortlich.
Systemverwaltungs- und Kontrolltools (Management Services & Utilities): wie Sicherung und Wiederherstellung, Sicherheitsverwaltung, Clusterverwaltung usw.
SQL-Schnittstelle (SQL-Schnittstelle): Wird zum Akzeptieren verschiedener von der gesendeten SQL-Befehle verwendet Client und gibt die Ergebnisse zurück, die der Benutzer abfragen muss. Wie DML, DDL, gespeicherte Prozeduren, Ansichten, Trigger usw.
Parser (Parser): Verantwortlich für das Parsen des angeforderten SQL, um einen „Analysebaum“ zu generieren. Überprüfen Sie dann weiter, ob der Analysebaum gemäß einigen MySQL-Regeln zulässig ist.
-
Abfrageoptimierer (Optimierer): Wenn der „Analysebaum“ die Parser-Grammatikprüfung besteht, wird er an den Optimierer übergeben, um ihn in einen Ausführungsplan umzuwandeln und dann mit der Speicher-Engine zu interagieren.
select uid, name from user where gender = 1;
Select--"Projection--"Join strategy
- select wählt zuerst basierend auf der where-Anweisung aus, anstatt alle Daten abzufragen und dann zu filtern;
- Die Projektion der ausgewählten Abfrageattribute erfolgt basierend auf UID und Name.
- Verbinden Sie die vorherige Auswahl und Projektion, um schließlich Abfrageergebnisse zu generieren eine Reihe kleiner Caches. Zum Beispiel Tabellencache, Datensatzcache, Berechtigungscache, Enginecache usw. Wenn der Abfrage-Cache ein Treffer-Abfrageergebnis hat, kann die Abfrageanweisung Daten direkt aus dem Abfrage-Cache abrufen.
Storage Engine Layer (Pluggable Storage Engines) -
Die Storage Engine ist für die Speicherung und den Abruf von Daten in MySQL verantwortlich und interagiert mit den zugrunde liegenden Systemdateien. Die MySQL-Speicher-Engine ist ein Plug-in. Die Abfrageausführungs-Engine im Server kommuniziert über eine Schnittstelle mit der Speicher-Engine. Mittlerweile gibt es viele Speicher-Engines, jede mit ihren eigenen Eigenschaften. Die häufigsten sind MyISAM und InnoDB.
Systemdateischicht (Dateisystem)
Diese Schicht ist für die Speicherung von Datenbankdaten und Protokollen im Dateisystem und die Vervollständigung der Interaktion mit der Speicher-Engine verantwortlich. Sie ist die physische Speicherschicht von Dateien. Enthält hauptsächlich Protokolldateien, Datendateien, Konfigurationsdateien, PID-Dateien, Socket-Dateien usw. -
- Protokolldatei
- Fehlerprotokoll
- Standardmäßig aktiviert, Variablen wie „%log_error%“ anzeigen;
- Allgemeines Abfrageprotokoll (Allgemeines Abfrageprotokoll)
- Allgemeine Abfrageanweisungen aufzeichnen, Variablen wie „%general%“ anzeigen ;
- Binäres Protokoll (Binärprotokoll)
- zeichnet die in der MySQL-Datenbank durchgeführten Änderungsvorgänge auf und zeichnet die Auftrittszeit und Ausführungszeit der Anweisung auf; es zeichnet jedoch keine Auswahl, Anzeige usw. auf. SQL tut dies Ändern Sie die Datenbank nicht. Wird hauptsächlich zur Datenbankwiederherstellung und Master-Slave-Replikation verwendet.
- Variablen wie „%log_bin%“ anzeigen; //Parameteransicht
- Binärprotokolle anzeigen
-
Protokoll für langsame Abfragen Langsames Abfrageprotokoll)
- Zeichnet alle Abfrage-SQL auf, deren Ausführungszeit abgelaufen ist. Der Standardwert beträgt 10 Sekunden.
- Variablen wie „%slow_query%“ anzeigen; //Ob aktiviert werden soll
- Variablen wie „%long_query_time%“ anzeigen; //Dauer
-
Konfigurationsdatei
- wird zum Speichern aller MySQL-Konfigurationsinformationsdateien verwendet. wie my.cnf, my.ini usw. Datendatei
- db.opt-Datei: Zeichnet den von dieser Bibliothek verwendeten Standardzeichensatz und die Überprüfungsregeln auf.
- FRM-Datei: Speichert Metadaten (Meta)-Informationen zur Tabelle, einschließlich Definitionsinformationen der Tabellenstruktur usw. Jede Tabelle verfügt über eine FRM-Datei.
- MYD-Datei: Sie ist für die MyISAM-Speicher-Engine bestimmt und speichert die Daten der MyISAM-Tabelle. Jede Tabelle verfügt über eine .MYD-Datei.
- MYI-Datei: Dediziert für die MyISAM-Speicher-Engine, die indexbezogene Informationen der MyISAM-Tabelle speichert. Jede MyISAM-Tabelle entspricht einer .MYI-Datei.
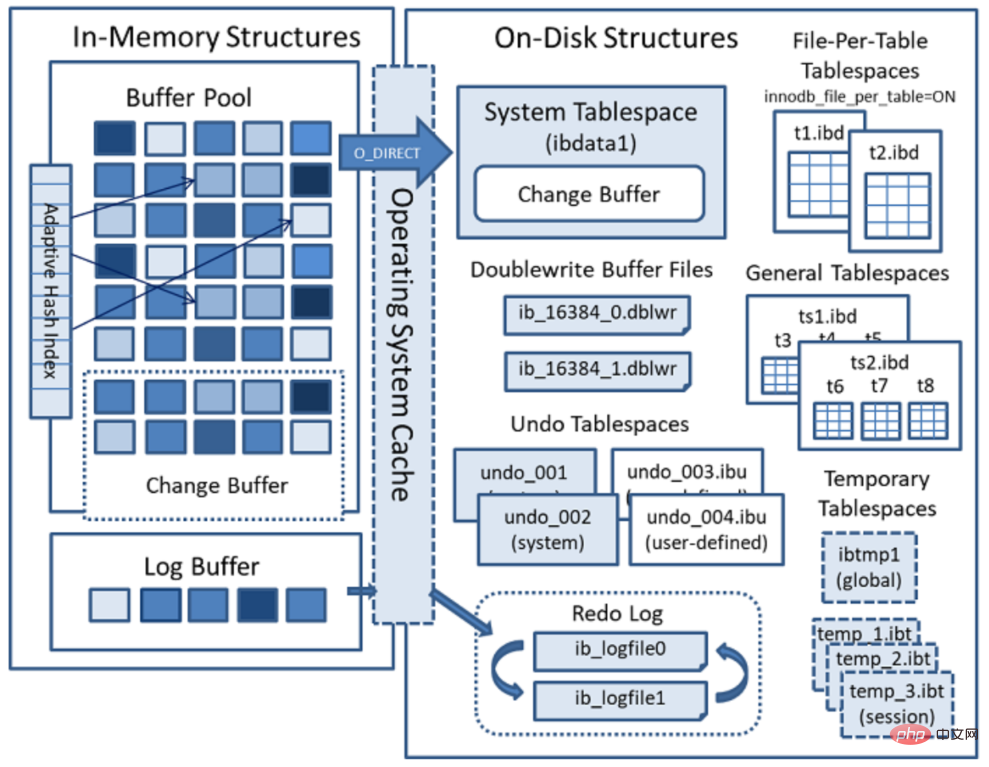
- IBD-Datei und IBDATA-Datei: Speichern Sie InnoDB-Datendateien (einschließlich Indizes). Die InnoDB-Speicher-Engine verfügt über zwei Tabellenbereichsmodi: exklusiven Tabellenbereich und gemeinsam genutzten Tabellenbereich. Exklusive Tabellenbereiche verwenden .ibd-Dateien zum Speichern von Daten, und jede InnoDB-Tabelle entspricht einer .ibd-Datei. Gemeinsam genutzte Tabellenbereiche verwenden .ibdata-Dateien und alle Tabellen verwenden eine (oder mehrere, selbst konfigurierte) .ibdata-Dateien.
- ibdata1-Datei: Systemtabellenbereichsdatendatei, in der Tabellenmetadaten, Rückgängig-Protokolle usw. gespeichert werden.
- ib_logfile0, ib_logfile1 Dateien: Redo-Log-Protokolldateien.
-
PID-Datei
- PID-Datei ist eine Prozessdatei der MySQL-Anwendung in der Unix/Linux-Umgebung und speichert wie viele andere Unix/Linux-Serverprogramme ihre eigene Prozess-ID. Socket-Datei
- Socket-Datei ist auch in einer Unix/Linux-Umgebung verfügbar. Benutzer können Unix Socket direkt verwenden, um eine Verbindung zu MySQL herzustellen, wenn eine Client-Verbindung in einer Unix/Linux-Umgebung hergestellt wird, ohne über ein TCP/IP-Netzwerk zu gehen.
2. MySQL-Betriebsmechanismus
- Stellen Sie eine Verbindung her (Connectoren und Verbindungspool) und stellen Sie über das Client/Server-Kommunikationsprotokoll eine Verbindung mit MySQL her. Die Kommunikationsmethode zwischen MySQL-Client und Server ist „Halbduplex“. Für jede MySQL-Verbindung gibt es jederzeit einen Thread-Status, um zu identifizieren, was die Verbindung tut.
- Kommunikationsmechanismus:
- Vollduplex: Kann gleichzeitig Daten senden und empfangen, z. B. beim Telefonieren.
- Halbduplex: bezieht sich auf einen bestimmten Zeitpunkt, bei dem entweder Daten gesendet oder Daten empfangen werden, nicht gleichzeitig. Zum Beispiel frühe Walkie-Talkies
- simplex: können nur Daten senden oder nur Daten empfangen. Beispiel: Einbahnstraße;
- Thread-Status: Zeige die Thread-Informationen an, die der Benutzer ausführt. Der Root-Benutzer kann alle Threads anzeigen, andere Benutzer können nur ihre eigenen anzeigen. Thread-ID, Sie können kill xx verwenden;
- user: Der Benutzer, der diesen Thread gestartet hat
- Host: Die IP- und Portnummer des Clients, der die Anfrage gesendet hat
- db: In welcher Bibliothek der aktuelle Befehl ausgeführt wird
- Command : Der Operationsbefehl, der von diesem Thread ausgeführt wird
- Create DB: Derzeitige Bibliotheksoperation erstellen
- Drop DB: Bibliotheksoperation löschen
- Execute: Ein PreparedStatement ausführen
- Close Stmt: Ein PreparedStatement schließen
- Query: Eine Anweisung ausführen
- Ruhezustand: Warten darauf, dass der Client eine Anweisung sendet.
- Beenden: Wird beendet.
- Shutdown: Herunterfahren des Servers.
-
Zeit: Gibt die Zeit an, die sich der Thread im aktuellen Status befindet, in Sekunden.
- Status: Thread-Status
- Aktualisierung: Suche nach übereinstimmenden Datensätzen und Durchführung von Änderungen
- Schlafend: Wartet derzeit darauf, dass der Client eine neue Anfrage sendet
- Beginnt: Anforderungsverarbeitung wird durchgeführt
- Prüftabelle: Die Datentabelle wird überprüft
- Schließtabelle: Die Daten in der Tabelle wird auf der Festplatte aktualisiert
- Gesperrt: Der Datensatz ist durch andere Abfragen gesperrt
- Daten senden: Verarbeiten der Select-Abfrage und gleichzeitiges Senden der Ergebnisse an den Client
-
Info: Zeichnet im Allgemeinen die Anweisungen auf Wird vom Thread ausgeführt und zeigt standardmäßig die ersten 100 Zeichen an. Möchten Sie die vollständige Verwendung von „show full Processlist“ sehen? Beim Abfrage-Cache-Prozess werden die Abfrageergebnisse direkt an den Client zurückgegeben. Wenn der Abfrage-Cache nicht aktiviert ist oder nicht genau dieselbe SQL-Anweisung abgefragt wird, führt der Parser eine syntaktische und semantische Analyse durch und generiert einen „Analysebaum“.
- Zwischenspeichern Sie die Ergebnisse der Select-Abfrage und der SQL-Anweisungen.
Fragen Sie beim Ausführen der Select-Abfrage zunächst den Cache ab, um festzustellen, ob ein Datensatz verfügbar ist und ob die Anforderungen genau gleich sind (einschließlich Parameterwerte). Die zwischengespeicherten Datentreffer werden abgeglichen.
Auch wenn der Abfragecache aktiviert ist, kann das folgende SQL nicht zwischengespeichert werden:
- Die Abfrageanweisung verwendet SQL_NO_CACHE
- Das Abfrageergebnis ist größer als die Einstellung query_cache_limit
- Es gibt einige Unsicherheiten Parameter in der Abfrage, wie zum Beispiel now()
-
- Variablen wie „%query_cache %“ anzeigen //Überprüfen Sie, ob der Abfragecache aktiviert ist, Speicherplatzgröße, Einschränkungen usw.
- Status anzeigen wie „Qcache%“; //Detailliertere Cache-Parameter, verfügbaren Cache-Speicherplatz, Cache-Blöcke, Cache-Größe usw. anzeigen.
-
Analyse Der Parser analysiert das vom Client gesendete SQL und generiert einen „Analysebaum“. Der Präprozessor prüft außerdem anhand einiger MySQL-Regeln, ob der „Analysebaum“ zulässig ist. Er prüft beispielsweise, ob die Datentabelle und die Datenspalte vorhanden sind, analysiert auch Namen und Aliase, um festzustellen, ob sie mehrdeutig sind, und generiert schließlich eine neuer „Parse-Baum“.
- Der Abfrageoptimierer (Optimizer) generiert den optimalen Ausführungsplan basierend auf dem „Analysebaum“. MySQL verwendet viele Optimierungsstrategien, um optimale Ausführungspläne zu generieren, die in zwei Kategorien unterteilt werden können: statische Optimierung (Kompilierungszeitoptimierung) und dynamische Optimierung (Laufzeitoptimierung).
- Äquivalente Transformationsstrategie
- 5=5 und a>5 wird in a > 5 geändert
- a 5 und a=5 geändert
- Anpassen die Bedingungsposition usw.
- Anzahl, Min, Max und andere Funktionen optimieren
- Die Min-Funktion der InnoDB-Engine muss nur den Index ganz links finden.
- Die Max-Funktion der InnoDB-Engine muss nur den Index ganz rechts finden.
- Anzahl der MyISAM-Engine (*), keine Berechnung erforderlich, direkt Rückkehr
- Beenden Sie die Abfrage vorzeitig
- Verwenden Sie die Limit-Abfrage, um die für das Limit erforderlichen Daten zu erhalten, ohne die nachfolgenden Daten weiter zu durchlaufen
- Optimierung in
- MySQL sortiert zunächst die Abfrage und verwendet dann die binäre Aufteilungsmethode, um Daten zu finden. Beispielsweise wird die ID in (2,1,3) zu (1,2,3);
- Die Abfrageausführungs-Engine ist zu diesem Zeitpunkt für die Ausführung der SQL-Anweisung verantwortlich Basierend auf der Speicherung der Tabelle in der SQL-Anweisung interagieren der Engine-Typ und die entsprechende API-Schnittstelle mit dem zugrunde liegenden Speicher-Engine-Cache oder den physischen Dateien, um die Abfrageergebnisse abzurufen und an den Client zurückzugeben. Wenn der Abfragecache aktiviert ist, werden die SQL-Anweisung und die Ergebnisse vollständig im Abfragecache gespeichert (Cache&Buffffer). Wenn dieselbe SQL-Anweisung in Zukunft ausgeführt wird, werden die Ergebnisse direkt zurückgegeben.
- Wenn das Abfrage-Caching aktiviert ist, müssen Sie zuerst die Abfrageergebnisse zwischenspeichern.
- Es sind zu viele zurückgegebene Ergebnisse vorhanden. Verwenden Sie den inkrementellen Modus für die Rückgabe.
- Beim Starten der Ausführung müssen Sie zunächst feststellen, ob Sie berechtigt sind, Abfragen für diese Tabelle T auszuführen. Wenn Wenn dies nicht der Fall ist, wird ein Fehler aufgrund fehlender Berechtigungen zurückgegeben (Wenn der Abfragecache erreicht wird, wird die Berechtigungsüberprüfung durchgeführt, wenn der Abfragecache die Ergebnisse zurückgibt. Die Abfrage ruft außerdem eine Vorprüfung auf, um die Berechtigungen vor dem Optimierer zu überprüfen.)
- Wenn Sie die Erlaubnis haben, öffnen Sie die Tabelle und fahren Sie mit der Ausführung fort. Wenn eine Tabelle geöffnet wird, verwendet der Executor die von der Engine bereitgestellte Schnittstelle basierend auf der Engine-Definition der Tabelle. Der Ausführungsablauf des Executors ist wie folgt:
- select * from test where age >
- Rufen Sie die InnoDB-Engine-Schnittstelle auf, um die erste Zeile dieser Tabelle abzurufen und festzustellen, ob der Alterswert 10 ist. Wenn nicht, überspringen Speichern Sie diese Zeile dann im Ergebnissatz.
- Rufen Sie die Engine-Schnittstelle auf, um die „nächste Zeile“ abzurufen, und wiederholen Sie die gleiche Beurteilungslogik, bis die letzte Zeile dieser Tabelle abgerufen wird.
- Der Executor gibt einen Datensatz, der aus allen Zeilen besteht, die die Bedingungen während des oben genannten Durchlaufvorgangs erfüllen, als Ergebnissatz an den Client zurück.
3. MySQL-Speicher-Engine
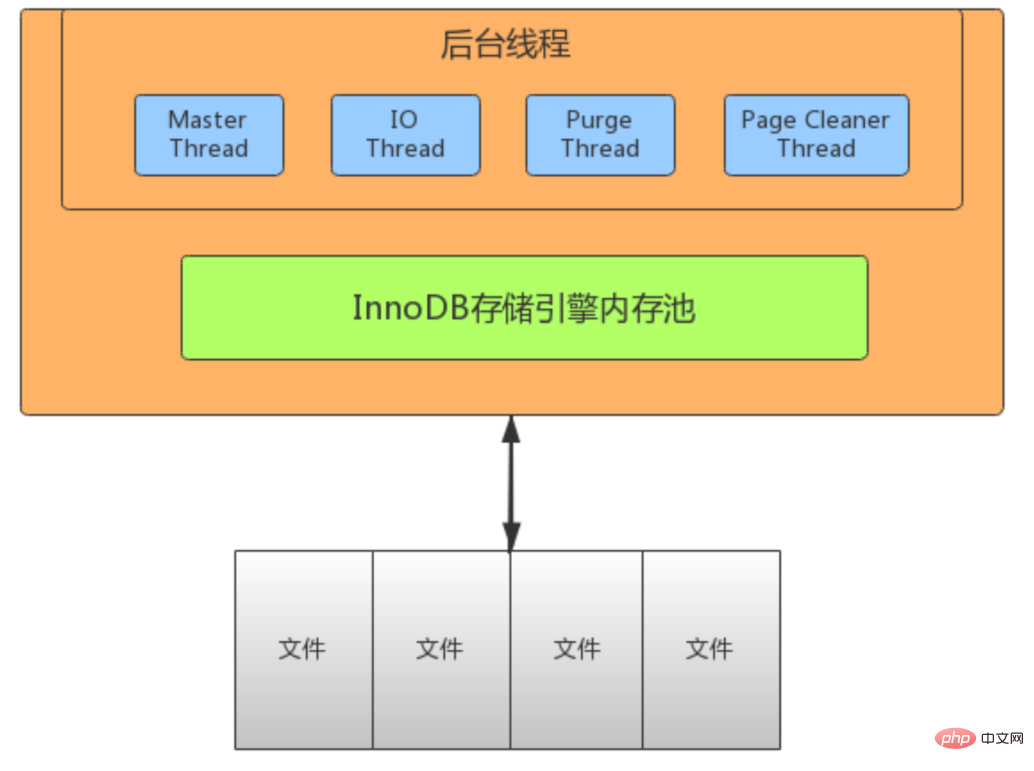
Die Speicher-Engine befindet sich auf der dritten Ebene der MySQL-Architektur. Sie ist für die Speicherung und Extraktion von Daten in MySQL verantwortlich Es basiert auf MySQL. Ein Dateizugriffsmechanismus, der durch die bereitgestellte abstrakte Schnittstelle der Dateizugriffsschicht angepasst wird. Dieser Mechanismus wird als Speicher-Engine bezeichnet.
Verwenden Sie den Befehl show engine, um die von der aktuellen Datenbank unterstützten Engine-Informationen anzuzeigen.
Die MyISAM-Speicher-Engine wurde standardmäßig vor Version 5.5 verwendet, und die InnoDB-Speicher-Engine wurde ab 5.5 verwendet.
- InnoDB: unterstützt Transaktionen, verfügt über Commit-, Rollback- und Crash-Recovery-Funktionen, Transaktionssicherheit;
- MyISAM: unterstützt keine Transaktionen und Fremdschlüssel, die Zugriffsgeschwindigkeit ist hoch;
- Speicher: nutzt Speicher zum Erstellen von Tabellen, die Zugriffsgeschwindigkeit ist sehr schnell, weil Die Daten befinden sich im Speicher und der Hash-Index wird standardmäßig verwendet.
- Archive: Archivtyp-Engine, unterstützt nur Insert- und Select-Anweisungen.
- Csv: Datenspeicherung In CSV-Dateien müssen aufgrund von Dateibeschränkungen alle Spalten angegeben werden, nicht null. Darüber hinaus unterstützt die CSV-Engine keine Indizes und Partitionen und ist daher für Zwischentabellen für den Datenaustausch geeignet. nur eingeben, aber nicht beenden, beim Betreten verschwinden und alle eingefügten Daten werden nicht gespeichert
- Föderiert: Kann auf Tabellen in entfernten MySQL-Datenbanken zugreifen. Eine lokale Tabelle speichert keine Daten und greift auf den Inhalt einer Remote-Tabelle zu.
- MRG_MyISAM: Eine Kombination aus einer Gruppe von MyISAM-Tabellen. Die Merge-Tabelle selbst kann auf einer Gruppe von MyISAM-Tabellen ausgeführt werden
- Transaktionen und Fremdschlüssel
InnoDB unterstützt Transaktionen und Fremdschlüssel mit Sicherheit und Integrität und ist für eine große Anzahl von Einfüge- oder Aktualisierungsvorgängen geeignet.
MyISAM unterstützt keine Transaktionen und Fremdschlüssel, sondern bietet Hochgeschwindigkeitsspeicherung und -abruf , geeignet für eine große Anzahl ausgewählter Abfragevorgänge
- Sperrmechanismus
- InnoDB unterstützt das Sperren auf Zeilenebene und das Sperren bestimmter Datensätze. Die Sperrung erfolgt indexbasiert.
- Indexstruktur
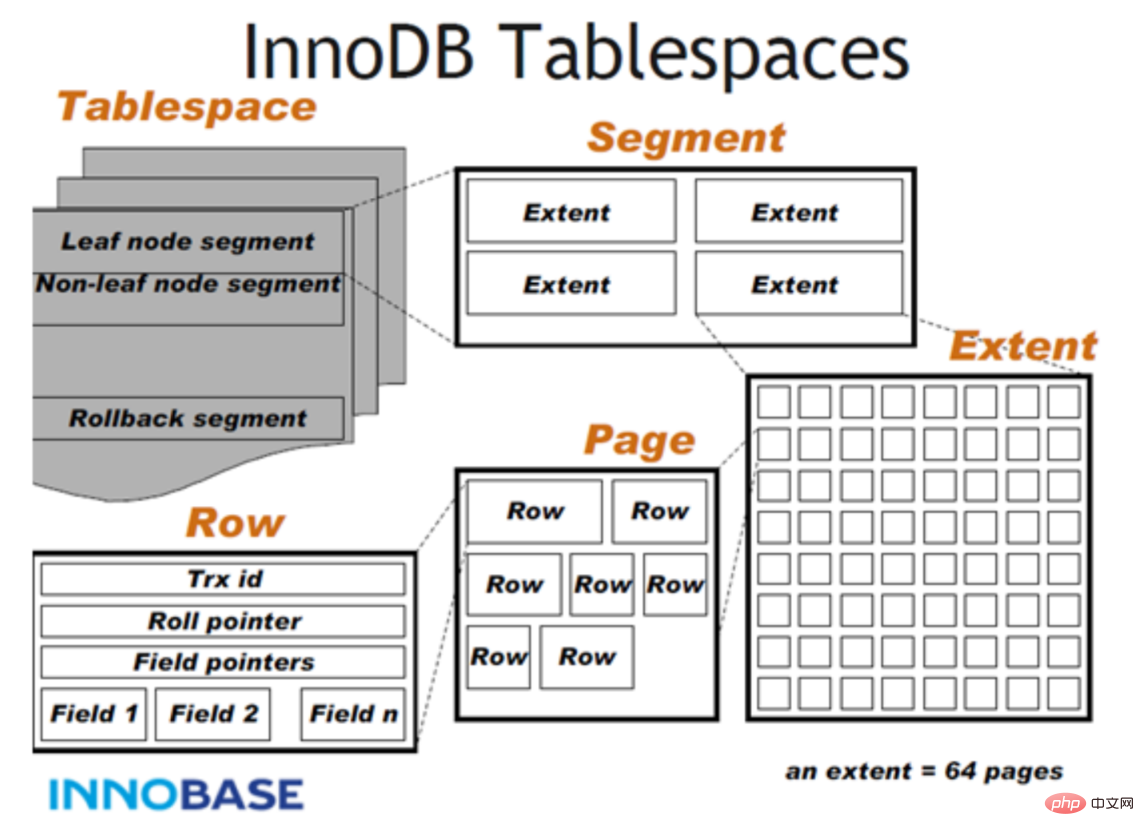
- InnoDB verwendet einen Clustered-Index (Clustered-Index). Der Index und die Datensätze werden zusammen gespeichert, wobei sowohl der Index als auch die Datensätze zwischengespeichert werden.
- Funktion zur Parallelitätsverarbeitung
- MyISAM verwendet Tabellensperren, was zu einer geringen Parallelitätsrate von Schreibvorgängen, keiner Blockierung zwischen Lesevorgängen und einer Blockierung von Lese- und Schreibvorgängen führt.
- Speicherdateien
- Die InnoDB-Tabelle entspricht zwei Dateien, einer .frm Tabellenstrukturdatei und eine .ibd-Datendatei. Die InnoDB-Tabelle unterstützt bis zu 64 TB;
- MySQL5.0 beträgt das Standardlimit 256 TB.
-
- Anwendbare Szenarien
MyISAM
Benötigt keine Transaktionsunterstützung (nicht unterstützt)Die Parallelität ist relativ gering (Problem mit dem Sperrmechanismus)Die Datenänderung ist relativ gering, hauptsächlich beim Lesen- Die Anforderungen an die Datenkonsistenz sind nicht hoch
-
- InnoDB
- Erfordert Transaktionsunterstützung (hat bessere Transaktionseigenschaften)
Szenarien mit häufigeren Datenaktualisierungen Speicher können Sie die besseren Caching-Funktionen von InnoDB nutzen, um die Speichernutzung zu verbessern und Festplatten-IO zu reduzieren-
-
- Zusammenfassung
- Wie wähle ich zwischen den beiden Engines?
- Benötigen Sie eine Transaktion? Ja, gibt es in InnoDB
Das obige ist der detaillierte Inhalt vonDetaillierte grafische Erläuterung der MySQL-Architekturprinzipien. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!





 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen







![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



