

Dieser Artikel vermittelt Ihnen relevantes Wissen über Python, das hauptsächlich Probleme im Zusammenhang mit dem Zeichnen dynamischer Visualisierungssymbole behandelt. Mit der Plotly-Grafikbibliothek können Sie mühelos einen Blick auf das Diagramm unten werfen es wird für alle hilfreich sein.

Empfohlenes Lernen: Python-Video-Tutorial
Geschichtenerzählen ist eine entscheidende Fähigkeit für Datenwissenschaftler. Um unsere Ideen auszudrücken und andere zu überzeugen, müssen wir effektiv kommunizieren. Und schöne Visualisierungen sind ein großartiges Werkzeug für diese Aufgabe.
In diesem Artikel werden 5 nicht-traditionelle Visualisierungstechniken vorgestellt, die Ihre Datengeschichten schöner und effektiver machen können. Hier wird die Plotly-Grafikbibliothek von Python verwendet, mit der Sie mühelos animierte Diagramme und interaktive Diagramme erstellen können.
Wenn Sie Plotly noch nicht installiert haben, führen Sie einfach den folgenden Befehl in Ihrem Terminal aus, um die Installation abzuschließen:
pip install plotly
Während Sie die Entwicklung dieses oder jenes studieren Indikator, wir Zeitdaten sind oft beteiligt. Mit dem Plotly-Animationstool können Benutzer mit nur einer Codezeile beobachten, wie sich Daten im Laufe der Zeit ändern, wie unten gezeigt:
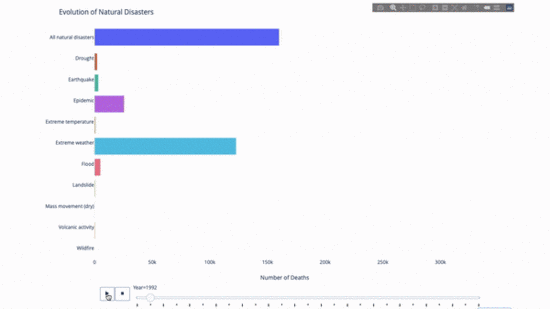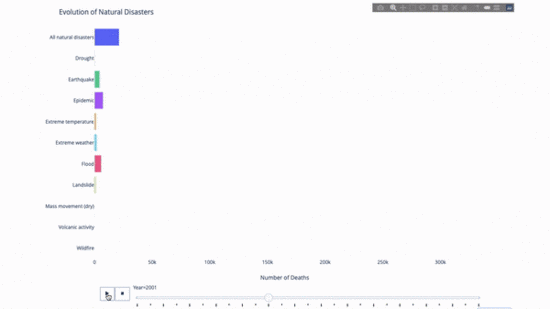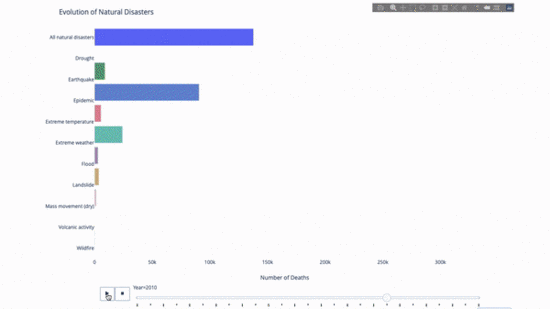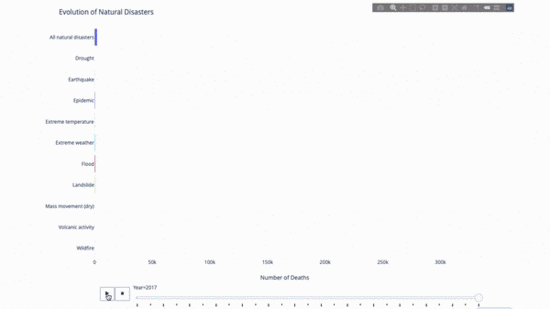
Der Code lautet wie folgt:
import plotly.express as px from vega_datasets import data df = data.disasters() df = df[df.Year > 1990] fig = px.bar(df, y="Entity", x="Deaths", animation_frame="Year", orientation='h', range_x=[0, df.Deaths.max()], color="Entity") # improve aesthetics (size, grids etc.) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)', title_text='Evolution of Natural Disasters', showlegend=False) fig.update_xaxes(title_text='Number of Deaths') fig.update_yaxes(title_text='') fig.show()
Solange Sie also eine Zeitvariable zum Filtern haben Fast jedes Diagramm ist für die Animation geeignet. Hier ist ein Beispiel für die Animation eines Streudiagramms:
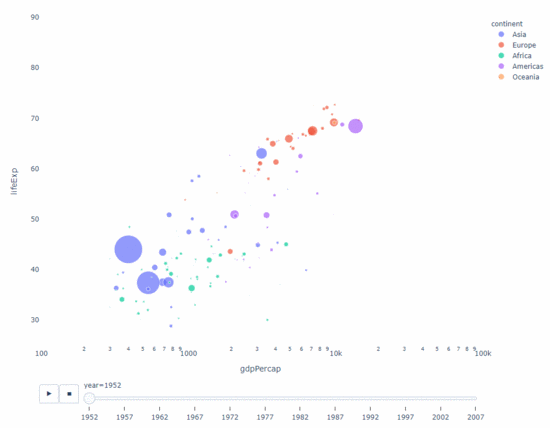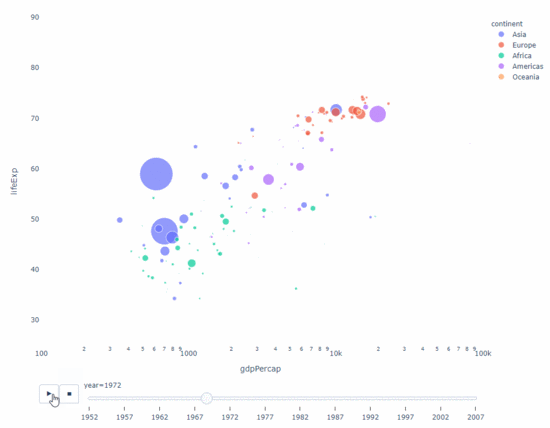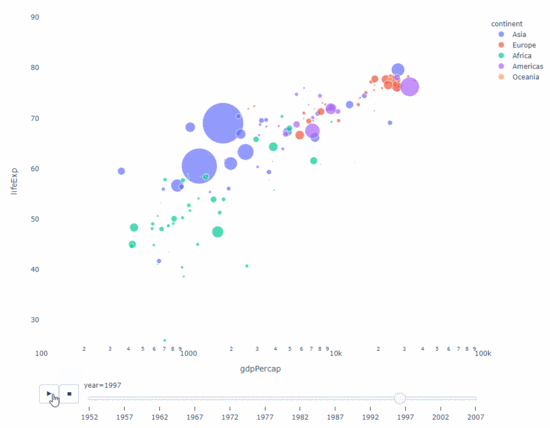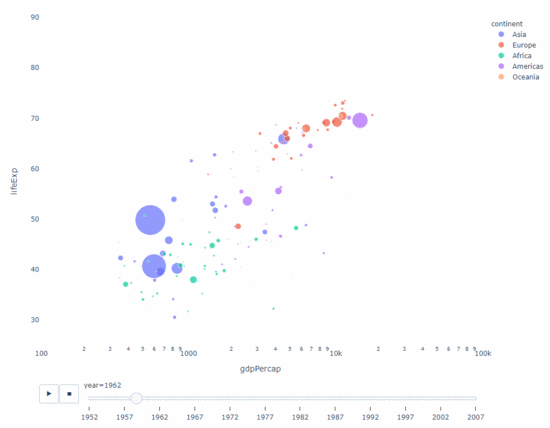
import plotly.express as px df = px.data.gapminder() fig = px.scatter( df, x="gdpPercap", y="lifeExp", animation_frame="year", size="pop", color="continent", hover_name="country", log_x=True, size_max=55, range_x=[100, 100000], range_y=[25, 90], # color_continuous_scale=px.colors.sequential.Emrld ) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)')
Ein Sunburst-Diagramm ist eine großartige Möglichkeit, Gruppierungsaussagen zu visualisieren. Wenn Sie eine bestimmte Größe nach einer oder mehreren kategorialen Variablen aufschlüsseln möchten, verwenden Sie ein Sonnendiagramm.
Angenommen, wir möchten die durchschnittlichen Trinkgelddaten nach Geschlecht und Tageszeit aufschlüsseln, dann kann diese doppelte Gruppierung nach Aussage durch Visualisierung im Vergleich zu einer Tabelle effektiver dargestellt werden.
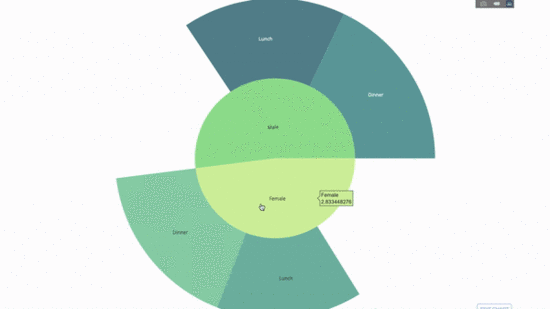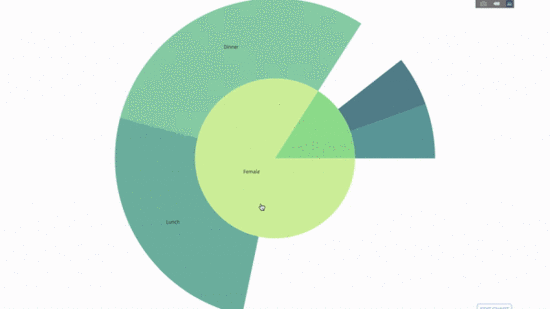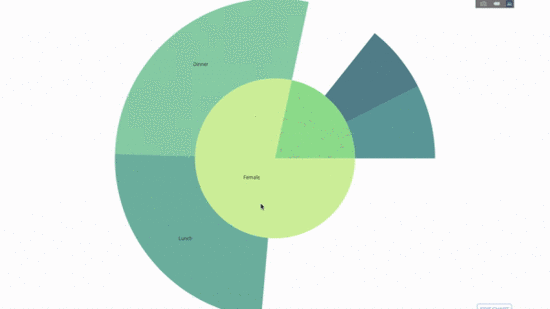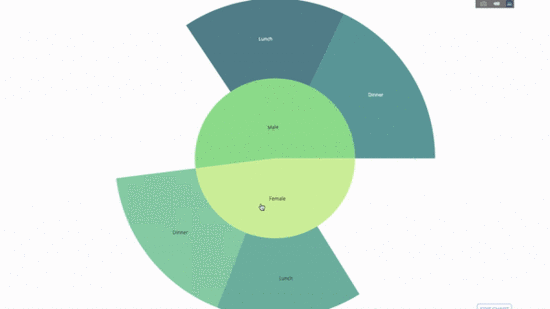
Dieses Diagramm ist interaktiv, sodass Sie die Kategorien selbst anklicken und erkunden können. Sie müssen lediglich alle Ihre Kategorien definieren, die Hierarchie zwischen ihnen deklarieren (siehe den Parent-Parameter im Code unten) und die entsprechenden Werte zuweisen, was in unserem Fall die Ausgabe der Group by-Anweisung ist.
import plotly.graph_objects as go
import plotly.express as px
import numpy as np
import pandas as pd
df = px.data.tips()
fig = go.Figure(go.Sunburst(
labels=["Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch '],
parents=["", "", "Female", "Female", 'Male', 'Male'],
values=np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex', 'time']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()Jetzt fügen wir dieser Hierarchie eine weitere Ebene hinzu:
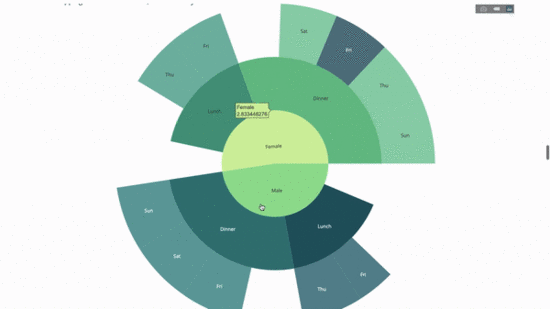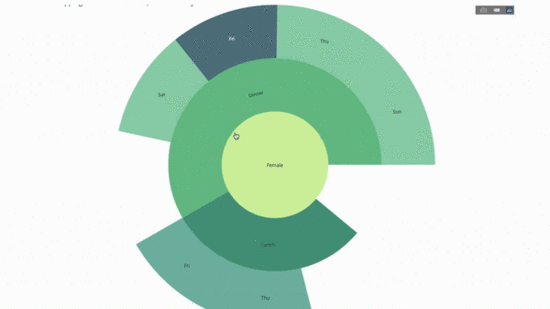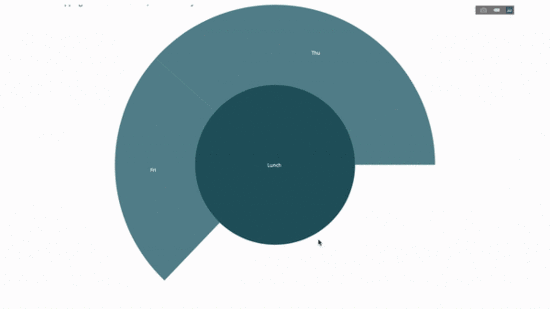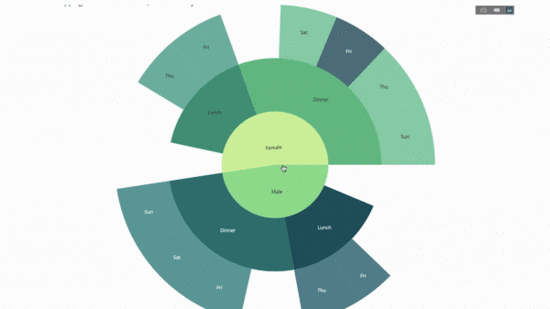
Dazu fügen wir die Werte einer weiteren Gruppe per Anweisung mit drei kategorialen Variablen hinzu.
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
import numpy as np
df = px.data.tips()
fig = go.Figure(go.Sunburst(labels=[
"Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch ', 'Fri', 'Sat',
'Sun', 'Thu', 'Fri ', 'Thu ', 'Fri ', 'Sat ', 'Sun ', 'Fri ', 'Thu '
],
parents=[
"", "", "Female", "Female", 'Male', 'Male',
'Dinner', 'Dinner', 'Dinner', 'Dinner',
'Lunch', 'Lunch', 'Dinner ', 'Dinner ',
'Dinner ', 'Lunch ', 'Lunch '
],
values=np.append(
np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex',
'time']).tip.mean().values,
),
df.groupby(['sex', 'time',
'day']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()Zeigerdiagramme dienen nur der Optik. Verwenden Sie diese Art von Diagramm, wenn Sie über Erfolgskennzahlen wie KPIs berichten und zeigen, wie nah diese an Ihren Zielen liegen.
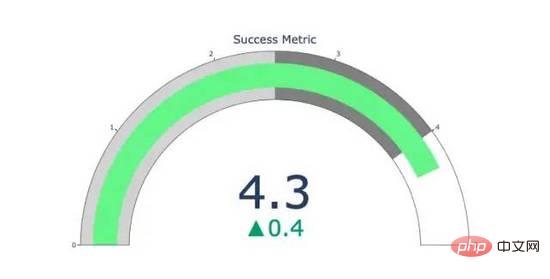
import plotly.graph_objects as go
fig = go.Figure(go.Indicator(
domain = {'x': [0, 1], 'y': [0, 1]},
value = 4.3,
mode = "gauge+number+delta",
title = {'text': "Success Metric"},
delta = {'reference': 3.9},
gauge = {'bar': {'color': "lightgreen"},
'axis': {'range': [None, 5]},
'steps' : [
{'range': [0, 2.5], 'color': "lightgray"},
{'range': [2.5, 4], 'color': "gray"}],
}))
fig.show()Eine weitere Möglichkeit, die Beziehung zwischen kategorialen Variablen zu untersuchen, ist ein Parallelkoordinatendiagramm wie das folgende. Sie können Werte jederzeit per Drag & Drop markieren, markieren und durchsuchen, ideal für Präsentationen.
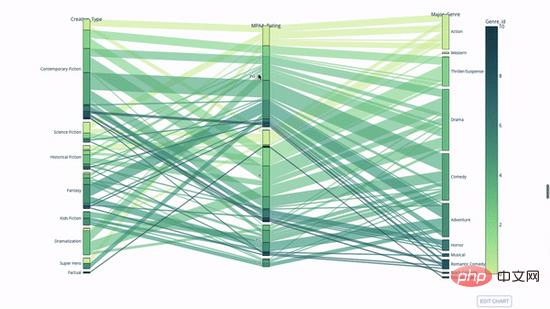
Der Code lautet wie folgt:
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_categories( df, dimensions=['MPAA_Rating', 'Creative_Type', 'Major_Genre'], color="Genre_id", color_continuous_scale=px.colors.sequential.Emrld, ) fig.show()
Parallelkoordinatendiagramm ist eine Ableitung des obigen Diagramms. Hier stellt jede Zeichenfolge eine einzelne Beobachtung dar. Dies ist eine Methode, mit der Ausreißer (einzelne Linien, die weit vom Rest der Daten entfernt sind), Cluster, Trends und redundante Variablen (z. B. wenn zwei Variablen bei jeder Beobachtung ähnliche Werte haben) identifiziert werden können wird auf derselben horizontalen Linie liegen, ein nützliches Hilfsmittel, um das Vorhandensein von Redundanz anzuzeigen.
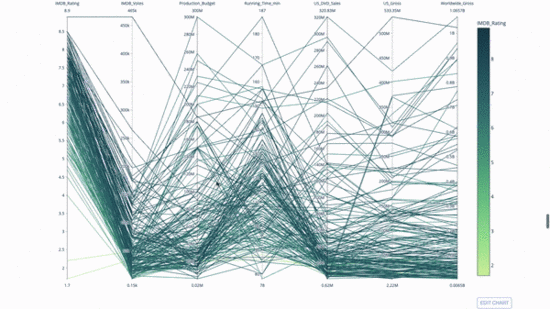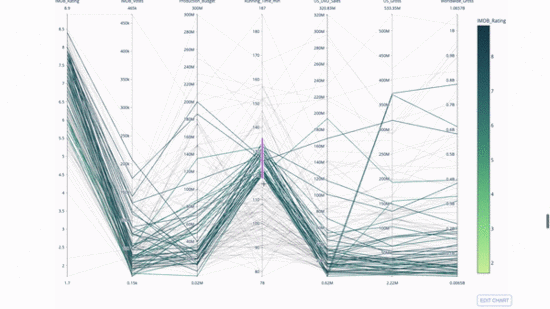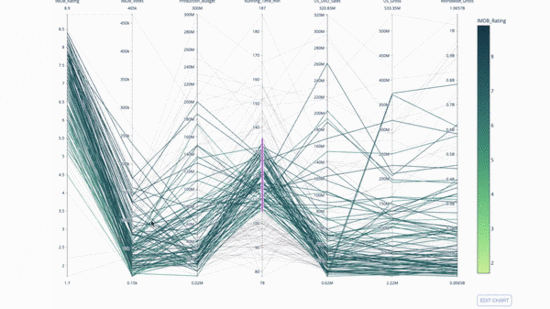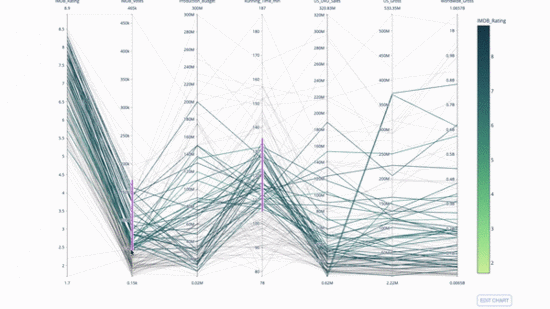
Der Code lautet wie folgt:
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_coordinates( df, dimensions=[ 'IMDB_Rating', 'IMDB_Votes', 'Production_Budget', 'Running_Time_min', 'US_Gross', 'Worldwide_Gross', 'US_DVD_Sales' ], color='IMDB_Rating', color_continuous_scale=px.colors.sequential.Emrld) fig.show()
Empfohlenes Lernen: Python-Video-Tutorial
Das obige ist der detaillierte Inhalt vonDetaillierte grafische Erklärung, wie man Python zum Zeichnen dynamischer Visualisierungsdiagramme verwendet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



