
 Datenbank
MySQL-Tutorial
Zusammenfassung der Lösungen für MySQL-Master-Slave-Verzögerung und Lese-/Schreibtrennung
Datenbank
MySQL-Tutorial
Zusammenfassung der Lösungen für MySQL-Master-Slave-Verzögerung und Lese-/Schreibtrennung
Zusammenfassung der Lösungen für MySQL-Master-Slave-Verzögerung und Lese-/Schreibtrennung

Dieser Artikel bringt Ihnen relevantes Wissen über MySQL, das hauptsächlich die Lösungen für die Master-Slave-Verzögerung und die Lese-/Schreib-Trennung vorstellt. Ich hoffe, dass es für alle hilfreich ist.

Empfohlenes Lernen: MySQL-Video-Tutorial
Wir alle wissen, dass Internetdaten eine Eigenschaft haben, die meisten Szenarien sind mehr lesen und weniger schreiben, wie zum Beispiel: Weibo, WeChat, Taobao Business Gemäß dem Twenty-eight-Prinzip kann die Leseverkehrsquote sogar 90 % erreichen读多写少,比如:微博、微信、淘宝电商,按照 二八原则,读流量占比甚至能达到 90%
结合这个特性,我们对底层的数据库架构也会做相应调整。采用 读写分离
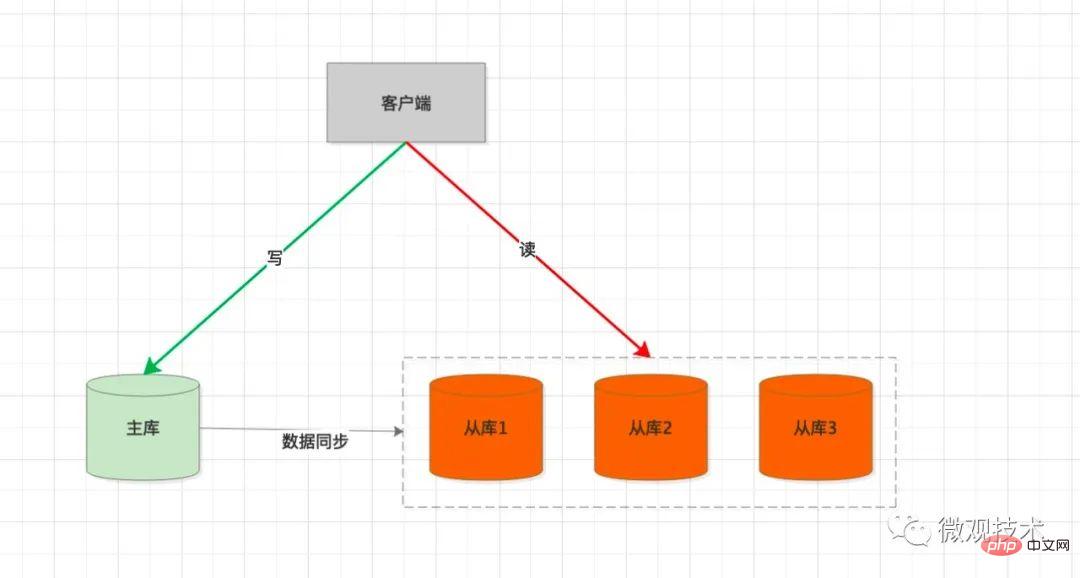
处理过程:
客户端会集成 SDK,每次执行 SQL 时,会判断是
写或读操作如果是
写SQL,请求会发到主库主数据库执行SQL,事务提交后,会生成
binlog,并同步给从库从库通过 SQL 线程回放binlog,并在从库表中生成相应数据如果是
读SQL,请求会通过负载均衡策略,挑选一个从库处理用户请求
看似非常合理,细想却不是那么回事
主库 与 从库 是采用异步复制数据,如果这两者之间数据还没有同步怎么办?
主库刚写完数据,从库还没来得及拉取最新数据,读 请求就来了,给用户的感觉,数据丢了???
针对这个问题,今天,我们就来探讨下有什么解决方案?
一、强制走主库
针对不用的业务诉求,区别性对待
场景一:
如果是对数据的 实时性 要求不是很高,比如:大V有千万粉丝,发布一条微博,粉丝晚几秒钟收到这条信息,并不会有特别大的影响。这时,可以走 从库。
场景二:
如果对数据的 实时性 要求非常高,比如金融类业务。我们可以在客户端代码标记下,让查询强制走主库。
二、从库延迟查询
由于主从库之间数据同步需要一定的时间间隔,那么有一种策略是延迟从从库查询数据。
比如:
select sleep(1) select * from order where order_id=11111;
在正式的业务查询时,先执行一个sleep 语句,给从库预留一定的数据同步缓冲期。
因为是采用一刀切,当面对高并发业务场景时,性能会下降的非常厉害,一般不推荐这个方案。
三、判断主从是否延迟?决定选主库还是从库
方案一:
在从库 执行 命令 show slave status
查看 seconds_behind_master 的值,单位为秒,如果为 0,表示主备库之间无延迟
方案二:
比较主从库的文件点位
还是执行 show slave status,响应结果里有截个关键参数
Master_Log_File 读到的主库最新文件
Read_Master_Log_Pos 读到的主库最新文件的坐标位置
Relay_Master_Log_File 从库执行到的最新文件
Exec_Master_Log_Pos 从库执行到的最新文件的坐标位置
两两比较,上面的参数是否相等
方案三:
比较 GTID 集合
Auto_Position=1 主从之间使用 GTID 协议
Retrieved_Gtid_Set 从库收到的所有binlog日志的 GTID 集合
Executed_Gtid_Set 从库已经执行完成的 GTID 集合
比较 Retrieved_Gtid_Set 和 Executed_Gtid_Set
Lese-Schreib-Trennung
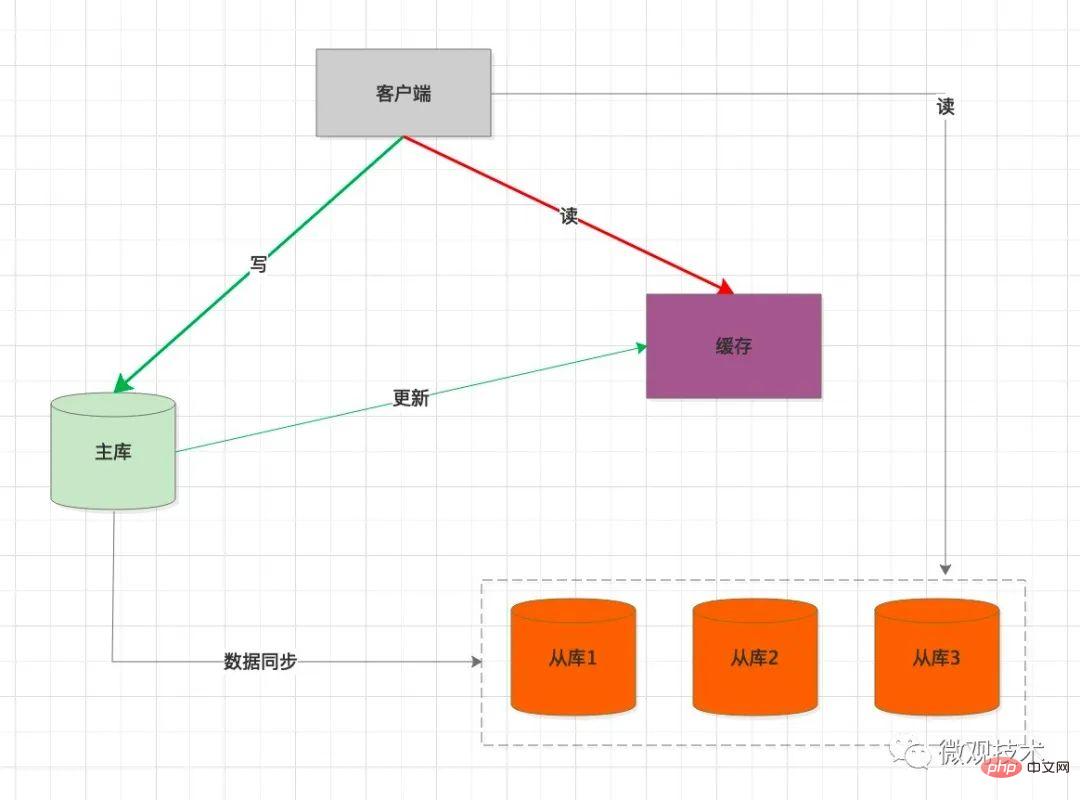
Verarbeitungsprozess:
Der Client integriert das SDK und jedes Mal, wenn SQL ausgeführt wird, wird es wird als
write- oderread-Vorgang beurteilt- 🎜Wenn es sich um
writeSQL handelt, wird die Anfrage an gesendet dieHauptbibliothek🎜 - 🎜Die Master-Datenbank führt SQL aus. Nachdem die Transaktion übermittelt wurde, wird
binloggeneriert und mit demSlave synchronisiert Bibliothek🎜 - 🎜
Slave-Bibliothekspieltbinlogüber den SQL-Thread ab und generiert entsprechende Daten in der Slave-Bibliothekstabelle🎜 - 🎜Wenn es sich um
readSQL handelt, durchläuft die Anfrage dieLoad Balancing-Strategie und es wird eineSlave-Bibliothekausgewählt Behandeln Sie die Benutzeranfrage🎜
Hauptbibliothek und Slave-Bibliothek verwendet die asynchrone Replikation von Daten. Was ist, wenn die Daten zwischen den beiden noch nicht synchronisiert sind? 🎜🎜Die Hauptbibliothek hat gerade das Schreiben der Daten abgeschlossen, und bevor die Slave-Bibliothek Zeit hat, die neuesten Daten abzurufen, kommt die read-Anfrage, die dem Benutzer das Gefühl gibt, dass die Daten verloren gegangen sind ? ? ? 🎜🎜Als Antwort auf dieses Problem wollen wir heute besprechen, welche Lösungen es gibt? 🎜🎜1. Erzwungene Nutzung der Hauptdatenbank 🎜🎜Behandeln Sie unterschiedliche Geschäftsanforderungen für unterschiedliche Anforderungen. 🎜🎜🎜Szenario 1: 🎜🎜🎜Wenn die Echtzeit-Anforderungen für Daten nicht sehr hoch sind, z : Großes V hat zig Millionen Fans, wenn er eine Weibo-Nachricht postet und seine Fans die Nachricht ein paar Sekunden später erhalten, wird das keine besonders große Wirkung haben. Zu diesem Zeitpunkt können Sie zu aus der Bibliothek wechseln. 🎜🎜🎜Szenario 2: 🎜🎜🎜Wenn die Echtzeit-Anforderungen an Daten sehr hoch sind, beispielsweise bei Finanzdienstleistungen. Wir können erzwingen, dass die Abfrage unter dem Client-Code-Tag an die Hauptdatenbank weitergeleitet wird. 🎜🎜2. Verzögerte Abfrage aus der Slave-Datenbank🎜🎜Da die Datensynchronisierung zwischen Master- und Slave-Datenbanken ein bestimmtes Zeitintervall erfordert, gibt es eine Strategie, um die Abfrage von Daten aus Slave-Datenbanken zu verzögern. 🎜🎜Zum Beispiel: 🎜select master_pos_wait(file, pos[, timeout]);
show Slave Status🎜🎜aus der Slave-Bibliothek aus, um den Wert von seconds_behind_master anzuzeigen. Code>, die Einheit ist Sekunden, wenn es 0 ist, was bedeutet, dass es keine Verzögerung zwischen der Master- und der Slave-Datenbank gibt🎜🎜🎜Option 2: 🎜🎜🎜Vergleichen Sie die Dateipunkte der Master- und Slave-Datenbank🎜🎜Oder führen Sie <code aus>Slave-Status anzeigen, es gibt einen Schlüssel im Antwortergebnis Parameter🎜- 🎜Master_Log_File Die zuletzt aus der Hauptbibliothek gelesene Datei🎜
- 🎜Read_Master_Log_Pos Die Koordinatenposition der Zuletzt aus der Hauptbibliothek gelesene Datei🎜
- 🎜Relay_Master_Log_File Ausgeführt aus der Bibliothek Die Koordinatenposition der zuletzt abgerufenen Datei🎜
- 🎜Exec_Master_Log_Pos ausgeführt aus der Bibliothek🎜 ul>🎜Vergleichen Sie die beiden Parameter, um zu sehen, ob die oben genannten Parameter gleich sind🎜🎜🎜Option 3:🎜 🎜🎜GTID-Sätze vergleichen🎜
- 🎜Auto_Position=1 GTID-Protokoll zwischen Master und Slave verwenden🎜
- 🎜Retrieved_Gtid_Set GTID-Satz aller von der Bibliothek empfangenen Binlog-Protokolle🎜 🎜Executed_Gtid_Set Der GTID-Satz, der von der Bibliothek ausgeführt wurde🎜
Retrieved_Gtid_Set und Executed_Gtid_Set sind gleich🎜🎜Beim Ausführen von Business SQL Stellen Sie während des Betriebs zunächst fest, ob die Slave-Datenbank die neuesten Daten synchronisiert hat. Dies bestimmt, ob die Master-Bibliothek oder die Slave-Bibliothek betrieben werden soll. 🎜🎜🎜Nachteile: 🎜🎜🎜Unabhängig davon, welche der oben genannten Lösungen angewendet wird, kann der Wert der Slave-Bibliothek niemals mit dem Wert der Hauptbibliothek mithalten, wenn in der Hauptbibliothek häufig Schreibvorgänge ausgeführt werden, und der Leseverkehr wird dies tun Rufen Sie immer die Hauptbibliothek auf. 🎜针对这个问题,有什么解决方案?
这个问题跟 MQ消息队列 既要求高吞吐量又要保证顺序是一样的,从全局来看确实无解,但是缩小范围就容易多了,我们可以保证一个分区内的消息有序。
回到 主从库 之间的数据同步问题,从库查询哪条记录,我们只要保证之前对应的写binglog已经同步完数据即可,可以不用管主从库的所有的事务binlog 是否同步。
问题是不是一下简单多了
四、从库节点判断主库位点
在从库执行下面命令,返回是一个正整数 M,表示从库从参数节点开始执行了多少个事务
select master_pos_wait(file, pos[, timeout]);
file 和 pos 表示主库上的文件名和位置
timeout 可选, 表示这个函数最多等待 N 秒
缺点:
master_pos_wait 返回结果无法与具体操作的数据行做关联,所以每次接收读请求时,从库还是无法确认是否已经同步数据,方案实用性不高。
五、比较 GTID
执行下面查询命令
阻塞等待,直到从库执行的事务中包含 gtid_set,返回 0
超时,返回 1
select wait_for_executed_gtid_set(gtid_set, 1);
MySQL 5.7.6 版本开始,允许在执行完更新类事务后,把这个事务的 GTID 返回给客户端。具体操作,将参数
session_track_gtids设置为OWN_GTID,调用 API 接口mysql_session_track_get_first返回结果解析出 GTID
处理流程:
发起
写SQL 操作,在主库成功执行后,返回这个事务的 GTID发起
读SQL 操作时,先在从库执行select wait_for_executed_gtid_set (gtid_set, 1)如果返回 0,表示已经从库已经同步了数据,可以在从库执行
查询操作否则,在主库执行
查询操作
缺点:
跟上面的 master_pos_wait 类似,如果 写操作 与 读操作 没有上下文关联,那么 GTID 无法传递 。方案实用性不高。
六、引入缓存中间件
高并发系统,缓存作为性能优化利器,应用广泛。我们可以考虑引入缓存作为缓冲介质
处理过程:
客户端
写SQL ,操作主库同步将缓存中的数据删除
当客户端读数据时,优先从缓存加载
如果 缓存中没有,会强制查询主库预热数据
缺点:
K-V 存储,适用一些简单的查询条件场景。如果复杂的查询,还是要查询从库。
七、数据分片
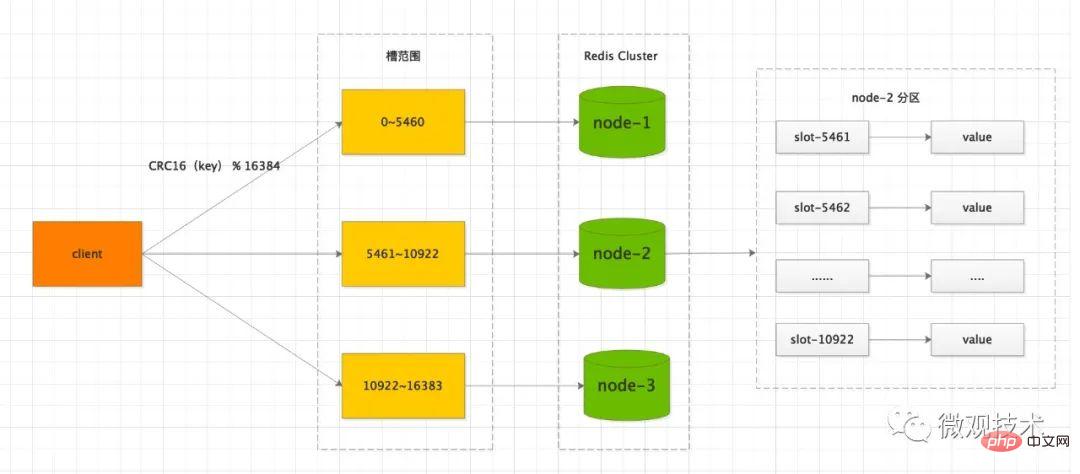
参考 Redis Cluster 模式, 集群网络拓扑通常是 3主 3从,主节点既负责写,也负责读。
通过水平分片,支持数据的横向扩展。由于每个节点都是独立的服务器,可以提高整体集群的吞吐量。
转换到数据库方面
常见的解决方式,是分库分表,每次读写都是操作主库的一个分表,从库只用来做数据备份。当主库发生故障时,主从切换,保证集群的高可用性。
推荐学习:mysql视频教程
Das obige ist der detaillierte Inhalt vonZusammenfassung der Lösungen für MySQL-Master-Slave-Verzögerung und Lese-/Schreibtrennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Navicat selbst speichert das Datenbankkennwort nicht und kann das verschlüsselte Passwort nur abrufen. Lösung: 1. Überprüfen Sie den Passwort -Manager. 2. Überprüfen Sie Navicats "Messnot Password" -Funktion; 3.. Setzen Sie das Datenbankkennwort zurück; 4. Kontaktieren Sie den Datenbankadministrator.
 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie kann ich das Datenbankkennwort in Navicat für Mariadb anzeigen?
Apr 08, 2025 pm 09:18 PM
Wie kann ich das Datenbankkennwort in Navicat für Mariadb anzeigen?
Apr 08, 2025 pm 09:18 PM
Navicat für MariADB kann das Datenbankkennwort nicht direkt anzeigen, da das Passwort in verschlüsselter Form gespeichert ist. Um die Datenbanksicherheit zu gewährleisten, gibt es drei Möglichkeiten, Ihr Passwort zurückzusetzen: Setzen Sie Ihr Passwort über Navicat zurück und legen Sie ein komplexes Kennwort fest. Zeigen Sie die Konfigurationsdatei an (nicht empfohlen, ein hohes Risiko). Verwenden Sie Systembefehlsleitungs -Tools (nicht empfohlen, Sie müssen die Befehlszeilen -Tools beherrschen).
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
Schritte zur Durchführung von SQL in Navicat: Verbindung zur Datenbank herstellen. Erstellen Sie ein SQL -Editorfenster. Schreiben Sie SQL -Abfragen oder Skripte. Klicken Sie auf die Schaltfläche Ausführen, um eine Abfrage oder ein Skript auszuführen. Zeigen Sie die Ergebnisse an (wenn die Abfrage ausgeführt wird).
