
 Datenbank
MySQL-Tutorial
Organisieren und fassen Sie fünf gängige MySQL-Hochverfügbarkeitslösungen zusammen
Datenbank
MySQL-Tutorial
Organisieren und fassen Sie fünf gängige MySQL-Hochverfügbarkeitslösungen zusammen
Organisieren und fassen Sie fünf gängige MySQL-Hochverfügbarkeitslösungen zusammen

Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL, in dem hauptsächlich Probleme im Zusammenhang mit gängigen Hochverfügbarkeitslösungen vorgestellt werden. Hier werden nur die Vor- und Nachteile häufig verwendeter Hochverfügbarkeitslösungen und die Auswahl von Hochverfügbarkeitslösungen erläutert Werfen Sie einen Blick darauf, ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: MySQL-Video-Tutorial
1. Übersicht
Wenn wir die Hochverfügbarkeitsarchitektur der MySQL-Datenbank betrachten, müssen wir hauptsächlich die folgenden Aspekte berücksichtigen:
- Wenn die Datenbank ausfällt oder unerwartet Im Falle von Unterbrechungen und anderen Ausfällen kann die Verfügbarkeit der Datenbank so schnell wie möglich wiederhergestellt und Ausfallzeiten so weit wie möglich reduziert werden, um sicherzustellen, dass der Betrieb nicht aufgrund von Datenbankausfällen unterbrochen wird.
- Die Daten von nicht primären Knoten, die für Funktionen wie Sicherung und schreibgeschützte Replikate verwendet werden, sollten in Echtzeit oder irgendwann mit den Daten des primären Knotens übereinstimmen.
- Wenn im Unternehmen ein Datenbankwechsel stattfindet, sollten die Datenbankinhalte vor und nach dem Wechsel konsistent sein und das Geschäft wird nicht durch fehlende oder inkonsistente Daten beeinträchtigt.
Wir werden hier nicht im Detail auf die Klassifizierung von Hochverfügbarkeit eingehen, sondern nur auf die Vor- und Nachteile häufig verwendeter Hochverfügbarkeitslösungen und die Auswahl von Hochverfügbarkeitslösungen. 2. Hochverfügbarkeitslösung In Versionen nach 5.7 wird die native halbsynchrone Replikation von MySQL durch die Einführung einer Reihe neuer Funktionen wie verlustfreier Replikation und logischer Multithread-Replikation zuverlässiger.
Die allgemeine Architektur ist wie folgt:
Sie wird normalerweise zusammen mit Software von Drittanbietern wie Proxy und Keepalived verwendet. Sie kann verwendet werden, um den Zustand der Datenbank zu überwachen und eine Reihe von Verwaltungsbefehlen auszuführen. Sollte die Primärdatenbank ausfallen, kann die Datenbank nach dem Wechsel zur Standby-Datenbank weiterhin verwendet werden. Vorteile: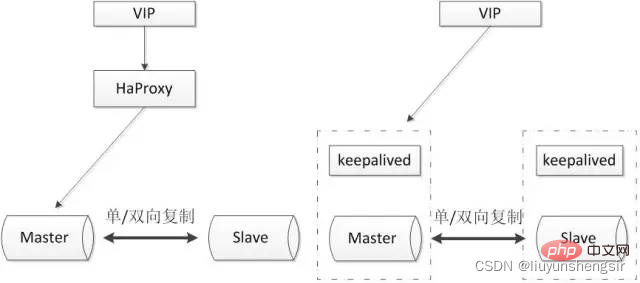 Die Architektur ist relativ einfach und verwendet die native halbsynchrone Replikation als Grundlage für die Datensynchronisierung.
Die Architektur ist relativ einfach und verwendet die native halbsynchrone Replikation als Grundlage für die Datensynchronisierung.
- Verlässt sich die halbsynchrone Replikation auf eine asynchrone Replikation, kann die Datenkonsistenz nicht garantiert werden gegeben an die Hochverfügbarkeitsmechanismen von Haproxy und Keepalived.
- 2.2. Halbsynchrone Replikationsoptimierung
- Der halbsynchrone Replikationsmechanismus ist zuverlässig. Wenn die halbsynchrone Replikation immer wirksam ist, können die Daten als konsistent betrachtet werden. Aufgrund einiger objektiver Gründe wie Netzwerkschwankungen, Zeitüberschreitungen bei der halbsynchronen Replikation und Wechsel zur asynchronen Replikation kann die Datenkonsistenz jedoch nicht garantiert werden. Daher kann die Datenkonsistenz verbessert werden, indem so weit wie möglich eine halbsynchrone Replikation sichergestellt wird.
- 2.2.1. Die halbsynchrone Replikation wird nach einer Zeitüberschreitung getrennt. Wenn die Replikation erneut hergestellt wird, werden zwei Kanäle eingerichtet Gleichzeitig beginnt ein halbsynchroner Kopierkanal mit dem Kopieren von der aktuellen Position, um sicherzustellen, dass der Slave den Fortschritt der aktuellen Host-Ausführung kennt. Ein weiterer asynchroner Replikationskanal beginnt, die nacheilenden Daten des Slaves einzuholen. Wenn der asynchrone Replikationskanal die Startposition der halbsynchronen Replikation erreicht, wird die halbsynchrone Replikation wieder aufgenommen.
Zwei Knoten, weniger Ressourcenbedarf, einfache Bereitstellung; Einfache Architektur, kein Problem bei der Auswahl des Masters, einfach direkt wechseln;
Im Vergleich zur nativen Replikation kann die optimierte halbsynchrone Replikation den Datenkonsistenz besser gewährleisten.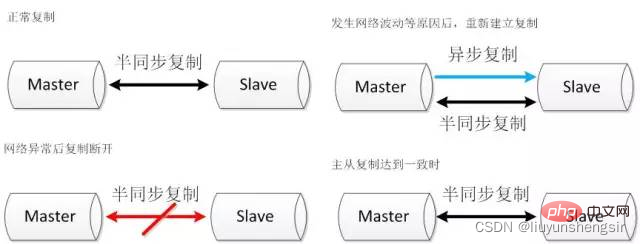 Nachteile:
Nachteile:
Verlässt sich immer noch auf die halbsynchrone Replikation, die das Problem der Datenkonsistenz nicht grundsätzlich löst. 2.3. Optimierung der Hochverfügbarkeitsarchitektur
Erweitern Sie die Dual-Node-Datenbank zu einer Multi-Node-Datenbank oder einem Multi-Node-Datenbankcluster. Sie können je nach Bedarf einen Cluster mit einem Master und zwei Slaves, einem Master und mehreren Slaves oder mehreren Mastern und mehreren Slaves wählen. 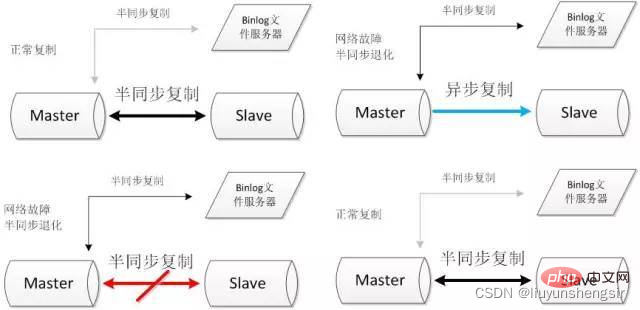
Aufgrund der semisynchronen Replikation gilt die Besonderheit, dass die semisynchrone Replikation als erfolgreich gilt, wenn eine erfolgreiche Antwort von einem Slave empfangen wird. Daher ist die Zuverlässigkeit der semisynchronen Replikation mit mehreren Slaves besser als die Zuverlässigkeit der Single-Slave-Replikation. Halbsynchrone Slave-Replikation. Und die Wahrscheinlichkeit, dass mehrere Knoten gleichzeitig ausfallen, ist geringer als die Wahrscheinlichkeit, dass ein einzelner Knoten ausfällt. Daher kann davon ausgegangen werden, dass die Architektur mit mehreren Knoten bis zu einem gewissen Grad eine höhere Verfügbarkeit aufweist als die Architektur mit zwei Knoten.
Aufgrund der großen Anzahl an Datenbanken ist jedoch eine Datenbankverwaltungssoftware erforderlich, um die Wartbarkeit der Datenbank sicherzustellen. Sie können zwischen MMM, MHA oder verschiedenen Proxy-Versionen usw. wählen. Gängige Lösungen sind wie folgt:
2.3.1. MHA + Multi-Node-Cluster
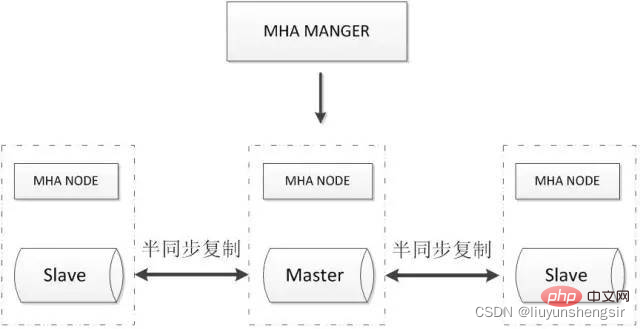
Der MHA-Manager erkennt regelmäßig den Master-Knoten im Cluster und kann den Slave automatisch mit dem neuesten Stand befördern Daten an den neuen Master weiterleiten und dann alle anderen Slaves an den neuen Master umleiten. Der gesamte Failover-Prozess ist für die Anwendung völlig transparent.
MHA-Knoten läuft auf jedem MySQL-Server. Seine Hauptfunktion besteht darin, Binärprotokolle während des Wechsels zu verarbeiten, um sicherzustellen, dass der Datenverlust minimiert wird.
MHA kann auch auf die folgenden Multi-Node-Cluster erweitert werden: 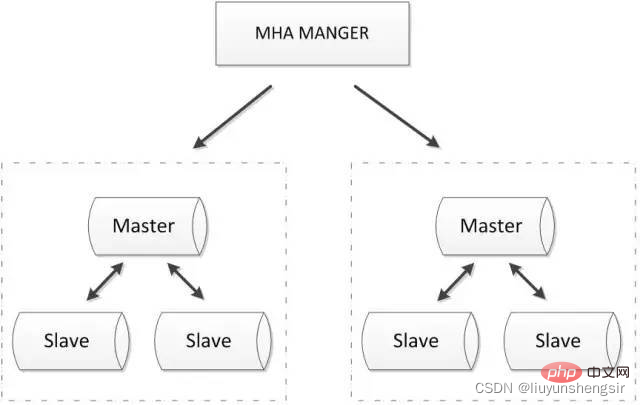
Vorteile:
kann Fehler automatisch erkennen und übertragen;
Gute Skalierbarkeit, die Anzahl und Struktur der MySQL-Knoten kann nach Bedarf erweitert werden
Im Vergleich zu MySQL-Replikation mit zwei Knoten, MySQL mit drei Knoten/mehreren Knoten hat eine geringere Wahrscheinlichkeit, nicht verfügbar zu sein
Nachteile:
Erfordert mindestens drei Knoten, was mehr Ressourcen erfordert als zwei Knoten;
Die Logik ist komplexer und danach ein Fehler Es ist schwieriger, Probleme zu beheben und zu lokalisieren.
Die Datenkonsistenz ist weiterhin durch die native semisynchrone Replikation gewährleistet, und es besteht immer noch das Risiko einer Dateninkonsistenz. Aufgrund von Netzwerkpartitionen kann es zu einem Split-Brain-Phänomen kommen
2.3.2. zookeeper+proxy
Zookeeper verwendet verteilte Algorithmen, um die Konsistenz von Clusterdaten sicherzustellen. Durch die Verwendung von zookeeper kann die hohe Verfügbarkeit von Proxys effektiv sichergestellt und Netzwerkpartitionen besser vermieden werden.
Vorteile: 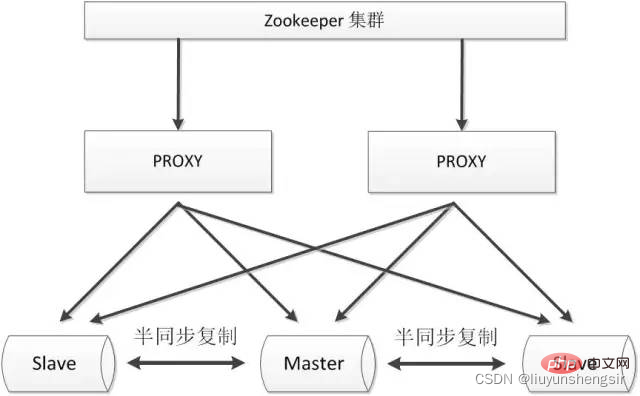
Gute Skalierbarkeit und kann auf große Cluster erweitert werden halbsynchrone Replikation;
Mit der Einführung von zk wird die Logik des gesamten Systems komplexer; länger Es basiert auf der nativen Replikationsfunktion von MySQL, verwendet jedoch die Synchronisierung von Festplattendaten, um die Datenkonsistenz sicherzustellen.Das Konzept von SAN besteht darin, eine direkte Hochgeschwindigkeitsnetzwerkverbindung (im Vergleich zu LAN) zwischen dem Speichergerät und dem Prozessor (Server) zu ermöglichen, über die die Daten zentralisiert werden können Lagerung. Häufig verwendete Architekturen sind wie folgt:
Nur zwei Knoten, einfache Bereitstellung, einfache Umschaltlogik; Es treten keine Dateninkonsistenzen aufgrund logischer Fehler in MySQL auf.
Erforderlich Verfügbarkeit von gemeinsam genutztem Speicher;
Teuer;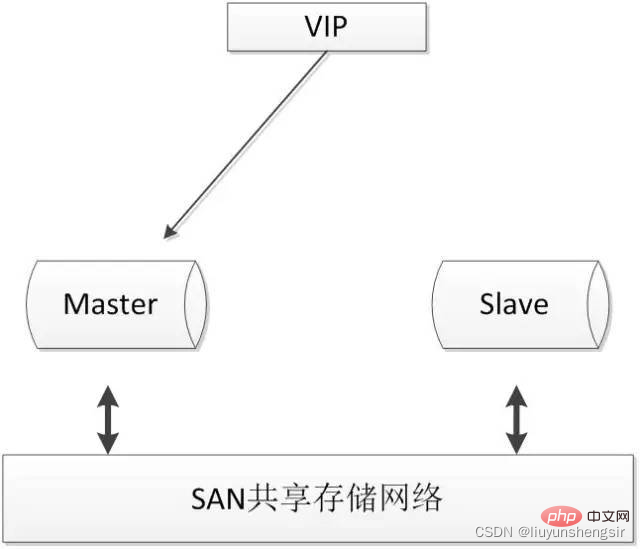
2.4.2. DRBD ist eine softwarebasierte, netzwerkbasierte Blockreplikationslösung, die hauptsächlich für Festplatten, Partitionen, logische Volumes usw. verwendet wird Wenn der Benutzer Daten auf die lokale Festplatte schreibt, werden die Daten auch auf die Festplatte eines anderen Hosts im Netzwerk gesendet. Auf diese Weise können der lokale Host (Primärknoten) und der Remote-Host (Standby-Knoten) Daten übertragen sorgen für Echtzeit-Synchronisation. Die häufig verwendete Architektur ist wie folgt:
Wenn ein Problem mit dem lokalen Host auftritt, bleiben dieselben Daten weiterhin auf dem Remote-Host erhalten und können weiterhin verwendet werden, um die Datensicherheit zu gewährleisten.
DRBD ist eine schnelle synchrone Replikationstechnologie, die vom Linux-Kernelmodul implementiert wird und den gleichen Shared-Storage-Effekt wie SAN erzielen kann.
Vorteile:
Nur zwei Knoten, einfache Bereitstellung, einfache Switching-Logik;
Garantierte starke Datenkonsistenz;
Hat einen größeren Einfluss auf die IO-Leistung; Die Slave-Bibliothek bietet keine Lesevorgänge. Verteiltes Protokoll
Das verteilte Protokoll kann das Problem der Datenkonsistenz gut lösen. Die gebräuchlicheren Lösungen sind wie folgt:
2.5.1. MySQL-Cluster
MySQL-Cluster ist die offizielle Cluster-Bereitstellungslösung. Es nutzt die NDB-Speicher-Engine, um redundante Daten in Echtzeit zu sichern, um eine hohe Verfügbarkeit und Datenkonsistenz der Datenbank zu erreichen. 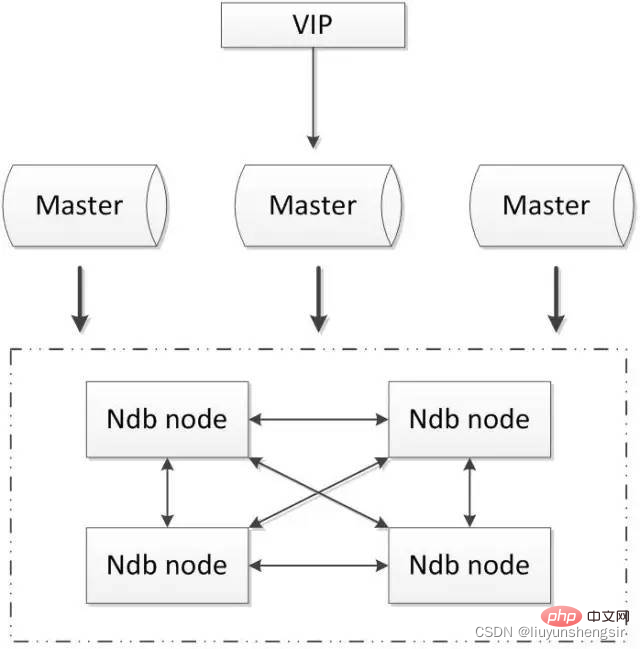
Vorteile:
Alle verwenden offizielle Komponenten und verlassen sich nicht auf Software von Drittanbietern;
Die Konfiguration ist komplex und erfordert die Verwendung des NDB-Speichers Die Engine unterscheidet sich etwas von der regulären MySQL-Engine.
Mindestens drei Knoten . Es ist einfach zu bedienen und hat keinen einzigen Fehlerpunkt, hohe Verfügbarkeit. Gängige Architekturen sind wie folgt:
Vorteile:
Multi-Master-Schreiben, verzögerungsfreie Replikation, Gewährleistung einer starken Datenkonsistenz;
Es gibt eine ausgereifte Community und Internetunternehmen nutzen es in großem Umfang; Failover, automatisches Hinzufügen und Entfernen von Knoten;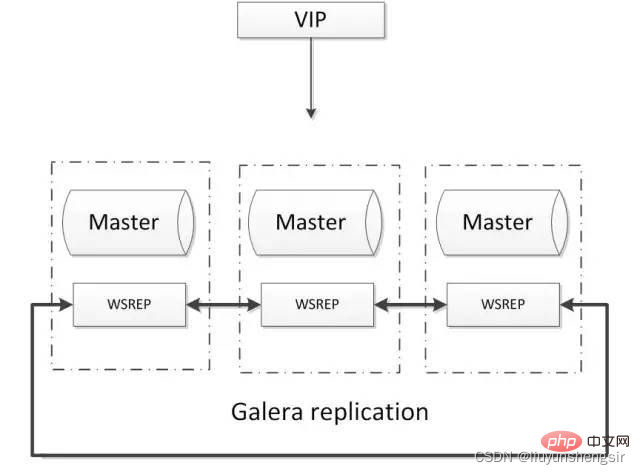 Nachteile:
Nachteile:
Erfordert wsrep-Patching für native MySQL-Knoten
Unterstützt nur die Innodb-Speicher-Engine Mindestens drei Knoten;
2.5.3. Das durch den Paxos-Algorithmus gelöste Problem ist wie ein verteiltes System funktioniert. Einigen Sie sich auf einen bestimmten Wert (Auflösung). Dieser Algorithmus gilt als der effizienteste seiner Art. Durch die Kombination von Paxos und MySQL kann eine starke Konsistenz verteilter MySQL-Daten erreicht werden. Gängige Architekturen sind wie folgt:
Vorteile:
Multi-Master-Schreiben, keine Verzögerungsreplikation, Gewährleistung einer starken Datenkonsistenz;
Unterstützt nur die Innodb-Speicher-Engine.
3. Da die Anforderungen der Menschen an die Datenkonsistenz weiter steigen, werden immer mehr Methoden ausprobiert, um das Problem der verteilten Datenkonsistenz zu lösen MySQL selbst, die Optimierung der MySQL-Cluster-Architektur, die Einführung von Paxos, Raft, 2PC-Algorithmus usw.
Die Methode zur Lösung des Problems der MySQL-Datenbankdatenkonsistenz mithilfe verteilter Algorithmen wird von den Menschen immer mehr akzeptiert. Eine Reihe ausgereifter Produkte wie PhxSQL, MariaDB Galera Cluster, Percona XtraDB Cluster usw. werden immer beliebter beliebt. In großem Umfang verwendet. 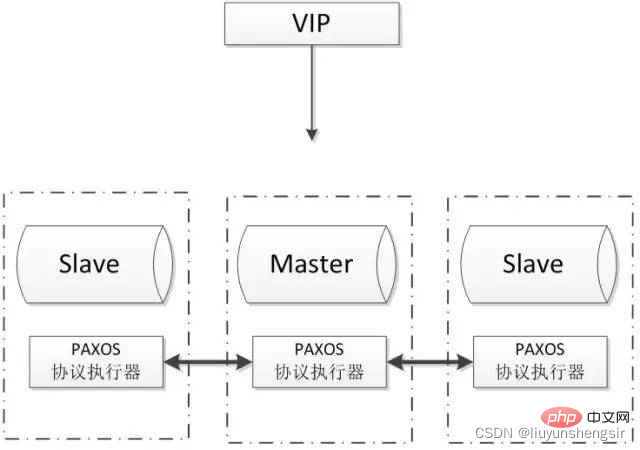
Mit der offiziellen GA der MySQL-Gruppenreplikation ist die Verwendung verteilter Protokolle zur Lösung von Datenkonsistenzproblemen zu einer Mainstream-Richtung geworden. Es wird erwartet, dass immer mehr hervorragende Lösungen vorgeschlagen werden und das MySQL-Hochverfügbarkeitsproblem besser gelöst werden kann.
Empfohlenes Lernen:
MySQL-Video-Tutorial
Das obige ist der detaillierte Inhalt vonOrganisieren und fassen Sie fünf gängige MySQL-Hochverfügbarkeitslösungen zusammen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 So erstellen Sie eine SQL -Datenbank
Apr 09, 2025 pm 04:24 PM
So erstellen Sie eine SQL -Datenbank
Apr 09, 2025 pm 04:24 PM
Das Erstellen einer SQL -Datenbank umfasst 10 Schritte: Auswählen von DBMs; Installation von DBMs; Erstellen einer Datenbank; Erstellen einer Tabelle; Daten einfügen; Daten abrufen; Daten aktualisieren; Daten löschen; Benutzer verwalten; Sichern der Datenbank.
