

Detaillierte Analyse der Atomizität von Befehlen in Redis

Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis, das hauptsächlich Probleme im Zusammenhang mit der Atomizität von Befehlen in atomaren Operationen behandelt, einschließlich Parallelitätsverarbeitungslösungen, Programmiermodellen, Multi-IO-Threads und Einzelbefehlen . Ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: Redis-Video-Tutorial
Wie Redis mit gleichzeitigem Zugriff umgeht
Concurrency-Handling-Lösungen in Redis
Im Geschäftsleben verwenden wir manchmal Redis, um einiges zu verarbeiten ency-Unternehmen Szenarien wie Flash-Sale-Geschäfte und Lagerbestände. . .
Lassen Sie uns zunächst analysieren, welche Probleme in Parallelitätsszenarien auftreten werden.
Parallelitätsprobleme treten hauptsächlich bei der Änderung von Daten auf, die im Allgemeinen in die folgenden zwei Schritte unterteilt werden:
1 Daten Gehen Sie zu lokal und ändern Sie sie lokal.
2 Nachdem der Client die Daten geändert hat, schreiben Sie sie zurück in Redis.
Wir nennen diesen Prozess die Operation Read-Modify-Write (Read-Modify-Write, auch RMW-Operation genannt). Wenn der Client gleichzeitig RMW-Operationen ausführt, muss er sicherstellen, dass read-modify-writeback eine atomare Operation ist. Bei der Ausführung von Befehlsoperationen können andere Clients nicht mit den aktuellen Daten arbeiten. 读取-修改-写回操作(Read-Modify-Write,简称为 RMW 操作)。如果客户端并发进行 RMW 操作的时候,就需要保证 读取-修改-写回是一个原子操作,进行命令操作的时候,其他客户端不能对当前的数据进行操作。
错误的栗子:
统计一个页面的访问次数,每次刷新页面访问次数+1,这里使用 Redis 来记录访问次数。
如果每次的读取-修改-写回操作不是一个原子操作,那么就可能存在下图的问题,客户端2在客户端1操作的中途,也获取 Redis 的值,也对值进行+1,操作,这样就导致最终数据的错误。
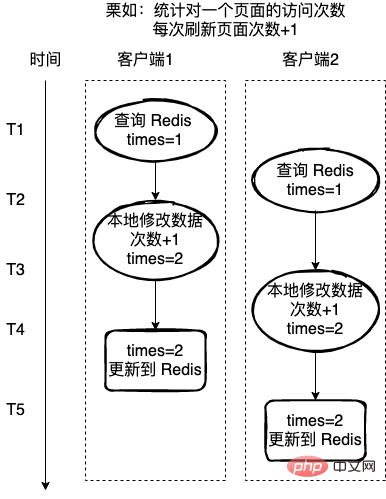
对于上面的这种情况,一般会有两种方式解决:
1、使用 Redis 实现一把分布式锁,通过锁来保护每次只有一个线程来操作临界资源;
2、实现操作命令的原子性。
- 栗如,对于上面的错误栗子,如果
读取-修改-写回Falsche Kastanie:
Zählen Sie die Anzahl der Besuche auf einer Seite und jedes Mal, wenn die Seite aktualisiert wird, wird die Anzahl der Besuche +1 verwendet. Hier wird Redis verwendet, um die Anzahl der Besuche aufzuzeichnen.
Wenn es sich bei jedem read-modify-write-back-Vorgang nicht um einen atomaren Vorgang handelt, liegt möglicherweise ein Problem vor, wie unten gezeigt, und erhält Redis auch mitten im Vorgang von Client 1. Wert und führt außerdem eine +1-Operation für den Wert durch, was zu Fehlern in den endgültigen Daten führt. 
Für die obige Situation gibt es im Allgemeinen zwei Lösungsmöglichkeiten:
1. Verwenden Sie Redis, um eine verteilte Sperre zu implementieren, und verwenden Sie die Sperre, um jeweils nur einen Thread zu schützen, um kritische Ressourcen zu betreiben.
2.
Li Ru, wennread-modify-writeback ein atomarer Befehl ist, wird dieser Befehl während des Vorgangs nicht gleichzeitig von anderen Threads gelesen Daten, damit Sie die oben genannten Probleme vermeiden können. Das Folgende ist eine detaillierte Analyse der Behandlung gleichzeitiger Zugriffsprobleme unter den beiden Aspekten Atomizität und Sperre Der Befehl in Redis Atomicity kann auf zwei Arten gehandhabt werden:
1 Verwenden Sie den atomaren Einzelbefehl in Redis
2. Schreiben Sie mehrere Operationen in ein Lua-Skript und führen Sie ein einzelnes Lua-Skript atomar aus. Wenn wir die Atomizität von Redis besprechen, besprechen wir zunächst das in Redis verwendete Programmiermodell.
Das Reactor-Modell wird in Redis verwendet. Nehmen wir an Schauen Sie sich hier das I/O-Modell unter Unix an.I/O-Modell in Unix
I/O auf dem Betriebssystem ist die Dateninteraktion zwischen Benutzerraum und Kernelraum, daher umfassen I/O-Vorgänge normalerweise die folgenden zwei Schritte:- 1. Warten auf Netzwerkdaten ankommen Netzwerkkarte (lesebereit)/warten, bis die Netzwerkkarte beschreibbar ist (lesebereit) –> Daten aus dem Kernelpuffer kopieren (lesen) /Kopieren aus Benutzerbereichsdaten-> Kernel-Puffer (Schreiben); Verwendung:
- Signal zum Ansteuern von E/A;
- Um zu bestimmen, ob ein E/A-Modell synchron oder asynchron ist, hängt es hauptsächlich vom zweiten Schritt ab: Daten werden zwischen Benutzer und kopiert Kernelraum Blockiert es den aktuellen Prozess? Wenn ja, handelt es sich um synchrone E/A, andernfalls handelt es sich um asynchrone E/A.
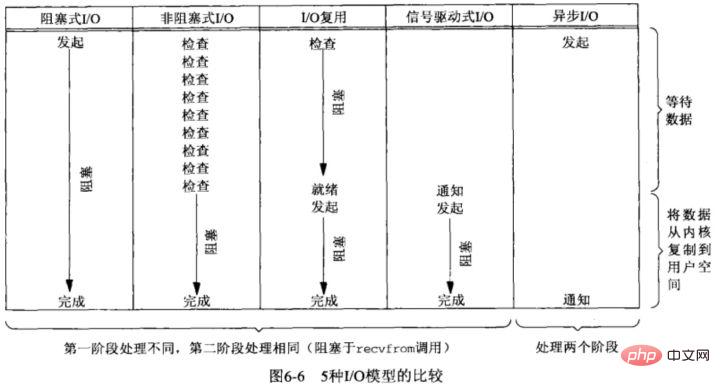
- Blockieren und Warten sind die beiden Prozesse „Kerneldaten sind bereit“ und „Daten werden vom Kernelmodus in den Benutzermodus kopiert“.
-
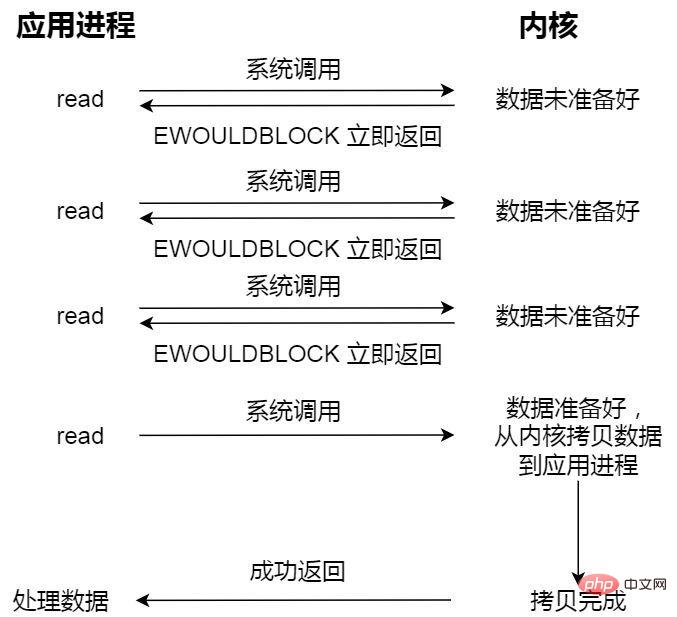
- Nicht blockierende synchrone E/A;
Nicht blockierende Leseanforderung kehrt sofort zurück, wenn die Daten nicht bereit sind, und kann zu diesem Zeitpunkt den Kernel kontinuierlich abfragen, bis die Daten bereit sind Der Kernel wird die Daten in den Anwendungspuffer kopieren und das Ergebnis kann durch Aufrufen von read abgerufen werden.
Der letzte Leseaufruf hier, der Prozess der Datenbeschaffung, ist ein synchroner Prozess und ein Prozess, der Warten erfordert. Unter Synchronisierung versteht man hier den Vorgang des Kopierens von Kernel-Statusdaten in den Cache-Bereich des Benutzerprogramms.
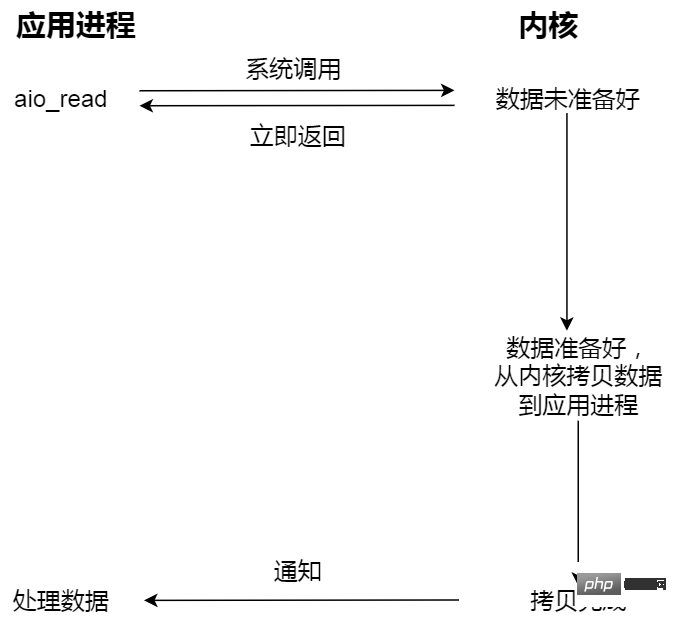
- Nicht blockierende asynchrone E/A;
Initiieren Sie eine asynchrone E/A und kehren Sie sofort zurück. Der Kernel kopiert die Daten automatisch aus dem Kernelbereich in den Benutzerbereich Im Gegensatz zum Synchronisierungsvorgang muss die Anwendung den Kopiervorgang nicht aktiv initiieren.
Wenn Sie beispielsweise zum Essen in die Kantine gehen, sind Sie wie die Anwendung und die Kantine ist wie das Betriebssystem.
Blocking I/O Man geht zum Beispiel in die Kantine, um zu essen, aber das Essen in der Kantine ist noch nicht fertig, und dann wartet man dort weiter und wartet. Nach langem Warten ist die Tante endlich in der Kantine Bringt das Essen heraus (Der Prozess der Datenvorbereitung), aber Sie müssen noch warten, bis die Tante das Essen (Kernelraum) in Ihre Brotdose (Benutzerraum) legt. Nachdem Sie diese beiden Prozesse durchlaufen haben, können Sie gehen.
Non-blocking I/O Du bist zum Beispiel in die Kantine gegangen und hast deine Tante gefragt, ob das Essen fertig sei, also bist du nach ein paar Dutzend Minuten in die Kantine gegangen noch einmal und fragte deine Tante, und sie sagte, es sei fertig, also hilft Tante dir, das Essen in deine Brotdose zu legen. Du musst auf diesen Vorgang warten.
Asynchrone E/A Wenn Sie beispielsweise die Tante in der Kantine bitten, das Geschirr zuzubereiten, es in die Lunchbox zu legen und Ihnen dann die Lunchbox zu liefern, müssen Sie nicht auf den gesamten Vorgang warten.
In Webdiensten gibt es normalerweise zwei Architekturen für die Verarbeitung von Webanfragen, nämlich:
Thread-basierte Architektur(threadbasierte Architektur),ereignisgesteuerte Architektur(Ereignis- Angetriebenes Modell)thread-based architecture(基于线程的架构)、event-driven architecture(事件驱动模型)thread-based architecture(基于线程的架构)
thread-based architecture(基于线程的架构):这种比较容易理解,就是多线程并发模式,服务端在处理请求的时候,一个请求分配一个独立的线程来处理。
因为每个请求分配一个独立的线程,所以单个线程的阻塞不会影响到其他的线程,能够提高程序的响应速度。
不足的是,连接和线程之间始终保持一对一的关系,如果是一直处于 Keep-Alive 状态的长连接将会导致大量工作线程在空闲状态下等待,例如,文件系统访问,网络等。此外,成百上千的连接还可能会导致并发线程浪费大量内存的堆栈空间。
event-driven architecture(事件驱动模型)
事件驱动的体系结构由事件生产者和事件消费者组,是一种松耦合、分布式的驱动架构,生产者收集到某应用产生的事件后实时对事件采取必要的处理后路由至下游系统,无需等待系统响应,下游的事件消费者组收到是事件消息,异步的处理。
事件驱动架构具有以下优势:
- 降低耦合;
降低事件生产者和订阅者的耦合性。事件生产者只需关注事件的发生,无需关注事件如何处理以及被分发给哪些订阅者。任何一个环节出现故障,不会影响其他业务正常运行。
- 异步执行;
事件驱动架构适用于异步场景,即便是需求高峰期,收集各种来源的事件后保留在事件总线中,然后逐步分发传递事件,不会造成系统拥塞或资源过剩的情况。
- 可扩展性;
事件驱动架构中路由和过滤能力支持划分服务,便于扩展和路由分发。
Reactor 模式和 Proactor 模式都是
event-driven architectureThread-basierte Architektur (Thread-basierte Architektur)
Thread-basierte Architektur (Thread-basierte Architektur): Dies ist einfacher zu verstehen, es ist der Multithread-Parallelitätsmodus, den der Server verarbeitet request: Eine Anfrage wird einem unabhängigen Thread zur Verarbeitung zugewiesen. Da jeder Anfrage ein unabhängiger Thread zugewiesen ist, hat das Blockieren eines einzelnen Threads keine Auswirkungen auf andere Threads, was die Reaktionsgeschwindigkeit des Programms verbessern kann. Der Nachteil besteht darin, dass zwischen Verbindungen und Threads immer eine Eins-zu-Eins-Beziehung besteht. Wenn es sich um eine lange Verbindung handelt, die sich immer im Keep-Alive-Zustand befindet, führt dies dazu, dass eine große Anzahl von Arbeitsthreads in einem Wartezustand liegt Ruhezustand, z. B. Dateisystemzugriff, Netzwerk usw. . Darüber hinaus können Hunderte oder Tausende von Verbindungen dazu führen, dass gleichzeitige Threads große Mengen an Speicherplatz im Speicherstapel verschwenden.- Ereignisgesteuerte Architektur (ereignisgesteuertes Modell)
- Die ereignisgesteuerte Architektur besteht aus Ereignisproduzenten und Ereigniskonsumentengruppen. Es handelt sich um eine lose gekoppelte und verteilte Treiberarchitektur. Der Produzent sammelt die von einer Anwendung generierten Informationen. Nach dem Ereignis wird die erforderliche Verarbeitung des Ereignisses in Echtzeit durchgeführt und dann an das Downstream-System weitergeleitet, ohne auf die Systemantwort zu warten. Die Downstream-Ereigniskonsumentengruppe empfängt die Ereignisnachricht und verarbeitet sie asynchron.
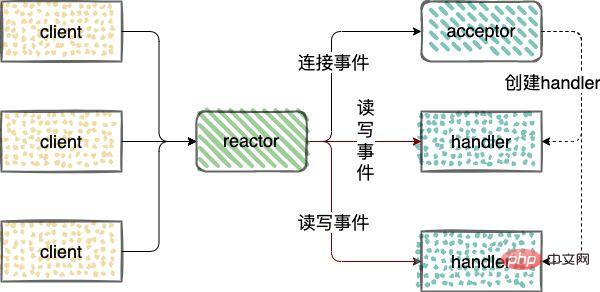
Kopplung reduzieren; 🎜Kopplung von Ereignisproduzenten und Abonnenten reduzieren; Der Ereignisproduzent muss nur auf das Auftreten des Ereignisses achten und muss nicht darauf achten, wie das Ereignis verarbeitet wird und an welche Abonnenten es verteilt wird. Sollte eine Verbindung ausfallen, hat dies keine Auswirkungen auf den normalen Betrieb anderer Unternehmen. 🎜🎜🎜Asynchrone Ausführung; 🎜🎜🎜Die ereignisgesteuerte Architektur eignet sich für asynchrone Szenarien. Auch in Zeiten der Spitzennachfrage werden Ereignisse aus verschiedenen Quellen im Ereignisbus gesammelt und dann nach und nach verteilt und zugestellt, ohne dass es dazu kommt Systemüberlastung oder überschüssige Ressourcensituation. 🎜🎜🎜Skalierbarkeit 🎜🎜🎜Die Routing- und Filterfunktionen in der ereignisgesteuerten Architektur unterstützen die Partitionierung von Diensten, um die Erweiterung und Routenverteilung zu erleichtern. 🎜🎜Reactor-Modus und Proactor-Modus sind beide Implementierungsmethoden derereignisgesteuerten Architektur(ereignisgesteuertes Modell). Hier finden Sie eine detaillierte Analyse des 🎜🎜🎜Reactor-Modus🎜🎜🎜Reactor-Modus bezieht sich auf die Verwendung eines oder mehrerer ereignisgesteuerter Verarbeitungsmodelle für Serviceanfragen, bei denen Eingaben gleichzeitig an den Serviceprozessor weitergeleitet werden. 🎜🎜Verarbeitung von Netzwerk-E/A-Verbindungsereignissen, Leseereignissen und Schreibereignissen. In Reactor🎜🎜🎜Reactor werden drei Arten von Rollen eingeführt: Ereignisse überwachen und verteilen, Ereignisse mit dem Akzeptor verbinden, Ereignisse lesen und in den Handler schreiben Netzwerk Die Verbindung verarbeitet nachfolgende Lese- und Schreibereignisse. 🎜🎜handler: verarbeitet Lese- und Schreibereignisse. 🎜🎜🎜🎜🎜🎜Reaktormodelle sind in 3 Kategorien unterteilt: 🎜- Single-Threaded-Reaktormodus;
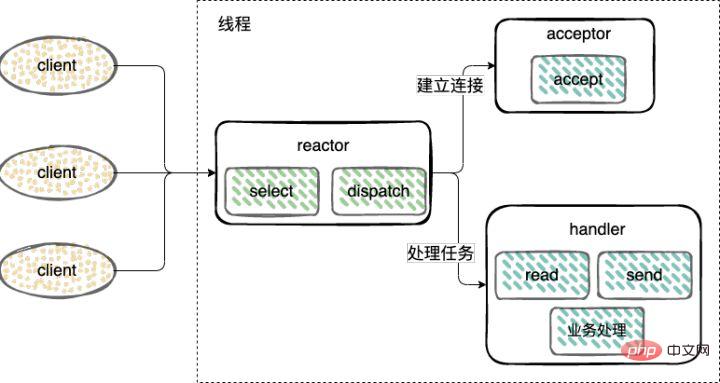
Der Verbindungsaufbau (Akzeptor), die Überwachung von Annahme-, Lese- und Schreibereignissen (Reaktor) und die Verarbeitung von Ereignissen (Handler) verwenden alle nur einen einzigen Thread; Threaded Reactor-Modus;
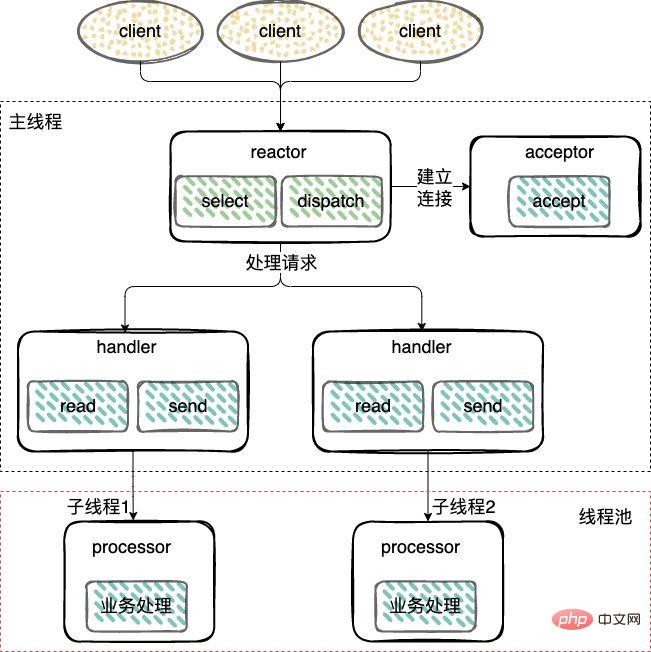
Im Gegensatz zum Single-Threaded-Modus wird ein Worker-Thread-Pool hinzugefügt und Nicht-
Stellen Sie eine Verbindung her (Akzeptor) und hören Sie zu, um Ereignisse anzunehmen, zu lesen, zu schreiben (Reaktor) und einen Thread wiederzuverwenden.I/O-Operationen werden aus dem Reactor-Thread entfernt und an den Worker-Thread übertragen pool (Thread-Pool) zur Ausführung.I/O操作从 Reactor 线程中移出转交给工作者线程池(Thread Pool)来执行。建立连接(Acceptor)和 监听accept、read、write事件(Reactor),复用一个线程。
工作线程池:处理事件(Handler),由一个工作线程池来执行业务逻辑,包括数据就绪后,用户态的数据读写。
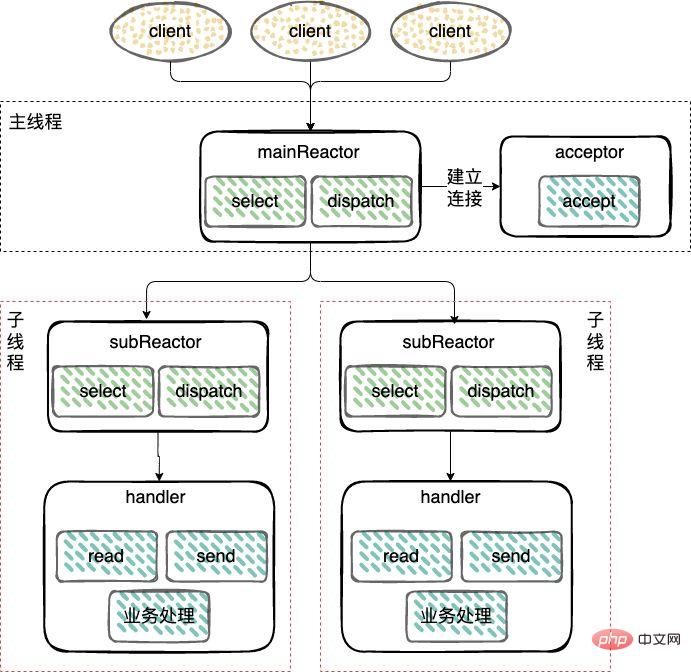
- 主从 Reactor 模式;
对于多个CPU的机器,为充分利用系统资源,将 Reactor 拆分为两部分:mainReactor 和 subReactor。
mainReactor:负责监听
server socket,用来处理网络新连接的建立,将建立的socketChannel指定注册给subReactor,通常一个线程就可以处理;subReactor:监听
accept、read、write事件(Reactor),包括等待数据就绪时,内核态的数据读写,通常使用多线程。工作线程:处理事件(Handler)可以和 subReactor 共同使用同一个线程,也可以做成线程池,类似上面多线程 Reactor 模式下的工作线程池的处理方式。
Proactor 模式
reactor 流程与 Reactor 模式类似
不同点就是
- Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。
在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
- Proactor 是异步网络模式,感知的是已完成的读写事件。
在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起
read/write来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。因此,Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。
举个实际生活中的例子,Reactor 模式就是快递员在楼下,给你打电话告诉你快递到你家小区了,你需要自己下楼来拿快递。而在 Proactor 模式下,快递员直接将快递送到你家门口,然后通知你。
为什么 Redis 选择单线程
Redis 中使用是单线程,可能处于以下几方面的考虑
1、Redis 是纯内存的操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,性能瓶颈在于网络 I/O;
2、避免过多的上下文切换开销,单线程则可以规避进程内频繁的线程切换开销;
3、避免同步机制的开销,多线程必然会面临对于共享资源的访问,这时候通常的做法就是加锁,虽然是多线程,这时候就会变成串行的访问。也就是多线程编程模式会面临的共享资源的并发访问控制问题;
4、简单可维护,多线程也会引入同步原语来保护共享资源的并发访问,代码的可维护性和易读性将会下降。
Redis 在 v6.0 版本之前,Redis 的核心网络模型一直是一个典型的单 Reactor 模型:利用
Master-Slave-Reaktormodus;epoll/select/kqueueWorker-Thread-Pool: Behandelt Ereignisse (Handler). Ein Worker-Thread-Pool führt Geschäftslogik aus, einschließlich Lesen und Schreiben von Daten im Benutzermodus, nachdem die Daten bereit sind.Um die Systemressourcen voll auszunutzen, ist der Reaktor bei Maschinen mit mehreren CPUs in zwei Teile aufgeteilt: Hauptreaktor und Unterreaktor.
mainReactor: Verantwortlich für die Überwachung vonServer-Socket, wird für die Einrichtung neuer Netzwerkverbindungen verwendet und registriert den eingerichteten socketChannel bei subReactor. Normalerweise kann ein Thread damit umgehen. subReactor: Überwachung vonAkzeptieren, lesen, schreiben-Ereignisse (Reactor), einschließlich des Lesens und Schreibens von Daten im Kernel-Modus, wenn darauf gewartet wird, dass Daten bereit sind, normalerweise unter Verwendung von Multithreading. Worker-Thread: Die Ereignisverarbeitung (Handler) kann denselben Thread wie der SubReactor verwenden oder in einen Thread-Pool umgewandelt werden, ähnlich der Verarbeitungsmethode des Worker-Thread-Pools im Multithread-Reactor-Modus oben. 🎜🎜🎜Proactor-Modus🎜🎜🎜Der Reaktorprozess ähnelt dem Reactor-Modus🎜🎜Der Unterschied besteht darin, dass 🎜🎜🎜Reactor ein nicht blockierender synchroner Netzwerkmodus ist und bereite Lese- und Schreibereignisse erkennt. 🎜🎜🎜Jedes Mal, wenn festgestellt wird, dass ein Ereignis eintritt (z. B. ein lesbares Bereitschaftsereignis), muss der Anwendungsprozess die Lesemethode aktiv aufrufen, um das Lesen der Daten abzuschließen. Das heißt, der Anwendungsprozess muss die Daten aktiv lesen Im Speicher des Anwendungsprozesses ist dieser Prozess synchron, und der Anwendungsprozess kann die Daten erst verarbeiten, nachdem er die Daten gelesen hat. 🎜🎜🎜Proactor ist ein asynchroner Netzwerkmodus, der abgeschlossene Lese- und Schreibereignisse erkennt. 🎜🎜🎜Wenn Sie eine asynchrone Lese- und Schreibanforderung initiieren, müssen Sie die Adresse des Datenpuffers (der zum Speichern der Ergebnisdaten verwendet wird) und andere Informationen übergeben, damit der Systemkern uns automatisch dabei helfen kann, das Lesen und Schreiben abzuschließen Die Lese- und Schreibarbeit erfolgt hier durch das Betriebssystem. Es ist nicht erforderlich, dass der Anwendungsprozess aktivLesen/Schreibeninitiiert, um Daten zu lesen und zu schreiben Nach Abschluss der Lese- und Schreibarbeiten wird der Bewerbungsprozess benachrichtigt, um die Daten direkt zu verarbeiten. 🎜🎜Daher kann Reactor als „das Betriebssystem benachrichtigt den Anwendungsprozess, wenn ein Ereignis eintritt, und lässt den Anwendungsprozess damit umgehen“ verstanden werden, während Proactor als „das Betriebssystem wird das Ereignis verarbeiten, wenn es eintritt“ verstanden werden kann. und dann den Bewerbungsprozess nach der Bearbeitung benachrichtigen.“ 🎜🎜Um ein Beispiel aus dem wirklichen Leben zu nennen: Das Reactor-Modell bedeutet, dass der Kurier unten ist und Sie anruft, um Ihnen mitzuteilen, dass der Kurier in Ihrer Gemeinde angekommen ist. Sie müssen nach unten gehen, um den Kurier selbst abzuholen. Im Proactor-Modus liefert der Kurier das Paket direkt an Ihre Haustür und benachrichtigt Sie anschließend. 🎜🎜🎜Warum Redis einen einzelnen Thread wählt🎜🎜🎜Die Verwendung eines einzelnen Threads in Redis kann auf die folgenden Überlegungen zurückzuführen sein🎜🎜1. Redis ist eine reine Speicheroperation und die Ausführungsgeschwindigkeit ist sehr hoch, daher ist dieser Teil der Operation normalerweise Es handelt sich nicht um einen Leistungsengpass, und der Leistungsengpass liegt in der Netzwerk-E/A. Durch Einzelthreading kann der Overhead der Synchronisierung vermieden werden Mechanismus, Multithreading ist unvermeidlich Beim Zugriff auf gemeinsam genutzte Ressourcen besteht der übliche Ansatz darin, zu sperren. Obwohl es sich um Multithreading handelt, wird es zu diesem Zeitpunkt zum seriellen Zugriff. Das heißt, das Problem der gleichzeitigen Zugriffskontrolle auf gemeinsam genutzte Ressourcen, mit dem der Multithread-Programmiermodus konfrontiert ist, führt auch Synchronisierungsprimitive ein, um den Code wartbar zu machen lesbar. 🎜🎜Redis Vor Version v6.0 war das Kernnetzwerkmodell von Redis immer ein typisches Einzelreaktormodell: Verwendung von Multiplexing-Technologien wieepoll/select/kqueuein einer Single-Threaded-Ereignisschleife Kontinuierlich Verarbeiten Sie Ereignisse (Client-Anfragen) und schreiben Sie schließlich Antwortdaten zurück an den Client: 🎜🎜Hier sehen Sie, wie Redis einen einzelnen Thread zum Verarbeiten von Aufgaben verwendet🎜🎜🎜🎜🎜🎜Das ereignisgesteuerte Framework erfasst und verteilt Ereignisse🎜🎜 🎜 Das Netzwerk-Framework von Redis implementiert das Reactor-Modell und entwickelt und implementiert selbst ein ereignisgesteuertes Framework. 🎜🎜Die Logik des ereignisgesteuerten Frameworks ist einfach 🎜- Ereignisinitialisierung;
- Ereigniserfassung;
- Verteilung und Verarbeitung der Hauptschleife.
Werfen wir einen Blick auf mehrere Hauptfunktionen, die vom ereignisgesteuerten Framework in Redis implementiert werden
// 执行事件捕获,分发和处理循环 void aeMain(aeEventLoop *eventLoop); // 用来注册监听的事件和事件对应的处理函数。只有对事件和处理函数进行了注册,才能在事件发生时调用相应的函数进行处理。 int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask, aeFileProc *proc, void *clientData); // aeProcessEvents 函数实现的主要功能,包括捕获事件、判断事件类型和调用具体的事件处理函数,从而实现事件的处理 int aeProcessEvents(aeEventLoop *eventLoop, int flags);
Nach dem Login kopierenVerwenden Sie aeMain als Hauptschleife, um Ereignisse kontinuierlich zu überwachen und zu erfassen, in der die Funktion aeProcessEvents aufgerufen wird, um Ereignisse zu implementieren Erfassen und bestimmen Sie Ereignistypen und rufen Sie bestimmte Ereignisverarbeitungsfunktionen auf, um die Ereignisverarbeitung zu implementieren.
// https://github.com/redis/redis/blob/5.0/src/ae.c#L496 void aeMain(aeEventLoop *eventLoop) { eventLoop->stop = 0; while (!eventLoop->stop) { if (eventLoop->beforesleep != NULL) eventLoop->beforesleep(eventLoop); aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP); } } // https://github.com/redis/redis/blob/5.0/src/ae.c#L358 int aeProcessEvents(aeEventLoop *eventLoop, int flags) { ... if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) { ... //调用aeApiPoll函数捕获事件 numevents = aeApiPoll(eventLoop, tvp); ... } ... }Nach dem Login kopierenSie können sehen, dass die Erfassung von IO-Ereignissen in aeProcessEvents durch den Aufruf von aeApiPoll abgeschlossen wird.
aeApiPoll ist eine I/O-Multiplex-API. Sie basiert auf der Kapselung von Systemaufrufen wie
epoll_wait/select/kevent. Sie wartet darauf, dass Lese- und Schreibereignisse ausgelöst werden Es handelt sich um eine Ereignisschleife (Event Loop), die die Grundlage für den ereignisgesteuerten Betrieb bildet.epoll_wait/select/kevent等系统调用的封装,监听等待读写事件触发,然后处理,它是事件循环(Event Loop)中的核心函数,是事件驱动得以运行的基础。Redis 是依赖于操作系统底层提供的 IO 多路复用机制,来实现事件捕获,检查是否有新的连接、读写事件发生。为了适配不同的操作系统,Redis 对不同操作系统实现的网络 IO 多路复用函数,都进行了统一的封装。
// https://github.com/redis/redis/blob/5.0/src/ae.c#L49 #ifdef HAVE_EVPORT #include "ae_evport.c" // Solaris #else #ifdef HAVE_EPOLL #include "ae_epoll.c" // Linux #else #ifdef HAVE_KQUEUE #include "ae_kqueue.c" // MacOS #else #include "ae_select.c" // Windows #endif #endif #endif
Nach dem Login kopierenae_epoll.c:对应 Linux 上的 IO 复用函数 epoll;
ae_evport.c:对应 Solaris 上的 IO 复用函数 evport;
ae_kqueue.c:对应 macOS 或 FreeBSD 上的 IO 复用函数 kqueue;
ae_select.c:对应 Linux(或 Windows)的 IO 复用函数 select。
客户端连接应答
监听 socket 的读事件,当有客户端连接请求过来,使用函数 acceptTcpHandler 和客户端建立连接
当 Redis 启动后,服务器程序的 main 函数会调用 initSever 函数来进行初始化,而在初始化的过程中,aeCreateFileEvent 就会被 initServer 函数调用,用于注册要监听的事件,以及相应的事件处理函数。
// https://github.com/redis/redis/blob/5.0/src/server.c#L2036 void initServer(void) { ... // 创建一个事件处理程序以接受 TCP 和 Unix 中的新连接 for (j = 0; j < server.ipfd_count; j++) { if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE, acceptTcpHandler,NULL) == AE_ERR) { serverPanic( "Unrecoverable error creating server.ipfd file event."); } } ... }Nach dem Login kopieren可以看到 initServer 中会根据启用的 IP 端口个数,为每个 IP 端口上的网络事件,调用 aeCreateFileEvent,创建对 AE_READABLE 事件的监听,并且注册 AE_READABLE 事件的处理 handler,也就是 acceptTcpHandler 函数。
然后看下 acceptTcpHandler 的实现
// https://github.com/redis/redis/blob/5.0/src/networking.c#L734 void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) { int cport, cfd, max = MAX_ACCEPTS_PER_CALL; char cip[NET_IP_STR_LEN]; UNUSED(el); UNUSED(mask); UNUSED(privdata); while(max--) { // 用于accept客户端的连接,其返回值是客户端对应的socket cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport); if (cfd == ANET_ERR) { if (errno != EWOULDBLOCK) serverLog(LL_WARNING, "Accepting client connection: %s", server.neterr); return; } serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport); // 会调用acceptCommonHandler对连接以及客户端进行初始化 acceptCommonHandler(cfd,0,cip); } } // https://github.com/redis/redis/blob/5.0/src/networking.c#L664 static void acceptCommonHandler(int fd, int flags, char *ip) { client *c; // 分配并初始化新客户端 if ((c = createClient(fd)) == NULL) { serverLog(LL_WARNING, "Error registering fd event for the new client: %s (fd=%d)", strerror(errno),fd); close(fd); /* May be already closed, just ignore errors */ return; } // 判断当前连接的客户端是否超过最大值,如果超过的话,会拒绝这次连接。否则,更新客户端连接数的计数 if (listLength(server.clients) > server.maxclients) { char *err = "-ERR max number of clients reached\r\n"; /* That's a best effort error message, don't check write errors */ if (write(c->fd,err,strlen(err)) == -1) { /* Nothing to do, Just to avoid the warning... */ } server.stat_rejected_conn++; freeClient(c); return; } ... } // 使用多路复用,需要记录每个客户端的状态,client 之前通过链表保存 typedef struct client { int fd; // 字段是客户端套接字文件描述符 sds querybuf; // 保存客户端发来命令请求的输入缓冲区。以Redis通信协议的方式保存 int argc; // 当前命令的参数数量 robj **argv; // 当前命令的参数 redisDb *db; // 当前选择的数据库指针 int flags; list *reply; // 保存命令回复的链表。因为静态缓冲区大小固定,主要保存固定长度的命令回复,当处理一些返回大量回复的命令,则会将命令回复以链表的形式连接起来。 // ... many other fields ... char buf[PROTO_REPLY_CHUNK_BYTES]; } client; client *createClient(int fd) { client *c = zmalloc(sizeof(client)); // 如果fd为-1,表示创建的是一个无网络连接的伪客户端,用于执行lua脚本的时候。 // 如果fd不等于-1,表示创建一个有网络连接的客户端 if (fd != -1) { // 设置fd为非阻塞模式 anetNonBlock(NULL,fd); // 禁止使用 Nagle 算法,client向内核递交的每个数据包都会立即发送给server出去,TCP_NODELAY anetEnableTcpNoDelay(NULL,fd); // 如果开启了tcpkeepalive,则设置 SO_KEEPALIVE if (server.tcpkeepalive) anetKeepAlive(NULL,fd,server.tcpkeepalive); // 创建一个文件事件状态el,且监听读事件,开始接受命令的输入 if (aeCreateFileEvent(server.el,fd,AE_READABLE, readQueryFromClient, c) == AE_ERR) { close(fd); zfree(c); return NULL; } } ... // 初始化client 中的参数 return c; }Nach dem Login kopieren1、acceptTcpHandler 主要用于处理和客户端连接的建立;
2、其中会调用函数 anetTcpAccept 用于 accept 客户端的连接,其返回值是客户端对应的 socket;
3、然后调用 acceptCommonHandler 对连接以及客户端进行初始化;
4、初始化客户端的时候,同时使用 aeCreateFileEvent 用来注册监听的事件和事件对应的处理函数,将 readQueryFromClient 命令读取处理器绑定到新连接对应的文件描述符上;
5、服务器会监听该文件描述符的读事件,当客户端发送了命令,触发了 AE_READABLE 事件,那么就会调用回调函数 readQueryFromClient() 来从文件描述符 fd 中读发来的命令,并保存在输入缓冲区中 querybuf。
命令的接收
readQueryFromClient 是请求处理的起点,解析并执行客户端的请求命令。
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1522 // 读取client的输入缓冲区的内容 void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) { client *c = (client*) privdata; int nread, readlen; size_t qblen; UNUSED(el); UNUSED(mask); ... // 输入缓冲区的长度 qblen = sdslen(c->querybuf); // 更新缓冲区的峰值 if (c->querybuf_peak < qblen) c->querybuf_peak = qblen; // 扩展缓冲区的大小 c->querybuf = sdsMakeRoomFor(c->querybuf, readlen); // 调用read从描述符为fd的客户端socket中读取数据 nread = read(fd, c->querybuf+qblen, readlen); ... // 处理读取的内容 processInputBufferAndReplicate(c); } // https://github.com/redis/redis/blob/5.0/src/networking.c#L1507 void processInputBufferAndReplicate(client *c) { // 当前客户端不属于主从复制中的Master // 直接调用 processInputBuffer,对客户端输入缓冲区中的命令和参数进行解析 if (!(c->flags & CLIENT_MASTER)) { processInputBuffer(c); // 客户端属于主从复制中的Master // 调用processInputBuffer函数,解析客户端命令, // 调用replicationFeedSlavesFromMasterStream 函数,将主节点接收到的命令同步给从节点 } else { size_t prev_offset = c->reploff; processInputBuffer(c); size_t applied = c->reploff - prev_offset; if (applied) { replicationFeedSlavesFromMasterStream(server.slaves, c->pending_querybuf, applied); sdsrange(c->pending_querybuf,applied,-1); } } } // https://github.com/redis/redis/blob/5.0/src/networking.c#L1428 void processInputBuffer(client *c) { server.current_client = c; /* Keep processing while there is something in the input buffer */ // 持续读取缓冲区的内容 while(c->qb_pos < sdslen(c->querybuf)) { ... /* Multibulk processing could see a <= 0 length. */ // 如果参数为0,则重置client if (c->argc == 0) { resetClient(c); } else { /* Only reset the client when the command was executed. */ // 执行命令成功后重置client if (processCommand(c) == C_OK) { if (c->flags & CLIENT_MASTER && !(c->flags & CLIENT_MULTI)) { /* Update the applied replication offset of our master. */ c->reploff = c->read_reploff - sdslen(c->querybuf) + c->qb_pos; } // 命令处于阻塞状态中的客户端,不需要进行重置 if (!(c->flags & CLIENT_BLOCKED) || c->btype != BLOCKED_MODULE) resetClient(c); } /* freeMemoryIfNeeded may flush slave output buffers. This may * result into a slave, that may be the active client, to be * freed. */ if (server.current_client == NULL) break; } } /* Trim to pos */ if (server.current_client != NULL && c->qb_pos) { sdsrange(c->querybuf,c->qb_pos,-1); c->qb_pos = 0; } server.current_client = NULL; }Nach dem Login kopieren1、readQueryFromClient(),从文件描述符 fd 中读出数据到输入缓冲区 querybuf 中;
2、使用 processInputBuffer 函数完成对命令的解析,在其中使用 processInlineBuffer 或者 processMultibulkBuffer 根据 Redis 协议解析命令;
3、完成对一个命令的解析,就使用 processCommand 对命令就行执行;
4、命令执行完成,最后调用 addReply 函数族的一系列函数将响应数据写入到对应 client 的写出缓冲区:client->buf 或者 client->reply ,client->buf 是首选的写出缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到 client->reply 链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把 client 添加进一个 LIFO 队列 clients_pending_write;
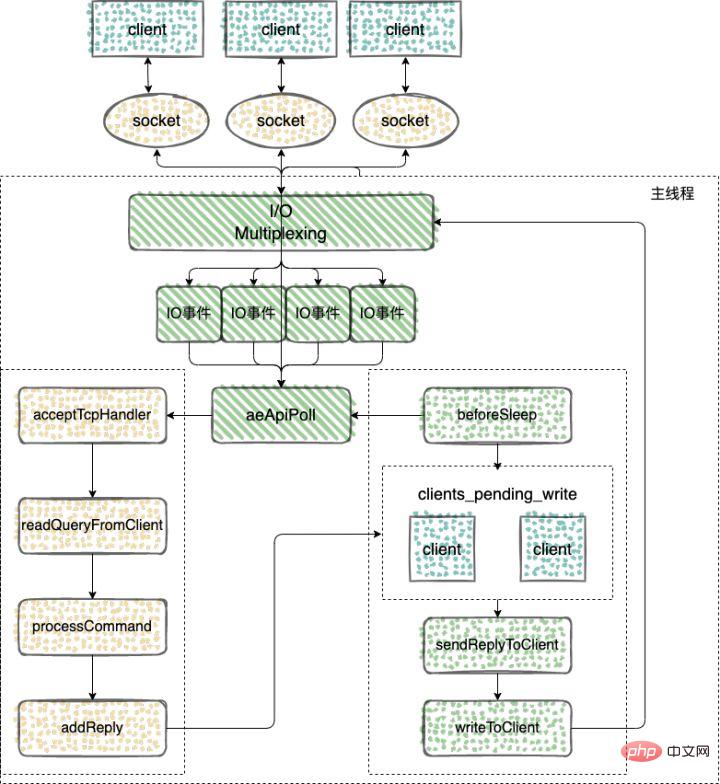
命令的回复
在 Redis 事件驱动框架每次循环进入事件处理函数前,来处理监听到的已触发事件或是到时的时间事件之前,都会调用 beforeSleep 函数,进行一些任务处理,这其中就包括了调用 handleClientsWithPendingWrites 函数,它会将
Redis verlässt sich auf den E/A-Multiplexmechanismus des zugrunde liegenden Betriebssystems, um die Ereigniserfassung zu implementieren und zu prüfen, ob neue Verbindungen sowie Lese- und Schreibereignisse auftreten. Um sich an verschiedene Betriebssysteme anzupassen, kapselt Redis die von verschiedenen Betriebssystemen implementierten Netzwerk-IO-Multiplexing-Funktionen einheitlich.Redis severae_epoll.c: entspricht der IO-Multiplexing-Funktion epoll unter Linux; 🎜🎜ae_evport.c: entspricht der IO-Multiplexing-Funktion evport unter Solaris; 🎜🎜ae_kqueue.c: entspricht der IO-Multiplexing-Funktion kqueue unter macOS oder FreeBSD ;🎜🎜ae_select.c: Entspricht der IO-Multiplexing-Funktion select von Linux (oder Windows). 🎜// https://github.com/redis/redis/blob/5.0/src/server.c#L1380 void beforeSleep(struct aeEventLoop *eventLoop) { UNUSED(eventLoop); ... // 将 Redis sever 客户端缓冲区中的数据写回客户端 handleClientsWithPendingWrites(); ... } // https://github.com/redis/redis/blob/5.0/src/networking.c#L1082 int handleClientsWithPendingWrites(void) { listIter li; listNode *ln; // 遍历 clients_pending_write 队列,调用 writeToClient 把 client 的写出缓冲区里的数据回写到客户端 int processed = listLength(server.clients_pending_write); listRewind(server.clients_pending_write,&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_WRITE; listDelNode(server.clients_pending_write,ln); ... // 调用 writeToClient 函数,将客户端输出缓冲区中的数据写回 if (writeToClient(c->fd,c,0) == C_ERR) continue; // 如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites 函数就 // 会调用 aeCreateFileEvent 函数,创建可写事件,并设置回调函数 sendReplyToClien if (clientHasPendingReplies(c)) { int ae_flags = AE_WRITABLE; if (server.aof_state == AOF_ON && server.aof_fsync == AOF_FSYNC_ALWAYS) { ae_flags |= AE_BARRIER; } // 将文件描述符fd和AE_WRITABLE事件关联起来,当客户端可写时,就会触发事件,调用sendReplyToClient()函数,执行写事件 if (aeCreateFileEvent(server.el, c->fd, ae_flags, sendReplyToClient, c) == AE_ERR) { freeClientAsync(c); } } } return processed; } // https://github.com/redis/redis/blob/5.0/src/networking.c#L1072 // 写事件处理程序,只是发送回复给client void sendReplyToClient(aeEventLoop *el, int fd, void *privdata, int mask) { UNUSED(el); UNUSED(mask); writeToClient(fd,privdata,1); } // https://github.com/redis/redis/blob/5.0/src/networking.c#L979 // 将输出缓冲区的数据写给client,如果client被释放则返回C_ERR,没被释放则返回C_OK int writeToClient(int fd, client *c, int handler_installed) { ssize_t nwritten = 0, totwritten = 0; size_t objlen; clientReplyBlock *o; // 如果指定的client的回复缓冲区中还有数据,则返回真,表示可以写socket while(clientHasPendingReplies(c)) { // 固定缓冲区发送未完成 if (c->bufpos > 0) { // 将缓冲区的数据写到fd中 nwritten = write(fd,c->buf+c->sentlen,c->bufpos-c->sentlen); ... // 如果发送的数据等于buf的偏移量,表示发送完成 if ((int)c->sentlen == c->bufpos) { c->bufpos = 0; c->sentlen = 0; } // 固定缓冲区发送完成,发送回复链表的内容 } else { // 回复链表的第一条回复对象,和对象值的长度和所占的内存 o = listNodeValue(listFirst(c->reply)); objlen = o->used; if (objlen == 0) { c->reply_bytes -= o->size; listDelNode(c->reply,listFirst(c->reply)); continue; } // 将当前节点的值写到fd中 nwritten = write(fd, o->buf + c->sentlen, objlen - c->sentlen); if (nwritten <= 0) break; c->sentlen += nwritten; totwritten += nwritten; ... } ... } ... // 如果指定的client的回复缓冲区中已经没有数据,发送完成 if (!clientHasPendingReplies(c)) { c->sentlen = 0; // 删除当前client的可读事件的监听 if (handler_installed) aeDeleteFileEvent(server.el,c->fd,AE_WRITABLE); /* Close connection after entire reply has been sent. */ // 如果指定了写入按成之后立即关闭的标志,则释放client if (c->flags & CLIENT_CLOSE_AFTER_REPLY) { freeClient(c); return C_ERR; } } return C_OK; }Nach dem Login kopierenClient-Verbindungsantwort
🎜Überwachen Sie das Leseereignis des Sockets. Wenn eine Client-Verbindungsanforderung eingeht, verwenden Sie die Funktion „acceptTcpHandler“, um eine Verbindung mit dem Client herzustellen. 🎜🎜Wenn Redis Startet der Server Die Hauptfunktion des Programms ruft zur Initialisierung die Funktion initSever auf. Während des Initialisierungsprozesses wird aeCreateFileEvent von der Funktion initServer aufgerufen, um die zu überwachenden Ereignisse und die entsprechenden Ereignisverarbeitungsfunktionen zu registrieren. 🎜🎜Sie können sehen, dass initServer aeCreateFileEvent für Netzwerkereignisse an jedem IP-Port basierend auf der Anzahl der aktivierten IP-Ports aufruft, einen Listener für das AE_READABLE-Ereignis erstellt und den Handler für das AE_READABLE-Ereignis registriert, bei dem es sich um die Funktion „acceptTcpHandler“ handelt. 🎜🎜Dann werfen Sie einen Blick auf die Implementierung von AcceptTcpHandler🎜// https://github.com/redis/redis/blob/6.2/src/networking.c#L3573 void initThreadedIO(void) { server.io_threads_active = 0; /* We start with threads not active. */ /* Don't spawn any thread if the user selected a single thread: * we'll handle I/O directly from the main thread. */ // 如果用户只配置了一个 I/O 线程,不需要创建新线程了,直接在主线程中处理 if (server.io_threads_num == 1) return; if (server.io_threads_num > IO_THREADS_MAX_NUM) { serverLog(LL_WARNING,"Fatal: too many I/O threads configured. " "The maximum number is %d.", IO_THREADS_MAX_NUM); exit(1); } /* Spawn and initialize the I/O threads. */ // 初始化线程 for (int i = 0; i < server.io_threads_num; i++) { /* Things we do for all the threads including the main thread. */ io_threads_list[i] = listCreate(); // 编号为0是主线程 if (i == 0) continue; /* Thread 0 is the main thread. */ /* Things we do only for the additional threads. */ pthread_t tid; // 初始化io_threads_mutex数组 pthread_mutex_init(&io_threads_mutex[i],NULL); // 初始化io_threads_pending数组 setIOPendingCount(i, 0); // 主线程在启动 I/O 线程的时候会默认先锁住它,直到有 I/O 任务才唤醒它。 pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */ // 调用pthread_create函数创建IO线程,线程运行函数为IOThreadMain if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) { serverLog(LL_WARNING,"Fatal: Can't initialize IO thread."); exit(1); } io_threads[i] = tid; } }Nach dem Login kopierenNach dem Login kopieren🎜1. AcceptTcpHandler wird hauptsächlich zum Herstellen einer Verbindung mit dem Client verwendet. 🎜🎜2 Die Funktion anetTcpAccept wird aufgerufen, um die Verbindung des Clients und ihren Rückgabewert zu akzeptieren ist der Socket, der dem Client entspricht. ;🎜🎜3. Rufen Sie dann AcceptCommonHandler auf, um die Verbindung und den Client zu initialisieren. 🎜🎜4 der readQueryFromClient-Befehl an den Dateideskriptor, der der neuen Verbindung entspricht. 🎜🎜5. Der Server überwacht das Leseereignis des Dateideskriptors und löst das AE_READABLE-Ereignis aus. ) wird aufgerufen, um aus der Dateibeschreibung den im Symbol fd gesendeten Befehl zu lesen und ihn im Eingabepuffer querybuf zu speichern. 🎜// https://github.com/redis/redis/blob/6.2/src/networking.c#L2219 void readQueryFromClient(connection *conn) { client *c = connGetPrivateData(conn); int nread, readlen; size_t qblen; /* Check if we want to read from the client later when exiting from * the event loop. This is the case if threaded I/O is enabled. */ // 判断是否从客户端延迟读取数据 if (postponeClientRead(c)) return; ... } // https://github.com/redis/redis/blob/6.2/src/networking.c#L3746 int postponeClientRead(client *c) { // 当多线程 I/O 模式开启、主线程没有在处理阻塞任务时,将 client 加入异步队列。 if (server.io_threads_active && server.io_threads_do_reads && !ProcessingEventsWhileBlocked && !(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ|CLIENT_BLOCKED))) { // 给客户端的flag添加CLIENT_PENDING_READ标记,表示推迟该客户端的读操作 c->flags |= CLIENT_PENDING_READ; // 将可获得加入clients_pending_write列表 listAddNodeHead(server.clients_pending_read,c); return 1; } else { return 0; } }Nach dem Login kopierenNach dem Login kopierenEmpfang von Befehlen
🎜readQueryFromClient ist der Ausgangspunkt für die Anforderungsverarbeitung, das Parsen und die Ausführung des Anforderungsbefehls des Clients. 🎜🎜1. readQueryFromClient(), liest Daten aus dem Dateideskriptor querybuf; 🎜🎜2. Verwenden Sie die Funktion „processInputBuffer“, um die Befehlsanalyse abzuschließen, wobei „processInlineBuffer“ oder „processMultibulkBuffer“ verwendet wird, um den Befehl zu analysieren Redis-Protokoll; 🎜🎜3. Nachdem Sie die Analyse eines Befehls abgeschlossen haben, führen Sie den Befehl mit 🎜🎜4 aus. Rufen Sie nach Abschluss der Befehlsausführung eine Reihe von Funktionen auf, in die die Antwortdaten geschrieben werden sollen Der Schreibpuffer des entsprechenden Clients: client->buf oder client->reply, client->buf ist der bevorzugte Schreibpuffer mit einer festen Größe von 16 KB. Im Allgemeinen kann er genügend Antwortdaten puffern, aber wenn Der Client muss innerhalb des Zeitfensters antworten. Die Daten sind sehr groß, dann wechselt er automatisch zur verknüpften Liste „Client->Antwort“. Die verknüpfte Liste kann theoretisch unendlich viele Daten speichern (begrenzt durch den physischen Speicher der Maschine). Fügen Sie den Client zu einer LIFO-Warteschlange hinzu Bei einem zeitgesteuerten Ereignis ruft es die Funktion beforeSleep auf, um eine Aufgabenverarbeitung durchzuführen, einschließlich des Aufrufs der Funktion handleClientsWithPendingWrites, die die Daten im// https://github.com/redis/redis/blob/6.2/src/networking.c#L3766 int handleClientsWithPendingReadsUsingThreads(void) { // 当多线程 I/O 模式开启,才能执行下面的流程 if (!server.io_threads_active || !server.io_threads_do_reads) return 0; int processed = listLength(server.clients_pending_read); if (processed == 0) return 0; // 遍历待读取的 client 队列 clients_pending_read, // 根据IO线程的数量,让clients_pending_read中客户端数量对IO线程进行取模运算 // 取模的结果就是客户端分配给对应IO线程的编号 listIter li; listNode *ln; listRewind(server.clients_pending_read,&li); int item_id = 0; while((ln = listNext(&li))) { client *c = listNodeValue(ln); int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; } // 设置当前 I/O 操作为读取操作,给每个 I/O 线程的计数器设置分配的任务数量, // 让 I/O 线程可以开始工作:只读取和解析命令,不执行 io_threads_op = IO_THREADS_OP_READ; for (int j = 1; j < server.io_threads_num; j++) { int count = listLength(io_threads_list[j]); setIOPendingCount(j, count); } // 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。 listRewind(io_threads_list[0],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); readQueryFromClient(c->conn); } listEmpty(io_threads_list[0]); // 忙轮询,等待所有 IO 线程完成待读客户端的处理 while(1) { unsigned long pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += getIOPendingCount(j); if (pending == 0) break; } // 遍历待读取的 client 队列,清除 CLIENT_PENDING_READ标记, // 然后解析并执行所有 client 的命令。 while(listLength(server.clients_pending_read)) { ln = listFirst(server.clients_pending_read); client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_READ; listDelNode(server.clients_pending_read,ln); serverAssert(!(c->flags & CLIENT_BLOCKED)); // client 的第一条命令已经被解析好了,直接尝试执行。 if (processPendingCommandsAndResetClient(c) == C_ERR) { /* If the client is no longer valid, we avoid * processing the client later. So we just go * to the next. */ continue; } // 解析并执行 client 命令 processInputBuffer(c); // 命令执行完成之后,如果 client 中有响应数据需要回写到客户端,则将 client 加入到待写出队列 clients_pending_write if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c)) clientInstallWriteHandler(c); } /* Update processed count on server */ server.stat_io_reads_processed += processed; return processed; }Nach dem Login kopierenNach dem Login kopierenRedis-Server-Clientpuffer zurück zum Client schreibt. 🎜🎜1. Die von der beforeSleep-Funktion aufgerufene Funktion „handleClientsWithPendingWrites“ durchläuft die Warteschlange „clients_pending_write“ (zurückzuschreibende Daten des Clients), ruft „writeToClient“ auf, um die Daten im Schreibpuffer des Clients zurück zum Client zu schreiben, und ruft dann die Funktion „writeToClient“ auf write Die Daten im Client-Ausgabepuffer werden an den Client gesendet;🎜// https://github.com/redis/redis/blob/6.2/src/networking.c#L3662 int handleClientsWithPendingWritesUsingThreads(void) { int processed = listLength(server.clients_pending_write); if (processed == 0) return 0; /* Return ASAP if there are no clients. */ // 如果用户设置的 I/O 线程数等于 1 或者当前 clients_pending_write 队列中待写出的 client // 数量不足 I/O 线程数的两倍,则不用多线程的逻辑,让所有 I/O 线程进入休眠, // 直接在主线程把所有 client 的相应数据回写到客户端。 if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) { return handleClientsWithPendingWrites(); } // 唤醒正在休眠的 I/O 线程(如果有的话)。 if (!server.io_threads_active) startThreadedIO(); /* Distribute the clients across N different lists. */ // 和上面的handleClientsWithPendingReadsUsingThreads中的操作一样分配客户端给IO线程 listIter li; listNode *ln; listRewind(server.clients_pending_write,&li); int item_id = 0; while((ln = listNext(&li))) { client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_WRITE; /* Remove clients from the list of pending writes since * they are going to be closed ASAP. */ if (c->flags & CLIENT_CLOSE_ASAP) { listDelNode(server.clients_pending_write, ln); continue; } int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; } // 设置当前 I/O 操作为写出操作,给每个 I/O 线程的计数器设置分配的任务数量, // 让 I/O 线程可以开始工作,把写出缓冲区(client->buf 或 c->reply)中的响应数据回写到客户端。 // 可以看到写回操作也是多线程执行的 io_threads_op = IO_THREADS_OP_WRITE; for (int j = 1; j < server.io_threads_num; j++) { int count = listLength(io_threads_list[j]); setIOPendingCount(j, count); } // 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。 listRewind(io_threads_list[0],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); writeToClient(c,0); } listEmpty(io_threads_list[0]); /* Wait for all the other threads to end their work. */ // 等待所有的线程完成对应的工作 while(1) { unsigned long pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += getIOPendingCount(j); if (pending == 0) break; } // 最后再遍历一次 clients_pending_write 队列,检查是否还有 client 的写出缓冲区中有残留数据, // 如果有,那就为 client 注册一个命令回复器 sendReplyToClient,等待客户端写就绪再继续把数据回写。 listRewind(server.clients_pending_write,&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); // 检查 client 的写出缓冲区是否还有遗留数据。 if (clientHasPendingReplies(c) && connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR) { freeClientAsync(c); } } listEmpty(server.clients_pending_write); /* Update processed count on server */ server.stat_io_writes_processed += processed; return processed; }Nach dem Login kopierenNach dem Login kopieren2、如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites 函数就会调用 aeCreateFileEvent 函数,注册 sendReplyToClient 到该连接的写就绪事件,等待将后续将数据写回给客户端。
上面的执行流程总结下来就是
1、
Redis Server启动后,主线程会启动一个时间循环(Event Loop),持续监听事件;2、client 到 server 的新连接,会调用 acceptTcpHandler 函数,之后会注册读事件 readQueryFromClient 函数,client 发给 server 的数据,都会在这个函数处理,这个函数会解析 client 的数据,找到对应的 cmd 函数执行;
3、cmd 逻辑执行完成后,server 需要写回数据给 client,调用 addReply 函数族的一系列函数将响应数据写入到对应 client 的写出缓冲区:
client->buf或者client->reply,client->buf是首选的写出缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到client->reply链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把 client 添加进一个 LIFO 队列clients_pending_write;4、在 Redis 事件驱动框架每次循环进入事件处理函数前,来处理监听到的已触发事件或是到时的时间事件之前,都会调用 beforeSleep 函数,进行一些任务处理,这其中就包括了调用 handleClientsWithPendingWrites 函数,它会将 Redis sever 客户端缓冲区中的数据写回客户端;
- beforeSleep 函数调用的 handleClientsWithPendingWrites 函数,会遍历 clients_pending_write(待写回数据的客户端) 队列,调用 writeToClient 把 client 的写出缓冲区里的数据回写到客户端,然后调用 writeToClient 函数,将客户端输出缓冲区中的数据发送给客户端;
- 如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites 函数就会调用 aeCreateFileEvent 函数,注册 sendReplyToClient 到该连接的写就绪事件,等待将后续将数据写回给客户端。
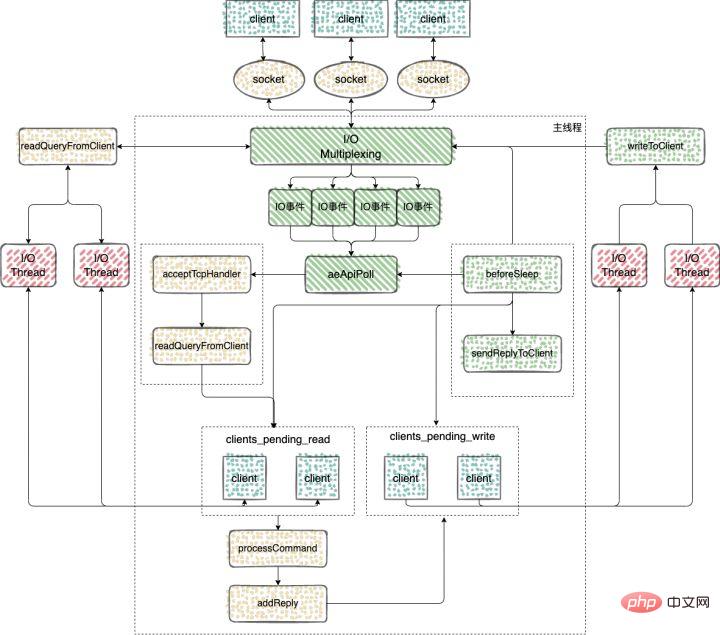
Redis 多IO线程
在 Redis6.0 的版本中,引入了多线程来处理 IO 任务,多线程的引入,充分利用了当前服务器多核特性,使用多核运行多线程,让多线程帮助加速数据读取、命令解析以及数据写回的速度,提升 Redis 整体性能。
Redis6.0 之前的版本用的是单线程 Reactor 模式,所有的操作都在一个线程中完成,6.0 之后的版本使用了主从 Reactor 模式。
由一个 mainReactor 线程接收连接,然后发送给多个 subReactor 线程处理,subReactor 负责处理具体的业务。
来看下 Redis 多IO线程的具体实现过程
多 IO 线程的初始化
使用 initThreadedIO 函数来初始化多 IO 线程。
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3573 void initThreadedIO(void) { server.io_threads_active = 0; /* We start with threads not active. */ /* Don't spawn any thread if the user selected a single thread: * we'll handle I/O directly from the main thread. */ // 如果用户只配置了一个 I/O 线程,不需要创建新线程了,直接在主线程中处理 if (server.io_threads_num == 1) return; if (server.io_threads_num > IO_THREADS_MAX_NUM) { serverLog(LL_WARNING,"Fatal: too many I/O threads configured. " "The maximum number is %d.", IO_THREADS_MAX_NUM); exit(1); } /* Spawn and initialize the I/O threads. */ // 初始化线程 for (int i = 0; i < server.io_threads_num; i++) { /* Things we do for all the threads including the main thread. */ io_threads_list[i] = listCreate(); // 编号为0是主线程 if (i == 0) continue; /* Thread 0 is the main thread. */ /* Things we do only for the additional threads. */ pthread_t tid; // 初始化io_threads_mutex数组 pthread_mutex_init(&io_threads_mutex[i],NULL); // 初始化io_threads_pending数组 setIOPendingCount(i, 0); // 主线程在启动 I/O 线程的时候会默认先锁住它,直到有 I/O 任务才唤醒它。 pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */ // 调用pthread_create函数创建IO线程,线程运行函数为IOThreadMain if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) { serverLog(LL_WARNING,"Fatal: Can't initialize IO thread."); exit(1); } io_threads[i] = tid; } }Nach dem Login kopierenNach dem Login kopieren可以看到在 initThreadedIO 中完成了对下面四个数组的初始化工作
io_threads_list 数组:保存了每个 IO 线程要处理的客户端,将数组每个元素初始化为一个 List 类型的列表;
io_threads_pending 数组:保存等待每个 IO 线程处理的客户端个数;
io_threads_mutex 数组:保存线程互斥锁;
io_threads 数组:保存每个 IO 线程的描述符。
命令的接收
Redis server在和一个客户端建立连接后,就开始了监听客户端的可读事件,处理可读事件的回调函数就是 readQueryFromClient// https://github.com/redis/redis/blob/6.2/src/networking.c#L2219 void readQueryFromClient(connection *conn) { client *c = connGetPrivateData(conn); int nread, readlen; size_t qblen; /* Check if we want to read from the client later when exiting from * the event loop. This is the case if threaded I/O is enabled. */ // 判断是否从客户端延迟读取数据 if (postponeClientRead(c)) return; ... } // https://github.com/redis/redis/blob/6.2/src/networking.c#L3746 int postponeClientRead(client *c) { // 当多线程 I/O 模式开启、主线程没有在处理阻塞任务时,将 client 加入异步队列。 if (server.io_threads_active && server.io_threads_do_reads && !ProcessingEventsWhileBlocked && !(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ|CLIENT_BLOCKED))) { // 给客户端的flag添加CLIENT_PENDING_READ标记,表示推迟该客户端的读操作 c->flags |= CLIENT_PENDING_READ; // 将可获得加入clients_pending_write列表 listAddNodeHead(server.clients_pending_read,c); return 1; } else { return 0; } }Nach dem Login kopierenNach dem Login kopieren使用 clients_pending_read 保存了需要进行延迟读操作的客户端之后,这些客户端又是如何分配给多 IO 线程执行的呢?
handleClientsWithPendingWritesUsingThreads 函数:该函数主要负责将 clients_pending_write 列表中的客户端分配给 IO 线程进行处理。
看下如何实现
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3766 int handleClientsWithPendingReadsUsingThreads(void) { // 当多线程 I/O 模式开启,才能执行下面的流程 if (!server.io_threads_active || !server.io_threads_do_reads) return 0; int processed = listLength(server.clients_pending_read); if (processed == 0) return 0; // 遍历待读取的 client 队列 clients_pending_read, // 根据IO线程的数量,让clients_pending_read中客户端数量对IO线程进行取模运算 // 取模的结果就是客户端分配给对应IO线程的编号 listIter li; listNode *ln; listRewind(server.clients_pending_read,&li); int item_id = 0; while((ln = listNext(&li))) { client *c = listNodeValue(ln); int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; } // 设置当前 I/O 操作为读取操作,给每个 I/O 线程的计数器设置分配的任务数量, // 让 I/O 线程可以开始工作:只读取和解析命令,不执行 io_threads_op = IO_THREADS_OP_READ; for (int j = 1; j < server.io_threads_num; j++) { int count = listLength(io_threads_list[j]); setIOPendingCount(j, count); } // 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。 listRewind(io_threads_list[0],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); readQueryFromClient(c->conn); } listEmpty(io_threads_list[0]); // 忙轮询,等待所有 IO 线程完成待读客户端的处理 while(1) { unsigned long pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += getIOPendingCount(j); if (pending == 0) break; } // 遍历待读取的 client 队列,清除 CLIENT_PENDING_READ标记, // 然后解析并执行所有 client 的命令。 while(listLength(server.clients_pending_read)) { ln = listFirst(server.clients_pending_read); client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_READ; listDelNode(server.clients_pending_read,ln); serverAssert(!(c->flags & CLIENT_BLOCKED)); // client 的第一条命令已经被解析好了,直接尝试执行。 if (processPendingCommandsAndResetClient(c) == C_ERR) { /* If the client is no longer valid, we avoid * processing the client later. So we just go * to the next. */ continue; } // 解析并执行 client 命令 processInputBuffer(c); // 命令执行完成之后,如果 client 中有响应数据需要回写到客户端,则将 client 加入到待写出队列 clients_pending_write if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c)) clientInstallWriteHandler(c); } /* Update processed count on server */ server.stat_io_reads_processed += processed; return processed; }Nach dem Login kopierenNach dem Login kopieren1、当客户端发送命令请求之后,会触发 Redis 主线程的事件循环,命令处理器 readQueryFromClient 被回调,多线程模式下,则会把 client 加入到 clients_pending_read 任务队列中去,后面主线程再分配到 I/O 线程去读取客户端请求命令;
2、主线程会根据 clients_pending_read 中客户端数量对IO线程进行取模运算,取模的结果就是客户端分配给对应IO线程的编号;
3、忙轮询,等待所有的线程完成读取客户端命令的操作,这一步用到了多线程的请求;
4、遍历 clients_pending_read,执行所有 client 的命令,这里就是在主线程中执行的,命令的执行是单线程的操作。
命令的回复
完成命令的读取、解析以及执行之后,客户端命令的响应数据已经存入 client->buf 或者 client->reply 中。
主循环在捕获 IO 事件的时候,beforeSleep 函数会被调用,进而调用 handleClientsWithPendingWritesUsingThreads ,写回响应数据给客户端。
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3662 int handleClientsWithPendingWritesUsingThreads(void) { int processed = listLength(server.clients_pending_write); if (processed == 0) return 0; /* Return ASAP if there are no clients. */ // 如果用户设置的 I/O 线程数等于 1 或者当前 clients_pending_write 队列中待写出的 client // 数量不足 I/O 线程数的两倍,则不用多线程的逻辑,让所有 I/O 线程进入休眠, // 直接在主线程把所有 client 的相应数据回写到客户端。 if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) { return handleClientsWithPendingWrites(); } // 唤醒正在休眠的 I/O 线程(如果有的话)。 if (!server.io_threads_active) startThreadedIO(); /* Distribute the clients across N different lists. */ // 和上面的handleClientsWithPendingReadsUsingThreads中的操作一样分配客户端给IO线程 listIter li; listNode *ln; listRewind(server.clients_pending_write,&li); int item_id = 0; while((ln = listNext(&li))) { client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_WRITE; /* Remove clients from the list of pending writes since * they are going to be closed ASAP. */ if (c->flags & CLIENT_CLOSE_ASAP) { listDelNode(server.clients_pending_write, ln); continue; } int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; } // 设置当前 I/O 操作为写出操作,给每个 I/O 线程的计数器设置分配的任务数量, // 让 I/O 线程可以开始工作,把写出缓冲区(client->buf 或 c->reply)中的响应数据回写到客户端。 // 可以看到写回操作也是多线程执行的 io_threads_op = IO_THREADS_OP_WRITE; for (int j = 1; j < server.io_threads_num; j++) { int count = listLength(io_threads_list[j]); setIOPendingCount(j, count); } // 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。 listRewind(io_threads_list[0],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); writeToClient(c,0); } listEmpty(io_threads_list[0]); /* Wait for all the other threads to end their work. */ // 等待所有的线程完成对应的工作 while(1) { unsigned long pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += getIOPendingCount(j); if (pending == 0) break; } // 最后再遍历一次 clients_pending_write 队列,检查是否还有 client 的写出缓冲区中有残留数据, // 如果有,那就为 client 注册一个命令回复器 sendReplyToClient,等待客户端写就绪再继续把数据回写。 listRewind(server.clients_pending_write,&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); // 检查 client 的写出缓冲区是否还有遗留数据。 if (clientHasPendingReplies(c) && connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR) { freeClientAsync(c); } } listEmpty(server.clients_pending_write); /* Update processed count on server */ server.stat_io_writes_processed += processed; return processed; }Nach dem Login kopierenNach dem Login kopieren1、也是会将 client 分配给所有的 IO 线程;
2、忙轮询,等待所有的线程将缓存中的数据写回给客户端,这里写回操作使用的多线程;
3、最后再遍历 clients_pending_write,为那些还残留有响应数据的 client 注册命令回复处理器 sendReplyToClient,等待客户端可写之后在事件循环中继续回写残余的响应数据。
通过上面的分析可以得出结论,Redis 多IO线程中多线程的应用
1、解析客户端的命令的时候用到了多线程,但是对于客户端命令的执行,使用的还是单线程;
2、给客户端回复数据的时候,使用到了多线程。
来总结下 Redis 中多线程的执行过程
1、Redis Server 启动后,主线程会启动一个时间循环(Event Loop),持续监听事件;
2、client 到 server 的新连接,会调用 acceptTcpHandler 函数,之后会注册读事件 readQueryFromClient 函数,client 发给 server 的数据,都会在这个函数处理;
3、客户端发送给服务端的数据,不会类似 6.0 之前的版本使用 socket 直接去读,而是会将 client 放入到 clients_pending_read 中,里面保存了需要进行延迟读操作的客户端;
4、处理 clients_pending_read 的函数 handleClientsWithPendingReadsUsingThreads,在每次事件循环的时候都会调用;
- 1、主线程会根据 clients_pending_read 中客户端数量对IO线程进行取模运算,取模的结果就是客户端分配给对应IO线程的编号;
- 2、忙轮询,等待所有的线程完成读取客户端命令的操作,这一步用到了多线程的请求;
- 3、遍历 clients_pending_read,执行所有 client 的命令,这里就是在主线程中执行的,命令的执行是单线程的操作。
5、命令执行完成以后,回复的内容还是会被写入到 client 的缓存区中,这些 client 和6.0之前的版本处理方式一样,也是会被放入到 clients_pending_write(待写回数据的客户端);
6、6.0 对于clients_pending_write 的处理使用到了多线程;
- 1、也是会将 client 分配给所有的 IO 线程;
- 2、忙轮询,等待所有的线程将缓存中的数据写回给客户端,这里写回操作使用的多线程;
- 3、最后再遍历 clients_pending_write,为那些还残留有响应数据的 client 注册命令回复处理器 sendReplyToClient,等待客户端可写之后在事件循环中继续回写残余的响应数据。
原子性的单命令
通过上面的分析,我们知道,Redis 的主线程是单线程执行的,所有 Redis 中的单命令,都是原子性的。
所以对于一些场景的操作尽量去使用 Redis 中单命令去完成,就能保证命令执行的原子性。
比如对于上面的
读取-修改-写回操作可以使用 Redis 中的原子计数器, INCRBY(自增)、DECRBR(自减)、INCR(加1) 和 DECR(减1) 等命令。这些命令可以直接帮助我们处理并发控制
127.0.0.1:6379> incr test-1 (integer) 1 127.0.0.1:6379> incr test-1 (integer) 2 127.0.0.1:6379> incr test-1 (integer) 3
Nach dem Login kopieren分析下源码,看看这个命令是如何实现的
// https://github.com/redis/redis/blob/6.2/src/t_string.c#L617 void incrCommand(client *c) { incrDecrCommand(c,1); } void decrCommand(client *c) { incrDecrCommand(c,-1); } void incrbyCommand(client *c) { long long incr; if (getLongLongFromObjectOrReply(c, c->argv[2], &incr, NULL) != C_OK) return; incrDecrCommand(c,incr); } void decrbyCommand(client *c) { long long incr; if (getLongLongFromObjectOrReply(c, c->argv[2], &incr, NULL) != C_OK) return; incrDecrCommand(c,-incr); }Nach dem Login kopieren可以看到 INCRBY(自增)、DECRBR(自减)、INCR(加1) 和 DECR(减1)这几个命令最终都是调用的 incrDecrCommand
// https://github.com/redis/redis/blob/6.2/src/t_string.c#L579 void incrDecrCommand(client *c, long long incr) { long long value, oldvalue; robj *o, *new; // 查找有没有对应的键值 o = lookupKeyWrite(c->db,c->argv[1]); // 判断类型,如果value对象不是字符串类型,直接返回 if (checkType(c,o,OBJ_STRING)) return; // 将字符串类型的value转换为longlong类型保存在value中 if (getLongLongFromObjectOrReply(c,o,&value,NULL) != C_OK) return; // 备份旧的value oldvalue = value; // 判断 incr 的值是否超过longlong类型所能表示的范围 // 长度的范围,十进制 64 位有符号整数 if ((incr < 0 && oldvalue < 0 && incr < (LLONG_MIN-oldvalue)) || (incr > 0 && oldvalue > 0 && incr > (LLONG_MAX-oldvalue))) { addReplyError(c,"increment or decrement would overflow"); return; } // 计算新的 value值 value += incr; if (o && o->refcount == 1 && o->encoding == OBJ_ENCODING_INT && (value < 0 || value >= OBJ_SHARED_INTEGERS) && value >= LONG_MIN && value <= LONG_MAX) { new = o; o->ptr = (void*)((long)value); } else { new = createStringObjectFromLongLongForValue(value); // 如果之前的 value 对象存在 if (o) { // 重写为 new 的值 dbOverwrite(c->db,c->argv[1],new); } else { // 如果之前没有对应的 value,新设置 value 的值 dbAdd(c->db,c->argv[1],new); } } // 进行通知 signalModifiedKey(c,c->db,c->argv[1]); notifyKeyspaceEvent(NOTIFY_STRING,"incrby",c->argv[1],c->db->id); server.dirty++; addReply(c,shared.colon); addReply(c,new); addReply(c,shared.crlf); }Nach dem Login kopieren总结
1、Redis 中的命令执行都是单线程的,所以单命令的执行都是原子性的;
2、虽然 Redis6.0 版本引入了多线程,但是仅是在接收客户端的命令和回复客户端的数据用到了多线程,实际命令的执行还是单线程在处理;
推荐学习:Redis视频教程

Das obige ist der detaillierte Inhalt vonDetaillierte Analyse der Atomizität von Befehlen in Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So lösen Sie Datenverlust mit Redis
Apr 10, 2025 pm 08:24 PM
So lösen Sie Datenverlust mit Redis
Apr 10, 2025 pm 08:24 PM
Zu den Ursachen für Datenverluste gehören Speicherausfälle, Stromausfälle, menschliche Fehler und Hardwarefehler. Die Lösungen sind: 1. Speichern Sie Daten auf Festplatten mit RDB oder AOF Persistenz; 2. Kopieren Sie auf mehrere Server, um eine hohe Verfügbarkeit zu erhalten. 3. Ha mit Redis Sentinel oder Redis Cluster; 4. Erstellen Sie Schnappschüsse, um Daten zu sichern. 5. Implementieren Sie Best Practices wie Persistenz, Replikation, Schnappschüsse, Überwachung und Sicherheitsmaßnahmen.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
