

Ausgewählte und zusammengefasste 15 MySQL-Optimierungsprobleme

Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL, in dem hauptsächlich Probleme im Zusammenhang mit der SQL-Optimierung vorgestellt werden, einschließlich der Fehlerbehebung bei SQL-Anweisungen während des Entwicklungsprozesses, der Fehlerbehebung bei SQL-Problemen in der Produktionsumgebung usw. Werfen wir einen Blick darauf Wenn ich es zusammenstelle, hoffe ich, dass es für alle hilfreich sein wird.

Empfohlenes Lernen: MySQL-Video-Tutorial
Wie behebt man SQL-Fehler während des Entwicklungsprozesses?
Ideen zur Fehlerbehebung
Für die meisten Programmierer ist die Fehlerbehebung bei SQL während des Entwicklungsprozesses im Grunde genommen leer. Mit der Weiterentwicklung der Branche wird dem Entwicklungsprozess jedoch immer mehr Aufmerksamkeit und Professionalität geschenkt. Eine davon besteht darin, SQL-Probleme so weit wie möglich während des Entwicklungsprozesses zu lösen, um zu vermeiden, dass SQL-Probleme während der Produktion aufgedeckt werden. Wie kann man also während des Entwicklungsprozesses bequem eine SQL-Fehlerbehebung für das Programm durchführen?
Die Idee besteht immer noch darin, das langsame Protokoll von MySQL zu verwenden, um Folgendes zu erreichen:
-
Zunächst müssen Sie während des Entwicklungsprozesses auch die langsame Abfrage der MySQL-Datenbank aktivieren
SET GLOBAL slow_query_log='on';
Nach dem Login kopierenNach dem Login kopieren -
Zweitens die Mindestzeit festlegen langsames SQL
Hinweis: Hier ist die Zeiteinheit s Sekunden, hat aber 6 Dezimalstellen, sodass die SQL-Ausführungszeit einer einzelnen Tabelle im Allgemeinen innerhalb von 20 ms liegt Wenn die von Ihnen ausgeführte SQL-Anweisung während des Entwicklungsprozesses 20 ms überschreitet, müssen Sie darauf achten.
SET GLOBAL long_query_time=0.02;
Nach dem Login kopierenNach dem Login kopieren -
Zur Vereinfachung des Betriebs kann langsames SQL in einer Tabelle statt in einer Datei aufgezeichnet werden.
SET GLOBAL log_output='TABLE';
Nach dem Login kopieren Schließlich kann das aufgezeichnete langsame SQL über die Tabelle mysql.slow_log abgefragt werden
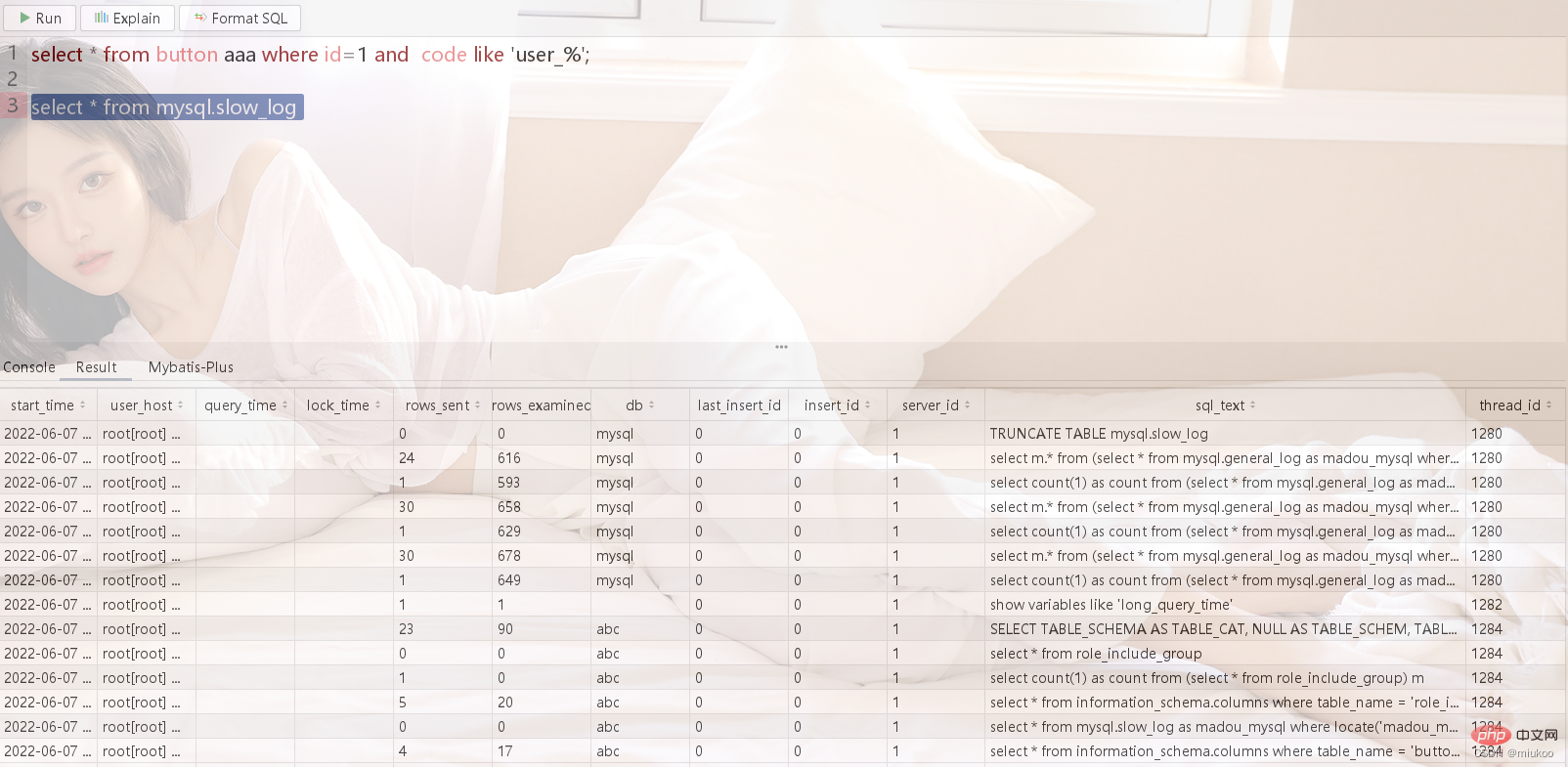 In der von Bruder Yong für Sie entwickelten Software steht auch eine grafische Oberfläche zur Verfügung, mit deren Hilfe Sie die oben genannten Funktionen schnell mit einem Klick implementieren können.
In der von Bruder Yong für Sie entwickelten Software steht auch eine grafische Oberfläche zur Verfügung, mit deren Hilfe Sie die oben genannten Funktionen schnell mit einem Klick implementieren können.
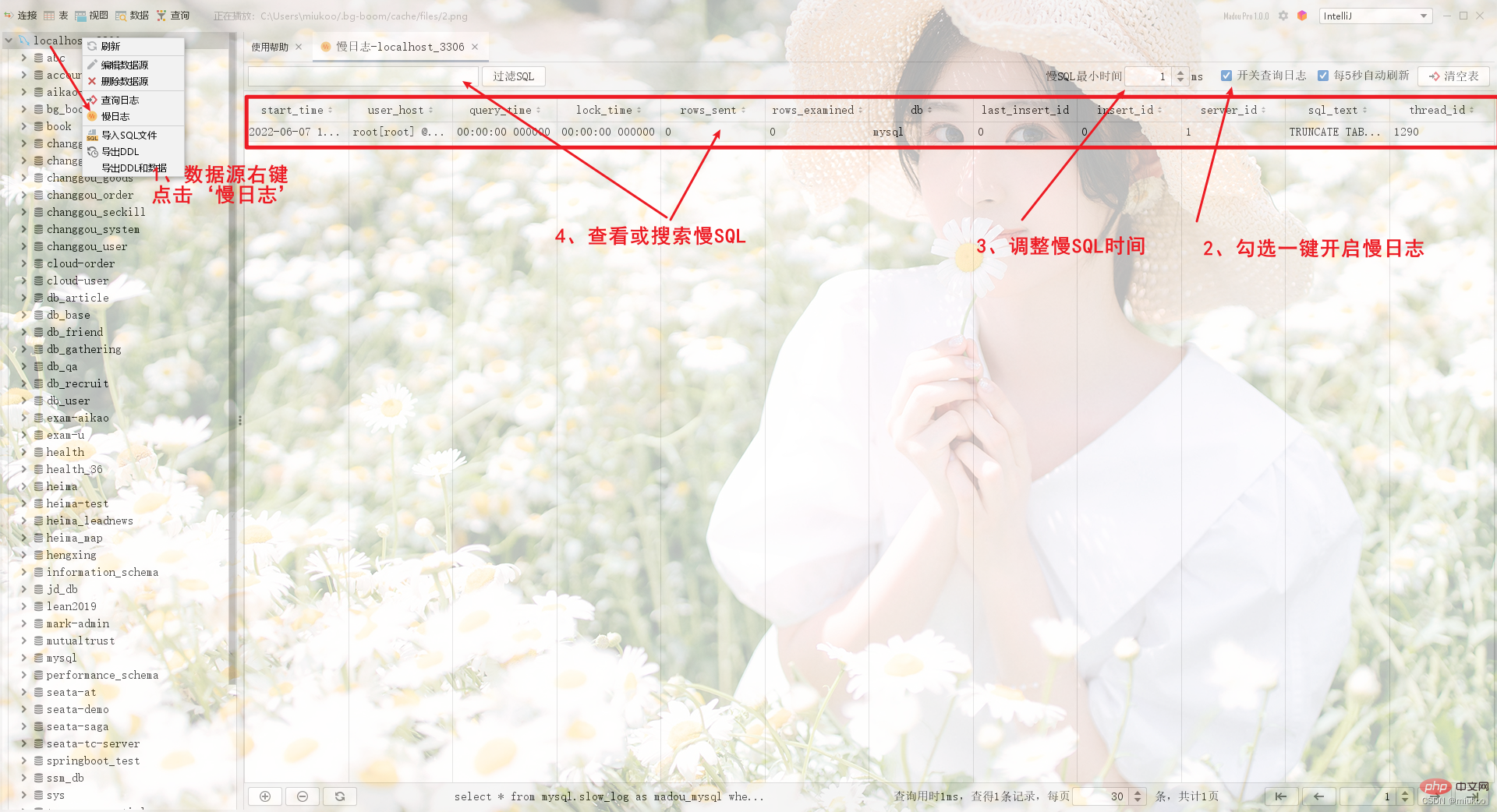 Ideen zur Fehlerbehebung
Ideen zur Fehlerbehebung
Die Fehlerbehebung bei generierten SQL-Problemen ist etwas komplizierter, aber die Gesamtidee besteht darin, Fehler durch langsames SQL zu beheben. Die konkreten Ideen lauten wie folgt:
Aktivieren Sie zunächst die langsame Abfrage der Datenbank Mysql
SET GLOBAL slow_query_log='on';
Stellen Sie zweitens die Einstellungen ein. Die Mindestzeit für langsames SQL der Datenbank Mysql
- Achten Sie auf: Es ist am besten, langsames SQL während der Produktion zu öffnen und nach der Verwendung zu schließen, um zu vermeiden, dass die Protokollierung die Geschäftsleistung beeinträchtigt
-
SET GLOBAL long_query_time=0.02;
Nach dem Login kopierenNach dem Login kopieren Wie optimiert man SQL?
- SQL-Tuning integriert mehrere Aspekte des Wissens Im Allgemeinen ist es üblich, unter zwei Gesichtspunkten zu optimieren: Tabellenstruktur und Tabellenindex.
Optimierung der Tabellenstruktur
1. Angemessene Verwendung von Feldklassen und -längenEin Beispiel zum Verständnis: Für ein Geschlechtsfeld belegt der Speicher von tinyint(1) 1 Byte und der Speicher von int(1) 4 Bytes, falls vorhanden Wenn es 1 Million Datensätze gibt, ist die Dateigröße der in int gespeicherten Tabelle etwa 2,8 MB größer als die der in tinyint gespeicherten Tabelle. Daher ist die Datei beim Lesen der im int-Typ gespeicherten Tabelle größer und die Lesegeschwindigkeit langsamer als das Lesen von tinyint. Dies ist tatsächlich der Kern dessen, warum es notwendig ist, Feldtyplängen vernünftig zu verwenden: Es geht darum, die Größe der gespeicherten Dateien zu reduzieren, um eine Leseleistung zu gewährleisten .
Natürlich sagen einige Freunde vielleicht, dass 2,8 Mio. keinen Einfluss auf die Gesamtsituation haben und daher ignoriert werden können. Bruder Yong möchte dieser Idee noch etwas hinzufügen: Angenommen, eine Tabelle hat 10 Felder und Ihr System verfügt über insgesamt 30 Tabellen. Dann werfen wir einen Blick auf die zusätzliche Dateigröße. (2,8Mx10x30=840M, das Herunterladen von 840M dauert mit Thunder Super. Diese Zeit wird im Computer als sehr langsam angesehen...)
2. Angemessener Einsatz von redundantem Design
2.1 TabelleIn MySQL gibt es eine spezielle und leichte temporäre Tabelle, die von MySQL automatisch erstellt und gelöscht wird. Temporäre Tabellen werden hauptsächlich während der Ausführung von SQL verwendet, um die Zwischenergebnisse bestimmter Vorgänge zu speichern. Dieser Vorgang wird von MySQL automatisch abgeschlossen, und Benutzer können nicht manuell eingreifen, und diese interne Tabelle ist für Benutzer unsichtbar.
Interne temporäre Tabellen sind im Optimierungsprozess von SQL-Anweisungen sehr wichtig. Viele Vorgänge in MySQL sind für Optimierungsvorgänge auf interne temporäre Tabellen angewiesen. Die Verwendung interner temporärer Tabellen erfordert jedoch Kosten für die Erstellung von Tabellen und den Zugriff auf Zwischendaten. Daher sollten Sie beim Schreiben von SQL-Anweisungen versuchen, die Verwendung temporärer Tabellen zu vermeiden
.Wird MySQL in diesen Szenarien intern temporäre Tabellen verwenden?
Bei einer auf mehrere Tabellen bezogenen Abfrage (JOIN) ist die von „Ordnung nach“ oder „Gruppierung nach“ verwendete Spalte keine Spalte der ersten Tabelle Indexspalte
Distinct und Group by werden zusammen verwendet
Die Order by-Anweisung verwendet das eindeutige Schlüsselwort
Group by-Spalten sind Indexspalten, aber wenn die Datenmenge zu groß ist
2.2 Vorgehensweise Überprüfen Sie, ob eine interne temporäre Tabelle verwendet wird.
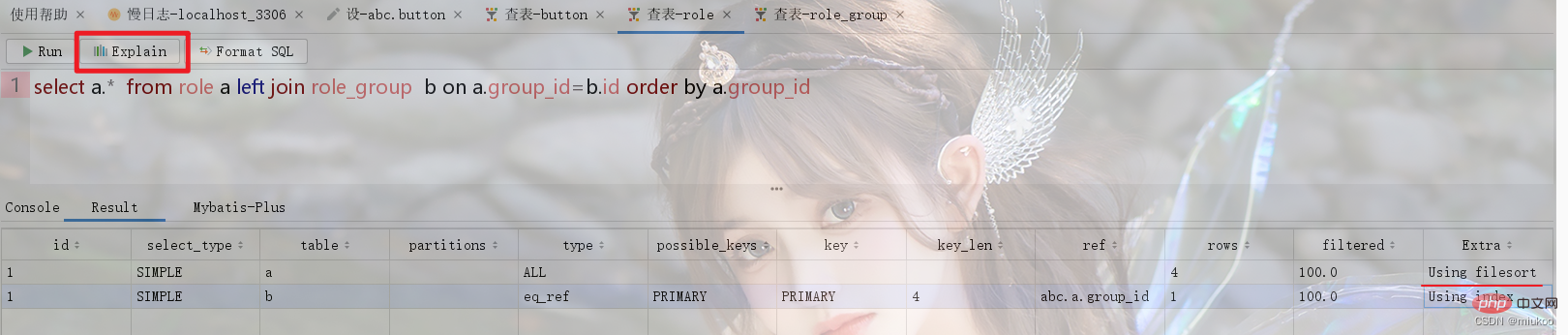
Verwenden Sie das Schlüsselwort „Explain“ oder die Funktionsschaltfläche des Tools, um den Ausführungsprozess von SQL anzuzeigen. Wenn das Schlüsselwort „Using temporary“ in der Spalte „Extra“ im Ergebnis angezeigt wird, bedeutet dies, dass Ihre SQL-Anweisung bei der Ausführung eine temporäre Tabelle verwendet.
Wie in der Abbildung unten gezeigt, besteht zwischen der Rollentabelle und der Rollengruppe Role_Group eine Viele-zu-Eins-Beziehung. Bei der Durchführung verwandter Abfragen wird die temporäre Tabelle zum Sortieren anhand der ID von Role_Group verwendet (siehe Abbildung 1 unten). . Wenn die Sortierung die ID der Rolle verwendet, werden temporäre Tabellen nicht verwendet (siehe Abbildung 2).
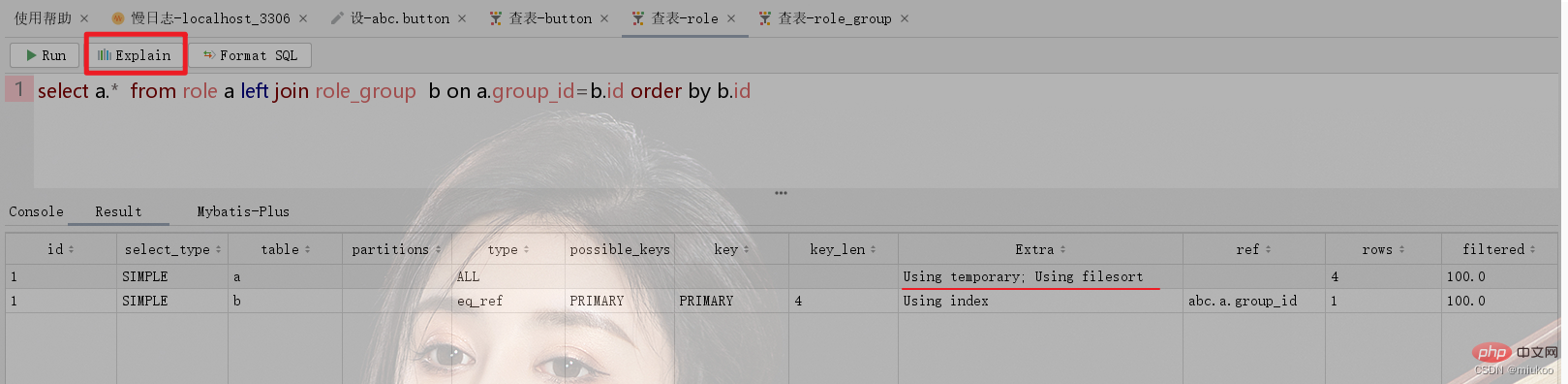
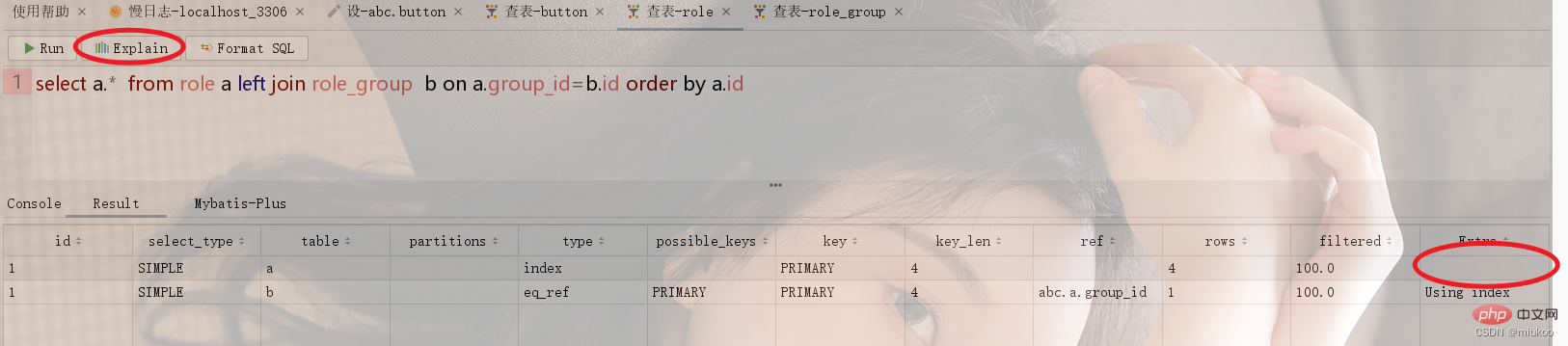
2.3 Wie kann das Problem gelöst werden, dass keine internen temporären Tabellen verwendet werden?
Es gibt zwei Lösungen für dieses Problem: Die eine besteht darin, die SQL-Anweisung so anzupassen, dass die Verwendung temporärer Tabellen vermieden wird, und die andere darin, sie redundant in der Tabelle zu speichern. Wenn Sie beispielsweise im Beispiel von Abbildung 1 in 2.2 nach der ID von „role_group“ sortieren müssen, können Sie nach „group_id“ in der Rollentabelle sortieren, und diese Spalte ist der ID-Spaltenwert in der Tabelle „role_group“, der redundant ist gelagert.
3. Sinnvolle Verwendung von Unterdatenbanken und Untertabellen
Unterdatenbanken und Untertabellen werden nicht nur zur Optimierung in großen Mengen verwendet, sondern vertikale Untertabellen können auch für die SQL-Optimierung verwendet werden. (Ich werde die vertikalen und horizontalen Untertabellen hier nicht erklären. Wenn Sie interessiert sind, senden Sie mir bitte eine private Nachricht)
Zum Beispiel: Das allgemeine Design einer Artikeltabelle umfasst nicht das große Feld des Artikelinhalts.

Das große Feld des Artikelinhalts wird in einer separaten Tabelle platziert

Warum übernimmt die Artikeltabelle das obige Design, anstatt die Felder in einer Tabelle zusammenzuführen?
Nehmen wir zunächst an, dass ein Artikel 1 Million groß ist, der Artikelinhalt 824 KB beträgt und die restlichen Felder 200 KB groß sind, dann:
Option 1, wenn eine Tabelle als Speicher verwendet wird, beträgt die Tabellengröße 100 W * 1 M = 100 W Haben Sie jeweils zwei Artikellisten und Artikeldetails auf der Startseite, um relevante Inhalte direkt aus der Datenbank abzufragen, dann:
Plan 1, die Artikelliste und Artikeldetails werden aus 100WM-Daten abgefragt
Plan 2, die Artikelliste wird ab 200 KB x 100 W abgefragt, Artikeldetails werden ab 824 KB x 100 W abgefragt (derzeit müssen Sie möglicherweise auch ab 200 KB x 100 W abfragen)
Trotzdem glaube ich, dass jeder eine klare Antwort im Kopf haben sollte!
Durch die vertikale Tabellenaufteilung können in verschiedenen Geschäftsszenarien unterschiedliche Datenmengen abgefragt werden. Oft ist diese Datenmenge kleiner als die Gesamtdatenmenge der Tabelle, was flexibler und effizienter ist als die Abfrage einer festen großen oder kleinen Menge. - Optimierung von Tabellenindizes
1. Indexspalten angemessen hinzufügenDie meisten Leute verstehen unter Indizes „Indizes können Abfragen beschleunigen“, aber Bruder Yong muss die zweite Hälfte dieses Satzes hinzufügen „Indizes können schneller werden.“ Abfragen oder verlangsamen das Einfügen oder Ändern von Daten“
.
Wenn eine Tabelle 5 Indizes hat, können Sie einen Index einfach als Tabelle betrachten. Dann gibt es 1 Tabelle + 6 Indextabellen = entsprechend 6 Tabellen. Wann sind diese 6 Tabellen? Kann es funktionieren? Berechnen wir es:
Einfügevorgang: Nachdem die Daten eingefügt wurden, müssen Sie Indexdaten in 5 Indextabellen einfügen.
Löschvorgang: Nachdem die Daten gelöscht wurden, müssen Sie die Indizes in 5 Indextabellen löschen
- Aktualisierungsvorgang
- Wenn die Daten in der Indexspalte geändert werden, müssen zuerst die Daten geändert werden, und der Index in der Indextabelle muss ebenfalls geändert werden
- Wenn die Daten in der Indexspalte nicht geändert werden Es muss nur die Datentabelle geändert werden. Überprüfen Sie die Datentabelle direkt
-
Durch die obigen Berechnungen werden Sie wie durch ein Wunder feststellen, dass sich dies negativ auf Einfüge-, Lösch- und Aktualisierungsvorgänge auswirkt, je mehr Indizes wir haben
. Daher ist es möglich zu beurteilen, dass die Auswirkung des Index geringer ist als der Nutzen der Abfrage, und ihn dann hinzuzufügen, anstatt ihn blind hinzuzufügen
.
2、合理的调配复合索引列个数和顺序
复合索引指的是包括有多个列的索引,它能有效的减少表的索引个数,平衡了多个字段需要多个索引直接的性能平衡,但是再使用复合索引的时候,需要注意索引列个数和顺序的问题。
先说列个数的问题,指的是一个复合索引中包括的列字段太多影响性能的问题,主要是对update操作的性能影响,如下红字:
如果修改了索引列的数据,则先修改数据,还需要修改索引表中的索引,如果索引列个数越多则修改该索引的概率越大
如果没有修改索引列的数据,则只修改数据表
再说复合索引中列顺序的问题,是指索引的最左匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,这个比较容易理解,就不多做阐述。
那些情况索引会失效?
索引无法存储null值,当使用is null或is not nulli时会全表扫描
like查询以"%"开头
对于复合索引,查询条件中没有给出索引中第一列的值时
mysql内部评估全表扫描比索引快时
or、!=、<>、in、not in等查询也可能引起索引失效
表设计有那些规范?
建表规约
表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型为
unsigned tinyint。 说明:任何字段如果为非负数,则必须是 unsigned。-
字段允许适当冗余,以提高查询性能,但必须考虑数据一致。e.g. 商品类目名称使用频率高,字段长度短,名称基本一成不变,可在相关联的表中冗余存储类目名称,
避免关联查询
。冗余字段遵循:
不是频繁修改的字段;
不是 varchar 超长字段,更不能是 text 字段。
索引规约
在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度即可。
页面搜索严禁左模糊或者全模糊,如果需要请通过搜索引擎来解决。 说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
-
如果有 order by 的场景,请注意利用索引的有序性。order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort 的情况,影响查询性能。
正例:where a=? and b=? order by c; 索引: a_b_c。
反例:索引中有范围查找,那么索引有序性无法利用,如 WHERE a>10 ORDER BY b; 索引 a_b 无法排序。
利用延迟关联或者子查询优化超多分页场景。 说明:MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 的行,返回 N 行。当 offset 特别大的时候,效率会非常的低下,要么控制返回的总页数,要么对超过阈值的页数进行 SQL 改写。
建组合索引的时候,区分度最高的在最左边。
SQL 性能优化的目标,至少要达到 range 级别,要求是 ref 级别,最好是 consts。
SQL 语句
不要使用 count(列名) 或 count(常量) 来替代 count(),count() 是 SQL92 定义的标准统计行数的语句,跟数据库无关,跟 NULL 和非 NULL 无关。 说明:count(*) 会统计值为 NULL 的行,而 count(列名) 不会统计此列为 NULL 值的行。
count(distinct column)计算该列除 NULL 外的不重复行数。注意,count(distinct column1,column2)如果其中一列全为 NULL,那么即使另一列用不同的值,也返回为 0。当某一列的值全为 NULL 时,
count(column)的返回结果为 0,但sum(column)的返回结果为 NULL,因此使用 sum() 时需注意 NPE 问题。 可以使用如下方式来避免 sum 的 NPE 问题。
SELECT IF(ISNULL(SUM(g), 0, SUM(g))) FROM table;
Nach dem Login kopieren使用
ISNULL()来判断是否为 NULL 值。 说明:NULL 与任何值的直接比较都为 NULL。Fremdschlüssel und Kaskaden sind nicht zulässig. Alle Fremdschlüsselkonzepte müssen auf der Anwendungsebene gelöst werden. Erklärung: Nehmen Sie als Beispiel die Beziehung zwischen Schülern und Noten. Die student_id der Schülertabelle ist der Primärschlüssel und die student_id der Notentabelle ist der Fremdschlüssel. Wenn die student_id in der Schülertabelle aktualisiert wird und gleichzeitig die student_id in der Notentabelle aktualisiert wird, handelt es sich um eine Kaskadenaktualisierung. Fremdschlüssel und Kaskadenaktualisierungen eignen sich für eine geringe Parallelität auf einem einzelnen Computer, sind jedoch nicht für verteilte Cluster mit hoher Parallelität geeignet; Kaskadenaktualisierungen sind stark blockierend und bergen das Risiko, dass Datenbankaktualisierungsstürme die Einfügungsgeschwindigkeit der Datenbank beeinträchtigen .
Die Verwendung gespeicherter Prozeduren ist verboten. Gespeicherte Prozeduren lassen sich nur schwer debuggen und erweitern und sind nicht portierbar.
inOperationen sollten nach Möglichkeit vermieden werden. Wenn dies nicht vermieden werden kann, müssen Sie die Anzahl der Sammlungselemente nach in sorgfältig bewerten und sie innerhalb von 1000 kontrollieren.in操作能避免则避免。若实在避免不了,需要仔细评估 in 后面的集合元素数量,控制在 1000 个之内。
ORM 映射
POJO 类的布尔属性不能加 is,而数据库字段必须加 is_,要求在 resultMap 中进行字段与属性的映射。
sql.xml配置参数使用:#{}, #param#,不要使用 ${},此种方式容易出现 SQL 注入。@Transactional
ORM-Zuordnung
Die booleschen Attribute der POJO-Klasse können nicht mit is hinzugefügt werden, aber die Datenbankfelder müssen mit is_ hinzugefügt werden, was eine Zuordnung von Feldern und Attributen in resultMap erfordert.
🎜sql.xmlKonfigurationsparameter verwenden:#{}, #param#, verwenden Sie nicht ${}, diese Methode ist anfällig für SQL-Injection. 🎜🎜🎜🎜@TransactionalMissbrauchen Sie Transaktionen nicht. Transaktionen wirken sich auf die QPS der Datenbank aus. Darüber hinaus müssen bei der Verwendung von Transaktionen verschiedene Aspekte von Rollback-Lösungen berücksichtigt werden, darunter Cache-Rollback, Suchmaschinen-Rollback, Nachrichtenkompensation, statistische Korrektur usw. 🎜🎜🎜🎜Empfohlenes Lernen: 🎜MySQL-Video-Tutorial🎜🎜
Das obige ist der detaillierte Inhalt vonAusgewählte und zusammengefasste 15 MySQL-Optimierungsprobleme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 So installieren Sie MySQL in CentOS7
Apr 14, 2025 pm 08:30 PM
So installieren Sie MySQL in CentOS7
Apr 14, 2025 pm 08:30 PM
Der Schlüssel zur eleganten Installation von MySQL liegt darin, das offizielle MySQL -Repository hinzuzufügen. Die spezifischen Schritte sind wie folgt: Laden Sie den offiziellen GPG -Schlüssel von MySQL herunter, um Phishing -Angriffe zu verhindern. Add MySQL repository file: rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm Update yum repository cache: yum update installation MySQL: yum install mysql-server startup MySQL service: systemctl start mysqld set up booting
