
Dieser Artikel bringt Ihnen relevantes Wissen über Redis, in dem hauptsächlich Fragen im Zusammenhang mit der Persistenz vorgestellt werden, einschließlich der Frage, warum Persistenz erforderlich ist, RDB-Persistenz, AOF-Persistenz usw. Schauen wir uns das gemeinsam an. Ich hoffe, es hilft allen.

Empfohlenes Lernen: Redis-Video-Tutorial
Redis verarbeitet Daten basierend auf dem Speicher. Wenn unerwartete Situationen wie Prozessabbrüche und Serverausfälle auftreten und kein Persistenzmechanismus vorhanden ist, gehen die Daten in Redis verloren und können nicht wiederhergestellt werden. Mit dem Persistenzmechanismus kann Redis beim nächsten Neustart zuvor persistente Dateien zur Datenwiederherstellung verwenden. Zwei von Redis unterstützte Persistenzmechanismen:
RDB: Erstellt einen Snapshot der aktuellen Daten und speichert ihn auf der Festplatte.
AOF: Zeichnen Sie jeden Datenvorgang auf der Festplatte auf.
schreibt den Snapshot des Datensatzes im Speicher innerhalb des angegebenen Zeitintervalls auf die Festplatte. Bei der Wiederherstellung wird die Snapshot-Datei direkt in den Speicher eingelesen. Bei der RDB-Persistenz (Redis DataBase) wird ein Snapshot aller aktuellen Daten in Redis erstellt und auf der Festplatte gespeichert. Die RDB-Persistenz kann manuell oder automatisch ausgelöst werden.
redis erstellt (Fork) einen separaten Unterprozess für die Persistenz. Er schreibt die Daten zunächst in eine temporäre Datei. Nach Abschluss des Persistenzprozesses wird diese temporäre Datei verwendet, um die letzte persistente Datei zu ersetzen. Während des gesamten Prozesses führt der Hauptprozess keine IO-Operationen aus, was eine extrem hohe Leistung gewährleistet. Wenn eine groß angelegte Datenwiederherstellung erforderlich ist und die Integrität der Datenwiederherstellung nicht sehr empfindlich ist, ist die RDB-Methode effizienter als die AOF-Methode. Der Nachteil von RDB besteht darin, dass die zuletzt gespeicherten Daten verloren gehen können.
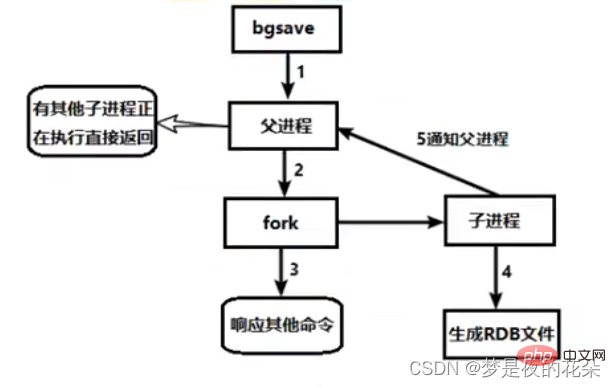
Sowohl die Befehle save als auch bgsave können die RDB-Persistenz manuell auslösen. save和 bgsave命令都可以手动触发RDB持久化。
savesave命令会手动触发RDB持久化,但是save命令会阻塞Redis服务,直到RDB持久化完成。当Redis服务储存大量数据时,会造成较长时间的阻塞,不建议使用。bgsavebgsave命令也会手动触发RDB持久化,和save命令不同是:Redis服务一般不会阻塞。Redis进程会执行fork操作创建子进程,RDB持久化由子进程负责,不会阻塞Redis服务进程。Redis服务的阻塞只发生在fork阶段,一般情况时间很短。bgsave命令的具体流程如下图: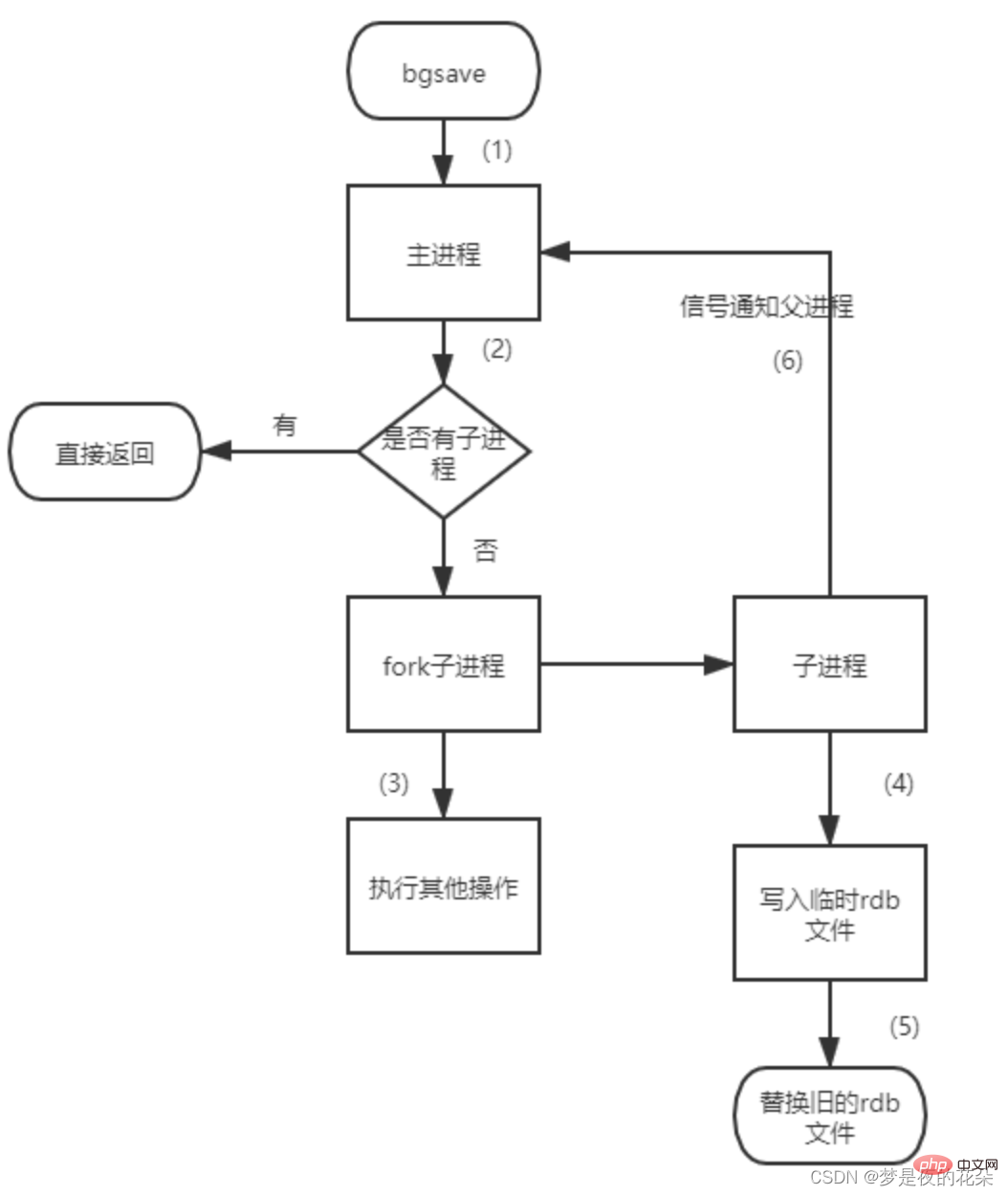
bgsave命令,Redis进程先判断当前是否存在正在执行的RDB或AOF子线程,如果存在就是直接结束。bgsave命令就结束了,自此Redis进程不会被阻塞,可以响应其他命令。除了执行以上命令手动触发以外,Redis内部可以自动触发RDB持久化。自动触发的RDB持久化都是采用bgsave的方式,减少Redis进程的阻塞。那么,在什么场景下会自动触发呢?
save的相关配置,如sava m n,它表示在m秒内数据被修改过n次时,自动触发bgsave操作。bgsave操作,并且把生成的RDB文件发送给从节点。debug reload命令时,也会自动触发bgsave操作。shutdown命令时,如果没有开启AOF持久化也会自动触发bgsave
save Durch Ausführen des Befehls save wird die RDB-Persistenz manuell ausgelöst, aber der Befehl save blockiert Redis Serve, bis die RDB-Persistenz abgeschlossen ist. Wenn der Redis-Dienst große Datenmengen speichert, führt dies zu einer langfristigen Überlastung und wird nicht empfohlen.
bgsave🎜🎜 Das Ausführen des Befehls bgsave löst auch manuell die RDB-Persistenz aus. Anders als beim Befehl save: der Redis-Dienst im Allgemeinen wird nicht blockiert. Der Redis-Prozess führt einen Fork-Vorgang aus, um einen untergeordneten Prozess zu erstellen. Der untergeordnete Prozess ist für die RDB-Persistenz verantwortlich und blockiert den Redis-Dienstprozess nicht. Die Blockierung des Redis-Dienstes erfolgt nur in der Fork-Phase und die Zeit ist im Allgemeinen sehr kurz. 🎜🎜bgsaveDer spezifische Prozess des Befehls ist wie folgt: 🎜🎜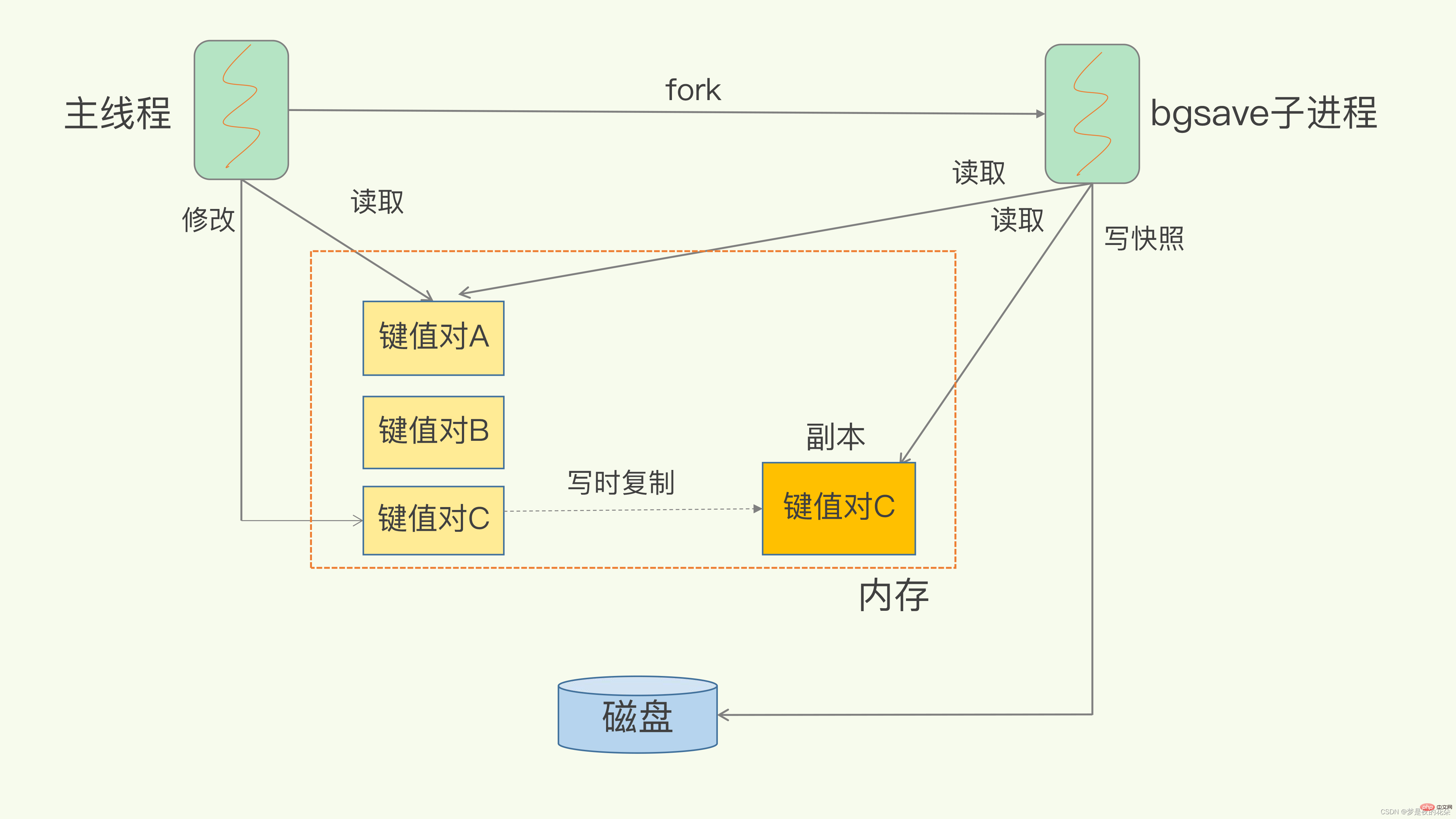 🎜 1. Führen Sie den Befehl
🎜 1. Führen Sie den Befehl bgsave aus. Der Redis-Prozess ermittelt zunächst, ob derzeit ein ausgeführter RDB- oder AOF-Sub-Thread vorhanden ist. Falls vorhanden, es wird direkt enden. 🎜 2. Der Redis-Prozess führt einen Fork-Vorgang durch, um einen untergeordneten Thread zu erstellen. Der Redis-Prozess wird während des Fork-Vorgangs blockiert. 🎜 3. Nachdem der Redis-Prozesszweig abgeschlossen ist, wird der Befehl bgsave beendet. Von da an wird der Redis-Prozess nicht blockiert und kann auf andere Befehle reagieren. 🎜 4. Der untergeordnete Prozess generiert eine Snapshot-Datei basierend auf dem Speicher des Redis-Prozesses und ersetzt die ursprüngliche RDB-Datei. 🎜 5. Senden Sie gleichzeitig ein Signal an den Hauptprozess, um den Hauptprozess darüber zu informieren, dass die RDB-Persistenz abgeschlossen ist, und der Hauptprozess aktualisiert relevante statistische Informationen (rdb_*-bezogene Optionen unter Info Persistenz). 🎜🎜🎜4. Automatische Auslösung🎜🎜Zusätzlich zur manuellen Auslösung durch Ausführen des oben genannten Befehls kann die RDB-Persistenz automatisch in Redis ausgelöst werden. Die automatisch ausgelöste RDB-Persistenz verwendet die Methode bgsave, um die Blockierung des Redis-Prozesses zu reduzieren. Unter welchen Umständen wird es also automatisch ausgelöst? 🎜save wird in der Konfigurationsdatei festgelegt, z. B. sava m n, was bedeutet, dass die Daten innerhalb von m n-mal geändert werden Sekunden, löst automatisch den bgsave-Vorgang aus. 🎜bgsave-Vorgang aus und sendet die generierte RDB-Datei an den Slave-Knoten. 🎜debug reload wird auch der Vorgang bgsave automatisch ausgelöst. 🎜shutdown die AOF-Persistenz nicht aktiviert ist, wird der Vorgang bgsave automatisch ausgelöst. 🎜🎜🎜5. RDB-Vorteile🎜🎜RDB-Datei ist eine kompakte binäre komprimierte Datei, die eine Momentaufnahme aller Redis-Daten zu einem bestimmten Zeitpunkt darstellt. Daher ist die Geschwindigkeit der Datenwiederherstellung mit RDB viel schneller als mit AOF, was sich sehr gut für Szenarien wie Sicherung, vollständige Replikation und Notfallwiederherstellung eignet. 🎜Jedes Mal, wenn Sie einen bgsave-Vorgang ausführen, müssen Sie einen Fork-Vorgang durchführen, um einen untergeordneten Vorgang zu erstellen Echtzeit-Persistenz kann nicht erreicht werden, oder auf der zweiten Ebene Persistenz. bgsave操作都要执行fork操作创建子经常,属于重量级操作,频繁执行成本过高,所以无法做到实时持久化,或者秒级持久化。
另外,由于Redis版本的不断迭代,存在不同格式的RDB版本,有可能出现低版本的RDB格式无法兼容高版本RDB文件的问题。
快照周期:内存快照虽然可以通过技术人员手动执行SAVE或BGSAVE
# 周期性执行条件的设置格式为 save <seconds> <changes> # 默认的设置为: save 900 1 save 300 10 save 60 10000 # 以下设置方式为关闭RDB快照功能 save ""</changes></seconds>
# 文件名称 dbfilename dump.rdb # 文件保存路径 dir ./ # 如果持久化出错,主进程是否停止写入 stop-writes-on-bgsave-error yes # 是否压缩 rdbcompression yes # 导入时是否检查 rdbchecksum yes
bgsave 子进程相互不影响。但是,如果主线程要修改一块数据(例如图中的键值对 C),那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决
AOF(Append Only File)持久化是把每次写命令追加写入日志中,当需要恢复数据时重新执行AOF文件中的命令就可以了。AOF解决了数据持久化的实时性,也是目前主流的Redis持久化方式。
Redis是“写后”日志,Redis先执行命令,把数据写入内存,然后才记录日志。日志里记录的是Redis收到的每一条命令,这些命令是以文本形式保存。PS: 大多数的数据库采用的是写前日志(WAL),例如MySQL,通过写前日志和两阶段提交,实现数据和逻辑的一致性。
而AOF日志采用写后日志,即先写内存,后写日志。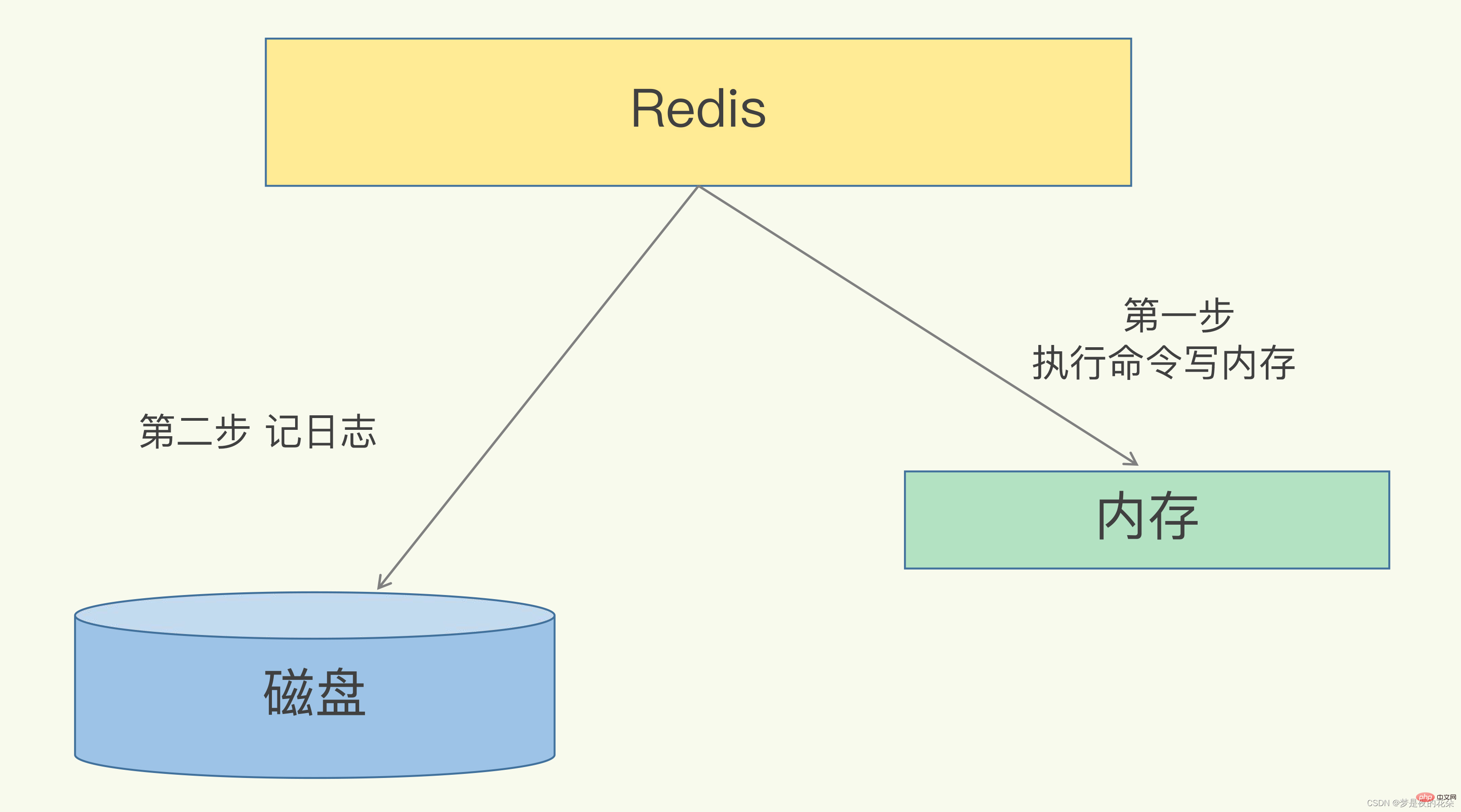
为什么采用写后日志?
Redis要求高性能,采用写日志有两方面好处:
但这种方式存在潜在风险:
AOF日志记录Redis的每个写命令,步骤分为:命令追加(append)、文件写入(write)和文件同步(sync)。
默认情况下,Redis是没有开启AOF的,可以通过配置redis.conf文件来开启AOF持久化,关于AOF的配置如下:
# appendonly参数开启AOF持久化 appendonly no # AOF持久化的文件名,默认是appendonly.aof appendfilename "appendonly.aof" # AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的 dir ./ # 同步策略 # appendfsync always appendfsync everysec # appendfsync no # aof重写期间是否同步 no-appendfsync-on-rewrite no # 重写触发配置 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb # 加载aof出错如何处理 aof-load-truncated yes # 文件重写策略 aof-rewrite-incremental-fsync yes
以下是Redis中关于AOF的主要配置信息:
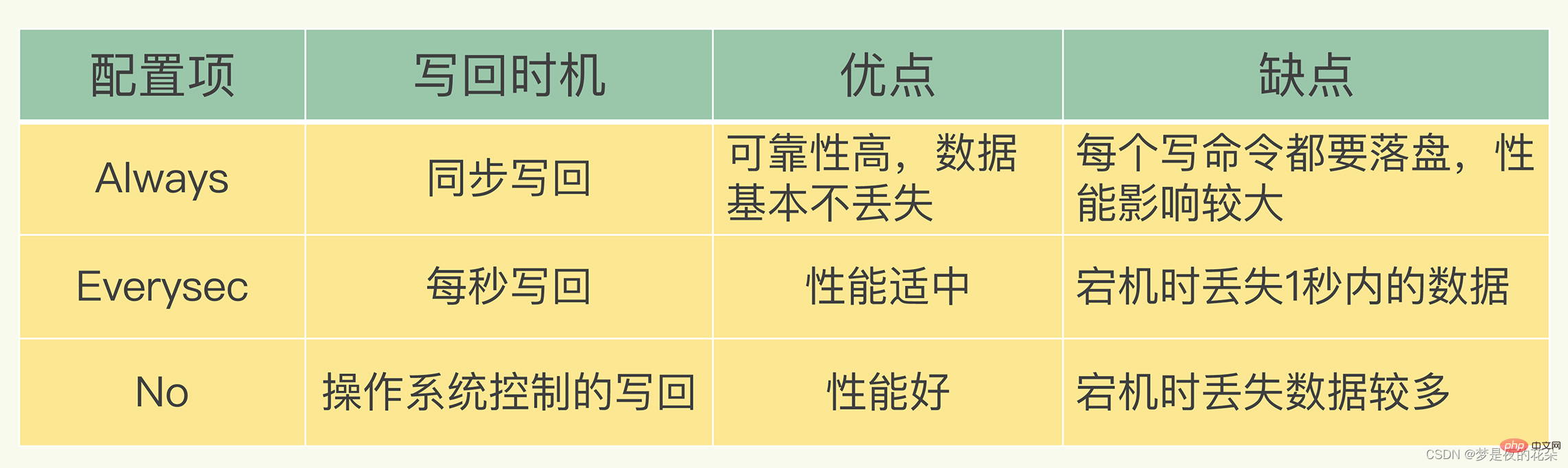
appendfsync:这个参数项是AOF功能最重要的设置项之一,主要用于设置“真正执行”操作命令向AOF文件中同步的策略。
什么叫“真正执行”呢?还记得Linux操作系统对磁盘设备的操作方式吗? 为了保证操作系统中I/O队列的操作效率,应用程序提交的I/O操作请求一般是被放置在linux Page Cache中的,然后再由Linux操作系统中的策略自行决定正在写到磁盘上的时机。而Redis中有一个fsync()函数,可以将Page Cache中待写的数据真正写入到物理设备上,而缺点是频繁调用这个fsync()函数干预操作系统的既定策略,可能导致I/O卡顿的现象频繁 。
与上节对应,appendfsync参数项可以设置三个值,分别是:always、everysec、no,默认的值为everysec。
no-appendfsync-on-rewrite:always和everysec的设置会使真正的I/O操作高频度的出现,甚至会出现长时间的卡顿情况,这个问题出现在操作系统层面上,所有靠工作在操作系统之上的Redis是没法解决的。为了尽量缓解这个情况,Redis提供了这个设置项,保证在完成fsync函数调用时,不会将这段时间内发生的命令操作放入操作系统的Page Cache(这段时间Redis还在接受客户端的各种写操作命令)。
Auto-aof-rewrite-percentage: Wie oben erwähnt, ist es in einer Produktionsumgebung für Techniker unmöglich, den Befehl „BGREWRITEAOF“ zu verwenden, um AOF-Dateien jederzeit und überall neu zu schreiben. Daher müssen wir uns häufiger auf die automatische Umschreibungsstrategie von AOF-Dateien in Redis verlassen. Redis bietet zwei Einstellungen zum Auslösen des automatischen Neuschreibens von AOF-Dateien: BGREWRITEAOF”命令去重写AOF文件。所以更多时候我们需要依靠Redis中对AOF文件的自动重写策略。Redis中对触发自动重写AOF文件的操作提供了两个设置:
auto-aof-rewrite-percentage表示如果当前AOF文件的大小超过了上次重写后AOF文件的百分之多少后,就再次开始重写AOF文件。例如该参数值的默认设置值为100,意思就是如果AOF文件的大小超过上次AOF文件重写后的1倍,就启动重写操作。
auto-aof-rewrite-min-size:设置项表示启动AOF文件重写操作的AOF文件最小大小。如果AOF文件大小低于这个值,则不会触发重写操作。注意,auto-aof-rewrite-percentage和auto-aof-rewrite-min-size只是用来控制Redis中自动对AOF文件进行重写的情况,如果是技术人员手动调用“BGREWRITEAOF
gibt an, ob die Größe der aktuellen AOF-Datei den Prozentsatz der AOF-Datei nach dem letzten Neuschreiben überschreitet. Danach wird mit dem Neuschreiben begonnen AOF-Datei erneut. Der Standardeinstellungswert dieses Parameterwerts ist beispielsweise 100, was bedeutet, dass der Neuschreibvorgang gestartet wird, wenn die Größe der AOF-Datei das 1-fache der Größe des letzten Neuschreibens der AOF-Datei überschreitet.auto-aof-rewrite-min-size
: Das Einstellungselement gibt die Mindestgröße der AOF-Datei an, um den Vorgang zum Umschreiben der AOF-Datei zu starten. Wenn die AOF-Dateigröße unter diesem Wert liegt, wird der Neuschreibvorgang nicht ausgelöst. Beachten Sie, dass auto-aof-rewrite-percentage und auto-aof-rewrite-min-size nur zur Steuerung des automatischen Neuschreibens von AOF-Dateien in Redis verwendet werden, wenn ein Techniker den Befehl „BGREWRITEAOF“ manuell aufruft unterliegen diesen beiden Einschränkungen nicht. 3. Detailliertes Verständnis des AOF-Umschreibens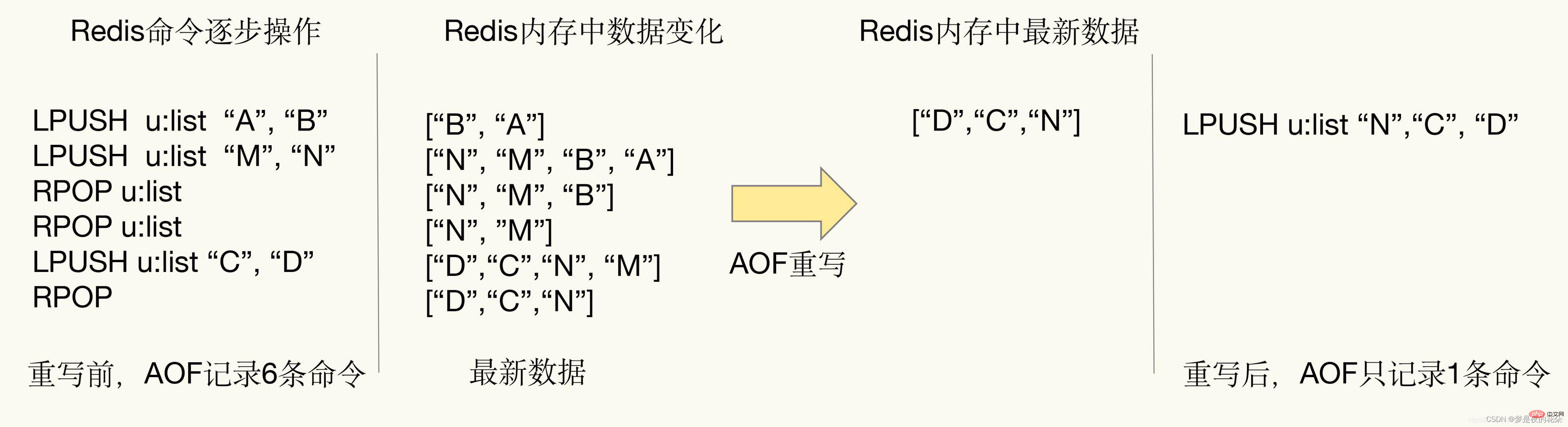 AOF zeichnet jeden Schreibbefehl in der AOF-Datei auf. Mit der Zeit wird die AOF-Datei immer größer. Wenn es nicht kontrolliert wird, wirkt es sich auf den Redis-Server und sogar auf das Betriebssystem aus. Darüber hinaus ist die Datenwiederherstellung umso langsamer, je größer die AOF-Datei ist. Um das Problem der Erweiterung der AOF-Dateigröße zu lösen, bietet Redis einen Mechanismus zum Umschreiben von AOF-Dateien, um AOF-Dateien zu „verkleinern“.
AOF zeichnet jeden Schreibbefehl in der AOF-Datei auf. Mit der Zeit wird die AOF-Datei immer größer. Wenn es nicht kontrolliert wird, wirkt es sich auf den Redis-Server und sogar auf das Betriebssystem aus. Darüber hinaus ist die Datenwiederherstellung umso langsamer, je größer die AOF-Datei ist. Um das Problem der Erweiterung der AOF-Dateigröße zu lösen, bietet Redis einen Mechanismus zum Umschreiben von AOF-Dateien, um AOF-Dateien zu „verkleinern“.
Illustration zur Erläuterung der AOF-Umschreibung
Wird die AOF-Umschreibung blockiert?
Der AOF-Umschreibprozess wird durch den Hintergrundprozess bgrewriteaof abgeschlossen. Der Hauptthread verzweigt sich im Hintergrund aus dem untergeordneten Prozess bgrewriteaof. Der Zweig kopiert den Speicher des Hauptthreads in den untergeordneten Prozess bgrewriteaof, der die neuesten Daten der Datenbank enthält. Anschließend kann der Unterprozess bgrewriteaof die kopierten Daten einzeln in Vorgänge schreiben und im Umschreibeprotokoll aufzeichnen, ohne den Hauptthread zu beeinträchtigen. Wenn aof neu geschrieben wird, blockiert es daher den Hauptthread, wenn der Prozess gegabelt wird.
Wann wird das AOF-Protokoll neu geschrieben?
Es gibt zwei Konfigurationselemente, um das Auslösen des AOF-Rewrites zu steuern: auto-aof-rewrite-min-size: Gibt die Mindestgröße der Datei an, wenn AOF-Rewrite ausgeführt wird. Der Standardwert ist 64 MB.
: Dieser Wert wird als Differenz zwischen der aktuellen AOF-Dateigröße und der AOF-Dateigröße nach dem letzten Umschreiben, geteilt durch die AOF-Dateigröße nach dem letzten Umschreiben, berechnet. Das heißt, die inkrementelle Größe der aktuellen AOF-Datei im Vergleich zur AOF-Datei nach dem letzten Umschreiben und das Verhältnis der AOF-Dateigröße nach dem letzten Umschreiben.
Was passiert, wenn beim Umschreiben des Protokolls neue Daten geschrieben werden? Der Umschreibungsprozess lässt sich wie folgt zusammenfassen: „Eine Kopie, zwei Protokolle“. Wenn beim Verzweigen aus dem untergeordneten Prozess und beim Neuschreiben neue Daten geschrieben werden, zeichnet der Hauptthread den Befehl in zwei Protokollspeicherpuffern auf. Wenn die AOF-Rückschreibrichtlinie auf „Immer“ konfiguriert ist, wird der Befehl direkt in die alte Protokolldatei zurückgeschrieben und eine Kopie des Befehls im AOF-Rewrite-Puffer gespeichert. Diese Vorgänge haben keine Auswirkungen auf die neue Protokolldatei. (Alte Protokolldatei: die vom Hauptthread verwendete Protokolldatei, neue Protokolldatei: die vom bgrewriteaof-Prozess verwendete Protokolldatei)
Nachdem der bgrewriteaof-Unterprozess den Umschreibvorgang der Protokolldatei abgeschlossen hat, wird er aufgefordert, den Hauptthread zu verwenden Wenn der Thread den Umschreibevorgang abgeschlossen hat, hängt der Hauptthread die Befehle im AOF-Umschreibepuffer an die Rückseite der neuen Protokolldatei an. Zu diesem Zeitpunkt kann die Ansammlung des AOF-Rewrite-Puffers bei hoher Parallelität sehr groß sein, was zu einer Blockierung führt. Später verwendete Redis die Linux-Pipeline-Technologie, um die gleichzeitige Wiedergabe während des AOF-Rewrites zu ermöglichen, sodass nach Abschluss des AOF-Rewrites Es muss nur noch eine kleine Menge der verbleibenden Daten wiedergegeben werden. Schließlich wird durch Ändern des Dateinamens die Atomizität des Dateiwechsels sichergestellt.Der Hauptthread verzweigt den untergeordneten Prozess, um das AOF-Protokoll neu zu schreiben
Nachdem der untergeordnete Prozess das Protokoll neu geschrieben hat, hängt der Hauptthread den AOF-Protokollpuffer anErsetzen Sie die Protokolldatei🎜 🎜🎜🎜Warme Erinnerung🎜 🎜🎜🎜Die Konzepte von Prozessen und Threads sind hier etwas verwirrend. Da im Hintergrundprozess bgreweiteaof nur ein Thread ausgeführt wird und der Hauptthread der Redis-Betriebsprozess ist, der ebenfalls ein einzelner Thread ist. Was ich hier zum Ausdruck bringen möchte, ist, dass die Vorgänge des Hintergrundprozesses keine Verbindung zum Hauptprozess haben und den Hauptthread nicht blockieren, nachdem der Redis-Hauptprozess einen Hintergrundprozess gegabelt hat🎜
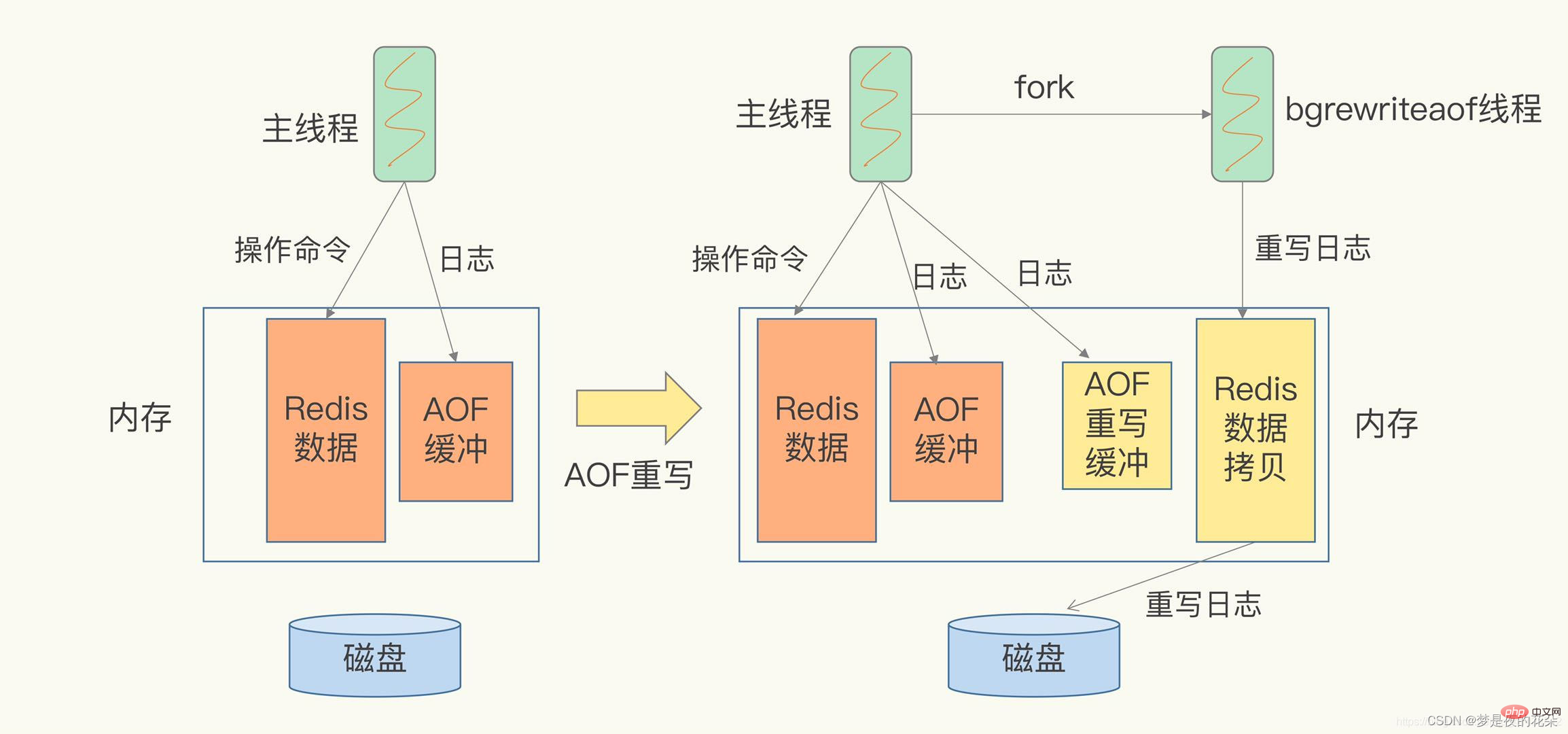
Wie teilt der Hauptthread den untergeordneten Prozess aus und kopiert die Speicherdaten?
Fork nutzt den vom Betriebssystem bereitgestellten Copy-on-Write-Mechanismus, um zu vermeiden, dass eine große Menge an Speicherdaten auf einmal kopiert und der untergeordnete Prozess blockiert wird. Beim Forken eines untergeordneten Prozesses kopiert der untergeordnete Prozess die Seitentabelle des übergeordneten Prozesses, dh die virtuelle und reale Zuordnungsbeziehung (die Zuordnungsindextabelle zwischen virtuellem Speicher und physischem Speicher), jedoch nicht den physischen Speicher. Diese Kopie verbraucht viele CPU-Ressourcen und der Hauptthread wird blockiert, bevor die Kopie abgeschlossen ist. Die Blockierungszeit hängt von der Datenmenge im Speicher ab. Je größer die Datenmenge, desto größer die Speicherseitentabelle. Nach Abschluss des Kopiervorgangs verwenden der übergeordnete und der untergeordnete Prozess denselben Speicheradressraum.
Aber der Hauptprozess kann Daten schreiben, und zu diesem Zeitpunkt werden die Daten im physischen Speicher kopiert. Wie unten gezeigt (Prozess 1 wird als Hauptprozess betrachtet, Prozess 2 wird als untergeordneter Prozess betrachtet): 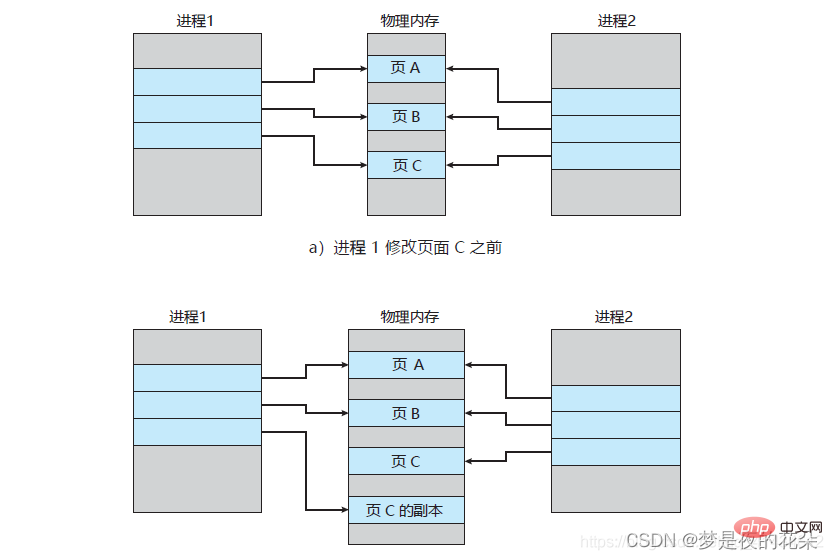
Wenn der Hauptprozess Daten geschrieben hat und diese Daten sich zufällig auf Seite c befinden, erstellt das Betriebssystem einen Kopie dieser Seite ( Eine Kopie von Seite c), dh die physischen Daten der aktuellen Seite werden kopiert und dem Hauptprozess zugeordnet, während der untergeordnete Prozess weiterhin die Originalseite c verwendet.
Während des gesamten Prozesses des Umschreibens des Protokolls, wo wird der Hauptthread blockiert?
Warum wird beim AOF-Umschreiben das ursprüngliche AOF-Protokoll nicht wiederverwendet?
Redis 4.0 schlägt eine Methode zur gemischten Verwendung von AOF-Protokollen und Speicher-Snapshots vor. Einfach ausgedrückt werden Speicher-Snapshots mit einer bestimmten Häufigkeit ausgeführt und zwischen zwei Snapshots werden AOF-Protokolle verwendet, um alle Befehlsvorgänge während dieses Zeitraums aufzuzeichnen.
Auf diese Weise müssen Snapshots nicht sehr häufig ausgeführt werden, wodurch die Auswirkungen häufiger Verzweigungen auf den Hauptthread vermieden werden. Darüber hinaus zeichnet das AOF-Protokoll nur Vorgänge zwischen zwei Snapshots auf, was bedeutet, dass nicht alle Vorgänge aufgezeichnet werden müssen. Daher wird die Datei nicht zu groß und ein Überschreiben kann vermieden werden.
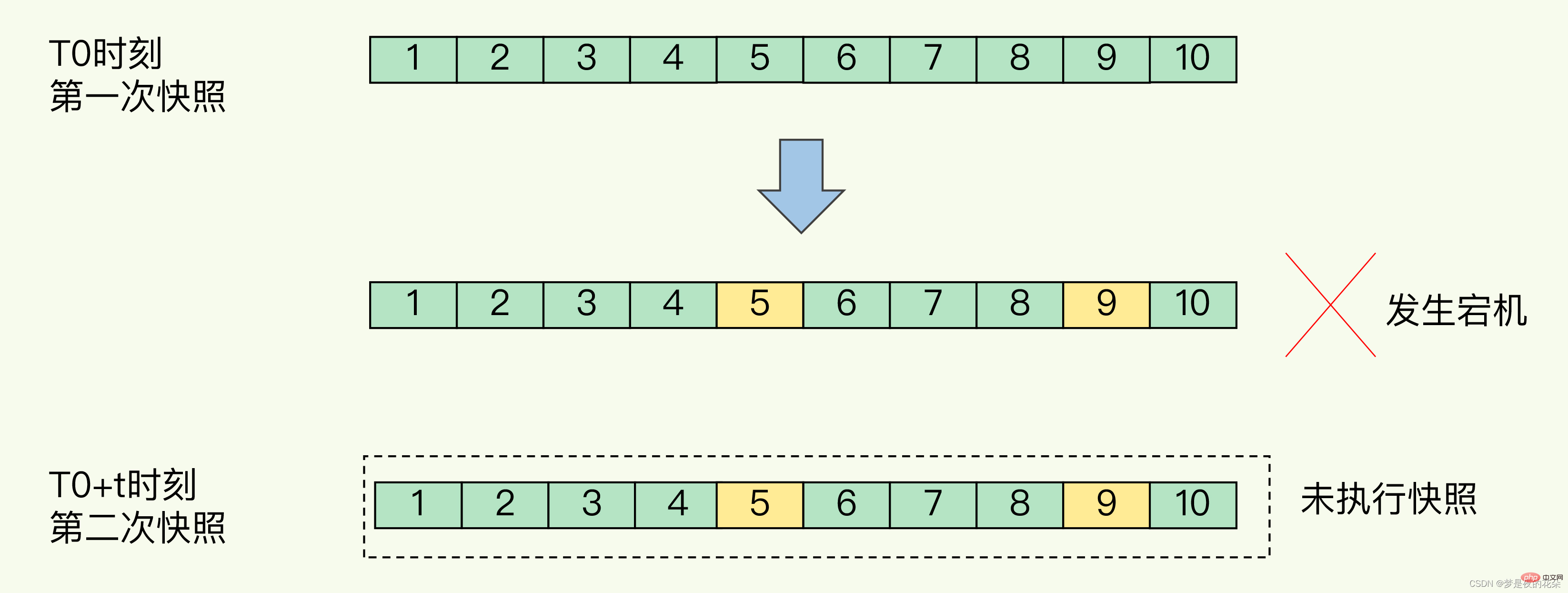
Wie in der Abbildung unten gezeigt, werden die Änderungen bei T1 und T2 im AOF-Protokoll aufgezeichnet. Wenn der vollständige Schnappschuss zum zweiten Mal erstellt wird, kann das AOF-Protokoll gelöscht werden, da die Änderungen zu diesem Zeitpunkt aufgezeichnet wurden der Snapshot, und sie werden während der Wiederherstellung gelöscht. Keine Protokolle mehr. 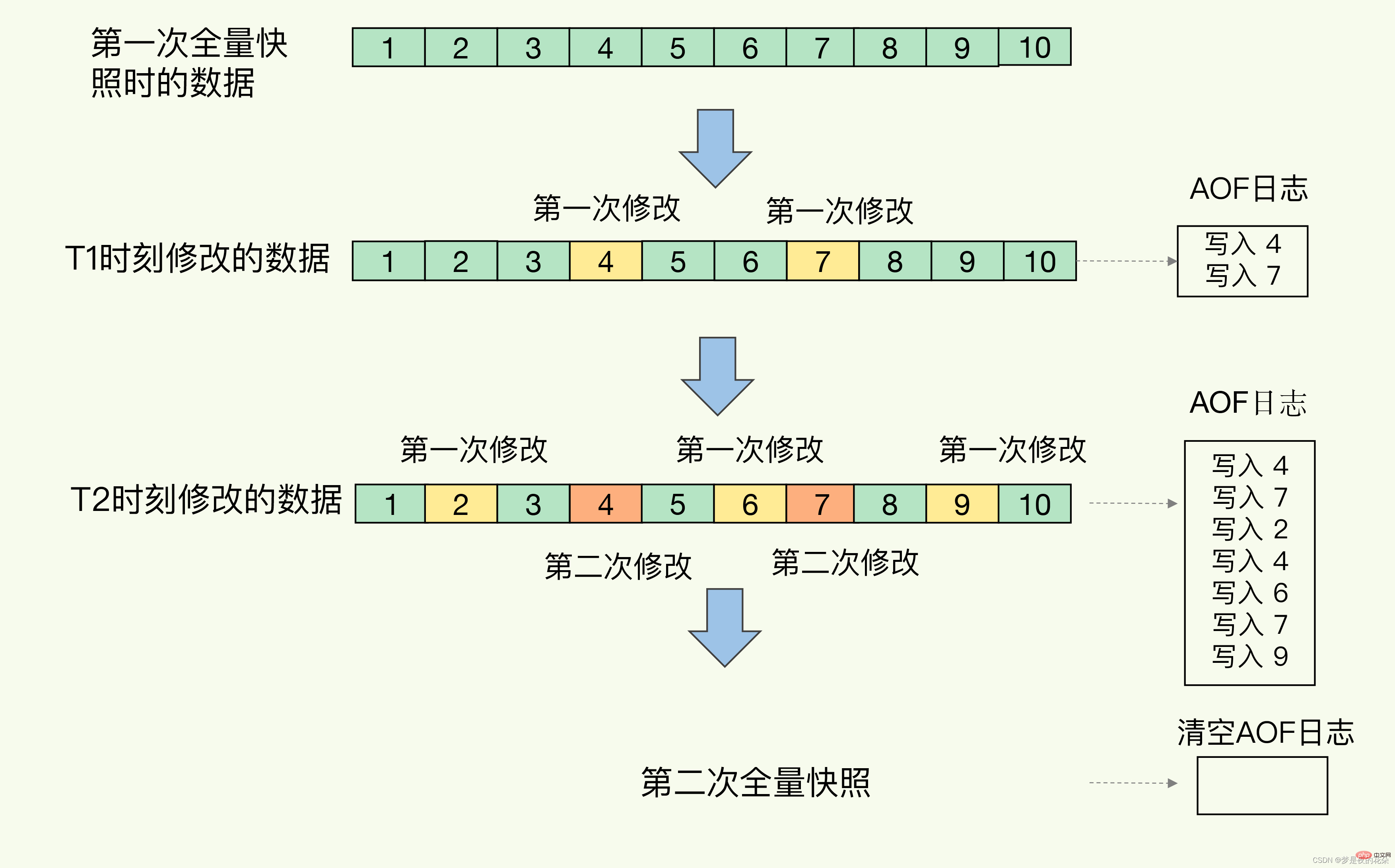
Diese Methode bietet nicht nur die Vorteile einer schnellen Wiederherstellung von RDB-Dateien, sondern auch den einfachen Vorteil, dass AOF nur Betriebsbefehle aufzeichnet. Sie wird in tatsächlichen Umgebungen häufig verwendet.
Wie stellen wir Daten aus diesen persistenten Dateien wieder her, nachdem die Datensicherung und die Persistenz abgeschlossen sind? Wenn auf einem Server sowohl RDB-Dateien als auch AOF-Dateien vorhanden sind, welche sollten geladen werden?
Tatsächlich müssen Sie Redis nur neu starten, wenn Sie Daten aus diesen Dateien wiederherstellen möchten. Wir verstehen diesen Prozess immer noch anhand des Diagramms: 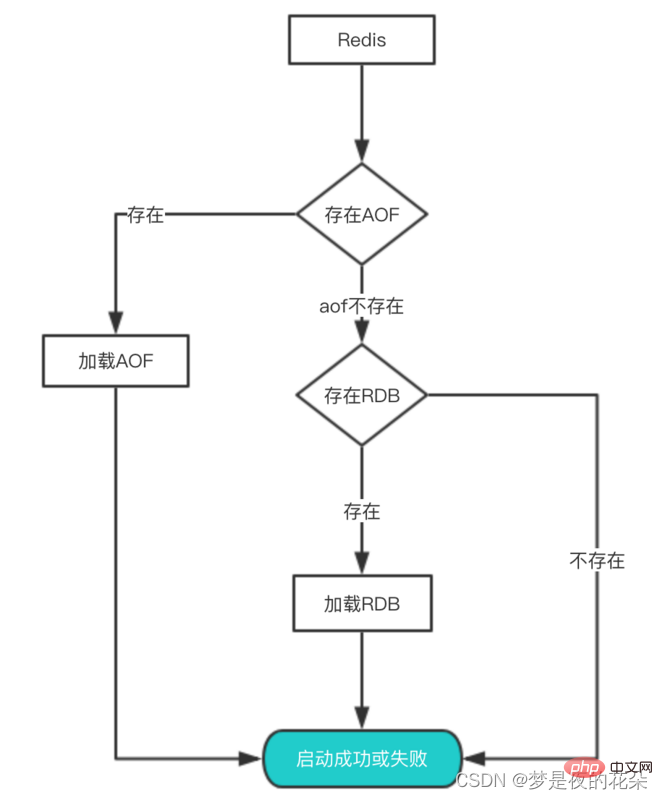
Das obige ist der detaillierte Inhalt vonBeherrschen Sie die Redis-Persistenz vollständig: RDB und AOF. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?












![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



