
 Backend-Entwicklung
Python-Tutorial
Python-Beispiel, ausführliche Erklärung von pdfplumber zum Lesen von PDF-Dateien und zum Schreiben in Excel
Backend-Entwicklung
Python-Tutorial
Python-Beispiel, ausführliche Erklärung von pdfplumber zum Lesen von PDF-Dateien und zum Schreiben in Excel
Python-Beispiel, ausführliche Erklärung von pdfplumber zum Lesen von PDF-Dateien und zum Schreiben in Excel

Dieser Artikel vermittelt Ihnen relevantes Wissen über Python, in dem hauptsächlich Probleme im Zusammenhang mit dem Lesen von PDF-Dateien durch PDFPlumber und dem Schreiben in Excel vorgestellt werden, einschließlich der Installation des PDFPlumber-Moduls, dem Laden von PDF und einigen praktischen Vorgängen usw. Schauen wir uns das gemeinsam an , ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: Python-Video-Tutorial
1. Vergleich von 13 wichtigen Bibliotheken für den Betrieb von PDF in Python
PDF (Portable Document Format) ist ein tragbares Dokumentformat, das die Verbreitung von Dokumenten über Betriebssysteme hinweg erleichtert. PDF-Dokumente folgen einem Standardformat, daher gibt es viele Tools, die PDF-Dokumente bearbeiten können, und Python bildet da keine Ausnahme.
Die Vergleichstabelle des Python-Betriebs-PDF-Moduls lautet wie folgt:
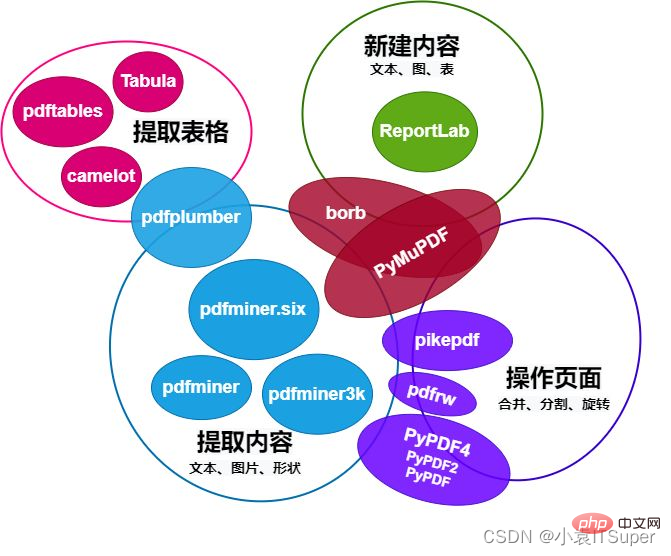
Dieser Artikel stellt hauptsächlich pdfplumber vor und konzentriert sich auf die Extraktion von PDF-Inhalten wie Text (Position, Schriftart und Farbe usw.) und Form (Rechteck, gerade Linie, Kurve) sowie die Funktion zum Parsen von Tabellen. pdfplumber专注PDF内容提取,例如文本(位置、字体及颜色等)和形状(矩形、直线、曲线),还有解析表格的功能。
二、pdfplumber模块
其他几个 Python 库帮助用户从 PDF 中提取信息。作为一个广泛的概述,pdfplumber它通过结合以下功能将自己与其他 PDF 处理库区分开来:
- 轻松访问有关每个 PDF 对象的详细信息
- 用于提取文本和表格的更高级别、可自定义的方法
- 紧密集成的可视化调试
- 其他有用的实用功能,例如通过裁剪框过滤对象
1. 安装
cmd控制台输入:
pip install pdfplumber
导包:
import pdfplumber
案例PDF截图(两页未截全):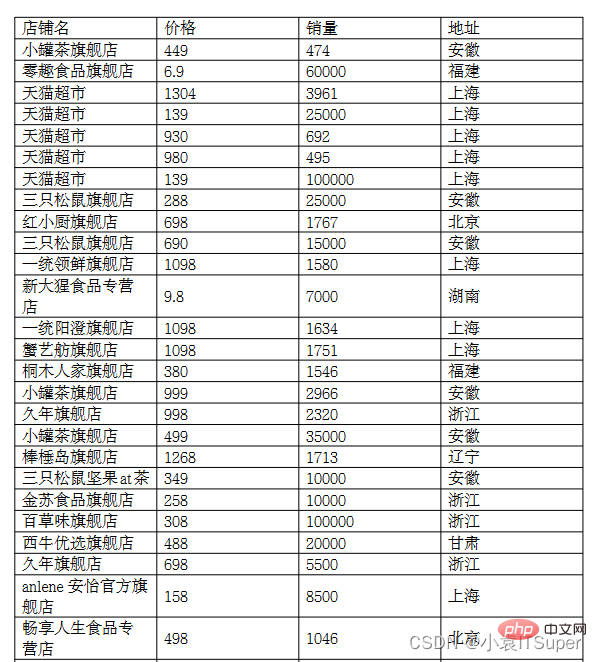
2. 加载PDF
读取PDF代码:pdfplumber.open("路径/文件名.pdf", password = "test", laparams = { "line_overlap": 0.7 })
参数解读:
-
password:要加载受密码保护的 PDF,请传递password关键字参数 -
laparams:要将布局分析参数设置为pdfminer.six的布局引擎,请传递laparams关键字参数
案例代码:
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf)
print(type(pdf))输出结果:
<pdfplumber.pdf.pdf><class></class></pdfplumber.pdf.pdf>
3. pdfplumber.PDF类
pdfplumber.PDF类表示单个 PDF,并具有两个主要属性:
| 属性 | 说明 |
|---|---|
.metadata |
从PDF的Info中获取元数据键 /值对字典。 通常包括“ CreationDate”,“ ModDate”,“ Producer”等。 |
.pages |
返回一个包含pdfplumber.Page实例的列表,每一个实例代表PDF每一页的信息 |
1. 读取PDF文档信息(.metadata):
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf.metadata)运行结果:
{'Author': 'wangwangyuqing', 'Comments': '', 'Company': '', 'CreationDate': "D:20220330113508+03'35'", 'Creator': 'WPS 文字', 'Keywords': '', 'ModDate': "D:20220330113508+03'35'", 'Producer': '', 'SourceModified': "D:20220330113508+03'35'", 'Subject': '', 'Title': '', 'Trapped': 'False'}2. 输出总页数
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(len(pdf.pages))运行结果:
2
4. pdfplumber.Page类
pdfplumber.Page类是pdfplumber整个的核心,大多数操作都围绕这个类进行操作,它具有以下几个属性:
| 属性 | 说明 |
|---|---|
.page_number |
顺序页码,从1第一页开始,从第二页开始2,依此类推。 |
.width |
页面的宽度。 |
.height |
页面的高度。 |
.objects/.chars/.lines/.rects/.curves/.figures/.images |
这些属性中的每一个都是一个列表,每个列表包含一个字典,用于嵌入页面上的每个此类对象。有关详细信息,请参阅下面的“对象”。 |
常用方法如下:
| 方法名 | 说明 |
|---|---|
.extract_text() |
用来提页面中的文本,将页面的所有字符对象整理为的那个字符串 |
.extract_words() |
返回的是所有的单词及其相关信息 |
.extract_tables() |
提取页面的表格 |
.to_image() |
用于可视化调试时,返回PageImage类的一个实例 |
.close() | 2. pdfplumber-Modul Mehrere andere Python-Bibliotheken helfen Benutzern, Informationen aus PDFs zu extrahieren. Im Großen und Ganzen unterscheidet sich pdfplumber von anderen PDF-Verarbeitungsbibliotheken durch die Kombination der folgenden Funktionen: |
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
# 查看页码
print('页码:', first_page.page_number)
# 查看页宽
print('页宽:', first_page.width)
# 查看页高
print('页高:', first_page.height)页码: 1页宽: 595.3页高: 841.9
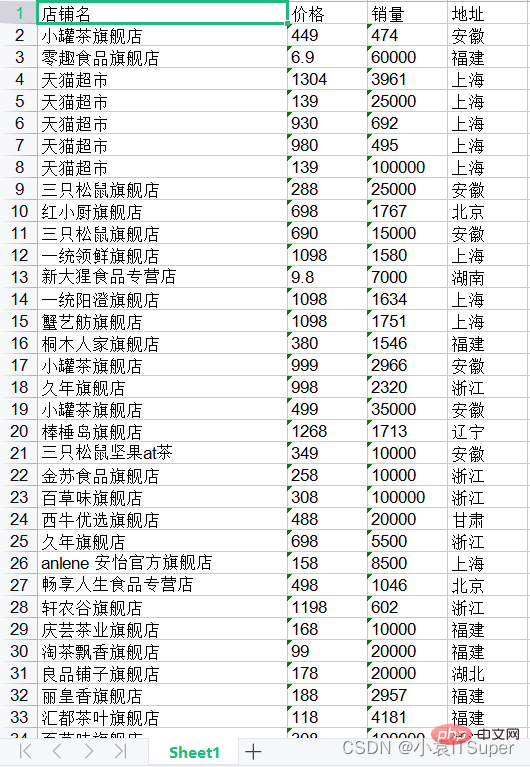 🎜🎜2. PDF laden🎜🎜PDF-Code lesen:
🎜🎜2. PDF laden🎜🎜PDF-Code lesen: pdfplumber.open(" path/filename.pdf", password = " test", laparams = { "line_overlap": 0.7 })🎜🎜Parameterinterpretation:🎜-
password: erforderlich Um ein passwortgeschütztes PDF zu laden, übergeben Sie das Passwort Schlüsselwortargument -
laparams: Um die Layout-Analyseparameter auf die Layout-Engine von pdfminer.six festzulegen, übergeben Sie das Schlüsselwortargument laparams
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
text = first_page.extract_text()
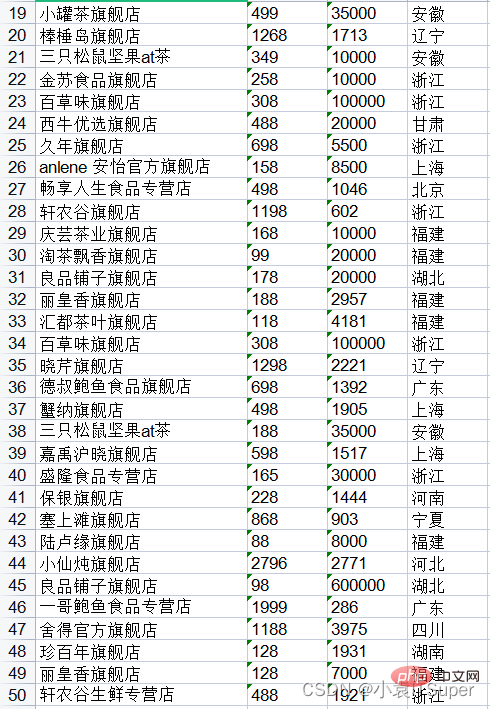
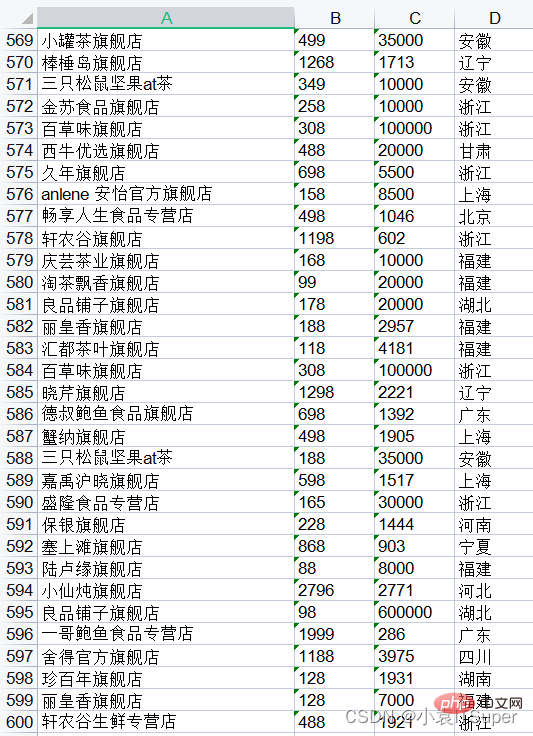
print(text)店铺名 价格 销量 地址 小罐茶旗舰店 449 474 安徽 零趣食品旗舰店 6.9 60000 福建 天猫超市 1304 3961 上海 天猫超市 139 25000 上海 天猫超市 930 692 上海 天猫超市 980 495 上海 天猫超市 139 100000 上海 三只松鼠旗舰店 288 25000 安徽 红小厨旗舰店 698 1767 北京 三只松鼠旗舰店 690 15000 安徽 一统领鲜旗舰店 1098 1580 上海 新大猩食品专营9.8 7000 湖南.......舰店 蟹纳旗舰店 498 1905 上海 三只松鼠坚果at茶 188 35000 安徽 嘉禹沪晓旗舰店 598 1517 上海
pdfplumber.PDF-Klasse stellt ein einzelnes PDF dar und hat zwei Haupteigenschaften: 🎜| Attribut | Beschreibung | 🎜||
|---|---|---|---|
| Attribut | Beschreibung | 🎜
|---|---|
| Methodenname | Beschreibung | 🎜
|---|---|
Das obige ist der detaillierte Inhalt vonPython-Beispiel, ausführliche Erklärung von pdfplumber zum Lesen von PDF-Dateien und zum Schreiben in Excel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Was ist der Grund, warum PS immer wieder Laden zeigt?
Apr 06, 2025 pm 06:39 PM
Was ist der Grund, warum PS immer wieder Laden zeigt?
Apr 06, 2025 pm 06:39 PM
PS "Laden" Probleme werden durch Probleme mit Ressourcenzugriff oder Verarbeitungsproblemen verursacht: Die Lesegeschwindigkeit von Festplatten ist langsam oder schlecht: Verwenden Sie Crystaldiskinfo, um die Gesundheit der Festplatte zu überprüfen und die problematische Festplatte zu ersetzen. Unzureichender Speicher: Upgrade-Speicher, um die Anforderungen von PS nach hochauflösenden Bildern und komplexen Schichtverarbeitung zu erfüllen. Grafikkartentreiber sind veraltet oder beschädigt: Aktualisieren Sie die Treiber, um die Kommunikation zwischen PS und der Grafikkarte zu optimieren. Dateipfade sind zu lang oder Dateinamen haben Sonderzeichen: Verwenden Sie kurze Pfade und vermeiden Sie Sonderzeichen. Das eigene Problem von PS: Installieren oder reparieren Sie das PS -Installateur neu.
 Wie beschleunigt man die Ladegeschwindigkeit von PS?
Apr 06, 2025 pm 06:27 PM
Wie beschleunigt man die Ladegeschwindigkeit von PS?
Apr 06, 2025 pm 06:27 PM
Das Lösen des Problems des langsamen Photoshop-Startups erfordert einen mehrstufigen Ansatz, einschließlich: Upgrade-Hardware (Speicher, Solid-State-Laufwerk, CPU); Deinstallieren veraltete oder inkompatible Plug-Ins; Reinigen des Systemmülls und übermäßiger Hintergrundprogramme regelmäßig; irrelevante Programme mit Vorsicht schließen; Vermeiden Sie das Öffnen einer großen Anzahl von Dateien während des Starts.
 Wie löst ich das Problem des Ladens beim Starten von PS?
Apr 06, 2025 pm 06:36 PM
Wie löst ich das Problem des Ladens beim Starten von PS?
Apr 06, 2025 pm 06:36 PM
Ein PS, der beim Booten auf "Laden" steckt, kann durch verschiedene Gründe verursacht werden: Deaktivieren Sie korrupte oder widersprüchliche Plugins. Eine beschädigte Konfigurationsdatei löschen oder umbenennen. Schließen Sie unnötige Programme oder aktualisieren Sie den Speicher, um einen unzureichenden Speicher zu vermeiden. Upgrade auf ein Solid-State-Laufwerk, um die Festplatte zu beschleunigen. PS neu installieren, um beschädigte Systemdateien oder ein Installationspaketprobleme zu reparieren. Fehlerinformationen während des Startprozesses der Fehlerprotokollanalyse anzeigen.
 HTML Nächste Seitenfunktion
Apr 06, 2025 am 11:45 AM
HTML Nächste Seitenfunktion
Apr 06, 2025 am 11:45 AM
<p> Die nächste Seitenfunktion kann über HTML erstellt werden. Zu den Schritten gehören: Erstellen von Containerelementen, Spalten von Inhalten, Hinzufügen von Navigationsverbindungen, Verbergen anderer Seiten und Hinzufügen von Skripten. Mit dieser Funktion können Benutzer segmentierte Inhalte durchsuchen und jeweils nur eine Seite anzeigen und sind geeignet, um große Mengen an Daten oder Inhalten anzuzeigen. </p>
 Ist das langsame PS -Laden mit der Computerkonfiguration zusammen?
Apr 06, 2025 pm 06:24 PM
Ist das langsame PS -Laden mit der Computerkonfiguration zusammen?
Apr 06, 2025 pm 06:24 PM
Der Grund für die langsame PS -Belastung ist der kombinierte Einfluss von Hardware (CPU, Speicher, Festplatte, Grafikkarte) und Software (System, Hintergrundprogramm). Zu den Lösungen gehören: Aktualisieren von Hardware (insbesondere Ersetzen von Solid-State-Laufwerken), Optimierung der Software (Reinigung von Systemmüll, Aktualisierung von Treibern, Überprüfung von PS-Einstellungen) und Verarbeitung von PS-Dateien. Regelmäßige Computerwartung kann auch dazu beitragen, die PS -Laufgeschwindigkeit zu verbessern.
 Wie löste ich das Problem des Ladens, wenn die PS die Datei öffnet?
Apr 06, 2025 pm 06:33 PM
Wie löste ich das Problem des Ladens, wenn die PS die Datei öffnet?
Apr 06, 2025 pm 06:33 PM
Das Laden von Stottern tritt beim Öffnen einer Datei auf PS auf. Zu den Gründen gehören: zu große oder beschädigte Datei, unzureichender Speicher, langsame Festplattengeschwindigkeit, Probleme mit dem Grafikkarten-Treiber, PS-Version oder Plug-in-Konflikte. Die Lösungen sind: Überprüfen Sie die Dateigröße und -integrität, erhöhen Sie den Speicher, aktualisieren Sie die Festplatte, aktualisieren Sie den Grafikkartentreiber, deinstallieren oder deaktivieren Sie verdächtige Plug-Ins und installieren Sie PS. Dieses Problem kann effektiv gelöst werden, indem die PS -Leistungseinstellungen allmählich überprüft und genutzt wird und gute Dateimanagementgewohnheiten entwickelt werden.
 Wie kann man das Problem des Ladens lösen, wenn PS immer zeigt, dass es geladen wird?
Apr 06, 2025 pm 06:30 PM
Wie kann man das Problem des Ladens lösen, wenn PS immer zeigt, dass es geladen wird?
Apr 06, 2025 pm 06:30 PM
PS -Karte ist "Laden"? Zu den Lösungen gehören: Überprüfung der Computerkonfiguration (Speicher, Festplatte, Prozessor), Reinigen der Festplattenfragmentierung, Aktualisierung des Grafikkartentreibers, Anpassung der PS -Einstellungen, der Neuinstallation von PS und der Entwicklung guter Programmiergewohnheiten.
 Was ist der Unterschied zwischen der Produktion H5 -Seiten und traditionellen Webseiten
Apr 06, 2025 am 07:03 AM
Was ist der Unterschied zwischen der Produktion H5 -Seiten und traditionellen Webseiten
Apr 06, 2025 am 07:03 AM
Der Hauptunterschied zwischen H5-Seiten über herkömmlichen Webseiten ist die mobile Priorität und Flexibilität, die besser für mobile Geräte geeignet ist und eine schnellere Entwicklungseffizienz und eine bessere plattformübergreifende Kompatibilität aufweist. Insbesondere führt die H5 -Seite neue Funktionen wie semantische Tags, Multimedia -Support, Offline -Speicher und geografischen Standort ein, um das mobile Erlebnis zu verbessern.
