

So optimieren Sie die MySQL-Paging-Abfrage

Optimierungsmethoden für Paging-Abfragen: 1. Unterabfrageoptimierung, Leistungsverbesserung kann durch Umschreiben von Paging-SQL-Anweisungen in Unterabfragen erreicht werden. 2. Optimierung der ID-Begrenzung: Sie können den Bereich der abgefragten IDs basierend auf der Anzahl der abgefragten Seiten und der Anzahl der abgefragten Datensätze berechnen und dann basierend auf der Anweisung „id between and“ abfragen. 3. Optimieren Sie basierend auf der Neuordnung des Index, finden Sie relevante Datenadressen über den Index und vermeiden Sie vollständige Tabellenscans. 4. Zur Optimierung der verzögerten Zuordnung können Sie JOIN verwenden, um zuerst den Paging-Vorgang für die Indexspalte abzuschließen und dann zur Tabelle zurückzukehren, um die erforderlichen Spalten abzurufen.

Die Betriebsumgebung dieses Tutorials: Windows7-System, MySQL8-Version, Dell G3-Computer.
Die Effizienz der Paging-Abfrage ist besonders wichtig, wenn die Datenmenge groß ist und sich auf die Front-End-Reaktion und das Benutzererlebnis auswirkt.
Optimierungsmethode der Paging-Abfrage
1. Unterabfrageoptimierung verwenden
Diese Methode lokalisiert zuerst die ID an der Offset-Position und fragt dann rückwärts ab zunehmend.
Prinzip der Unterabfrageoptimierung: https://www.jianshu.com/p/0768ebc4e28d
select * from sbtest1 where k=504878 limit 100000,5;Abfrageprozess:
Zuerst werden die Indexblattknotendaten abgefragt und dann basierend auf dem Primärschlüsselwert auf dem Blatt geclustert Knoten Alle Feldwerte, die für die Abfrage des Index erforderlich sind. Wie auf der linken Seite der Abbildung unten gezeigt, müssen Sie den Indexknoten 100.005 Mal abfragen, die Daten des Clustered-Index 100.005 Mal abfragen und schließlich die Ergebnisse aus den ersten 100.000 Elementen herausfiltern und die letzten 5 Elemente herausnehmen. MySQL verbringt viele zufällige E/A-Vorgänge mit der Abfrage von Daten im Clustered-Index, und die von 100.000 zufälligen E/A-Vorgängen abgefragten Daten werden nicht im Ergebnissatz angezeigt.
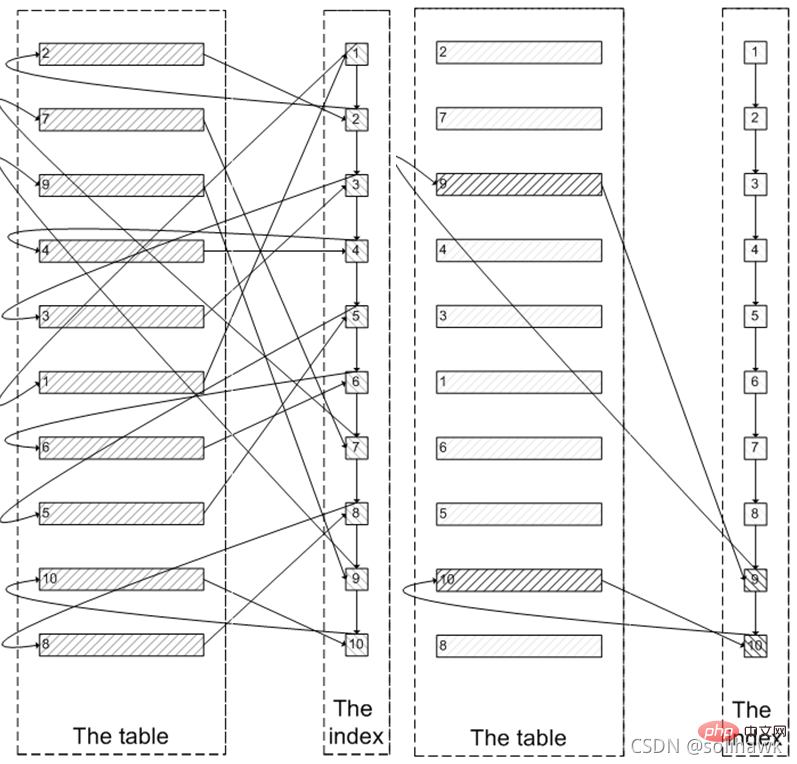
Da der Index am Anfang verwendet wird, warum nicht zuerst entlang der Indexblattknoten die letzten 5 benötigten Knoten abfragen und dann die tatsächlichen Daten im Clustered-Index abfragen? Dies erfordert nur 5 zufällige I/Os, ähnlich dem Prozess auf der rechten Seite des Bildes oben. Dies ist eine Unterabfrageoptimierung. Diese Methode lokalisiert zunächst die ID an der Offset-Position und fragt dann später ab. Diese Methode eignet sich für Situationen, in denen die ID zunimmt. Wie unten gezeigt:
mysql> select * from sbtest1 where k=5020952 limit 50,1; mysql> select id from sbtest1 where k=5020952 limit 50,1; mysql> select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10; mysql> select * from sbtest1 where k=5020952 limit 50,10;
Bei der Unterabfrageoptimierung hat die Frage, ob k im Prädikat einen Index hat, einen großen Einfluss auf die Abfrageeffizienz. Die obige Anweisung verwendet keinen Index und ein vollständiger Tabellenscan dauert 24,2 Sekunden, aber nach Verwendung des Index , es dauert nur 0,67 s.
mysql> explain select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10; +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ | 1 | PRIMARY | sbtest1 | NULL | index_merge | PRIMARY,c1 | c1,PRIMARY | 8,4 | NULL | 19 | 100.00 | Using intersect(c1,PRIMARY); Using where | | 2 | SUBQUERY | sbtest1 | NULL | ref | c1 | c1 | 4 | const | 88 | 100.00 | Using index | +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ 2 rows in set, 1 warning (0.11 sec)
Aber diese Optimierungsmethode hat auch Einschränkungen:
Diese Schreibweise erfordert, dass die Primärschlüssel-ID kontinuierlich sein muss
Die Where-Klausel erlaubt das Hinzufügen anderer Bedingungen nicht
2 Qualifizierungsoptimierung
Diese Methode geht davon aus, dass die ID der Datentabelle kontinuierlich zunimmt. Dann können wir den Bereich der abgefragten ID basierend auf der Anzahl der abgefragten Seiten und der Anzahl der abgefragten Datensätze berechnen Abfrage.
Unter der Annahme, dass die ID der Tabelle in der Datenbank kontinuierlich zunimmt, kann der Bereich der abgefragten ID basierend auf der Anzahl der abgefragten Seiten und der Anzahl der abgefragten Datensätze berechnet und dann basierend auf der ID zwischen und abgefragt werden. Der ID-Bereich kann über die Paging-Formel berechnet werden. Wenn die aktuelle Seitengröße beispielsweise m und die aktuelle Seitennummer no1 ist, beträgt der Maximalwert der Seite max=(no1+1)m-1. und der Mindestwert ist min=no1m. SQL-Anweisungen können als ID zwischen min und max ausgedrückt werden.
select * from sbtest1 where id between 1000000 and 1000100 limit 100;
Diese Abfragemethode kann die Abfragegeschwindigkeit erheblich optimieren und kann grundsätzlich innerhalb von zehn Millisekunden abgeschlossen werden. Die Einschränkung besteht darin, dass Sie die ID genau kennen müssen. Im Allgemeinen wird jedoch in der Geschäftstabelle der Paging-Abfrage das Basis-ID-Feld hinzugefügt, was die Paging-Abfrage erheblich vereinfacht. Es gibt eine andere Möglichkeit, das obige SQL zu schreiben:
select * from sbtest1 where id >= 1000001 limit 100;
Sie können den Unterschied in der Ausführungszeit sehen:
mysql> show profiles; +----------+------------+--------------------------------------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------------------------------------------------------------------------------------------+ | 6 | 0.00085500 | select * from sbtest1 where id between 1000000 and 1000100 limit 100 | | 7 | 0.12927975 | select * from sbtest1 where id >= 1000001 limit 100 | +----------+------------+--------------------------------------------------------------------------------------------------------------+
Sie können auch die in-Methode zum Abfragen verwenden, wenn mehrere Tabellen verknüpft sind Auf Abfrage festgelegte Tabellenabfrage-ID:
select * from sbtest1 where id in (select id from sbtest2 where k=504878) limit 100;
Beachten Sie bei der Verwendung in der Abfrage, dass einige MySQL-Versionen die Verwendung von limit in der in-Klausel nicht unterstützen.
3. Optimierung basierend auf Index-Neuordnung
Bei der Neuordnung basierend auf Index wird der Optimierungsalgorithmus in der Indexabfrage verwendet, um die relevante Datenadresse über den Index zu finden, um einen vollständigen Tabellenscan zu vermeiden, was viel Zeit spart. Darüber hinaus verfügt MySQL auch über einen zugehörigen Index-Cache, und es ist besser, den Cache zu verwenden, wenn die Parallelität hoch ist. Sie können die folgende Anweisung in MySQL verwenden:
SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M
Diese Methode eignet sich für Situationen, in denen die Datenmenge groß ist (Zehntausende von Tupeln). Das Spaltenobjekt nach ORDER BY ist am besten der Primärschlüssel oder der eindeutige Index , so dass die ORDER BY-Operation den Index nutzen kann, aber die Ergebnismenge stabil ist. Zum Beispiel die folgenden zwei Anweisungen:
mysql> show profiles; +----------+------------+--------------------------------------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------------------------------------------------------------------------------------------+ | 8 | 3.30585150 | select * from sbtest1 limit 1000000,10 | | 9 | 1.03224725 | select * from sbtest1 order by id limit 1000000,10 | +----------+------------+--------------------------------------------------------------------------------------------------------------+
Nach der Verwendung der order by-Anweisung für die Indexfeld-ID wurde die Leistung erheblich verbessert.
4. Verwenden Sie zur Optimierung die verzögerte Zuordnung.
Ähnlich wie bei der obigen Unterabfragemethode können wir JOIN verwenden, um zuerst den Paging-Vorgang für die Indexspalte abzuschließen und dann zur Tabelle zurückzukehren, um die erforderlichen Spalten abzurufen.
select a.* from t5 a inner join (select id from t5 order by text limit 1000000, 10) b on a.id=b.id;

从实验中可以得出,在采用JOIN改写后,上面的两个局限性都已经解除了,而且SQL的执行效率也没有损失。
5、记录上次查询结束的位置
和上面使用的方法都不同,记录上次结束位置优化思路是使用某种变量记录上一次数据的位置,下次分页时直接从这个变量的位置开始扫描,从而避免MySQL扫描大量的数据再抛弃的操作。
select * from t5 where id>=1000000 limit 10;

6、使用临时表优化
使用临时存储的表来记录分页的id然后进行in查询
这种方式已经不属于查询优化,这儿附带提一下。
对于使用 id 限定优化中的问题,需要 id 是连续递增的,但是在一些场景下,比如使用历史表的时候,或者出现过数据缺失问题时,可以考虑使用临时存储的表来记录分页的id,使用分页的id来进行 in 查询。这样能够极大的提高传统的分页查询速度,尤其是数据量上千万的时候。
【相关推荐:mysql视频教程】
Das obige ist der detaillierte Inhalt vonSo optimieren Sie die MySQL-Paging-Abfrage. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
