

Ausführliche Erläuterung der SQL-Fensterfunktionen in einem Artikel

Dieser Artikel vermittelt Ihnen relevantes Wissen über SQL, das hauptsächlich Probleme im Zusammenhang mit Fensterfunktionen organisiert. SQL-Fensterfunktionen bieten komplexe Analysen und Berichtsstatistiken für Online-Analyseverarbeitung (OLAP) und Business-Intelligence-Funktionen (BI). Verkaufsstatistiken, Kategorierankings, Jahres-/Monatsanalysen usw. Schauen wir sie uns gemeinsam an. Ich hoffe, dass sie für alle hilfreich sind.

Empfohlenes Lernen: „SQL-Tutorial“
Was ist eine Fensterfunktion?
SQL-Fensterfunktionen bieten komplexe Analyse- und Berichtsstatistikfunktionen für Online-Analyseverarbeitung (OLAP) und Business Intelligence (BI), wie z Kumulierte Produktverkaufsstatistiken, Kategorierankings, Jahres-/Monatsanalysen usw. Diese Funktionen lassen sich oft nur schwer mit Aggregatfunktionen und Gruppierungsoperationen implementieren.
Die Fensterfunktion kann wie eine Aggregatfunktion einen Datensatz analysieren und Ergebnisse zurückgeben. Der Unterschied zwischen beiden besteht darin, dass die Fensterfunktion keinen Datensatz zu einem einzelnen Ergebnis zusammenfasst, sondern stattdessen einen Datensatz für jede Zeile analysiert von Daten. Gibt ein Ergebnis zurück. Der Unterschied zwischen Aggregatfunktionen und Fensterfunktionen ist in der folgenden Abbildung dargestellt.

Nehmen Sie die SUM-Funktion als Beispiel, um den Unterschied zwischen den beiden Funktionen zu demonstrieren. SUM() in der folgenden Anweisung ist eine Aggregatfunktion:
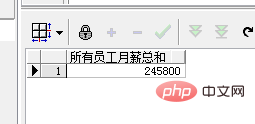
SELECT SUM(salary) AS "所有员工月薪总和" FROM employee
Die obige SUM-Funktion kann als Aggregatfunktion verwendet werden dass alle Mitarbeiterdaten zu einem Ergebnis zusammengefasst werden. Daher gibt die Abfrage das gesamte Monatsgehalt aller Mitarbeiter zurück:
SUM() in der folgenden Anweisung ist eine Fensterfunktion:
SELECT emp_name AS "员工姓名", SUM(salary) OVER () AS "所有员工月薪总和" FROM employee;
Unter diesen gibt das Schlüsselwort OVER an, dass SUM() eine Fensterfunktion ist. Leere Klammern bedeuten, dass alle Daten in einer Gruppe zusammengefasst sind. Die von dieser Abfrage zurückgegebenen Ergebnisse lauten wie folgt:
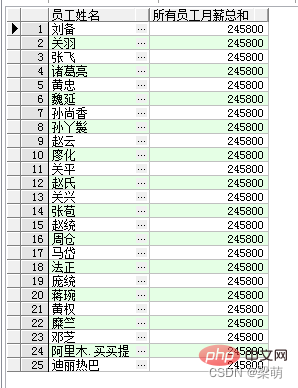
Die obigen Abfrageergebnisse geben alle Mitarbeiternamen zurück, und über die Aggregatfunktion SUM() wird für jeden Mitarbeiter das gleiche Zusammenfassungsergebnis zurückgegeben.
Wie Sie dem obigen Beispiel entnehmen können, unterscheidet sich die Syntax der Fensterfunktion von der Aggregatfunktion darin, dass sie eine OVER-Klausel enthält. Die OVER-Klausel wird verwendet, um ein Fenster für die Datenanalyse anzugeben. Die vollständige Fensterfunktionsdefinition lautet wie folgt:

wobei window_function der Name der Fensterfunktion ist, expression ein optionales Analyseobjekt (Feldname oder Ausdruck). und die OVER-Klausel enthält drei Optionen: Partition (PARTITION BY), Sortierung (ORDER BY) und Fenstergröße (frame_clause).
Tipps: Aggregationsfunktionen fassen mehrere Datenzeilen in derselben Gruppe zu einem einzigen Ergebnis zusammen, während Fensterfunktionen alle Originaldaten beibehalten. In einigen Datenbanken werden Fensterfunktionen auch als OLAP-Funktionen (Online Analytical Processing) oder Analysefunktionen bezeichnet.
Fensterfunktionskomponenten
1. Datenpartitionen erstellen
Die Option PARTITION BY in der OVER-Klausel der Fensterfunktion wird zum Definieren von Partitionen verwendet und ihre Rolle ähnelt der GROUP BY-Klausel in der Abfrageanweisung. Wenn wir die Partitionsoption angeben, analysiert die Fensterfunktion jede Partition separat.
Zum Beispiel zählt die folgende Anweisung das monatliche Gesamtgehalt der Mitarbeiter nach verschiedenen Abteilungen:
SELECT emp_name AS "员工姓名", salary "月薪", dept_id AS "部门编号", SUM(salary) OVER ( PARTITION BY dept_id ) AS "部门合计" FROM employee;
Unter diesen gibt die Option PARTITION BY die Aufteilung nach Abteilung an. Die von der Abfrage zurückgegebenen Ergebnisse lauten wie folgt:
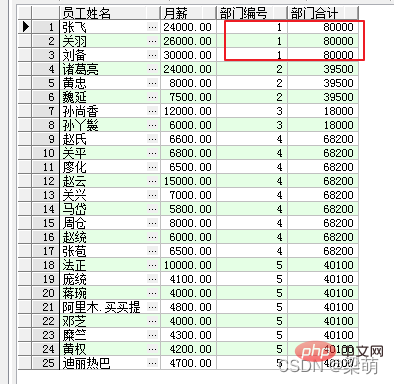
Die ersten drei Datenzeilen in den Abfrageergebnissen gehören zur selben Abteilung, daher sind die entsprechenden Abteilungsgesamtfelder gleich 80.000 (30.000 + 26.000 + 24.000). Mitarbeiter anderer Abteilungen werden analog gezählt.
Tipps: Nach Angabe der PARTITION BY-Option in der OVER-Klausel der Fensterfunktion können wir statistische Gruppenergebnisse erhalten, ohne die GROUP BY-Klausel zu verwenden.
Wenn die Option PARTITION BY nicht angegeben ist, bedeutet dies, dass alle Daten als Ganzes analysiert werden.
2. Sortieren innerhalb der Partition
Die Option ORDER BY in der OVER-Klausel der Fensterfunktion wird verwendet, um die Sortiermethode der Daten innerhalb der Partition anzugeben, und ihre Funktion ähnelt der ORDER BY-Klausel in der Abfrageanweisung .
Sortieroptionen werden normalerweise für die kategoriale Einstufung von Daten verwendet. Beispielsweise wird die folgende Anweisung verwendet, um die monatliche Gehaltsrangfolge von Mitarbeitern innerhalb der Abteilung zu analysieren:
SELECT emp_name AS "员工姓名", salary "月薪", dept_id AS "部门编号", RANK() OVER ( PARTITION BY dept_id ORDER BY salary DESC ) AS "部门内排名" FROM employee;
Darunter wird die RANK-Funktion zur Berechnung der Rangfolge der Daten verwendet, die Option PARTITION BY gibt die Partitionierung nach Abteilung an und die Die Option „Sortieren nach“ gibt das monatliche Gehalt innerhalb der Abteilung von hoch bis „Sortieren nach niedrig“ an. Die von der Abfrage zurückgegebenen Ergebnisse lauten wie folgt:
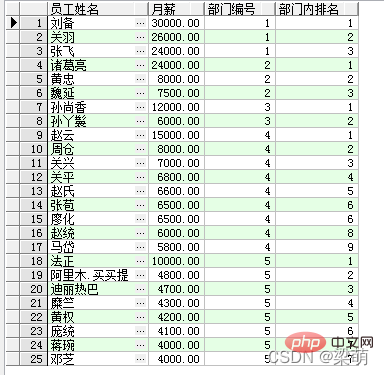
查询结果中的前3行数据属于同一个部门:“刘备”的月薪最高,在部门内排名第1;“关羽”排名第2;“张飞”排名第3。其他部门的员工采用同样的方式进行排名。
提示:窗口函数OVER子句中的ORDER BY选项和查询语句中的ORDER BY子句的使用方法相同。因此,也可以使用NULLS FIRST或者NULLS LAST选项指定空值的排序位置。
3.指定窗口大小
窗口函数OVER子句中的frame_clause选项用于指定一个移动的分析窗口,窗口总是位于分区的范围之内,是分区的一个子集。在指定了分析窗口之后,窗口函数不再基于分区进行分析,而是基于窗口内的数据进行分析。
窗口选项可以用于实现各种复杂的分析功能,例如计算累计到当前日期为止的销售额总和,每个月及其前后各N个月的平均销售额等。
指定窗口大小的具体选项如下:

其中,ROWS表示以数据行为单位计算窗口的偏移量,RANGE表示以数值(例如10天、5km等)为单位计算窗口的偏移量。
frame_start选项用于定义窗口的起始位置,可以指定以下内容之一:
●UNBOUNDED PRECEDING——表示窗口从分区的第一行开始。
●N PRECEDING——表示窗口从当前行之前的第N行开始。
●CURRENT ROW——表示窗口从当前行开始。
frame_end选项用于定义窗口的结束位置,可以指定以下内容之一:
●CURRENT ROW——表示窗口到当前行结束。
●M FOLLOWING——表示窗口到当前行之后的第M行结束。
●UNBOUNDED FOLLOWING——表示窗口到分区的最后一行结束。
下图说明了这些窗口大小选项的含义
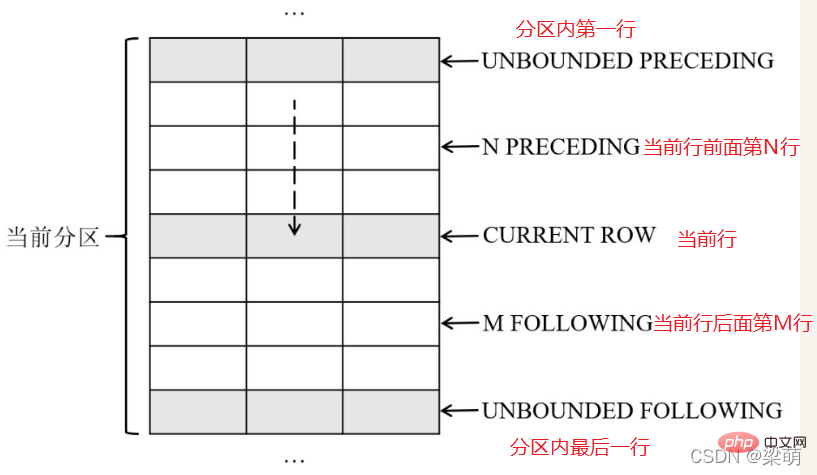
下面语句表示分析窗口从当前分区的第一行开始,直到当前行结束,即对应到图中前面5行记录。
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
窗口函数分类
1.聚合窗口函数
许多常见的聚合函数也可以作为窗口函数使用,包括AVG()、SUM()、COUNT()、MAX()以及MIN()等函数。
SQL窗口函数-聚合窗口函数
2.排名窗口函数
排名窗口函数用于对数据进行分组排名,包括ROW_NUMBER()、RANK()、DENSE_RANK()、PERCENT_RANK()、CUME_DIST()以及NTILE()等函数。
SQL窗口函数-排名窗口函数
3.取值窗口函数
取值窗口函数用于返回指定位置上的数据行,包括FIRST_VALUE()、LAST_VALUE()、LAG()、LEAD()、NTH_VALUE()等函数。
SQL窗口函数-取值窗口函数
示例表和脚本
--员工信息表 CREATE TABLE employee ( emp_id NUMBER , emp_name VARCHAR2(50) NOT NULL , sex VARCHAR2(10) NOT NULL , dept_id INTEGER NOT NULL , manager INTEGER , hire_date DATE NOT NULL , job_id INTEGER NOT NULL , salary NUMERIC(8,2) NOT NULL , bonus NUMERIC(8,2) , email VARCHAR2(100) NOT NULL , comments VARCHAR2(500) , create_by VARCHAR2(50) NOT NULL , create_ts TIMESTAMP NOT NULL , update_by VARCHAR2(50) , update_ts TIMESTAMP ) ; COMMENT ON TABLE employee IS '员工信息表'; COMMENT ON COLUMN employee.emp_id IS '员工编号,自增主键'; COMMENT ON COLUMN employee.emp_name IS '员工姓名'; COMMENT ON COLUMN employee.sex IS '性别'; COMMENT ON COLUMN employee.dept_id IS '部门编号'; COMMENT ON COLUMN employee.manager IS '上级经理'; COMMENT ON COLUMN employee.hire_date IS '入职日期'; COMMENT ON COLUMN employee.job_id IS '职位编号'; COMMENT ON COLUMN employee.salary IS '月薪'; COMMENT ON COLUMN employee.bonus IS '年终奖金'; COMMENT ON COLUMN employee.email IS '电子邮箱'; COMMENT ON COLUMN employee.comments IS '备注信息'; COMMENT ON COLUMN employee.create_by IS '创建者'; COMMENT ON COLUMN employee.create_ts IS '创建时间'; COMMENT ON COLUMN employee.update_by IS '修改者'; COMMENT ON COLUMN employee.update_ts IS '修改时间'; INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (1,'刘备', '男', 1, NULL, DATE '2000-01-01', 1, 30000, 10000, 'liubei@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (2,'关羽', '男', 1, 1, DATE '2000-01-01', 2, 26000, 10000, 'guanyu@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (3,'张飞', '男', 1, 1, DATE '2000-01-01', 2, 24000, 10000, 'zhangfei@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (4,'诸葛亮', '男', 2, 1, DATE '2006-03-15', 3, 24000, 8000, 'zhugeliang@shuguo.com', NULL, 'Admin', TIMESTAMP '2006-03-15 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (5,'黄忠', '男', 2, 4, DATE '2008-10-25', 4, 8000, NULL, 'huangzhong@shuguo.com', NULL, 'Admin', TIMESTAMP '2008-10-25 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (6,'魏延', '男', 2, 4, DATE '2007-04-01', 4, 7500, NULL, 'weiyan@shuguo.com', NULL, 'Admin', TIMESTAMP '2007-04-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (7,'孙尚香', '女', 3, 1, DATE '2002-08-08', 5, 12000, 5000, 'sunshangxiang@shuguo.com', NULL, 'Admin', TIMESTAMP '2002-08-08 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (8,'孙丫鬟', '女', 3, 7, DATE '2002-08-08', 6, 6000, NULL, 'sunyahuan@shuguo.com', NULL, 'Admin', TIMESTAMP '2002-08-08 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (9,'赵云', '男', 4, 1, DATE '2005-12-19', 7, 15000, 6000, 'zhaoyun@shuguo.com', NULL, 'Admin', TIMESTAMP '2005-12-19 10:00:00', 'Admin', TIMESTAMP '2006-12-31 10:00:00'); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (10,'廖化', '男', 4, 9, DATE '2009-02-17', 8, 6500, NULL, 'liaohua@shuguo.com', NULL, 'Admin', TIMESTAMP '2009-02-17 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (11,'关平', '男', 4, 9, DATE '2011-07-24', 8, 6800, NULL, 'guanping@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-07-24 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (12,'赵氏', '女', 4, 9, DATE '2011-11-10', 8, 6600, NULL, 'zhaoshi@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-11-10 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (13,'关兴', '男', 4, 9, DATE '2011-07-30', 8, 7000, NULL, 'guanxing@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-07-30 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (14,'张苞', '男', 4, 9, DATE '2012-05-31', 8, 6500, NULL, 'zhangbao@shuguo.com', NULL, 'Admin', TIMESTAMP '2012-05-31 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (15,'赵统', '男', 4, 9, DATE '2012-05-03', 8, 6000, NULL, 'zhaotong@shuguo.com', NULL, 'Admin', TIMESTAMP '2012-05-03 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (16,'周仓', '男', 4, 9, DATE '2010-02-20', 8, 8000, NULL, 'zhoucang@shuguo.com', NULL, 'Admin', TIMESTAMP '2010-02-20 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (17,'马岱', '男', 4, 9, DATE '2014-09-16', 8, 5800, NULL, 'madai@shuguo.com', NULL, 'Admin', TIMESTAMP '2014-09-16 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (18,'法正', '男', 5, 2, DATE '2017-04-09', 9, 10000, 5000, 'fazheng@shuguo.com', NULL, 'Admin', TIMESTAMP '2017-04-09 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (19,'庞统', '男', 5, 18, DATE '2017-06-06', 10, 4100, 2000, 'pangtong@shuguo.com', NULL, 'Admin', TIMESTAMP '2017-06-06 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (20,'蒋琬', '男', 5, 18, DATE '2018-01-28', 10, 4000, 1500, 'jiangwan@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-01-28 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (21,'黄权', '男', 5, 18, DATE '2018-03-14', 10, 4200, NULL, 'huangquan@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-03-14 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (22,'糜竺', '男', 5, 18, DATE '2018-03-27', 10, 4300, NULL, 'mizhu@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-03-27 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (23,'邓芝', '男', 5, 18, DATE '2018-11-11', 10, 4000, NULL, 'dengzhi@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-11-11 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (24,'简雍', '男', 5, 18, DATE '2019-05-11', 10, 4800, NULL, 'jianyong@shuguo.com', NULL, 'Admin', TIMESTAMP '2019-05-11 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (25,'孙乾', '男', 5, 18, DATE '2018-10-09', 10, 4700, NULL, 'sunqian@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-10-09 10:00:00', NULL, NULL);
推荐学习:《SQL教程》
Das obige ist der detaillierte Inhalt vonAusführliche Erläuterung der SQL-Fensterfunktionen in einem Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Was ist der Unterschied zwischen HQL und SQL im Hibernate-Framework?
Apr 17, 2024 pm 02:57 PM
Was ist der Unterschied zwischen HQL und SQL im Hibernate-Framework?
Apr 17, 2024 pm 02:57 PM
HQL und SQL werden im Hibernate-Framework verglichen: HQL (1. Objektorientierte Syntax, 2. Datenbankunabhängige Abfragen, 3. Typsicherheit), während SQL die Datenbank direkt betreibt (1. Datenbankunabhängige Standards, 2. Komplexe ausführbare Datei). Abfragen und Datenmanipulation).
 Verwendung der Divisionsoperation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
Verwendung der Divisionsoperation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
„Verwendung der Divisionsoperation in OracleSQL“ In OracleSQL ist die Divisionsoperation eine der häufigsten mathematischen Operationen. Während der Datenabfrage und -verarbeitung können uns Divisionsoperationen dabei helfen, das Verhältnis zwischen Feldern zu berechnen oder die logische Beziehung zwischen bestimmten Werten abzuleiten. In diesem Artikel wird die Verwendung der Divisionsoperation in OracleSQL vorgestellt und spezifische Codebeispiele bereitgestellt. 1. Zwei Arten von Divisionsoperationen in OracleSQL In OracleSQL können Divisionsoperationen auf zwei verschiedene Arten durchgeführt werden.
 Vergleich und Unterschiede der SQL-Syntax zwischen Oracle und DB2
Mar 11, 2024 pm 12:09 PM
Vergleich und Unterschiede der SQL-Syntax zwischen Oracle und DB2
Mar 11, 2024 pm 12:09 PM
Oracle und DB2 sind zwei häufig verwendete relationale Datenbankverwaltungssysteme, die jeweils über ihre eigene, einzigartige SQL-Syntax und -Eigenschaften verfügen. In diesem Artikel werden die SQL-Syntax von Oracle und DB2 verglichen und unterschieden und spezifische Codebeispiele bereitgestellt. Datenbankverbindung Verwenden Sie in Oracle die folgende Anweisung, um eine Verbindung zur Datenbank herzustellen: CONNECTusername/password@database. In DB2 lautet die Anweisung zum Herstellen einer Verbindung zur Datenbank wie folgt: CONNECTTOdataba
 Ausführliche Erläuterung der Funktion „Tag festlegen' in den dynamischen SQL-Tags von MyBatis
Feb 26, 2024 pm 07:48 PM
Ausführliche Erläuterung der Funktion „Tag festlegen' in den dynamischen SQL-Tags von MyBatis
Feb 26, 2024 pm 07:48 PM
Interpretation der dynamischen SQL-Tags von MyBatis: Detaillierte Erläuterung der Verwendung von Set-Tags. MyBatis ist ein hervorragendes Persistenzschicht-Framework. Es bietet eine Fülle dynamischer SQL-Tags und kann Datenbankoperationsanweisungen flexibel erstellen. Unter anderem wird das Set-Tag zum Generieren der SET-Klausel in der UPDATE-Anweisung verwendet, die sehr häufig bei Aktualisierungsvorgängen verwendet wird. In diesem Artikel wird die Verwendung des Set-Tags in MyBatis ausführlich erläutert und seine Funktionalität anhand spezifischer Codebeispiele demonstriert. Was ist Set-Tag? Set-Tag wird in MyBati verwendet
 Was bedeutet das Identitätsattribut in SQL?
Feb 19, 2024 am 11:24 AM
Was bedeutet das Identitätsattribut in SQL?
Feb 19, 2024 am 11:24 AM
Was ist Identität in SQL? In SQL ist Identität ein spezieller Datentyp, der zum Generieren automatisch inkrementierender Zahlen verwendet wird. Er wird häufig verwendet, um jede Datenzeile in einer Tabelle eindeutig zu identifizieren. Die Spalte „Identität“ wird oft in Verbindung mit der Primärschlüsselspalte verwendet, um sicherzustellen, dass jeder Datensatz eine eindeutige Kennung hat. In diesem Artikel wird die Verwendung von Identity detailliert beschrieben und es werden einige praktische Codebeispiele aufgeführt. Die grundlegende Möglichkeit, Identity zu verwenden, besteht darin, Identit beim Erstellen einer Tabelle zu verwenden.
 So implementieren Sie Springboot+Mybatis-plus, ohne SQL-Anweisungen zum Hinzufügen mehrerer Tabellen zu verwenden
Jun 02, 2023 am 11:07 AM
So implementieren Sie Springboot+Mybatis-plus, ohne SQL-Anweisungen zum Hinzufügen mehrerer Tabellen zu verwenden
Jun 02, 2023 am 11:07 AM
Wenn Springboot + Mybatis-plus keine SQL-Anweisungen zum Hinzufügen mehrerer Tabellen verwendet, werden die Probleme, auf die ich gestoßen bin, durch die Simulation des Denkens in der Testumgebung zerlegt: Erstellen Sie ein BrandDTO-Objekt mit Parametern, um die Übergabe von Parametern an den Hintergrund zu simulieren dass es äußerst schwierig ist, Multi-Table-Operationen in Mybatis-plus durchzuführen. Wenn Sie keine Tools wie Mybatis-plus-join verwenden, können Sie nur die entsprechende Mapper.xml-Datei konfigurieren und die stinkende und lange ResultMap konfigurieren Schreiben Sie die entsprechende SQL-Anweisung. Obwohl diese Methode umständlich erscheint, ist sie äußerst flexibel und ermöglicht es uns
 So beheben Sie den 5120-Fehler in SQL
Mar 06, 2024 pm 04:33 PM
So beheben Sie den 5120-Fehler in SQL
Mar 06, 2024 pm 04:33 PM
Lösung: 1. Überprüfen Sie, ob der angemeldete Benutzer über ausreichende Berechtigungen zum Zugriff auf oder zum Betrieb der Datenbank verfügt, und stellen Sie sicher, dass der Benutzer über die richtigen Berechtigungen verfügt. 2. Überprüfen Sie, ob das Konto des SQL Server-Dienstes über die Berechtigung zum Zugriff auf die angegebene Datei verfügt Ordner und stellen Sie sicher, dass das Konto über ausreichende Berechtigungen zum Lesen und Schreiben der Datei oder des Ordners verfügt. 3. Überprüfen Sie, ob die angegebene Datenbankdatei von anderen Prozessen geöffnet oder gesperrt wurde. Versuchen Sie, die Datei zu schließen oder freizugeben, und führen Sie die Abfrage erneut aus . Versuchen Sie es als Administrator. Führen Sie Management Studio aus als usw.
 Wie verwende ich SQL-Anweisungen zur Datenaggregation und Statistik in MySQL?
Dec 17, 2023 am 08:41 AM
Wie verwende ich SQL-Anweisungen zur Datenaggregation und Statistik in MySQL?
Dec 17, 2023 am 08:41 AM
Wie verwende ich SQL-Anweisungen zur Datenaggregation und Statistik in MySQL? Datenaggregation und Statistiken sind sehr wichtige Schritte bei der Durchführung von Datenanalysen und Statistiken. Als leistungsstarkes relationales Datenbankverwaltungssystem bietet MySQL eine Fülle von Aggregations- und Statistikfunktionen, mit denen Datenaggregation und statistische Operationen problemlos durchgeführt werden können. In diesem Artikel wird die Methode zur Verwendung von SQL-Anweisungen zur Durchführung von Datenaggregation und Statistiken in MySQL vorgestellt und spezifische Codebeispiele bereitgestellt. 1. Verwenden Sie zum Zählen die COUNT-Funktion. Die COUNT-Funktion wird am häufigsten verwendet
