

Dieser Artikel vermittelt Ihnen relevantes Wissen über Python, das hauptsächlich Probleme im Zusammenhang mit dem Random-Forest-Modell organisiert, einschließlich einer Einführung in das Ensemble-Modell, Grundprinzipien des Random-Forest-Modells, Verwendung von sklearn zur Implementierung des Random-Forest-Modells usw. , Schauen wir es uns gemeinsam an, ich hoffe, es wird für alle hilfreich sein.

【Verwandte Empfehlungen: Python3-Video-Tutorial】
Das Ensemble-Lernmodell verwendet eine Reihe von schwachen Lernenden (auch Basismodelle oder Basismodelle genannt), um jedes zu lernen und zu kombinieren Die Ergebnisse schwacher Lernender werden integriert, um bessere Lernergebnisse als bei einem einzelnen Lernenden zu erzielen.
Zu den gängigen Algorithmen für integrierte Lernmodelle gehören der Bagging-Algorithmus und der Boosting-Algorithmus.
Das typische maschinelle Lernmodell des Bagging-Algorithmus ist das Random-Forest-Modell, während die typischen maschinellen Lernmodelle des Boosting-Algorithmus die Modelle AdaBoost, GBDT, XGBoost und LightGBM sind.
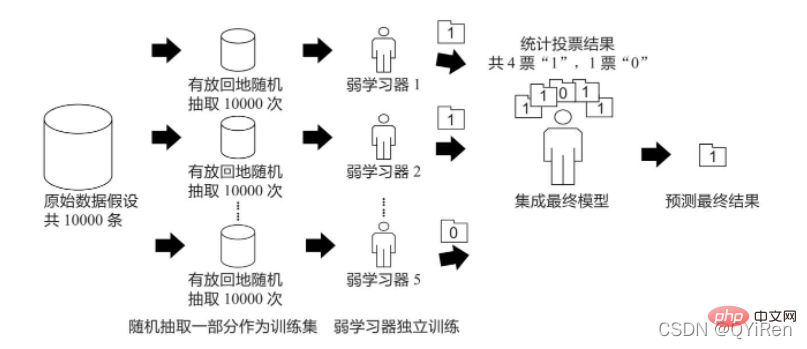
Das Prinzip des Bagging-Algorithmus ähnelt der Abstimmung. Jeder schwache Lernende hat eine Stimme. Basierend auf den Stimmen aller schwachen Lernenden wird schließlich das endgültige Vorhersageergebnis gemäß dem Prinzip generiert. „Minderheit gehorcht der Mehrheit“, wie in der folgenden Abbildung dargestellt.
Angenommen, es gibt 10.000 Originaldaten und 10.000 Daten werden zufällig ausgewählt und ersetzt, um einen neuen Trainingssatz zu bilden (da eine zufällige Stichprobe mit Ersetzung erfolgt, kann ein bestimmtes Datenelement mehrmals ausgewählt werden (Es ist auch möglich, dass ein bestimmtes Datenelement nicht einmal ausgewählt wurde) und ein schwacher Lernender jedes Mal mithilfe eines Trainingssatzes trainiert wird. Auf diese Weise können nach n-maliger Zufallsstichprobe und Ersetzung am Ende des Trainings n schwache Lernende, die durch verschiedene Trainingssätze trainiert wurden, gemäß dem Prinzip „der“ erhalten werden „Minderheit gehorcht der Mehrheit“, um ein genaueres und vernünftigeres endgültiges Vorhersageergebnis zu erhalten.
Konkret werden beim Klassifizierungsproblem n schwache Lernende zur Abstimmung verwendet, um das Endergebnis zu erhalten, und beim Regressionsproblem wird der Durchschnitt von n schwachen Lernenden als Endergebnis herangezogen.
Der Unterschied zwischen ihm und dem Bagging-Algorithmus besteht darin, dass er alle schwachen Lernenden gleich behandelt Behandlung bedeutet für Laien, sich auf die „Kultivierung von Eliten“ und „auf Fehler zu achten“ zu konzentrieren.
„Elitenbildung“ bedeutet, dass nach jeder Trainingsrunde schwächere Lernende mit genaueren Vorhersageergebnissen ein höheres Gewicht erhalten und schwache Lernende mit schlechter Leistung ein geringeres Gewicht erhalten. Auf diese Weise hat das „ausgezeichnete Modell“ in der endgültigen Vorhersage ein großes Gewicht, was bedeutet, dass es mehrere Stimmen abgeben kann, während das „allgemeine Modell“ nur eine Stimme abgeben kann oder nicht abstimmen kann.
„Auf Fehler achten“ bedeutet, die Gewichtung oder Wahrscheinlichkeitsverteilung des Trainingssatzes nach jeder Trainingsrunde zu ändern, indem die Gewichtung der Beispiele erhöht wird, die vom schwachen Lernenden in der vorherigen Runde falsch vorhergesagt wurden, und die Gewichtung verringert wird der Beispiele, die der schwache Lernende in der vorherigen Runde falsch gelernt hat. Die Gewichtung des von der Maschine vorhergesagten richtigen Beispiels wird verwendet, um den Schwerpunkt des schwachen Lernenden auf die Daten zu erhöhen, die falsch vorhersagen, wodurch der Gesamtvorhersageeffekt verbessert wird des Modells.
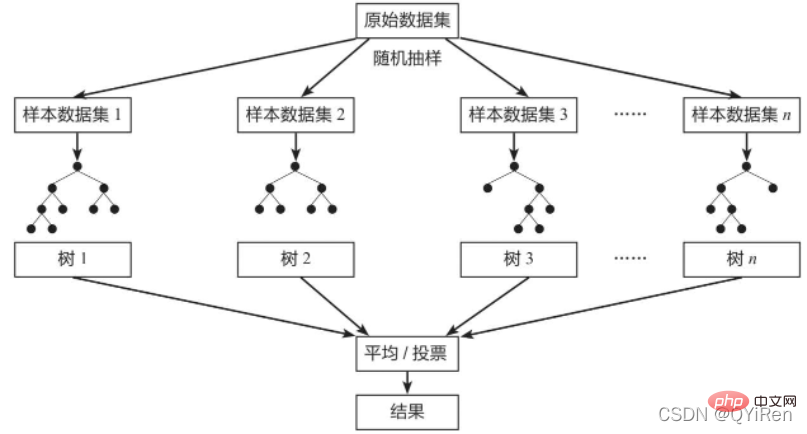
2 Grundprinzipien des Random-Forest-ModellsRandom Forest (Random Forest) ist ein klassisches Bagging-Modell und sein schwacher Lerner ist ein Entscheidungsbaummodell. Wie in der Abbildung unten gezeigt, erstellt das Zufallswaldmodell zufällig Stichproben aus dem Originaldatensatz, um n verschiedene Beispieldatensätze zu bilden, und erstellt dann n verschiedene Entscheidungsbaummodelle basierend auf diesen Datensätzen und schließlich basierend auf dem Durchschnitt dieser Datensätze Entscheidungsbaummodelle (für Regressionsmodelle) oder Abstimmungen (für Klassifizierungsmodelle), um die Endergebnisse zu erhalten.
Um die Generalisierungsfähigkeit (oder Universalfähigkeit) des Modells sicherzustellen, folgt das Zufallswaldmodell beim Aufbau jedes Baums häufig den beiden Grundprinzipien „Zufallsdaten“ und „Zufallsmerkmale“.
Im Vergleich zu einem einzelnen Entscheidungsbaummodell integriert das Zufallswaldmodell mehrere Entscheidungsbäume, sodass seine Vorhersageergebnisse genauer sind, es nicht leicht zu einer Überanpassung kommt und seine Generalisierungsfähigkeit stärker ist.Zufallsdaten: Extrahieren Sie zufällig Daten aus allen Daten und ersetzen Sie sie als Trainingsdaten für eines der Entscheidungsbaummodelle. Beispielsweise gibt es 1.000 Originaldaten, die 1.000 Mal extrahiert und ersetzt werden, um einen neuen Datensatz zum Trainieren eines bestimmten Entscheidungsbaummodells zu bilden.
Merkmal zufällig: Wenn die Merkmalsdimension jeder Stichprobe M ist, geben Sie eine Konstante k
Der Code lautet wie folgt.
from sklearn.ensemble import RandomForestClassifier X = [[1,2],[3,4],[5,6],[7,8],[9,10]] y = [0,0,0,1,1] # 设置弱学习器数量为10 model = RandomForestClassifier(n_estimators=10,random_state=123) model.fit(X,y) model.predict([[5,5]]) # 输出为:array([0])
4.1 Generierung von Aktienderivatvariablen
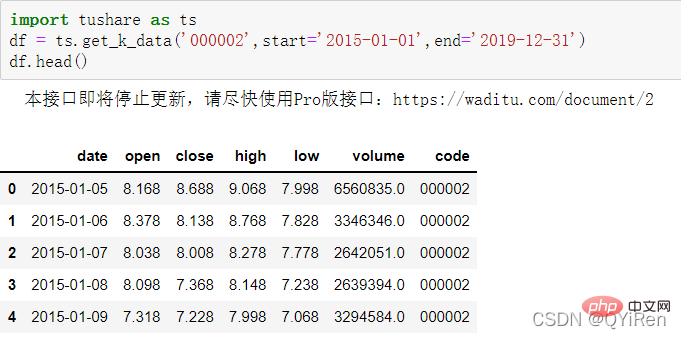
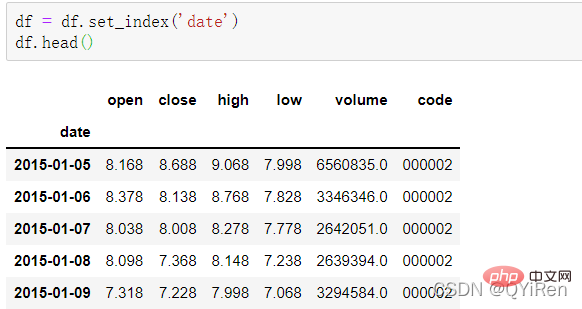
In diesem Abschnitt wird erläutert, wie die Grunddaten von Aktien verwendet werden, um einige derivative Variablendaten zu erhalten, z. B. den gleitenden 5-Tage-Durchschnittspreis MA5 und 10, häufig verwendete gleitende Durchschnittsindikatoren in der technischen Aktienanalyse MA10, relativer Stärkeindikator RSI, Momentumindikator MOM, exponentieller gleitender Durchschnitt EMA, gleitende durchschnittliche Konvergenz und Divergenz MACD usw. 4.1.1 Grundlegende Bestandsdaten abrufenVerwenden Sie zunächst die Funktion get_k_data(), um die grundlegenden Bestandsdaten vom 01.01.2015 bis zum 31.12.2019 abzurufen. Die ersten 5 Datenzeilen sind in der folgenden Abbildung dargestellt. Bei den fehlenden Daten handelt es sich um Feiertagsdaten (keine Handelstage). Verwenden Sie die Funktion set_index(), um die Datumsspalte auf den Zeilenindex festzulegen, der Code lautet wie folgt.
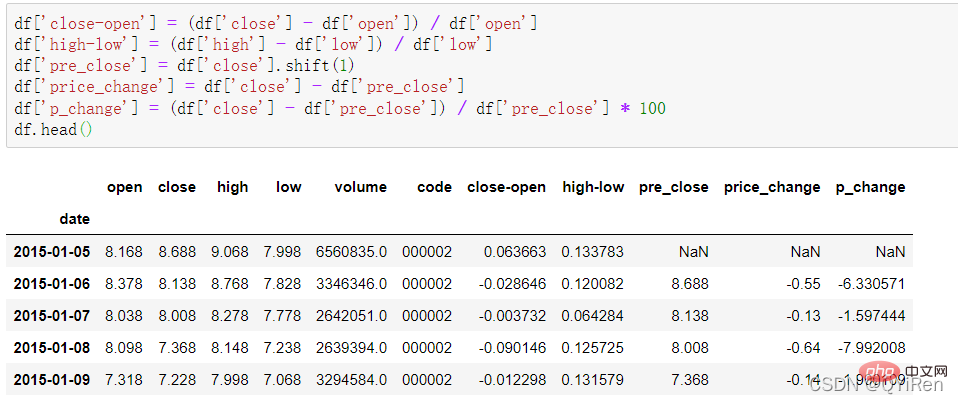
4.1.2 Generieren einfacher abgeleiteter VariablenEinige einfache abgeleitete Variablendaten können mit dem folgenden Code generiert werden.
high-low bedeutet (höchster Preis – niedrigster Preis);
pre_close bedeutet den gestrigen Schlusskurs, verwenden Sie Verschiebung (1) Verschieben Sie alle Daten in der Schlussspalte um eine Zeile nach unten und bilden Sie eine neue Spalte. Wenn es sich um eine Verschiebung (-1) handelt, bedeutet dies, dass sich der Schlusskurs um eine Zeile nach oben bewegt ist an diesem Tag Die Aktienkursänderung;
p_change stellt die prozentuale Änderung des Aktienkurses an diesem Tag dar, auch bekannt als Anstieg oder Rückgang des Aktienkurses an diesem Tag.
4.1.3 Erzeugen Sie den MA-Wert des gleitenden Durchschnittsindikators
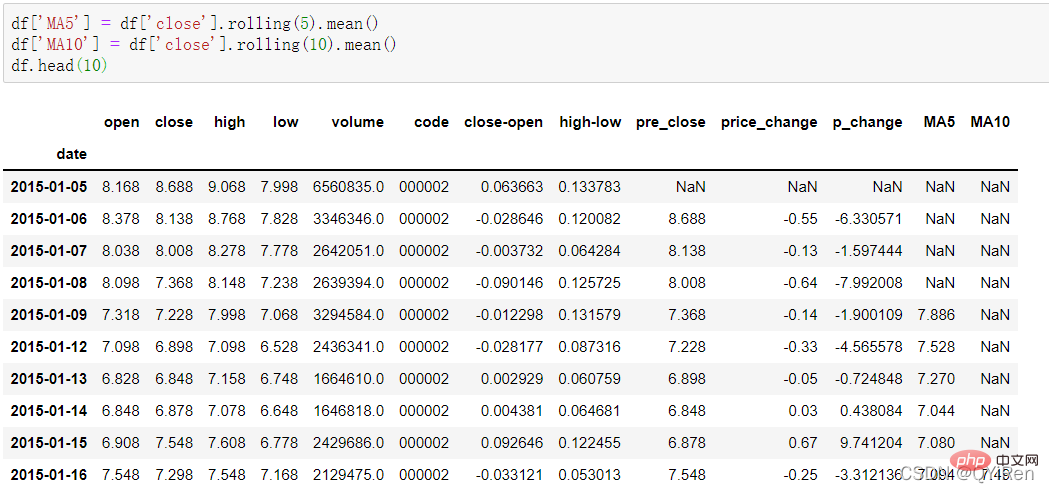
Der gleitende 5-Tage-Durchschnitt und der gleitende 10-Tage-Durchschnitt des Aktienkurses können mit dem folgenden Code generiert werden.
Hinweis: Die Verwendung der Rollfunktion
Dabei bedeutet MA gleitender Durchschnitt, „Durchschnitt“ bezieht sich auf das arithmetische Mittel des Abschlusses der letzten n Tage und „gleitend“ bezieht sich auf immer in Für die Berechnung werden die Preisdaten der letzten n Tage verwendet.Zum Beispiel: MA5-Berechnung
Da bei der Berechnung von Daten wie MA5 die Datenmenge in den ersten 4 Tagen nicht ausreicht, kann der diesen 4 Tagen entsprechende gleitende Durchschnitt nicht berechnet werden, sodass ein Nullwert NaN generiert wird. Normalerweise wird die Funktion dropna() zum Löschen von Nullwerten verwendet, um Probleme durch Nullwerte bei nachfolgenden Berechnungen zu vermeiden. Der Code lautet wie folgt.Gemäß den obigen Daten beträgt der MA5-Wert von Nr. 5 (1,2+1,4+1,6+1,8+2,0)/5=1,6, während der MA5-Wert von Nr. 6 ist (1,4 + 1,6 + 1,8 + 2,0 + 2,2)/5 = 1,8 und so weiter. Der gleitende Durchschnitt der Aktienkurse über einen bestimmten Zeitraum wird zu einer Kurve verbunden, die der gleitende Durchschnitt ist. Ebenso ist MA10 der durchschnittliche Aktienkurs der letzten 10 Tage ab dem Tag der Berechnung.
Der RSI-Wert des Relative Strength Index kann mit dem folgenden Code generiert werden.
Sie können sehen, dass die Zeilen vor dem 16. gelöscht wurden.
4.1.4 Verwenden Sie die TA-Lib-Bibliothek, um den RSI-Wert des Relative Strength Index zu generieren
Der RSI-Wert kann die Stärke des Aktienkursanstiegs im Verhältnis zum kurzfristigen Rückgang widerspiegeln
und uns dabei helfen, den Anstiegs- und Falltrend des Aktienkurses besser einzuschätzen.Je größer der RSI-Wert, desto stärker ist der Aufwärtstrend im Vergleich zum Abwärtstrend und umgekehrt, desto schwächer ist der Aufwärtstrend im Vergleich zum Abwärtstrend.
Die Berechnungsformel des RSI-Werts lautet wie folgt.
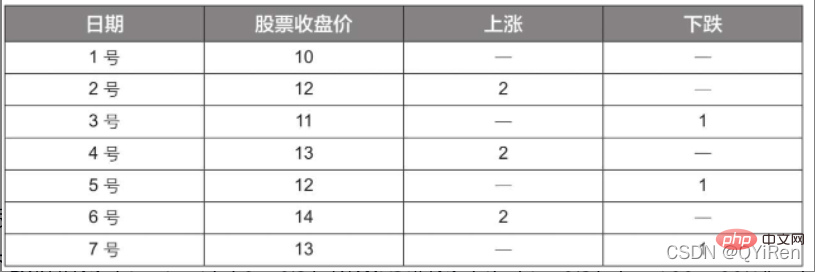
Beispiel:
Gemäß den Daten in der obigen Tabelle kann bei Annahme von N=6 der durchschnittlich steigende Preis in 6 Tagen als (2+2+2)/6=1 ermittelt werden, und der Der durchschnittliche fallende Preis in 6 Tagen beträgt (1+1+1)/6=0,5, der RSI-Wert beträgt also (1/(1+0,5))×100=66,7.
Normalerweise liegt der RSI-Wert zwischen 20 und 80. Wenn er 80 überschreitet, ist er überkauft, wenn er unter 20 liegt, ist er überverkauft. Wenn er 50 beträgt, wird davon ausgegangen, dass die Macht von Käufern und Verkäufern besteht ist gleich. Wenn der Aktienkurs beispielsweise an 6 aufeinanderfolgenden Tagen steigt, beträgt der durchschnittliche fallende Preis am 6. Tag 0 und der RSI-Wert am 6. Tag beträgt 100. Dies zeigt an, dass sich der Aktienkäufer in einer sehr starken Position befindet Dieses Mal werden Anleger jedoch auch daran erinnert, dass dies auch ein übermäßiger Zeitraum sein kann. Im Kaufzustand müssen Sie das Risiko eines Rückgangs des Aktienkurses verhindern.
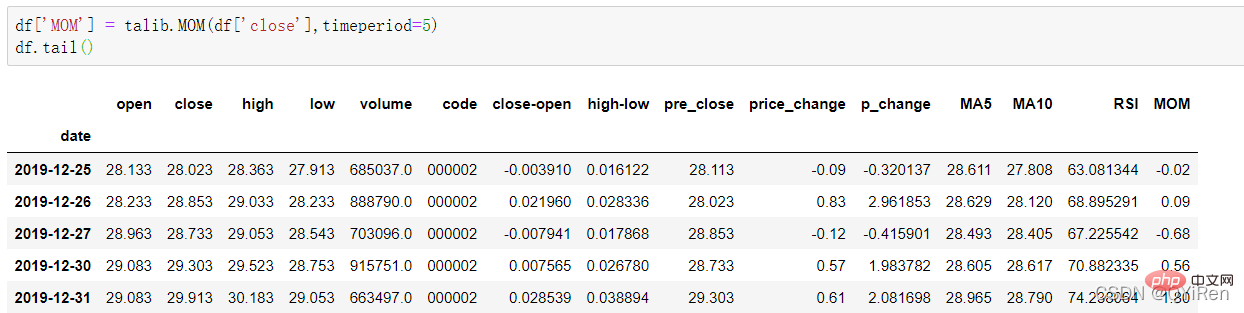
Sie können den MOM-Wert des Momentum-Indikators mit dem folgenden Code generieren.
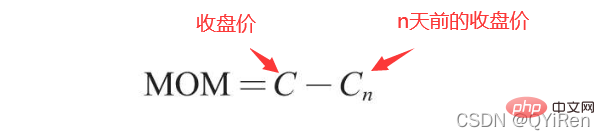
MOM ist die Abkürzung für Momentum, die die Anstiegs- und Fallrate der Aktienkurse über einen bestimmten Zeitraum widerspiegelt . Die Berechnungsformel lautet wie folgt.
Beispiel:
Angenommen, Sie möchten den MOM-Wert von Nr. 6 berechnen und der Parameter timeperiod ist im vorherigen Code auf 5 gesetzt, dann müssen Sie den Schlusskurs von subtrahieren Nr. 1 aus dem Schlusskurs von Nr. 6, d. h. der MOM-Wert von Nr. 6 beträgt 2,2-1,2=1. Ebenso beträgt der MOM-Wert von Nr. 7 2,4-1,4=1. Durch die Verbindung der MOM-Werte für aufeinanderfolgende Tage entsteht eine Kurve, die den Anstieg und Rückgang des Aktienkurses widerspiegelt.
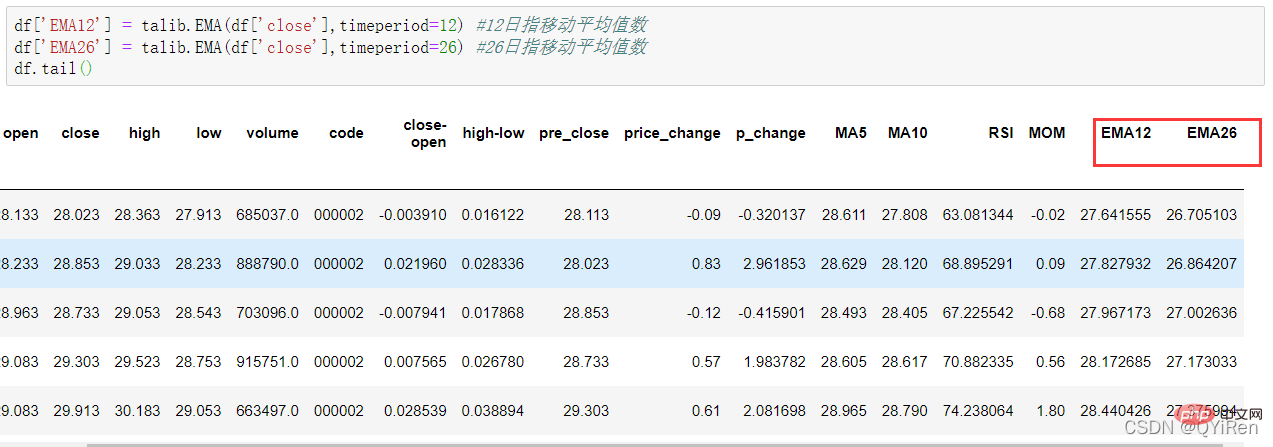
Sie können einen exponentiellen gleitenden Durchschnitt EMA mit dem folgenden Code generieren.
EMA ist ein exponentiell abnehmender gewichteter gleitender Durchschnitt und wird auf der Grundlage der Berechnungsergebnisse analysiert. Es wird verwendet, um den Trend zukünftiger Aktienkurstrends zu bestimmen.
Die Berechnungsformel von EMA lautet wie folgt.
Unter diesen ist EMAtoday der EMA-Wert des Tages; EMAyesterday ist der gestrige EMA-Wert; im Allgemeinen ist der Wert 2/(N+1), N stellt die Anzahl der Tage dar. Wenn N 6 ist, beträgt α 2/7, und der entsprechende EMA heißt EMA6, was der exponentielle gleitende 6-Tage-Durchschnitt ist. Die Formel rekursiert so lange, bis der erste EMA-Wert erscheint (der erste EMA-Wert ist normalerweise der Durchschnitt der ersten fünf Zahlen).
Beispiel: EMA6
Der erste EMA-Wert ist der Durchschnitt der ersten 5 Zahlen, es gibt also keinen EMA-Wert in den ersten 5 Tagen; der EMA-Wert von Nr. 6 ist der erste EMA-Wert ist der Mittelwert der ersten 5 Tage 1; der EMA-Wert von Nr. 7 ist der zweite EMA-Wert. Der Berechnungsprozess ist wie folgt.
Sie können MACD-Werte für die Konvergenz und Divergenz des gleitenden Durchschnitts mit dem folgenden Code generieren.
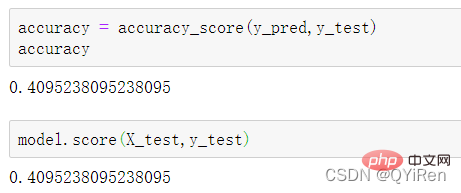
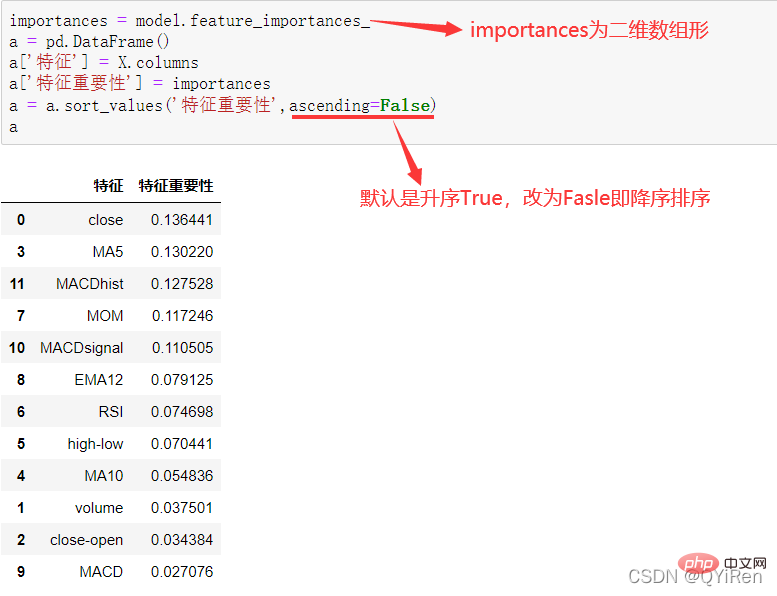
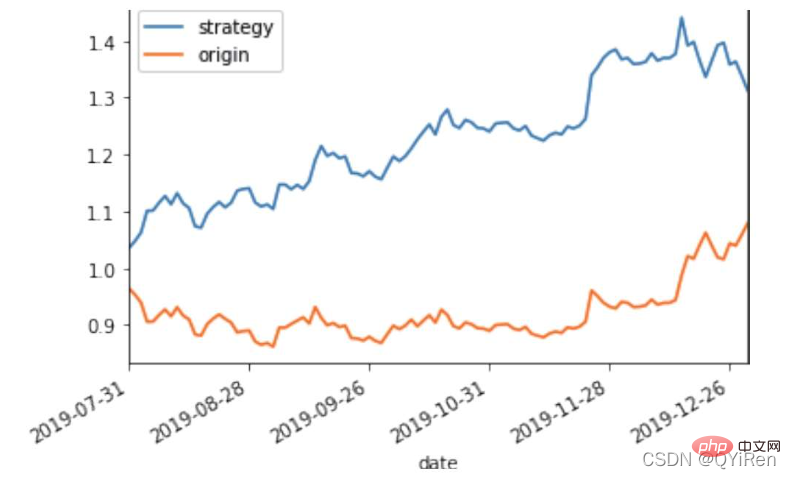
MACD ist ein häufig verwendeter Indikator auf der Grundlage des EMA-Werts. Die Berechnungsmethode ist relativ kompliziert. Hier müssen Sie nur wissen, dass MACD ein Trendindikator ist und seine Änderungen Änderungen in Markttrends darstellen. MACD auf verschiedenen K-Linien-Ebenen repräsentiert den Kauf- und Verkaufstrend im aktuellen Niveauzyklus. 首先强调最核心的一点:应该是用当天的股价数据预测下一天的股价涨跌情况,所以目标变量y应该是下一天的股价涨跌情况。为什么是用当天的股价数据预测下一天的股价涨跌情况呢?这是因为特征变量中的很多数据只有在当天交易结束后才能确定(例如,收盘价close只有收盘了才有),所以当天正在交易时的股价涨跌情况是无法预测的,而等到收盘时尽管所需数据齐备,但是当天的股价涨跌情况已成定局,也就没有必要预测了,所以是用当天的股价数据预测下一天的股价涨跌情况。 第2行代码中使用了NumPy库中的where()函数,传入的3个参数的含义分别为判断条件、满足条件的赋值、不满足条件的赋值。其中df['price_change'].shift(-1)是利用shift()函数将price_change(股价变化)这一列的所有数据向上移动1行,这样就获得了每一行对应的下一天的股价变化。因此,这里的判断条件就是下一天的股价变化是否大于0,如果大于0,说明下一天股价涨了,则y赋值为1;如果不大于0,说明下一天股价不变或跌了,则y赋值为-1。预测结果就只有1或-1两种分类。 这里需要注意的是,划分要按照时间序列进行,而不能用train_test_split()函数进行随机划分。这是因为股价的变化趋势具有时间性特征,而随机划分会破坏这种特征,所以需要根据当天的股价数据预测下一天的股价涨跌情况,而不能根据任意一天的股价数据预测下一天的股价涨跌情况。 将前90%的数据作为训练集,后10%的数据作为测试集,代码如下。 设置模型参数:决策树的最大深度max_depth设置为3,即每个决策树最多只有3层;弱学习器(即决策树模型)的个数n_estimators设置为10,即该随机森林中共有10个决策树;叶子节点的最小样本数min_samples_leaf设置为10,即如果叶子节点的样本数小于10则停止分裂;随机状态参数random_state的作用是使每次运行结果保持一致,这里设置的数字123没有特殊含义,可以换成其他数字。 用predict_proba()函数可以预测属于各个分类的概率,代码如下。 通过如下代码可以查看整体的预测准确度。 打印输出score为0.40,说明模型对整个测试集中约40%的数据预测正确。这一预测准确度并不算高,也的确符合股票市场千变万化的特点。 通过如下代码可以分析各个特征变量的特征重要性。 由图可知,当日收盘价close、MA5、MACDhist相关指标等特征变量对下一天股价涨跌结果的预测准确度影响较大。 前面已经评估了模型的预测准确度,不过在商业实战中,更关心它的收益回测曲线(又称为净值曲线),也就是看根据搭建的模型获得的结果是否比不利用模型获得的结果更好。 可视化结果如下图所示。图中上方的曲线为根据模型得到的收益率曲线,下方的曲线为股票本身的收益率曲线,可以看到,利用模型得到的收益还是不错的。 要说明的是,这里讲解的量化金融内容比较浅显,搭建的模型过于理想化,真正的股市是错综复杂的,股票交易也有很多限制,如不能做空、不能T+0交易,还要考虑手续费等因素。 随机森林模型是一种非常重要的集成模型,它集成了决策树模型的众多优点,又规避了决策树模型容易过度拟合等缺点,在实战中应用较为广泛。 【相关推荐:Python3视频教程 】4.2 模型搭建
4.2.1 引入需要搭建的库
# 导入相关库
import tushare as ts
import numpy as np
import pandas as pd
import talib
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
4.2.2 获取数据
# 1.股票基本数据获取
import tushare as ts
df = ts.get_k_data('000002',start='2015-01-01',end='2019-12-31')
df = df.set_index('date')
# 2.简单衍生变量数据构造
df['close-open'] = (df['close'] - df['open']) / df['open']
df['high-low'] = (df['high'] - df['low']) / df['low']
df['pre_close'] = df['close'].shift(1)
df['price_change'] = df['close'] - df['pre_close']
df['p_change'] = (df['close'] - df['pre_close']) / df['pre_close'] * 100
# 3.移动平均线相关数据构造
df['MA5'] = df['close'].rolling(5).mean()
df['MA10'] = df['close'].rolling(10).mean()
df.dropna(inplace=True)
# 4.通过TA-Lib库构造衍生变量数据
df['RSI'] = talib.RSI(df['close'],timeperiod=12)
df['MOM'] = talib.MOM(df['close'],timeperiod=5)
df['EMA12'] = talib.EMA(df['close'],timeperiod=12) #12日指移动平均值数
df['EMA26'] = talib.EMA(df['close'],timeperiod=26) #26日指移动平均值数
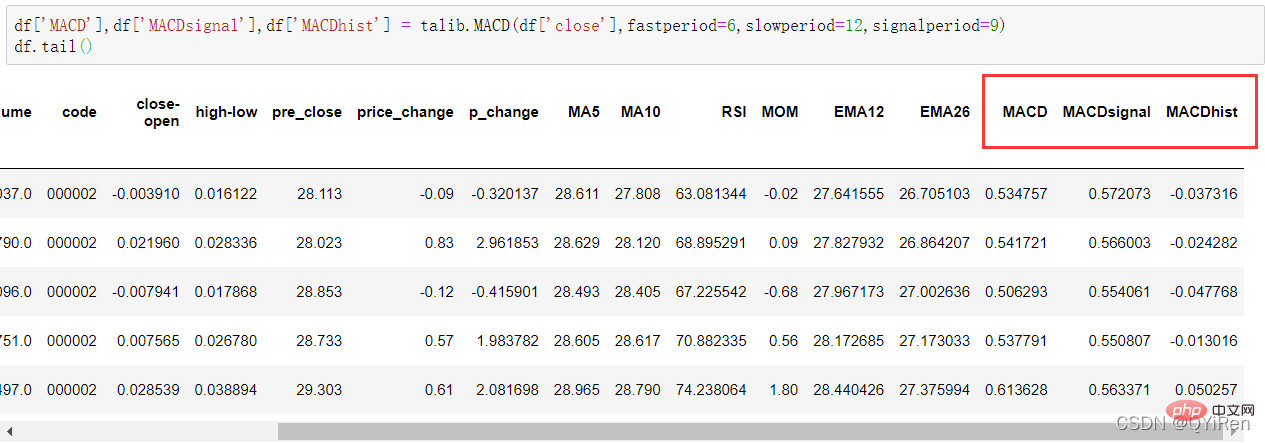
df['MACD'],df['MACDsignal'],df['MACDhist'] = talib.MACD(df['close'],fastperiod=6,slowperiod=12,signalperiod=9)
df.dropna(inplace=True)4.2.3 提取特征变量和目标变量
X = df[['close','volume','close-open','MA5','MA10','high-low','RSI','MOM','EMA12','MACD','MACDsignal','MACDhist']]
y = np.where(df['price_change'].shift(-1) > 0,1,-1)
4.2.4 划分训练集和测试集
X_length = X.shape[0]
split = int(X_length * 0.9)
X_train,X_test = X[:split],X[split:]
y_train,y_test = y[:split],y[split:]
4.2.5 模型搭建
model = RandomForestClassifier(max_depth=3,n_estimators=10,min_samples_leaf=10,random_state=123)
model.fit(X_train,y_train)
4.3 模型评估与使用
4.3.1 预测下一天的股价涨跌情况
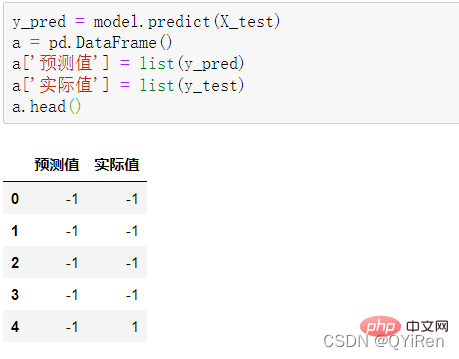
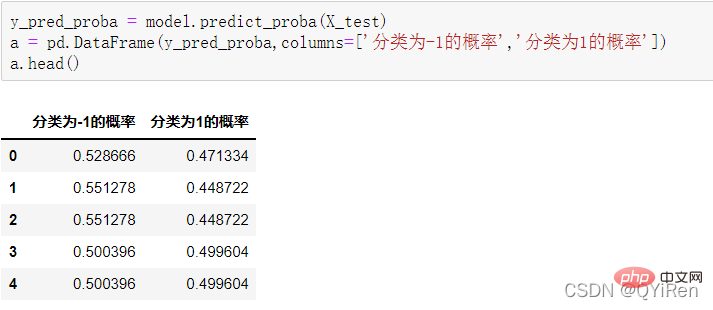
4.3.2 模型准确度评估
4.3.3 分析特征变量的特征重要性
4.4 参数调优
from sklearn.model_selection import GridSearchCV
parameters={'n_estimators':[5,10,20],'max_depth':[2,3,4,5,6],'min_samples_leaf':[5,10,20,30]}
new_model = RandomForestClassifier(random_state=123)
grid_search = GridSearchCV(new_model,parameters,cv=6,scoring='accuracy')
grid_search.fit(X_train,y_train)
grid_search.best_params_
# 输出
# {'max_depth': 5, 'min_samples_leaf': 20, 'n_estimators': 5} 4.5 收益回测曲线绘制
# 在测试数据上添加一列,预测收益
X_test['prediction'] = model.predict(X_test)
# 计算每天的股价变化率
X_test['p_change'] = (X_test['close'] - X_test['close'].shift(1)) / X_test['close'].shift(1)
# 计算累积收益率
# 例如,初始股价是1,2天内的价格变化率为10%
# 那么用cumprod()函数可以求得2天后的股价为1×(1+10%)×(1+10%)=1.21
# 此结果也表明2天的收益率为21%。
X_test['origin'] = (X_test['p_change'] + 1).cumprod()
# 计算利用模型预测后的收益率
X_test['strategy'] = (X_test['prediction'].shift(1) * X_test['p_change'] + 1).cumprod()
X_test[['strategy','origin']].dropna().plot()
# 设置自动倾斜
plt.gcf().autofmt_xdate()
plt.show()
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Beispiele für Python-Random-Forest-Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Sie können sehen, dass die Zeilen vor dem 16. gelöscht wurden.
Sie können sehen, dass die Zeilen vor dem 16. gelöscht wurden. 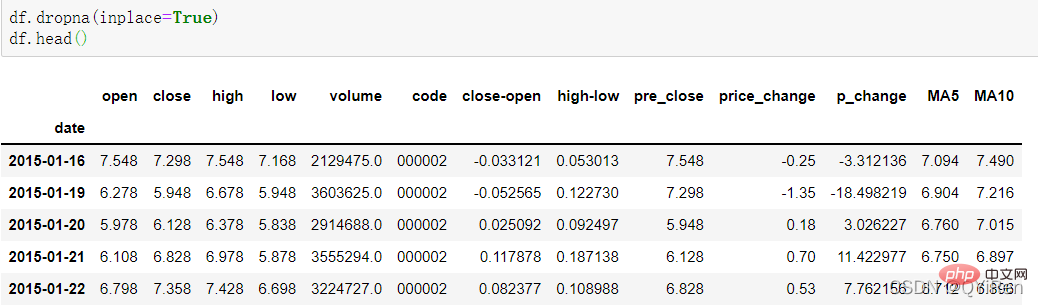


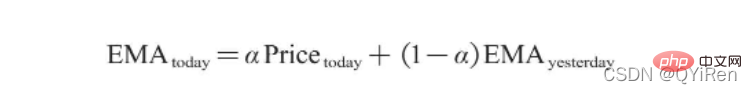

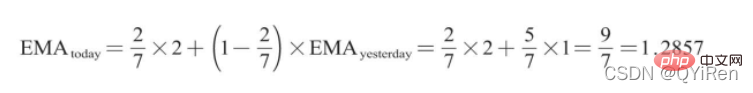

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



