

Dieser Artikel fasst für Sie einige ausgewählte Java-Grundlagen-Hochfrequenzinterviewfragen aus dem Jahr 2023 zusammen, die es wert sind, gesammelt zu werden (mit Antworten). Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird für alle hilfreich sein.
![[Hämatemesis-Zusammenstellung] 2023 Java grundlegende Fragen und Antworten zu Hochfrequenzinterviews (Sammlung)](https://img.php.cn/upload/article/000/000/024/62c79d0ce0756800.jpg)
Die drei grundlegenden Merkmale der Objektorientierung sind: Kapselung, Vererbung und Polymorphismus.
Vererbung: Eine Methode, die es einem Objekt eines bestimmten Typs ermöglicht, die Eigenschaften eines Objekts eines anderen Typs zu erhalten. Vererbung bedeutet, dass eine Unterklasse die Merkmale und Verhaltensweisen der übergeordneten Klasse erbt, sodass das Unterklassenobjekt (Instanz) über die Instanzfelder und -methoden der übergeordneten Klasse verfügt, oder dass die Unterklasse Methoden von der übergeordneten Klasse erbt, sodass die Unterklasse über die Instanzfelder und Methoden der übergeordneten Klasse verfügt Gleiches Verhalten wie die übergeordnete Klasse. (Empfohlenes Tutorial: Einführung in Java-Tutorial)
Kapselung: Versteckt die Eigenschaften und Implementierungsdetails einiger Objekte, und der Zugriff auf Daten kann nur über extern verfügbare Schnittstellen erfolgen. Auf diese Weise bieten Objekte unterschiedliche Schutzniveaus für interne Daten, um zu verhindern, dass unabhängige Teile des Programms versehentlich die privaten Teile des Objekts ändern oder falsch verwenden.
Polymorphismus: Für dasselbe Verhalten haben verschiedene Unterklassenobjekte unterschiedliche Ausdrücke. Es gibt drei Bedingungen für die Existenz von Polymorphismus: 1) Vererbung; 2) Überschreiben; 3) Referenzpunkte der übergeordneten Klasse auf das Unterklassenobjekt.
Ein einfaches Beispiel: In League of Legends drücken wir die Q-Taste:
Das gleiche Ereignis wird entstehen unterschiedliche Ergebnisse, wenn es bei verschiedenen Objekten auftritt.
Lassen Sie mich Ihnen ein weiteres einfaches Beispiel geben, um Ihnen das Verständnis zu erleichtern. Dieses Beispiel ist vielleicht nicht ganz korrekt, aber ich denke, es ist hilfreich für das Verständnis.
public class Animal { // 动物
public void sleep() {
System.out.println("躺着睡");
}
}
class Horse extends Animal { // 马 是一种动物
public void sleep() {
System.out.println("站着睡");
}
}
class Cat extends Animal { // 猫 是一种动物
private int age;
public int getAge() {
return age + 1;
}
@Override
public void sleep() {
System.out.println("四脚朝天的睡");
}
}In diesem Beispiel:
Haus und Katze sind beide Tiere, also erben sie beide Tier und erben auch das Schlafverhalten von Tier.
Aber für das Schlafverhalten wurden House und Cat neu geschrieben und haben unterschiedliche Ausdrücke (Implementierungen). Dies wird als Polymorphismus bezeichnet.
In Cat ist das Altersattribut als privat definiert und kann von der Außenwelt nicht direkt abgerufen werden. Die einzige Möglichkeit, die Altersattribute von Cat zu erhalten, ist die Verwendung der getAge-Methode. Dies wird als Kapselung bezeichnet. Natürlich ist das Alter hier nur ein Beispiel, und im tatsächlichen Gebrauch kann es sich um ein viel komplexeres Objekt handeln.
// 代码块1 short s1 = 1; s1 = s1 + 1; // 代码块2 short s1 = 1; s1 += 1;
Beim Kompilieren von Codeblock 1 wird ein Fehler gemeldet. Der Grund für den Fehler ist: Inkompatibler Typ: Bei der Konvertierung von int nach short kann es zu Verlusten kommen.
Codeblock 2 wird normal kompiliert und ausgeführt Codeblock 2, Der Bytecode lautet wie folgt:
public class com.joonwhee.open.demo.Convert {
public com.joonwhee.open.demo.Convert();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: iconst_1 // 将int类型值1入(操作数)栈
1: istore_1 // 将栈顶int类型值保存到局部变量1中
2: iload_1 // 从局部变量1中装载int类型值入栈
3: iconst_1 // 将int类型值1入栈
4: iadd // 将栈顶两int类型数相加,结果入栈
5: i2s // 将栈顶int类型值截断成short类型值,后带符号扩展成int类型值入栈。
6: istore_1 // 将栈顶int类型值保存到局部变量1中
7: return
}Sie können sehen, dass der Bytecode die i2s-Anweisung enthält, die zum Konvertieren von int in short verwendet wird. i2s ist die Abkürzung von int in short
Tatsächlich ist s1 += 1 ist äquivalent zu s1 =. (kurz)(s1 + 1). Wenn Sie interessiert sind, können Sie den Bytecode dieser beiden Codezeilen selbst kompilieren.
Wie kommt es, dass sie identisch sind? Fragen, die Sie erwähnt haben, sind wieder abnormal geworden? Ausführen: Integer a = Integer.valueOf(128), der Prozess der automatischen Konvertierung von Basistypen in Wrapper-Klassen wird als Autoboxing bezeichnet.
public static void main(String[] args) {
Integer a = 128, b = 128, c = 127, d = 127;
System.out.println(a == b);
System.out.println(c == d);
}IntegerCache wird eingeführt, um einen bestimmten Wertebereich zwischenzuspeichern. 128~127. 127 in dieser Frage trifft auf den IntegerCache, also sind c und d die gleichen Objekte, aber 128 wird nicht getroffen, also sind a und b unterschiedliche Objekte
Aber dieser Cache-Bereich kann geändert werden, bei manchen Leuten vielleicht nicht Kennen Sie die Startparameter: -XX:AutoBoxCacheMax=
Fortgeschritten: Unter normalen Umständen können Bitoperationen als die höchste Leistung angesehen werden. Tatsächlich sind Compiler jetzt jedoch „sehr intelligent“, und viele Befehlscompiler müssen keine eigene Optimierung durchführen Praktische Bitoperationen führen nicht nur zu einer schlechten Lesbarkeit des Codes, sondern führen auch einige clevere Optimierungen dazu, dass der Compiler keine besseren Optimierungen durchführen kann. Dies können die sogenannten „Pig-Teamkollegen“ sein
&&:逻辑与运算符。当运算符左右两边的表达式都为 true,才返回 true。同时具有短路性,如果第一个表达式为 false,则直接返回 false。
&:逻辑与运算符、按位与运算符。
按位与运算符:用于二进制的计算,只有对应的两个二进位均为1时,结果位才为1 ,否则为0。
逻辑与运算符:& 在用于逻辑与时,和 && 的区别是不具有短路性。所在通常使用逻辑与运算符都会使用 &&,而 & 更多的适用于位运算。
答:不是。Java 中的基本数据类型只有8个:byte、short、int、long、float、double、char、boolean;除了基本类型(primitive type),剩下的都是引用类型(reference type)。
基本数据类型:数据直接存储在栈上
引用数据类型区别:数据存储在堆上,栈上只存储引用地址
不行。String 类使用 final 修饰,无法被继承。
String:String 的值被创建后不能修改,任何对 String 的修改都会引发新的 String 对象的生成。
StringBuffer:跟 String 类似,但是值可以被修改,使用 synchronized 来保证线程安全。
StringBuilder:StringBuffer 的非线程安全版本,没有使用 synchronized,具有更高的性能,推荐优先使用。
一个或两个。如果字符串常量池已经有“xyz”,则是一个;否则,两个。
当字符创常量池没有 “xyz”,此时会创建如下两个对象:
一个是字符串字面量 "xyz" 所对应的、驻留(intern)在一个全局共享的字符串常量池中的实例,此时该实例也是在堆中,字符串常量池只放引用。
另一个是通过 new String() 创建并初始化的,内容与"xyz"相同的实例,也是在堆中。
两个语句都会先去字符串常量池中检查是否已经存在 “xyz”,如果有则直接使用,如果没有则会在常量池中创建 “xyz” 对象。
另外,String s = new String("xyz") 还会通过 new String() 在堆里创建一个内容与 "xyz" 相同的对象实例。
所以前者其实理解为被后者的所包含。
==:运算符,用于比较基础类型变量和引用类型变量。
对于基础类型变量,比较的变量保存的值是否相同,类型不一定要相同。
short s1 = 1; long l1 = 1; // 结果:true。类型不同,但是值相同 System.out.println(s1 == l1);
对于引用类型变量,比较的是两个对象的地址是否相同。
Integer i1 = new Integer(1); Integer i2 = new Integer(1); // 结果:false。通过new创建,在内存中指向两个不同的对象 System.out.println(i1 == i2);
equals:Object 类中定义的方法,通常用于比较两个对象的值是否相等。
equals 在 Object 方法中其实等同于 ==,但是在实际的使用中,equals 通常被重写用于比较两个对象的值是否相同。
Integer i1 = new Integer(1);
Integer i2 = new Integer(1);
// 结果:true。两个不同的对象,但是具有相同的值
System.out.println(i1.equals(i2));
// Integer的equals重写方法
public boolean equals(Object obj) {
if (obj instanceof Integer) {
// 比较对象中保存的值是否相同
return value == ((Integer)obj).intValue();
}
return false;
}不对。hashCode() 和 equals() 之间的关系如下:
当有 a.equals(b) == true 时,则 a.hashCode() == b.hashCode() 必然成立,
反过来,当 a.hashCode() == b.hashCode() 时,a.equals(b) 不一定为 true。
反射是指在运行状态中,对于任意一个类都能够知道这个类所有的属性和方法;并且对于任意一个对象,都能够调用它的任意一个方法;这种动态获取信息以及动态调用对象方法的功能称为反射机制。
数据分为基本数据类型和引用数据类型。基本数据类型:数据直接存储在栈中;引用数据类型:存储在栈中的是对象的引用地址,真实的对象数据存放在堆内存里。
浅拷贝:对于基础数据类型:直接复制数据值;对于引用数据类型:只是复制了对象的引用地址,新旧对象指向同一个内存地址,修改其中一个对象的值,另一个对象的值随之改变。
深拷贝:对于基础数据类型:直接复制数据值;对于引用数据类型:开辟新的内存空间,在新的内存空间里复制一个一模一样的对象,新老对象不共享内存,修改其中一个对象的值,不会影响另一个对象。
深拷贝相比于浅拷贝速度较慢并且花销较大。
并发:两个或多个事件在同一时间间隔发生。
并行:两个或者多个事件在同一时刻发生。
并行是真正意义上,同一时刻做多件事情,而并发在同一时刻只会做一件事件,只是可以将时间切碎,交替做多件事情。
网上有个例子挺形象的:
你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
Constructor 不能被 override(重写),但是可以 overload(重载),所以你可以看到⼀个类中有多个构造函数的情况。
值传递。Java 中只有值传递,对于对象参数,值的内容是对象的引用。
public class Demo {
/**
* 静态变量:又称类变量,static修饰
*/
public static String STATIC_VARIABLE = "静态变量";
/**
* 实例变量:又称成员变量,没有static修饰
*/
public String INSTANCE_VARIABLE = "实例变量";
}成员变量存在于堆内存中。静态变量存在于方法区中。
成员变量与对象共存亡,随着对象创建而存在,随着对象被回收而释放。静态变量与类共存亡,随着类的加载而存在,随着类的消失而消失。
成员变量所属于对象,所以也称为实例变量。静态变量所属于类,所以也称为类变量。
成员变量只能被对象所调用 。静态变量可以被对象调用,也可以被类名调用。
区分两种情况,发出调用时是否显示创建了对象实例。
1)没有显示创建对象实例:不可以发起调用,非静态方法只能被对象所调用,静态方法可以通过对象调用,也可以通过类名调用,所以静态方法被调用时,可能还没有创建任何实例对象。因此通过静态方法内部发出对非静态方法的调用,此时可能无法知道非静态方法属于哪个对象。
public class Demo {
public static void staticMethod() {
// 直接调用非静态方法:编译报错
instanceMethod();
}
public void instanceMethod() {
System.out.println("非静态方法");
}
}2)显示创建对象实例:可以发起调用,在静态方法中显示的创建对象实例,则可以正常的调用。
public class Demo {
public static void staticMethod() {
// 先创建实例对象,再调用非静态方法:成功执行
Demo demo = new Demo();
demo.instanceMethod();
}
public void instanceMethod() {
System.out.println("非静态方法");
}
}public class InitialTest {
public static void main(String[] args) {
A ab = new B();
ab = new B();
}
}
class A {
static { // 父类静态代码块
System.out.print("A");
}
public A() { // 父类构造器
System.out.print("a");
}
}
class B extends A {
static { // 子类静态代码块
System.out.print("B");
}
public B() { // 子类构造器
System.out.print("b");
}
}执行结果:ABabab,两个考察点:
1)静态变量只会初始化(执行)一次。
2)当有父类时,完整的初始化顺序为:父类静态变量(静态代码块)->子类静态变量(静态代码块)->父类非静态变量(非静态代码块)->父类构造器 ->子类非静态变量(非静态代码块)->子类构造器 。
关于初始化,这题算入门题,我之前还写过一道有(fei)点(chang)意(bian)思(tai)的进阶题目,有兴趣的可以看看:一道有意思的“初始化”面试题
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。
重载:一个类中有多个同名的方法,但是具有有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)。
重写:发生在子类与父类之间,子类对父类的方法进行重写,参数都不能改变,返回值类型可以不相同,但是必须是父类返回值的派生类。即外壳不变,核心重写!重写的好处在于子类可以根据需要,定义特定于自己的行为。
如果我们有两个方法如下,当我们调用:test(1) 时,编译器无法确认要调用的是哪个。
// 方法1 int test(int a); // 方法2 long test(int a);
方法的返回值只是作为方法运行之后的一个“状态”,但是并不是所有调用都关注返回值,所以不能将返回值作为重载的唯一区分条件。
抽象类只能单继承,接口可以多实现。
抽象类可以有构造方法,接口中不能有构造方法。
抽象类中可以有成员变量,接口中没有成员变量,只能有常量(默认就是 public static final)
抽象类中可以包含非抽象的方法,在 Java 7 之前接口中的所有方法都是抽象的,在 Java 8 之后,接口支持非抽象方法:default 方法、静态方法等。Java 9 支持私有方法、私有静态方法。
抽象类中的方法类型可以是任意修饰符,Java 8 之前接口中的方法只能是 public 类型,Java 9 支持 private 类型。
设计思想的区别:
接口是自上而下的抽象过程,接口规范了某些行为,是对某一行为的抽象。我需要这个行为,我就去实现某个接口,但是具体这个行为怎么实现,完全由自己决定。
抽象类是自下而上的抽象过程,抽象类提供了通用实现,是对某一类事物的抽象。我们在写实现类的时候,发现某些实现类具有几乎相同的实现,因此我们将这些相同的实现抽取出来成为抽象类,然后如果有一些差异点,则可以提供抽象方法来支持自定义实现。
我在网上看到有个说法,挺形象的:
普通类像亲爹 ,他有啥都是你的。
抽象类像叔伯,有一部分会给你,还能指导你做事的方法。
接口像干爹,可以给你指引方法,但是做成啥样得你自己努力实现。
Error 和 Exception 都是 Throwable 的子类,用于表示程序出现了不正常的情况。区别在于:
Error 表示系统级的错误和程序不必处理的异常,是恢复不是不可能但很困难的情况下的一种严重问题,比如内存溢出,不可能指望程序能处理这样的情况。
Exception 表示需要捕捉或者需要程序进行处理的异常,是一种设计或实现问题,也就是说,它表示如果程序运行正常,从不会发生的情况。
修饰类:该类不能再派生出新的子类,不能作为父类被继承。因此,一个类不能同时被声明为abstract 和 final。
修饰方法:该方法不能被子类重写。
修饰变量:该变量必须在声明时给定初值,而在以后只能读取,不可修改。 如果变量是对象,则指的是引用不可修改,但是对象的属性还是可以修改的。
public class FinalDemo {
// 不可再修改该变量的值
public static final int FINAL_VARIABLE = 0;
// 不可再修改该变量的引用,但是可以直接修改属性值
public static final User USER = new User();
public static void main(String[] args) {
// 输出:User(id=0, name=null, age=0)
System.out.println(USER);
// 直接修改属性值
USER.setName("test");
// 输出:User(id=0, name=test, age=0)
System.out.println(USER);
}
}其实是三个完全不相关的东西,只是长的有点像。。
final 如上所示。
finally:finally 是对 Java 异常处理机制的最佳补充,通常配合 try、catch 使用,用于存放那些无论是否出现异常都一定会执行的代码。在实际使用中,通常用于释放锁、数据库连接等资源,把资源释放方法放到 finally 中,可以大大降低程序出错的几率。
finalize:Object 中的方法,在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。finalize()方法仅作为了解即可,在 Java 9 中该方法已经被标记为废弃,并添加新的 java.lang.ref.Cleaner,提供了更灵活和有效的方法来释放资源。这也侧面说明了,这个方法的设计是失败的,因此更加不能去使用它。
public class TryDemo {
public static void main(String[] args) {
System.out.println(test());
}
public static int test() {
try {
return 1;
} catch (Exception e) {
return 2;
} finally {
System.out.print("3");
}
}
}执行结果:31。
相信很多同学应该都做对了,try、catch。finally 的基础用法,在 return 前会先执行 finally 语句块,所以是先输出 finally 里的 3,再输出 return 的 1。
public class TryDemo {
public static void main(String[] args) {
System.out.println(test1());
}
public static int test1() {
try {
return 2;
} finally {
return 3;
}
}
}执行结果:3。
这题有点陷阱,但也不难,try 返回前先执行 finally,结果 finally 里不按套路出牌,直接 return 了,自然也就走不到 try 里面的 return 了。
finally 里面使用 return 仅存在于面试题中,实际开发中千万不要这么用。
public class TryDemo {
public static void main(String[] args) {
System.out.println(test1());
}
public static int test1() {
int i = 0;
try {
i = 2;
return i;
} finally {
i = 3;
}
}
}执行结果:2。
这边估计有不少同学会以为结果应该是 3,因为我们知道在 return 前会执行 finally,而 i 在 finally 中被修改为 3 了,那最终返回 i 不是应该为 3 吗?确实很容易这么想,我最初也是这么想的,当初的自己还是太年轻了啊。
这边的根本原因是,在执行 finally 之前,JVM 会先将 i 的结果暂存起来,然后 finally 执行完毕后,会返回之前暂存的结果,而不是返回 i,所以即使这边 i 已经被修改为 3,最终返回的还是之前暂存起来的结果 2。
Tatsächlich ist es anhand des Bytecodes leicht zu erkennen. Vor der endgültigen Eingabe speichert die JVM die Ergebnisse vorübergehend mit den Anweisungen iload und ireturn .
Um zu vermeiden, dass die Atmosphäre erneut abnormal wird, werde ich das spezifische Bytecode-Programm hier nicht veröffentlichen. Interessierte Schüler können es selbst kompilieren und ausprobieren.

Schnittstellen-Standardmethode: Mit Java 8 können wir der Schnittstelle eine nicht abstrakte Methodenimplementierung hinzufügen. Verwenden Sie einfach das Standardschlüsselwort.
Lambda-Ausdruck und funktionale Schnittstelle: Lambda-Ausdruck ist im Wesentlichen eine anonyme innere Klasse. Es kann auch eine sein Codestück, das weitergegeben werden kann. Lambda ermöglicht die Verwendung der Funktion als Parameter einer Methode (die Funktion wird als Parameter an die Methode übergeben, um den Code prägnanter zu gestalten, aber missbrauchen Sie ihn nicht, sonst kommt es zu Lesbarkeitsproblemen, Josh). Bloch, Autor von „Effective Java“, schlug vor, Lambda-Ausdrücke am besten in nicht mehr als drei Zeilen zu verwenden.
Stream-API: Ein Tool zum Ausführen komplexer Operationen an Sammlungsklassen mithilfe funktionaler Programmierung. Es kann mit Lambda-Ausdrücken verwendet werden, um Sammlungen einfach zu verarbeiten. Eine wichtige Abstraktion für die Arbeit mit Sammlungen in Java 8. Sie ermöglicht Ihnen die Angabe der Vorgänge, die Sie für Sammlungen ausführen möchten, und kann sehr komplexe Vorgänge wie das Suchen, Filtern und Zuordnen von Daten ausführen. Die Verwendung der Stream-API zum Bearbeiten von Sammlungsdaten ähnelt der Verwendung von SQL zum Durchführen von Datenbankabfragen. Sie können die Stream-API auch verwenden, um Vorgänge parallel auszuführen. Kurz gesagt, die Stream-API bietet eine effiziente und benutzerfreundliche Möglichkeit, Daten zu verarbeiten.
Methodenreferenz: Die Methodenreferenz bietet eine sehr nützliche Syntax, mit der direkt auf Methoden oder Konstruktoren vorhandener Java-Klassen oder -Objekte (Instanzen) verwiesen werden kann. In Verbindung mit Lambda können Methodenreferenzen die Sprachstruktur kompakter und prägnanter machen und redundanten Code reduzieren.
Datums- und Uhrzeit-API: Java 8 führt eine neue Datums- und Uhrzeit-API ein, um die Datums- und Uhrzeitverwaltung zu verbessern.
Optionale Klasse: Die berühmte NullPointerException ist die häufigste Ursache für Systemfehler. Das Google Guava-Projekt hat vor langer Zeit Optional eingeführt, um Nullzeiger-Ausnahmen zu lösen, die Verunreinigung von Code durch Nullprüfungscode abzulehnen und von Programmierern zu erwarten, dass sie sauberen Code schreiben. Inspiriert von Google Guava ist Optional jetzt Teil der Java 8-Bibliothek.
Neue Tools: Neue Kompilierungstools, wie zum Beispiel: Nashorn Engine jjs, Klassenabhängigkeitsanalysator jdeps.
33. Was ist der Unterschied zwischen der Sleep()-Methode und der yield()-Methode des Threads?
34. Wofür wird die Methode „join()“ des Threads verwendet?
35. Wie viele Möglichkeiten gibt es, Multithread-Programme zu schreiben?
36. Der Unterschied zwischen dem Thread-Aufruf der start()-Methode und dem Aufruf der run()-Methode
37. Thread-Statusfluss
Ein Thread kann sich in einem der folgenden Zustände befinden: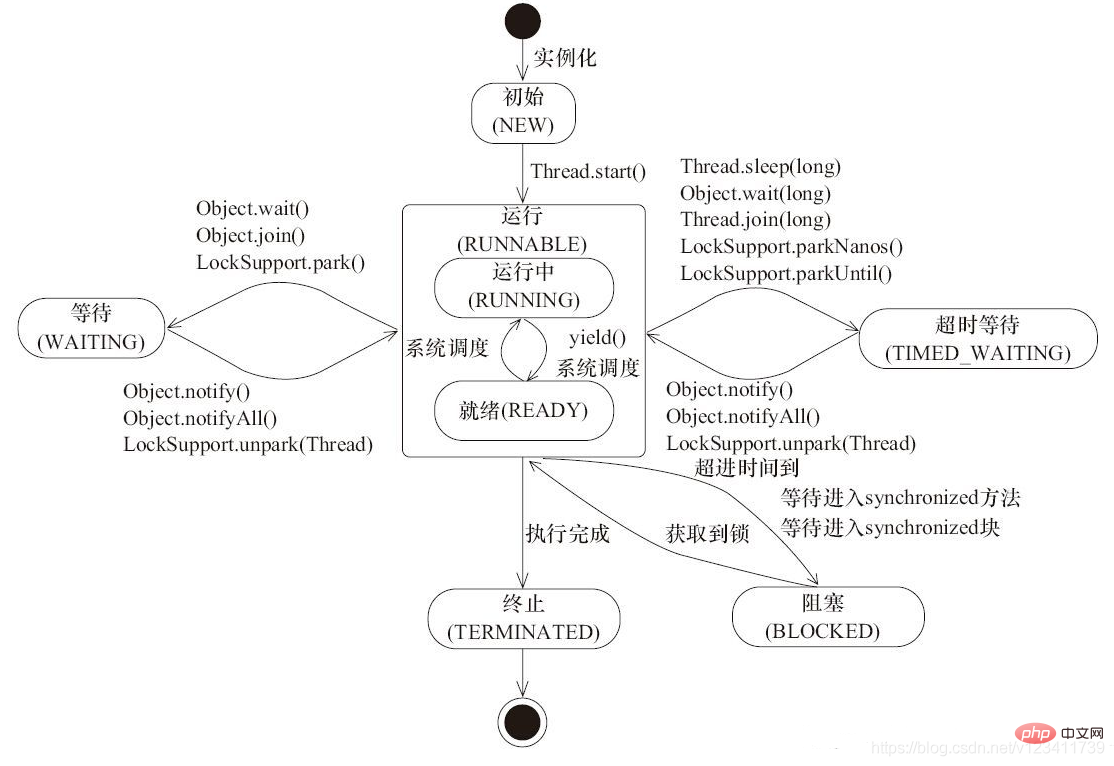
NEW:新建但是尚未启动的线程处于此状态,没有调用 start() 方法。
RUNNABLE:包含就绪(READY)和运行中(RUNNING)两种状态。线程调用 start() 方法会会进入就绪(READY)状态,等待获取 CPU 时间片。如果成功获取到 CPU 时间片,则会进入运行中(RUNNING)状态。
BLOCKED:线程在进入同步方法/同步块(synchronized)时被阻塞,等待同步锁的线程处于此状态。
WAITING:无限期等待另一个线程执行特定操作的线程处于此状态,需要被显示的唤醒,否则会一直等待下去。例如对于 Object.wait(),需要等待另一个线程执行 Object.notify() 或 Object.notifyAll();对于 Thread.join(),则需要等待指定的线程终止。
TIMED_WAITING:在指定的时间内等待另一个线程执行某项操作的线程处于此状态。跟 WAITING 类似,区别在于该状态有超时时间参数,在超时时间到了后会自动唤醒,避免了无期限的等待。
TERMINATED:执行完毕已经退出的线程处于此状态。
线程在给定的时间点只能处于一种状态。这些状态是虚拟机状态,不反映任何操作系统线程状态。
1)Lock 是一个接口;synchronized 是 Java 中的关键字,synchronized 是内置的语言实现;
2)Lock 在发生异常时,如果没有主动通过 unLock() 去释放锁,很可能会造成死锁现象,因此使用 Lock 时需要在 finally 块中释放锁;synchronized 不需要手动获取锁和释放锁,在发生异常时,会自动释放锁,因此不会导致死锁现象发生;
3)Lock 的使用更加灵活,可以有响应中断、有超时时间等;而 synchronized 却不行,使用 synchronized 时,等待的线程会一直等待下去,直到获取到锁;
4)在性能上,随着近些年 synchronized 的不断优化,Lock 和 synchronized 在性能上已经没有很明显的差距了,所以性能不应该成为我们选择两者的主要原因。官方推荐尽量使用 synchronized,除非 synchronized 无法满足需求时,则可以使用 Lock。
1.作用于非静态方法,锁住的是对象实例(this),每一个对象实例有一个锁。
public synchronized void method() {}2.作用于静态方法,锁住的是类的Class对象,因为Class的相关数据存储在永久代元空间,元空间是全局共享的,因此静态方法锁相当于类的一个全局锁,会锁所有调用该方法的线程。
public static synchronized void method() {}3.作用于 Lock.class,锁住的是 Lock 的Class对象,也是全局只有一个。
synchronized (Lock.class) {}4.作用于 this,锁住的是对象实例,每一个对象实例有一个锁。
synchronized (this) {}5.作用于静态成员变量,锁住的是该静态成员变量对象,由于是静态变量,因此全局只有一个。
public static Object monitor = new Object(); synchronized (monitor) {}死锁的四个必要条件:
1)互斥条件:进程对所分配到的资源进行排他性控制,即在一段时间内某资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
2)请求和保持条件:进程已经获得了至少一个资源,但又对其他资源发出请求,而该资源已被其他进程占有,此时该进程的请求被阻塞,但又对自己获得的资源保持不放。
3)不可剥夺条件:进程已获得的资源在未使用完毕之前,不可被其他进程强行剥夺,只能由自己释放。
4)环路等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被 链中下一个进程所请求。即存在一个处于等待状态的进程集合{Pl, P2, …, pn},其中 Pi 等待的资源被 P(i+1) 占有(i=0, 1, …, n-1),Pn 等待的资源被 P0占 有,如下图所示。
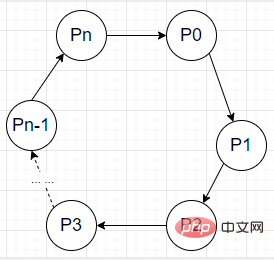
预防死锁的方式就是打破四个必要条件中的任意一个即可。
1)打破互斥条件:在系统里取消互斥。若资源不被一个进程独占使用,那么死锁是肯定不会发生的。但一般来说在所列的四个条件中,“互斥”条件是无法破坏的。因此,在死锁预防里主要是破坏其他几个必要条件,而不去涉及破坏“互斥”条件。。
2)打破请求和保持条件:1)采用资源预先分配策略,即进程运行前申请全部资源,满足则运行,不然就等待。 2)每个进程提出新的资源申请前,必须先释放它先前所占有的资源。
3) Durchbrechen der unveräußerlichen Bedingung: Wenn ein Prozess bestimmte Ressourcen belegt und dann weitere Ressourcen beansprucht, diese aber nicht erfüllen kann, muss der Prozess die ursprünglich belegten Ressourcen freigeben.
4) Durchbrechen Sie die Wartebedingung der Schleife: Implementieren Sie eine geordnete Ressourcenzuweisungsstrategie, nummerieren Sie alle Ressourcen im System einheitlich und alle Prozesse können Ressourcen nur in Form steigender Seriennummern beantragen.
Wenn wir direkt einen neuen Thread in der Methode erstellen, werden bei häufigem Aufruf dieser Methode viele Threads erstellt, was nicht nur Systemressourcen verbraucht, sondern auch die Stabilität des Systems verringert und das System versehentlich zum Absturz bringt. Sie können sich zur Prüfung direkt an die Finanzabteilung wenden.
Wenn wir den Thread-Pool sinnvoll nutzen, können wir das Dilemma eines Systemabsturzes vermeiden. Im Allgemeinen kann die Verwendung eines Thread-Pools folgende Vorteile bringen:
threadFactory: Factory, die zum Erstellen von Arbeitsthreads verwendet wird.
corePoolSize (Anzahl der Kernthreads): Wenn im Thread-Pool weniger Threads ausgeführt werden als corePoolSize, wird ein neuer Thread erstellt, um die Anforderung zu verarbeiten, auch wenn andere Arbeitsthreads inaktiv sind.
workQueue (Warteschlange): Eine blockierende Warteschlange, die dazu dient, Aufgaben aufzubewahren und an Arbeitsthreads zu übergeben.
maximumPoolSize (maximale Anzahl von Threads): Die maximale Anzahl von Threads, die im Thread-Pool geöffnet werden dürfen.
handler (Ablehnungsrichtlinie): Beim Hinzufügen einer Aufgabe zum Thread-Pool wird die Ablehnungsrichtlinie in den folgenden zwei Situationen ausgelöst: 1) Der Ausführungsstatus des Thread-Pools ist nicht RUNNING; 2) Der Thread-Pool hat den erreicht Maximale Anzahl an Threads und die Blockierungswarteschlange ist voll.
keepAliveTime (Keep Alive Time): Wenn die aktuelle Anzahl der Threads im Thread-Pool corePoolSize überschreitet, werden die überschüssigen Threads beendet, wenn ihre Leerlaufzeit keepAliveTime überschreitet.

AbortPolicy: Abbruchrichtlinie. Die Standard-Ablehnungsstrategie löst direkt eine RejectedExecutionException aus. Der Aufrufer kann diese Ausnahme abfangen und je nach Bedarf seinen eigenen Behandlungscode schreiben.
DiscardPolicy: Richtlinie verwerfen. Tun Sie nichts und verwerfen Sie die abgelehnte Aufgabe einfach.
DiscardOldestPolicy: Verwerfen Sie die älteste Richtlinie. Das Verwerfen der ältesten Aufgabe in der Blockierungswarteschlange entspricht der Ausführung der nächsten Aufgabe in der Warteschlange und dem anschließenden erneuten Senden der abgelehnten Aufgabe. Wenn es sich bei der blockierenden Warteschlange um eine Prioritätswarteschlange handelt, führt die Strategie „Älteste löschen“ dazu, dass die Aufgaben mit der höchsten Priorität gelöscht werden. Daher ist es am besten, diese Strategie nicht mit einer Prioritätswarteschlange zu verwenden.
CallerRunsPolicy: Anrufer-Ausführungsrichtlinie. Führen Sie die Aufgabe im Aufrufer-Thread aus. Diese Strategie implementiert einen Anpassungsmechanismus, der die Aufgabe weder abbricht noch eine Ausnahme auslöst, sondern die Aufgabe zurück zum Aufrufer (dem Hauptthread, der den Thread-Pool aufruft, um die Aufgabe auszuführen) zurücksetzt. Daher kann der Hauptthread für mindestens einen bestimmten Zeitraum keine Aufgaben übermitteln, sodass der Thread-Pool Zeit hat, die Verarbeitung der ausgeführten Aufgaben abzuschließen.
List (ein guter Helfer für den Umgang mit Ordnung): Die List-Schnittstelle speichert eine Reihe nicht eindeutiger Elemente (kann mehrere Elemente enthalten, die auf dasselbe Objekt verweisen). ), bestelltes Objekt.
Set (Fokus auf eindeutige Eigenschaften): Doppelte Sets sind nicht zulässig und mehrere Elemente verweisen nicht auf dasselbe Objekt.
Karte (professionelle Benutzer, die Schlüssel zum Suchen verwenden): Verwenden Sie die Speicherung von Schlüssel-Wert-Paaren. Die Karte verwaltet die mit dem Schlüssel verknüpften Werte. Zwei Schlüssel können auf dasselbe Objekt verweisen, der Schlüssel kann jedoch nicht wiederholt werden. Ein typischer Schlüssel ist ein String-Typ, es kann aber auch ein beliebiges Objekt sein.
ArrayList wird unten basierend auf dynamischen Arrays implementiert, und LinkedList wird unten basierend auf verknüpften Listen implementiert.
Für die Indizierung von Daten nach Index (Get/Set-Methode): ArrayList lokalisiert den Knoten direkt an der entsprechenden Position des Arrays über den Index, während LinkedList vom Kopfknoten oder Endknoten aus durchlaufen muss, bis der Zielknoten gefunden wird ArrayList ist LinkedList hinsichtlich der Effizienz überlegen.
Für zufälliges Einfügen und Löschen: ArrayList muss die Knoten hinter dem Zielknoten verschieben (verwenden Sie die System.arraycopy-Methode, um die Knoten zu verschieben), während LinkedList nur die nächsten oder vorherigen Attribute der Knoten vor und nach dem Ziel ändern muss Knoten, daher ist LinkedList hinsichtlich der Effizienz besser als LinkedList ArrayList.
Für sequentielles Einfügen und Löschen: Da ArrayList keine Knoten verschieben muss, ist es hinsichtlich der Effizienz besser als LinkedList. Aus diesem Grund wird ArrayList in der tatsächlichen Verwendung häufiger verwendet, da wir in den meisten Fällen das sequentielle Einfügen verwenden.
Vector und ArrayList sind fast gleich. Der einzige Unterschied besteht darin, dass Vector die Synchronisierungsmethode verwendet, um die Thread-Sicherheit zu gewährleisten, sodass ArrayList eine bessere Leistung aufweist.
Ähnliche Beziehungen umfassen: StringBuilder und StringBuffer, HashMap und Hashtable.
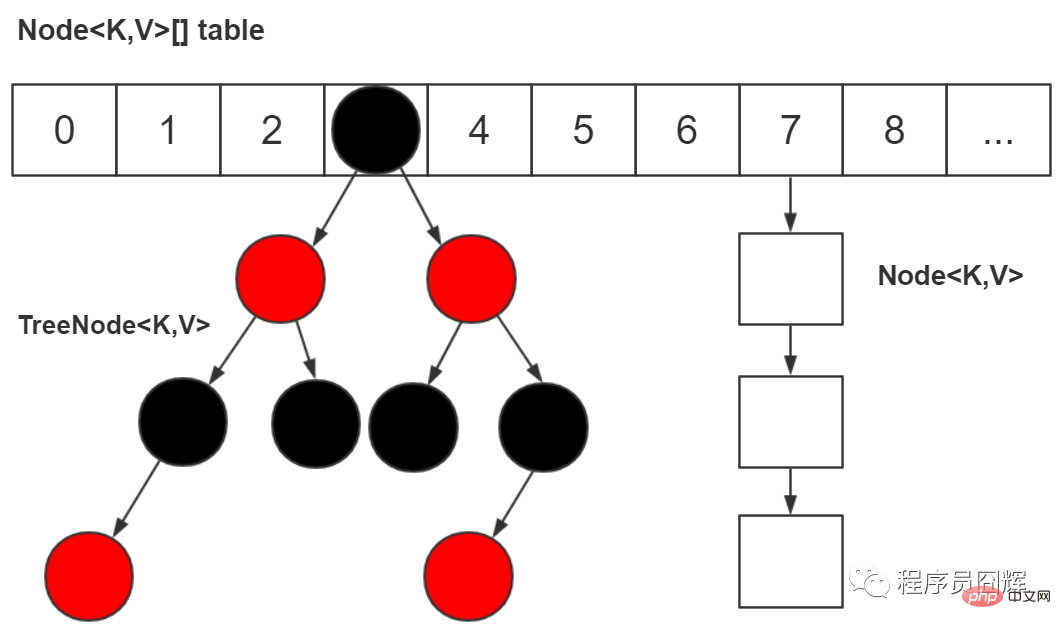 50. Warum sollten wir es in „Array + verknüpfte Liste + rot-schwarzer Baum“ ändern?
50. Warum sollten wir es in „Array + verknüpfte Liste + rot-schwarzer Baum“ ändern?
51. Wann sollten Sie eine verknüpfte Liste verwenden? Wann sollten rotschwarze Bäume verwendet werden?
52. Was ist die standardmäßige Anfangskapazität von HashMap? Gibt es eine Grenze für die Kapazität von HashMap?
53. Was ist der Einfügungsprozess von HashMap?
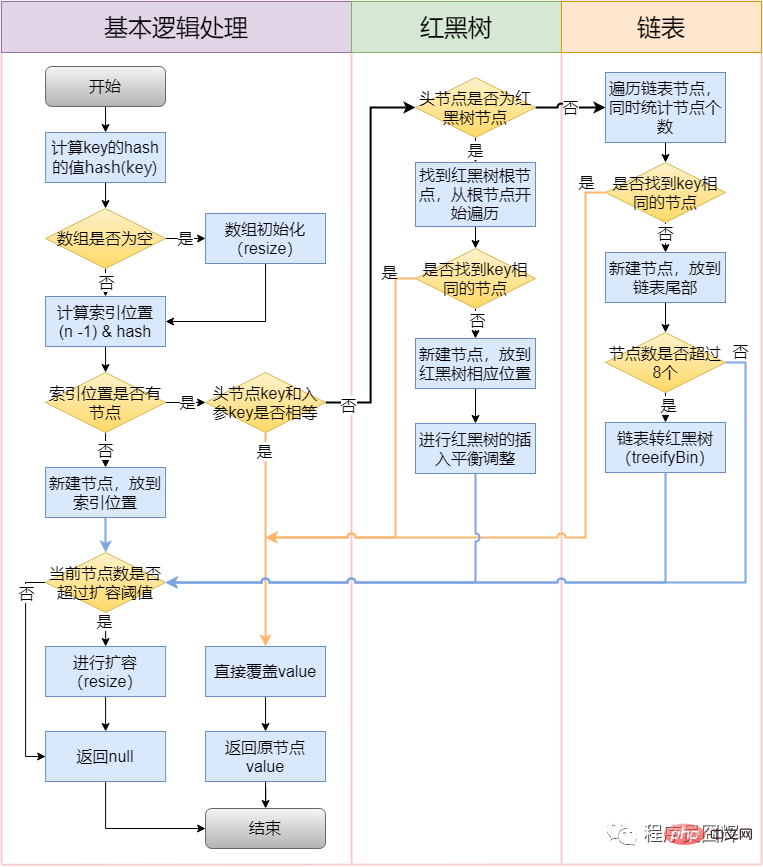 54. Was ist der Erweiterungs- (Größenänderungs-) Prozess von HashMap?
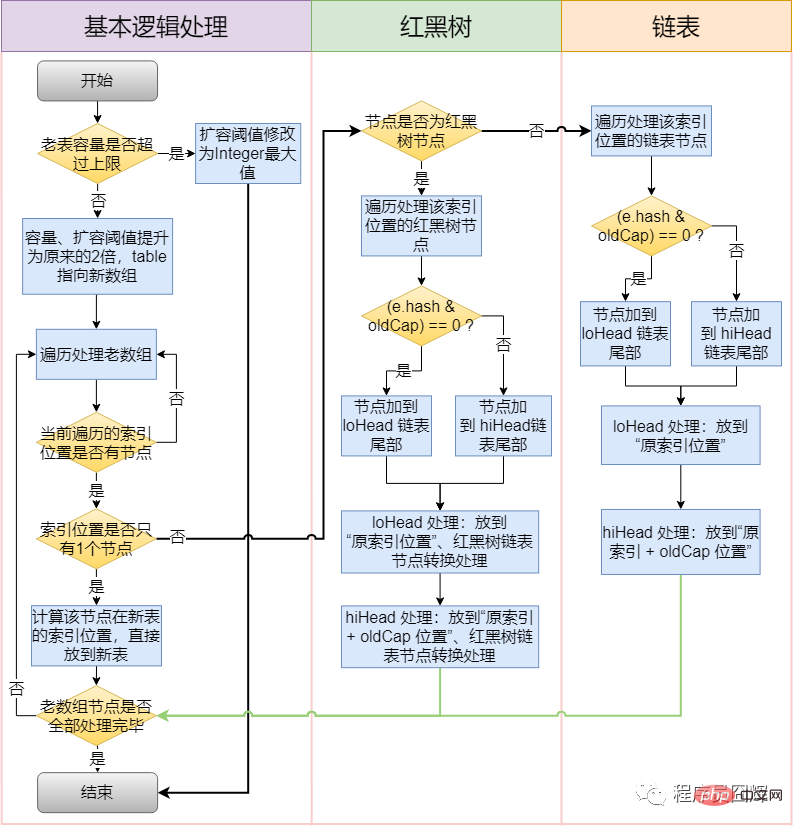
54. Was ist der Erweiterungs- (Größenänderungs-) Prozess von HashMap?
 56. Der Unterschied zwischen HashMap und Hashtable?
56. Der Unterschied zwischen HashMap und Hashtable?
57. Java-Speicherstruktur (Laufzeitdatenbereich)
运行时常量池:运行时常量池是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
String str = new String("hello");上面的语句中变量 str 放在栈上,用 new 创建出来的字符串对象放在堆上,而"hello"这个字面量是放在堆中。
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
启动类加载器(Bootstrap ClassLoader):
这个类加载器负责将存放在
扩展类加载器(Extension ClassLoader):
这个加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载
应用程序类加载器(Application ClassLoader):
这个类加载器由sun.misc.Launcher$AppClassLoader实现。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
自定义类加载器:
用户自定义的类加载器。
类加载的过程包括:加载、验证、准备、解析、初始化,其中验证、准备、解析统称为连接。
加载:通过一个类的全限定名来获取定义此类的二进制字节流,在内存中生成一个代表这个类的java.lang.Class对象。
验证:确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
准备:为静态变量分配内存并设置静态变量初始值,这里所说的初始值“通常情况”下是数据类型的零值。
解析:将常量池内的符号引用替换为直接引用。
初始化:到了初始化阶段,才真正开始执行类中定义的 Java 初始化程序代码。主要是静态变量赋值动作和静态语句块(static{})中的语句。
在什么时候?
在触发GC的时候,具体如下,这里只说常见的 Young GC 和 Full GC。
触发Young GC:当新生代中的 Eden 区没有足够空间进行分配时会触发Young GC。
触发Full GC:
对什么?
对那些JVM认为已经“死掉”的对象。即从GC Root开始搜索,搜索不到的,并且经过一次筛选标记没有复活的对象。
做了什么?
对这些JVM认为已经“死掉”的对象进行垃圾收集,新生代使用复制算法,老年代使用标记-清除和标记-整理算法。
在Java语言中,可作为GC Roots的对象包括下面几种:
Markieren – Klarer Algorithmus
Markiert zunächst alle Objekte, die recycelt werden müssen, und nachdem die Markierung abgeschlossen ist, werden alle markierten Objekte einheitlich recycelt. Es gibt zwei Hauptmängel: Zum einen ist die Effizienz des Markierungs- und Löschvorgangs nicht hoch, zum anderen das Platzproblem, da nach dem Markieren und Löschen eine große Anzahl diskontinuierlicher Speicherfragmente entsteht und möglicherweise zu viele Platzfragmente vorhanden sind Ursache Wenn in Zukunft während der Programmausführung ein größeres Objekt zugewiesen werden muss, kann nicht genügend zusammenhängender Speicher gefunden werden und es muss im Voraus eine weitere Garbage-Collection-Aktion ausgelöst werden.
Kopieralgorithmus
Um das Effizienzproblem zu lösen, erschien ein Sammelalgorithmus namens „Kopieren“, der den verfügbaren Speicher je nach Kapazität in zwei gleich große Blöcke aufteilt und jeweils nur einen davon nutzt. Wenn dieser Speicherblock erschöpft ist, kopieren Sie die verbleibenden Objekte in einen anderen Block und bereinigen Sie dann sofort den verwendeten Speicherplatz. Auf diese Weise wird jedes Mal der gesamte halbe Bereich recycelt, und es ist nicht erforderlich, beim Zuweisen von Speicher komplexe Situationen wie Speicherfragmentierung zu berücksichtigen. Bewegen Sie einfach den oberen Zeiger des Heaps und weisen Sie den Speicher der Reihe nach zu effizient zu laufen. Die Kosten dieses Algorithmus bestehen lediglich darin, den Speicher auf die Hälfte seiner ursprünglichen Größe zu reduzieren, was etwas zu hoch ist.
Tag – Sortieralgorithmus
Der Kopiersammlungsalgorithmus führt mehr Kopiervorgänge aus, wenn die Objektüberlebensrate hoch ist, und die Effizienz wird geringer. Noch wichtiger: Wenn Sie nicht 50 % des Speicherplatzes verschwenden möchten, müssen Sie über zusätzlichen Speicherplatz verfügen, um die extreme Situation zu bewältigen, in der alle Objekte im verwendeten Speicher zu 100 % aktiv sind. Daher ist diese Art der Zuweisung erforderlich kann nicht direkt im Algorithmus der alten Generation verwendet werden.
Basierend auf den Merkmalen der alten Generation hat jemand einen anderen „Mark-Compact“-Algorithmus vorgeschlagen. Der Markierungsprozess ist immer noch der gleiche wie beim „Mark-Clear“-Algorithmus, aber die nachfolgenden Schritte dienen nicht der direkten Reinigung des Recyclingmaterials Stattdessen werden alle lebenden Objekte an ein Ende verschoben und dann wird der Speicher außerhalb der Endgrenze direkt gelöscht.
Generational Collection-Algorithmus
Die aktuelle kommerzielle Garbage Collection für virtuelle Maschinen verwendet den „Generational Collection“-Algorithmus. Dieser Algorithmus teilt den Speicher nur nach den verschiedenen Überlebenszyklen von Objekten auf.
Im Allgemeinen ist der Java-Heap in die neue und die alte Generation unterteilt, sodass entsprechend den Merkmalen jeder Generation der am besten geeignete Erfassungsalgorithmus verwendet werden kann.
In der neuen Generation wird festgestellt, dass bei der Speicherbereinigung jedes Mal eine große Anzahl von Objekten stirbt und nur wenige überleben. Verwenden Sie dann den Kopieralgorithmus und müssen Sie nur die Kopierkosten für eine kleine Anzahl überlebender Objekte bezahlen um die Sammlung zu vervollständigen.
Da in der alten Generation die Objektüberlebensrate hoch ist und kein zusätzlicher Platz vorhanden ist, um ihre Zuweisung zu gewährleisten, muss zum Recycling der Mark-Clean- oder Mark-Clean-Algorithmus verwendet werden.
In der Zeit von Gold, Drei und Silber bereiten sich meiner Meinung nach viele Studenten auf einen Jobwechsel vor.
Ich habe meine letzten Originalartikel zusammengefasst: Originalzusammenfassung, die eine Analyse vieler häufig gestellter Interviewfragen enthält, von denen ich viele bei Interviews mit großen Unternehmen angetroffen habe Standardmäßig können Sie es vielleicht nicht vollständig verstehen, wenn Sie es nur einmal lesen, aber ich glaube, dass Sie etwas gewinnen werden, wenn Sie es immer wieder lesen.
Weitere Kenntnisse zum Thema Programmierung finden Sie unter: Programmierkurse! !
Das obige ist der detaillierte Inhalt von[Hämatemesis-Zusammenstellung] 2023 Java grundlegende Fragen und Antworten zu Hochfrequenzinterviews (Sammlung). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



