

In Linux ist der Stapel eine serielle Datenstruktur. Das Merkmal dieser Datenstruktur ist, dass Daten nur an einem Ende der Reihe verschoben und abgelegt werden können Stack, Thread-Stack, Kernel-Stack und Interrupt-Stack.

Die Betriebsumgebung dieses Tutorials: Linux7.3-System, Dell G3-Computer.
Stack (Stack) ist eine serielle Datenstruktur. Das Merkmal dieser Datenstruktur ist LIFO (Last In First Out). Daten können nur an einem Ende der Zeichenfolge (dem oberen Ende des Stapels) verschoben und entnommen werden.
Prozessstapel
Thread-Stack
Kernel-Stack
Interrupt-Stack

Die meisten Prozessorarchitekturen haben Hardware-Stacks implementiert. Es gibt ein dediziertes Stapelzeigerregister und spezifische Hardwareanweisungen, um den Push/Pop-Vorgang abzuschließen. In der ARM-Architektur ist beispielsweise der R13 (SP)-Zeiger das Stapelzeigerregister, PUSH ist die Assembleranweisung zum Schieben auf den Stapel und POP ist die Assembleranweisung zum Öffnen des Stapels.
【Erweiterte Lektüre】Einführung in ARM-Register
Der ARM-Prozessor verfügt über 37 Register. Diese Register sind in teilweise überlappenden Gruppen angeordnet. Jeder Prozessormodus verfügt über einen anderen Satz von Registern. Gruppierte Register ermöglichen einen schnellen Kontextwechsel zur Behandlung von Prozessorausnahmen und privilegierten Vorgängen. Die folgenden Register stehen zur Verfügung: ist ein Stapelzeiger. C/C++-Compiler verwenden immer sp als Stapelzeiger
lr (r14), um die Rücksprungadresse beim Aufruf einer Unterroutine zu speichern. Wenn die Rücksprungadresse auf dem Stapel gespeichert ist, kann lr als Allzweckregister verwendet werden
Platzverwaltung lokaler Variablen- Programmzähler (PC): Befehlsregister
- Application Status Register (APSR): Enthält die Arithmetic Logic Unit (ALU) Status-Flag Kopieren
- Current Program Status Register (CPSR): Speichert APSR-Flag, aktuellen Prozessormodus, Interrupt-Deaktivierungs-Flag usw.
- Saved Program Status Register (SPSR): Wenn eine Ausnahme auftritt, verwenden Sie SPSR zum Speichern CPSR
- Das Obige ist das Prinzip und die Implementierung des Stapels. Schauen wir uns als Nächstes an, was der Stapel tut. Die Rolle des Stapels kann in zwei Aspekten widergespiegelt werden: Funktionsaufruf und Multitasking-Unterstützung. 1. Funktionsaufruf
- Wir wissen, dass ein Funktionsaufruf die folgenden drei Grundprozesse hat:
- Übergabe von Aufrufparametern
Die Anzahl der Aufrufparameter einer Funktion ist im Allgemeinen relativ gering, sodass Allzweckregister bestimmte Anforderungen erfüllen können. Allerdings sind die Anzahl und der Platzbedarf lokaler Variablen relativ groß, und es ist schwierig, sich auf begrenzte Allzweckregister zu verlassen. Daher können wir bestimmte RAM-Speicherbereiche zum Speichern lokaler Variablen verwenden. Doch wo ist der geeignete Lagerort? Es ist notwendig, Konflikte beim Aufruf verschachtelter Funktionen zu vermeiden und auf Effizienz zu achten.
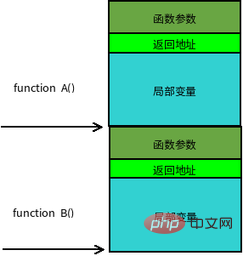
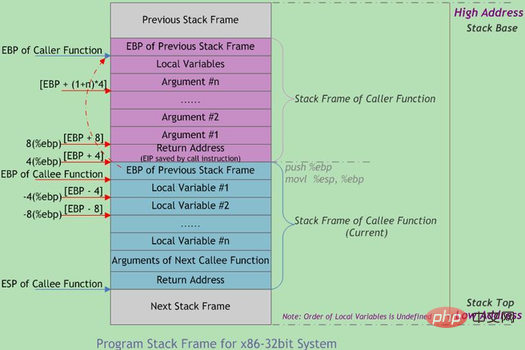
【Erweiterte Lektüre】: Funktionsstapelrahmen
Funktionsaufrufe sind häufig verschachtelt. Gleichzeitig befinden sich Informationen zu mehreren Funktionen im Stapel. Jede unvollendete Funktion belegt einen unabhängigen kontinuierlichen Bereich, der als Stapelrahmen bezeichnet wird. Der Stapelrahmen speichert Funktionsparameter, lokale Variablen und Daten, die zum Wiederherstellen des vorherigen Stapelrahmens usw. erforderlich sind. Die Reihenfolge beim Einschieben in den Stapel beim Aufruf einer Funktion ist:
tatsächliche Parameter N~1 → Rücksprungadresse der aufrufenden Funktion → aufrufende Funktion Frame-Basiszeiger EBP → Die aufgerufene Funktion lokale Variable 1~N
Die Grenze des Stapelrahmens wird durch den Stapelrahmen-Basisadressenzeiger EBP definiert und der Stapelzeiger ESP zeigt auf den unteren Rand des aktuellen Stapelrahmens (hohe Adresse). ) und ist im aktuellen Stapelrahmen fixiert; ESP zeigt auf den oberen Rand des aktuellen Stapelrahmens (niedrige Adresse), ESP bewegt sich, wenn Daten aus dem Stapel geschoben und herausgeholt werden, wenn das Programm ausgeführt wird. Daher basiert der Großteil des Datenzugriffs in der Funktion auf EBP. Das typische Speicherlayout des Funktionsaufrufstapels ist in der folgenden Abbildung dargestellt:
Die Bedeutung des Stapels besteht jedoch nicht nur aus Funktionsaufrufen -Aufgabenmodus des Betriebssystems erstellt werden. Nehmen wir als Beispiel den Hauptfunktionsaufruf. Die Hauptfunktion enthält einen Endlosschleifenkörper. Zuerst wird Funktion A und dann Funktion B aufgerufen.
func B():
return;
func A():
B();
func main():
while (1)
A();Stellen Sie sich vor, dass das Programm in einer Einprozessorsituation für immer in dieser Hauptfunktion bleibt. Selbst wenn sich eine andere Aufgabe im Wartezustand befindet, kann das Programm nicht von der Hauptfunktion zu einer anderen Aufgabe springen. Denn wenn es sich um eine Funktionsaufrufbeziehung handelt, handelt es sich im Wesentlichen immer noch um eine Aufgabe der Hauptfunktion und kann nicht als Multitask-Umschaltung gezählt werden. In diesem Moment ist die Hauptfunktionsaufgabe tatsächlich an ihren Stapel gebunden. Unabhängig davon, wie verschachtelt die Funktionsaufrufe sind, bewegt sich der Stapelzeiger innerhalb des Bereichs dieses Stapels.
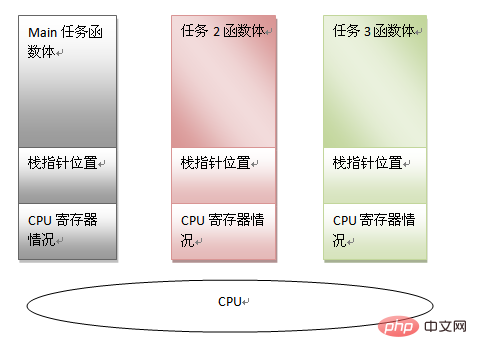
Es ist ersichtlich, dass eine Aufgabe durch die folgenden Informationen charakterisiert werden kann:
Hauptfunktionskörpercode
Hauptfunktionsstapelzeiger
aktuelle CPU-Registerinformationen
Wenn wir das speichern können Mit den obigen Informationen können Sie die CPU zwingen, andere Aufgaben zu erledigen. Solange Sie diese Hauptaufgabe auch in Zukunft weiterhin ausführen möchten, können Sie die oben genannten Informationen wiederherstellen. Unter solchen Voraussetzungen hat Multitasking eine Existenzgrundlage, und es lässt sich auch eine andere Bedeutung der Existenz des Stapels erkennen. Wenn der Planer im Multitasking-Modus einen Aufgabenwechsel für erforderlich hält, muss er nur die Aufgabeninformationen speichern (dh die drei oben genannten Dinge). Stellen Sie den Status einer anderen Aufgabe wieder her und springen Sie dann zum Speicherort der letzten Ausführung, um die Ausführung fortzusetzen.
Es ist ersichtlich, dass jede Aufgabe über einen eigenen Stapelplatz verfügt, sodass verschiedene Aufgaben aus Gründen der Code-Wiederverwendung beispielsweise eine Hauptfunktion haben können zwei Aufgabeninstanzen. Danach wurde auch das Framework des Betriebssystems gebildet. Wenn eine Aufgabe beispielsweise Sleep () aufruft und wartet, kann sie die CPU aktiv anderen Aufgaben überlassen, oder die Time-Sharing-Betriebssystemaufgabe wird erzwungen Die Zeitscheibe ist aufgebraucht. Geben Sie die CPU auf. Egal welche Methode verwendet wird, finden Sie einfach eine Möglichkeit, den Kontextraum der Aufgabe und den Stapel zu wechseln.
[Erweiterte Lektüre]: Die Beziehung zwischen Aufgaben, Threads und Prozessen
Aufgabe ist ein abstraktes Konzept, das sich auf eine von Software ausgeführte Aktivität bezieht; Threads sind die Aktionen, die zum Abschließen der Aufgabe erforderlich sind; ist die Sammelbezeichnung für die Ressourcen, die zum Abschließen dieser Aktion erforderlich sind. Es gibt eine anschauliche Metapher über die Beziehung zwischen den dreien:
Aufgabe = Lieferung
Thread = einen Lieferwagen fahren
Systemplanung = entscheiden Was ist angemessen? Welcher Lieferwagen soll gefahren werden?
Prozess = Straße + Tankstelle + Lieferwagen + Garage
Nachdem wir das Funktionsprinzip und den Zweck des Stacks vorgestellt haben, kehren wir zum Linux-Kernel zurück. Der Kernel unterteilt den Stapel in vier Typen:
Prozessstapel
Thread-Stack
Kernel-Stack
Interrupt-Stack
Der Prozessstapel gehört zu der Benutzer Der Stapelmodus und der virtuelle Adressraum des Prozesses sind eng miteinander verbunden. Lassen Sie uns zunächst verstehen, was virtueller Adressraum ist: Auf einer 32-Bit-Maschine beträgt die Größe des virtuellen Adressraums 4G. Diese virtuellen Adressen werden dem physischen Speicher über Seitentabellen zugeordnet, die vom Betriebssystem verwaltet und von der MMU-Hardware (Memory Management Unit) des Prozessors referenziert werden. Jeder Prozess verfügt über einen eigenen Satz von Seitentabellen, sodass jeder Prozess scheinbar exklusiven Zugriff auf den gesamten virtuellen Adressraum hat.
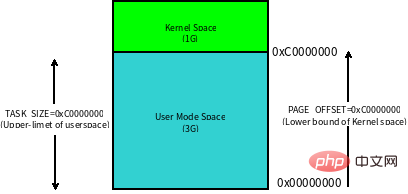
Linux 内核将这 4G 字节的空间分为两部分,将最高的 1G 字节(0xC0000000-0xFFFFFFFF)供内核使用,称为 内核空间。而将较低的3G字节(0x00000000-0xBFFFFFFF)供各个进程使用,称为 用户空间。每个进程可以通过系统调用陷入内核态,因此内核空间是由所有进程共享的。虽然说内核和用户态进程占用了这么大地址空间,但是并不意味它们使用了这么多物理内存,仅表示它可以支配这么大的地址空间。它们是根据需要,将物理内存映射到虚拟地址空间中使用。
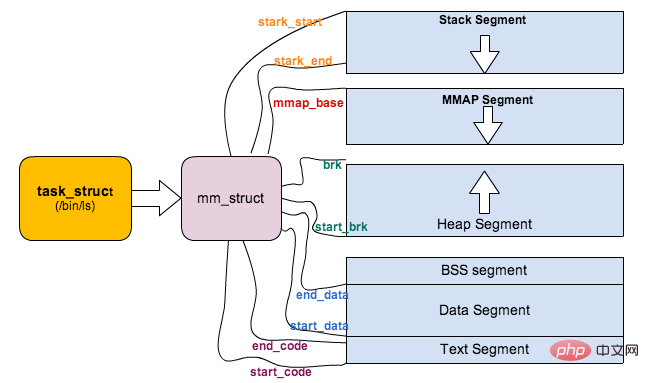
Linux 对进程地址空间有个标准布局,地址空间中由各个不同的内存段组成 (Memory Segment),主要的内存段如下:
程序段 (Text Segment):可执行文件代码的内存映射
数据段 (Data Segment):可执行文件的已初始化全局变量的内存映射
BSS段 (BSS Segment):未初始化的全局变量或者静态变量(用零页初始化)
堆区 (Heap) : 存储动态内存分配,匿名的内存映射
栈区 (Stack) : 进程用户空间栈,由编译器自动分配释放,存放函数的参数值、局部变量的值等
映射段(Memory Mapping Segment):任何内存映射文件

而上面进程虚拟地址空间中的栈区,正指的是我们所说的进程栈。进程栈的初始化大小是由编译器和链接器计算出来的,但是栈的实时大小并不是固定的,Linux 内核会根据入栈情况对栈区进行动态增长(其实也就是添加新的页表)。但是并不是说栈区可以无限增长,它也有最大限制 RLIMIT_STACK (一般为 8M),我们可以通过 ulimit 来查看或更改 RLIMIT_STACK 的值。
【扩展阅读】:如何确认进程栈的大小
我们要知道栈的大小,那必须得知道栈的起始地址和结束地址。栈起始地址 获取很简单,只需要嵌入汇编指令获取栈指针 esp 地址即可。栈结束地址 的获取有点麻烦,我们需要先利用递归函数把栈搞溢出了,然后再 GDB 中把栈溢出的时候把栈指针 esp 打印出来即可。代码如下:
/* file name: stacksize.c */
void *orig_stack_pointer;
void blow_stack() {
blow_stack();
}
int main() {
__asm__("movl %esp, orig_stack_pointer");
blow_stack();
return 0;
}$ g++ -g stacksize.c -o ./stacksize $ gdb ./stacksize (gdb) r Starting program: /home/home/misc-code/setrlimit Program received signal SIGSEGV, Segmentation fault. blow_stack () at setrlimit.c:4 4 blow_stack(); (gdb) print (void *)$esp $1 = (void *) 0xffffffffff7ff000 (gdb) print (void *)orig_stack_pointer $2 = (void *) 0xffffc800 (gdb) print 0xffffc800-0xff7ff000 $3 = 8378368 // Current Process Stack Size is 8M
上面对进程的地址空间有个比较全局的介绍,那我们看下 Linux 内核中是怎么体现上面内存布局的。内核使用内存描述符来表示进程的地址空间,该描述符表示着进程所有地址空间的信息。内存描述符由 mm_struct 结构体表示,下面给出内存描述符结构中各个域的描述,请大家结合前面的 进程内存段布局 图一起看:
struct mm_struct {
struct vm_area_struct *mmap; /* 内存区域链表 */
struct rb_root mm_rb; /* VMA 形成的红黑树 */
...
struct list_head mmlist; /* 所有 mm_struct 形成的链表 */
...
unsigned long total_vm; /* 全部页面数目 */
unsigned long locked_vm; /* 上锁的页面数据 */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long shared_vm; /* 共享页面数目 Shared pages (files) */
unsigned long exec_vm; /* 可执行页面数目 VM_EXEC & ~VM_WRITE */
unsigned long stack_vm; /* 栈区页面数目 VM_GROWSUP/DOWN */
unsigned long def_flags;
unsigned long start_code, end_code, start_data, end_data; /* 代码段、数据段 起始地址和结束地址 */
unsigned long start_brk, brk, start_stack; /* 栈区 的起始地址,堆区 起始地址和结束地址 */
unsigned long arg_start, arg_end, env_start, env_end; /* 命令行参数 和 环境变量的 起始地址和结束地址 */
...
/* Architecture-specific MM context */
mm_context_t context; /* 体系结构特殊数据 */
/* Must use atomic bitops to access the bits */
unsigned long flags; /* 状态标志位 */
...
/* Coredumping and NUMA and HugePage 相关结构体 */
};
【扩展阅读】:进程栈的动态增长实现
进程在运行的过程中,通过不断向栈区压入数据,当超出栈区容量时,就会耗尽栈所对应的内存区域,这将触发一个 缺页异常 (page fault)。通过异常陷入内核态后,异常会被内核的 expand_stack() 函数处理,进而调用 acct_stack_growth() 来检查是否还有合适的地方用于栈的增长。
如果栈的大小低于 RLIMIT_STACK(通常为8MB),那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情,这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会发生 栈溢出(stack overflow),进程将会收到内核发出的 段错误(segmentation fault) 信号。
动态栈增长是唯一一种访问未映射内存区域而被允许的情形,其他任何对未映射内存区域的访问都会触发页错误,从而导致段错误。一些被映射的区域是只读的,因此企图写这些区域也会导致段错误。
从 Linux 内核的角度来说,其实它并没有线程的概念。Linux 把所有线程都当做进程来实现,它将线程和进程不加区分的统一到了 task_struct 中。线程仅仅被视为一个与其他进程共享某些资源的进程,而是否共享地址空间几乎是进程和 Linux 中所谓线程的唯一区别。线程创建的时候,加上了 CLONE_VM 标记,这样 线程的内存描述符 将直接指向 父进程的内存描述符。
if (clone_flags & CLONE_VM) {
/*
* current 是父进程而 tsk 在 fork() 执行期间是共享子进程
*/
atomic_inc(¤t->mm->mm_users);
tsk->mm = current->mm;
}虽然线程的地址空间和进程一样,但是对待其地址空间的 stack 还是有些区别的。对于 Linux 进程或者说主线程,其 stack 是在 fork 的时候生成的,实际上就是复制了父亲的 stack 空间地址,然后写时拷贝 (cow) 以及动态增长。然而对于主线程生成的子线程而言,其 stack 将不再是这样的了,而是事先固定下来的,使用 mmap 系统调用,它不带有 VM_STACK_FLAGS 标记。这个可以从 glibc 的 nptl/allocatestack.c 中的 allocate_stack() 函数中看到:
mem = mmap (NULL, size, prot, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0);
由于线程的 mm->start_stack 栈地址和所属进程相同,所以线程栈的起始地址并没有存放在 task_struct 中,应该是使用 pthread_attr_t 中的 stackaddr 来初始化 task_struct->thread->sp(sp 指向 struct pt_regs 对象,该结构体用于保存用户进程或者线程的寄存器现场)。这些都不重要,重要的是,线程栈不能动态增长,一旦用尽就没了,这是和生成进程的 fork 不同的地方。由于线程栈是从进程的地址空间中 map 出来的一块内存区域,原则上是线程私有的。但是同一个进程的所有线程生成的时候浅拷贝生成者的 task_struct 的很多字段,其中包括所有的 vma,如果愿意,其它线程也还是可以访问到的,于是一定要注意。
在每一个进程的生命周期中,必然会通过到系统调用陷入内核。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先进程用户空间中的栈,而是一个单独内核空间的栈,这个称作进程内核栈。进程内核栈在进程创建的时候,通过 slab 分配器从 thread_info_cache 缓存池中分配出来,其大小为 THREAD_SIZE,一般来说是一个页大小 4K;
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};thread_union 进程内核栈 和 task_struct 进程描述符有着紧密的联系。由于内核经常要访问 task_struct,高效获取当前进程的描述符是一件非常重要的事情。因此内核将进程内核栈的头部一段空间,用于存放 thread_info 结构体,而此结构体中则记录了对应进程的描述符,两者关系如下图(对应内核函数为 dup_task_struct()):
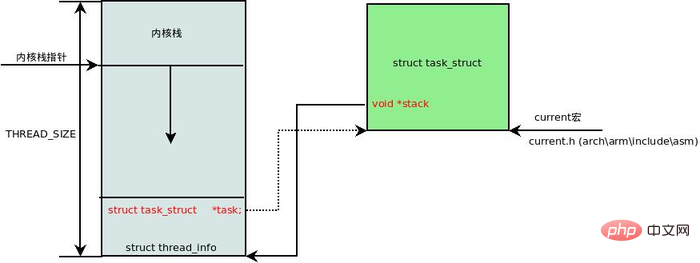
有了上述关联结构后,内核可以先获取到栈顶指针 esp,然后通过 esp 来获取 thread_info。这里有一个小技巧,直接将 esp 的地址与上 ~(THREAD_SIZE - 1) 后即可直接获得 thread_info 的地址。由于 thread_union 结构体是从 thread_info_cache 的 Slab 缓存池中申请出来的,而 thread_info_cache 在 kmem_cache_create 创建的时候,保证了地址是 THREAD_SIZE 对齐的。因此只需要对栈指针进行 THREAD_SIZE 对齐,即可获得 thread_union 的地址,也就获得了 thread_union 的地址。成功获取到 thread_info 后,直接取出它的 task 成员就成功得到了 task_struct。其实上面这段描述,也就是 current 宏的实现方法:
register unsigned long current_stack_pointer asm ("sp");
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1));
}
#define get_current() (current_thread_info()->task)
#define current get_current()进程陷入内核态的时候,需要内核栈来支持内核函数调用。中断也是如此,当系统收到中断事件后,进行中断处理的时候,也需要中断栈来支持函数调用。由于系统中断的时候,系统当然是处于内核态的,所以中断栈是可以和内核栈共享的。但是具体是否共享,这和具体处理架构密切相关。
X86 上中断栈就是独立于内核栈的;独立的中断栈所在内存空间的分配发生在 arch/x86/kernel/irq_32.c 的 irq_ctx_init() 函数中 (如果是多处理器系统,那么每个处理器都会有一个独立的中断栈),函数使用 __alloc_pages 在低端内存区分配 2个物理页面,也就是8KB大小的空间。有趣的是,这个函数还会为 softirq 分配一个同样大小的独立堆栈。如此说来,softirq 将不会在 hardirq 的中断栈上执行,而是在自己的上下文中执行。

而 ARM 上中断栈和内核栈则是共享的;中断栈和内核栈共享有一个负面因素,如果中断发生嵌套,可能会造成栈溢出,从而可能会破坏到内核栈的一些重要数据,所以栈空间有时候难免会捉襟见肘。
Empfohlenes Lernen: Linux-Video-Tutorial
Das obige ist der detaillierte Inhalt vonWas ist ein Linux-Stack?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!


















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



