Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis. Der übliche Weg, um eine hohe Verfügbarkeit zu erreichen, besteht darin, mehrere Kopien der Datenbank zu kopieren, um sie auf verschiedenen Servern bereitzustellen Es gibt drei Bereitstellungsmodi, um eine hohe Verfügbarkeit zu erreichen: den Master-Slave-Modus, den Sentinel-Modus und den Cluster-Modus.

Empfohlenes Lernen: Redis-Video-Tutorial
Hohe Verfügbarkeit von Redis
1. Warum ist Hochverfügbarkeit
- Um einzelne Fehlerpunkte zu verhindern und dazu zu führen, dass der gesamte Cluster nicht verfügbar ist?
- Der übliche Weg, eine hohe Verfügbarkeit zu erreichen, besteht darin, mehrere Kopien der Datenbank für die Bereitstellung zu kopieren verschiedene Server, auf denen auch bei Ausfall einer Maschine weiterhin Dienste bereitgestellt werden können
- Redis verfügt über drei Bereitstellungsmodi, um eine hohe Verfügbarkeit zu erreichen: Master-Slave-Modus, Sentinel-Modus und Cluster-Modus
2. Master- Slave-Modus: Der Master-Knoten ist für den Lese- und Schreibbetrieb zuständig. Das Implementierungsprinzip ist der
Master-Slave-Replikationsmechanismus
-
Die Master-Slave-Replikation umfasst vollständige Replikation und inkrementelle Replikationzwei. Diese Art von
- Wenn der Slave zum ersten Mal eine Verbindung zum Master herstellt oder wenn dies der Fall ist gilt als erste Verbindung und verwendet die vollständige Replikation
- Nachdem der Slave vollständig mit dem Master synchronisiert ist und die Daten auf dem Master erneut aktualisiert werden, wird eine Erhöhung der Volume-Replikation ausgelöst
- 3. Sentinel-Modus
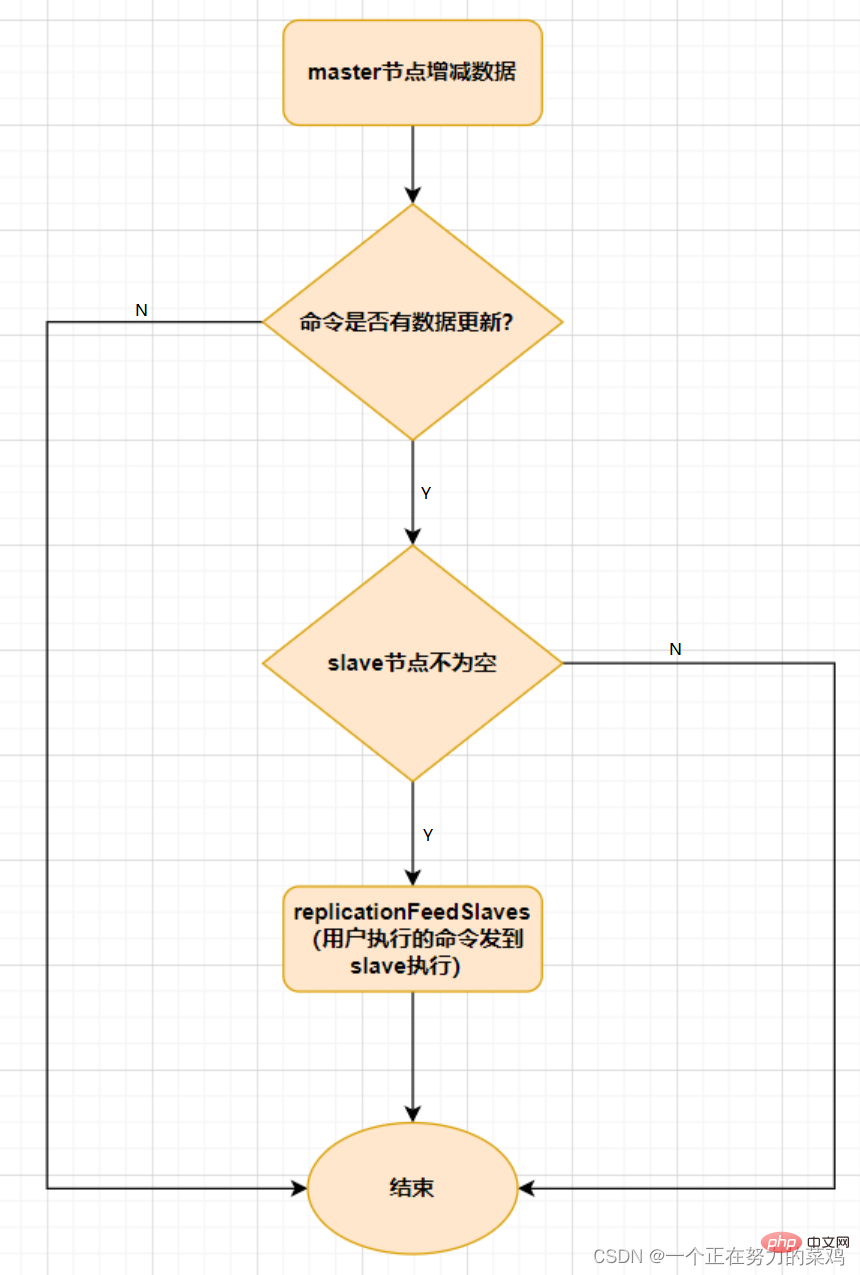
Sobald der Master-Knoten im Master-Slave-Modus aufgrund eines Fehlers keine Dienste bereitstellen kann, muss der Slave-Knoten manuell zum Master-Knoten und gleichzeitig zur Anwendungspartei heraufgestuft werden Um dieses Problem zu lösen, muss Redis in den meisten Geschäftsszenarien offiziell die Sentinel-Architektur (Sentinel) bereitstellen oder mehr Sentinel-Instanzen, die alle Redis-Masterknoten und Slave-Knoten überwacht werden können. Wenn der überwachte Master-Knoten in den Offline-Zustand wechselt, wird ein Slave-Knoten unter dem Offline-Master-Server automatisch auf einen neuen Master-Knoten aktualisiert - Bei der Überwachung von Redis-Knoten können jedoch Probleme (einzelne Punkte) auftreten, sodass mehrere Sentinels zur Überwachung von Redis-Knoten verwendet werden können und jeder Sentinel auch drei Funktionen hat
1.发送命令,等待Redis服务器(包括主服务器和从服务器)返回监控其运行状态
2.哨兵监测到主节点宕机会自动将从节点切换成主节点,然后通过发布订阅模式通知其他的从节点修改配置文件,让它们切换主机
3.哨兵之间还会相互监控,从而达到高可用
Nach dem Login kopieren
Der Failover-Prozess ist wie folgt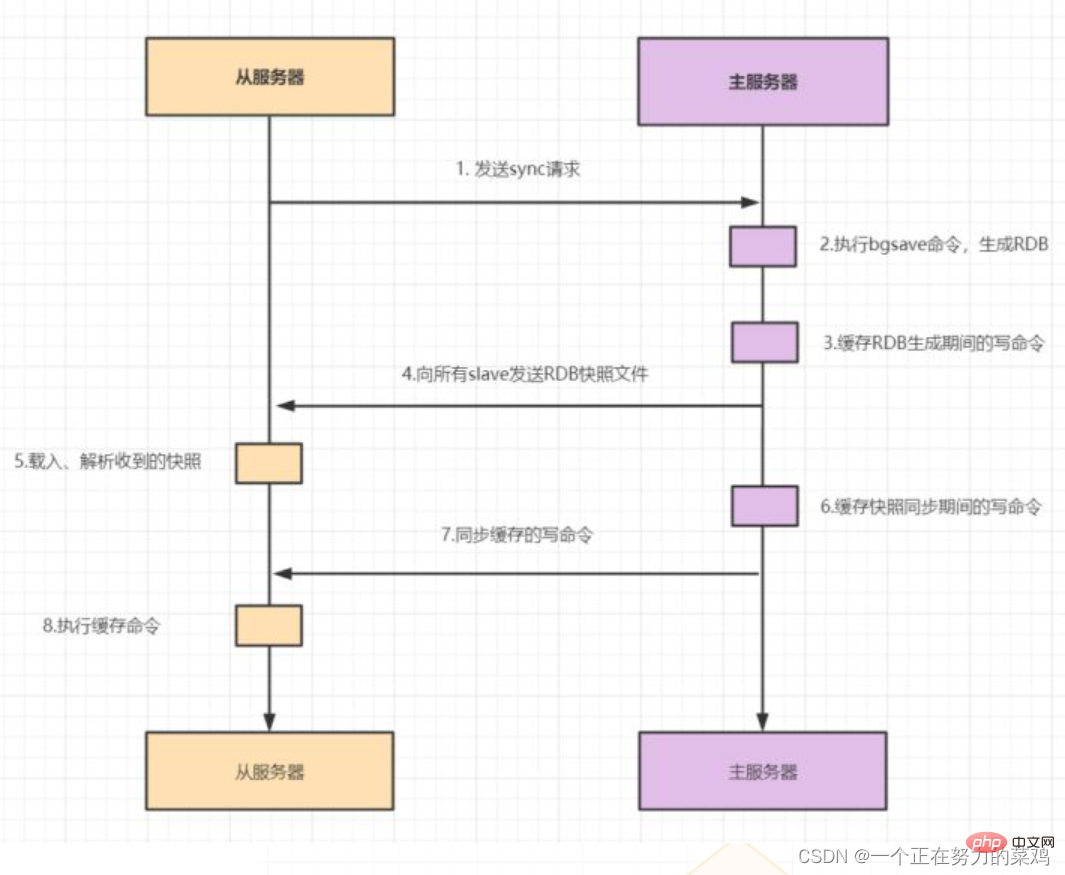
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线
当后面的哨兵也检测到主服务器不可用并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作
切换成功后通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线
这样对于客户端而言,一切都是透明的
Nach dem Login kopieren
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他Sentinel实例发送一个PING命令
如果实例距离最后一次有效回复PING命令的时间超过down-after-milliseconds选项所指定的值,则这个实例会被Sentinel标记为主观下线
如果一个Master被标记为主观下线,则正在监视这个Master的所有Sentinel要以每秒一次的频率确认Master的确进入了主观下线状态
当有足够数量的Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态,则Master会被标记为客观下线
一般情况下,每个Sentinel会以每10秒一次的频率向它已知的所有Master,Slave发送INFO命令
当Master被Sentinel标记为客观下线时,Sentinel向下线的Master的所有Slave发送INFO命令的频率会从10秒一次改为每秒一次
若没有足够数量的Sentinel同意Master已经下线,Master的客观下线状态就会被移除;若Master重新向Sentinel的PING命令返回有效回复,Master 的主观下线状态就会被移除
Nach dem Login kopieren
 4.Cluster-Cluster-Modus
4.Cluster-Cluster-Modus
Der Sentinel-Modus basiert auf dem Master-Slave-Modus, wodurch eine Lese- und Schreibtrennung erreicht wird, und kann auch Automatisch umschalten, wodurch das System verfügbarer wird. Hoch, aber die in jedem Knoten gespeicherten Daten sind gleich, was Speicher verschwendet und nicht einfach online zu erweitern ist. Daher wurde der
Cluster-Cluster- ins Leben gerufen Redis3.0 implementiert den verteilten Speicher von Redis
, das heißt, es speichert unterschiedliche Inhalte auf jedem Redis-Knoten, kann das Problem der Online-Erweiterung lösen und bietet auch Replikations- und Failover-Funktionen , und Knoten tauschen kontinuierlich Informationen aus: - Knotenfehler, neue Knotenverbindungen, Master-Slave-Knotenwechselinformationen, Slot-Informationen usw. Übliche Klatschnachrichten sind Ping, Pong, Meet, Fail Hash-Slot-Slot-Algorithmus
ping消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息
meet消息:通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换
pong消息:当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信;pong消息内部封装了自身状态数据,节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新
fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态
Nach dem Login kopieren
 Subjektiv offline
Subjektiv offline: Ein Knoten geht davon aus, dass ein anderer Knoten nicht verfügbar ist, das heißt, dieser Status ist nicht die endgültige Fehlerbeurteilung kann nur die Meinung eines Knotens darstellen.
Ziel offline: Mehrere Knoten im Cluster betrachten den Knoten als nicht verfügbar. Wenn der Master-Knoten, der den Steckplatz hält, ausfällt, muss ein Failover für den Knoten durchgeführt werden um es zu ersetzen, um die hohe Verfügbarkeit des Clusters sicherzustellen ist nicht mehr verfügbar Frage nach der Ausführung
- Kann die Ablaufzeit der Sperre länger eingestellt werden, um dieses Problem zu lösen? Offensichtlich ist die Ausführungszeit des Unternehmens ungewiss. Redisson löst dieses Problem, indem es von Zeit zu Zeit einen zeitgesteuerten Daemon-Thread für den Thread öffnet, der die Sperre erhält. Es verlängert die Ablaufzeit der Sperre, um zu verhindern, dass die Sperre abgelaufen ist und vorzeitig freigegeben wird
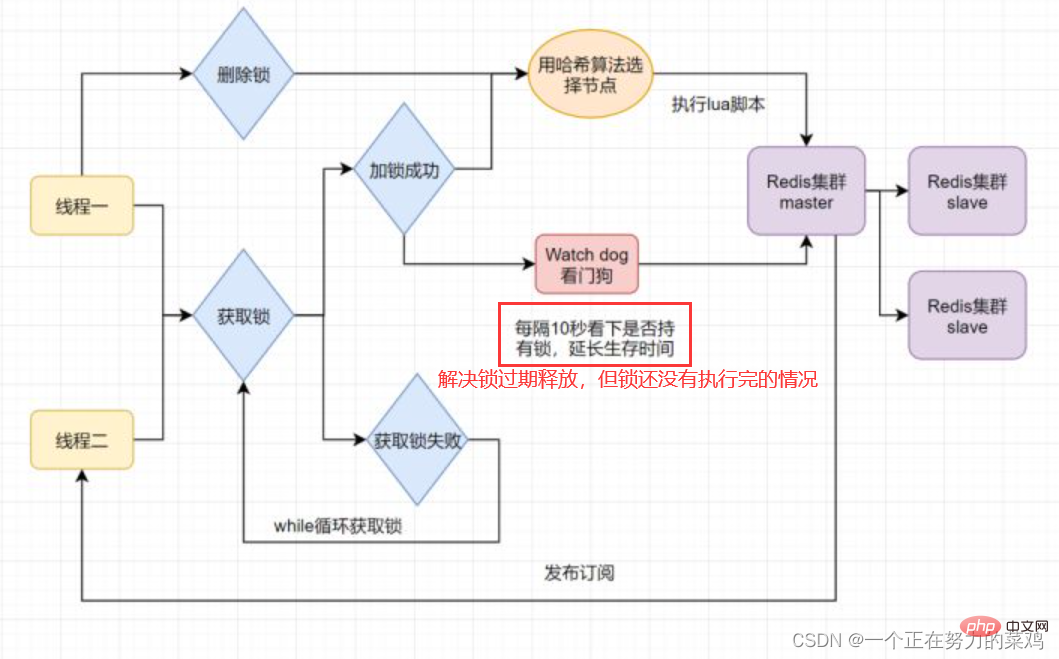
2. Redlock-Algorithmus
- Sobald der Thread die Sperre auf dem Redis-Masterknoten erhält, der gesperrte Schlüssel jedoch nicht mit dem Slave-Knoten synchronisiert wurde, fällt zu diesem Zeitpunkt der Masterknoten aus und ein Slave Knoten wird aktualisiert auf Auf dem Masterknoten kann Thread zwei die Sperre desselben Schlüssels erhalten, aber Thread eins hat auch die Sperre erhalten und die Sicherheit der Sperre ist weg
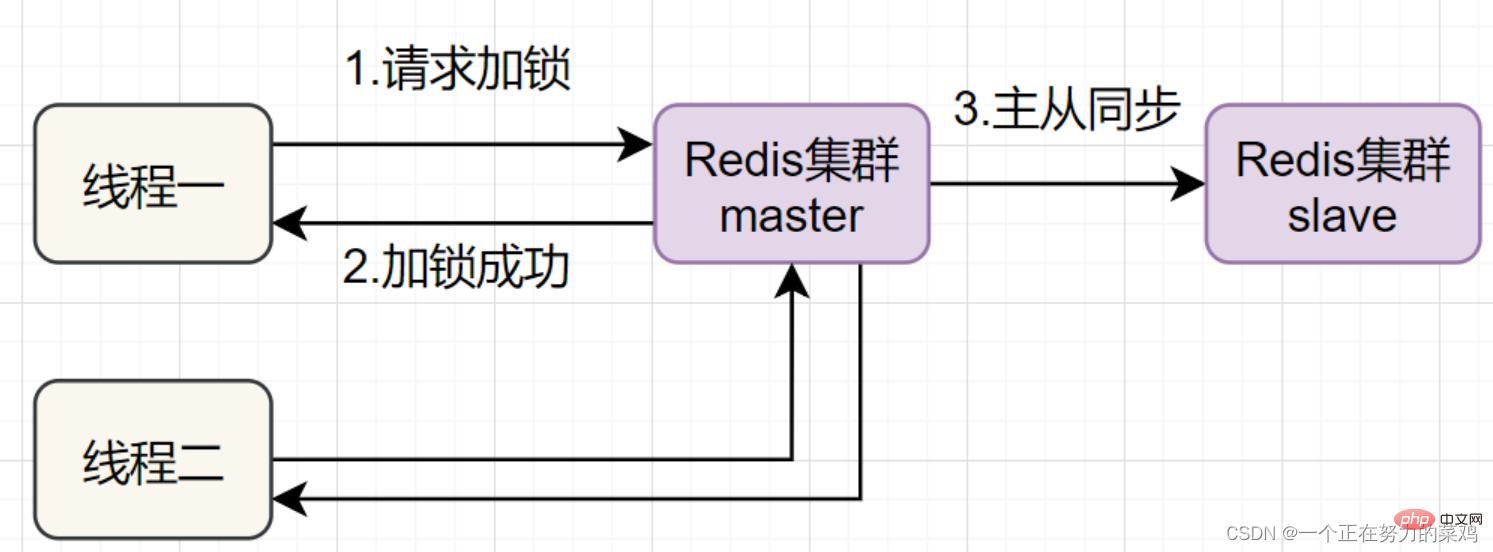
-
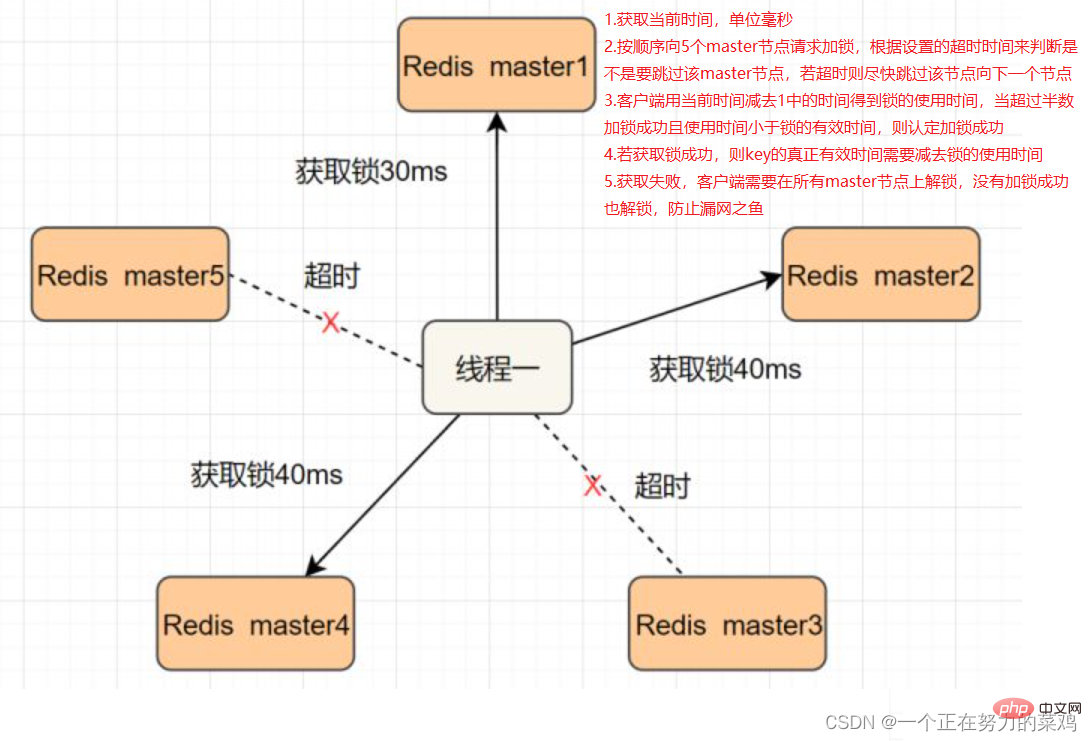
RedlockUm dieses Problem zu lösen, Stellen Sie mehrere Redis-Master bereit, um sicherzustellen, dass sie nicht gleichzeitig ausfallen. Diese Masterknoten sind „völlig unabhängig voneinander“ und es findet keine Datensynchronisierung untereinander statt. Die Implementierungsschritte sind wie folgt: Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher1. Verzögertes doppeltes Löschen
Verzögern Sie nach dem Aktualisieren der Datenbank den Ruhezustand für eine Weile und löschen Sie dann den Cache
Diese Lösung ist nur während der Ruhephase in Ordnung. Es können schmutzige Daten vorhanden sein, und das allgemeine Unternehmen wird diese auch akzeptieren
Aber wenn Sie sie zum zweiten Mal löschen, was ist mit einem Cache-Fehler? Die Daten im Cache und in der Datenbank sind möglicherweise immer noch inkonsistent. Wie wäre es, wenn Sie eine natürliche Ablaufzeit für den Schlüssel festlegen und ihn automatisch ablaufen lassen? Was soll ich tun, wenn die vom Unternehmen innerhalb der Ablaufzeit akzeptierten Daten inkonsistent sind? Es gibt noch andere bessere Lösungen
-
- 2. Mechanismus zum erneuten Löschen des Caches
- Verzögertes doppeltes Löschen kann dazu führen, dass der zweite Schritt des Löschens des Caches fehlschlägt, was zu Problemen mit der Dateninkonsistenz führt
-
Wenn der Löschvorgang fehlschlägt, löschen Sie ihn mehrmals Mal mehr Ja, stellen Sie einfach sicher, dass das Löschen des Caches erfolgreich ist, damit Sie den 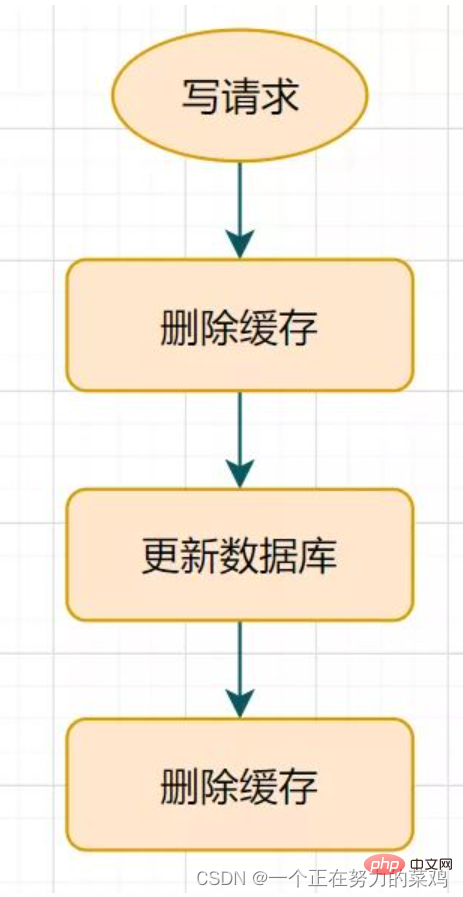 Cache-Löschwiederholungsmechanismus
Cache-Löschwiederholungsmechanismus
- 3 einführen können. Lesen Sie das Biglog und löschen Sie den Cache asynchron. Der Wiederholungsmechanismus zum Löschen des Caches führt zu einem viel Eindringen in den Geschäftscode, daher Einführung in das Lesen von Biglog und asynchrones Löschen des Caches
-
Empfohlenes Lernen: 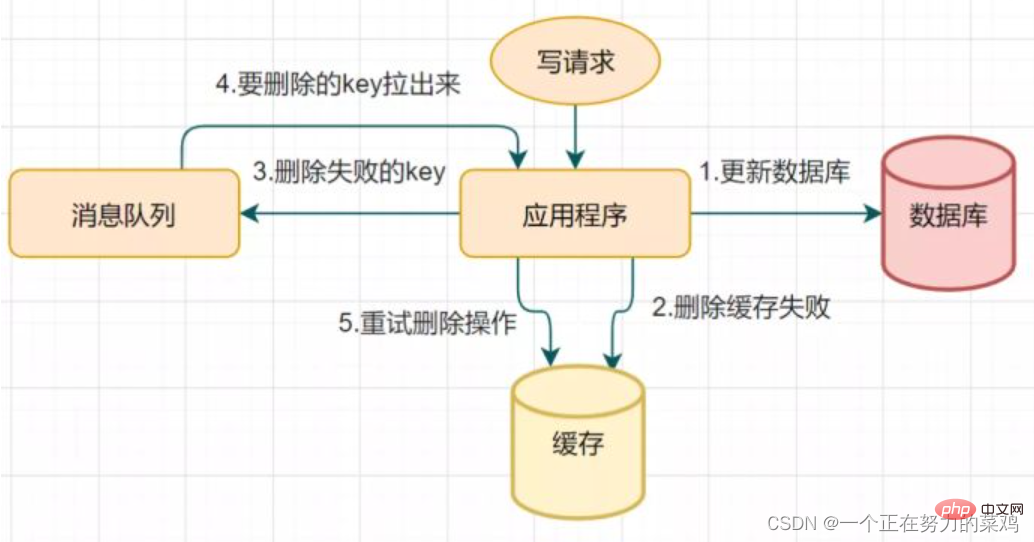 Redis-Video-Tutorial
Redis-Video-Tutorial
Das obige ist der detaillierte Inhalt vonDetaillierte grafische Erläuterung des Redis-Clusters und der Erweiterung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?











![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



