

Das Oracle-Beispiel erklärt gruppierte Daten im Detail

Dieser Artikel vermittelt Ihnen relevantes Wissen über Oracle, das hauptsächlich Probleme im Zusammenhang mit gruppierten Daten organisiert, sodass Daten in logische Gruppen unterteilt werden können, sodass aggregierte Berechnungen für jede Gruppe durchgeführt werden können. hoffe es hilft allen.

Empfohlenes Tutorial: „Oracle Video Tutorial“
Gruppierung ermöglicht die Aufteilung von Daten in logische Gruppen, sodass aggregierte Berechnungen für jede Gruppe durchgeführt werden können.
1. Erstellen Sie eine Gruppe
Gruppe wird mithilfe der GROUP BY-Klausel in der SELECT-Anweisung erstellt.
Beispiel:
SELECT vend_id, count(*) as num_prodsfrom productsgroup by vend_id;

Dank der Verwendung von GROUP BY müssen Sie nicht jede zu bewertende und zu berechnende Gruppierung angeben, dies erfolgt automatisch. Die GROUP BY-Klausel weist Oracle an, die Daten zu gruppieren und eine Aggregation für jede Gruppe durchzuführen (und nicht für die gesamte Ergebnismenge).
Bevor Sie GROUP BY verwenden, sind unten einige wichtige Regeln aufgeführt, die Sie über die Verwendung kennen müssen.
- Die GROUP BY-Klausel kann so viele Spalten wie nötig enthalten. Es ermöglicht eine verschachtelte Gruppierung und ermöglicht so eine genauere Kontrolle darüber, wie Daten gruppiert werden.
- Wenn Sie in der Group by-Klausel verschachtelte Gruppen haben, werden die Daten in der zuletzt angegebenen Gruppe zusammengefasst. Mit anderen Worten: Beim Erstellen einer Gruppierung werden alle angegebenen Spalten gemeinsam ausgewertet (Daten werden also nicht für jede einzelne Spalte abgerufen).
- Jede in der Gruppe nach aufgeführte Spalte muss eine abgerufene Spalte oder ein gültiger Ausdruck (keine Aggregatfunktion) sein. Wenn ein Ausdruck in „select“ verwendet wird, muss derselbe Ausdruck in „group by“ angegeben werden. Aliase können nicht verwendet werden.
- Mit Ausnahme von Aggregatberechnungsanweisungen sollte jede Spalte in der SELECT-Anweisung in der GROUP BY-Klausel erscheinen.
- Wenn die Gruppierungsspalte eine Spalte mit einem NULL-Wert enthält, wird NULL als Gruppierung zurückgegeben. Wenn mehrere Zeilen mit NULL-Werten vorhanden sind, werden sie alle gruppiert.
- Die GROUP BY-Klausel muss nach der WHERE-Klausel und vor der ORDER BY-Klausel stehen.
2. Filtergruppierung
Where-Klausel wird normalerweise auch für die Zeilenfilterung verwendet. Allerdings gilt „wo“ hier nicht, da „wo“ bestimmte Zeilen filtern und nicht gruppieren kann. Tatsächlich kann where nicht auf die Gruppierung angewendet werden.
Oracle bietet hierfür eine weitere Klausel: HAVING. Der einzige Unterschied zwischen der Where-Klausel und der Have-Klausel besteht darin, dass Where Zeilen filtert, während Have Filtergruppen hat.
**Tipps: **Having unterstützt alle Where-Operatoren
Die Regeln für Where und Have sind genau die gleichen, nur mit unterschiedlichen Schlüsselwörtern.
Beispiel:
SELECT cust_id, COUNT(*) AS ordersFROM ordersGROUP BY cust_idHAVING COUNT(*) >= 2;
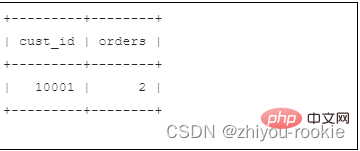
Hinweis: Der Unterschied zwischen haben und wo
Betrachten Sie den Unterschied zwischen haben und wo aus einem anderen Blickwinkel: Hier erfolgt die Filterung vor den Daten, während die Filterung vorher erfolgt Nach der Datengruppierung. Dies ist ein wichtiger Unterschied. Durch die where-Klausel gelöschte Zeilen werden nicht in die Gruppierung einbezogen. Dadurch können sich die berechneten Werte basierend auf den in der Have-Klausel verwendeten ändern, was wiederum Auswirkungen darauf haben kann, welche Gruppen gefiltert werden.
Beispiel für die gemeinsame Verwendung der Klausel „Where“ und „Having“:
select vend_id, count(*), as num_prodsfrom productswhere prod_price>=10group by vend_idhaving count(*) > 2;
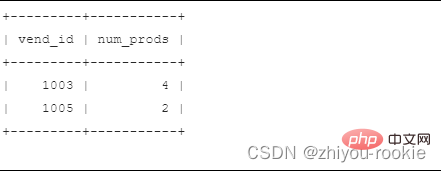
SELECT vend_id, COUNT(*) AS num_prodsFROM productsGROUP BY vend_idHAVING COUNT(*) >= 2;

3. Gruppieren und Sortieren
Der Unterschied zwischen „group by“ und „order by“ ist enorm, auch wenn sie normalerweise verwendet werden zur Vervollständigung Das Gleiche.
In der folgenden Tabelle wird der Unterschied zwischen Sortieren nach und Gruppieren nach beschrieben Gruppierungsreihenfolge
| darf nur ausgewählte Spalten oder Ausdrücke verwenden und verwendet definitiv alle ausgewählten Spaltenausdrücke | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
时常,你会发现使用GROUP BY分组的数据的确是以分组顺序输出的。但是并非总是如此,并且实际上SQL规范也并没有如此要求。而且你实际上可能希望它以不同于分组的方式进行排序。你以一种方式对数据进行分组(以获得特定于分组的聚合值),并不意味着你也希望输出以相同的方式进行排序。总是应该还提供一个显式的ORDER BY子句,即使它与GROUP BY子句完全相同。 提示:不要忘记ORDER BY
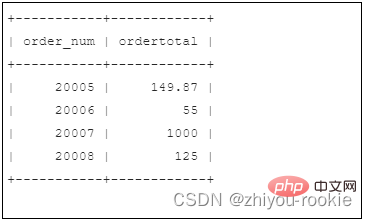
为了演示同时使用GROUP BY和ORDER BY的情况,让我们看一个示例。下面的SELECT语句类似于之前使用的SELECT语句。它用于检索总价在50以上(含50)的所有订单的订单号和订单总价: SELECT order_num, SUM(quantity*item_price) AS ordertotalFROM orderitemsGROUP BY order_numHAVING SUM(quantity*item_price) >= 50; Nach dem Login kopieren
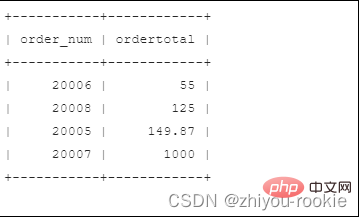
要按订单总价对输出进行排序,只需添加一个ORDER BY子句,如下: SELECT order_num, SUM(quantity*item_price) AS ordertotalFROM orderitemsGROUP BY order_numHAVING SUM(quantity*item_price) >= 50ORDER BY ordertotal; Nach dem Login kopieren
4、select子句排序select子句和它们的顺序
推荐教程:《Oracle视频教程》 |
Das obige ist der detaillierte Inhalt vonDas Oracle-Beispiel erklärt gruppierte Daten im Detail. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Was tun, wenn das Orakel nicht geöffnet werden kann
Apr 11, 2025 pm 10:06 PM
Was tun, wenn das Orakel nicht geöffnet werden kann
Apr 11, 2025 pm 10:06 PM
Lösungen für Oracle können nicht geöffnet werden, einschließlich: 1. Starten Sie den Datenbankdienst; 2. Starten Sie den Zuhörer; 3.. Hafenkonflikte prüfen; 4. Umgebungsvariablen korrekt einstellen; 5. Stellen Sie sicher, dass die Firewall- oder Antivirus -Software die Verbindung nicht blockiert. 6. Überprüfen Sie, ob der Server geschlossen ist. 7. Verwenden Sie RMAN, um korrupte Dateien wiederherzustellen. 8. Überprüfen Sie, ob der TNS -Dienstname korrekt ist. 9. Netzwerkverbindung prüfen; 10. Oracle Software neu installieren.
 So lösen Sie das Problem des Schließens von Oracle Cursor
Apr 11, 2025 pm 10:18 PM
So lösen Sie das Problem des Schließens von Oracle Cursor
Apr 11, 2025 pm 10:18 PM
Die Methode zur Lösung des Oracle Cursor Closeure -Problems umfasst: explizit den Cursor mithilfe der Close -Anweisung schließen. Deklarieren Sie den Cursor in der für Aktualisierungsklausel so, dass er nach Beendigung des Umfangs automatisch schließt. Deklarieren Sie den Cursor in der Verwendung der Verwendung so, dass er automatisch schließt, wenn die zugehörige PL/SQL -Variable geschlossen ist. Verwenden Sie die Ausnahmebehandlung, um sicherzustellen, dass der Cursor in jeder Ausnahmesituation geschlossen ist. Verwenden Sie den Verbindungspool, um den Cursor automatisch zu schließen. Deaktivieren Sie die Automatikübermittlung und Verzögerung des Cursors Schließen.
 So erstellen Sie Cursor in Oracle Loop
Apr 12, 2025 am 06:18 AM
So erstellen Sie Cursor in Oracle Loop
Apr 12, 2025 am 06:18 AM
In Oracle kann die For -Loop -Schleife Cursors dynamisch erzeugen. Die Schritte sind: 1. Definieren Sie den Cursortyp; 2. Erstellen Sie die Schleife; 3.. Erstellen Sie den Cursor dynamisch; 4. Führen Sie den Cursor aus; 5. Schließen Sie den Cursor. Beispiel: Ein Cursor kann mit dem Zyklus für Kreislauf erstellt werden, um die Namen und Gehälter der Top 10 Mitarbeiter anzuzeigen.
 So stoppen Sie die Oracle -Datenbank
Apr 12, 2025 am 06:12 AM
So stoppen Sie die Oracle -Datenbank
Apr 12, 2025 am 06:12 AM
Führen Sie die folgenden Schritte aus, um eine Oracle -Datenbank zu stoppen: 1. Eine Verbindung zur Datenbank herstellen; 2. Sofort herunterfahren; 3.. Herunterfahren vollständig.
 So paginieren Sie die Oracle -Datenbank
Apr 11, 2025 pm 08:42 PM
So paginieren Sie die Oracle -Datenbank
Apr 11, 2025 pm 08:42 PM
Oracle Database Paging verwendet Rownum Pseudo-Säulen oder Abrufanweisungen zum Implementieren: Rownum Pseudo-Säulen werden verwendet, um Ergebnisse nach Zeilennummern zu filtern und für komplexe Abfragen geeignet sind. Die Abrufanweisung wird verwendet, um die angegebene Anzahl der ersten Zeilen zu erhalten, und eignet sich für einfache Abfragen.
 Welche Schritte sind erforderlich, um CentOs in HDFs zu konfigurieren
Apr 14, 2025 pm 06:42 PM
Welche Schritte sind erforderlich, um CentOs in HDFs zu konfigurieren
Apr 14, 2025 pm 06:42 PM
Das Erstellen eines Hadoop -verteilten Dateisystems (HDFS) auf einem CentOS -System erfordert mehrere Schritte. Dieser Artikel enthält einen kurzen Konfigurationshandbuch. 1. Bereiten Sie sich auf die Installation von JDK in der frühen Stufe vor: Installieren Sie JavadevelopmentKit (JDK) auf allen Knoten, und die Version muss mit Hadoop kompatibel sein. Das Installationspaket kann von der offiziellen Oracle -Website heruntergeladen werden. Konfiguration der Umgebungsvariablen: Bearbeiten /etc /Profildatei, setzen Sie Java- und Hadoop -Umgebungsvariablen, damit das System den Installationspfad von JDK und Hadoop ermittelt. 2. Sicherheitskonfiguration: SSH-Kennwortfreie Anmeldung zum Generieren von SSH-Schlüssel: Verwenden Sie den Befehl ssh-keygen auf jedem Knoten
 So erstellen Sie Oracle Dynamic SQL
Apr 12, 2025 am 06:06 AM
So erstellen Sie Oracle Dynamic SQL
Apr 12, 2025 am 06:06 AM
SQL -Anweisungen können basierend auf der Laufzeiteingabe erstellt und ausgeführt werden, indem die dynamische SQL von Oracle verwendet wird. Zu den Schritten gehören: Vorbereitung einer leeren Zeichenfolgenvariable zum Speichern von dynamisch generierten SQL -Anweisungen. Verwenden Sie die sofortige Ausführung oder Vorbereitung, um dynamische SQL -Anweisungen zu kompilieren und auszuführen. Verwenden Sie die Bind -Variable, um die Benutzereingabe oder andere dynamische Werte an dynamische SQL zu übergeben. Verwenden Sie sofortige Ausführung oder führen Sie aus, um dynamische SQL -Anweisungen auszuführen.
 Was tun, wenn das Oracle -Protokoll voll ist
Apr 12, 2025 am 06:09 AM
Was tun, wenn das Oracle -Protokoll voll ist
Apr 12, 2025 am 06:09 AM
Wenn Oracle -Protokolldateien voll sind, können die folgenden Lösungen übernommen werden: 1) alte Protokolldateien reinigen; 2) die Größe der Protokolldatei erhöhen; 3) die Protokolldateigruppe erhöhen; 4) automatische Protokollverwaltung einrichten; 5) die Datenbank neu initialisieren. Vor der Implementierung einer Lösung wird empfohlen, die Datenbank zu sichern, um den Datenverlust zu verhindern.
