
 Backend-Entwicklung
Python-Tutorial
Detaillierte Erläuterung der drei Methoden zum Parsen von Parametern in Python
Backend-Entwicklung
Python-Tutorial
Detaillierte Erläuterung der drei Methoden zum Parsen von Parametern in Python
Detaillierte Erläuterung der drei Methoden zum Parsen von Parametern in Python

Dieser Artikel vermittelt Ihnen relevantes Wissen über Python. Die erste Option ist die Verwendung von argparse, einem beliebten Python-Modul, das speziell für das Parsen von Befehlen verwendet wird Lesen Sie eine JSON-Datei, in der wir alle Hyperparameter platzieren können. Die dritte und weniger bekannte Methode ist die Verwendung einer YAML-Datei. Schauen wir sie uns an. Ich hoffe, sie ist für alle hilfreich.

【Verwandte Empfehlung: Python3-Video-Tutorial】
Der Hauptzweck dessen, was wir heute teilen, besteht darin, die Effizienz des Codes durch die Verwendung der Befehlszeile und Konfigurationsdateien in Python zu verbessern
Los geht's!
Wir verwenden maschinelles Lernen. Um den Parameteranpassungsprozess zu üben, stehen drei Möglichkeiten zur Auswahl. Die erste Möglichkeit besteht darin, argparse zu verwenden, ein beliebtes Python-Modul zum Parsen von Befehlszeilen. Die andere besteht darin, eine JSON-Datei zu lesen, in die wir alle Hyperparameter einfügen können. Die dritte Möglichkeit besteht darin, YAML-Dateien zu verwenden. Neugierig, fangen wir an!
Voraussetzungen
Im folgenden Code verwende ich Visual Studio Code, eine sehr effiziente integrierte Python-Entwicklungsumgebung. Das Schöne an diesem Tool ist, dass es jede Programmiersprache durch die Installation von Erweiterungen unterstützt, das Terminal integriert und die gleichzeitige Arbeit mit einer großen Anzahl von Python-Skripten und Jupyter-Notebooks
Datensätzen ermöglicht, indem es den Shared Bicycle Dataset auf Kaggle
verwendet argparse
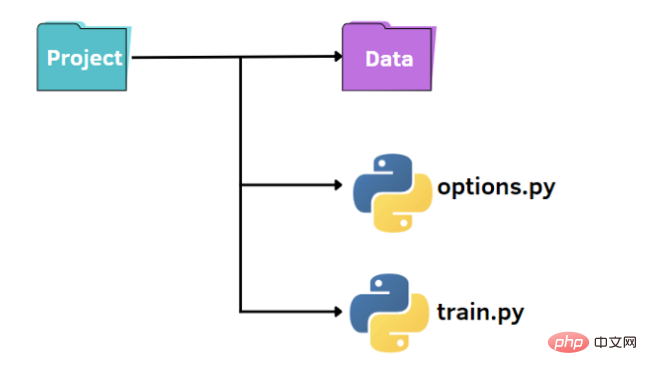
Wie im Bild oben gezeigt, haben wir eine Standardstruktur zum Organisieren unseres kleinen Projekts:
- Ein Ordner mit dem Namen data, der unseren Datensatz enthält
- train.py-Datei
- zur Angabe der Hyperparameter-Optionen.py-Datei
Zuerst können wir eine Datei train.py erstellen, in der wir die grundlegende Vorgehensweise zum Importieren der Daten, zum Trainieren des Modells anhand der Trainingsdaten und zum Auswerten am Testsatz haben:
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from options import train_options
df = pd.read_csv('data\hour.csv')
print(df.head())
opt = train_options()
X=df.drop(['instant','dteday','atemp','casual','registered','cnt'],axis=1).values
y =df['cnt'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
if opt.normalize == True:
scaler = StandardScaler()
X = scaler.fit_transform(X)
rf = RandomForestRegressor(n_estimators=opt.n_estimators,max_features=opt.max_features,max_depth=opt.max_depth)
model = rf.fit(X_train,y_train)
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_pred, y_test))
mae = mean_absolute_error(y_pred, y_test)
print("rmse: ",rmse)
print("mae: ",mae)Im Code haben wir auch die train_options importiert Funktion, die in der Datei „options.py“ enthalten ist. Bei der letztgenannten Datei handelt es sich um eine Python-Datei, aus der wir die in train.py berücksichtigten Hyperparameter ändern können:
import argparse
def train_options():
parser = argparse.ArgumentParser()
parser.add_argument("--normalize", default=True, type=bool, help='maximum depth')
parser.add_argument("--n_estimators", default=100, type=int, help='number of estimators')
parser.add_argument("--max_features", default=6, type=int, help='maximum of features',)
parser.add_argument("--max_depth", default=5, type=int,help='maximum depth')
opt = parser.parse_args()
return optIn diesem Beispiel verwenden wir die argparse-Bibliothek, die beim Parsen von Befehlszeilenargumenten sehr beliebt ist. Zuerst initialisieren wir den Parser und können dann die Parameter hinzufügen, auf die wir zugreifen möchten.
Hier ist ein Beispiel für die Ausführung des Codes:
python train.py

Um die Standardwerte von Hyperparametern zu ändern, gibt es zwei Möglichkeiten. Die erste Möglichkeit besteht darin, in der Datei „options.py“ unterschiedliche Standardwerte festzulegen. Eine andere Möglichkeit besteht darin, den Hyperparameterwert über die Befehlszeile zu übergeben:
python train.py --n_estimators 200
Wir müssen den Namen des Hyperparameters, den wir ändern möchten, und den entsprechenden Wert angeben.
python train.py --n_estimators 200 --max_depth 7
Verwendung von JSON-Dateien
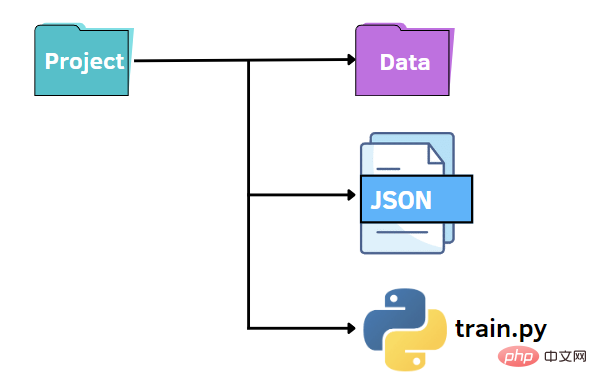
Wie zuvor können wir eine ähnliche Dateistruktur beibehalten. In diesem Fall ersetzen wir die Datei „options.py“ durch eine JSON-Datei. Mit anderen Worten: Wir wollen die Werte der Hyperparameter in einer JSON-Datei angeben und sie an die train.py-Datei übergeben. JSON-Dateien können eine schnelle und intuitive Alternative zur argparse-Bibliothek sein und Schlüssel-Wert-Paare zum Speichern von Daten nutzen. Als Nächstes erstellen wir eine Datei „options.json“, die die Daten enthält, die wir später an anderen Code übergeben müssen.
{
"normalize":true,
"n_estimators":100,
"max_features":6,
"max_depth":5
}Wie Sie oben sehen können, ist es einem Python-Wörterbuch sehr ähnlich. Aber im Gegensatz zu einem Wörterbuch enthält es Daten im Text-/String-Format. Darüber hinaus gibt es einige gängige Datentypen mit leicht unterschiedlicher Syntax. Boolesche Werte sind beispielsweise falsch/wahr, während Python Falsch/Wahr erkennt. Weitere mögliche Werte in JSON sind Arrays, die mittels eckiger Klammern als Python-Listen dargestellt werden.
Das Schöne an der Arbeit mit JSON-Daten in Python ist, dass sie über die Lademethode in ein Python-Wörterbuch konvertiert werden können:
f = open("options.json", "rb")
parameters = json.load(f)Um auf ein bestimmtes Element zuzugreifen, müssen wir nur seinen Schlüsselnamen in eckigen Klammern angeben:
if parameters["normalize"] == True: scaler = StandardScaler() X = scaler.fit_transform(X) rf=RandomForestRegressor(n_estimators=parameters["n_estimators"],max_features=parameters["max_features"],max_depth=parameters["max_depth"],random_state=42) model = rf.fit(X_train,y_train) y_pred = model.predict(X_test)
Verwendung von YAML-Dateien
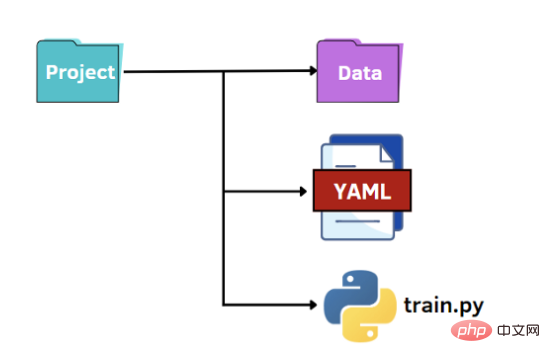
Die letzte Möglichkeit besteht darin, das Potenzial von YAML zu nutzen. Wie bei JSON-Dateien lesen wir die YAML-Datei im Python-Code als Wörterbuch, um auf die Werte der Hyperparameter zuzugreifen. YAML ist eine für Menschen lesbare Datendarstellungssprache, in der Hierarchien mithilfe von doppelten Leerzeichen anstelle von Klammern wie in JSON-Dateien dargestellt werden. Unten zeigen wir, was die Datei „options.yaml“ enthalten wird:
normalize: True n_estimators: 100 max_features: 6 max_depth: 5
In train.py öffnen wir die Datei „options.yaml“, die immer mit der Load-Methode in ein Python-Wörterbuch konvertiert wird, dieses Mal aus der Yaml-Bibliothek importiert:
import yaml
f = open('options.yaml','rb')
parameters = yaml.load(f, Loader=yaml.FullLoader)Wie zuvor können wir mithilfe der für ein Wörterbuch erforderlichen Syntax auf den Wert des Hyperparameters zugreifen.
Abschließende Gedanken
Profile lassen sich sehr schnell kompilieren, wohingegen argparse das Schreiben einer Codezeile für jedes Argument erfordert, das wir hinzufügen möchten.
Deshalb sollten wir je nach Situation die am besten geeignete Methode wählen.
Wenn wir beispielsweise Kommentare zu Parametern hinzufügen müssen, ist JSON nicht geeignet, da es keine Kommentare zulässt, während YAML und argparse möglicherweise sehr gut geeignet sind.
【Verwandte Empfehlungen: Python3-Video-Tutorial】
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der drei Methoden zum Parsen von Parametern in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
 Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
 Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python eignet sich besser für Anfänger mit einer reibungslosen Lernkurve und einer kurzen Syntax. JavaScript ist für die Front-End-Entwicklung mit einer steilen Lernkurve und einer flexiblen Syntax geeignet. 1. Python-Syntax ist intuitiv und für die Entwicklung von Datenwissenschaften und Back-End-Entwicklung geeignet. 2. JavaScript ist flexibel und in Front-End- und serverseitiger Programmierung weit verbreitet.
 So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
Im VS -Code können Sie das Programm im Terminal in den folgenden Schritten ausführen: Erstellen Sie den Code und öffnen Sie das integrierte Terminal, um sicherzustellen, dass das Codeverzeichnis mit dem Terminal Working -Verzeichnis übereinstimmt. Wählen Sie den Befehl aus, den Befehl ausführen, gemäß der Programmiersprache (z. B. Pythons Python your_file_name.py), um zu überprüfen, ob er erfolgreich ausgeführt wird, und Fehler auflösen. Verwenden Sie den Debugger, um die Debugging -Effizienz zu verbessern.
 Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
VS -Code kann unter Windows 8 ausgeführt werden, aber die Erfahrung ist möglicherweise nicht großartig. Stellen Sie zunächst sicher, dass das System auf den neuesten Patch aktualisiert wurde, und laden Sie dann das VS -Code -Installationspaket herunter, das der Systemarchitektur entspricht und sie wie aufgefordert installiert. Beachten Sie nach der Installation, dass einige Erweiterungen möglicherweise mit Windows 8 nicht kompatibel sind und nach alternativen Erweiterungen suchen oder neuere Windows -Systeme in einer virtuellen Maschine verwenden müssen. Installieren Sie die erforderlichen Erweiterungen, um zu überprüfen, ob sie ordnungsgemäß funktionieren. Obwohl VS -Code unter Windows 8 möglich ist, wird empfohlen, auf ein neueres Windows -System zu upgraden, um eine bessere Entwicklungserfahrung und Sicherheit zu erzielen.
 PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP entstand 1994 und wurde von Rasmuslerdorf entwickelt. Es wurde ursprünglich verwendet, um Website-Besucher zu verfolgen und sich nach und nach zu einer serverseitigen Skriptsprache entwickelt und in der Webentwicklung häufig verwendet. Python wurde Ende der 1980er Jahre von Guidovan Rossum entwickelt und erstmals 1991 veröffentlicht. Es betont die Lesbarkeit und Einfachheit der Code und ist für wissenschaftliche Computer, Datenanalysen und andere Bereiche geeignet.
 Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
VS -Code -Erweiterungen stellen böswillige Risiken dar, wie das Verstecken von böswilligem Code, das Ausbeutetieren von Schwachstellen und das Masturbieren als legitime Erweiterungen. Zu den Methoden zur Identifizierung böswilliger Erweiterungen gehören: Überprüfung von Verlegern, Lesen von Kommentaren, Überprüfung von Code und Installation mit Vorsicht. Zu den Sicherheitsmaßnahmen gehören auch: Sicherheitsbewusstsein, gute Gewohnheiten, regelmäßige Updates und Antivirensoftware.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
