

Dieser Artikel vermittelt Ihnen relevantes Wissen über Java. Er stellt vor allem die rekursive DDL-Anwendung des Java-Lexikonanalysators vor. Ich hoffe, er wird Ihnen gemeinsam helfen alle.

Empfohlenes Lernen: „Java-Video-Tutorial“
Da es kein fertiges Tool gibt, schreiben Sie selbst eines
Angesichts der Tatsache, dass wir hauptsächlich PyCharm für die Entwicklung verwenden Es ist einfach so, dass jetbrains auch SDK für die Entwicklung von Plug-Ins bereitstellt, sodass keine Notwendigkeit besteht, die UI-Ebene zu berücksichtigen. PyCharm开发,正好jetbrains也提供了SDK用于开发插件,所以UI层面可以不用额外考虑了。
使用流程很简单,只需要导入DDL语句就可以生成Python所需要的Model代码。
例如导入以下 DDL:
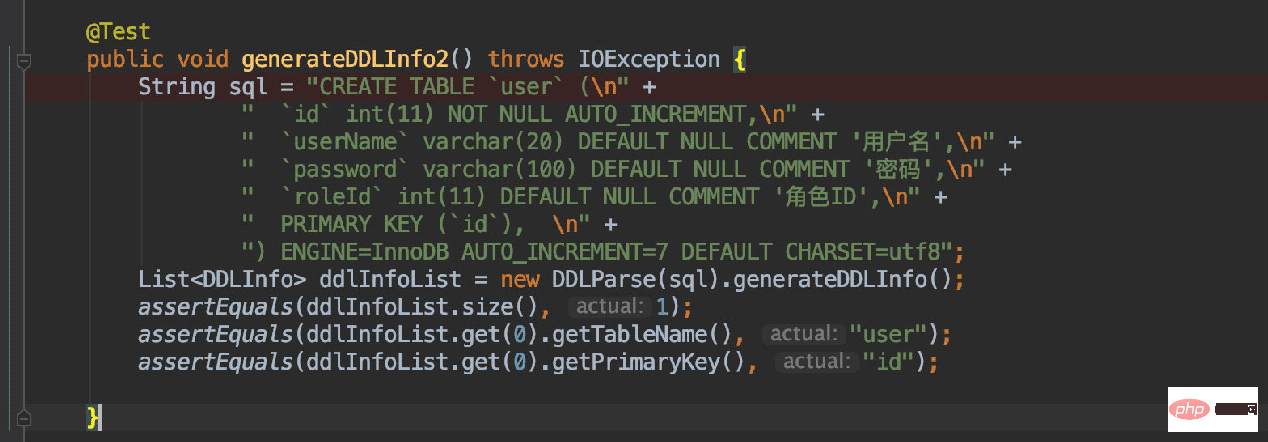
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码', `roleId` int(11) DEFAULT NULL COMMENT '角色ID', PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
便会生成对应的 Python 代码:
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
userName = db.Column(db.String) # 用户名
password = db.Column(db.String) # 密码
roleId = db.Column(db.Integer) # 角色ID仔细对比源文件及目标代码会很容易找出规律,无非就是解析出表名、字段、及字段的属性(是否为主键、类型、长度),最后再转换为Python所需要的模板即可。
在我动手之前我认为是非常简单的,无非就是解析字符串,但实际上手后发现不是那么回事;主要是有以下几个问题:
总结一句话,如何通过一系列规则识别出一段字符串中的关键信息,这同样也是 MySQL Server 所做的事情。
在开始真正解析 DDL 之前,先来看下一段简单的脚本如何解析:
x = 20
按照我们平时开发的经验,这条语句分为以下几部分:
x表示变量=表示赋值符号20表示赋值结果所以我们对这段脚本的解析结果应当为:
VAR x
GE =
VAL 100
这个解析过程在编译原理中称为”词法解析“,可能大家听到编译原理这几个字就头大(我也是);对于刚才那段脚本我们可以编写一个非常简单的词法解析器生成这样的结果。
再开始之前先捋一下思路,可以看到上文的结果中通过VAR表示变量、GE表示赋值符号 ”=“、VAL表示赋值结果,现在需要重点记住这三个状态。
在依次读取字符解析时,程序就是在这几个状态中来回切换,如下图:
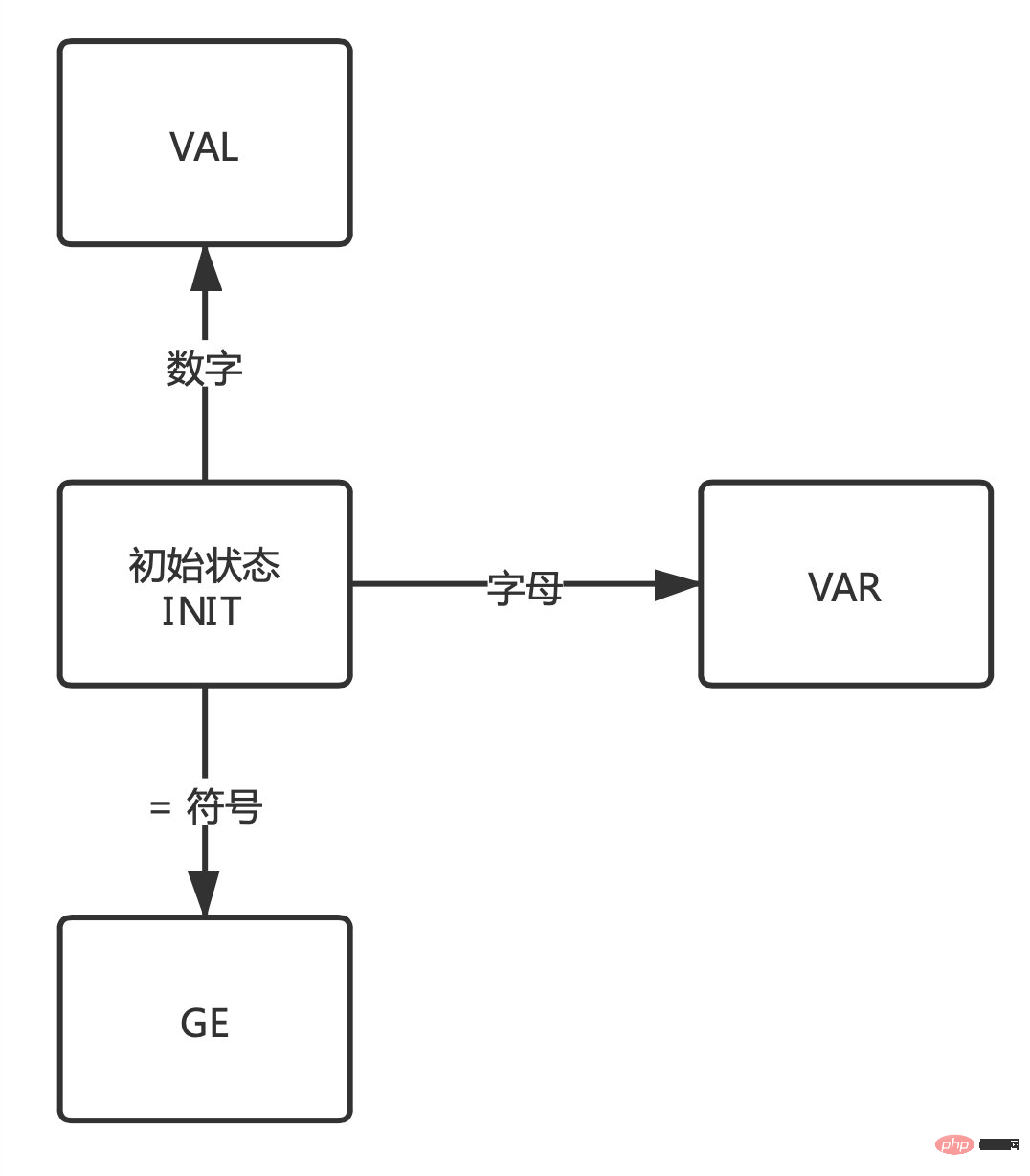
VAR状态。GE状态。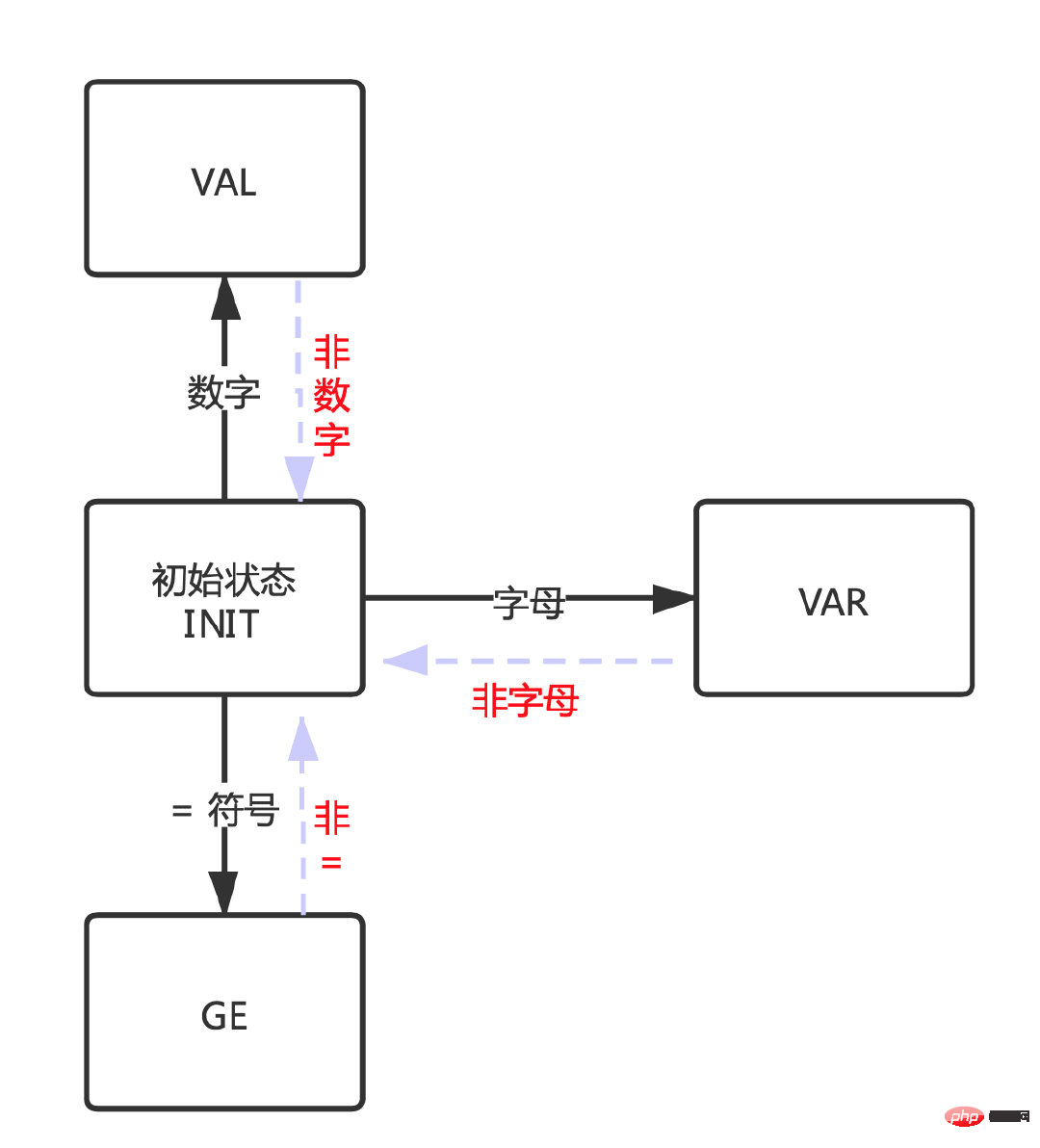
同理,当不满足这几个状态时候又会回到初始从而再次确认新的状态。
光看图有点抽象,直接来看核心代码:
public class Result{
public TokenType tokenType ;
public StringBuilder text = new StringBuilder();
}首先定义了一个结果类,收集最终的解析结果;其中的TokenType就对应了图中的三种状态,简单的用枚举值来表示。
public enum TokenType {
INIT,
VAR,
GE,
VAL
}首先对应到第一张图:初始化状态。
需要对当前解析的字符定义一个TokenType:
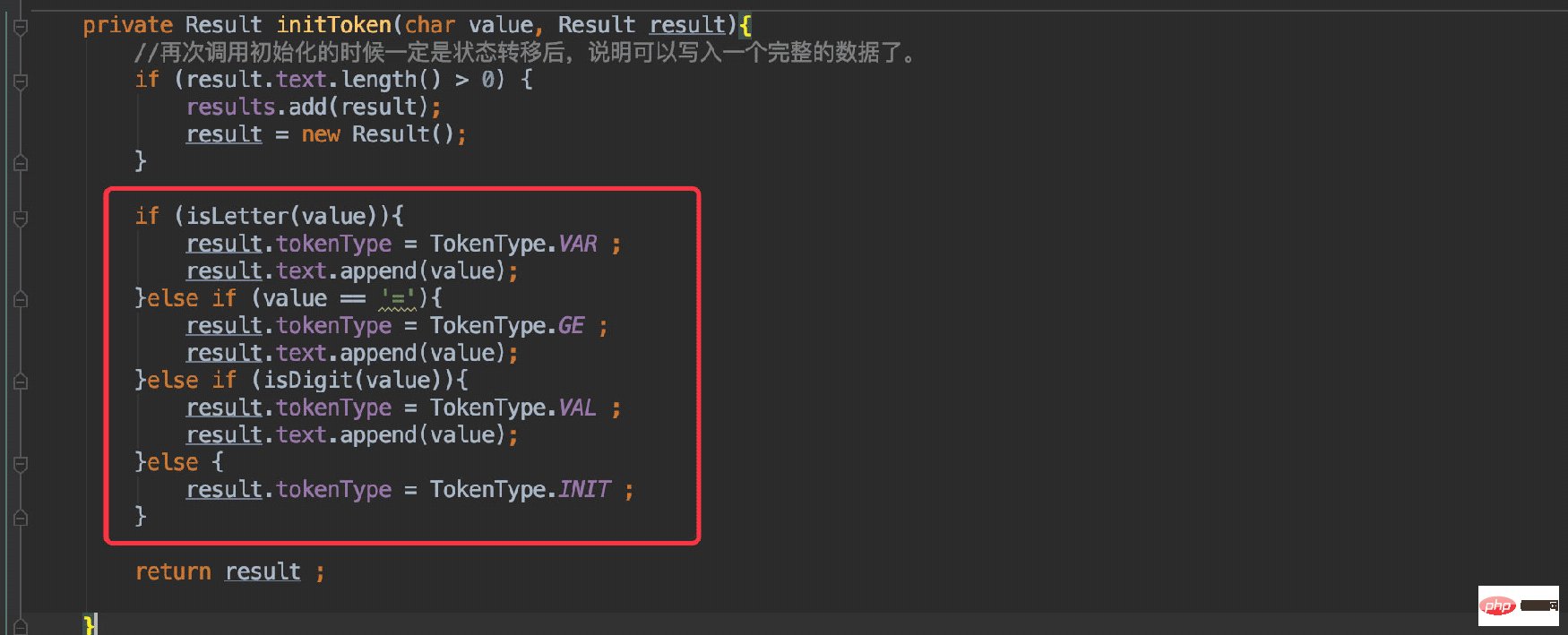
和图中描述的流程一致,判断当前字符给定一个状态即可。
接着对应到第二张图:状态之间的转换。
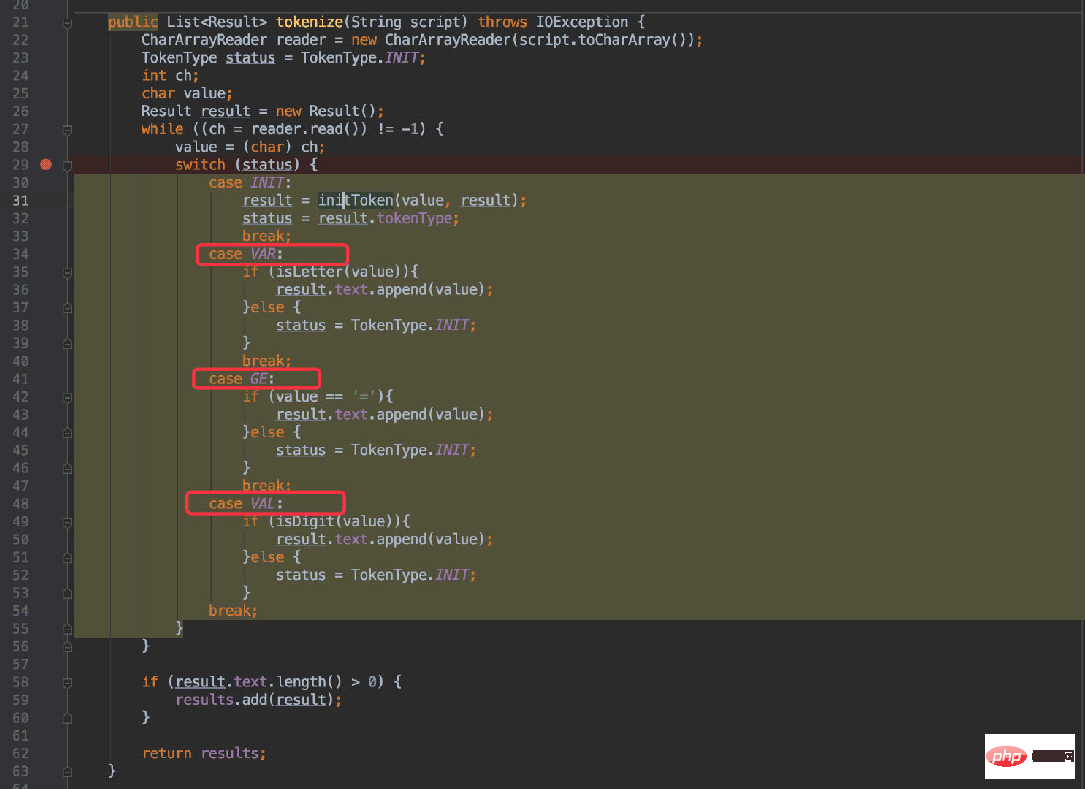
会根据不同的状态进入不同的case,在不同的case中判断是否应当跳转到其他状态(进入INIT状态后会重新生成状态)。
举个例子:x = 20:
首选会进入VAR状态,接着下一个字符为空格,自然在 38 行中重新进入初始状态,导致再次确定下一个字符=进入GE状态。
当脚本为ab = 30:
第一个字符为 a 也是进入VAR
DDL-Anweisung importieren, um den für Python erforderlichen Model-Code zu generieren. Importieren Sie beispielsweise die folgende DDL:🎜CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码', `roleId` int(11) DEFAULT NULL COMMENT '角色ID', PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
`userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码',
Python erforderliche Vorlage. 🎜🎜Bevor ich anfing, dachte ich, es sei nichts weiter als das Parsen einer Zeichenfolge, aber tatsächlich stellte ich fest, dass dies nicht der Fall war: 🎜🎜x = 20🎜🎜Nach unserer üblichen Entwicklungserfahrung ist diese Aussage in die unterteilt folgende Teile: 🎜
x stellt eine Variable dar= stellt ein Zuweisungssymbol dar 20 Stellt das Zuweisungsergebnis dar🎜VAR x🎜🎜GE =🎜🎜VAL 100🎜🎜Dies Der Analysevorgang erfolgt während der Kompilierung. Das Prinzip wird als „lexikalisches Parsen“ bezeichnet. Wenn Sie das Wort „Kompilierungsprinzip“ hören, können wir gerade einen sehr einfachen lexikalischen Parser schreiben Ergebnis. 🎜
VAR für Variablen und GE für Zuweisungssymbole steht. „=" und VAL stellen das Zuweisungsergebnis dar. Jetzt müssen Sie sich darauf konzentrieren, sich diese drei Zustände zu merken. 🎜🎜Beim Lesen und Parsen von Zeichen nacheinander wechselt das Programm zwischen diesen Zuständen hin und her, wie unten gezeigt: 🎜 🎜
🎜
VAR. GE.  🎜🎜Wenn diese Zustände nicht erfüllt sind, wird in ähnlicher Weise in den Ausgangszustand zurückgekehrt, um den neuen Zustand erneut zu bestätigen. 🎜🎜Nur das Bild ist etwas abstrakt. Schauen wir uns direkt den Kerncode an: 🎜
🎜🎜Wenn diese Zustände nicht erfüllt sind, wird in ähnlicher Weise in den Ausgangszustand zurückgekehrt, um den neuen Zustand erneut zu bestätigen. 🎜🎜Nur das Bild ist etwas abstrakt. Schauen wir uns direkt den Kerncode an: 🎜
} else if (value == '`' && pStatus == Status.BASE_INIT) {
result.tokenType = DDLTokenType.FI;
result.text.append(value);
}TokenType entspricht den drei Zuständen in Das Bild wird einfach durch Aufzählungswerte dargestellt. 🎜`userName` varchar(20) DEFAULT NULL COMMENT '用户名',
TokenType für das aktuell geparste Zeichen definieren: 🎜 🎜🎜 stimmt mit dem im Bild beschriebenen Prozess überein. Es muss lediglich der aktuelle Charakter ermittelt und ihm ein Status zugewiesen werden. 🎜🎜Dann entspricht das zweite Bild: der Übergang zwischen Zuständen. 🎜
🎜🎜 stimmt mit dem im Bild beschriebenen Prozess überein. Es muss lediglich der aktuelle Charakter ermittelt und ihm ein Status zugewiesen werden. 🎜🎜Dann entspricht das zweite Bild: der Übergang zwischen Zuständen. 🎜
🎜🎜 Geben Sie je nach Status unterschiedliche case ein und beurteilen Sie, ob in verschiedenen case-Zuständen zu anderen Status gesprungen werden soll (geben Sie den INIT-Status ein). wird später neu generiert). 🎜🎜Zum Beispiel: x = 20:🎜🎜Bei der ersten Auswahl wird der Status VAR eingegeben, und beim nächsten Zeichen handelt es sich natürlich um ein Leerzeichen Der Anfangszustand wird in Zeile 38 angezeigt, was zu Folgendem führt: Bestätigen Sie das nächste Zeichen = erneut, um in den Zustand GE zu gelangen. 🎜🎜Wenn das Skript ab = 30 ist:
das erste Zeichen ist a, das auch in den VAR-Status wechselt, und das zweite Zeichen ist b, was der Fall ist immer noch ein Buchstabe, also geben Sie Zeile 36 ein, der Status ändert sich nicht und das Zeichen b wird angehängt. Die folgenden Schritte sind die gleichen wie im vorherigen Beispiel. 🎜🎜Es ist sinnlos, mehr zu sagen. Ich schlage vor, dass Sie den Einzeltest selbst durchführen und Sie werden verstehen: 🎜
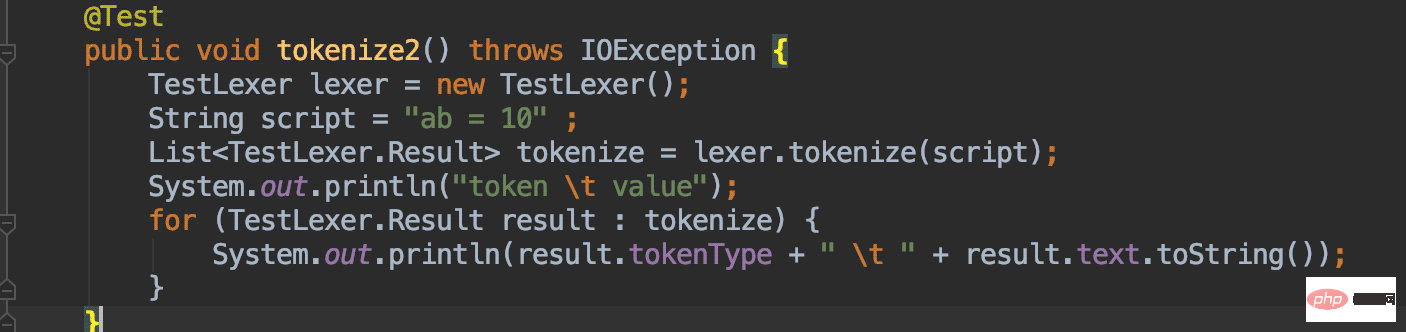
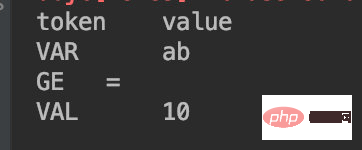
简单的解析完成后来看看DDL这样的脚本应当如何解析:
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码', `roleId` int(11) DEFAULT NULL COMMENT '角色ID', PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
原理类似,首先还是要看出规律(也就是语法):
CREATE TABLE开头。)结尾。根据我们需要解析的数据种类,我这里定义了这个枚举:
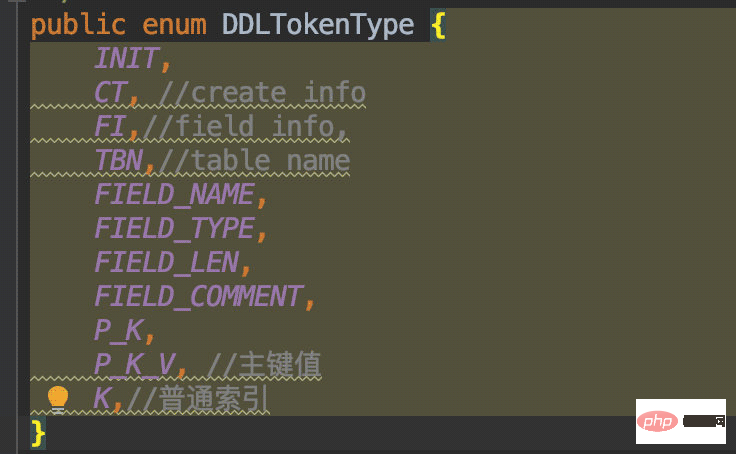
然后在初始化类型时进行判断赋值:
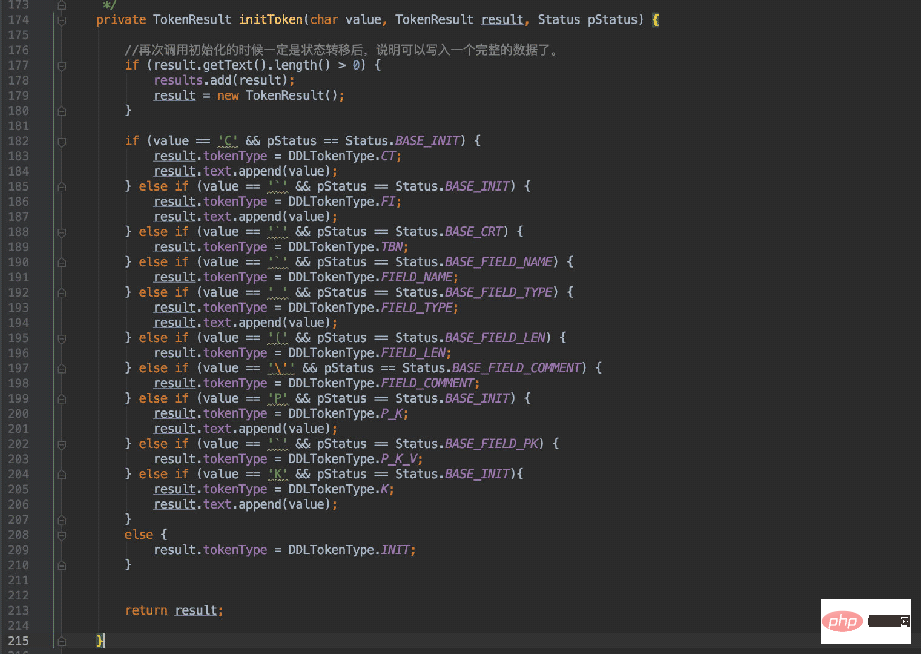
由于需要解析的数据不少,所以这里的判断条件自然也就多了。
针对于DDL的语法规则,我们这里还有需要有特殊处理的地方;比如解析具体字段信息时如何关联起来?
举个例子:
`userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码',
这里我们解析出来的数据得有一个映射关系:
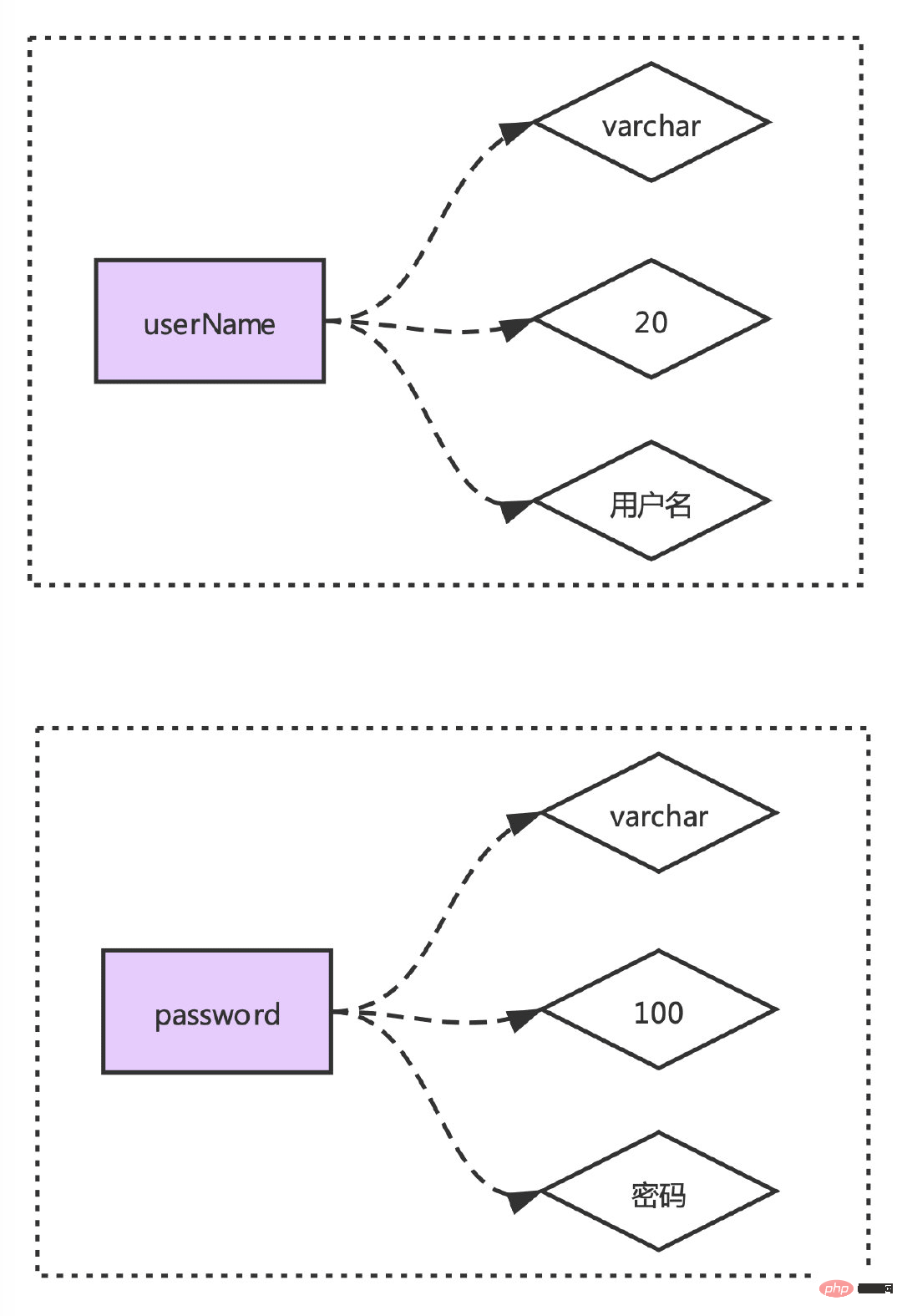
所以我们只能一个字段的全部信息解析完成并且关联好之后才能解析下一个字段。
于是这里我采用了递归的方式进行解析(不一定是最好的,欢迎大家提出更优的方案)。
} else if (value == '`' && pStatus == Status.BASE_INIT) {
result.tokenType = DDLTokenType.FI;
result.text.append(value);
}当当前字符为 ”`“ 符号时,将状态置为 “FI”(FieldInfo),同时当解析到为 “,” 符号时便进入递归处理。
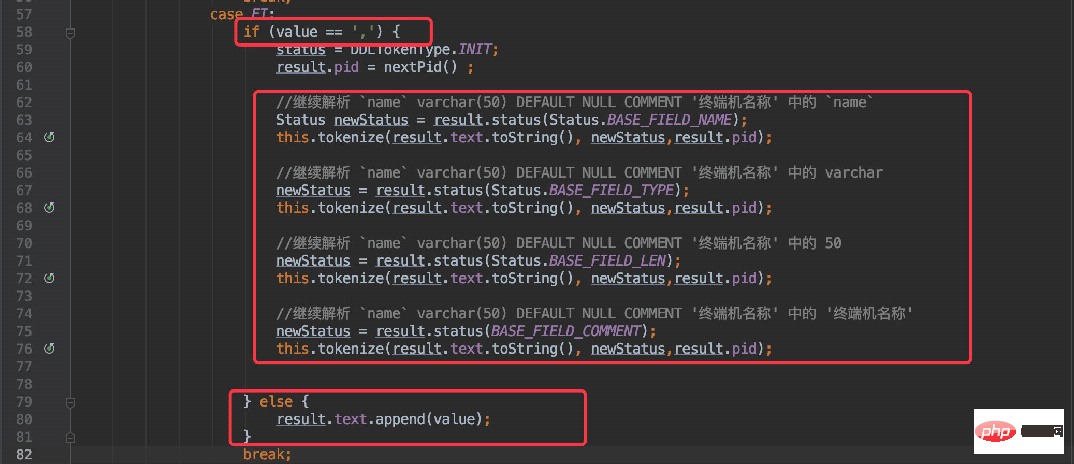
可以理解为将这一段字符串单独提取出来处理:
`userName` varchar(20) DEFAULT NULL COMMENT '用户名',
接着再将这段字符递归调用当前方法再次进行解析,这时便按照字段名称、类型、长度、注释的规则解析即可。
同时既然存在递归,还需要将子递归的数据关联起来,所以我在返回结果中新增了一个pid的字段,这个也容易理解。
默认值为 0,一旦递归后便自增 +1,保证每次递归的数据都是唯一的。
用同样的方法在解析主键时也是先将整个字符串提取出来:
PRIMARY KEY (`id`)
只不过是 “P” 打头 “)” 结尾。
} else if (value == 'P' && pStatus == Status.BASE_INIT) {
result.tokenType = DDLTokenType.P_K;
result.text.append(value);
}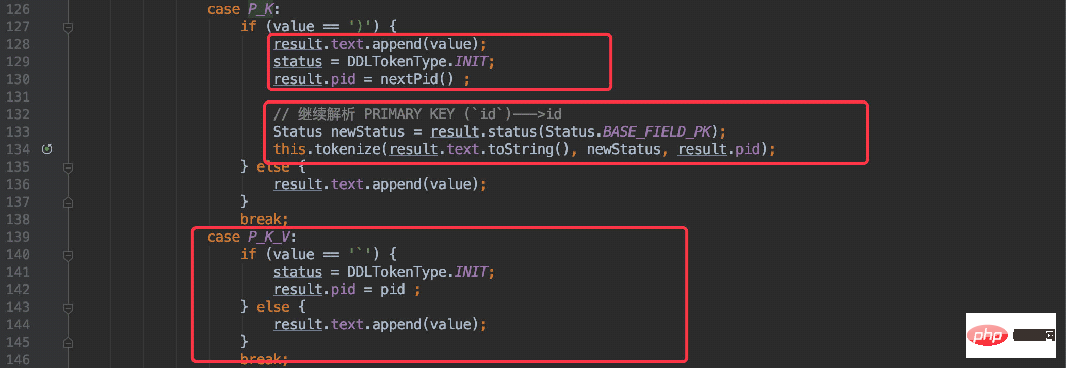
也是将整段字符串递归解析,再递归的过程中进行状态切换P_K ---> P_K_V最终获取到主键。
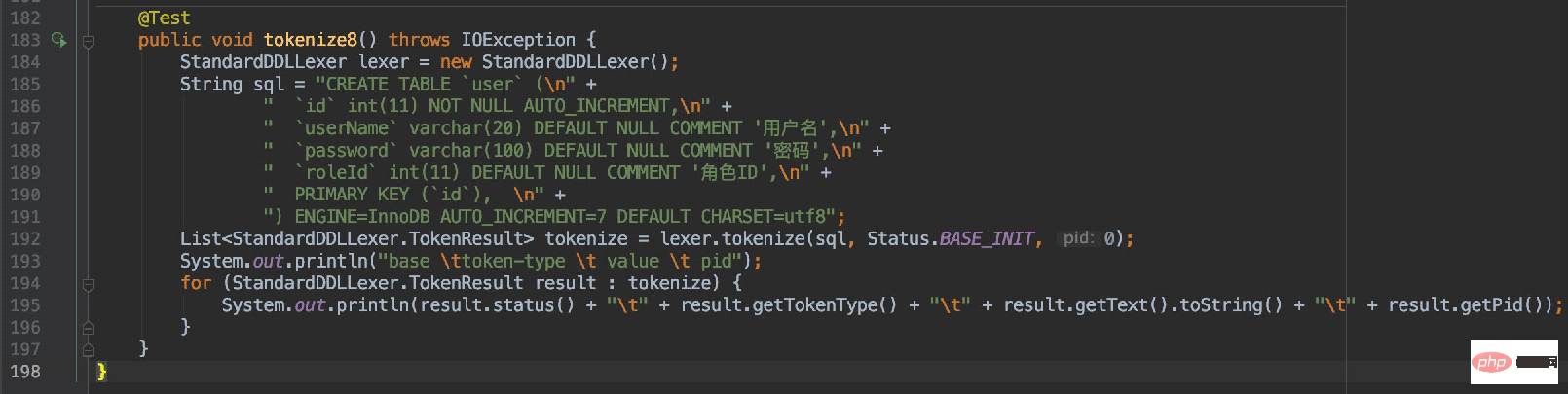
所以通过对刚才那段DDL解析得到的结果如下:
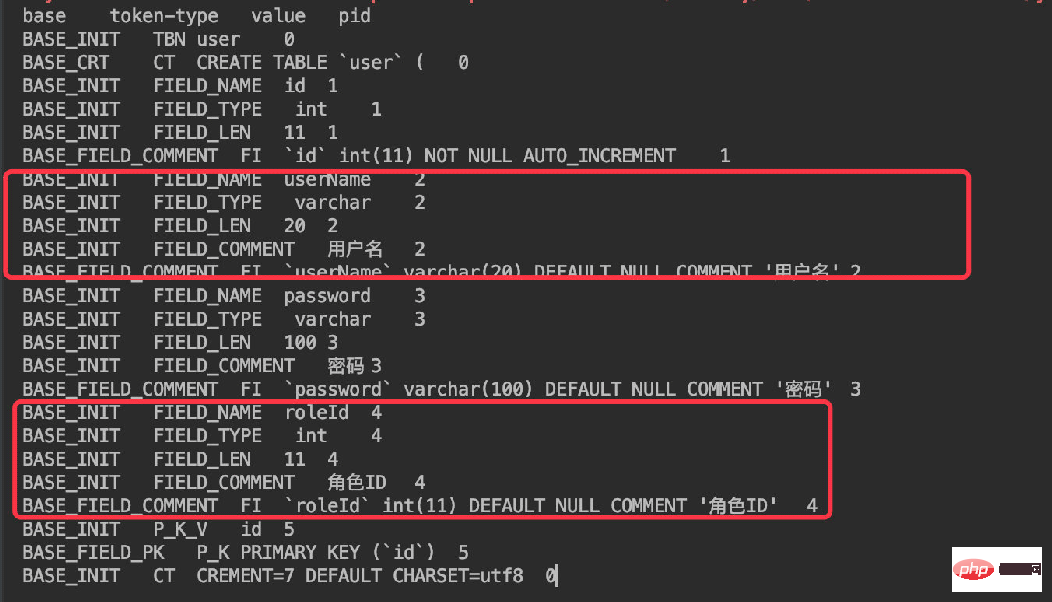
这样每个字段也通过了pid进行了区分关联。
所以现在只需要对这个词法解析器进行封装,便可以提供一个简单的API来获取表中的数据了。
推荐学习:《java视频教程》
Das obige ist der detaillierte Inhalt vonDetaillierte Analyse der rekursiven DDL-Anwendung des Java-Lexikalanalysators. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!









![JavaScript-Kern-Tutorial [DOM-Stücklistenoperationen, die JS kennen muss]](https://img.php.cn/upload/course/000/000/041/61c56ae28d02a390.jpg)
![TypeScript-Einführungsvideo [kann auch ohne JavaScript-Lernen verstanden werden]](https://img.php.cn/upload/course/000/000/068/6242c0fc4be39373.png)







![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



