

So lösen Sie das MySQL-Deep-Paging-Problem

Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL und stellt hauptsächlich die elegante Lösung für das Deep-Paging-Problem von MySQL vor. In diesem Artikel wird erläutert, wie das Deep-Paging-Problem optimiert werden kann, wenn die MySQL-Tabelle eine große Datenmenge enthält, und das Pseudonym angehängt Ich hoffe, dass der Code eines aktuellen Falls zur Optimierung langsamer SQL-Probleme für alle hilfreich ist.

Empfohlenes Lernen: MySQL-Video-Tutorial
Im täglichen Nachfrageentwicklungsprozess wird meiner Meinung nach jeder mit Limit vertraut sein, aber wenn Limit verwendet wird und der Offset (Offset) sehr groß ist, werden Sie eine Abfrage finden Effizienz Immer langsamer. Wenn der Grenzwert zu Beginn 2000 beträgt, kann es 200 ms dauern, die erforderlichen Daten abzufragen. Wenn der Grenzwert jedoch 4000 Offset 100000 beträgt, werden Sie feststellen, dass die Abfrageeffizienz bereits etwa 1 S erfordert immer schlimmer.
Zusammenfassung
In diesem Artikel wird erläutert, wie das Deep-Paging-Problem optimiert werden kann, wenn die MySQL-Tabelle eine große Datenmenge enthält, und der Pseudocode eines aktuellen Falls zur Optimierung des langsamen SQL-Problems angehängt werden.
1. Beschreibung des Deep-Paging-Problems
Werfen wir zunächst einen Blick auf die Tabellenstruktur (geben Sie nur ein Beispiel, die Tabellenstruktur ist unvollständig und nutzlose Felder werden nicht angezeigt)
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
Nehmen wir das Deep-Paging-SQL an, das wir verwenden möchten Die Abfrage sieht so aus
select * from p2p_detail_record ppdr where ppdr .start_time_stamp >1656666798000 limit 0,2000

Die Abfrageeffizienz beträgt 94 ms. Ist sie schnell? Wenn wir also 100.000 oder 2.000 begrenzen, beträgt die Abfrageeffizienz 1,5 S, was bereits sehr langsam ist. Was ist, wenn es mehr sind?

2. Analyse der Gründe für langsames SQL
Lassen Sie uns einen Blick auf den Ausführungsplan dieses SQL werfen

und wir haben auch den Index erreicht. Warum ist er also immer noch langsam? ? Lassen Sie uns zunächst die relevanten Wissenspunkte von MySQL überprüfen.
Clustered-Index und Nicht-Clustered-Index
Clustered-Index: Blattknoten speichern die gesamte Datenzeile.
Nicht gruppierter Index: Der Blattknoten speichert den Primärschlüsselwert, der der gesamten Datenzeile entspricht.
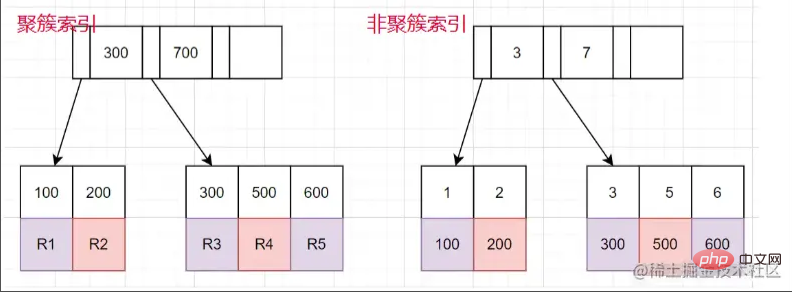
Der Prozess der Verwendung einer nicht gruppierten Indexabfrage
- Suchen Sie den entsprechenden Blattknoten über den nicht gruppierten Indexbaum und erhalten Sie den Wert des Primärschlüssels.
- Rufen Sie dann den Wert des Primärschlüssels ab und kehren Sie zum Clustered-Index-Baum zurück, um die entsprechende gesamte Datenzeile zu finden. (Der gesamte Vorgang wird als Tabellenrückgabe bezeichnet.)
limit 100000,10 scannt 100010 Zeilen, während limit 0,10 nur 10 Zeilen scannt. Hier müssen wir 100010 Mal zur Tabelle zurückkehren, und es wird viel Zeit für die Rückkehr zur Tabelle aufgewendet. Kernidee der Lösung:limit 100000,10,就会扫描100010行,而limit 0,10,只扫描10行。这里需要回表100010次,大量的时间都在回表这个上面。
方案核心思路: 能不能事先知道要从哪个主键ID开始,减少回表的次数
常见解决方案
通过子查询优化
select * from p2p_detail_record ppdr where id >= (select id from p2p_detail_record ppdr2 where ppdr2 .start_time_stamp >1656666798000 limit 100000,1) limit 2000
相同的查询结果,也是10W条开始的第2000条,查询效率为200ms,是不是快了不少。
标签记录法
标签记录法: 其实标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。类似书签的作用
select * from p2p_detail_record ppdr where ppdr.id > 'bb9d67ee6eac4cab9909bad7c98f54d4' order by id limit 2000 备注:bb9d67ee6eac4cab9909bad7c98f54d4是上次查询结果的最后一条ID
使用标签记录法,性能都会不错的,因为命中了idKönnen wir im Voraus wissen, mit welcher Primärschlüssel-ID wir beginnen sollen, um die Anzahl der Tabellenrückgaben zu reduzieren?Gemeinsame Lösungen
- Optimierung durch Unterabfragen
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
Nach dem Login kopierenNach dem Login kopierenNach dem Login kopierenDie gleiche Abfrage Das Ergebnis ist auch der 2000. Artikel mit 100.000 Artikeln. Die Abfrageeffizienz beträgt 200 ms, was viel schneller ist.  Tag-Aufzeichnungsmethode
Tag-Aufzeichnungsmethode
- Markieren Sie tatsächlich den Artikel, den Sie zuletzt überprüft haben. Wenn Sie das nächste Mal erneut nachsehen, beginnen Sie mit dem Scannen ab diesem Artikel.
- Ähnlich wie bei Lesezeichen
//最小ID String lastId = null; //一页的条数 Integer pageSize = 2000; List<P2pRecordVo> list ; do{ list = listP2pRecordByPage(lastId,pageSize); //标签记录法,记录上次查询过的Id lastId = list.get(list.size()-1).getId(); //获取上一次查询数据最后的ID,用于记录 //对数据的操作逻辑 XXXXX(); }while(isNotEmpty(list)); <select id ="listP2pRecordByPage"> select * from p2p_detail_record ppdr where 1=1 <if test = "lastId != null"> and ppdr.id > #{lastId} </if> order by id asc limit #{pageSize} </select>Nach dem Login kopierenNach dem Login kopierenBei Verwendung der Tag-Aufzeichnungsmethode ist die Leistung gut, da der Index
id erreicht wird. Diese Methode hat jedoch mehrere .
1. Sie können nur auf aufeinanderfolgenden Seiten abfragen, nicht seitenübergreifend.2. Es wird ein Feld ähnlich kontinuierlicher automatischer Inkrementierung benötigt (Order by id kann verwendet werden). Lösungsvergleich
- Verwendung der Methode zur Unterabfrageoptimierung
Vorteile: Eine seitenübergreifende Abfrage ist möglich und Sie können die Daten auf jeder gewünschten Seite überprüfen.
Nachteile: Nicht so effizient wie die
Tag-Aufzeichnungsmethode🎜. 🎜Grund:🎜 Nachdem Sie beispielsweise 100.000 Daten überprüft haben, müssen Sie zuerst auch das 1000. Datenelement abfragen, das dem nicht gruppierten Index entspricht, und dann die ID ab dem 100.000. Datenelement zur Abfrage abrufen. 🎜🎜🎜Verwendung der 🎜Tag-Aufzeichnungsmethode🎜🎜🎜🎜🎜Vorteile: 🎜 Die Abfrageeffizienz ist sehr stabil und sehr schnell. 🎜🎜🎜Nachteile:🎜🎜- 不跨页查询,
- 需要一种类似连续自增的字段
关于第二点的说明: 该点一般都好解决,可使用任意不重复的字段进行排序即可。若使用可能重复的字段进行排序的字段,由于mysql对于相同值的字段排序是无序,导致如果正好在分页时,上下页中可能存在相同的数据。
实战案例
需求: 需要查询查询某一时间段的数据量,假设有几十万的数据量需要查询出来,进行某些操作。
需求分析 1、分批查询(分页查询),设计深分页问题,导致效率较慢。
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
伪代码实现:
//最小ID
String lastId = null;
//一页的条数
Integer pageSize = 2000;
List<P2pRecordVo> list ;
do{
list = listP2pRecordByPage(lastId,pageSize); //标签记录法,记录上次查询过的Id
lastId = list.get(list.size()-1).getId(); //获取上一次查询数据最后的ID,用于记录
//对数据的操作逻辑
XXXXX();
}while(isNotEmpty(list));
<select id ="listP2pRecordByPage">
select *
from p2p_detail_record ppdr where 1=1
<if test = "lastId != null">
and ppdr.id > #{lastId}
</if>
order by id asc
limit #{pageSize}
</select>这里有个小优化点: 可能有的人会先对所有数据排序一遍,拿到最小ID,但是这样对所有数据排序,然后去min(id),耗时也蛮长的,其实第一次查询,可不带lastId进行查询,查询结果也是一样。速度更快。
总结
1、当业务需要从表中查出大数据量时,而又项目架构没上ES时,可考虑使用标签记录法的方式,对查询效率进行优化。
2、从需求上也应该尽可能避免,在大数据量的情况下,分页查询最后一页的功能。或者限制成只能一页一页往后划的场景。
推荐学习:mysql视频教程
Das obige ist der detaillierte Inhalt vonSo lösen Sie das MySQL-Deep-Paging-Problem. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
 So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
Schritte zur Durchführung von SQL in Navicat: Verbindung zur Datenbank herstellen. Erstellen Sie ein SQL -Editorfenster. Schreiben Sie SQL -Abfragen oder Skripte. Klicken Sie auf die Schaltfläche Ausführen, um eine Abfrage oder ein Skript auszuführen. Zeigen Sie die Ergebnisse an (wenn die Abfrage ausgeführt wird).
