
 Datenbank
Redis
Der Unterschied zwischen der Strategie zur Speicherbeseitigung von Redis und der Strategie zur abgelaufenen Löschung
Datenbank
Redis
Der Unterschied zwischen der Strategie zur Speicherbeseitigung von Redis und der Strategie zur abgelaufenen Löschung
Der Unterschied zwischen der Strategie zur Speicherbeseitigung von Redis und der Strategie zur abgelaufenen Löschung


Empfohlenes Lernen: Redis-Video-Tutorial
Vorwort
Redis kann die Ablaufzeit für Schlüssel festlegen, daher muss ein entsprechender Mechanismus zum Löschen abgelaufener Schlüssel-Wert-Paare vorhanden sein. Diese Aufgabe ist der Ablauf Strategie zum Löschen von Schlüsselwerten.
Die „Speichereliminierungsstrategie“ und die „Ablauflöschstrategie“ von Redis werden von vielen Freunden leicht verwechselt. Obwohl diese beiden Mechanismen beide Löschvorgänge durchführen, sind die verwendeten Auslösebedingungen und Strategien unterschiedlich.
Heute erkläre ich Ihnen die „Strategie zur Speicherbeseitigung“ und die „Strategie zur abgelaufenen Löschung“.
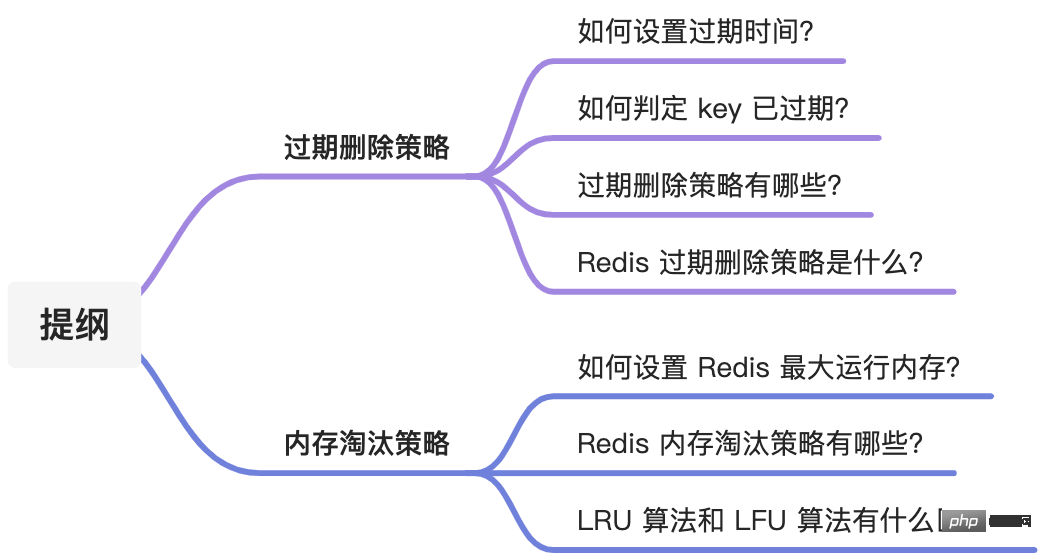
Abgelaufene Löschstrategie
Redis kann die Ablaufzeit für Schlüssel festlegen, daher muss ein entsprechender Mechanismus zum Löschen abgelaufener Schlüssel-Wert-Paare vorhanden sein, und was dies bewirkt, ist die Strategie zum Löschen abgelaufener Schlüsselwerte .
Wie stelle ich die Ablaufzeit ein?
Lassen Sie uns zunächst über den Befehl zum Festlegen der Ablaufzeit für den Schlüssel sprechen. Es gibt 4 Befehle zum Festlegen der Schlüsselablaufzeit:
- expire
: Den Schlüssel so einstellen, dass er nach n Sekunden abläuft - pexpire
: Schlüssel so einstellen, dass er nach n Millisekunden abläuft. Beispielsweise bedeutet pexpire key2 100000, dass Schlüssel2 nach 100000 Millisekunden abläuft. - expireat
key> : Schlüssel so einstellen, dass er nach einem bestimmten Zeitstempel abläuft (auf Millisekunden genau), zum Beispiel bedeutet pexpireat key4 1655654400000, dass Schlüssel4 nach dem Zeitstempel 1655654400000 abläuft (auf Millisekunden genau) - Natürlich, Beim Festlegen der Zeichenfolge können Sie auch die Ablaufzeit für den Schlüssel festlegen. Es gibt drei Befehle:
- set
px ; - setex
Geben Sie bei der Eingabe eines Schlüssel-Wert-Paares auch die Ablaufzeit an (auf Sekunden genau). - Wenn Sie die verbleibende Überlebenszeit eines Schlüssels überprüfen möchten, können Sie den TTL-Befehl
verwenden.
# 设置键值对的时候,同时指定过期时间位 60 秒 > setex key1 60 value1 OK # 查看 key1 过期时间还剩多少 > ttl key1 (integer) 56 > ttl key1 (integer) 52
Wenn Sie die Ablaufzeit des Schlüssels plötzlich bereuen und abbrechen, können Sie den Befehl PERSIST
# 取消 key1 的过期时间 > persist key1 (integer) 1 # 使用完 persist 命令之后, # 查下 key1 的存活时间结果是 -1,表明 key1 永不过期 > ttl key1 (integer) -1
Wie kann ich feststellen, ob der Schlüssel abgelaufen ist?
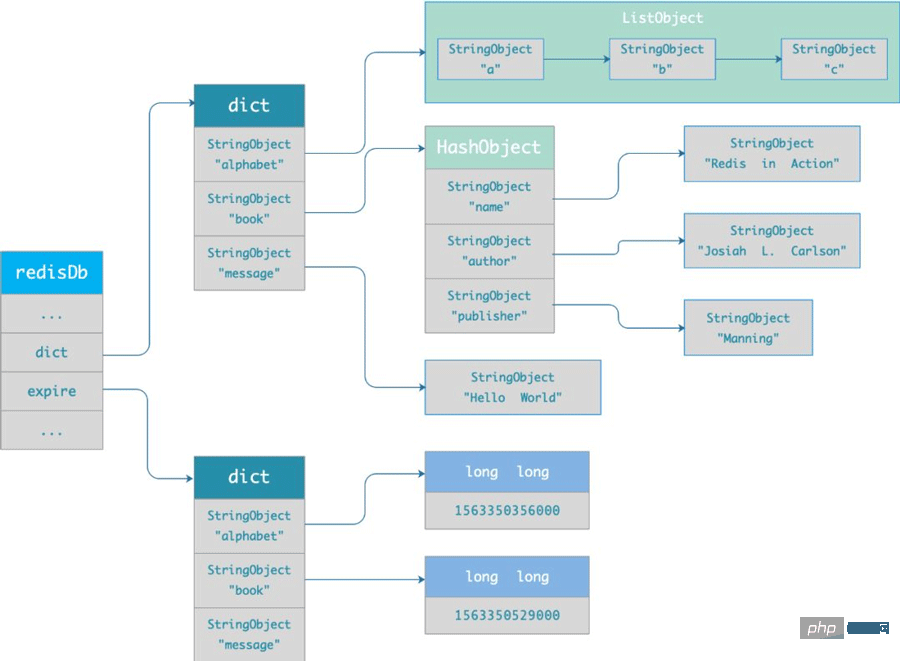
Immer wenn wir eine Ablaufzeit für einen Schlüssel festlegen, speichert Redis den Schlüssel mit der Ablaufzeit in einem Ablaufwörterbuch (expires dict). Mit anderen Worten: Das „Expires Dictionary“ speichert die Ablaufzeit aller Schlüssel in der Datenbank. .
Das abgelaufene Wörterbuch wird wie folgt in der redisDb-Struktur gespeichert:typedef struct redisDb {
dict *dict; /* 数据库键空间,存放着所有的键值对 */
dict *expires; /* 键的过期时间 */
....
} redisDb;
Der Schlüssel des abgelaufenen Wörterbuchs ist ein Zeiger, der auf ein bestimmtes Schlüsselobjekt zeigt ;
- Der Wert des abgelaufenen Wörterbuchs ist eine Ganzzahl vom Typ long long.
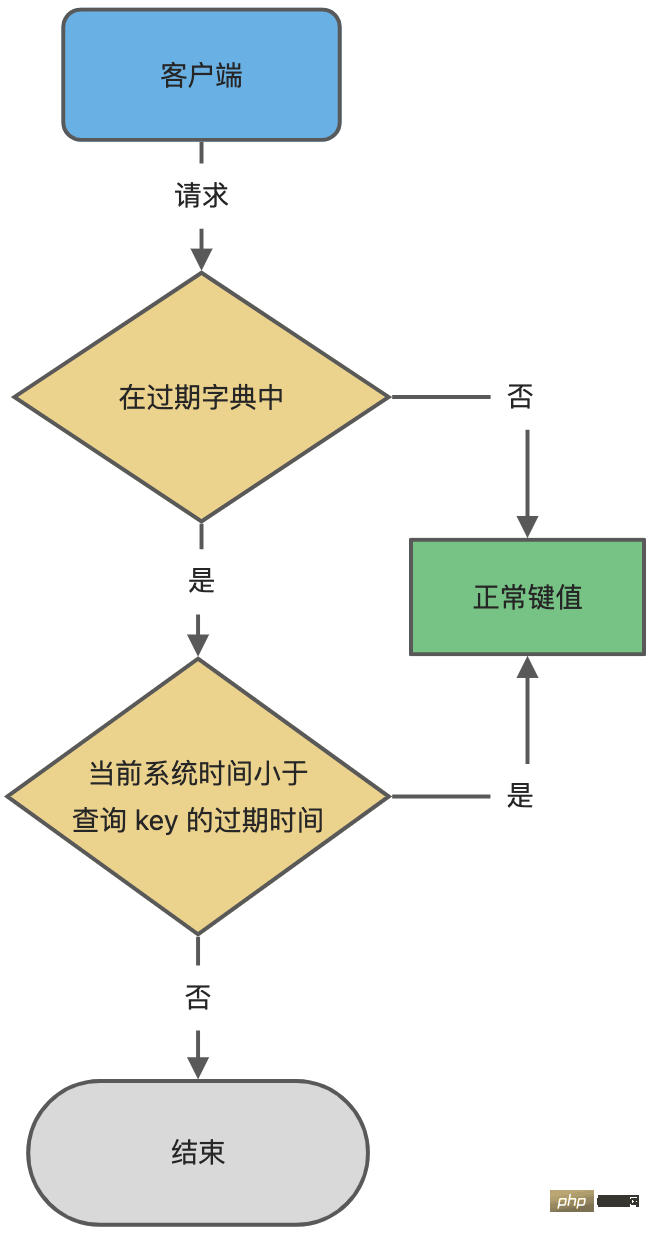
 Das Wörterbuch ist eigentlich eine Hash-Tabelle, und der größte Vorteil der Hash-Tabelle besteht darin, dass wir schnell mit der Zeitkomplexität O(1) suchen können. Wenn wir einen Schlüssel abfragen, prüft Redis zunächst, ob der Schlüssel im Ablaufwörterbuch vorhanden ist:
Das Wörterbuch ist eigentlich eine Hash-Tabelle, und der größte Vorteil der Hash-Tabelle besteht darin, dass wir schnell mit der Zeitkomplexität O(1) suchen können. Wenn wir einen Schlüssel abfragen, prüft Redis zunächst, ob der Schlüssel im Ablaufwörterbuch vorhanden ist:
- Wenn er vorhanden ist, wird die Ablaufzeit des Schlüssels ermittelt verglichen mit der aktuellen Systemzeit. Wenn sie größer als die Systemzeit ist, ist sie nicht abgelaufen. Andernfalls wird festgestellt, dass der Schlüssel abgelaufen ist.
Welche Strategien zum Löschen abgelaufener Schlüssel gibt es?
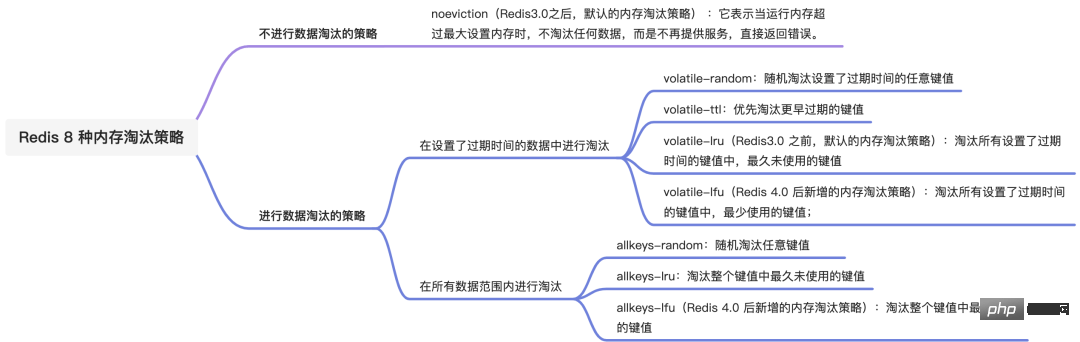
接下来,分别分析它们的优缺点。 定时删除策略是怎么样的? 定时删除策略的做法是,在设置 key 的过期时间时,同时创建一个定时事件,当时间到达时,由事件处理器自动执行 key 的删除操作。 定时删除策略的优点:可以保证过期 key 会被尽快删除,也就是内存可以被尽快地释放。因此,定时删除对内存是最友好的。 定时删除策略的缺点:在过期 key 比较多的情况下,删除过期 key 可能会占用相当一部分 CPU 时间,在内存不紧张但 CPU 时间紧张的情况下,将 CPU 时间用于删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。所以,定时删除策略对 CPU 不友好。 惰性删除策略是怎么样的?惰性删除策略的做法是,不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。 惰性删除策略的优点:因为每次访问时,才会检查 key 是否过期,所以此策略只会使用很少的系统资源,因此,惰性删除策略对 CPU 时间最友好。 惰性删除策略的缺点:如果一个 key 已经过期,而这个 key 又仍然保留在数据库中,那么只要这个过期 key 一直没有被访问,它所占用的内存就不会释放,造成了一定的内存空间浪费。所以,惰性删除策略对内存不友好。 定期删除策略是怎么样的?定期删除策略的做法是,每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。 定期删除策略的优点:通过限制删除操作执行的时长和频率,来减少删除操作对 CPU 的影响,同时也能删除一部分过期的数据减少了过期键对空间的无效占用。 定期删除策略的缺点: 前面介绍了三种过期删除策略,每一种都有优缺点,仅使用某一个策略都不能满足实际需求。 所以, Redis 选择「惰性删除+定期删除」这两种策略配和使用,以求在合理使用 CPU 时间和避免内存浪费之间取得平衡。 Redis 是怎么实现惰性删除的? Redis 的惰性删除策略由 db.c 文件中的 expireIfNeeded 函数实现,代码如下: Redis 在访问或者修改 key 之前,都会调用 expireIfNeeded 函数对其进行检查,检查 key 是否过期: 惰性删除的流程图如下: Redis 是怎么实现定期删除的? 再回忆一下,定期删除策略的做法:每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。 1.这个间隔检查的时间是多长呢? 在 Redis 中,默认每秒进行 10 次过期检查一次数据库,此配置可通过 Redis 的配置文件 redis.conf 进行配置,配置键为 hz 它的默认值是 hz 10。 特别强调下,每次检查数据库并不是遍历过期字典中的所有 key,而是从数据库中随机抽取一定数量的 key 进行过期检查。 2.随机抽查的数量是多少呢? 我查了下源码,定期删除的实现在 expire.c 文件下的 activeExpireCycle 函数中,其中随机抽查的数量由 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 定义的,它是写死在代码中的,数值是 20。 也就是说,数据库每轮抽查时,会随机选择 20 个 key 判断是否过期。 接下来,详细说说 Redis 的定时删除的流程: 可以看到,定时删除是一个循环的流程。 那 Redis 为了保证定时删除不会出现循环过度,导致线程卡死现象,为此增加了定时删除循环流程的时间上限,默认不会超过 25ms。 针对定时删除的流程,我写了个伪代码: 定时删除的流程如下: 前面说的过期删除策略,是删除已过期的 key,而当 Redis 的运行内存已经超过 Redis 设置的最大内存之后,则会使用内存淘汰策略删除符合条件的 key,以此来保障 Redis 高效的运行。 在配置文件 redis.conf 中,可以通过参数 maxmemory 不同位数的操作系统,maxmemory 的默认值是不同的: Redis 内存淘汰策略共有八种,这八种策略大体分为「不进行数据淘汰」和「进行数据淘汰」两类策略。 1.不进行数据淘汰的策略 noeviction(Redis3.0之后,默认的内存淘汰策略) :它表示当运行内存超过最大设置内存时,不淘汰任何数据,而是不再提供服务,直接返回错误。 2.进行数据淘汰的策略 针对「进行数据淘汰」这一类策略,又可以细分为「在设置了过期时间的数据中进行淘汰」和「在所有数据范围内进行淘汰」这两类策略。 在设置了过期时间的数据中进行淘汰: 在所有数据范围内进行淘汰: 如何查看当前 Redis 使用的内存淘汰策略? 可以使用 config get maxmemory-policy 命令,来查看当前 Redis 的内存淘汰策略,命令如下: 可以看出,当前 Redis 使用的是 noeviction 类型的内存淘汰策略,它是 Redis 3.0 之后默认使用的内存淘汰策略,表示当运行内存超过最大设置内存时,不淘汰任何数据,但新增操作会报错。 如何修改 Redis 内存淘汰策略? 设置内存淘汰策略有两种方法: LFU 内存淘汰算法是 Redis 4.0 之后新增内存淘汰策略,那为什么要新增这个算法?那肯定是为了解决 LRU 算法的问题。 接下来,就看看这两个算法有什么区别?Redis 又是如何实现这两个算法的? 什么是 LRU 算法? LRU 全称是 Least Recently Used 翻译为最近最少使用,会选择淘汰最近最少使用的数据。 传统 LRU 算法的实现是基于「链表」结构,链表中的元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要内存淘汰时,只需要删除链表尾部的元素即可,因为链表尾部的元素就代表最久未被使用的元素。 Redis 并没有使用这样的方式实现 LRU 算法,因为传统的 LRU 算法存在两个问题: Redis 是如何实现 LRU 算法的? Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。 当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。 Redis 实现的 LRU 算法的优点: 但是 LRU 算法有一个问题,无法解决缓存污染问题,比如应用一次读取了大量的数据,而这些数据只会被读取这一次,那么这些数据会留存在 Redis 缓存中很长一段时间,造成缓存污染。 因此,在 Redis 4.0 之后引入了 LFU 算法来解决这个问题。 什么是 LFU 算法? LFU 全称是 Least Frequently Used 翻译为最近最不常用的,LFU 算法是根据数据访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。 所以, LFU 算法会记录每个数据的访问次数。当一个数据被再次访问时,就会增加该数据的访问次数。这样就解决了偶尔被访问一次之后,数据留存在缓存中很长一段时间的问题,相比于 LRU 算法也更合理一些。 Redis 是如何实现 LFU 算法的? LFU 算法相比于 LRU 算法的实现,多记录了「数据的访问频次」的信息。Redis 对象的结构如下: Redis 对象头中的 lru 字段,在 LRU 算法下和 LFU 算法下使用方式并不相同。 在 LRU 算法中,Redis 对象头的 24 bits 的 lru 字段是用来记录 key 的访问时间戳,因此在 LRU 模式下,Redis可以根据对象头中的 lru 字段记录的值,来比较最后一次 key 的访问时间长,从而淘汰最久未被使用的 key。 在 LFU 算法中,Redis对象头的 24 bits 的 lru 字段被分成两段来存储,高 16bit 存储 ldt(Last Decrement Time),低 8bit 存储 logc(Logistic Counter)。 注意,logc 并不是单纯的访问次数,而是访问频次(访问频率),因为 logc 会随时间推移而衰减的。 Jedes Mal, wenn auf den Schlüssel zugegriffen wird, wird zuerst eine Abklingoperation für logc durchgeführt. Der Abklingwert hängt von der Differenz zwischen der vorherigen und der nachfolgenden Zugriffszeit ab. Wenn der Zeitunterschied zwischen der letzten Zugriffszeit und dieser Zugriffszeit groß ist, dann ist der Dämpfungswert Je größer er ist, desto mehr eliminiert der auf diese Weise implementierte LFU-Algorithmus Daten basierend auf der Zugriffshäufigkeit und nicht nur auf der Anzahl der Zugriffe. Bei der Zugriffshäufigkeit muss berücksichtigt werden, wie lange der Schlüsselzugriff erfolgt. Je länger der vorherige Zugriff des Schlüssels vom aktuellen Zeitpunkt an zurückliegt, desto geringer wird die Zugriffshäufigkeit dieses Schlüssels und desto größer ist die Wahrscheinlichkeit, dass er eliminiert wird. Starten Sie nach Abschluss der Dämpfungsoperation für logc die Erhöhungsoperation für logc. Die Erhöhungsoperation erfolgt nicht einfach direkt um +1, sondern erhöht sich basierend auf der Wahrscheinlichkeit. Je größer der logc für einen Schlüssel ist, desto schwieriger wird es, ihn zu erhöhen logc. Wenn Redis also auf den Schlüssel zugreift, ändert sich logc wie folgt: redis.conf bietet zwei Konfigurationselemente zum Anpassen des LFU-Algorithmus, um das Wachstum und den Abfall von logc zu steuern: Die von Redis verwendete Strategie zum Löschen abgelaufener Daten ist „verzögertes Löschen + reguläres Löschen“, und die gelöschten Objekte sind abgelaufene Schlüssel. Die Speichereliminierungsstrategie besteht darin, das Problem des übermäßigen Speichers zu lösen. Wenn der laufende Speicher von Redis den maximalen laufenden Speicher überschreitet, wird die Speichereliminierungsstrategie ausgelöst Ich denke auch, dass 8 Strategien wie folgt klassifiziert sind: Das obige ist der detaillierte Inhalt vonDer Unterschied zwischen der Strategie zur Speicherbeseitigung von Redis und der Strategie zur abgelaufenen Löschung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!Redis 过期删除策略是什么?
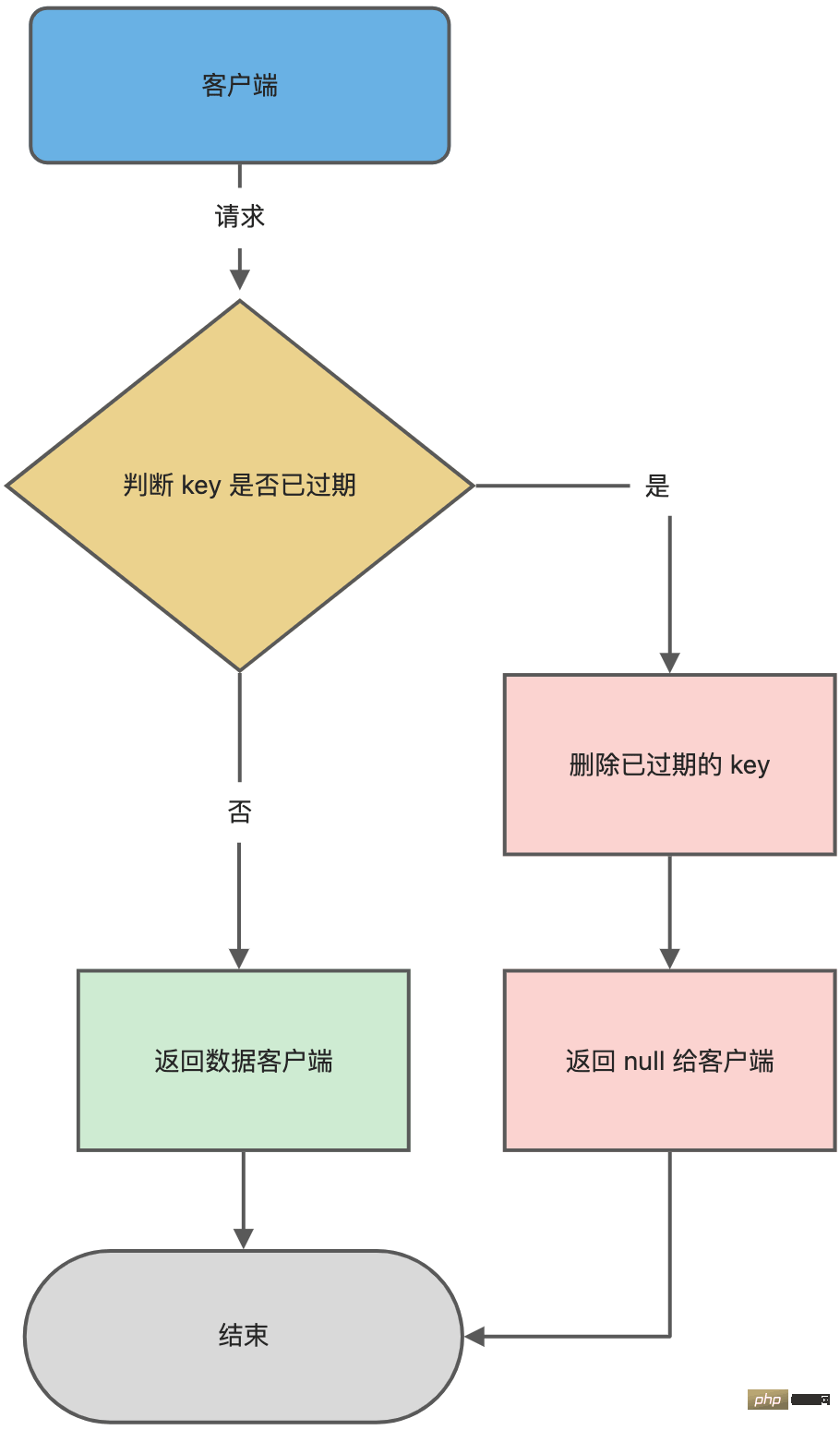
int expireIfNeeded(redisDb *db, robj *key) {
// 判断 key 是否过期
if (!keyIsExpired(db,key)) return 0;
....
/* 删除过期键 */
....
// 如果 server.lazyfree_lazy_expire 为 1 表示异步删除,反之同步删除;
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}
do {
//已过期的数量
expired = 0;
//随机抽取的数量
num = 20;
while (num--) {
//1. 从过期字典中随机抽取 1 个 key
//2. 判断该 key 是否过期,如果已过期则进行删除,同时对 expired++
}
// 超过时间限制则退出
if (timelimit_exit) return;
/* 如果本轮检查的已过期 key 的数量,超过 25%,则继续随机抽查,否则退出本轮检查 */
} while (expired > 20/4);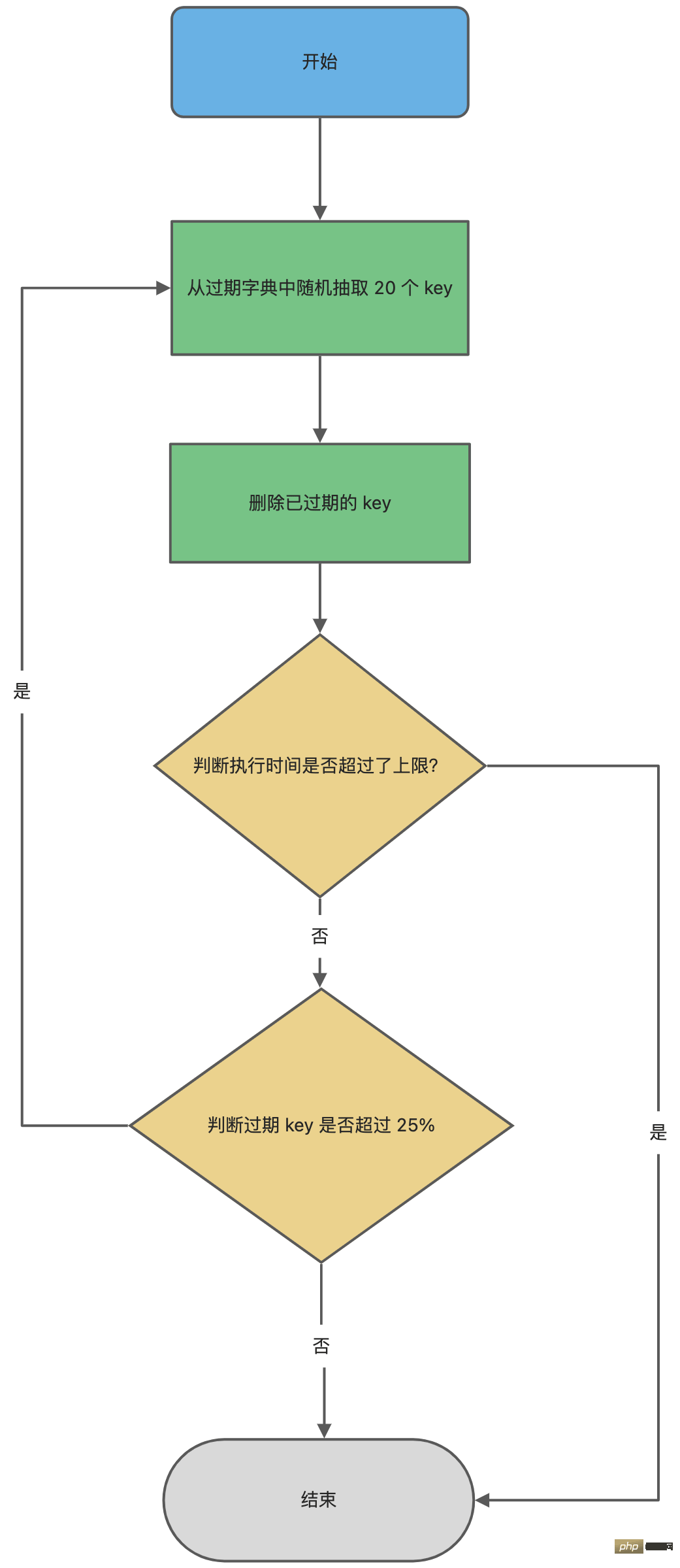
内存淘汰策略
如何设置 Redis 最大运行内存?
Redis 内存淘汰策略有哪些?
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "noeviction"
LRU 算法和 LFU 算法有什么区别?
typedef struct redisObject {
...
// 24 bits,用于记录对象的访问信息
unsigned lru:24;
...
} robj;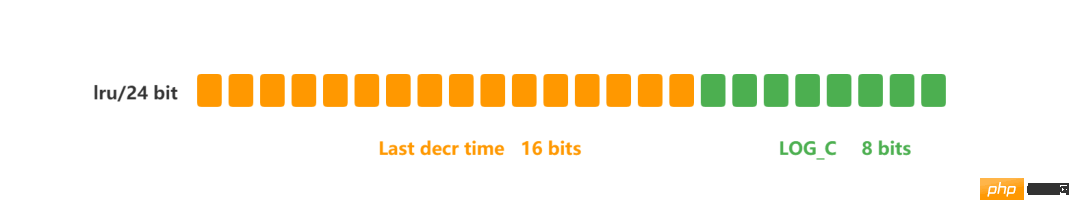
Zusammenfassung


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Warum tritt bei der Installation einer Erweiterung mit PECL in einer Docker -Umgebung ein Fehler auf? Wie löst ich es?
Apr 01, 2025 pm 03:06 PM
Warum tritt bei der Installation einer Erweiterung mit PECL in einer Docker -Umgebung ein Fehler auf? Wie löst ich es?
Apr 01, 2025 pm 03:06 PM
Ursachen und Lösungen für Fehler Bei der Verwendung von PECL zur Installation von Erweiterungen in der Docker -Umgebung, wenn die Docker -Umgebung verwendet wird, begegnen wir häufig auf einige Kopfschmerzen ...
 Was ist der Grund, warum die Redis -Liste gleichzeitiger Pop -Betrieb einen leeren Wert zurückgibt?
Apr 01, 2025 pm 02:39 PM
Was ist der Grund, warum die Redis -Liste gleichzeitiger Pop -Betrieb einen leeren Wert zurückgibt?
Apr 01, 2025 pm 02:39 PM
Redis ...
 Wie kann ich mehrere Dienste in DockerFile effizient starten?
Apr 01, 2025 pm 02:15 PM
Wie kann ich mehrere Dienste in DockerFile effizient starten?
Apr 01, 2025 pm 02:15 PM
Über die effiziente Verwendung von CMD -Befehlen in Dockerfile viele neue Docker -Benutzer verwenden CMD ...
 Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Das Problem der Verwendung von RETISTREAM zur Implementierung von Nachrichtenwarteschlangen in der GO -Sprache besteht darin, die Go -Sprache und Redis zu verwenden ...
 Vergleich von Redis -Warteschlangen und MySQL -Stabilität: Warum ist Redis für den Datenverlust anfällig?
Apr 01, 2025 pm 02:24 PM
Vergleich von Redis -Warteschlangen und MySQL -Stabilität: Warum ist Redis für den Datenverlust anfällig?
Apr 01, 2025 pm 02:24 PM
Vergleich von Redis -Warteschlangen und MySQL -Stabilität: Warum ist Redis für den Datenverlust anfällig? In der Entwicklungsumgebung, die mit PHP7.2- und ThinkPhp -Frameworks verwendet wird, stehen wir häufig vor der Wahl der Zusammenarbeit ...
 Wie kann man die Gültigkeit von Redis -Verbindungen im Laravel6 -Projekt effektiv überprüfen?
Apr 01, 2025 pm 02:00 PM
Wie kann man die Gültigkeit von Redis -Verbindungen im Laravel6 -Projekt effektiv überprüfen?
Apr 01, 2025 pm 02:00 PM
Wie man die Gültigkeit von Redis -Verbindungen in Laravel6 -Projekten überprüft, ist ein häufiges Problem, insbesondere wenn Projekte auf Redis für die Geschäftsverarbeitung angewiesen sind. Das Folgende ist ...
 So wenden Sie Debian Strings auf einer Website an
Apr 02, 2025 am 08:21 AM
So wenden Sie Debian Strings auf einer Website an
Apr 02, 2025 am 08:21 AM
In diesem Artikel wird erläutert, wie die Website der Website auf Debian -Systemen optimiert wird. "DebianStrings" ist kein Standardbegriff und kann sich auf Tools oder Technologien beziehen, die in Debian -Systemen verwendet werden, um die Website der Website zu verbessern. Im Folgenden finden Sie einige praktische Tipps: 1. Es wird empfohlen, das Pagode -Panel zu verwenden, um den Installations- und Konfigurationsprozess für die Konfiguration von Webserver und PHP -Umgebung zu vereinfachen. Es wird empfohlen, Nginx1.22.1 als Webserver, Php8.2 als Skript-Interpreter und MySQL10.7.3-MariADB als Datenbanksystem zu installieren. Stellen Sie sicher, dass Sie die erforderlichen PHP
 Wie wähle ich die am besten geeignete Cache -Strategie aus, wenn Django und MySQL große Datenvolumina verarbeiten?
Apr 01, 2025 pm 03:33 PM
Wie wähle ich die am besten geeignete Cache -Strategie aus, wenn Django und MySQL große Datenvolumina verarbeiten?
Apr 01, 2025 pm 03:33 PM
Django Mysql ...
